1 Introduction
Internet of things (IoT) is an exponentially growing field. Accordingly, IoT is experiencing huge security and privacy challenges [26]. From the recent study conducted in 2017, more than 57% of the companies have adopted IoT technology and 84% have already experienced an IoT related security breach [13]. A study by HP [12] in 2015 found out that most of IoT devices had one or more significant vulnerabilities.
In this regard, we perform security analysis by choosing fuzzing as our technique. Fuzzing is an age-old concept, first used to detect vulnerabilities in UNIX utilities [3]. Fuzzing is an automated software testing technique in which invalid, unexpected or random data is provided as an input to a target system/program so as to get a crash or an exception which can potentially lead to a vulnerability. Although fuzzing technique is random and straightforward, its benefit-cost ratio is very high. Thus, it is more efficient than other standard techniques and is often used with other proven debugging and testing methods like black-box testing, beta-testing, etc. Fuzzing can be done in random, mutational or generational fashion. In our work, we adapt mutation fuzzing method. Mutation-based fuzzers are very effective when dealing with unstructured inputs [15].
In the current state-of-the-art, there are several fuzzers such as American Fuzzy Lop [23], Peach [20], Sulley [2], Radamsa [16], etc. Most of the current works focus on the type of inputs rather than the sequence. One of the challenging tasks of developing an IoT protocol fuzzer involves generation of inputs for IoT-related protocols.
In most of the cases, the target rejects inputs due to various factors such as semantics, data-types, illegal sequences, protocol fields, etc., since it does not adhere to the target’s input specifications. The current mutation techniques related to fuzzing lack consideration for location, context and time [20]. Most of the fuzzers mutate blindly and often lack a mutation strategy that is usually random or based just on the structure. The assumption that every mutation has a higher probability of generating a crash does not hold true and leads to inefficient fuzzing.
In order to fill this gap, our goal is to propose a framework called SMuF (State Machine based Mutational Fuzzing Framework for Internet of Things) for fuzzing IoT protocols. Our design focuses on input mutation which remains orthogonal to the traditional mutation based fuzzer. Based on our goal, first, in our work, we use state machine to understand and generate various states and paths of a protocol. Our technique makes sure that the state machine of the protocol can fuzz all the possible protocol paths. Next, we determine the various fields of the protocol and generate legitimate protocol packets.
Second, we propose a mutation technique which focuses on mutating certain locations of the input, context of the data being carried and mutating based on time. This makes our fuzzing method more efficient. Location-based mutation will be able to mutate particular fields which will still be legitimate enough to be able to reach the target. For example, we will not mutate fields like a checksum or target IP addresses. Moreover, mutating the context will help us in identifying privacy leakage when an IoT device is not able to distinguish between two different types of data carrying different context. Mutating based on time will involve mutating time-related factors including the rate of sending packets, TTL of the packet and so on. This will be helpful in detecting race time-related vulnerabilities. Next, just not limiting on approach of mutation, we also focus on how to mutate or which mutation operator to use for mutation. For example, we use various mutation techniques such as bit-flipping, bit-shifting, etc., and also various crossover techniques inspired from genetic algorithms [10].
Third, We have also proposed a probability score to differentiate between different mutated inputs in terms of diversity. Probability score ensures that we are testing the protocol implementation with unusual packets or paths. A mutation-based fuzzer can also use the probability score as a fitness function. After we have generated new inputs by mutation, we use probability score to select those inputs whose characteristics are comparatively uncommon in the normal input for the IoT device.
Finally, we have implemented and evaluated our fuzzing framework in our IoT security testbed. We fuzzed more than 30 IoT devices and found various known vulnerabilities such as Denial of Service (DoS), Buffer Overflow, Session Hijacking, etc.
We propose a mutational fuzzing framework called SMuF for IoT protocols that takes the help of directed graph of the state machine of the protocol. Also, we consider various levels and sub-levels of the IoT protocol packet.
We propose a mutational fuzzing technique based on location, context and time.
We propose a method to select the most uncommon input generated based on probability score.
We have implemented and evaluated our framework in our IoT security testbed on various IoT devices and found various vulnerabilities.
The rest of the paper is structured as follows: In Sect. 2, we provide the overview of our fuzzing framework and in Sect. 3, we give the details of our approach used in our work. In Sect. 4, we jot down the experimental setup, experimentation and provide results. In Sect. 5, we provide the related work and conclude in Sect. 6.
2 Framework Overview
We have designed and developed mutational fuzzing framework called SMuF that targets various IoT devices and their respective protocols. Our design is generic and any existing fuzzers can be used as a plugin.
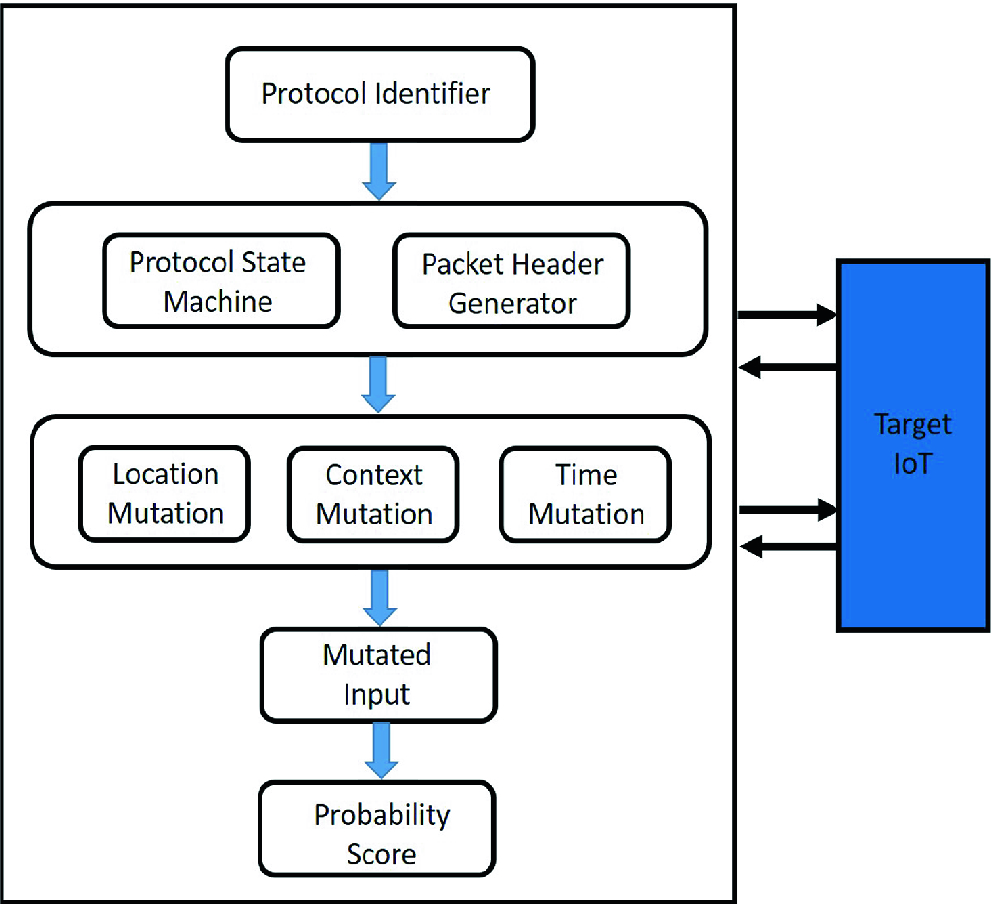
Overview of IoT protocol fuzzing framework (SMuF)
First, SMuF is initiated by scanning the network and identifying the protocol which could be IP, BLE, Zigbee, etc., from our Protocol Identifier module. Next, from Protocol State Machine module we create various states of the identified protocol. Simultaneously, the Protocol State Machine module creates a directed graph representation along with the transition. From the directed graph, we use Depth First Search (DFS) to find all possible paths in the graph and then leverage the shortest path from the start state to the final state. Each of the paths represent a valid sequence of input packets. The Packet Header Generator module then generates a legitimate packet based on the protocol. Every field in the packet represents the corresponding level with regard to their hierarchy.
Next, our mutation strategy is used for location, in our case fields in a packet, context and time along with standard mutation operators such as bit-flipping, bit-shifting, etc. Using Mutation based on location, we mutate certain fields of a protocol packet. In Mutation based on context, we change the context of one packet to create a new input with a different context thus changing the context of the original input. For example, the context we consider are based on the different payloads of the packets and also the authentication process between different states of a protocol. In Mutation based on time, we change the time-related factors like the rate at which the packets are transmitting or time-related fields like TTL.
After the mutation, we are left with a set of Mutated inputs which can be used for fuzzing. However, as we want to choose the inputs with higher probability of causing a crash, we use a Probability score to find and select the types of inputs that are not commonly encountered by the target IoT device. We select those inputs whose characteristics are comparatively uncommon in the normal input for the IoT device.
3 Approach
In this section, we elaborate on our approach used in each of the module of SMuF. In our framework, before initiating other modules, we will capture the information of the protocols from our Protocol Identifier Module.
3.1 Protocol State Machine
 State A
State A  Final state is one path. We modify DFS to find all possible paths between start and end states.
Final state is one path. We modify DFS to find all possible paths between start and end states.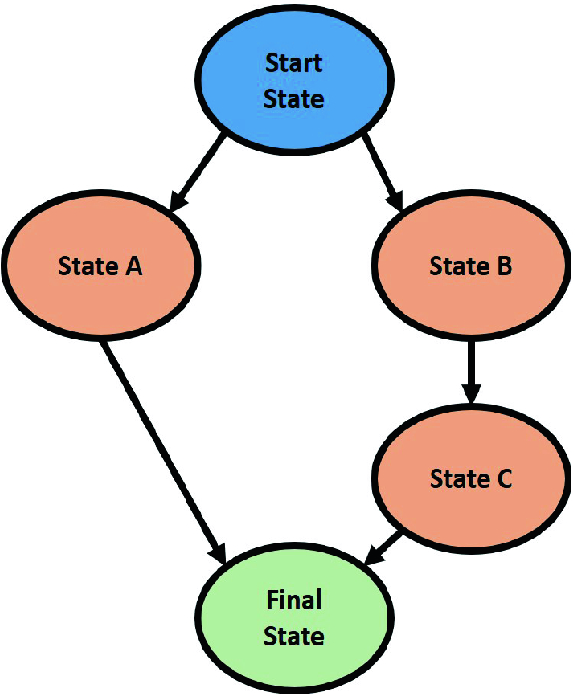
Example of a state machine directed graph
We simultaneously begin from one of the start states and keep track of visited states. When we reach one of the end states, we take all the states from our visited state data structure and store them as a path. We make sure that we do not end up in an infinite loop by marking the current state as visited state. To keep it simple, we can start with one of the shortest paths, if there is a tie, we break it randomly. In the chosen path, we select one of the packets that causes a transition and apply the mutation to that transition. Once we have fuzzed one particular path, we move on to the other paths. Thus, eventually covering all possible paths in the end.
3.2 Packet Representation
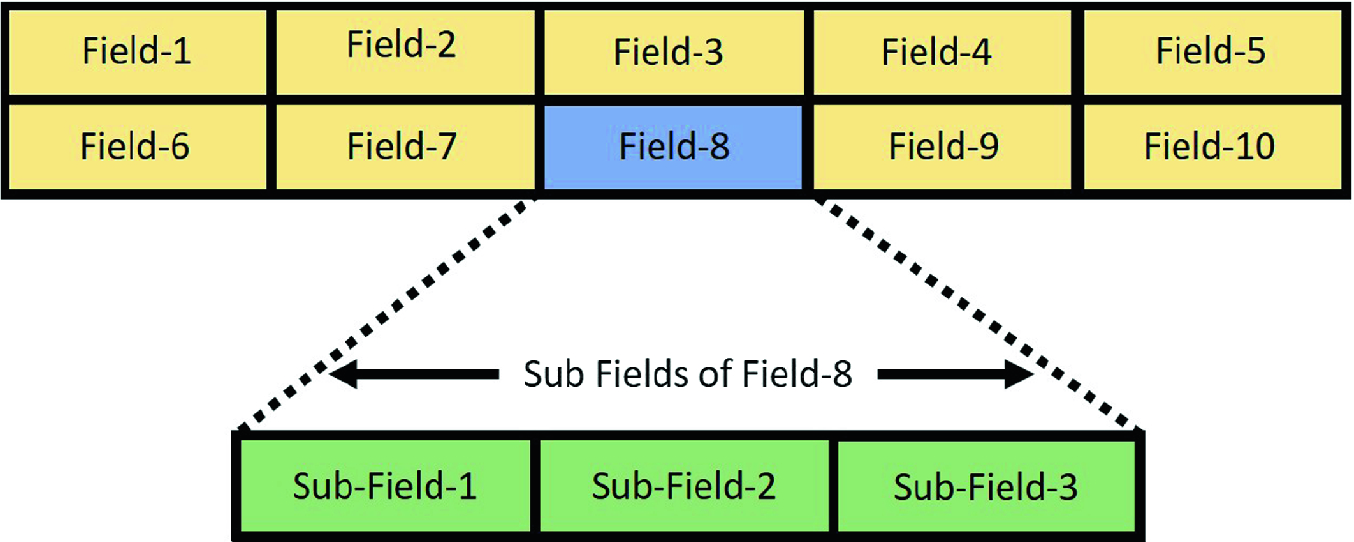
Protocol header
3.3 Mutation
The whole crux of SMuF is the mutation. Instead of just mutating traditionally, i.e., using standard mutation operators like bit-flipping, byte-flipping, etc., mutation is carried out based on location, context and time as a factor. We mutate terminals as well as non-terminals of the packet levels depending on the packet structure and the mutation operator we want to use. After we have generated mutated inputs, we use probability score to select the most uncommon inputs.
Mutation Based on Location. For mutation based on location, instead of blindly fuzzing all the fields of packet or packets of all the state, we mutate those fields and states which have a higher probability of either creating a vulnerability or creating a more diversified input. We can choose to apply different strategies to identify which field or state to mutate first. The strategies can be derived using manual analysis, static analysis, etc., based on previously recorded crashes/vulnerabilities or a combination, etc. One example of manual analysis is that we prohibit our fuzzer to mutate field of checksum in a packet as in almost all of the cases if the checksum is not right, the packet is going to get dropped.
Mutation Based on Context. For mutation based on the context, we identify a packet to be processed in one particular context or a field in the packet with a certain context attached to it. We then mutate the context based on the different contexts possible. We mutate two different packets which are to be processed in two different contexts say Packet1 in context A and Packet2 in context B. We then apply a simple crossover algorithm to generate a new packet which is an offspring of Packet1 and Packet2. This packet will have properties of Packet1 but the context of Packet2. We do this at the payload level for devices in which we can distinguish between different contexts. Such mutations help in identifying privacy bugs [31]. On the other hand, we take into consideration the acknowledgement exchanged between the sender and the receiver states to determine the context in which the fuzzing activity needs to be performed. The context here refers to swapping of payload context and authentication processes between each state of the protocol.
Mutation Based on Time. Mutation-based on time is done in two ways. One is by mutating time-related factors like the rate of sending packets. Second, is to mutate time-related/sensitive fields like time-to-live (TTL) in TCP or Leap indicator, precision in NTP and manipulate the packet accordingly. This would help in uncovering vulnerabilities caused due to insufficient rate-limiting protection, deadlocks or the ones that easily result in DoS [19, 21, 29].
3.4 Probability Score
Once we have generated different inputs based on different mutation strategies, we now will have to play those inputs to the target system. The fuzzing activity is a time-sensitive operation, i.e., one cannot send all the inputs at once to process. From the inputs we have generated, we have to send our most efficient inputs first in an ideal scenario. For this, we use the probability score of a packet which is nothing but a probability that the target has previously encountered the input for causing crash. We use a classifier to group packets based on certain properties and then decide the common and uncommon groups. We prefer to send those set of inputs which have a low probability score and a diverse structure. This makes our approach more efficient.
 be a subset of S having collection packets whose max length is i. Let P be one of the packets generated after mutation. Then the probability score of that packet P is:
be a subset of S having collection packets whose max length is i. Let P be one of the packets generated after mutation. Then the probability score of that packet P is:
4 Experimentation and Evaluation
In this section, we look at the experimental setup of our framework in a state-of-the-art IoT testbed [28] and evaluate the same.
4.1 Experimental Setup

IoT security testbed with IoT devices
We analyzed the network traffic to understand the communication of IP cameras throughout the experimentation time period. We were able to obtain information such as session identifiers, tokens, and values for several features. The IP cameras use TCP protocol for the streaming operation and HTTP protocol to communicate commands for feature changes. We analyzed each of the TCP packet responsible for a feature change.
We implemented fuzzing framework in Python. It makes use of Scapy [24] module to interact with the IoT devices. The fuzzing framework was set up on a workstation running Kali Linux (2017.1) [18]. We connected the workstation to the same access point as that of the other IoT devices.
4.2 Experimentation
Probability score
Size of the packets (in bytes) | Probability score |
|---|---|
Less than 10 | 0.2011 |
Between 10 to 60 | 0.047 |
Between 60 to 100 | 0.226 |
Between 100 to 300 | 0.1032 |
Between 300 to 500 | 0.3168 |
Between 500 to 1000 | 0.0785 |
Greather than 1000 | 0.0274 |
We collected the normal traffic from the IoT devices and used it to assign the probability score on the basis of payload length. Based on the size of the payloads, we were able to arrive at the probability score for the packets. The probability score for packets whose payload length is less than 10 bytes is 0.2011, greater than 10 but less than 60 bytes is 0.047 etc. Based on the count of packets of different size we gave the probability score as shown in Table 1.
We mutate based on few mutation factors which we have chosen for each field manually. We chose mutation factor to be 0 for checksum field, 0.8 for payload, 0.5 for ports and 0.4 for flags. We tried our experiment with different values but got the fastest result in this configuration. Instead of randomly mutating we mutate it based on location, context and time. We place a high priority on mutating fields like source/destination port and HTTP payload and low priority on fields like a checksum. For the time-based mutation, we mutated rate of packet sending based on TTL.
4.3 Results and Analysis
When we mutated based on location (payload data with feature change), we were able to force the IoT device to start rejecting packets eventually due to TCP buffer being full. As a result, we were able to carry out TCP buffer overflow on most of the IoT devices.
With regard to context, we chose to take over the session with the help of session IDs. After analyzing the network traffic, we fuzzed the payload of the feature change packets with session IDs that previously existed. We were able to change the video streaming rates and the modes of the IP cameras based on the previous session IDs. We were able to perform session hijacking as a result of fuzzing of payload. Also, we were able to bypass the authentication process by fuzzing the IP Cameras such as TP-Link and D-Link during the handshake. We analyzed the tokens captured during the network traffic analysis stage and then used the same to subsequently bypass BLE Fitbit authentication.
In regard to mutation by time, we first noticed that when the TTL field was considered for fuzzing, IoT devices experienced DoS. When feature change packets were used to fuzz IoT devices with valid TTL values (Integer Fuzzing - Only integer values were considered for TTL field), the IoT devices accepted the packets and changed the features. The packets contained toggling features such as day/night mode, audio streaming set to True/False, etc., for IP cameras. Since the features were toggled, the IP cameras after a while, stopped toggling the features even though we were sending valid packets from the fuzzing framework, local web server, and the Android applications. This resulted in DoS on IP cameras. Next, we were able to perform DoS for the video and audio streaming for the camera by sending just one packet. When we fuzzed the port numbers of the HTTP packet through our framework, the cameras went down. The cameras were inaccessible via the android applications and the local web servers.
We found various vulnerabilities such as Buffer Overflow, DoS, Session Hijacking, By-pass authentication, etc., across the IoT devices through our fuzzing framework.
5 Related Work
Skyfire [17] is a seed generation technique for a fuzzer that leverages the power of the probabilistic context-sensitive grammar (PCSG). Its design is for programs whose inputs are highly structured files which are guarded by syntax and semantic rules. The end goal is to generate good, diverse, uncommon and valid seeds that a fuzzer can start with. Thus, can easily be used with other fuzzing tools. The output of Skyfire will be the input of a fuzzer. Skyfire lacks to work on IoT and also does not cover various states based on location, context and time. Shastry et al. [4] have proposed fuzzing using an input dictionary to help with the mutation. Their method is applicable only if you have the source code available and not tailored for IoT. Veggalam et al. [27] proposed a fuzzing framework for interpreters using a genetic algorithm. This method is limited only to interpreters and depends on the quality of test samples provided and lacks to work on IoT.
Ruiter et al. [14] describe a state machine learning technique to extract the state machines from protocol implementations of TLS and then doing a manual analysis to look for vulnerabilities. Lahmadi et al. [1] method is rule-based, and its accuracy depends on how good a scenario-based model can be created. This can be quite challenging for some of the protocols.
Peach [20] is one of the most widely used commercial fuzzer which can work as a generation based as well as mutation based fuzzer. Sulley [2] is open source block based fuzzer. It takes all the values which are in the form of blocks that are often used for stateful network protocol fuzzing. Radamsa [16] is a mutation based fuzzer which contains multiple mutation algorithms. However, all the above-mentioned work still lacks to cover the large search space of the target IoT.
6 Conclusion and Future Work
We have introduced a mutation-based fuzzing framework called SMuF which incorporates various modules such as protocol identifier, protocol state machine, packet generator, mutation, and probability score. SMuF incorporates not only works with all the current fuzzing operators but also introduced three more strategies to mutate: mutation based on location, mutation based on context and mutation based on time. We implemented and evaluated our framework in our IoT security testbed. We have discovered various known vulnerabilities such as DoS, Buffer Overflow, Session Hijacking, etc. In future, we will expand the framework with more modules that can evaluate various IoT devices and discover large scale known and unknown vulnerabilities.
Acknowledgments
The first author’s work was done during his internship in SUTD supported by the SUTD start-up research grant SRG-ISTD-2017-124.