 Figure 46: The core, chronic conflict facing every IT organization
Figure 46: The core, chronic conflict facing every IT organizationWe believe that DevOps is benefiting from an incredible convergence of management movements, which are all mutually reinforcing and can help create a powerful coalition to transform how organizations develop and deliver IT products and services.
John Willis named this “the Convergence of DevOps.” The various elements of this convergence are described below in approximate chronological order. (Note that these descriptions are not intended to be an exhaustive description, but merely enough to show the progression of thinking and the rather improbable connections that led to DevOps.)
The Lean Movement started in the 1980s as an attempt to codify the Toyota Production System with the popularization of techniques such as Value Stream Mapping, kanban boards, and Total Productive Maintenance.
Two major tenets of Lean were the deeply held belief that lead time (i.e., the time required to convert raw materials into finished goods) was the best predictor of quality, customer satisfaction, and employee happiness; and that one of the best predictors of short lead times was small batch sizes, with the theoretical ideal being “single piece flow” (i.e., “1x1” flow: inventory of 1, batch size of 1).
Lean principles focus on creating value for the customer—thinking systematically, creating constancy of purpose, embracing scientific thinking, creating flow and pull (versus push), assuring quality at the source, leading with humility, and respecting every individual.
Started in 2001, the Agile Manifesto was created by seventeen of the leading thinkers in software development, with the goal of turning lightweight methods such as DP and DSDM into a wider movement that could take on heavyweight software development processes such as waterfall development and methodologies such as the Rational Unified Process.
A key principle was to “deliver working software frequently, from a couple of weeks to a couple of months, with a preference to the shorter timescale.” Two other principles focus on the need for small, self-motivated teams, working in a high-trust management model and an emphasis on small batch sizes. Agile is also associated with a set of tools and practices such as Scrum, Standups, and so on.
Started in 2007, the Velocity Conference was created by Steve Souders, John Allspaw, and Jesse Robbins to provide a home for the IT Operations and Web Performance tribe. At the Velocity 2009 conference, John Allspaw and Paul Hammond gave the seminal “10 Deploys per Day: Dev and Ops Cooperation at Flickr.”
At the 2008 Agile Toronto conference, Patrick Dubois and Andrew Schafer held a “birds of a feather” session on applying Agile principles to infrastructure as opposed to application code. They rapidly gained a following of like-minded thinkers, including John Willis. Later, Dubois was so excited by Allspaw and Hammond’s “10 Deploys per Day: Dev and Ops Cooperation at Flickr” presentation that he created the first DevOpsDays in Ghent, Belgium, in 2009, coining the word “DevOps.”
Building upon the Development discipline of continuous build, test, and integration, Jez Humble and David Farley extended the concept of continuous delivery, which included a “deployment pipeline” to ensure that code and infrastructure are always in a deployable state and that all code checked in to truck is deployed into production.
This idea was first presented at Agile 2006 and was also independently developed by Tim Fitz in a blog post titled “Continuous Deployment.”
In 2009, Mike Rother wrote Toyota Kata: Managing People for Improvement, Adaptiveness and Superior Results, which described learnings over his twenty-year journey to understand and codify the causal mechanisms of the Toyota Production System. Toyota Kata describes the “unseen managerial routines and thinking that lie behind Toyota’s success with continuous improvement and adaptation… and how other companies develop similar routines and thinking in their organizations.”
His conclusion was that the Lean community missed the most important practice of all, which he described as the Improvement Kata. He explains that every organization has work routines, and the critical factor in Toyota was making improvement work habitual, and building it into the daily work of everyone in the organization. The Toyota Kata institutes an iterative, incremental, scientific approach to problem solving in the pursuit of a shared organizational true north.
In 2011, Eric Ries wrote The Lean Startup: How Today’s Entrepreneurs Use Continuous Innovation to Create Radically Successful Businesses, codifying his lessons learned at IMVU, a Silicon Valley startup, which built upon the work of Steve Blank in The Four Steps to the Epiphany as well as continuous deployment techniques. Eric Ries also codified related practices and terms including Minimum Viable Product, the build-measure-learn cycle, and many continuous deployment technical patterns.
In 2013, Jeff Gothelf wrote Lean UX: Applying Lean Principles to Improve User Experience, which codified how to improve the “fuzzy front end” and explained how product owners can frame business hypotheses, experiment, and gain confidence in those business hypotheses before investing time and resources in the resulting features. By adding Lean UX, we now have the tools to fully optimize the flow between business hypotheses, feature development, testing, deployment, and service delivery to the customer.
In 2011, Joshua Corman, David Rice, and Jeff Williams examined the apparent futility of securing applications and environments late in the life cycle. In response, they created a philosophy called “Rugged Computing,” which attempts to frame the non-functional requirements of stability, scalability, availability, survivability, sustainability, security, supportability, manageability, and defensibility.
Because of the potential for high release rates, DevOps can put incredible pressure on QA and Infosec, because when deploy rates go from monthly or quarterly to hundreds or thousands daily, no longer are two week turnaround times from Infosec or QA tenable. The Rugged Computing movement posited that the current approach to fighting the vulnerable industrial complex being employed by most information security programs is hopeless.
The Theory of Constraints body of knowledge extensively discusses the use of creating core conflict clouds (often referred to as “C3”). Here is the conflict cloud for IT:
Figure 46: The core, chronic conflict facing every IT organization
During the 1980s, there was a very well-known core, chronic conflict in manufacturing. Every plant manager had two valid business goals: protect sales and reduce costs. The problem was that in order to protect sales, sales management was incentivized to increase inventory to ensure that it was always possible to fulfill customer demand.
On the other hand, in order to reduce cost, production management was incentivized to decrease inventory to ensure that money was not tied up in work in progress that wasn’t immediately shippable to the customer in the form of fulfilled sales.
They were able to break the conflict by adopting Lean principles, such as reducing batch sizes, reducing work in process, and shortening and amplifying feedback loops. This resulted in dramatic increases in plant productivity, product quality, and customer satisfaction.
The principles behind DevOps work patterns are the same as those that transformed manufacturing, allowing us to optimize the IT value stream, converting business needs into capabilities and services that provide value for our customers.
The columnar form of the downward spiral depicted in The Phoenix Project is shown below:
Table 4: The Downward Spiral
The problem with high amounts of queue time is exacerbated when there are many handoffs, because that is where queues are created. Figure 47 shows wait time as a function of how busy a resource at a work center is. The asymptotic curve shows why a “simple thirty-minute change” often takes weeks to complete—specific engineers and work centers often become problematic bottlenecks when they operate at high utilization. As a work center approaches 100% utilization, any work required from it will languish in queues and won’t be worked on without someone expediting/escalating.
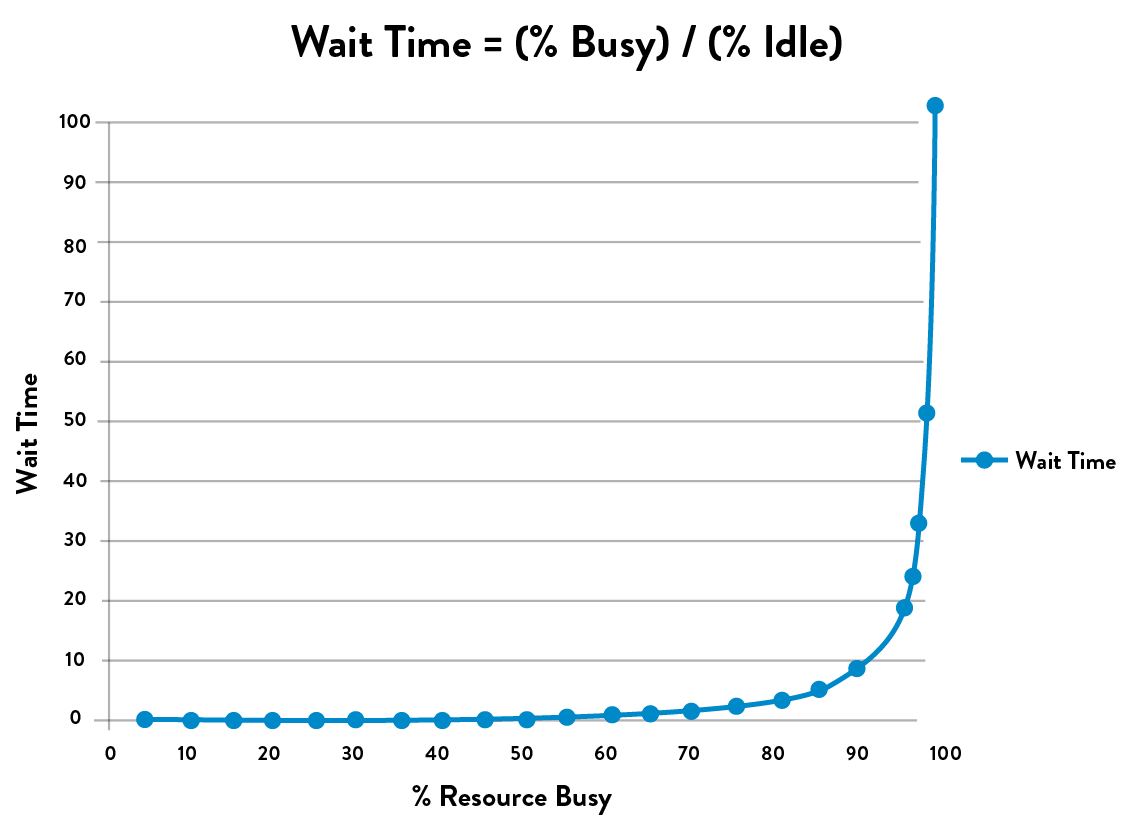 Figure 47: Queue size and wait times as function of percent utilization (Source: Kim, Behr, and Spafford, The Phoenix Project, ePub edition, 557.)
Figure 47: Queue size and wait times as function of percent utilization (Source: Kim, Behr, and Spafford, The Phoenix Project, ePub edition, 557.)
In figure 47, the x-axis is the percent busy for a given resource at a work center, and the y-axis is the approximate wait time (or, more precisely stated, the queue length). What the shape of the line shows is that as resource utilization goes past 80%, wait time goes through the roof.
In The Phoenix Project, here’s how Bill and his team realized the devastating consequences of this property on lead times for the commitments they were making to the project management office:
I tell them about what Erik told me at MRP-8, about how wait times depend upon resource utilization. “The wait time is the ‘percentage of time busy’ divided by the ‘percentage of time idle.’ In other words, if a resource is fifty percent busy, then it’s fifty percent idle. The wait time is fifty percent divided by fifty percent, so one unit of time. Let’s call it one hour.
So, on average, our task would wait in the queue for one hour before it gets worked.
“On the other hand, if a resource is ninety percent busy, the wait time is ‘ninety percent divided by ten percent,’ or nine hours. In other words, our task would wait in queue nine times longer than if the resource were fifty percent idle.”
I conclude, “So…For the Phoenix task, assuming we have seven handoffs, and that each of those resources is busy ninety percent of the time, the tasks would spend in queue a total of nine hours times the seven steps…”
“What? Sixty-three hours, just in queue time?” Wes says, incredulously. “That’s impossible!”
Patty says with a smirk, “Oh, of course. Because it’s only thirty seconds of typing, right?”
Bill and team realize that their “simple thirty-minute task” actually requires seven handoffs (e.g., server team, networking team, database team, virtualization team, and, of course, Brent, the “rockstar” engineer).
Assuming that all work centers were 90% busy, the figure shows us that the average wait time at each work center is nine hours—and because the work had to go through seven work centers, the total wait time is seven times that: sixty-three hours.
In other words, the total % of value added time (sometimes known as process time) was only 0.16% of the total lead time (thirty minutes divided by sixty-three hours). That means that for 99.8% of our total lead time, the work was simply sitting in queue, waiting to be worked on.
Decades of research into complex systems shows that countermeasures are based on several myths. In “Some Myths about Industrial Safety,” by Denis Besnard and Erik Hollnagel, they are summarized as such:
The differences between what is myth and what is true are shown below:
Table 5: Two Stories

Many ask how can any work be completed if the Andon cord is being pulled over five thousand times per day? To be precise, not every Andon cord pull results in stopping the entire assembly line. Rather, when the Andon cord is pulled, the team leader overseeing the specified work center has fifty seconds to resolve the problem. If the problem has not been resolved by the time the fifty seconds is up, the partially assembled vehicle will cross a physically drawn line on the floor, and the assembly line will be stopped.
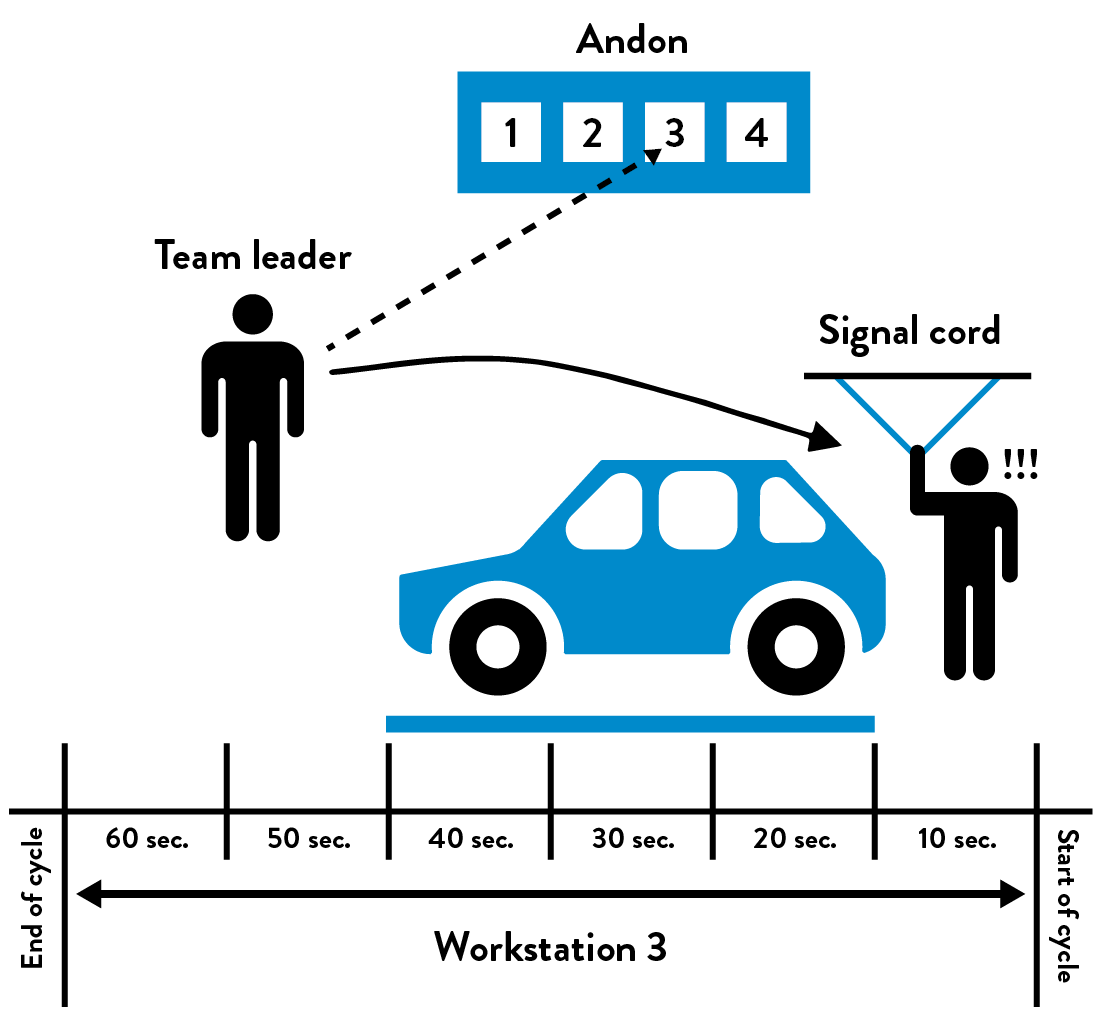 Figure 48: The Toyota Andon cord
Figure 48: The Toyota Andon cord
Currently, in order to get complex COTS (commercial off-the-shelf) software (e.g., SAP, IBM WebSphere, Oracle WebLogic) into version control, we may have to eliminate the use of graphical point-and-click vendor installer tools. To do that, we need to discover what the vendor installer is doing, and we may need to do an install on a clean server image, diff the file system, and put those added files into version control. Files that don’t vary by environment are put into one place (“base install”), while environment-specific files are put into their own directory (“test” or “production”). By doing this, software install operations become merely a version control operation, enabling better visibility, repeatability, and speed.
We may also have to transform any application configuration settings so that they are in version control. For instance, we may transform application configurations that are stored in a database into XML files and vice versa.
A sample agenda of the post-mortem meeting is shown below:
Bethany Macri from Etsy observed, “Blamelessness in a post-mortem does not mean that no one takes responsibility. It means that we want to find out what the circumstances were that allowed the person making the change or who introduced the problem to do this. What was the larger environment….The idea is that by removing blame, you remove fear, and by removing fear, you get honesty.”
After the 2011 AWS EAST Outage, Netflix had numerous discussions about engineering their systems to automatically deal with failure. These discussions have evolved into a service called “Chaos Monkey.”
Since then, Chaos Monkey has evolved into a whole family of tools, known internally as the “Netflix Simian Army,” to simulate increasingly catastrophic levels of failures:
Other member of the Simian Army now include:
Lenny Rachitsky wrote about the benefits of what he called “transparent uptime”: