Rule-Based Systems: From Direct to Interlingual Approaches
Different approaches and different techniques have been used for machine translation. For example, translation can be direct, from one language to the other (i.e., with no intermediate representation), or indirect, when a system first tries to determine a more abstract representation of the content to be translated. This intermediate representation can also be language independent so as to make it possible to directly translate one source text into different target languages.
Translation can be direct, from one language to the other (i.e., with no intermediate representation), or indirect, when a system first tries to determine a more abstract representation of the content to be translated.
Each system is unique and implements a more or less original approach to the problem. However, for the sake of clarity and simplicity, the different approaches can be grouped into three different categories, as most textbooks on the topic do.
- A direct translation system is a system that tries to produce a translation directly from a source language to a target language with no intermediate representation. These systems are generally dictionary-based: a dictionary provides a word-for-word translation, and then more or less sophisticated rules try to re-order the target words so as to get a word order as close as possible to what is required by the target language. There is no syntactic analysis in this kind of system, and reordering rules apply directly to surface forms.
- Transfer systems are more complex than direct translation systems, since they integrate some kind of syntactic analysis. The translation process is then able to exploit the structure of the source sentence provided by the syntactic analysis component, avoiding the word-for-word limitation of direct translation. The result is thus supposed to be more idiomatic than with direct translation, as long as the syntactic component provides accurate information on the source and on the target language.
- The most ambitious systems are based on an interlingua, which is a more or less formal representation of the content to be translated. Extensive research has been done on the notion of interlingua. Fundamental questions immediately arose such as: how deep and precise should an interlingua be so as to provide a sound representation of the sentence to be translated? Instead of developing a completely artificial language, which is known to be a very complex task, English is often used as an interlingua, but this is in fact quite misleading, since the representation is then neither formal nor language-independent. It is thus better to speak of a “pivot language,” or simply a “pivot,” when the interlingua is a specific natural language (English, in most cases, as we have just seen, but Esperanto and other languages have also been used in the past). In this context, when translating from language A to language B, the system first tries to transfer the content of A to the pivot language before translating from the pivot to the target language B.
These three kinds of approaches can be considered to form a continuum, going from a strategy that is very close to the surface of the text (a word-for-word translation) up to systems trying to develop a fully artificial and abstract representation independent of any language. These varying strategies have been summarized in a very striking figure called the “Vauquois triangle,” from the name of a famous French researcher in machine translation in the 1960s (figure 2).
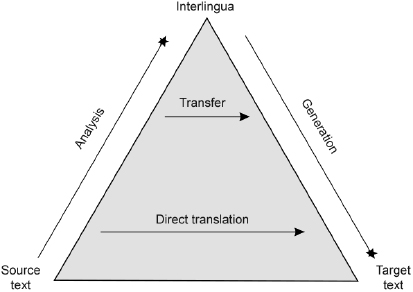
Figure 2 Vauquois’ triangle (image licensed under CC BY-SA 3.0, via WikiMedia Commons). Source: https://en.wikipedia.org/wiki/File:Direct_translation_and_transfer_translation_pyramind.svg.
{kind=link}
Direct transfer, represented at the bottom of the triangle, corresponds to word-for-word translation. In this framework, there is no need to analyze the source text and, in the simplest case, a simple bilingual dictionary is enough. Of course, this strategy does not work very well, since every language has its own specificities and everybody knows that word-for-word translation is a bad strategy that should be avoided. It can nevertheless give some rough information on the content of a text and may seem acceptable when the two languages considered are very close (same language family, similar syntax, etc.).
Researchers have from the very beginning also tried to develop more sophisticated strategies to take into account the structure of the languages at stake. The notion of “transfer rules” appeared in the 1950s: to go from a source language to a target language, one needs to have information on how to translate groups of words that form a linguistic unit (an idiom or even a phrase). The structure of sentences is too variable to be taken into account directly as a whole, but sentences can be split into fragments (or chunks) that can be translated using specific rules. For example, adjectives in French are usually placed after the noun, whereas they are before the noun in English. This can be specified using transfer rules. More complex rules can apply to structures like “je veux qu’il vienne” ⇔ “I want him to come,” where there is no exact word-for-word correspondence between the two sentences (“I want that he comes” is not very good English, and “je veux lui de venir” is simply ungrammatical in French).
The notion of transfer can also be applied to the semantic level in order to choose the right meaning of a word depending on the context (for example, to know whether a given occurrence of “bank” refers to the bank of a river or to a money-lending institution). In practice, this is a hard problem if done manually, since it is impossible to predict all the contexts of use of a given word. For exactly the same reason, this quickly proved to be one of the most difficult problems to solve during the early days of machine translation. We will see in the following chapters that, more recently, statistical techniques have produced much more satisfactory results, since the problem can be accurately approached by the observation of very large quantities of data—the kind of thing computers are very good at, and humans less so (at least when they try to provide an explicit and formal model of the problem).
Last but not least, another family of systems is based on the notion of interlingua, as we have already seen in the previous section. Transfer rules, by definition, always concern two different languages (i.e., English to French in our examples so far) and thus need to be adapted for each new couple of languages considered. The notion of interlingua is supposed to solve this problem by providing a language-independent level of representation. Compared to transfer systems, the interlingual approach still needs one analysis component to go from the source text to the interlingual representation, but then this representation can give birth to translations into several languages directly. The production of a target text from the interlingual representation format, however, requires what is called a “generation module”—in other words, a module able to go from a more or less abstract representation in the interlingual format to linguistically valid sentences in the different target languages.
Interlingual systems are very ambitious, since they need both a complete understanding of the sentence to be translated and accurate generation components to produce linguistically valid sentences in the different target languages. Moreover, we saw in the previous chapter that understanding text is to a great extent an abstract notion: what does it mean to “understand”? What information is required so as to be able to translate? To what extent is it possible to formalize the comprehension process given the current state of the art in the domain? As a result, and despite several years of research by several very active groups, interlingual systems have never been deployed on a very large scale. The issues are too complex: understanding a text may potentially mean representing an infinity of expressed and inferred information, which is of course highly challenging and simply goes beyond the current state of the art.