Dynamic Uncertainty-Based Analytics for Caching Performance Improvements in Mobile Broadband Wireless Networks
Abstract
With the increasing popularity of Netflix, Yahoo! Video, etc., interactive multimedia services such as video-on-demand (VoD) provide an interesting and rich field of research. The advent of smarter wireless devices has resulted in increased prevalence for such services through wireless connectivity. Personalization of individual user needs and providing reduced latency under heterogeneous and dynamically varying user demands have therefore become important. However, simultaneously maintaining low operational costs along with low user latency under uncertainty and heterogeneity in user spatio-temporal behavior and video demand is a challenging problem. In this chapter, we describe the working principles of a recently proposed intelligent and efficient VoD framework for wireless mobile devices that handles dynamic uncertainty using a predictive, analytics-driven lookahead. We present an end-to-end architecture leading to a better quality of experience (QoE) for users with limited infrastructural changes, along with enhanced performance and low operational costs. We also introduce an efficient caching algorithm, the intelligent network caching algorithm (INCA), that uses an analytics-driven lookahead scheme for both prefetch and replacement policies to deliver higher performance. Additionally, we delve into the theoretical formulation of the QoE optimization problem that explicitly models dynamic uncertainty in user behavior, and lies at the intersection of Markov predictive control and Markov decision process. Further, using empirical analysis over realistic user video query logs we demonstrate a better hit rate and QoE with low prefetch bandwidth for INCA as compared with well-known caching schemes.
Keywords
Video-on-demand; Lookahead predictive caching; Collaborative filtering; Quality-of-experience; User latency
16.1 Introduction
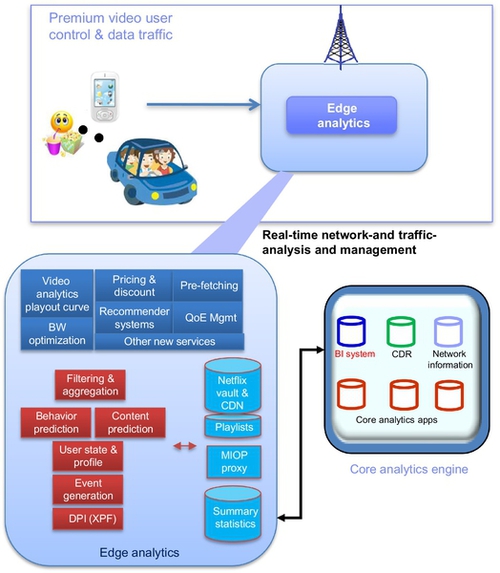
The rapid evolution of wireless network-based services has been augmented by significant developments in network technologies, cheaper infrastructure, and diversified business strategies. As such, interactive multimedia technology and its applications have recently received a great deal of attention from the industry, as well as from researchers. The promise of viewing movies, holding conferences, browsing online bookstores, online shopping and many other activities from the confines of one’s home is quite lucrative. The advent of mobile devices and smartphones such as iPhones, iPads and others, has provided users with a wealth of applications and services anywhere, anytime. Development of such interactive multimedia systems incurs a diverse set of technical difficulties, many of which are intractable in isolation. A complete architectural framework that efficiently tackles the problems continues to be a significant obstacle. Wireless analytics would enable catering to a broad range of ubiquitous services such as advertising recommendations, location-based services, and other use-case scenarios, some of which are presented in Fig. 1.
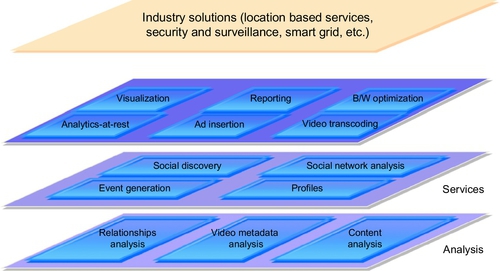
One of the key emerging applications is video-on-demand (VoD), wherein a user may request movie clips, trailers, video songs, etc., on his/her wireless device. Such services combine the quality of TV while enabling the same interactions as that of a DVD. Advancements in information retrieval, networking, and digital signal processing have augured the need for such services for end users. Streaming of a requested video involves a latency, or wait period for the users while the video is fetched. Naïve approaches involving dedicated video streams or sessions per user for reducing the latency are not viable given the enormous infrastructure requirements. On the other end of the spectrum, batch mode viewing and resource sharing among users calls for far less engagement of the providers, but leads to a delayed response.
Several solutions, such as the split-and-merge protocol [1], co-operative caching [2] using Vickrey-Clarke-Groves (VCG) auctions, the segment-based buffer management approach [3], and MPEG-4 fine grained scalable (FGS) video with post-encoding rate control [4], among others, have been proposed for improving hit rates while lowering storage costs. However, these methods are limited in that their transmission characteristics are inadequate for bandwidth-intensive applications or for large numbers of simultaneous users. Although GigE and DWDM hardware technologies (from Motorola) cater to scalable VoD along with push-pull policies for peer-to-peer VoD systems [5], limited work exists in the theoretical formulation of the quality-of-experience (QoE) optimization problem, and leveraging insights from user patterns and fine-grain user profiles [6] to improve cache performance.
In this chapter, we discuss the state-of-the-art method for how predictive analytics can be leveraged to improve the QoE from both theoretical and experimental perspectives. The users' movement and access patterns exhibit dynamic temporal uncertainty — where uncertainty changes as more information is revealed after every action. In these scenarios, using short-term predictions (leveraging analytics) about the behavior of the system, the information about future time steps is refined as we get close to them. The QoE optimization problem is thus formulated as an online resource allocation problem that lies at the intersection of Markov predictive control (MPC) (incorporates predictions) and Markov decision processes (MDP) (model state and action space).
This chapter discusses a recently proposed VoD framework employing an intelligent caching mechanism based on user behavior predictions, enabling low latency as well as scalability. We impress the need for Big Data architecture and paradigms to tackle the massive amount of data involved. We further present an outline for the theoretical formulation of the QoE optimization problem and a framework that uses a k-lookahead scheme for higher cache performance. This leads to an efficient VoD system that ensures a better QoE of the users. We also present the novel analytics-driven video caching algorithm, intelligent network caching algorithm (INCA), that leverages prediction of the location of users and request patterns using historical data and performs lookahead-based prefetch and replacement. This helps in avoiding backhaul congestion as well as in reducing the access latency for end users with low prefetch costs.
16.1.1 Big Data Concerns
Given the proliferation of mobile devices and the popularity of associated multimedia services, traditional approaches further suffer from the data deluge problem. Typically, the call data records (CDRs) or the event data records (EDRs), including the subscriber information, caller-callee information, temporal data, and other factors, can be in the order of 300 GB per day to cater to over 50 million subscribers. This is further aggravated in the VoD scenario with user-profile information (eg, age, language, etc.), movie preferences, list of watched videos, among others. For performing predictive analysis in the VoD framework, one needs to process the massive CDR data as well as the deep packet inspection (DPI) data to gather information on videos watched and URLs accessed.
Given these constraints, scalable Big Data architectures such as Hadoop (with Pig/Spark) and efficient data stores such as Hbase along with fast SQL query engines like PrestoDB are vital to efficiently process such massive data. In addition to handling massive data, this problem requires execution of the following computationally expensive kernels:
• Social network analysis: community detection algorithms for recommendations.
• Segmentation using CRM and movie-watched information: clustering algorithms such as Gaussian mixture models.
• Association rule mining: extracting meaningful patterns and rules (along with confidence and support) using user spatio-temporal data.
• Collaborative filtering analysis using a hybrid approach: providing video/genre recommendations to users using ratings and usage data as well as the metadata of the movies and user-profile information.
• Rank aggregation or ranking algorithm: combining a video preference list of the users to form a single list that fits in the cache at the basestation.
In fact, when the proposed VoD framework is deployed at higher levels of the wireless network architecture, such as the RAN or SGSN level, it results in even more processing requirements for both compute and data handling.
16.1.2 Key Focus Areas
In a nutshell, the salient areas of focus of this chapter are as follows:
• We provide an extensive discussion on the existing wireless network architecture, and existing works on VoD services.
• We present the complete architectural structure for an end-to-end efficient scalable VoD framework, simultaneously providing user personalization, reduced latency and operational costs.
• We describe the recently proposed video caching algorithm, INCA [7,8] combining predictive analytics and caching models. It leverages user location and request pattern mining (from historical data) and performs k-lookahead schemes for cache prefetch and replacement. This leads to higher cache hits and a better QoE for the users. This further helps in avoiding backhaul congestion as well as incurring low prefetch costs.
• We also provide a theoretical formulation of the QoE optimization problem, and provide a performance bound for our algorithm.
• We demonstrate experimental results to demonstrate that with a small increase (less than 10%) in prefetch bandwidth, INCA achieves a 15–20% QoE improvement and around 12–18% improvement in the number of satisfied users over well-known caching strategies.
16.2 Background
16.2.1 Cellular Network and VoD
For a cellular network, the base stations (BS), along with the radio network controllers (RNC), are equipped with IT capabilities, and thus edge analytics would enable us to track real-time user context to enhance service delivery and improve overall QoE for the end users. In this context, we define:
Edge This refers to the basestations (BS), or the (distributed) wireless system comprising the BS, to which a user connects. The edge is restricted in its storage capacity and computational capability. The primary role of the edge lies in performing fast online or incremental analytics. In the remainder of the chapter we use the terms “edge” and “BS” interchangeably.
Core This refers to the central backbone components of the network comprising RNC, SGSN, and GGSN, and is considered to be endowed with practically infinite storage and computation resources for performing rigorous batch mode or offline analytics.
The edge takes part in the real-time handling of users (device hand-off, etc.) and other analytical decisions. The core, bestowed with greater storage and computing power, usually works in an offline fashion, receives online user tracking from the basestations, updates the historical database correspondingly, and executes a rigorous frequent-pattern-mining, association-rule-mining algorithm to generate the frequent rules and behaviors on a per-user basis. These rules are later queried by the edges for subsequent online processing (eg, ranking and prefetching). It also handles housing, log generation, and updating the databases and performing queries. Thus, an efficient system evolves as a result of interplay between the online and offline computations.
The combination of frequent pattern mining, prediction, and aggregation of the results forms the basis of the INCA algorithm and provides a novel approach to efficiently tackle the expanse of such network-based services. The proposed system can cater not only to the VoD domain, but also other wireless network-based applications such as advertisement insertion, location-based services, etc., thereby making it a general framework for a broad range of scenarios requiring network intelligence and analytics at the heart.
A typical VoD scenario involves a user request to the basestation. If the requested video is available, it is directly streamed. Otherwise, the basestation initiates a request to the core. The video is then fed to the basestation from where it is provided to the users. Fig. 2 depicts a simple VoD request scenario.
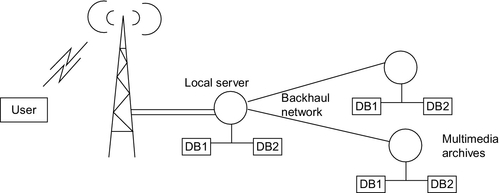
Interactive VoD services can be broadly classified into the following categories [9,10]:
2. pay-per-view,
3. quasi VoD,
4. near VoD, and
5. true Video-on-Demand (T-VoD).
In this chapter, we aim to propose a novel framework for delivering T-VoD by efficiently prepopulating the cache of the basestations with the most probable user request videos, thereby increasing the hit ratio and reducing user latency.
16.2.2 Markov Processes
MDPs are applicable in fields characterized by uncertain state transitions and a necessity for sequential decision making, such as robot control, manufacturing, traffic signal control and others. MDPs satisfy the Markov property, defining that the state transitions are conditionally independent of actions and states encountered before the current decision step. An agent can therefore rely on a policy that directly maps states to actions for determining the next action. After execution of an action, the system is assumed to stay in the new state until the next action, ie, the system, has no autonomous behavior.
At each step the system is in one of these possible finite sets of states: 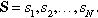 In each state,
In each state, 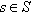 there exists a finite set of actions, As, that the agent can perform
there exists a finite set of actions, As, that the agent can perform 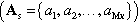 . The system evolves according to the system model,
. The system evolves according to the system model, 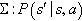 , where
, where 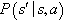 is the probability of transitioning from state s to state s′ after action a is performed. The performance function is given by r, where R(x, a, x ′, w) is the reward obtained with the transition from state s to state s′ under action a and state of nature,
is the probability of transitioning from state s to state s′ after action a is performed. The performance function is given by r, where R(x, a, x ′, w) is the reward obtained with the transition from state s to state s′ under action a and state of nature, 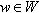 . The fundamental problem of the MDP is to find a function that specifies the action π(st) that needs to be chosen at state s and time t. The goal is to choose π in such a way that maximizes the expected reward under some cumulative function. Mathematically:
. The fundamental problem of the MDP is to find a function that specifies the action π(st) that needs to be chosen at state s and time t. The goal is to choose π in such a way that maximizes the expected reward under some cumulative function. Mathematically:
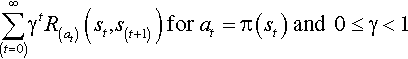
Here, γ is typically close to one and is known as the discount factor.
The MDP can be solved using dynamic programming. Suppose we know the state transition function P and the reward function R, and we wish to calculate the policy that maximizes the expected discounted reward. The standard family of algorithms to calculate this optimal policy requires storage of two arrays indexed by state value V, which contains real values, and policy π which contains actions. At the end of the algorithm, π will contain the solution and V(s) will contain the discounted sum of the rewards to be earned (on average) by following that solution from state s. The algorithm has the following two kinds of steps, which are repeated in some order for all the states until no further changes take place. They are defined recursively as follows:
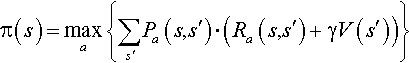
In the preceding equation, a stands for the action taken to change the state of the machine from s to s′. Next, the V(s) is computed as:
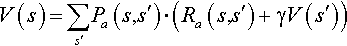
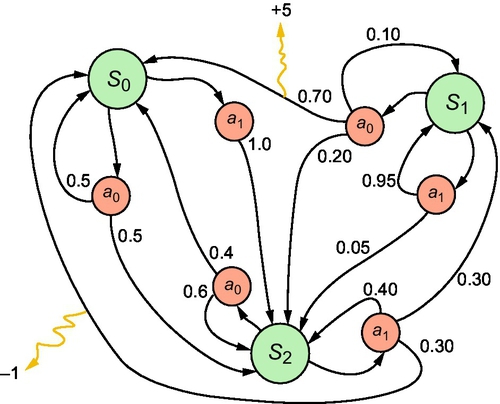
Fig. 3 demonstrates a simple MDPs with three event states and two actions. INCA leverages a predictive analytics framework to compute reasonable accuracy on the predicted state of nature for k steps into the future. A typical sequence of events, when the online algorithm is in state, st, at the start of time step t, is as follows:
(1) the active disturbances set W is chosen arbitrarily by nature (as an adversary) and it is revealed to the online algorithm with certain accuracy;
(2) the online algorithm takes some action a and moves to state σ(s, a) and obtains a reward R(s, a, w); and
(3) time is incremented to t ← t + 1.
In this context, an offline algorithm with the total reward OFF has prescient information regarding the disturbance profile. The regret of the online algorithm equals the maximum value of (OFF − ON), and the competitive ratio equals the maximum value of (OFF/ON), over all choice of the disturbance parameters, where ON is the total reward obtained by the online algorithm. Further, the average regret is defined as ((OFF − ON)/T) over a time horizon T.
16.3 Related Work
Numerous approaches in the past have been studied for efficient video caching that cover a variety of techniques including collapsing of multiple related cache entries, collaborative caching, distributed caching over femto-cells, and the segment-based buffer management approach.
Shen and Akella [11] introduced a video-centric proxy cache called iProxy. iProxy [11] uses information-bound references to collapse multiple related cache entries into a single one, improving hit-rates while lowering storage costs. iProxy incorporates a novel dynamic linear rate adaptation scheme to ensure high stream quality in the face of channel diversity and device heterogeneity. Our framework can leverage these techniques (with minor modifications) to improve cache performance and lower storage costs. Zhang et al. [12] introduced a price-based cache replacement algorithm for a single cache server. For the case of multiple cache servers, the authors present a server selection algorithm. Tan et al. [13] introduced a smart caching design to replicate video contents in multiple access points which improves the quality of experience by reducing the delay of video streaming.
For collaborative clustering, He et al. [14] decomposed the problem of caching video into two sub-problems, namely:
(a) content selection problem and
(b) server selection problem.
They then developed a system capacity reservation strategy to solve the content placement problem. For the source selection problem, the authors proposed an adaptive traffic aware algorithm known as LinkShare. Borst et al. [15] designed a distributed hierarchical cache clustering algorithm to maximize the traffic volume served by caches while minimizing the total bandwidth cost. However, the algorithm performs well only when the request pattern across all the nodes is uniform.
Prior works on efficient video caching can be categorized into one of the following four approaches:
(b) collaborative caching,
(c) segment-based buffer management, and
(d) adaptive video caching.
Some of the important works in the area of independent caching are [11–13,16].
Collaborative caching paradigms among cache servers that are deployed by different wireless service providers (WSPs) has also been studied in [2] to consider benefits and address the challenges related to both incentives and truthfulness of selfish WSPs. Dai et al. [2] proposes a collaborative mechanism that aims to maximize social welfare in the context of VCG auctions (used in game theory). The incentives designed for WSPs encourage them to spontaneously and truthfully cooperate for trading their resources in a self-enforcing manner. The simulation results show that the performance of streaming systems can be substantially improved by maximizing the social welfare in these auctions, in which bandwidth units are used to serve more valuable demands.
The segment-based buffer management approach [3] for multimedia streams groups blocks of media stream into variable-sized segments. The cache admission and replacement policies are then performed on a per-segment basis. Segment-based caching leads to an increase in the byte-hit ratio (total traffic reduction) as well as a reduction in the number of requests that require a delayed start, and is especially useful for limited cache sizes and when the set of hot media objects changes over time. We use segment-based caching in our VoD framework. Wu et al. [3] demonstrated the effectiveness of the variable-sized distance sensitive segment caching schemes for large media objects. This is a recursive scheme where a media file is divided into multiple equal sized blocks. Multiple blocks are then grouped into a segment by a proxy server. The cache admission and replacement policy for the proxy server attaches different values of priority to different segments. The size of a segment is sensitive to its distance from the beginning of the media. The smaller the distance, the smaller the size. In general, the size of the segment i + 1 is twice the size of the segment i. The purpose of doubling the size for the consecutive segments is to let the cache manager discard a big chunk of cached media objects, especially if a viewer decides to stop viewing the video. However, the scheme may not be much more effective for videos of smaller sizes.
An adaptive video caching framework that enables low-cost and fine-grained adaptation has been proposed [4] which employs MPEG-4 FGS video with post-encoding rate control. This framework is designed to be both network-aware and media-adaptive. Zhang et al. [12] presents a lookahead video delivery scheme for stored video delivery in multi-cell networks that simultaneously improves the streaming experience as well as reduces the basestation power consumption. It exploits the knowledge of future wireless rates that users can anticipate facing. We leverage the behavior of user mobility and video access to deliver higher cache performance using lookahead-driven prefetch and replacement policies.
Further, uncertainty handling is critical in mobile and video caching scenarios. Robust planning under uncertainty has been studied in the past in multiple contexts, including renewable energy such as solar and wind, financial markets, and others. Over the last couple of decades, MPC has become an important technology for finding control policies for complex, dynamic systems as found in the process industry and other domains. MPC is based on models that describe the behavior of the systems which could consist of differences or differential equations or MDPs. Regan and Boutilier [17] presents a method for computing approximate robust solutions to imprecise-reward MDPs in the context of online reward elicitation. It presents the non-dominated region vertex algorithm, deriving from insights in partially observable MDPs which generates approximate sets of nondominated policies with provable error bounds. This can be leveraged to efficiently approximate minimax regret using existing constraint generation methods. Regan and Boutilier [17] also shows how online optimization of the non-dominated set, as reward knowledge is refined, allows regret to quickly decrease to zero with only a small fraction of all non-dominated policies.
Incorporation of short-term predictions under dynamic temporal uncertainty for renewable integration in intelligent energy systems has been studied in [3]. It provides online randomized and deterministic algorithms to handle time-varying uncertainty in future rewards for nonstationary MDPs for energy resource allocation; and also presents theoretical upper and lower bounds that hold for a finite horizon. In the deterministic case, discounting future rewards can be used as a strategy to maximize the total (undiscounted) reward. This chapter discusses INCA, which presents the first theoretical model of the QoE optimization problem for video caching under dynamic temporal uncertainty and compares the results of our lookahead-driven caching with the algorithm presented in [18]. Negenborn et al. [19] proposes a learning-based extension for reducing the online computational cost of the MPC algorithm, using reinforcement learning to learn expectations of performance online. The approach allows for system models to gradually change over time, reduces computations over conventional MPC, and improves decision quality by making decisions over an infinite horizon.
16.4 VoD Architecture
This section presents the detailed architectural design of the recently proposed VoD framework and the interactions among the various subsystems therein [7,8]. The framework works by predicting the impending actions of the current and future users (from historical data) within the ambit of each basestation, and utilizes them to improve the startup latency, or QoE, as well as reduce the video delivery cost for the service providers.
The logical working of the system is modularized into two related components, the edge and the core. The handoff of a user into the ambit of a basestation (BS), or a video request by an existing user, generates an event record at the BS. The set of such events are forwarded to the core and logged to be used as historical data for mining predictive rules for users. These events may also be used by the edge for rule updating in realtime. The core uses rigorous predictive algorithms such as associative rule mining to generate intelligence regarding user behavior for optimizing the QoE of the users for video, network constraints, and other requirements of the providers. The overall components at play for such scenarios are summarized in Fig. 4.
16.5 Overview
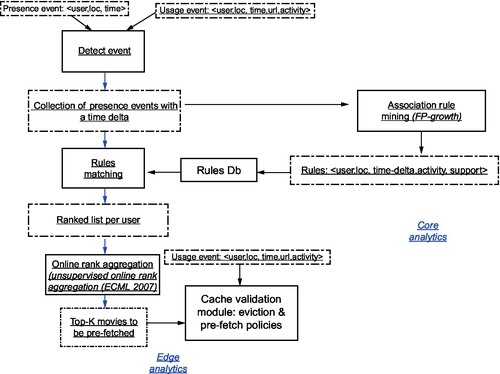
Given a basestation, B and time, t, we would like to predict and prefetch the probable videos to be requested at time t + 1 along with videos that could be used multiple times in future time slots (referred to as a lookahead scheme). Using historical data and by considering the current location and direction of movement of the users, we initially predict the users that might be connected to B at t + 1.
Given this set of probable users, the edge is fed the complete set of video watching patterns and rules of the users by the core. Video usage pattern rules of these users are provided to the edge by the core. Along with possible user-generated view-lists, user usage pattern rules are generated based on historical data using association rule mining techniques. Further, collaborative filtering is applied to also obtain other probable requests based on similar interests of different users, along with the other currently most-watched ones or videos relating to real-time occurring events, eg, budgeting, sports, etc. This procedure further strengthens the prediction confidence of user video requests based on other users sharing the same taste and behavior [20].
Based on the complete set of rules for all such users, the support and confidence of each rule, and the view lists of the users, a preferred ordering or ranking of the different videos is computed in an online fashion. This ranked corpus then guides the decision as to which videos should be prefetched or evicted from the edge cache. Without loss of generality, we assume that users usually request videos from their preferred viewlist. Fig. 5 represents the components and a top-level information flow within the framework.
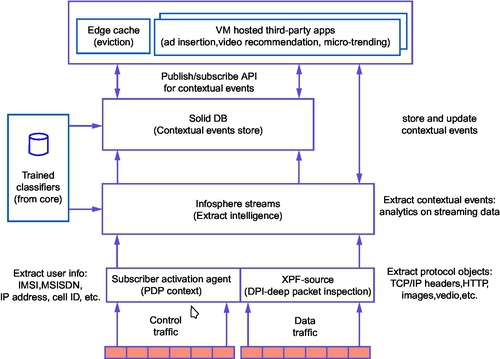
16.6 Data Generation
A layered approach is adopted, wherein the lower layers in the stack are responsible for simple analytics providing a compact synopsis for sophisticated operations at higher layers. When a user connects to a basestation, the MIOP subscriber activation agent processes the control traffic and generates PDP context (de)activation records or EDRs. A presence event is generated upon the entry of a user into a basestation region, while a usage event corresponds to the activities of a user, such as video request, URL lookup, etc. All communications are uniquely identified by the IP address and the MSISDN of the user mobile device. The extensible packet filter (XPF) along with DPI intercepts the raw IP packets and constructs a semantically richer protocol object on the y containing TCP/IP header, images, JavaScripts, etc. It also decompressed protocol objects when required. These objects then feed into a stream layer as a sequence of events and are logged for constituting the historical data. This application layer can then be provided to the third-party applications as a complete protocol. Fig. 6 summarizes the process.
16.7 Edge and Core Components
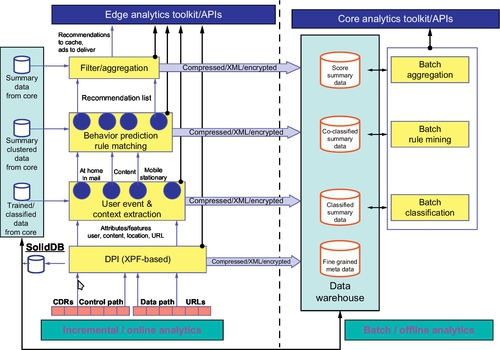
In this section we provide the complete modularization of the VoD framework, working of the core and edge components, and their interactions based on the models as discussed in the previous sections. It can be observed that the prototype is quite simple and requires no major engineering on the part of the service providers, given the currently used infrastructures across the globe. This renders our proposed end-to-end VoD system effective as well as practically viable.
The broad performance components of the edge are:
1. Event generation: the EDRs (presence and usage events) are generated and passed on to the XPF (packet extraction) and stream layer for initial processing. It is then communicated to the core for persistence in the data records to be treated as historical data.
2. Association rule checking: the generated events are checked against the rules obtained from the core, and online learning or rule updating of the current rules are performed. The core is also queried for the rules pertaining to prospective users and their probable request videos.
3. Activity inference: the probability of a video being requested is computed from the support and confidence of the rules obtained from the core. Collaborative filtering is used to make the predictive analysis robust.
4. Rank aggregation: scoring of the entire set of predicted request videos obtained from the rules and the view list of the users is performed based on score and relative priority of users to obtain a ranking for the probability of request activity.
5. Content analysis: based on content delivery of previous sessions for the users, the resume point of the to-be-prefetched video can be inferred. This involves keeping track of the amount of data previously delivered and can be easily done by simple byte counting.
6. Caching optimizations: video caching, eviction and placement based on the result of the ranking of the videos and lookahead scheme is employed. Video delivery optimizations such as smoothing can also be performed on the set of videos identified for prefetch.
The core provides support and assists the entire system with its high computation and storage capability and performs the following:
1. EDR collection: the EDRs collected by the edge are shipped to the core during off-peak hours, where it is collected and stored.
2. Rule mining: Apriori and FP-tree techniques are applied to extract specific rules associated with user video watching patterns from the EDRs collected over a long period of time. Rules having support above a threshold are filtered out as relevant and are indexed by user identity, location and time.
3. Query reporting: the rules mined from the historical data are reported back to the basestations when queried.
The complete architectural design, the components, and the data flow among them to provide a highly efficient end-to-end system for true VoD applications enhancing the end-user experience.
16.8 INCA Caching Algorithm
Based on the VoD framework described previously, we now introduce the working principles of the INCA. An EDR is generated when a user enters a basestation (Presence Event) and/or performs an activity (Usage Event). A Presence Event, when a user enters a basestation, consists of three fields < UserID, LocID, TimeStamp>, with the time slots within a day discretized. For example, the event < ABC123, B0, MORN> denotes a user with ID ABC123 connected to basestation B0 at the time-slot Morning.
A Usage Event, such as a video request, involves the addition of another tuple, EventActivity. Each tuple may have further sub-tuples, eg, Activity may be subdivided into sub-tuples TypeOfActivity, Genre, etc. to classify different kinds of activities such as video, audio, or just web page browsing and Genre to accurately capture the genre of the specific activity.
In reality, EDRs have several other fields in addition to the ones mentioned herein. For extracting meaningful information out of these EDRs, it is essential to remove the unnecessary fields and store the resulting transactions at the edge. The processed set of transactions (after duplicate and unnecessary field removal) are periodically sent to the core from the BS. The FP-growth algorithm [21] is employed for association rule mining, and rules having support above a threshold are filtered out as relevant and are indexed by user identity, location and time. A day is divided into several time slots, such as early morning, late-afternoon, early evening, etc., of appropriate duration (roughly three hours has been used for experimental analysis in this chapter). During event generation, the TimeStamp in each EDR can be mapped to one of these time slots.
The idea here is to prefetch, in the current timeslot, the videos that have a high possibility of being requested in the next time slot. At the start of a particular timeslot at a given basestation, the rules database is queried for a list of users and videos/movies (genres) that exist in the next timeslot for that particular basestation. It is important to mention here that each user has a small preference list of movies, which is assumed to be created by the user explicitly.
For prefetching using lookahead, k = 1, INCA first predicts (in the current timeslot), the videos that have a high possibility of being requested per user in the next time slot. The prediction is based on rules (extracted at the core) stored at the edge, and the FP-growth algorithm [21] for the association rule mining procedure. Collaborative filtering techniques are also used to incorporate possible video requests from other users with similar behavior. Interestingly, the current location of direction of travel of connected and nearby users are used to predict the users that would connect to a basestation in the next time slot. For higher values of lookahead, k > 1, time slots beyond the next one are also considered and video requests are predicted per user. Rules not pertaining to the time slots or to users not within the basestation are filtered out.
The predicted videos (for the next time slot) are ranked using rank aggregation algorithms such as [22] under the constraint of total number (or percent) of available cache slots that can be evicted for prefetching. The relative priority of the users (eg, premium or normal) as well as priority of videos (decreasing with the increase in future time slots) are considered during rank aggregation. A small bandwidth, from the current time slot, is then dedicated for prefetching the selected videos. We later show that only a small percentage of the current bandwidth is required for high performance (in terms of cache hits), thereby making the framework extremely scalable.
When a user requests a video it is first looked up in the basestation cache. In the case of cache miss, the video is fetched from the core, and the analytics-driven cache replacement policy is followed. In this replacement policy, with each entry of the cache, we maintain three metrics:
• p-score that refers to a usage metric from history, such as least recently used (LRU) or least frequently used (LFU);
• f-score that refers to its usage frequency predicted in the future for k time slots; and
• pop-score that refers to global popularity of the movie.
During replacement, the set of movies which are on the skyline (with the lowest scores criteria) across the three metrics are selected, and randomly, one of these cache lines is replaced. For skyline computation, we use the online algorithm for d-dimensional skyline computation, as given by Kossmann et al. [23].
It is interesting to note that individual components of the proposed architecture can be customized with different state-of-the-art techniques to suit various needs of the application at hand, making the framework extremely robust. The complete end-to-end architecture is presented in Fig. 7.
16.9 QoE Estimation
To evaluate the effectiveness of INCA, QoE (the delay experienced by a user after the request has been placed) is computed and used as the primary measure for comparison.
For INCA we have:
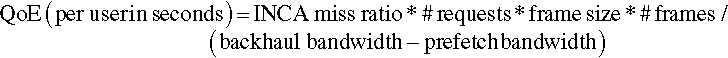
The prefetch bandwidth (Bp) can be expressed as:
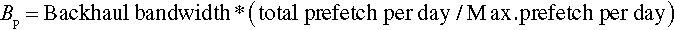
where 
Similarly, for first-in-first-out (FIFO), LRU and LFU schemes with no prefetch, the QoE is:

We later exhibit performance of the system with varying parameters such as bandwidth availability, number of simultaneous users, etc. The model is also compatible with partial object caching, involving frame storage, to handle high-definition videos at limited backhaul bandwidth. The number of frames to be fetched depends on the frame rate of the video, the bandwidth, and the cache size.
Therefore, the reduction in delay due to INCA over other approaches is given by the:
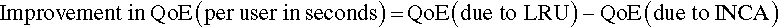
16.10 Theoretical Framework
At time slot t, let v(u, t) be the video requested by user u and x(v(u, t)) (x(v) in short) be an indicator variable which is 1 if v(u, t) is present in the cache, C(z), otherwise 0. The state of the MDP is defined by v(u, t) and C(z). Let, n(u, t) be the number of times a user u requests videos in time slot t. The wait time for user u is denoted as w(u, t) and equals (1 − x(v)) * |v|/Bav, where |v| denotes the size of the part of the video prefetched, and Bav is available bandwidth.
Let d(v, t) denote the prefetch data transfer in time slot t, and it equals (1 − y(v)) * |v|, where y(v, t) is 1 if the video v was prefetched, else 0. The actions in the MDP consist of prefetch actions denoted by y(v, t) as well as fetch actions taken when a particular video requested by a user is not in the cache. The prefetch actions are controlled by the system to improve hit rate, while the fetch actions are forced onto the system due to user video request. Further, let G(u, t) denote the utility gained by user u in time slot t: it is a function of the wait time incurred by the user, w(u, t), in that slot.
For a prefetch action, the reward associated is 0, while when a user u requests a video, the reward gained is G(u, t). G(u, t), which could be positive or negative, depending on if the requested video is in the cache or not and how much wait time w(u, t) is experienced by that user. The QoE optimization problem can be formulated as a maximization of the sum of the difference in the utility across the users, and the cost of prefetch data transfer across all prefetches, ie,
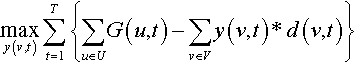
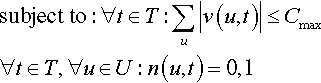
Our online algorithm, INCA, leverages the short-term predictions from the joint edge and core analytics and performs actions y(v, t) using k-step lookahead. For such delayed MDP, under the assumption of no uncertainty in rewards for L + 1 steps in future, Garg et al. [18] provides an online algorithm that chooses the future path with best discounted future reward, and proves bounds on average regret as 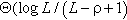 and a competitive ratio as
and a competitive ratio as 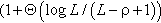 .
.
Hence, such a bound also applies to our proposed algorithm. However, in practice, these short-term predictions are not accurate. In the next section, we study the behavior of INCA experimentally with varying numbers of lookahead steps, k.
To evaluate the effectiveness of INCA, QoE, the delay experienced by a user after the request has been placed, is computed and compared with other caching policies. For INCA, QoE (per user) in seconds is given by:
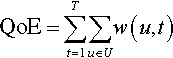
Here, Bav = Bmax − Bp, and prefetch bandwidth (Bp) is given by:

And Max prefetch per day = Max. prefetch per time slot * #time slots per day * Max. #simultaneous users.
Our model considers partial object caching, involving frame storage, to handle high- definition videos at a limited backhaul bandwidth. The number of frames to be fetched depends on the frame rate of the video, the bandwidth and the cache size.
16.11 Experiments and Results
This section presents the experimental results of the studied VoD framework with the INCA algorithm, based on real data from the web video data set. This data set had a total of 10,000 videos corresponding to the search results for the top 25 queries at three popular video content providers. We use realistic data from the web video data set 4. For mobility pattern of users, we model our setup to represent real-life query logs of a large Fortune 500 Telecom organization obtained from http://vireo.cs.cityu.edu.hk/webvideo.
We compare the performance of the INCA algorithm based on cache hits under varying parameters. The QoE of users (as defined earlier) present at a basestation provides the performance benchmark of our proposed VoD system. Additionally, we define the satisfied users metric to model “premium membership” users to whom enhanced multimedia services need to be guaranteed.
Some applications would routinely flush the cache contents at the end of each day, while others might flush it dynamically by monitoring the activity (frequency of requests to the cache) in an effort to improve the hit rate. However, frequent flushing of the cache in the context of the INCA approach would lead to consumption of the costly network bandwidth, which is required for prefetching the cache with videos relevant to the current time slot. In some situations, if the cache is relatively large compared to the volume of requests it receives, it takes a while for the cache to warm up, and therefore frequent flushing is prohibitive in this case. In the current setting, we count the number of cache hits (or misses) at the end of each day.
In the experiments, we empirically set the pre-fetch amount to 30% and assume a limited bandwidth of 10 Mbps, to model a realistic cellular network setting. Our setup measures the cache hit (or miss) ratio per day. Each unit/entry of cache is assumed to accommodate part of a single video.
16.11.1 Cache Hits With NU, NC, NM and k
To demonstrate the effectiveness of the approaches, we measure the cache hit rates of INCA, and compare the results with those obtained by FIFO, LRU, LFU and greedy dual size (GDS)-frequency [24] by varying:
(ii) the number of users connected to a basestation (NU),
(iii) the number of videos present (NM), and
(iv) the amount of lookahead (k).
Variation of cache hits with NC
We study the gain of the cache hit ratio of INCA over other policies with variation in the cache size (NC). NU and NM are set to 200 and 10 K respectively. Each unit of cache is considered to store 250 video fragments. Fig. 8A shows the cache hit gain of INCA (with lookahead, k = 2) over FIFO, LRU, LFU and GDS. At a 1500 cache size (6 units), the hit gain ranges from 26% (over FIFO) to 13% (over GDS). The gain increases with an increase in cache size and stabilizes at around 1000 cache entries. As cache size increases, more relevant entries are prefetched into the cache by INCA, giving it a higher gain over other policies.
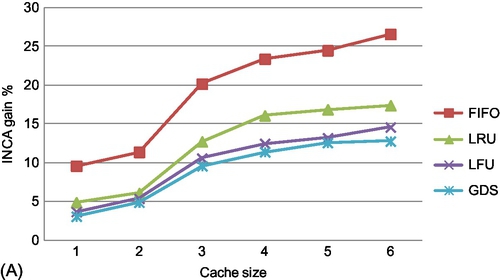
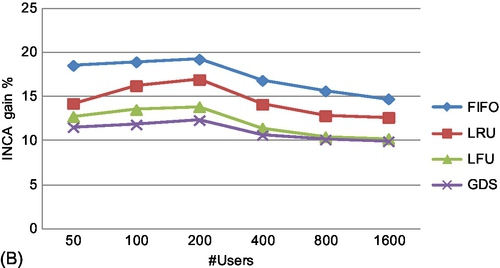
Variation of cache hits with NU
The behavior of the cache hit gain percentage of INCA (with k = 2) over FIFO, LRU, LFU and GDS with variation in the number of users (NU) is presented in Fig. 8B. The cache size is fixed at 1000 entries. At 1600 users, the hit gain varies from 9.9% (over GDS) to 14% (over FIFO). The decrease in the gain with an increase in the number of users is expected due to the fixed cache size across increasing users (increased video requests). But this decrease is not large, owing to the adaptability of INCA for increasing users by analyzing their access and movement patterns and incorporating these insights in prefetch and replacement decisions.
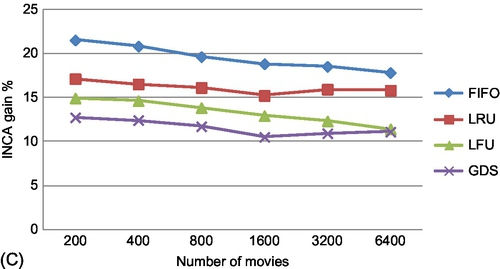
Variation of cache hits with NM
The variation in cache hit gains of INCA (with k = 2) over other cache polices with an increase in the number of videos present (NM) is depicted in Fig. 8C with 200 users. At 6400 movies, the hit gain of INCA ranges from 11% (over GDS) to 16% (over FIFO). We also observe a slight reduction in gains with an increase in the number of videos. Again, this decrease is not large, owing to the discriminative ability of our algorithm to make good online decisions for both prefetch and replacement, even with larger numbers of videos.
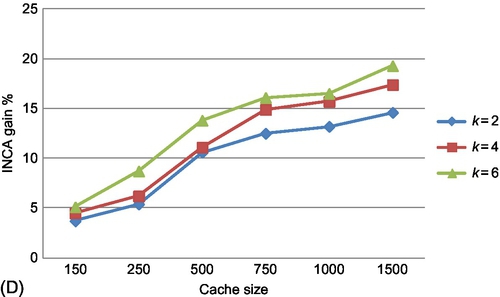
Variation of cache hits with k
The impact of lookahead, k, on the performance of INCA versus GDS (best performing amongst other cache policies) is illustrated in Fig. 8D. As the lookahead is increased to 6, the overall hit gain improvement in INCA is around 15% at a cache size of 1000, and increases to about 20% for higher cache sizes. This criticality of lookahead for the cache performance of INCA corroborates with theoretical bounds (with a perfect L-lookahead assumption) on the competitive ratio and regret mentioned previously.
INCA versus online algorithm
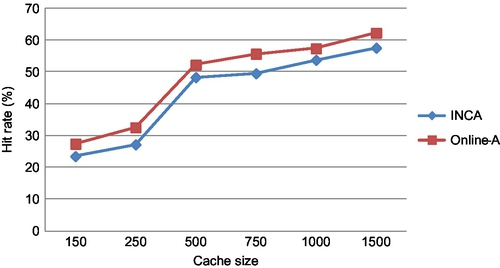
Fig. 9 presents the comparison between INCA and the online algorithm [18] which has proven regret bounds. INCA closely follows the online algorithm [18] even though it is, on average, 11% lesser. This is due to the fact that INCA has reasonable accuracy in short-term predictions (using the k-lookahead strategy) while [18] assumes perfect accuracy of short-term predictions.
16.11.2 QoE Impact With Prefetch Bandwidth
We next study the QoE of the users (as defined earlier) by varying the current bandwidth available for prefetching videos (for next time slots).
The variation in aggregate QoE improvement across users with respect to GDS (best performing amongst other caching policies) with varying prefetch bandwidth requirement is presented in Fig. 10. Here, we set lookahead, k = 2 for INCA, and curves with varying cache sizes have been plotted. We assume 100 users (NU), the average number of requests per time slot to be 310 and NM = 10 K. We also consider 300 movies to present in the preference list of each user.
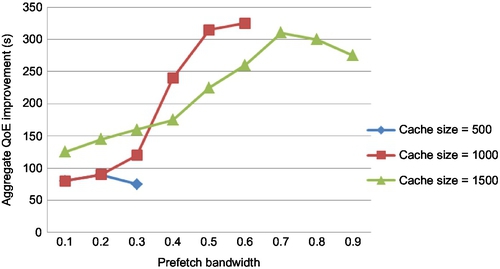
Fig. 10 demonstrates improvement in QoE in INCA with an increase in the prefetch bandwidth. With only 0.7 Mbps prefetch bandwidth and a cache size of 1000, the improvement in QoE is around 300 s, which is a 15% gain over the start-up latency in GDS. As compared to other cache policies, INCA has an even higher aggregate QoE gain of around 20%. Further, an increase in cache size beyond 1000 does not significantly improve the QoE gain. In fact, with higher cache size and prefetch bandwidth, the QoE slightly decreases due to high latency incurred for activity requests within the current time slot leading to an overall QoE degradation.
16.11.3 User Satisfaction With Prefetch Bandwidth
Service providers often offer “premium services” at additional cost. Such premium users need to be supplied with enhanced performance and extremely low latency. To this extent, this is defined as the satisfied users metric. A user is said to be satisfied if all his requests are cache hits at basestations, thereby exhibiting practically 0 fetch latency. Such guarantees on high viewing experiences would enable higher revenue generation for the providers. The number of satisfied users can be approximated by:
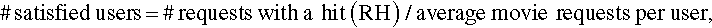
where RH = (gain% of INCA * #requests)/100.
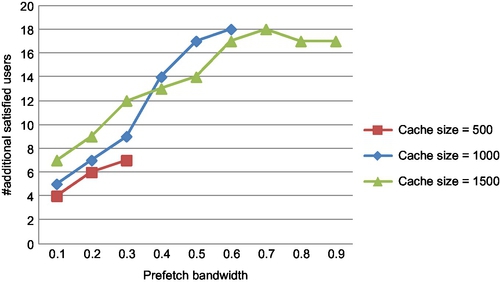
For performance analysis based on QoE, we use similar parameter settings. Fig. 11 demonstrates around 18 additional satisfied users for INCA (k = 2) over GDS per time slot, by using a small prefetch bandwidth of 0.7 Mbps. This corresponds to a 12% improvement over GDS, while improvement over other caching policies is up to 18%. These experiments demonstrate that the prefetch requirement of INCA is less than 10% of the available bandwidth, to deliver strong improvements in QoE and number of satisfied users. Interestingly, the prefetch requirement of INCA is a meager 7% of the available bandwidth.
16.12 Synthetic Dataset
We explore the scalability performance of our proposed VoD framework with randomly generated synthetic video request data. We capture the robustness of INCA with respect to the LRU caching technique by varying the randomness. A user is considered to request videos outside her preference list with a certain probability. Keeping in view the unorganized and haphazard nature of user behavior, we try to model the user requests by introducing a certain percentage of randomness while generating user requests at a basestation. We consider a data randomness DR of 50% and 70%, wherein a user requests a video outside the preference list with probability DR. As before, we measure the improvement in cache hits, QoE, and number of satisfied users for varying cache sizes. We set NU = 100 and NM = 20,000, with the average number of requests per time slot and user preference list size set to 310 and 300 respectively.
16.12.1 INCA Hit Gain
We vary the cache size (Fig. 12A), number of users (Fig. 12B), and the number of videos (Fig. 12C) while studying the improvement in cache hits (at the basestation) for INCA over the LRU protocol. This models the behavior of a new user (for whom historical data is unavailable) or unusual request of an existing user. We observe that INCA significantly outperforms LRU, obtaining nearly 15% and 10% improvements for DR = 50% and 70% respectively. With an increase in cache size, the performance of INCA improves and stabilizes for a cache size of 750. As the number of users increases, the performance is seen to decrease due to a high number of video requests. Interestingly, the performance of INCA is observed to be nearly independent of the number of movies present. With higher randomness of video requests from the users (outside the preference list), the number of cache hits decreases, as expected, leading to a slight reduction in the performance of INCA.
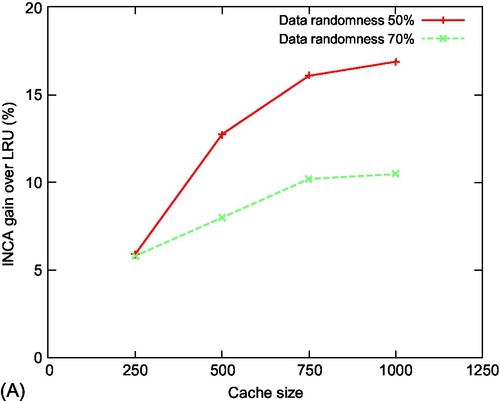
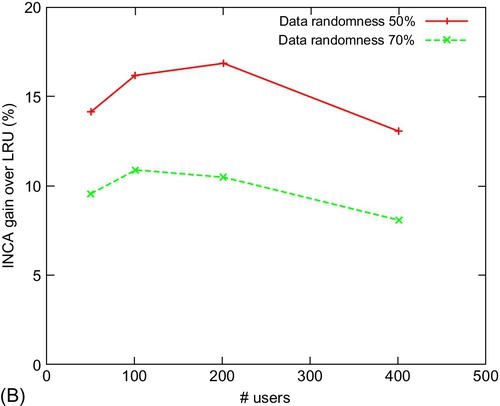
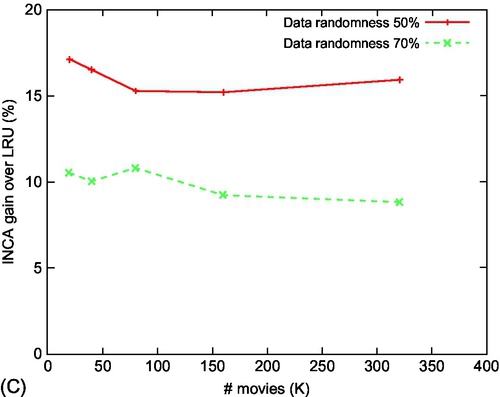
16.12.2 QoE Performance
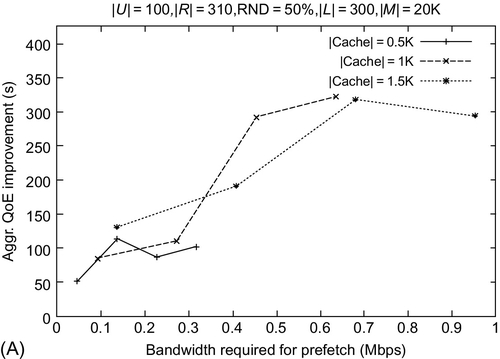
INCA exhibits enhanced QoE of users (over LRU) for varying cache sizes and a prefetch bandwidth with different DR values. Fig. 13A and B exhibit that with an increase in cache size, the QoE improves. INCA obtains around 300 and 150 s enhanced QoE as compared to LRU with a cache size of 1000 for DR = 50% and 70% respectively. With an initial increase in the prefetch bandwidth available, INCA significantly outperforms LRU in QoE. However, as before, the QoE slightly decreases with a further increase in prefetch bandwidth, due to increased latency for current time slot operations. Similar trends are observed for the different DR values.
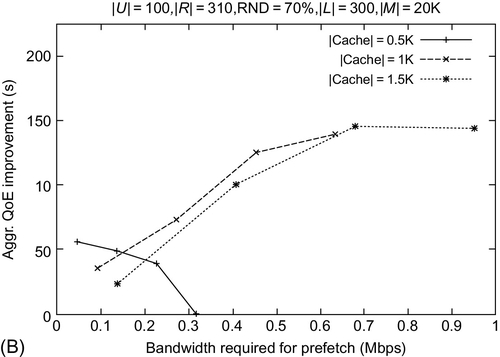
16.12.3 Satisfied Users
Fig. 14A and B depict that with an increase in the available prefetch bandwidth, the number of satisfied users in INCA is higher than that for LRU. We observe more than 14 additional satisfied users for INCA (with varying DR), which stabilizes at around 0.7 Mbps bandwidth. Additionally, the number of satisfied users in INCA increases with an increase in cache size, and is seen to stabilize at NC = 1000.
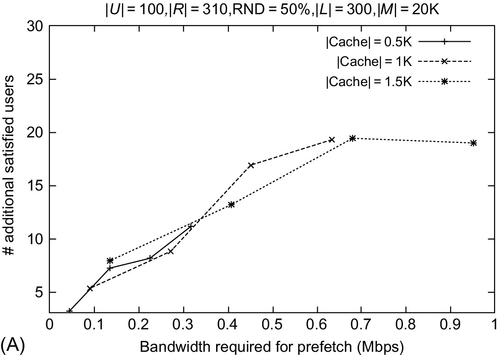
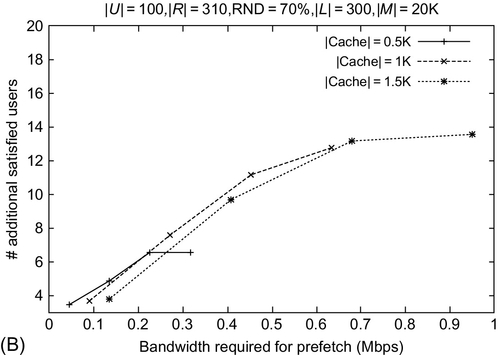
16.13 Conclusions and Future Directions
We discussed a novel framework for efficient VoD services for multimedia applications. Leveraging predictive rule extraction coupled with collaborative filtering for its k-lookahead scheme, INCA performs prefetching and replacement and obtains higher performance. We also provided the theoretical formulation for QoE that is at the intersection of MPC and MDP. Using empirical results, we demonstrate superior performance of our framework with enhanced cache hits, QoE, and the number of satisfied users as compared to well-known approaches. It provides a robust VoD architecture encompassing and optimizing multiple infrastructural factors such as bandwidth, cache size, etc., as well as demonstrating scalability for modern large-scale applications. Intelligent caching based on user behavior prediction enables the prefetch of probable videos using only a small amount of the current available bandwidth, leads to enhanced quality of experience for the users. Empirical results as shown herein showcase the improved performance of our framework under various real-time scenarios.
Future research direction involves computation of bounds for regret and competitive ratio considering imprecise rewards in the lookahead scheme. Further extension for 4G connectivity provides the scope for further improvements. Performance comparison with other frequent/association rule mining algorithms might provide valuable insights into the working of the algorithm.