The foundational ideas of API providers responding to data requests.
HTTP as the application level protocol for API providers, where a client and a provider are constrained to work within the confines of the protocol.
REST as a set of principles that broadly govern API providers but allow significant latitude in design.
- Given a provider, be able to issue HTTP requests, both GET and POST, conformant with provider expectations, including conveying parameters as part of the HTTP request in
the path part of the resource path,
the query string part of the resource path,
the headers of the request, and
the body of a POST request.
Process the result, from reacting appropriately to different status codes to parsing and interpreting the data in the body of the result.
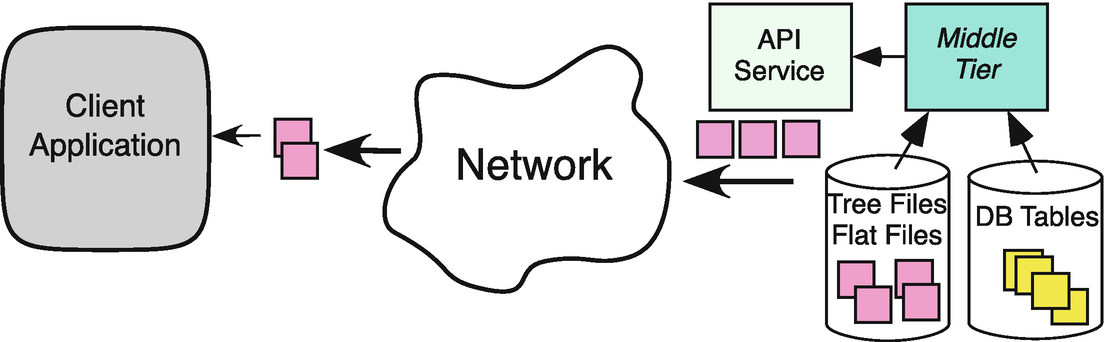
API service provider data source
23.1 Motivation and Background
Open Data : Often data is collected directly and indirectly by local, regional, and national governments or other organization, and the data is provided openly as a public service.
Service for Customer: The customer users of a company’s products and service expect to be able to use applications running in browsers and on smart devices and to be able to interact with the provider.
Service for Profit: Some providers are purveyors of data, which they gather and curate and then, through charging or ad revenue, establish a business model for their data curation work.
Innovation: For many companies, having client applications that can access data, often on behalf of users, and to innovate with those applications can be a motivation in of itself. The more users tie themselves to providers through the applications they use, the more secure the user–company relationship.
The Data System Provider is the entity providing the interface available over the network and generally is the keeper of the data, hosting it in back-end systems.
The Data System Client, also known as the application or just App, is the entity that issues the requests for data and processes the responses. The client app may perform its function to allow for analysis and combination of data from multiple data sources but could also be running at the behest of a human user.
The Resource/Data Owners are the entities with intellectual ownership or stake in the data hosted by the provider. These are sometimes users or customers of the provider, and the data collected can often be a product of that company–customer relationship.
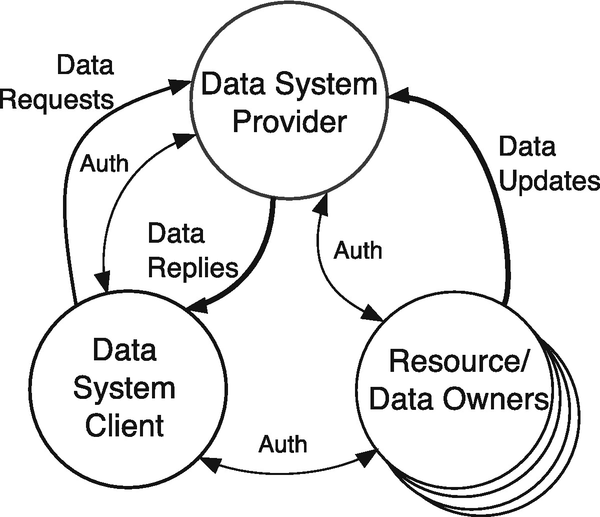
Data system principals
- 1.
Intention: In web scraping , web pages are designed for presentation for viewing, primarily in browsers, and data extraction is often a repurposing of the data contained therein. In API services, the provider is intending to provide the data itself.
- 2.
Format: In web scraping, the format is HTML; while it has a table structure and list generation capable of defining trees of information (like ol and ul), these were not intended for data exchange beyond their capacity for being rendered and seen by users through web browsers. In API services, because of the intention for use by client applications, the format is consistent with the various data models covered in Part II of this book. These formats include CSV, JSON, and XML.
- 3.
Abstraction: In API services, the desire is to present a usable interface by which clients can acquire data, but to allow the provider the implementation freedom to structure, store, and query the underlying data in whatever back-end system design is most suitable. In web scraping, the back end is determined by the capabilities of the web server employed by the provider. This is why, in Fig. 23.1, we depict a network-facing component that can service the requests coming over the network, but we abstractly show a middle tier , which is responsible for the dynamic query of data from the provider’s choice of back end.
Also, when web scraping, the acquired HTML is often static , already consisting of a textual HTML file in the file system of the web server. In API service providers, the data is often dynamic , being generated on the fly based on a request. In this regard, API service providers are more akin to the relational database systems that, in response to an SQL request, dynamically access the back end and respond with the requested data.
Whenever there is a choice, an application should use an API rather than performing web scraping.
23.1.1 General API Characteristics
It should follow the basic principles of client–server , with a request followed by a response.
From a client application standpoint, it should work like a function/method call, where the invocation is passed arguments corresponding to defined parameters, and the function/method, as translated into a client request, returns a data result.
Following on one of the strengths of the Internet, servers should not be strongly bound to clients, so that, as clients come and go, the servers are not required to maintain state information about the clients and their prior sequence of operation.
The API should leverage existing application level protocols, so that both servers and clients can be developed independently and do not have to incorporate a novel protocol.
23.1.2 Principles of REpresentational State Transfer (REST)
REST is an acronym for REpresentational State Transfer and is primarily about a set of principles guiding requests for data (state) and accompanying transfer. REST was first proposed by Roy Fielding in a PhD dissertation at UC Irvine [10, 11].
- 1.
Uniform Interface—we want servers to “do things” the same way, so that libraries, like our requests module, can provide tools to facilitate building requests.This principle argues for separation of specifying “what we want” from the representation/format of the data.
- 2.
Stateless —most fundamentally, this means that everything needed to successfully execute a request is “packaged together” in a unit, so the functionality can be provided independent of any prior interaction. Here, state refers to application state, so a server, for instance, should not need to have recorded prior steps related to a client.
- 3.
Cacheable —to allow for optimization, and to satisfy requests “more locally,” information should be able to be tagged to indicate whether or not it is cacheable.
- 4.
Client–Server—Separation of client concerns from the server means that the server can move, or an intermediary can provide information, and the server can implement and/or change the implementation of the service and not affect correct operation of the client.
In practice, many providers have adopted REST principles in defining their API and employ HTTP as the application layer protocol that enables many of these principles. While other choices for an application level protocol and other API designs exist, this chapter focuses on what are called RESTful services, which all use HTTP.
We have seen in Chaps. 20 and 22 the definition of HTTP and how to use HTTP in a client–server architecture to make requests and get replies and have seen in Chap. 21 how to extract results in our various formats to build in-memory data structures out of the structured data.
What remains is understanding the mechanisms used and specified, in a more formal way, by API providers so that we can understand what data is offered by providers and so that we can formulate the requests, using HTTP, to get the desired data. In relational database systems, our request was formulated as an SQL query that specified the tables, the columns, the filtering of rows, and so forth.
Each provider of an API determines how its own API is going to work, and the specifics, within the overall context of REST principles and by requests sent using HTTP, of how a request must be constructed to be interpreted appropriately by the provider and data returned. There is no standard that is the equivalent of SQL. However, for all providers, the client must convey the parameters of the request, and, using HTTP, there are a limited number of mechanisms for doing this. Understanding the building blocks of clients specifying request parameters through HTTP is the primary goal of this chapter and the subject of Sect. 23.2. Then, in Sect. 23.3, we bring the building blocks together with a more complete case study.
23.1.3 Reading Questions
In real-world terms, what is the value of a middle tier for dynamic query of data over a network?
The reading says “Whenever there is a choice, an application should use an API rather than performing web scraping.” How can you find out if there is an API to use?
Give reasons why a data-providing API should work like a function/method call from the client application standpoint?
What are the practical consequences of the “general API characteristic” that servers should not be bound strongly to clients?
Following on the previous question, are there any consequences for your particular computer of the design decision about servers vs. clients?
Please give a justification in real-world terms of each of the four “guiding principles” of REST. That is, describe, for each principle, what the world would be like if the principle were not followed, and explain why this matters.
23.2 HTTP for REST API Requests
RESTful APIs use the existing application level protocol of HTTP for making their requests and use the HTTP response message for carrying the outcome/status of the request and, if successful, the data resulting from the request. By using an existing protocol, the API must design and decide how to use HTTP, as defined, as the vehicle for making requests.
For the examples in this section, we will employ the APIs provided by GitHub [15] and by The Movie Database [64] to demonstrate the various concepts. The GitHub API provides access to public information and data, such as information about organizations and public repositories and events, as well as private information accessed through authentication and authorization on individual users and their private repositories. The Movie Database (TMDB ) API allows for searching and discovering information about movies and TV shows, acquiring data about specific shows, actors and actresses, and rating information, and it also has APIs for managing user information and placing and updating ratings for movies and TV shows. The TMDB APIs are not available for anonymous access but require requests to identify themselves as belonging to a particular application that has been previously registered. As a part of their terms of service, TMDB requires attribution for the use of their API and for any images, and we do so here:
For educational purposes and illustration of REST, this book uses the  API but is not endorsed or certified by TMDB.
API but is not endorsed or certified by TMDB.
The GitHub API allows a combination of both anonymous and application-/user-specific types of requests to be made. For a request to GitHub, we need to be able to specify things like the organization , the owner, a repository , the content type, etc. For a request to TMBD, we need to be able to specify, for instance, a search term, an application identifier, a movie, or TV show identifier or to convey information like a value for updating a rating. We categorize all such pieces of information that are conveyed from the client to a provider as the parameters of the request.
First, highlighted in light green, the HTTP method itself is conveying information about the request, and APIs use GET for a request to read information and a POST to send additional information to a provider and to request an update of some data maintained by the provider.
Second, highlighted in turquoise, we show an endpoint-path , which is part of the resource-path specified in the request. APIs use different base paths to distinguish different endpoints and also can encode request parameter items in the elements (location steps) of the path itself.
Third, highlighted in purple, a resource-path can optionally contain a query-string , whose start is signified by a ? character, and contains one or more query-parameters consisting of key-value pairs.
Fourth, highlighted in blue, each request contains a set of header lines. These header lines can also be used in an API to define request parameters.
Finally, in a POST request, there exists a POST body , highlighted in orange. This can contain request parameters consisting of key-value pairs (like we saw in Sect. 22.2.4) or, more generally, can consist of a JSON encoding string containing request parameters.

Request parameters in HTTP
The specification as given by the provider is the final word on how request parameters are conveyed, the expectations of the provider, required versus optional parameters, any authentication and authorization issues, success and error returns, and the format of any returned data. Any coverage in these examples is meant to be illustrative, and not as documentation.
APIs change over time, and while these examples all operated as expected at the time of this writing, changes made by providers may change the outcomes of the current set of examples.
Different providers can use terminology that may be different from each other and could also be different from that used in this book. They may also present information differently. So, it is important to build experience looking at the documentation of different providers to be able to translate and relate to the concepts presented here.
In our examples, we will use a combination of screenshots of the provider’s API documentation as well as a curl command-line incantation that can issue such a request. When a request is a GET and has no parameters beyond the resource path, we can also issue it through a web browser by entering the corresponding URL in the address line, and the reader is encouraged to deepen his or her understanding by actively executing examples where possible.
In the example code presented below, we assume the usual set of imports, and the existence of helper functions documented in Appendix A, such as util.buildURL( ) , util.print_data( ) , and util.read_creds( ) .
23.2.1 Endpoints
Generally, API providers, using the resource tree structure of the resource path URI entailed in an HTTP request, define a set of endpoints to be used for those requests. Typically, a single endpoint may be organized as having multiple subordinate paths that define different operations on that endpoint. One could draw the analogy of an endpoint representing an object class in an object-oriented programming language, and the set of subordinate paths as representing the methods that may be invoked on the object.
- organizations:
to list repositories of a particular organization and
to get detailed information about an organization.
- repositories:
to list public repositories.
- users/owners:
to retrieve basic information about the user,
to find set of users who are followers of a user,
to find set of users this user is following, and
to retrieve information about a particular repository of this user,
For the GitHub API, the root endpoint is given, through developer documentation, as https://api.github.com. We present a number of examples illustrating the most common ways of interacting with REST APIs. For each example, we present a command-line method, using curl to make the HTTP request, followed by a Python requests module programmatic example to accomplish the same end result.
For endpoints without parameters, using an API is no different from requesting a web page or other specific resource in the resource tree.
23.2.1.1 Root Endpoint
GitHub provides a “meta” endpoint at the root of its API resource tree. When accessed, it returns a JSON-formatted result with a key-value dictionary of the top level endpoints supported in the GitHub API.

We can see from the results that could allow programs, through programmatic means, to discover other endpoints in the API.
23.2.1.2 Non-Root Endpoint
/events is a GitHub API endpoint that, without further parameters, gets the first “page” of the set of current GitHub events: https://developer.github.com/v3/activity/events/. There is a maximum limit of 30 events in a page, so to request subsequent “batches” of 30, a client would have to specify a parameter whose argument gave the desired page.
The JSON result, on success, contains a list of dictionaries, with a dictionary representing each event.


23.2.2 Path Parameters
When an API uses the endpoint-path portion of the resource-path in a request to encode, as steps in the path, parameters, we call these path parameters . Refer back to Fig. 23.3 to reinforce where in a request this information is placed. Say that we want to make a request to get detailed information about a particular organization. The name of the organization is a parameter to the request. In the GitHub API documentation, such a request is shown as
What this means is that a request should encode the parameter of the name of the organization into the resource path, at the place indicated by :org. This notation of using a : and then the name of the request parameter is common as a means of specification among many providers, although some providers will use {variable}, or even <<variable>> to mean the same thing. Note that the syntactic decorations (:, { and }, or << and >>) are not tokens in the syntax and would not be included in a realization of the path.

As a second example of using path parameters, consider the desire to make a request to find the most recent GitHub events associated with a particular repository. But repositories in GitHub are named within either an organization or a GitHub user. So, now we have two request parameters to specify—the owner of the repository and the name of the repository itself.
This is documented in the GitHub API by
If the owner has the value denison-cs and the repository is named welcome, then we can make the request as follows:

23.2.3 Query Parameters
For the next set of examples, we will employ the API provided by The Movie Database (TMDB ). While GitHub has endpoints that can illustrate these same concepts, it is instructive to see the topics of Query Parameters , Header Parameters , and POST information from an additional perspective.
The TMDB API has two versions that are active, versions 3 and 4. For purposes of illustration here, we will use version 3, as it has endpoints that are interesting and are good examples of what we are trying to demonstrate. In addition, and in common with a large number of API providers out there, this API requires authentication, by which the client is assured of the identity of the provider and the provider is assured of the identity of the client application. Authenticating the provider to the client happens by virtue of using the https protocol in requests. In reference to Fig. 23.2, these two directions of authentication correspond to the bidirectional arrow labeled “Auth” between the entities of the provider and the client. This type of authentication is limited to identity of the application, and more sophisticated techniques must be employed to integrate users/data owners. A full discussion of all of these more advanced authentication and authorization techniques is deferred to Chap. 24.
In the TMDB database, all accesses require the request to provide an authenticating API key . The API key is obtained by an application developer registering as a TMDB user, complete with a username and password, on the TMDB site, and then, in an additional step, creating the identity for an application by providing detail about the app and its intended use, and, when successful, being given a 32 digit and letter string that identifies the application. These steps are taken in the developer’s browser. The resultant API key is then integrated into the application, usually by storing the key in a file or database so that the application can securely obtain the key when needed. As a part of authentication, it is assumed that, like a password, only the designated application can possess the provided key, and that if an application makes a request and specifies the key (over an encrypted network connection), then the application has authenticated to the provider, and the request may proceed.
Like we have done previously, we place authentication credential information in a JSON file, creds.json that includes information like the following:

23.2.3.1 Search for Movies
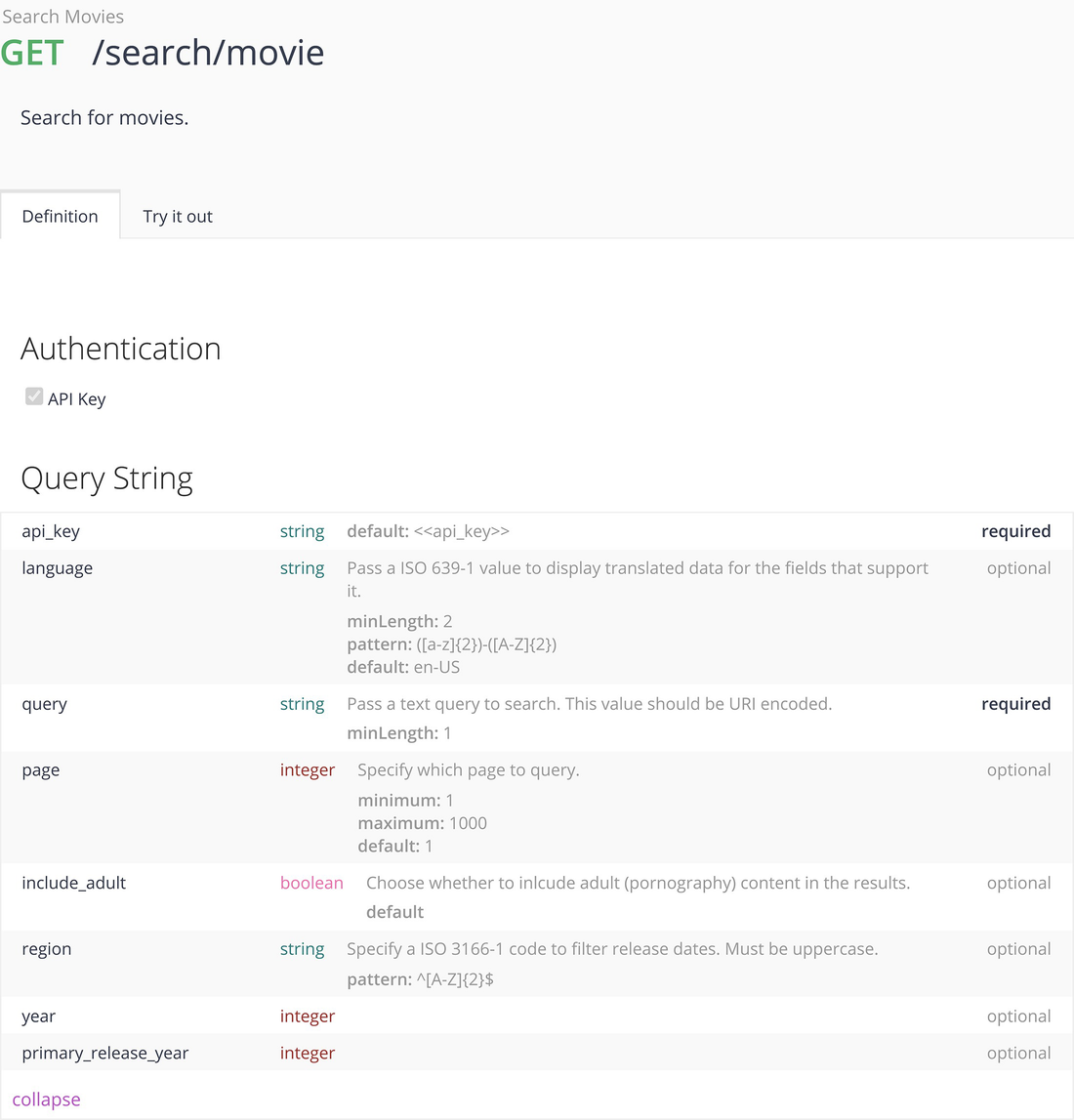
TMDB search movie specification
In order to search for a movie, the specification indicates that an HTTP GET request to endpoint search/movie should be used and that the request parameters that are required for such a request are named api_key and query and are listed under the Query String section of the documentation. This conveys that we need to specify two query parameters formatted as a query string. The query string is part of the resource path in the HTTP request and is formatted as a ? followed by a name=value for each query parameter, with an & character separating parameter key-value pairs. If we are constructing a query string by hand, we substitute + characters, or % 20 character sequence for any embedded space in a value, in accordance with URL encoding rules.
Say that we want to search for movies that match "Star Wars". The curl incantation of such a request, using the API key example above, follows:2

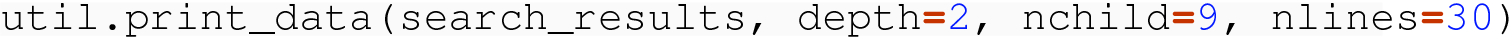
Using the documentation page for this API endpoint, we see that we could employ additional query parameters to, for instance, search for movies whose language is other than en-US, or, for results with multiple pages, request a different page of the results. Note how the JSON dictionary result informs the requestor of the total number of results and pages, so that programmatic control to get multiple pages is possible.
23.2.4 Header Parameters
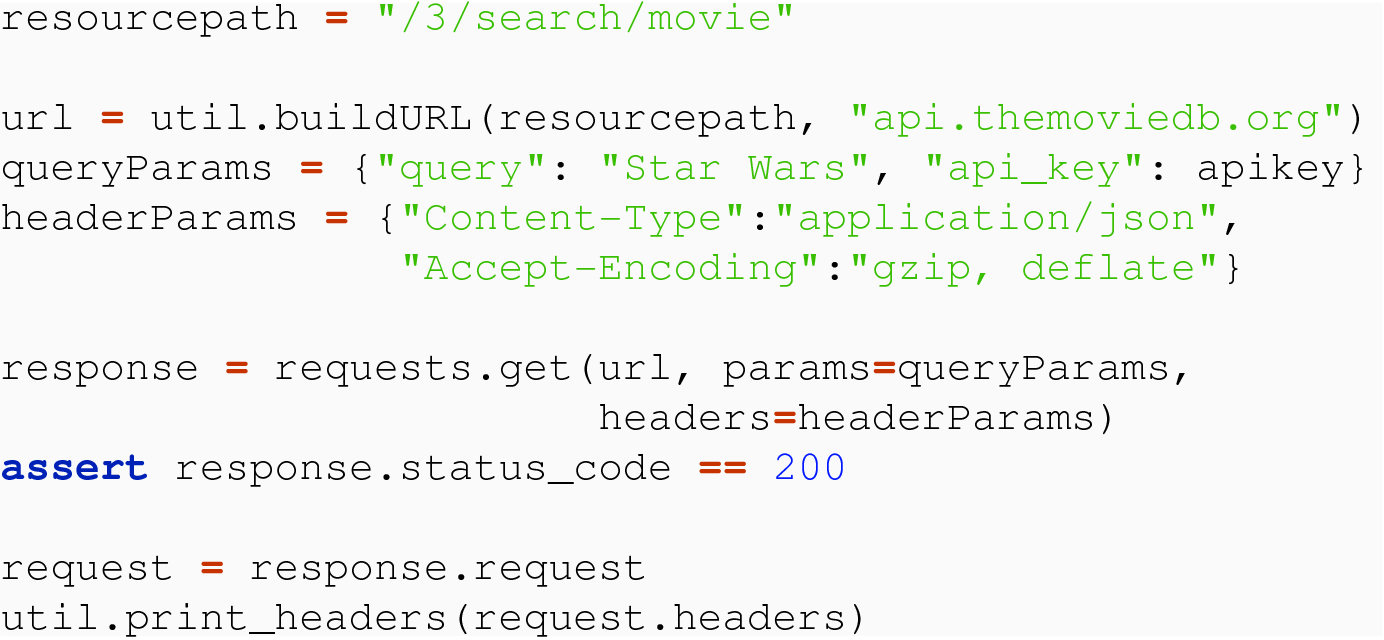
We see that this request is successful, and that our chosen headers are reflected in the response object, even though the headers themselves do not appear in the URI. Of course, we could create a functional abstraction for the code above, so that the content type and/or accept-encoding are parameters, and any header dictionary as in Chap. 20 could be passed to the requests module. However, TMDB will only provide data in JSON format, regardless of the value of "Content-Type". Since APIs are much more restrictive than general web resources, it is unwise to attempt to use headers beyond those required or supported by the API documentation. For example, if we added "Transfer-Encoding": "chunked" to headerParams in the code above, it would result in a status code of 501, since the TMDB API is unable to provide data in a chunked encoding.
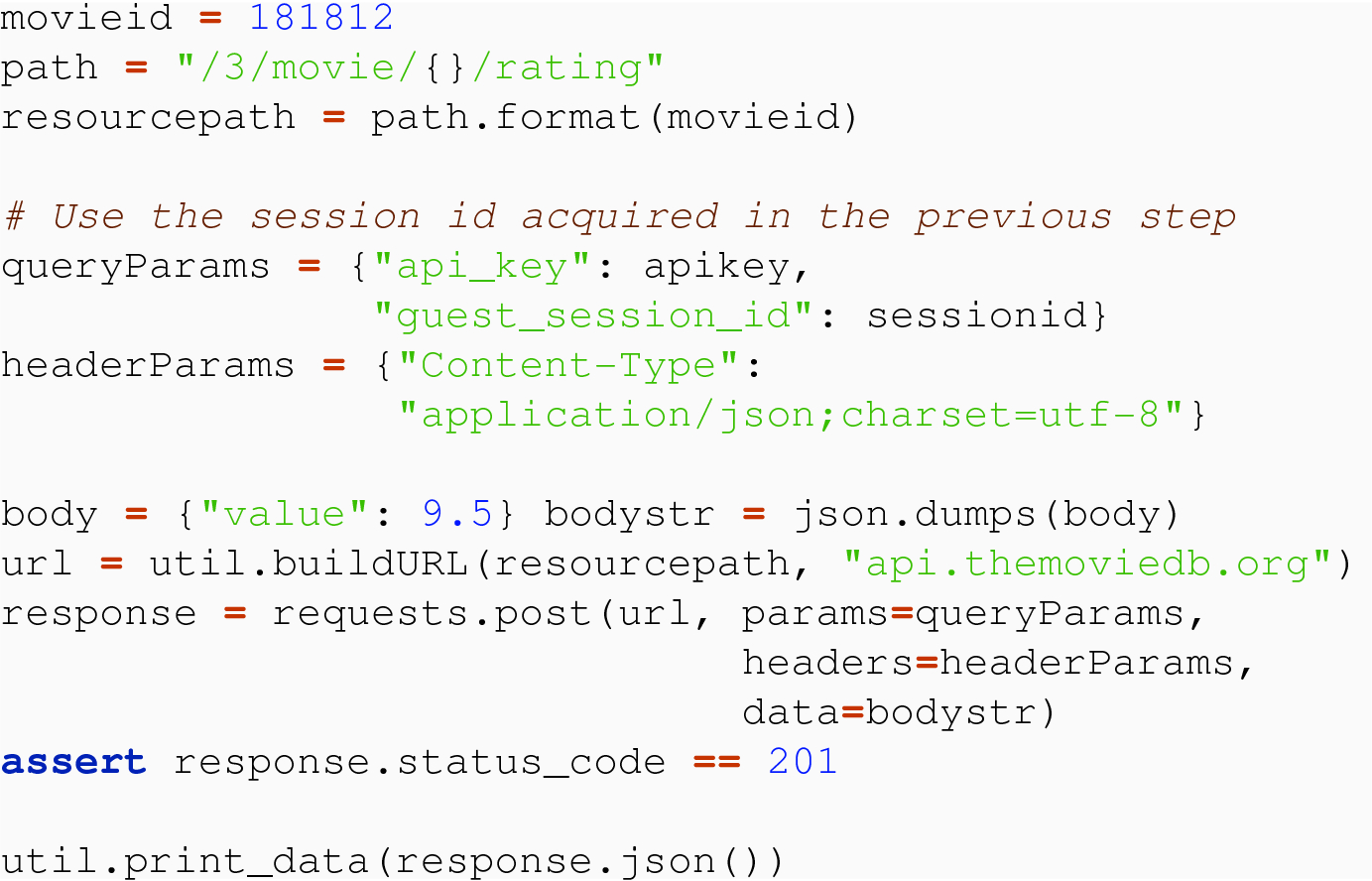
23.2.5 POST and POST Body
POST request
Path parameter
Header parameter
Query parameter
Authentication through query parameter
POST body.
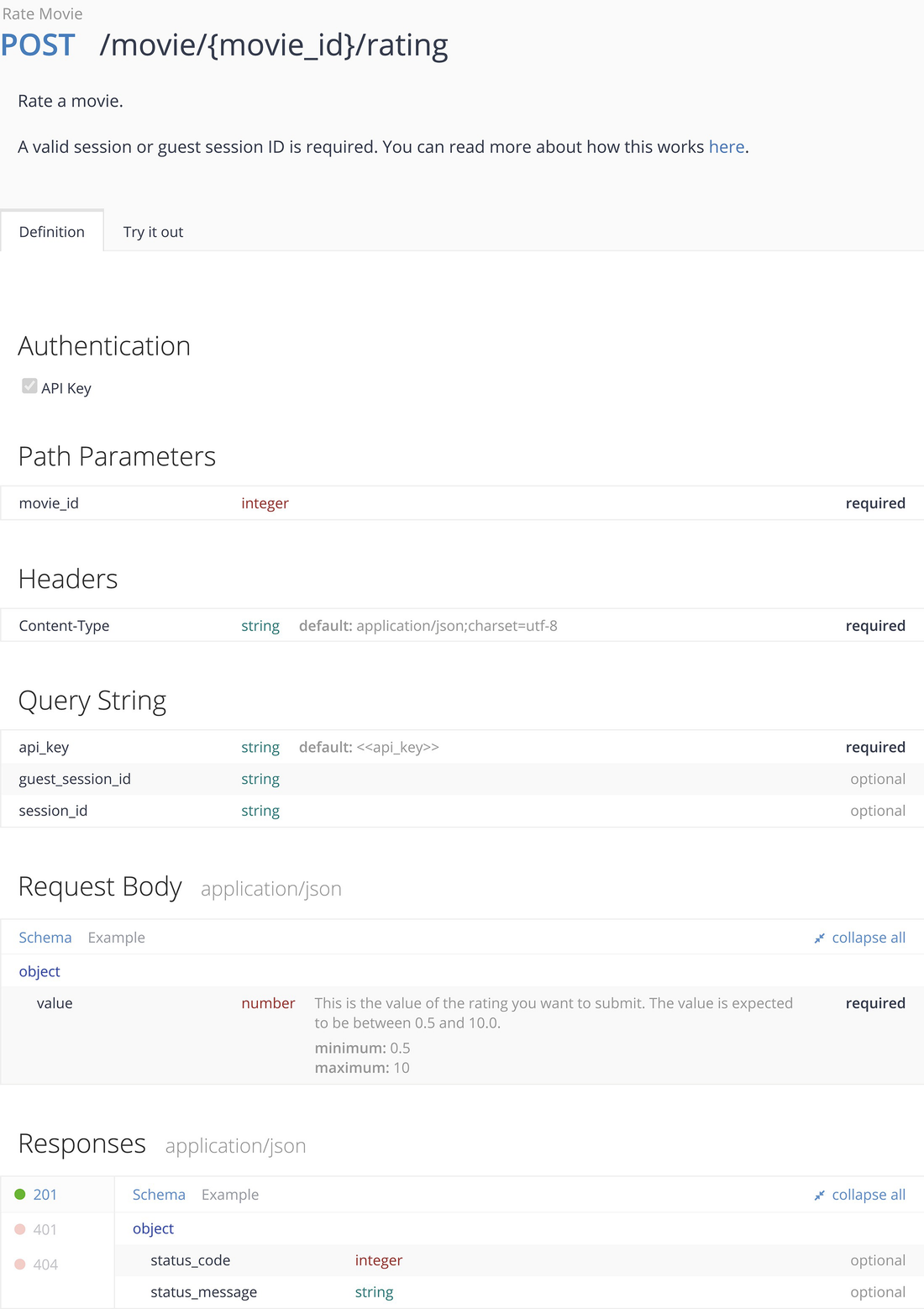
TMDB rate movie specification
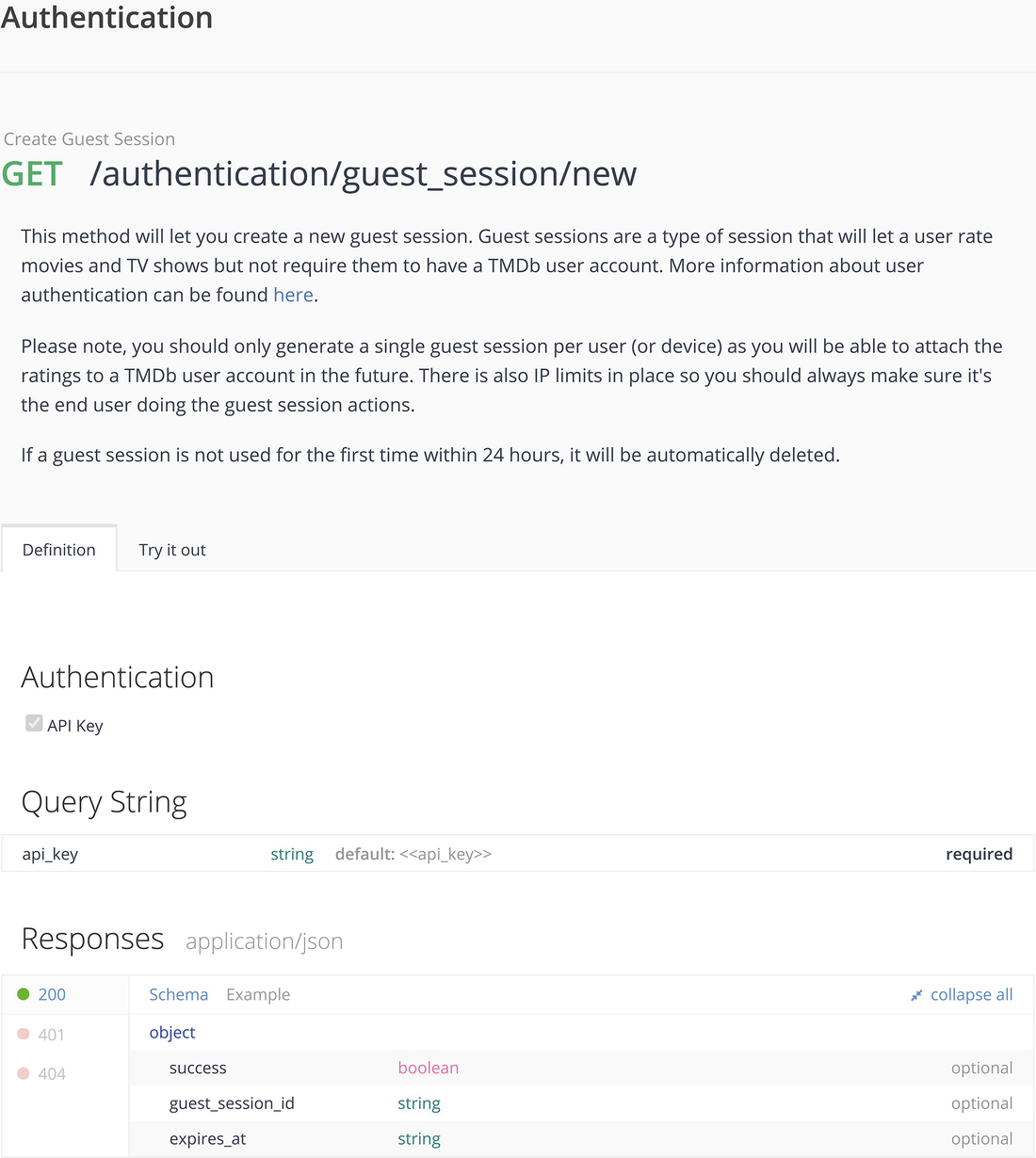
TMDB guest session specification
Following the documentation, the curl incantation uses the specified endpoint and includes an api_key query parameter.


At the conclusion of this code, the variable sessionid refers to the desired value, and we can use this in the POST to follow.
With a valid session id, the curl incantation must specify that the request is not a GET, by using the --request option, and, for the POST, specifies the body of the request by using the --data option.

- 1.
This request is authenticating a client, not a user. An API key is not the same as a session id, which is associated with the specific user wishing to rate the movie. This is why we need a guest session id. If we do indeed want to associate the rating with a specific user, we would need to obtain a session id, which requires a different form of authentication. OAuth is used for this purpose and is discussed in the next chapter.
- 2.
The body of the message has to be JSON. If you instead pass a dictionary as the data parameter to requests, it assumes you want the data body to be URL-encoded as a form. We needed the dumps to convert from JSON to the string needed for the body and to keep requests from doing the URI-encoding processing.
- 3.
For this POST, success is a 201, not a 200. A 201 is also a successful response, and some providers use this status code for a successful POST. Other providers could choose to use a 200, so the documentation must be consulted.
It is very important to look at any non-201 response, and, in particular, to look at the response body to get a more detailed message. For instance, it would not be appropriate to generate a guest session each time, since an update like this has its real use in being associated with a user. But a guest session has a limited duration, so a guest session id could expire, and an operation that “used to work” could start not working. And without attention to the status code and message, it would appear as “buggy,” when it is not.
23.2.6 Reading Questions
Please give a real-world justification for the design decision to make the TMDB API not available for anonymous access.
Please give concrete examples to illustrate the kinds of things we need to be able to specify for a request to GitHub. Then, do the same for a request to TMDB.
You can fill in any application name and URL that you like, but in the Application Summary field, you need to write a sentence or two. Feel free to simply describe that you are going to use the API key to learn about APIs for a course you are taking. When you finish, please write down the first four digits of the API key you received in the cell below. Keep the rest of your API key secret, and keep it in a place you will never forget it.
Please write down two terms of use you would expect, and one that surprised you, plus why. If any of the terms of use confused you, please write down your confusion below, so you can clarify it later.
The reading gives an example of an endpoint-path to the root for the GitHub API. Please formulate an endpoint-path to the root for TMDB and then describe what happens when you navigate to that link in your web browser.
The reading gives an example of an endpoint-path to a non-root endpoint. Please give an analogous example for TMDB and describe what happens and why when you navigate to that path in a browser.
For the curl example of searching TMDB for “Star Wars,” are the parameters shown query parameters or path parameters and how do you know based on the URI?
The reading mentions TMDB query parameters to search for different pages and languages. Please investigate the documentation and provide example URIs to justify this statement.
Please read the information at that website carefully and then answer the following questions:
- 1.
On the left sidebar, please give an example of a different kind of SEARCH you can do with the TMDB API. Then, please find the goal of a POST message under MOVIES on the left sidebar.
- 2.
In the Responses table, what example of a status code 401 is provided?
- 3.
In the schema for a successful application/json response, what path would lead to vote_average?
- 4.
At the top of the page, in “Try it out,” please put in the required api_key (you can use the one from the reading), a search for “citizen kane,” not including adult films, and only including films released in 1941. Please write down the resulting URL and describe what happens when you click “Send Request.” Is it the same thing that happens when you copy and paste the URL into your web browser?
- 5.
Experiment with different settings in the “Try it out” menu. What happens if you leave out the API key? Does capitalization matter? Can you search for a film with the symbol + in the title (e.g., the movie +1 released in 2013 about three college friends)? How are spaces and pluses converted into URLs, and why?
Suppose we created a URL as follows:
Please identify all parameters and their type (that is, query parameter, path parameter, header parameter, etc.).
23.2.7 Exercises
The first set of exercises will work with the TMDB developer API, version 3, documented here: https://developers.themoviedb.org/3/getting-started/introduction. Part of the point of these exercises is to find the documentation for obtaining various types of information and then being able to apply the techniques of the section to actually make the request.
For these exercises, we presuppose that you have registered and have an API key to use for making requests.
Many of the exercises will ask that you construct an answer to the question by using both the command-line and the curl and that you write code to do it programmatically, with requests.
Suppose we want to get detail from the TMDB API about actor Samuel L. Jackson. Before we can get detail information, we need to do a search to find the unique ID associated with the actor.
Find the documentation for searching for an actor, and, following the model in the book, and possibly combining with the “Try It Out” option in the documentation, construct a command-line as well as a requests-based search.
In the previous question, you might have been specific and included first and last names, in which case you may have obtained a single result. But you may have used, for instance, just the last name, or could have specified last name followed by first name, which would give you a different total number of results. Suppose your goal is to continue searching until you get down to a single result. Write code that interacts with a user to get a search term and then uses a while loop to make a request and then process the reply. If the result has a single result, print information about the result and terminate the loop. If the result has multiple results, print the total number of results, ask for a new search term, and continue the loop.
As a result of the previous questions, you should have the TMDB id associated with Samuel L. Jackson. Explore the documentation and find the API associated with getting the movie credits for a particular person. Write the curl and the requests programming to get the first page of movie credits for Samuel L. Jackson.
Write a function
that uses apikey to retrieve the movie credits associated with the person identified by personid and fetch the given page. The return value should be a data structure interpreted from the JSON-formatted body of the response. Return None if the request was not successful.
Suppose you want to rate a particular TV show, for instance, the show “Silicon Valley.” Works the techniques you have learned as well as the model shown in the section, to do the following:
- 1.
Find the id associated with the TV show.
- 2.
Obtain a guest session id.
- 3.
Formulate the POST request to perform the actual rating.
Relating these exercises to our use of the indicators data set in early chapters, we are interested in countries whose three character code is CAN, CHN, GBR, RUS, USA, and VNM. In the API, and as maintained by the World Bank, the indicators that they use map to the more intuitive names used in this book as follows:
Textbook indicator | World bank indicator |
|---|---|
pop | SP.POP.TOTL |
gdp | NY.GDP.MKTP.CD |
life | SP.DYN.LE00.IN |
imports | BM.GSR.GNFS.CD |
exports | BX.GSR.GNFS.CD |
Formulate API requests for each of the following scenarios:
Retrieve detailed information about VNM. Note the information available about the country.
In a single query, retrieve information about USA, CHN, and IND in the JSON format.
Retrieve information about the imports indicator.
Retrieve imports of the USA over all years.
Retrieve imports of the USA in 2011.
Retrieve the GDP of CHN, IND, and USA for years 2015–2019.
23.3 Case Study
In this section, we present a case study demonstrating the process common in data systems clients to use a REST API as a data source, acquire data, and put it into a useful tabular form and corresponding pandas data frames. We use the requests module to obtain data from the TMDB API about popular movies and cast members in those movies. We divide our work into two phases. In the first phase, we focus on constructing a table of popular movies and demonstrate the need, in the design, for using more than a single request to achieve a result. In the second phase, we use the popular movies table as input to the process of generating a table of top cast members from those movies. This involves the input driving multiple requests to obtain the needed data, another common pattern.

23.3.1 Phase 1: Build a Table of Popular Movies
/movie/now_playing: Gets list of movies in theaters;
/movie/top_rated: Gets the top rated movies in TMDB;
/movie/upcoming: Gets a list of upcoming movies in theaters;
/discover/movie: Gets a flexible list of movies based on many different criteria and provides sort options. Some of the criteria include
release year minimum and maximum
vote average minimum and maximum
vote count minimum and maximum
with particular people in cast or crew
/search/movie: General search function equivalent to entering a search string in the interactive version of the TMDB site.
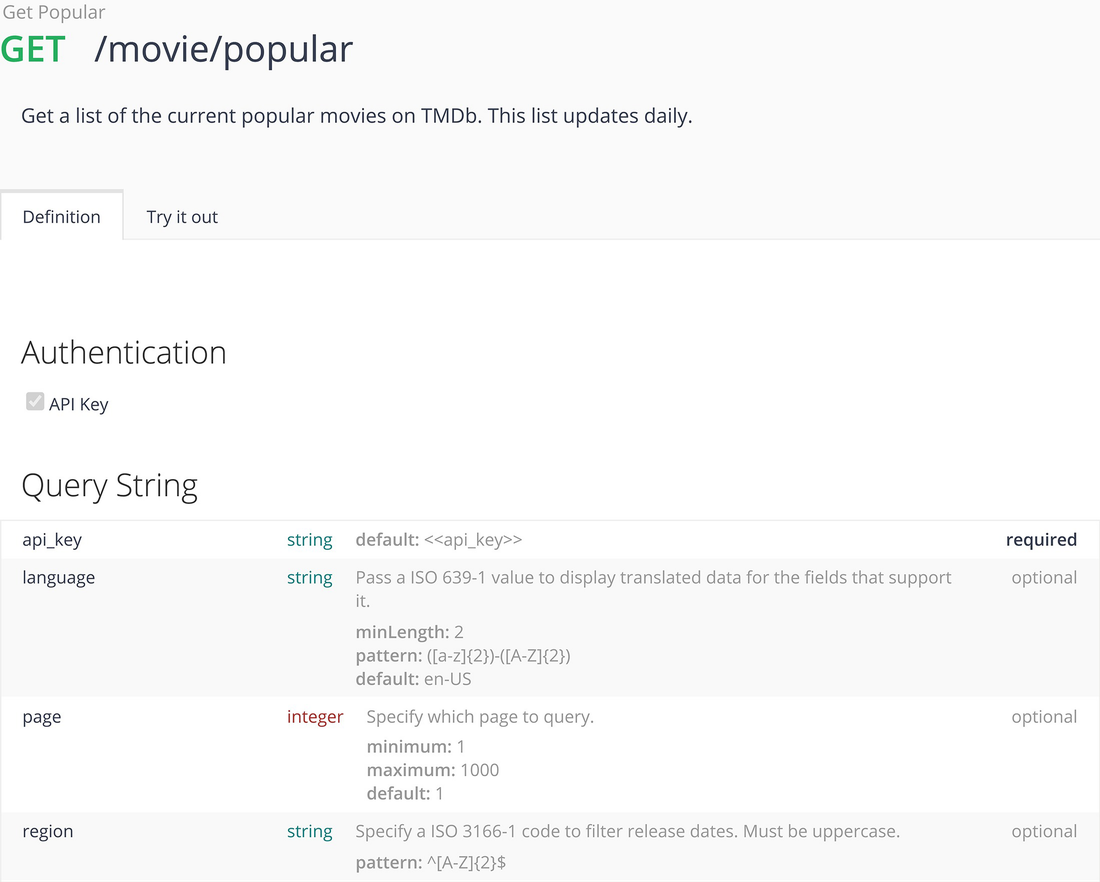
TMDB popular movie API
retrieving a page of results through the API, and
using the results to build a native Python data structure of tabular information.
These parts can then be combined and repeated to retrieve multiple pages and aggregate the native Python data structure, which will then allow construction of the data frame.
23.3.1.1 Design a Function to Issue Request
With a mind toward developing clean and reusable software , we start with a building block function that can be used to issue a single request of the API. We illustrate how to do this using curl and then how to do it using the requests module. In the design of our function, we want a parameter for the page, so that we can easily request different pages of results.
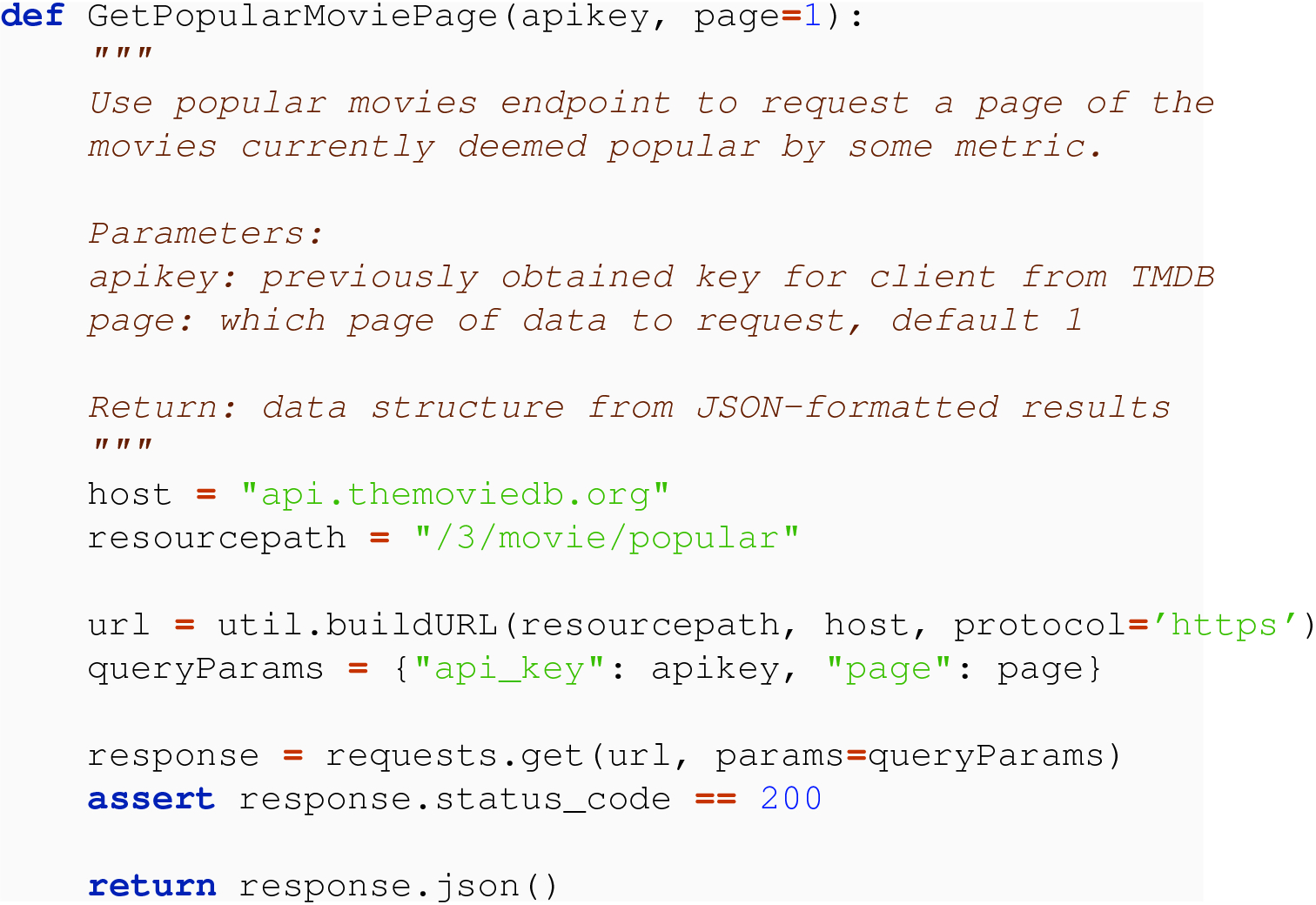
23.3.1.2 Understand Results
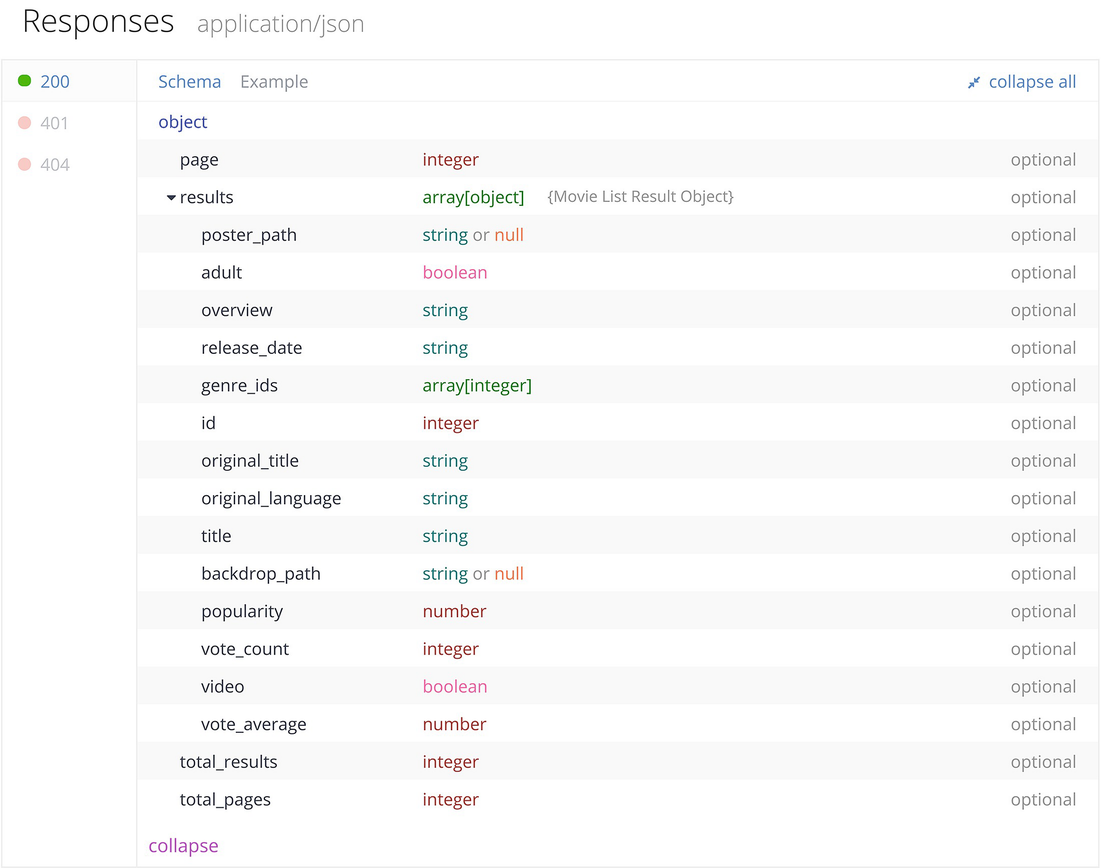
TMDB popular movie results
- 1.
The root is a dictionary (JSON object) with keys page, total_results, total_pages, in addition to results.
- 2.
The primary information is in results, which is of type array[object], which is the JSON way of saying a list of dict (dictionary) objects.
- 3.
Each individual dictionary in the results list gives information about exactly one movie.
- 4.
The full set of popular movie information extends significantly beyond the results in this one request/response exchange. The result tells us what page we have and also tells us the total number of pages and the total number of results. Depending on the goal, we may need to issue multiple requests to obtain the full set of results.
23.3.1.3 Design Movie Table
To build a tabular representation of the movies, we need to decide on the fields. For simplicity, we will select just a subset of the possible information and will include one non-tidy field in our movie table, as noted in our target list of fields:
Field | Python type | Notes |
id | int | The TMDB identifier for the movie |
title | str | The TMDB title |
genres | str | Encode list of integers from result into comma-separated list as string; not tidy, but convenient for our current needs |
popularity | float | Metric computed by TMDB for the popularity of a movie |
vote_count | int | Number of rating votes for this movie at TMDB |
vote_average | float | TMDB computer average of votes |
release_date | str | Release date of the movie |

23.3.1.4 Handle Multiple Pages
Very often, an API service provider throttle results in various ways. If the number of results from a request can be large, the results are typically divided into chunks or pages , and a request indicates the total number of pages and/or results as part of each response. It is up to the client to navigate this and, if necessary, issue additional requests until all the desired data is acquired.



23.3.2 Phase 2: Build Table of Top Cast Given Movie IDs
Given the set of movie IDs from Phase 1, the second phase of our case study was to build a table of top cast from that set of movies. That will involve multiple requests, one per movie, to obtain the cast list for each movie. Then, for each of these cast lists, we compose a cast table. We use a threshold so that we only include a limited number of cast members per movie. Finally, we remove duplicates in the cast table.
understanding the relevant API,
designing a table for the cast members and a function to build a native Python data structure for the cast of a given movie, and
designing a function to perform this repeatedly over a set of movies.
23.3.2.1 Understand Movie Credits API
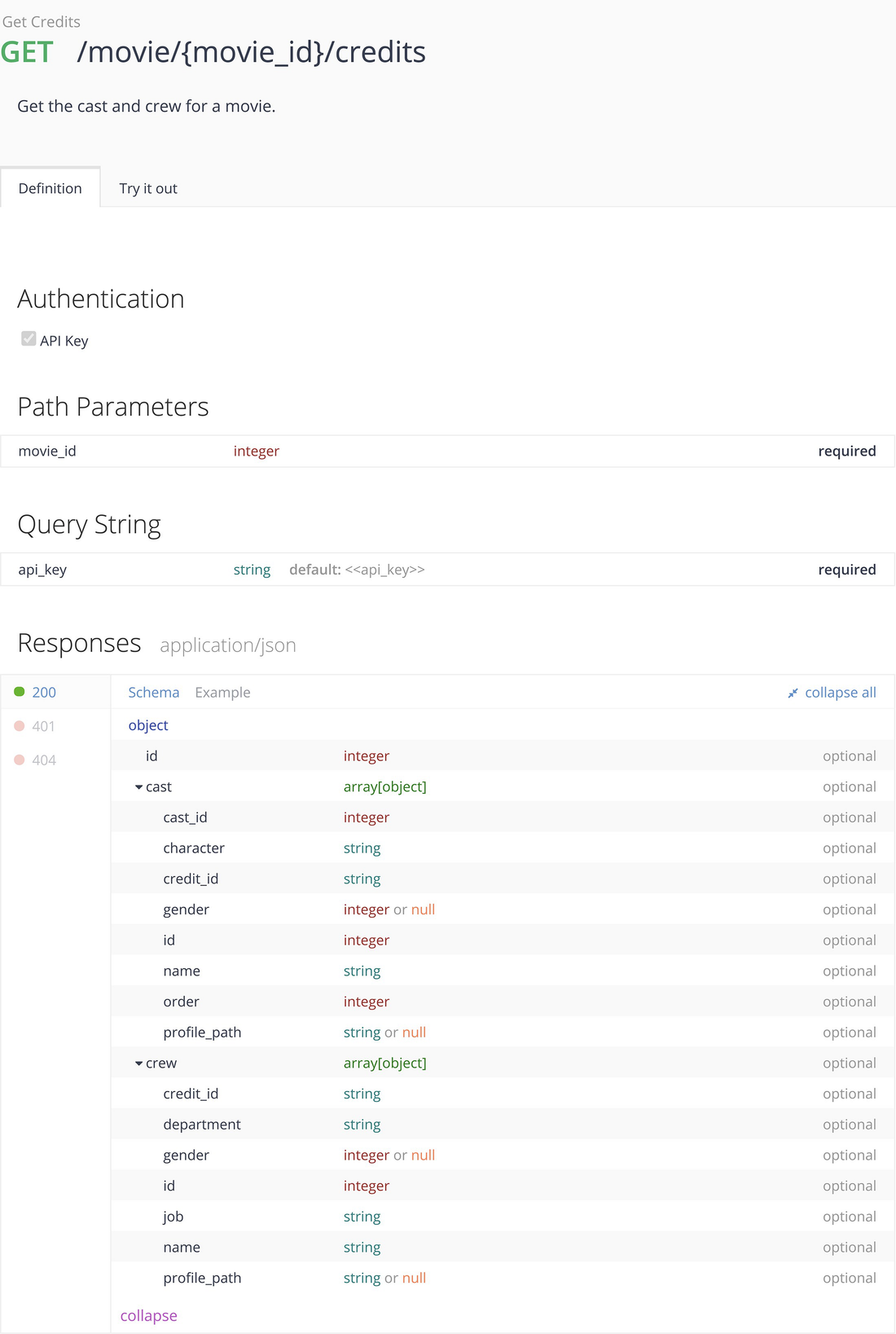
TMDB movie credits API
- 1.
The root of the return is a JSON object
- 2.
The root has three children: the id of the movie and children for cast and crew.
- 3.
The cast child is a JSON array of JSON objects.
- 4.
Among the fields for a cast member, the name, id, and gender of the cast member appear to be independent of the particular movie.
- 5.
The order field is an integer that gives the relative importance of this cast member.
If we seek to limit to the “top” cast, we can use a threshold to filter by the cast whose order value is less than or equal to a given threshold.
We illustrate a request to the API using curl.
23.3.2.2 Goal: Design Cast Table
To build a tabular representation of the movies, we need to decide on the fields. For simplicity, we will just select three fields, already available in the results of the credits from a movie. This could be enhanced by requests to get detailed information about each of the selected persons in the cast. This is our target list of fields:
Field | Python type | Notes |
|---|---|---|
id | int | The TMDB identifier for the person |
name | str | The String name of the person |
gender | int | Encoding as an integer for the gender of the person and may be null |

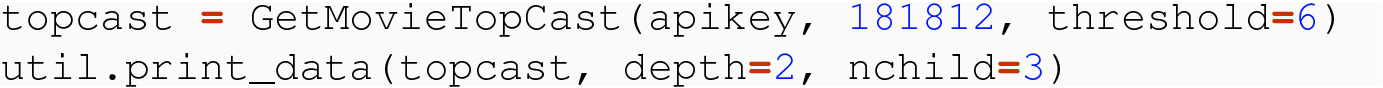

And we see a successful outcome with a top cast data frame.
23.3.3 Summary Comments
In this chapter, we have learned how to interface with APIs, how to formulate requests that satisfy the API documentation, how to read the documentation to learn what kind of response we will receive, and how to wrangle the response into a pandas data frame. These skills are tremendously useful in data science.
When taking what we have learned into practice, we will see that there is no standardization, and that there are as many different ways for a provider to specify an API as there are providers out there. One of the more recent directions one can observe in the landscape of API services is for providers to reduce the number of endpoints, in the limit providing just a single endpoint, but to increase the expressive power of what can be requested. In this type of API service, the client builds a tree structure that describes the information they desire using a Graph Query Language or GraphQL [17]. This, in essence, extends the ideas presented in this chapter and combines them with parts of what we learned in Chaps. 15 through 17 in the hierarchical model (and hence the term graph in the name of this query language).
We turn next to issues of authentication and authorization, so that our client apps can obtain sensitive and/or protected user data from API providers.
23.3.4 Reading Questions
If array[object] is the JSON way of saying a list of dict (dictionary) objects, what do you think is the JSON way of saying a list of lists?
Please explore the documentation for TMDB API and find an example where the responses give you a different JSON type (other than array[object]) and report your answer here. Study the figures in the chapter carefully to see where the type is specified in the Responses table.
What would happen if we did not use the parameter threshold in our functions?
What is the connection between the URI sent by requests.get( ) in GetPopularMoviePage and the URL in the curl command above the function? Explain your answer.
Please justify the book’s reason for using a LoD for the desired movie table. Please refer back to earlier chapters for the pros and cons of the various ways to represent two-dimensional data in Python.
Carefully study the function GetPopularMovies( ) and then explain the logic behind the while loop. Specifically, when does the code escape the loop and what does that mean in the context of the problem?
Why is it important to remove duplicates from the Top Cast table? Please reference the tidy data assumptions.
Study the code for GetMovieTopCast( ) and GetTopCast( ) . In the latter, why do we use Composite_LoD.extend( ) instead of .append( ) ?
The Internet is full of APIs that can provide data on a wide variety of subjects. Please locate an API on a subject you are interested in, read the documentation, and describe a data analysis project you could complete using this API. Please make sure to provide sufficient detail to justify your plan. At the time of writing, a search engine for APIs was available at http://apis.io/
23.3.5 Exercises
Please run the code from the reading, which carries out a POST to TMDB, but use the session id from the book, without getting a new guest session id of your own. The session id will be expired, so you should not get a 201 status code. Write code to demonstrate the extraction information from the response to figure out the problem with your request. (Printing the status code is not sufficient.)
- 1.
Start by replicating and successfully executing the code to obtain a guest session id, and name it guest_session_id.
- 2.
Repeat the code from the book to perform the POST but do NOT convert the dictionary with value mapping to a number into a JSON-formatted string.
Run this code and print out the status code and the text body of the response.
From the request object (obtained from response.request), print out the body of the request.
The reading mentioned the TMDB endpoint /discover/movie. Many examples of what can be done with this endpoint are provided at the following link:
However, as always with APIs, it is unwise to rely solely on examples. Rather, you must read and understand the API documentation. Navigate the TMDB API documentation and find the URL that explains how to use the endpoint /discover/movie (the place with the “Try it out” tab). Record that URL as the answer to this question.
Write a function
that returns a Python dictionary mapping genre names to id numbers, e.g., {'Action':28, 'Adventure':12,...}. Your function should only make a single call to requests.get( ) , with the appropriate endpoint-path for TMDB and with the given API key. As always, return None if something goes wrong.
Write a function
that uses the /search/person endpoint to conduct a search for the given name and returns just the id of the first entry in the results list. If you solved searchPerson( ) in the last exercise set, this only needs to go a bit further to retrieve the first element and the id from that first element.
As always, return None if something goes wrong, but return -1 if there were no results.
Suppose you want to generate a list of movies featuring your favorite actors/actresses and in the genres you like. Suppose actorList and genreList are lists of strings, like “Humphrey Bogart” or “Adventure.” You can use your functions searchPersonId and getGenreDict to find the ids associated with these strings.
After studying the API documentation and examples for the /discover/movie endpoint, please write a function
that returns a LoD with one dictionary per movie, with columns title (that is, “original title”), id, popularity, language, and overview. For full credit, your function should use a single call to requests.get( ) and should include movies with all of the actors on actorList and with any of the genres on genreList. Be careful with your ANDs and ORs to solve this problem as stated. If you come across a non-existent actor or genre (e.g., “adventure”), do not include it in the search. Please sort your results by popularity, from most popular to least popular.
Write a function
that returns a data frame consisting of all US movies whose rating is less than or equal to the given rating (e.g., G, PG-13, R, etc.) in the given year, sorted by revenue, from largest revenue to smallest. Your columns should be title, release_date, popularity, vote_average, and overview.
Be careful, as your initial invocation of requests.get( ) might only return page 1 out of some large number of pages. You should be sure to get the information from all the pages. A helper function would be wise. The filter on year should use year, not release_date.
Hint: study the documentation for the /discover/movie endpoint carefully. What we have called rating they call something else.