Upon completion of this chapter, you should understand the following:
The relational model structural concepts of:
Tables defining a data relation,
Rows providing data records,
Columns defining the fields of a record, with specific data type,
Primary Key to uniquely identify records, and
Relationships between tables, from one-to-one, one-to-many, and many-to-many.
The background motivation for relational databases, basic types of databases, and some of the advantageous characteristics.
How the notion of clients and providers fits into a database system architecture.
The single most important form of a data system, grounded in nearly 50 years of development of both underlying theory of structure and efficient implementations, is the Relational Database system. In Sect. 5.3, we presented an overview of the relational model, describing it as composed of an inter-dependent set of tables, and distinguishing it from the tabular model by its database design prior to data population, and its mathematical foundation. We also gave a high-level definition of a database management system (DBMS). The relational model is extremely powerful, facilitates very efficient access to the data it stores, and is protected (via constraints) from a wide variety of errors. The trade-off is that careful thought is required prior to designing the rigid relational structure that the data must conform to. The current chapter describes and explores the relational model further.
We start by giving additional background on the requirements that a database system must meet and how relational databases, in particular, meet those requirements. We highlight the types of relational databases that are of particular interest in a broad treatment of data systems, the subject of this book. The chapter then presents more information on the structural details, and places the client and database system provider in the context of an architecture.
In subsequent chapters, we focus on operations to query data from a relational database. We introduce SQL query operations and progress through queries on a single table in Chap. 11 and then SQL queries involving multiple tables in Chap. 12. Because SQL is a declarative language, specifying what data is desired, and is agnostic to the programming language or system of the client, these chapters focus on just the SQL, and defer the programming aspects of using a particular package and API to Chap. 13.
Within the relational data model, many of the constraints are related to the design of a database. We thus group a discussion of constraints with advice regarding database design in Chap. 14. There, we also cover the SQL for realizing the design of a database through SQL CREATE, and populating the database through SQL INSERT.1
The treatment of relational databases, as well as the SQL for operating on the database, in this book is, necessarily, a small fraction of the subject. We are interested in understanding the relational data model as one of our data forms and the provider system as a source of data. Our perspective is that of a client interacting with this particular data system, as needed for acquiring data and preparing it for analysis. As such, we omit topics like updating database records, deep understanding of consistency issues, and transactional support. We omit the underlying mathematical set theory but note that it facilitates the relational algebra that makes relational databases so powerful and efficient. We also omit the discussion of the provider-side system design for the efficient storage and retrieval of data.
10.1 Background
The term database is used in many contexts, both in the real world, and as used in this book. We begin with a comparison of definitions. The definition from Wikipedia states [86]:
A database is an organized collection of data, generally stored and accessed electronically from a computer system.
The Wikipedia description of a database also states: “Where databases are more complex they are often developed using formal design and modeling techniques.” This definition is perhaps too general. It might, with appropriate argument, be applied to the entire spectrum of data systems presented in this book. The Merriam-Webster definition [33] enhances this definition by adding that the collection is usually large, and that the organization allows for “rapid search and retrieval”. Within these definitions, we can focus on the organized structure, and allow that this might include a structure that is well-defined, and the idea of constraints that can be enforced so that the organized structure can be maintained. We can also focus on the rapid search and retrieval, and allow that this might include a standard language that allows specification for what data should be retrieved.
With this additional focus, we arrive at the notion of a relational database, that is, those databases based on the relational model of data. In practice, this means the database comes equipped with a schema relating the different tables within it, that the database is organized for rapid search and retrieval, that the database contains information about its own constraints, and that these constraints are enforced. The notion of a relational database proposed by [4], with its formal methods for determining tables and relationships, is a prime example. We will not have need for the overly general definition of database given above, and will instead often use the term database as a substitute for “relational database,” often implemented on a dedicated system of the provider, called a relational database management system, or sometimes just a database management system. The use of the relational model achieves the goal of organized structure, and the use of SQL achieves the goal of rapid search and retrieval.
10.1.1 Motivation and Requirements
The primary motivation for any database system is to provide a repository of persistent data that centralizes the data and allows for the organization, search, and retrieval components of the above definitions. Often, a database system is hosted by a data system provider, and provides access to data system clients with appropriate permissions. However, it is also possible for the database to be hosted locally on the computer of the data system client, if the client desires the data in a more structured form, and with more efficient query access, relative to the tabular data model.
In our motivation, we employ the adjective of centralized (at least logically) and the notion of a persistent repository to guide us from a potential concept of a database as one or more files on a local system for just the client or application running on that local system2 to the more general idea of a system where the same data set can be reliably accessed and queried by multiple clients, possibly executing applications on different machines, and to have only one place to go for the data, and for the clients to be able to do their work without any coordination between these clients, even though they may be executing at the same time.
Persistence means that the data repository maintains its information and its integrity across clients coming and going and even across the stopping and starting of provider system software and hardware. Even more beneficial is if the repository can maintain its information and integrity across unexpected failures, like power outages or logical errors in client applications.
A database system should allow us to reduce common sources of errors. Through the tabular model, we have seen three common sources of errors that we would like to prevent:
Allowing data to violate structural constraints (violations of tidy data).
Allowing data in a column to not have an appropriate data type, or be restricted to a set of acceptable values.
Allowing some data to be repeated (i.e., redundant) in a way that allows changes to one copy not be reflected consistently across all copies.
In the tabular model, these errors could occur because constraints are a set of conventions, and no mechanism exists to check or enforce compliance. In the relational model, we can and will enforce such constraints.
Allied with our initial motivation, a requirement may be stated that separates the client or a set of clients from the provider, where the data is actually stored and maintained. This allows a single and consistent database to be available to multiple users and multiple client applications. And once we make the step of, at least potentially, a separation of client from provider and their server system, we open up the possibility of operations that might be permitted for some clients and not permitted for others.
Beyond the requirement of independent clients and their access to a single database, might be the requirement of sharing. In this requirement, when one client makes one or more updates to the database: be they the addition of records, the changing of existing records, or the deletion of records, the other clients will eventually see the update, and algorithms of clients may proceed along different paths, depending on this interaction.
The definition of database includes the idea of rapid search and retrieval. For ease of retrieval, and to complete the separation between the provider and the client, we require relieving the client of knowledge of the physical model entailed in how the data is stored at the provider. We, instead, want the clients to employ a logical and programming language agnostic way of specifying the operations to be performed on the database. In other words, we want to declare what data should be retrieved or updated while abstracting away the details of how, given the physical model and reality, that is actually accomplished.
The final requirement to be discussed involves what, in distributed systems parlance, is called consistency semantics. This requirement is at the confluence of two earlier-cited requirements: we must maintain the integrity of the database, and we also must support multiple clients, executing concurrently. The requirement of consistency semantics arises because two (or more) clients might be accessing the same data in the database at nearly the same time, and the individual operations of the clients might be performed in some interleaved way, causing the database to become logically corrupted.
Using an illustrative example, first suppose that an individual operation, like a read of a record, or to change a value in a record, can be executed by a provider without interference. Then suppose that one client wants to perform the three steps and two database operations of:
Read the value of field A out of record n, obtaining value x.
Compute a new value, say 2 ∗ x.
Update field A of record n with 2 ∗ x.
Another client might, at approximately the same time, be performing the three step sequence of:
Read the value of field A out of record n, obtaining value y.
Compute a new value, say y∕2.
Update field A of record n with y∕2.
Say that, before execution, the A field of record n contains the value 32. If one client executed all three steps, and then the other client executed all three steps, then the result would be that the A field of record n again contains the value 32.
Suppose, instead, that the interleaving of the clients happens such that both take their first step before either takes their third step. That means that x is 32, and also that y is 32. If the first client then completes and then the second client completes, then afterward the A field of record n contains the value 16. If the second client performs their update followed by the first client, then afterward, the A field of record n contains the value 64.
So we have three possible outcomes, with final values of 32, 16, or 64. If these sets of operations involved deposits and withdrawals from a bank account whose data were maintained in a database, the logically correct solution would be the value of 32. That value would be the final result whether the first client executed, followed by the second client, or vice versa. But it would not be correct (or consistent) for any possible interleaving were to be observable, with final results of 16, or 64.
While much more complex examples exist, this relatively simple example should illustrate the requirement for consistency when we must maintain logical integrity in the presence of a shared database with concurrent clients.
10.1.2 The Relational Database Solution
Relational databases are the most common form of database, and, for the provider side, many commercial (OracleTM) and open source (PostgreSQL, MySQL, SQLite) realizations exist. This subsection describes how the relational model and the relational database realizations satisfy the requirements of Sect. 10.1.1.
To support, in part, the requirement of maintaining integrity and to support reduction of common errors, relational databases use a complete design and definition of the database ahead of time, prior to any population of the data or issuing of any operations. This design of the database is called the database schema and the design of any particular table is called a table schema. The schema defines data types and valid values for column fields so that the system can enforce that no invalid data in the column field is even possible. The database design and, ultimately, the schema, often involves formal techniques of modeling.
Database modeling and design also supports the requirement of eliminating redundant information. In the design process, the tables are determined through a process called normalization such that each one models separate information. The net result is a larger number of tables, but designed so that redundancy is eliminated. Through the design and normalization process, the relationships that relate one table to another are also explicitly established.
In the relational database solution, because the design result is a set of related tables, the operations also include powerful basic operations to combine tables. Further, the operations, both simpler single table operations and operations to combine and to query combinations of tables, satisfy properties of the underlying mathematics. The set theory and predicate logic basis allow the mathematics to model tables as sets and to prove that, whenever we operate on a table or a subtable, we get a coherent table as the result. This allows the operations to be composed and chained in powerful ways.
The realization of relational database management systems use a client–server architecture to satisfy the requirements of a persistent and logically centralized repository for the data, separate from the client set. Depending on the system, it can manage a multiplicity of users with possibly differing access to data and permissions for operations. These realizations also, then, support sharing and coordination for access to common data.
Relational database management systems provide a meta-operation, called a transaction that allows clients to define groupings of operations that must be completed as a unit. This allows the system to recognize possible interleavings that might lead to incorrect/inconsistent results, and can use them to ensure the logical consistency of the database. In many aspects of the relational database solution, the core idea is to make sure, through schema and initial population, that the database starts in a consistent (aka sound) state, and each subsequent operation or transaction only transitions a database from one sound state to the next sound state, even in the presence of concurrent clients.
In the relational database solution, we have separated the client from the provider, and placed the onus of the physical realization on the provider. Since clients being implemented in different platforms or using different programming languages, it is essential to give clients a way to declare what data is required, without specifying how. The satisfaction of this requirement in the relational database solution is the language SQL.
In an ever changing and data-centric world, to address needs of greater scale and access from clients with different characteristics, the relational database solution is not the end-all and be-all. In recent years, many types of databases have been designed to address many of the same requirements. These alternatives are advanced topics beyond the scope of this book.
10.1.3 Types of Relational Databases
Relational databases are often categorized based on how they are used. While such a categorization is not “pure,” in that some databases are used in multiple ways, looking at the categorization can help us to understand what parts of the relational database solution pertain to the objectives of this book.
An Operational Database is one used in the operation of an enterprise, be it in for-profit or non-profit business, the education sector, or any other enterprise. That means that the database is dynamic and “online,” being used for maintaining information about contacts, vendors, inventory, sales, budgets, and so forth. The operations on an operational database are a mix of queries and are undergoing constant update, with additions of records, deletions of records, and changes to existing records. These databases are used in the minute-by-minute processes, involving both human and data-centric processes, of the enterprise. This type of database is also called an online transactional processing (OLTP) system.
An Analytical Database, on the other hand, is used to support analysis. Most often, this analysis is by the enterprise for decision support. Other analytical databases might be open and accessible for analysis by outside users, and be used for data science and machine learning on databases maintained for the public good. These analytical databases are often used to track historical and time dependent data. Such databases are relatively static, populated initially with a collection of data and then, possibly added to as additional data becomes available. So the operations are primarily queries and then the addition of new data, but rarely are there deletions of records, nor changes to existing records.
In an analytical database, even one used in a shared client environment, the operations are primarily read-only and the operations of one client are independent of one another. The issue of consistency is avoided because there are, generally, no updates to existing records shared by two clients.
Our objectives in this book are to understand data systems from a client user/application perspective, and to understand the forms and sources of data for the purpose of data acquisition and as a prelude to analysis. Thus, we are primarily interested in understanding and using analytical databases. As such, in this book, we omit coverage of the mechanisms of transactions, and also omit coverage of the parts of SQL that deal with updating existing records and with deleting existing records.
10.1.4 Reading Questions
The reading discusses the difference between a “database” (as defined by Wikipedia) and a “relational database.” Draw an analogy with our discussion of the difference between tabular data (that is, with rows and columns) and tidy data.
Give a real-world example, different from any in the reading, of a situation where it might be important for many different individuals to have access to the same database.
Please think of a time you shared an electronic resource or document with another person. When one of you made a change, would the other person eventually see that? How do you think this was managed by the system?
Give a real-world example, based on your experience, of how a system you have used has handled consistency. What happened if two users tried to update it at the same time? What if users made changes while offline, and syncing was only possible when both came back online?
The reading explains the importance of database transactions. Using the language from the reading, give an example from the field of banking, showing why database transactions are important (e.g., what could go wrong if we did not have such a notion). Hint: you can use the example in the text as inspiration.
Give a real-world example illustrating the difference between a database schema and a table schema.
Give a real-world example where you might want to give some users different rights than others, as regards access and modification privileges for a shared database.
Based on how operational database was defined, what are some special issues that could make working with an operational database harder than working with an analytical database?
10.2 Structure
In the relational database model, the structure is a set of inter-dependent tables, where each table is comprised of rows and columns. An individual table is also, in its mathematical context, called a relation. Note that it is this term, of a table as a relation, that is the origin of the model as a relational database. A common misconception is that the name has to do with the relationships that might exist between tables.
A relational database, then, is the collection of tables that are designed together in a single schema. The database includes information governing the relationships between individual tables, as well as information about the users/clients permitted to access the database, and what types of access are allowed. A single provider system may host many relational databases, each with different schemas and with different user/client permissions.
10.2.1 Single Table Characteristics
We begin by considering the structure-related characteristics of a single table in the relational model. Like in the tabular model, tables are composed of rows and columns. But unlike in the tabular model, a table cannot have non-conformant table representations, like values for columns, nor variables for rows—the limitless variety of messy data we saw in the tabular model.
In the relational model, the columns of a table are also called fields, and the rows are called records.3 Each column/field has a distinct name within the table along with a data type, a data size, and possibly other constraints determined at design time. Field names are used like variables, and are not arbitrary strings, like we saw in the tabular model and in pandas. For instance, no spaces, other whitespace, nor special characters are allowed as part of field names. We often use the term field synonymously with field name. Like in tidy data, the fields in the relational model should capture the notion of exactly one variable.
10.2.1.1 Functional Dependencies





10.2.1.2 Table Keys
A key is one or more fields that can potentially be used to uniquely identify an individual record. In the relational model, given a value for a key, there is only one record that corresponds to the given key. If we have correctly written all possible functional dependencies for the mapping of a table, then the set of independent variable fields on the left-hand side of each functional dependency would enumerate all the potential keys. This set of potential keys is also called the candidate keys of the table.
If a key is composed of more than one field, the key is called a composite key. When there is a composite key, it is the combination of field values that must uniquely identify a record. In our example above, a coursesubject of "ECON" does not necessarily uniquely identify a record; it is the combination of "ECON" for coursesubject and the value 350 for coursenum that should identify a record.
The design of a relational database table must identify, for every table, a primary key. This, clearly, must be one of the candidate keys, and will be used by the system to build auxiliary structures to allow efficient access to a record, given its primary key. Remember that, for persistence, these tables reside on disk storage, and access can be very slow. If we have no means to “narrow the search,” finding a record by using a linear search of all the records would make such a system infeasible. Since a primary key for a table could potentially be any of the possible candidate keys, the primary key might well be a composite key.4
Even when another candidate key might exist for a table, often an “artificial” key is used for the primary key, where the key is created as the table is populated with data records. These artificial keys might be created by the enterprise (like the studentid for a college adding a student for the first time), or it could be generated automatically by the DBMS.
10.2.1.3 Illustrative Example
Fields of the courses table
Field | Data type and size | Field description |
|---|---|---|
courseid | Integer (4 bytes) | Unique number associated with a particular course |
coursesubject | String of up to 4 chars | The identifier for the subject, be it department or program |
coursenum | Integer (4 bytes) | The number of the course, as used in the catalog |
coursetitle | String up to 128 chars | Full title of the course |
coursehours | Integer (4 bytes) | Credit hours for course, from 1 to 4 |


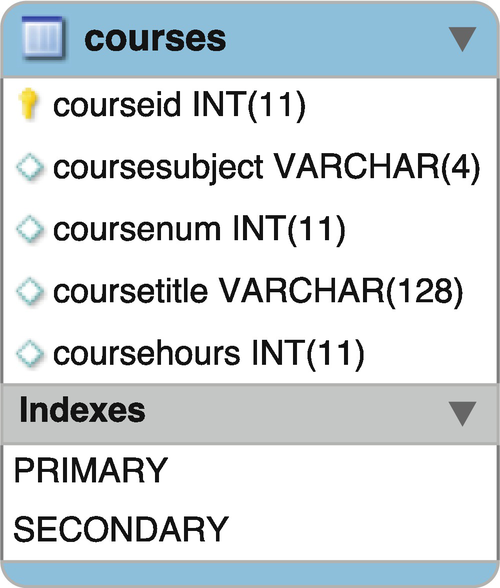
Table schema for courses
In the schema, a table is depicted in a rectangular box, with the name of the table in the bar at the top. Inside the box are each of the fields with the name of the field and the data type. In this case INT is used for the default integer size of 4 bytes. For strings, the SQL data type uses VARCHAR for variable length strings and the number in parentheses is the maximum number of characters to be used for this field.
The primary key is indicated in the schema with a small key icon. The icon next to the other fields is either filled in, or not, depending on whether we wish to enforce the constraint that the field is non-NULL or not. Here, coursesubject and coursenum must not be NULL (missing), but coursetitle and coursehours are allowed to be NULL. The Indexes section of the table schema refers to the auxiliary structures built by the DBMS to allow efficient access given a key. A PRIMARY index will always exist, automatically built for the primary key. In this case, we are also showing a secondary index that, while not shown in this picture, is the composite key of coursesubject and coursenum.
In the relational model, the tables of a database are created, one at a time, and we, in fact, use the SQL language itself to create the tables. Although details of table creation will be covered later, in Chap. 14, we show the SQL for this particular example to illustrate how a design and associated schema are realized:
The capitalization of SQL keywords is by convention, but not required.
For some database systems, the capitalization of field names is significant, so CourseID would be interpreted as a different field from courseid.
The backticks around table and field names may, in many cases, be omitted.5
For each of the fields, after the SQL data type, is the constraint of NULL or NOT NULL. Other constraints can also be included as part of the table creation.
Once a table is created within a database, it may be populated with data. The SQL INSERT command is used to add records to a table, and will also be covered in Chap. 14. Because the DBMS has the information from the CREATE shown above, it can enforce all constraints. So if we try to INSERT a record whose courseid already exists in the table, violating the uniqueness of a primary key, that SQL will result in an error. Likewise, if an INSERT tried to use a string that was longer than 4 characters for coursesubject, or a record that did not include an integer for coursenum, an error would result at insert time.
Populated courses table
courseid | coursesubject | coursenum | coursetitle | coursehours |
|---|---|---|---|---|
1023 | MATH | 135 | Calculus I | 4 |
2055 | CS | 111 | Discovering computer science | 4 |
2099 | CS | 399 | Independent study | 4 |
3012 | ECON | 201 | Micro economic theory | 4 |
10.2.2 Multiple Table Characteristics
While the structural characteristics of any single table are described above, we now consider additional structural characteristics of the relational model that involve multiple tables. Given any two tables, we must provide a way for one table to have fields and field values that somehow correspond to the fields and field values in another table. In other words, we are seeking to characterize and provide for the relationships that may exist between two tables. And the tables, as a set of records for some mapping, are representing a set of “things,” often with a correspondence in the real world.
Consider our courses table. Records of this table are intended to each represent exactly one course, like an item in the list of courses of a catalog for a college. The dependent fields then give all the information about that particular course. So given a course, the title for the course may be found, along with its course credits, and any other information we might wish to include. There might be multiple courses with the same title, say “Independent Study,” one associated with CS-399, but the same title might be associated with HIST-299. But given a single course, we can find the one and only title associated with that course.
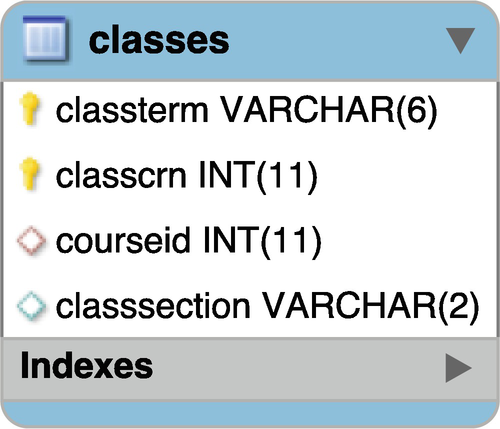
Table schema for classes
We define the composite key of classterm and classcrn as the primary key of the classes table.
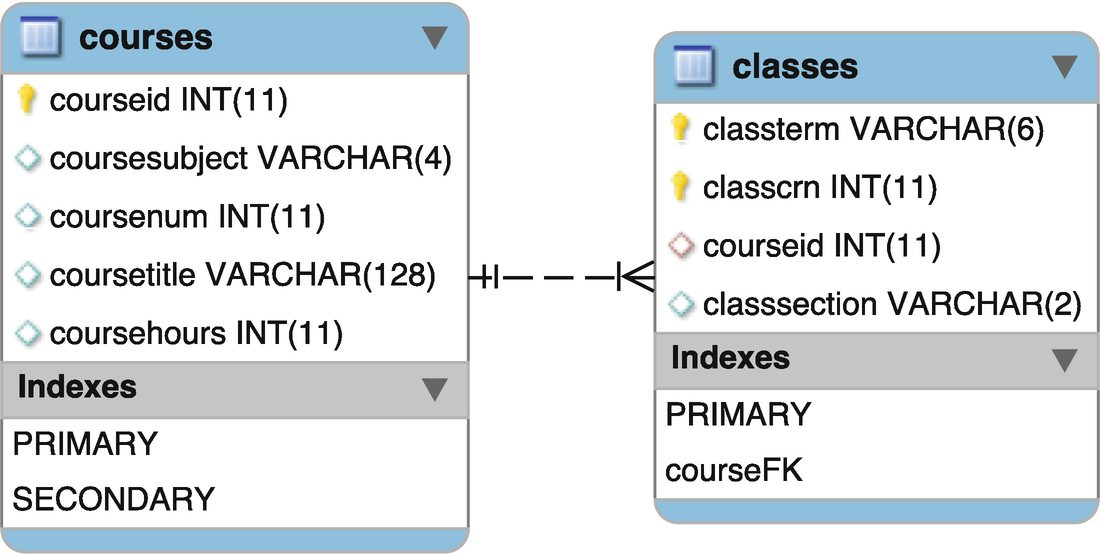
Database schema for courses and classes
When, by design, the fields of one table are used to establish relationships with another table through some corresponding field, we explicitly define a foreign key to allow for efficient table combination (i.e., a join). Again, this is part of the design of the database and part of the set of SQL used in the creation of the database, and before any population. This further enhances our ability to reduce common errors from being possible. In this case, an SQL INSERT into the classes table that included a courseid that did not exist in the courses table would be rejected with an error. Such inter-table constraints are called referential integrity constraints.
We could further expand our database of courses and classes and find table interactions that require a many-to-many relationship. For instance, we could add a students table. For a given student record, that student is generally taking multiple (many) classes. And it is certainly the case that, given a class, there are multiple (many) students taking the class.
In relational databases, many-to-many relationships are realized by adding an additional table, called a “joining” table or “linking” table, that allows us to define all the pairwise associations between the two original tables. By using this additional table and multiple one-to-many relationships, we can achieve the many-to-many relationship. We will explore this topic, from an operational standpoint, in Chap. 12, and from a design standpoint in Chap. 14. Because the many-to-many relationship is realized using an additional table and the one-to-many relationship (and appropriate foreign keys), it does not further complicate our discussion of the structural aspects of the relation model in this section.
10.2.3 Reading Questions
The reading mentions the phrase mathematical relation, which is a generalization of the notion of a function. Look up the definition of “mathematical relation” and try to explain how to think of an individual table as a relation.
When we were making data tidy in previous chapters, we often needed to move back and forth between integer and string representations of years by applying int( ) and str( ) to the column years. Would this be possible in a database? Why or why not?
Which of these are allowable field names and why?
- 1.
Address/PO
- 2.
num-cases
- 3.
number of visits
- 4.
pop_size
- 5.
socialSecurity#
- 6.
4chanUsername
The reading gives several examples of functional dependencies. Write down a functional dependency for the classes table, whose fields are shown in the Figure.
Give an example of key other than student id that uniquely defines a student.
Make a list of 4–5 fields that could be present in a hypothetical student database (with information on students), then modify the CREATE TABLE command to fit this example. Do not forget to specify a key.
The reading mentions that, when a database is created, each column is given a name, data type, data size, and “possibly other constraints.” Give a real-world example with a specific column and another constraint one might wish for it.
The reading discusses how one can connect the courses and classes tables by including courseid as a field in the classes table. The reading also discusses how courseid is a primary index for the courses table. Is it also a primary index for the classes table? Explain.
The reading explains the one-to-many relationship between courses and classes (since one course could be associated to many classes). Think of a database D such that courses would have a many-to-one relationship with D (that is, many courses associated to each record in D).
The reading discusses how one can connect the courses and classes tables by including courseid as a field in the classes table. Is it also possible to match up these two tables by adding a column to courses instead of adding a column to classes? Explain.
The reading provides examples of many-to-one and many-to-many relationships between database tables. Give an example of a one-to-one relationship between two tables.
10.3 Database Architecture
From a practical standpoint, when a relational database system is realized, at least in general, then we have shifted our source of data as well as our form of data. While we defer the general treatment of the various sources of data to Part III of this book, it helps to understand the relational model in the context of its architecture. We need to see how a client and a provider co-exist, often connected through a network, and how the provider responds to the needs of the client.
A client might be an application that we construct, but it also could be tool or utility that simply provides access to a database and allows us to issue SQL commands directly.6 When we are in the relational model, and are considering the provider in this model, the provider and server are referred to as the Relational Database Management System (RDBMS), or just “database management system” (DBMS) in common parlance. With the dual roles of client and provider in mind, we return again to the question of formally defining what is meant by this term. The Wikipedia definition follows [86].
A database management system (DBMS) is the provider software and hardware that interacts with clients and client applications on one side, and manages the data and its storage organization on the other.
The DBMS software additionally encompasses the core facilities provided to administer the database. The sum total of the database, the DBMS, and the associated applications can be referred to as a “database system.” Often the term “database” is also used to loosely refer to any of the DBMS, the database system or an application associated with the database.
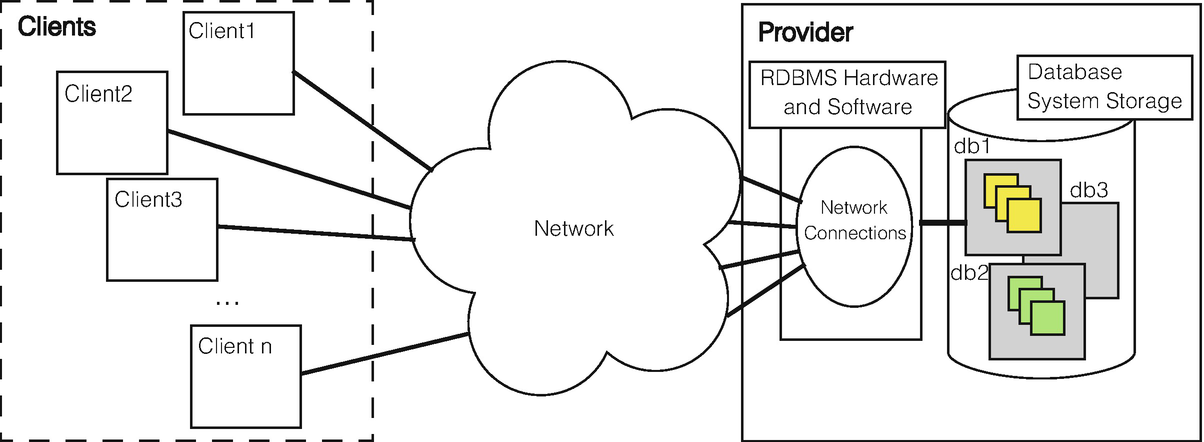
Relational database architecture
Each client establishes a connection over the network, and the target of that connection is within the software of the provider. The network, shown in the abstract as a bubble, could be as large as the Internet, and the provider could be one or more systems provisioned in the cloud, or the network could be the size of an enterprise and the provider could be a dedicated system maintained by an IT department. In particular, if the client is accessing the RDBMS over the Internet, and loses Internet connectivity, then access to the database(s) will be lost. On the smaller end of the spectrum, the network could be local, or even, virtually, within the confines of a single machine.
Each client must have a user identity that is part of the structure of the provider side, along with appropriate authentication and permissions. These are necessary so that different clients are not compromised, in a security sense, by the shared access.
On the provider side, we depict disk (or any other persistent) storage with a cylinder icon. In the figure we show that the RDBMS might be maintaining multiple databases, where an individual database (or schema) is defined, as above, as an interrelated set of tables. Here, we show db1, db2, and db3 as distinct databases. While we shall not concern ourselves with the physical model and structure, we should note that these are not simply files in the operating system. Database systems employ extraordinary efforts to manage raw disk storage and to provide for efficient access. Oracle, PostgreSQL, and MySQL are examples that realize the architecture of Fig. 10.4.
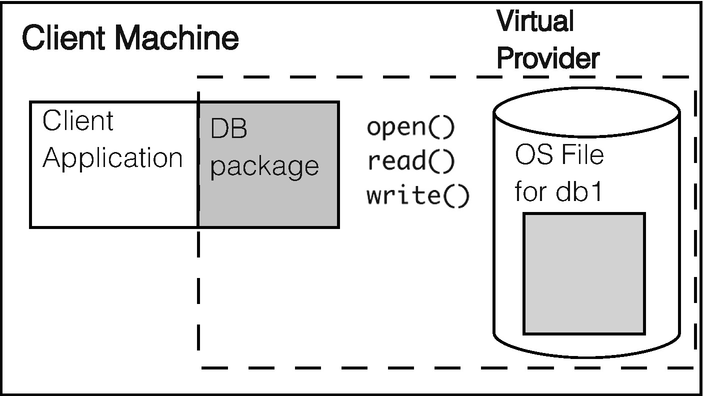
Single machine database architecture
In this simplified architecture, there are no separate user identities maintained by the database package. The client application has its OS-provided identity, and permissions for the OS file for the database are the same mechanisms as with any other file in the file system.
The differences between these two architectures, while they might be apparent in the connection establishment and in the programming package(s) being used, are not apparent in SQL operations.
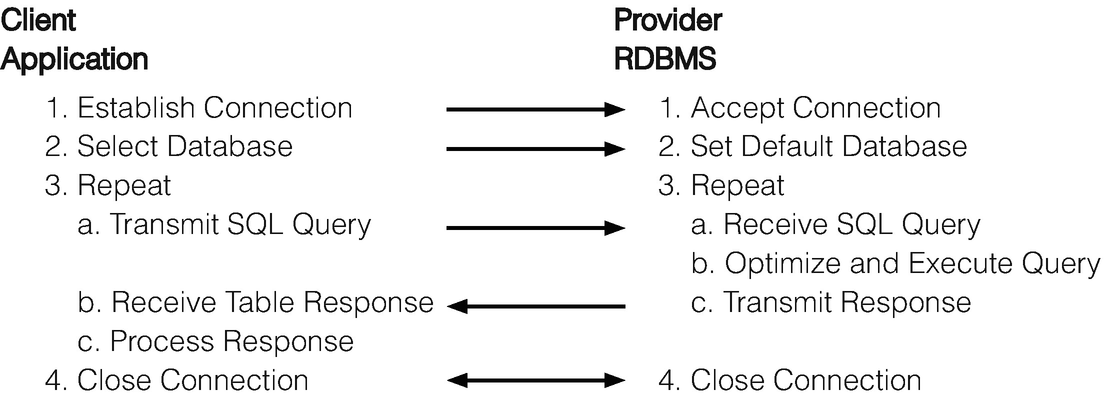
Client/provider database interaction
In the figure, the client is shown on the left and the provider on the right, and we use arrows to depict communication over the network, with the arrow head used to show the “net” direction of the communication.7
Before any queries or other SQL may be issued, the client first establishes a connection which, with appropriate authentication, is accepted by the provider. Depending on how the client established the connection and the defaults of the database software, a client may next need to select the particular database to use for subsequent interactions.
From that point on, the client and provider coordinate to exchange requests and responses. The client constructs an SQL query and transmits it (over the network) to the provider. The provider, after receiving the query, must parse the query, optimize and determine how best to obtain the data, and execute the query. The provider then transmits the response. The response is then received by the client and processed. The whole request-response interaction may be repeated as many times as necessary to fulfill the needs of the client.
The reader should realize that this is an abstraction, and Chap. 13 will give many specific details. In particular, if the data is truly large, it may be inefficient for the response to be transmitted in a single network operation, so we will see how responses can be processed in more manageable sized units. With this architecture and the client-provider interaction in mind, we can now, usefully, explore SQL queries that involve single and multiple tables.
10.3.1 Reading Questions
The book says each client must have a user id, so that different clients are not compromised, in a security sense, by the shared access to the RDBMS. Describe a real-world scenario that might represent a security compromise if such protections were not in place.
To understand the Client/Provider Database Interaction, use a program like MySQLWorkbench to connect to the databases provided with the book. Describe your experience, as a user, of establishing a connection, selecting a database, and viewing the data inside it.
If you were designing a database management system from the provider side, and you knew many students would be accessing the databases, what permissions would you grant the students by default and why?