Example-based translation, or translation by analogy, was introduced in the 1980s in Japan by Makoto Nagao (1984). Nagao noticed that traditional rule-based systems—still the common approach during the 1980s—tended to become more and more complex over time. As a result, they were progressively more difficult to maintain, which was of course a major problem. These systems generally also require a complete analysis of the sentence to be translated, which makes them extremely weak: if just one part of a given sentence cannot be analyzed, no translation will be provided for the whole sentence. Conversely, Nagao observed that professional human translators mainly work with fragments of text that they translate and recombine to form complete and coherent sentences. Translators generally do not carry out a complete preliminary analysis of the sentence to be translated, he argued.
At the same time, Nagao noticed that parallel corpora contain a great deal of valuable information that is for the most part lacking in bilingual dictionaries, even professional ones. Thus, he suggested, rather than trying to develop new dictionaries and new analyses or transfer rules between the languages at hand, it would be more convenient to directly use fragments of translation that one can find in existing bilingual corpora.
Rather than trying to develop new dictionaries and new analysis or transfer rules between the languages at hand, it would be more convenient to directly use fragments of translation that one can find in existing bilingual corpora.
An Overview of Example-Based Machine Translation
Example-based machine translation typically operates in three stages to translate a given sentence:
The system tries to find fragments of the sentence to be translated in the corpora available for the source language. All the relevant fragments are collected and stored.
The system then looks for translational equivalences in the target language, thanks to the bi-texts used for translation.
The system finally tries to combine the translation fragments to obtain a correct sentence in the target language.
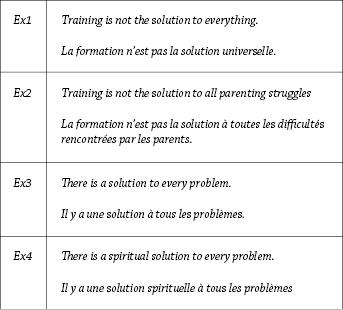
A simple example will illustrate this approach. Let’s imagine that we ask the system to translate “Training is not the solution to every problem” into French and that a bilingual corpus is available with, among others, the following pairs of sentences (figure 9).
Figure 9 Automatically extracted sentences from a bilingual corpus in order to translate the sentence “training is not the solution to every problem.” Each sentence in English contains a sequence of n similar words with the sentence to be translated.
The system tries to find translational equivalents in the target language. For example, “training is not the solution” can be found in Ex1 and Ex2. In both cases the translation includes “la formation n’est pas la solution”: the system can infer that it is a translation of the English sequence, since this expression is shared by the two sentences in the target language. Likewise, from Ex3 and Ex4, the system can infer that “to every problem” can be translated into French as “à tous les problèmes.” By combining these two identified sequences of words, the system produces the translation “la formation n’est pas la solution à tous les problèmes.”
As one might imagine, this is a very simplified example, one where the sentence in the source language directly corresponds to long existing sequences of words in the target language. In practice, the problem is obviously more complicated.
The Search for Translation Examples
Since it is very rare to find exact matches at sentence level between the text to be translated and the available bilingual corpus, it is necessary to find equivalences (called examples in this approach) at the infra-sentential level, as seen in the previous example. But even at the infra-sentential level, searching for translational equivalences is a complex problem: (i) the identified “examples” (sequences of exactly matching words) are often very short; (ii) for the same sequence in the source languages, different translations can often be found, and it is not obvious how to choose the most relevant one; and (iii) merging different fragments of text is difficult, since fragments often overlap or are not fully compatible with each other. Thus, rather than just looking for exact equivalences at word level (or character level), it is useful to try to find equivalences on a more general basis in order to make the approach more robust. This is often referred to as translation by analogy: it no longer involves finding fragments of texts that reproduce the exact sentence to be translated, but rather fragments of texts bearing an analogy with the sentence to translate.
Several techniques have been proposed to find analogies, translational equivalents, or “examples” on a more or less linguistic basis:
comparison of strings of characters,
comparison of words,
comparison of sequences of linguistic tags (i.e., noun, verb, etc.),
comparison of linguistic structures.
The first approach, comparison of strings of characters, has the advantage of being independent of the languages considered and can, for example, also be applied to Asian languages (the fact that a word can often be a single character in Asian languages is not a problem for this approach). The second strategy, comparison of words, is well suited for languages with good lemmatizers (i.e., tools able to recognize words as they appear in a dictionary), but this is not the case for all languages. Moreover, as already said, these approaches are too close to the surface of the text. There are too many sources of variation in a language to make these techniques really powerful.
More advanced techniques rely on a stage of text preprocessing to enrich available bilingual corpora with higher-level information. In practice, linguistic tags are added to words in order to make it possible for the system to have a more abstract representation of the data. The preprocessing stage generally includes part-of-speech tagging (recognizing adjectives, nouns, verbs, etc.), and sometimes a shallow semantic analysis (recognizing dates, proper nouns, idioms, etc.). Transfer rules mapping linguistic sequences between the source language and the target language must then take into account this new information. For example, if adjectives have been described as optional, “there is a spiritual solution” can be used to translate “il y a une solution,” even if the French fragment does not include any word related to “spiritual.” Of course, when linguistic equivalences are not perfect, the translation may possibly be quite different from the original text.
Lastly, the recognition of specific syntactic structures would make it possible to proceed through a direct comparison of syntactic trees (i.e., a representation of the structure of the sentence). In theory, this strategy makes it possible to compare sentences that look very different at surface level (i.e., if one just looks at sequences of words). For example, the two sentences “he gave Mary a book” and “he gave this book to Mary” have the same syntactic structure, although a system that looks only at sequences of words would find merely similar fragments (“he gave” and a few isolated words).
Once the relevant fragments in the target language have been collected, a series of rules or statistical indices are applied to try to recompose a complete sentence from the identified fragments. This is a difficult task because these fragments are usually partial and incomplete, and they overlap and do not correspond to autonomous syntactic phrases. Some research groups tried to develop systems using only relevant syntactic phrases (complete noun phrases or verb phrases, for example) but this does not result in any improvement for different reasons, mainly data sparsity (it is very difficult to collect enough relevant examples at phrase level).
Appeal and Limitations of Example-Based Machine Translation
Example-based machine translation generated great interest during the 1980s. Rather than developing a machine translation system manually, which is long and very costly, the example-based approach allowed for optimal exploitation of large quantities of bilingual texts that were beginning to be available at the time. It is clearly not a coincidence if this approach emerged at the same time as the first work on bilingual text alignment.
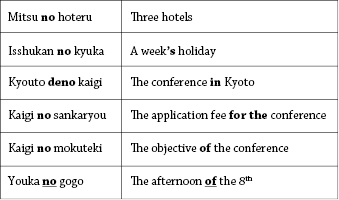
The approach was mainly explored for Asian languages that do not show the same similarity as, for example, French-English pairs. Hence, the Japanese structure Noun1 no Noun2 (Noun1 の Noun2) is often cited as an example, because the particle “no” (corresponding to the Japanese character の) can represent various types of links between two nouns. Here are some examples frequently cited in the literature and taken from an article from 1991 (Sumita and Iida, 1991):
Figure 10 Different examples with the Japanese particle “no.” One can see that the particle requires the use of a different linguistic structure each time when translating into English, depending on the context (see Sumita and Iida, 1991).
It is clear from figure 10 that “no” can express a wide variety of possible relations between the two nouns: it can be a kind of genitive, but it can also express indications of goal, time, or location. The authors demonstrate that it is hardly possible to formalize this by rules, since it would require the system to have access to semantic information. The example-based approach seems to be more appropriate, as long as the examples provide a good coverage of the text to be translated.
The limits of this approach are clear: by default, if no translational fragment is found from the set of examples, the system will either fail or produce a word-for-word translation. This approach was essentially explored for genetically distant languages (typically Japanese-English) for which it seemed difficult to develop manual transfer rules. Rather than describing specific contexts manually, the proponents of the example-based approach observed that an ambiguous pattern can be disambiguated with a proper look at semantic classes and explicit markers in the translational equivalences.1 For example, in the case of the Japanese particle “no,” it is possible to find equivalences with the English genitive marked by “’s” and with sequences introduced by specific prepositions (“for,” “in,” “of,” etc.). Each of these elements (“no” on one hand, and genitive markers or prepositions on the other hand) is considered as a “marker.”
The approach was also used for specific domains using a particular sub-language with a limited vocabulary and a very specific and highly regular terminology and phraseology. This is, for example, the case of computer documentation, which is one of the main fields where example-based translation has been tested with some success (Somers, 1999; Gough and Way, 2004). In such contexts, sentences are regular and the same expressions are often used, which means that the example-based approach can obtain an acceptable coverage of the text to be translated. The main problem remained, however, extending the coverage, which is always partial, even for the most regular texts. The consequence is that example-based translation is interesting but can hardly be used alone in practical contexts.
Example-based translation has therefore sometimes been used as a module within a more complex system. Mixing the example-based approach with a statistical analysis of very large corpora has proven to lead to very interesting results, since statistical approaches are known to have good recall and can in turn benefit from the precision of the example-based paradigm.