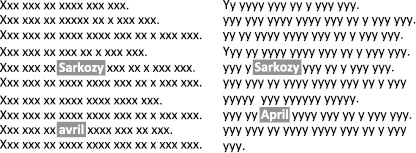The 1980s saw an increase in the number of available electronic texts—texts directly accessible by computers. Among these texts, some were translations of each other and could therefore be “aligned,” or matched at paragraph or sentence level. These aligned texts have always been an invaluable source of knowledge for human translators. It soon became clear, however, that automatic tools could also benefit from these new data. In fact, this increasingly large amount of data revived the field and, most importantly, completely revolutionized the approach used for machine translation.
The Notion of Parallel Corpora or Bi-texts
A parallel corpus is a corpus composed of a set of pairs of texts in a translation context. An aligned parallel pair of texts is called a bi-text, from bilingual text, while a multi-text includes multiple aligned translations.
This type of resource is popular among professional human translators. It is actually an extremely valuable source of knowledge: more than a bilingual dictionary, previous translations can provide examples of relevant translations according to the context. In the case of technical translation, the translator must generally use the terminology, the phraseology, and the style of previous translations for reasons of uniformity. It is therefore essential to have access to past translations. It is also important to know in which direction the translation was carried out (i.e., the source language) since the source is by definition the reference text.
Human translators thus generally have access to past translations through a tool called a “translation memory.” A translation memory module makes it possible to store and retrieve fragments of translation from past work, generally through a powerful search engine. Past translations can be analyzed and tagged before being stored, which makes it possible to query the translation memory powerfully, rather than with basic keywords. There are several tools like this available on the market, primarily for professional translators.
Bi-texts were perceived very early on as an important source of knowledge for machine translation. Translation memories contain relevant translation fragments, since these tools store professional past translations. Beyond that, more and more bilingual texts are available on the Internet, so one can imagine the development of systems based uniquely on bilingual data from the Internet. Today, this is in fact the dominant approach in the field of machine translation.
Two types of approaches can be distinguished. On the one hand, the analysis of existing translations and their generalization according to various linguistic strategies can be used as a reservoir of knowledge for future translations. This is known as example-based translation, because in this approach previous translations are considered examples for new translations. On the other hand, with the increasing amount of translations available on the Internet, it is now possible to directly design statistical models for machine translation. This approach, known as statistical machine translation, is the most popular today.
Unlike a translation memory, which can be relatively small, automatic processing presumes the availability of an enormous amount of data. Robert Mercer, one of the pioneers of statistical translation,1 proclaimed: “There is no data like more data.” In other words, for Mercer as well as followers of the statistical approach, the best strategy for developing a system consists in accumulating as much data as possible. These data must be representative and diversified, but as these are qualitative criteria that are difficult to evaluate, it is the quantitative criterion that continues to prevail. In fact, it has been proven that the systems’ performance regularly improves as more bi-texts are available to develop it.
“There is no data like more data.” [Robert Mercer]
Availability of Parallel Corpora
There are two major sources of bi-texts: on the one hand, corpora already available for two or more languages; the bi-texts may be aligned or not. On the other hand, for pairs of languages without adequate corpora, techniques have been developed to automatically develop such corpora, generally by collecting texts available on the web.
Existing Corpora
There are well-known sources of parallel texts. For example, the majority of countries and institutions that have several official languages have to produce official texts (legislative texts for example) in each of these different languages. This is generally a source of very valuable bilingual corpora, since the translation must be an accurate copy of the original. But since these texts are for the most part associated with legislative and legal fields, machine translation systems based on these data may not be very accurate for other domains or other genres.
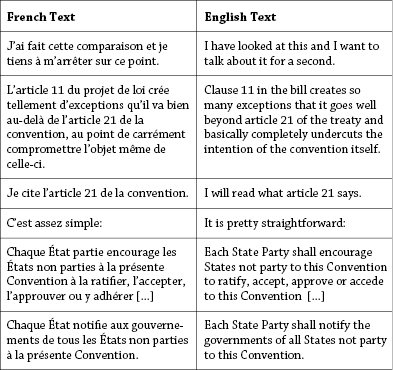
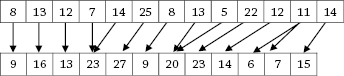
The first experiments regarding the alignment of texts, in the 1980s, drew heavily on the Canadian Hansard, which records the official transcripts of Canadian parliamentary debates. The Canadian Hansard is aligned at text level and also at sentence level, which means that this corpus is an invaluable source of knowledge when translating between French and English (see figure 3).
Figure 3 An extract from the Hansard corpus aligned at sentence level.
Other corpora of the same type are available today, particularly corpora made of texts produced by European institutions. The European context is by nature highly multilingual and has already produced several invaluable resources, such as the Europarl corpus and the JRC-Acquis corpus. Both of these corpora include more than 20 languages from Europe. These corpora have been intensively used by machine translation systems and are easy to use since they are in fact already aligned at text and paragraph level, as well as occasionally at sentence level. They consist of several tens of millions of words for each language, but the size varies a great deal according to the language or the pair of languages in consideration (for example, Europarl contains 11 million words for Estonian, 33 million for Finnish, and 54 million words for both English and French).
Many other corpora exist, especially for other families of languages, although it is generally the “strongest” languages (meaning the most widely represented on the Internet) that are the most popular. However, these corpora are not always sufficient: most languages have very few or even no resources at all to develop a system. In this context, it is necessary to develop new corpora, and this is usually done on the web.
Automatic Creation of Parallel Corpora
Researchers early on sought to exploit the mass of texts available on the Internet to complete existing resources. The web is actually far more diverse than existing available parallel corpora, which are related to the legal domain for the most part, as already mentioned. The techniques for “harvesting” high-quality bilingual texts on the web are relatively simple. A harvesting system generally includes a “robot”—that is, a system capable of browsing the web by bouncing from page to page, while following the links mentioned on each webpage. Then, for each webpage, the system checks the language used and if an equivalent page in the target language exists.
The system begins with the rarer language of the two. For example, if the aim is to develop a bilingual corpus between Greek and English, it seems more appropriate to begin with websites written in Greek, which are fewer in number than websites in English. It should also be noted that few pages in English have a corresponding page in Greek, whereas the opposite situation is more likely; for example, websites of English universities rarely have a translation in Greek, whereas websites of Greek universities often have a translation in English.
For each website or page, two tricks can be used: first, the system searches for an equivalent at the website address (URL) level. For example, if one site corresponds with the URL http://my.website.com/gr/, the system will look for an equivalent such as http://my.website.com/en/—that is, a “mirror site” in the target language, identified by its URL. If this first strategy does not work, the system can search each webpage for a link toward the page in the target language, since multilingual sites often make it possible to navigate from one language to the other (these links are often identifiable through small icons featuring the country symbol of the target language). Once two websites have been identified as being translations of each other, the system has to control correspondences at the level of individual webpages. Several tools can be applied to check the language of the identified webpages if this was not previously done. Then, one can compare, for example, the length of the documents (if two documents or two texts are of very different sizes, they are probably not a reliable translation), the HTML structure (the two files must share the same structure), and so on.
These techniques have little to do with linguistics, but, when applied at web scale, they can allow for the extremely rapid development of large corpora in numerous languages from scratch. If the content of the selected webpages is closely monitored (for example, by starting with a list of specific URLs and then retrieving only those webpages that contain specific keywords), it is furthermore possible to obtain specialized corpora for different domains at a lower cost. Nonetheless, one must keep in mind that the process is entirely automatic: it does not guarantee the representativeness of the data nor the quality of the identified sources. In fact, nothing guarantees the quality of the bi-texts obtained in such a way. However, quantity goes together with quality: a given website may propose poor translations, but the consequences will be limited, since one can expect that a multitude of other websites will propose “good” translations, which means that bad translations will be statistically negligible and have no influence in the end. For the same reasons, a literary translation that is unique and original will also be discarded because it will not be statistically significant among all the other translation possibilities. This is not really a problem for machine translation, which looks for standard equivalents and does not attempt to produce originality.
Still, the limitations of this approach must be noted. Not all languages are well represented on the Internet, and this is especially true when searching for bilingual texts. In practice, in the majority of existing corpora, one of the languages is English, increasing the influence of this language. Despite the amount of available data, it is difficult to harvest enough data to develop a quality bilingual corpus, if one of the languages (target or source) is not English. I will return to this subject later in chapter 11.
Once the corpus has been built, it is necessary to align it at paragraph or sentence level, or both, for it to be usable by machine translation systems.
Sentence Alignment
In nearly all languages, a sentence is a linguistic unit that is syntactically and semantically autonomous (as opposed to a phrase or any other nonautonomous group of words). Consequently, natural language processing is often based on the notion of the sentence—particularly machine translation, which operates generally sentence by sentence, each being considered independently from the others.
Sentence alignment flourished toward the end of the 1980s and in the 1990s, during a time when more and more corpora were becoming available. Several kinds of applications using this type of resource were also beginning to appear: machine translation, of course, but also other multilingual applications, for example multilingual terminology extraction.
Sentence alignment is generally based on specific features of bi-texts: it is assumed that the translation generally follows the structure of the original text and that the sentences are usually chained in the same way in the source text and the target text. Furthermore, one can define a length ratio between two pairs of languages (for example, in terms of number of words, a French text is generally 1.2 times longer than the corresponding English text). The relative length of the sentences was the first criterion explored for sentence alignment. The first experiments in the domain of sentence alignment were made on the transcripts of the Canadian Parliament, since this corpus is of extremely good quality and the translation is very close to the original texts, contrary to what is usually found on the Internet.
Alignment Based on Relative Length of Sentences
A simple strategy for sentence alignment is to observe, first, that the sentences of a text vary in length, and second, that there is usually a good correlation between sentence length of the source text and sentence length of the target text. One can try to align the sentences on this basis; that is, by observing the relative length difference in the source text and looking for similar patterns in the target language. In order to avoid spreading alignment errors (i.e., a mistake in a given place that spreads to the rest of the text), it is therefore necessary to proceed somewhat globally, not just sentence by sentence. One way to solve the problem is to find specific patterns in the source language and observe whether the same patterns can be found in the target language. This way, it is possible to find “islands of confidence,” or relatively reliable configurations distributed throughout the text.
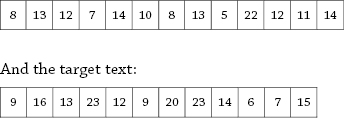
Let’s imagine a text composed of a given number of sentences and its translation. In the figure below, each cell is a sentence, and the number in each cell refers to the number of words in the sentence. Below is the source text:
Figure 4 Two texts of different length. Each cell with a number n corresponds to a sentence of length n.
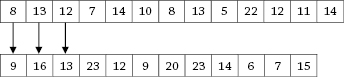
We can see that the two texts do not have exactly the same number of sentences. The first three sentences have a relatively similar number of words and can therefore be linked together (note that the target language seems to systematically use a slightly larger number of words per sentence than the source language).
Figure 5 Beginning of alignment based on sentence length.
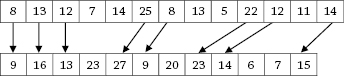
The same applies for the end of the text and some specific patterns in the text (for example, two consecutive sentences whose lengths are very different).
Figure 6 Other possible simple alignments.
Finally, the system tries to “bridge the gaps” by establishing links between the source and the target text, so as to obtain a fully connected bi-text in the end (each sentence in the source language must be linked to one or sometime two sentences in the target language). In the end, the system may have to proceed to “asymmetric alignments”; that is, connecting one sentence in the source text with more than one sentence in the target text.
Figure 7 Alignment of remaining sentences.
Our example is clearly simplified. There are many ways of accomplishing a dynamic alignment: for example, by identifying the shortest and longest sentences or the difference in length between adjacent sentences; by calculating the length of groups of sentences in the first place; and so on.
Gale and Church (1993) applied this type of algorithm to the Hansard corpus (Canadian Parliament texts), obtaining an error rate of about 4% (i.e., 4% of the sentences were wrongly aligned). They show that this rate can even be lowered to less than 1% if only one-to-one mappings between sentences are taken into account (i.e., if we keep only single sentences in the source text that correspond to single sentences in the target text, which means that asymmetric alignments lead to more errors). They also show that the 1–1 relation corresponds to more than 89% of the sentences in the source text, about 9% correspond to 1–2 or 2–1 relations (i.e., one sentence in the source text is connected to exactly two sentences in the target language, or vice versa), and the other cases (i.e., a sentence that is not translated, or one sentence translated by three or more sentences) are very marginal.
The great advantage of this approach is its simplicity and its relative robustness. It has been proven that the method works well for different pairs of languages: the method is actually transferable and completely independent from the languages considered. It can even be applied to nonalphabetical languages with syllabic or ideographic writing, such as Asian languages. This robustness must nevertheless be qualified, since performance will worsen if the translation is not as reliable as in the case of the Canadian Parliament transcripts, which is an exceptionally good corpus from this point of view. The method can also suffer from discrepancies (one misalignment leading to other misalignments, creating a cascading effect), even if the dynamic approach described above is meant to respond to this problem.
Different strategies have been devised to limit the problems of cascading misalignments. One way consists in trying to first find homogeneous text portions made of several sentences. Paragraphs are the most obvious units between the text and the sentence level, and paragraphs have been used with some success to complete the task. Additionally, most texts now come from the web, which means they contain HTML or other explicit tags that can be used for text alignment, since the target text may have the same structure as the source text. Finally, it is also possible to locate similar words in the original text and in the translation. This helps in finding what are called correspondence points. This approach is said to be lexical, since it is based on the analysis of a part of the lexicon.
Lexical Approach
Several studies have proposed strategies to align sentences based on lexical correspondences. This strategy is less generic than those described so far, but it is relatively efficient, especially between linguistically related languages.
If one considers a given bi-text (i.e., a pair of texts such that one is a translation of the other), one can often observe similar or nearly similar strings referring, for example, to person names, locations, and more generally proper nouns. These lexical correspondences are generally called cognates. Other elements can play a similar role, especially numbers, acronyms, and so on. Typography can also be helpful to identify related words, for example in bold and italics.
Figure 8 Two texts in a translation situation. Although the content of the texts is unknown (here represented by “xxx” and “yyy”), some words are identical or similar and can help determine reliable correspondence points.
All of these elements can be used to identify correspondence points between the source and the target texts. Sentence alignment is then calculated by resorting to dynamic programming, in a manner similar to what is done for alignment based on sentence length. Pairs of sentences with several correspondence points are most probably translations of each other. The process is applied iteratively until there is nothing left to align.
Mixed Approaches
It is, of course, possible to combine the two approaches in order to define a system based on both lexical indices and sentence length. On the one hand, cognates are rarely sufficient for aligning two texts. On the other hand, sentence length is generally a good feature for alignment, but it can happen that several consecutive sentences have a similar length. The idea is to find as many cues as possible between sentences to reinforce confidence in different local alignments.
Sentence alignment was a particularly active research topic in the 1990s. Researchers explored various cues, especially the structure of HTML documents, as seen above. The presence of titles, frames, and icons were used as features for the task. As a result of this research effort, the number of available bilingual corpora exploded in the 1990s. These new resources cleared the path for example-based translation and then for statistical translation, which is now the dominant paradigm in the field. The following chapters will discuss how these resources have been exploited in order to produce more robust and more reliable translation systems than those developed previously.