5.1 Dynamic Behaviour onto Real Time
Real-time strategies convert the idea of bounded response systems into a dynamic operation, considering the certainty onto time response. To achieve such a goal, the use of scheduling algorithms is preferable. A real-time system is where the interaction amongst elements are with a certainty of time response as global and local through the processing elements. The most common algorithms for real-time are the schedulers, like Earliest Deadline First or Priority Exchange, that manage those tasks in preemptive mode [1].
In particular, one of the most important properties of hard real-time systems is predictability [2]. This means that, based on features of the kernel and the information associated with each task, the system is able to predict the evolution of its tasks and to successively guarantee that all time restrictions are accomplished. However, this is possible only occasionally, due to the high degree of non-determinism of the distributed systems. Several factors introduce scheduling uncertainties, such as the features of the processor and the kernel, the applied scheduling algorithms, the synchronisation mechanisms, the memory management, the communications, the interruption management mechanisms, among others [3].
Distributed systems whose functionality is restricted to accomplishing time deadlines are known as Real-time distributed systems (RTDS), as reviewed in the previous section. These constitute the object study of the present book. Due to the increasing complexity of the interaction of the elements of a RTDS, it is necessary to carry out a more detailed analysis of all real-time aspects that influence the activities of the system.
A real-time application is featured by a set  of activities, known as tasks, associated with certain time restrictions that have to be accomplished to achieve a wanted behaviour. It is frequent that the n tasks in real-time
of activities, known as tasks, associated with certain time restrictions that have to be accomplished to achieve a wanted behaviour. It is frequent that the n tasks in real-time  execute after some time. From this, a task is understood as a sequence of identical activations
execute after some time. From this, a task is understood as a sequence of identical activations  , separated between each other by a time-lapse [3].
, separated between each other by a time-lapse [3].
- 1.
Arrival time (
 ) is the time in which a task is set for execution. It is also referred as release time.
) is the time in which a task is set for execution. It is also referred as release time. - 2.
Consumption time (
 ) is the time that takes to each task to execute its assigned activities without interruption. If it is a hard real-time system, it is considered as the Worst-Case Execution Time (WCET).
) is the time that takes to each task to execute its assigned activities without interruption. If it is a hard real-time system, it is considered as the Worst-Case Execution Time (WCET). - 3.
Delivery deadline (
 ) is the limit time in which a task should have finished. If the task is over before or at such an instant, the task is schedulable. If All tasks finish before all their delivery deadlines, the system is schedulable.
) is the limit time in which a task should have finished. If the task is over before or at such an instant, the task is schedulable. If All tasks finish before all their delivery deadlines, the system is schedulable. - 4.
Start time (
 ) is the time in which a task starts its execution.
) is the time in which a task starts its execution. - 5.
Finishing time (
 ) is the time in which a task finishes. It is also known as the response time. A task is schedulable if
) is the time in which a task finishes. It is also known as the response time. A task is schedulable if  .
. - 6.
Shifting (
 ). Occasionally, a task may have a lag or shift since it does not necessarily start exactly at its initial time. Commonly, the start time of the first periodic instance is also known as shift.
). Occasionally, a task may have a lag or shift since it does not necessarily start exactly at its initial time. Commonly, the start time of the first periodic instance is also known as shift.
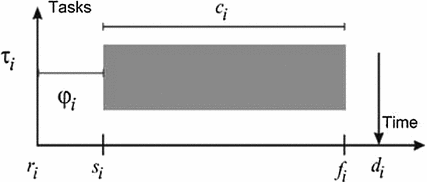
Time parameters of a common task
- 1.
Criticality is a parameter related to the consequences of not accomplishing a deadline.
- 2.
Value (
 ) represents the relative importance of a task regarding other tasks. It is not shown in the Fig. 5.1
) represents the relative importance of a task regarding other tasks. It is not shown in the Fig. 5.1 - 3.
Delay (
 ) represents the time delay of a task for achieving its objective regarding its deadline
) represents the time delay of a task for achieving its objective regarding its deadline  .
. - 4.
Laxitude (
 ) is the maximum time that a task may delay its activation to achieve its deadline.
) is the maximum time that a task may delay its activation to achieve its deadline.
If all tasks have a shift equal to zero ( ,
,  ), this is, all tasks start at the release time, the system is known to be synchronous; otherwise, the system is asynchronous.
), this is, all tasks start at the release time, the system is known to be synchronous; otherwise, the system is asynchronous.
There are other classifications for the real-time tasks that depend on the feature taken into consideration [3, 4]:
In terms of the way of execution, tasks may be preemptive or non-preemptive. A preemptive task is that whose execution can be interrupted by other tasks, to be continued later. A non-preemptive task has to be executed until completion of its consumption time, without interruptions.
In terms of the consequences produced by fault, tasks may be critical, if the fault causes catastrophic consequences, or uncritical, if the fault does not cause a serious consequence. Uncritical tasks are commonly used to deal with auxiliary functions, such as system maintenance, non-critical variable monitoring, etc.
- 1.
Periodical, if their execution should repeat at a constant time interval, known as period (
 ). A periodical task is a sequence of identical invocations activated at a constant rate. A periodical task is represented as
). A periodical task is a sequence of identical invocations activated at a constant rate. A periodical task is represented as  . Reference [1] describes a periodic task as a sequence of activations with the same parameters. This kind of tasks are characterized by time parameters (
. Reference [1] describes a periodic task as a sequence of activations with the same parameters. This kind of tasks are characterized by time parameters ( ) (Fig. 5.1). The kth activation of a periodic task
) (Fig. 5.1). The kth activation of a periodic task  is represented as
is represented as  , and it starts at the instant
, and it starts at the instant  , and should finish before the instant
, and should finish before the instant  .
. - 2.Aperiodical, if they can be active at non-predictable time instants. For example, aperiodic tasks may be events generated by alarms. Aperiodic tasks can be classified as:
Without a deadline, which is non-critical, since they have no deadline to accomplish for their finishing. They can arrive at any moment, and they are only defined by their consumption time
 .
.With a hard deadline, they have a non-critical execution deadline. They are characterized by their consumption time and their deadline (
 ).
).
- 3.
Sporadical, if a considerable fault is produced when they do not finish before their deadline. They are defined with the same parameters of a periodical task (
 ), taking into consideration that the period indicates the minimal time between two consecutive activations.
), taking into consideration that the period indicates the minimal time between two consecutive activations.
Basic references about scheduling and scheduling algorithms have been proposed during recent years, regarding their analysis, by [1, 3, 5]. In these, several aspects are used to identify the necessary considerations in the scheduling analysis of the reconfiguration strategies developed later in this book.
A distinctive feature of real-time operating systems is the management of task execution, known as scheduling. For [3], defining the scheduling problem requires to specify three sets: a set of n tasks  , a set of m processors
, a set of m processors  , and a set of s types of resources
, and a set of s types of resources  . The precedence between tasks can be specified through an acyclic directed graph, and time restrictions can be associated with each task [3]. In this context, scheduling means to assign processors in
. The precedence between tasks can be specified through an acyclic directed graph, and time restrictions can be associated with each task [3]. In this context, scheduling means to assign processors in  and resources in
and resources in  to tasks in
to tasks in  , aiming to complete all tasks under some imposed restrictions. This problem, in its general form, is NP-complete, and thus, intractable from a computing perspective. Certainly, the complexity of the scheduling algorithms is very relevant in real-time dynamic systems, in which scheduling decisions have to be taken on-line precisely during the execution of tasks.
, aiming to complete all tasks under some imposed restrictions. This problem, in its general form, is NP-complete, and thus, intractable from a computing perspective. Certainly, the complexity of the scheduling algorithms is very relevant in real-time dynamic systems, in which scheduling decisions have to be taken on-line precisely during the execution of tasks.
A queue of tasks waiting for execution
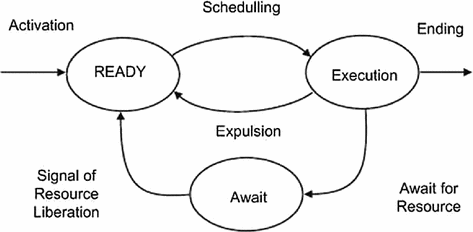
States of a process or task
Given a set of tasks  , executing on a single processor, scheduling refers to assigning tasks to the processor, so each task is executed until it finishes. More formally, [3] defines scheduling as a function
, executing on a single processor, scheduling refers to assigning tasks to the processor, so each task is executed until it finishes. More formally, [3] defines scheduling as a function  such that
such that  , and thus,
, and thus,  and
and  . In other words,
. In other words,  is an integer step function, and
is an integer step function, and  , with
, with  , means that task
, means that task  is executing at time t, while
is executing at time t, while  means that the processor is waiting.
means that the processor is waiting.
 on a processor [3]:
on a processor [3]:For times
 ,
,  ,
,  , and
, and  , the processor performs a context switch.
, the processor performs a context switch.Each interval
 in which
in which  is constant, refers to an amount of time in which task
is constant, refers to an amount of time in which task  is executing. The interval [x, y) identifies all values of t such that
is executing. The interval [x, y) identifies all values of t such that  .
.
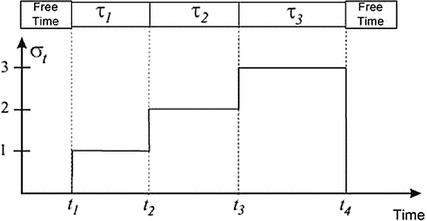
An example of scheduling a set of tasks
A preemptive scheduling is that in which executing tasks can be arbitrarily suspended at any moment to assign the processor to another task, regarding a predefined scheduling policy. In this kind of scheduling, tasks can be executed at disjoint time intervals.
A scheduling is called feasible if all tasks can be completed regarding a set of specific restrictions. Thus, a set of tasks is schedulable if there exists at least one algorithm which can produce a feasible scheduling.
 is shown in Fig. 5.5 [3].
is shown in Fig. 5.5 [3].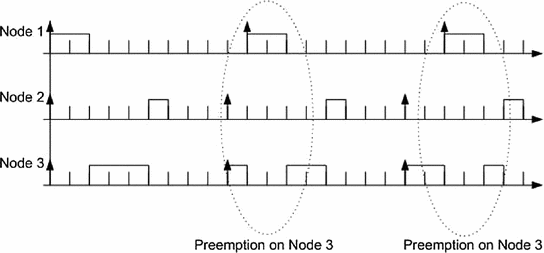
A preemptive scheduling of the set of tasks  between node 3 and node 1
between node 3 and node 1
Classification of Scheduling Algorithms
References [1, 3–5] reduce the complexity of implementing a scheduler by simplifying the architecture of the system. They choose a model preemptive or not, using pre-established execution priorities, eliminating precedence and/or limitations of the resources, assuming the activation of simultaneous tasks, sets of homogeneous tasks, this is, exclusively using periodic or aperiodic tasks. All these different features are used to classify several types of scheduling algorithms, proposed by the cited sources.
Preemptive. With preemptive algorithms, executing tasks can be interrupted at any moment to assign the processor to another active task, regarding a predefined scheduling policy.
Non-preemptive. With non-preemptive algorithms, a task is executed on the processor until finishing it. In this case, all scheduling decisions are taken when a task finishes its execution.
Static. Static algorithms are those that base their scheduling decisions on fixed parameters, assigned to tasks before their activation.
Dynamic. Dynamic algorithms base their scheduling decisions on dynamic parameters, able to change during the evolution of the system.
Off-line. A scheduling algorithm is used off-line if it is executed over the total set of tasks before their activation. The resulting scheduling is stored in a table and later executed by the dispatcher.
On-line. A scheduling algorithm is said to be used online if the scheduling decisions are taken during the execution time, each time a new task enters the system, or when a task finishes its execution.
Optimal. A scheduling algorithm is named optimal if it minimises some cost function defined over the set of tasks. When there is no such a function, and the only concern is achieving a feasible scheduling, then the algorithm is called feasible (suboptimal) if when using such an algorithm, it always finds the same scheduling.
Heuristic. An algorithm is named heuristic if it tends to find an optimal scheduling, but it does not guarantee it for all cases.
A static scheduler (off-line) requires the complete information about the scheduling problem at hand (number of tasks, deadlines, priorities, periods, etc.) to be known priori; however, with an online implementation, the configuration changes during execution, and thus, the scheduling problem has to be solved before the scheduler executes it.
A scheduler is dynamic (on-line) if during execution time it is feasible to know the scheduling parameters, as well as performing the proposed configuration changes.
Gambier [7] highlights the advantage of determinism of static schedulers and as a liability their lack of flexibility. On the contrary, dynamic scheduling is very flexible, but it lacks certainty; on-line scheduling may have a poor performance if the system experiments an overload.
Consult [3, 4, 7] for a classification of dynamic schedulers. In this kind of schedulers, there is a family of schedulers called by priorities [3], which for each task, an important value is associated, known as priority. So, always the active task with the highest priority is executed. Priority schedulers can subdivide into the fixed priority schedulers and dynamic schedulers. The fixed priority schedulers, which assign an initial, immutable value of priority to each task, so each task keeps its priority during the whole execution. On the contrary, if the priority of each task changes during execution, then the scheduler is said to be of dynamic priorities.
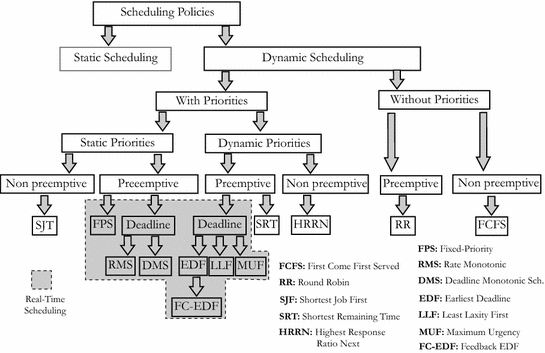
Summary of the classification for scheduling algorithms
Figure 5.6 presents a summary of the classification for scheduling algorithms available [7].
Scheduling of Periodic Tasks
In particular, given that in several real-time applications, the activities with the largest demand are constituted by periodic activities, here it is presented a review analysis of schedulability for the most well-known scheduling algorithms of periodic tasks. The schedulability analysis is presented for each algorithm, aiming to derive a guaranteed test for a set of tasks. According to with [1, 3–5], it is important at the beginning to define the used notation and develop the concept of utilisation factor.
The notation to represent the parameters of the task for the schedulability analysis [3] is shown in Table 2.1.
- 1.
All instances of a periodic task
 are activated with a constant frequency. The interval
are activated with a constant frequency. The interval  between two consecutive activations is the period of the task.
between two consecutive activations is the period of the task. - 2.
All the instances of a periodic task
 have the same worst execution time
have the same worst execution time  .
. - 3.
All instances of a periodic task
 have the same relative deadline
have the same relative deadline  , which is equal or less to their period
, which is equal or less to their period  .
. - 4.
All tasks in
 are independent, this is, there is no precedence relation or resource restriction among them.
are independent, this is, there is no precedence relation or resource restriction among them.
 can be completely characterized by its shift
can be completely characterized by its shift  , the period
, the period  (as mentioned before), and the worst execution time
(as mentioned before), and the worst execution time  , and presented as [3]:
, and presented as [3]:
 and the absolute deadline
and the absolute deadline  of the kth instance can be obtained as:
of the kth instance can be obtained as:

 is feasible if all its activations finish before their deadlines. A set of tasks
is feasible if all its activations finish before their deadlines. A set of tasks  is schedulable (feasible) if all the tasks within the set are feasible.
is schedulable (feasible) if all the tasks within the set are feasible. from which the pattern of activations of the tasks is repeated for a set of periodic tasks
from which the pattern of activations of the tasks is repeated for a set of periodic tasks  . It is useful to ensure a scheduling interval as the representation horizon [4]. The maximum number M of activations for n tasks in each hyperperiod is equal to:
. It is useful to ensure a scheduling interval as the representation horizon [4]. The maximum number M of activations for n tasks in each hyperperiod is equal to:
 [1].
[1]. of n periodic tasks, the utilization factor of the processor is the time fraction that the processor spends in the execution of the set of tasks
of n periodic tasks, the utilization factor of the processor is the time fraction that the processor spends in the execution of the set of tasks  . Given that
. Given that  is the time fraction that the processor spends executing a task
is the time fraction that the processor spends executing a task  , the utilization factor for the n tasks is given as the summation of all the relations of this kind for each task, and bounded as follows:
, the utilization factor for the n tasks is given as the summation of all the relations of this kind for each task, and bounded as follows:
 is schedulable, and above which
is schedulable, and above which  is not schedulable. Such a limit depends on the set of tasks, the particular relationships between periods of tasks, and the algorithm used to schedule the tasks.
is not schedulable. Such a limit depends on the set of tasks, the particular relationships between periods of tasks, and the algorithm used to schedule the tasks. be the superior bound of the utilisation factor of the processor for a set of tasks
be the superior bound of the utilisation factor of the processor for a set of tasks  using algorithm A. When
using algorithm A. When  , it is considered that the set of tasks can be executed by the processor. In such a situation,
, it is considered that the set of tasks can be executed by the processor. In such a situation,  is schedulable by A, but any increment in the execution time of any of the tasks would make the set
is schedulable by A, but any increment in the execution time of any of the tasks would make the set  infeasible. For the given algorithm A, the minimal superior bound
infeasible. For the given algorithm A, the minimal superior bound  of the utilisation factor of the processor is the minimum of the utilisation factors of all the sets of tasks that completely make use of the processor:
of the utilisation factor of the processor is the minimum of the utilisation factors of all the sets of tasks that completely make use of the processor:
 for some scheduling algorithm A. The sets of tasks
for some scheduling algorithm A. The sets of tasks  in the figure differ in the number of tasks and in the value of their periods. When scheduled by algorithm A, each set of tasks
in the figure differ in the number of tasks and in the value of their periods. When scheduled by algorithm A, each set of tasks  totally uses the processor when the utilisation factor
totally uses the processor when the utilisation factor  (changed when modifying the execution times of their tasks) reaches the particular superior bound
(changed when modifying the execution times of their tasks) reaches the particular superior bound  . If
. If  , then
, then  is schedulable; otherwise
is schedulable; otherwise  is not schedulable.
is not schedulable.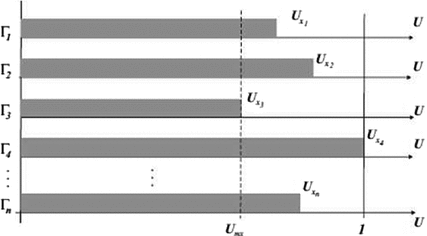
 for some scheduling algorithm A
for some scheduling algorithm A
Reference [3] points out that each set of tasks is able to have a different maximum bound. Given that  is the minimum of all the maximum bounds, any set of tasks that has a utilisation factor of the processor under
is the minimum of all the maximum bounds, any set of tasks that has a utilisation factor of the processor under  is schedulable by A.
is schedulable by A.
 defines an important characteristic of the scheduling algorithms since it allows to easily verify the schedulability if a set of tasks. Certainly, any set of tasks whose utilisation factor is under this bound is schedulable by the algorithm A. In contrast, any utilisation factor above this bound would work if and only if the periods of the tasks are adequately related [1, 3].
defines an important characteristic of the scheduling algorithms since it allows to easily verify the schedulability if a set of tasks. Certainly, any set of tasks whose utilisation factor is under this bound is schedulable by the algorithm A. In contrast, any utilisation factor above this bound would work if and only if the periods of the tasks are adequately related [1, 3].
 ; if
; if  , then
, then  , which can be written as:
, which can be written as:
 represents the number of times that
represents the number of times that  is executed during the interval P, while
is executed during the interval P, while  is the total computing time required by
is the total computing time required by  in the interval P. Therefore, the sum of the left side of the inequality in Eq. 5.7 represents the total computing time demand required by all tasks in P. Clearly, if such a demand exceeds the available time of the processor, there is no feasible scheduling for the set of tasks [3, 5].
in the interval P. Therefore, the sum of the left side of the inequality in Eq. 5.7 represents the total computing time demand required by all tasks in P. Clearly, if such a demand exceeds the available time of the processor, there is no feasible scheduling for the set of tasks [3, 5].A similar situation is presented in several distributed systems, regardless the communication media, like for example, wireless technology. In this sense, local networks provide an approachable situation like MANET [9].
Related Work. Several technologies have been previously combined to develop a protocol for MANET networks, allowing it to be context-aware. Such a context-aware feature is what allows triggering a distributed task every time an event occurs. In all previous work, the first step to execute a distributed task is to discover which nodes can perform the processes that compose such a distributed task.
This service (or process) discovery, regarding a mobile network, has been an important research topic during the last few years. Examples of these are the SLPManet [10] protocol, which modifies the Service Location Protocol [11] to work in MANET environments. Basically, this protocol establishes that service request packages are broadcasted, while service replies packages are cached by every node. However, due to this protocol is developed at the level of the application layer, it simply cannot access any routeing and scheduling information. Another problem is that cache entries may be false when the network topology changes.
Here, a discovery-less architecture is proposed, similar to [12]. Nevertheless, instead of AODV, DSR [13] is used here. Moreover, the protocols proposed by some related work require that only one service is discovered per message. Here, in order to execute a coordinated task, several processes should be found, and hence, the protocol proposed uses multiple service requests, encapsulated into one DSR route request.
Other approaches have been developed around the study of MANET networks and mobile networks, related to the topic here, such as those presented in [14–16]. These types of study have focused the research on context awareness, instead of process management. Further, the Coordinated Task protocol attempts to keep a low network load by merging all service discovery replies that belong to a particular Coordinated Task. Here, service discovery replies are piggy-backed on DSR route reply packets.
After process discovery, the related Coordinated Task should be executed. However, execute a distributed task on MANET is a challenge because during execution the availability of nodes may change: some mobile nodes become unavailable (they leave the network, or fail). Thus, they have to be replaced by other available nodes.
In [17], a distributed task is modelled as a Task Graph. An on-line algorithm is used to replace the unavailable nodes. However, this does not take into consideration the performance (in terms of execution time) or the network load, which makes this approach not suitable for the problem posed here, as RTDS.
Here, a similar Task Graph approach to [18] is used, but only to represent the data flow among of the processes. However, the network load is considered in order to map processes to nodes. Moreover, local cache information is used for replacing unavailable nodes, instead of performing new service requests.
Coordinated Tasks. A Coordinated Task is specified by using a control-driven coordination model [3, 19]. In this model, every process of the task has two ports: input and output. These ports are the only means of interaction between a process and its environment. Input and output ports from different processes are linked to form a communication flow. This communication model guarantees that the activity of each process is decoupled from the activity of any other process: each process is only in charge of performing a sequence of instructions that consumes and produces data. Data transmission between two nodes is the responsibility of the operating system on those nodes.
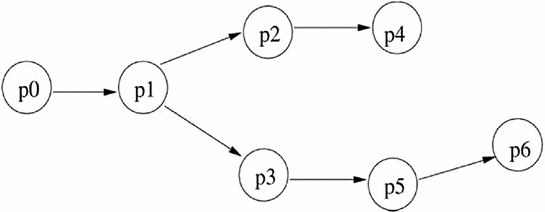
Example of a task graph
The CT execution flow is implemented by using an adjacency list. Entries of such a list are tuples, composed of two process ids: one for the source process of the flow, and the other for the destination process. Tuples in the list are ordered according to the flow direction. So, every process may appear as a source or as a destination. For the CT execution flow in Fig. 5.8, the correspondent adjacency list is  .
.
Now, the Coordination Task protocol is in charge of mapping processes of the Coordinated Task onto available nodes. This protocol also links the input ports of each process to the corresponding output ports. For the actual purposes, nodes with sensors are specifically used to start a Coordinated Task, and thus, they have a CT execution script per each event. Hence, every Coordinated Task has an associated execution script.
Coordinated Task Name. A unique name that identifies a Coordinated Task.
Trigger Event Identifier. A unique id that represents an event.
Processes Identifiers. A field used to identify a process in a Coordinated Task. Depending on the application, the process id could be represented as simple as integers, or as complex as full XML descriptions, like WSDL.
Processes Adjacency List. The adjacency list, describing the CT execution flow.
Coordinated Task Soft Deadline. Every Coordinated Task should be completed before a deadline, and thus, this field represents such a deadline as a timeout value.
Coordinated Task Maximum Communication Requirement. A list indicating how many data is transmitted by every process for each node. If a node does not produce data, its entry is the size of a CT Message.
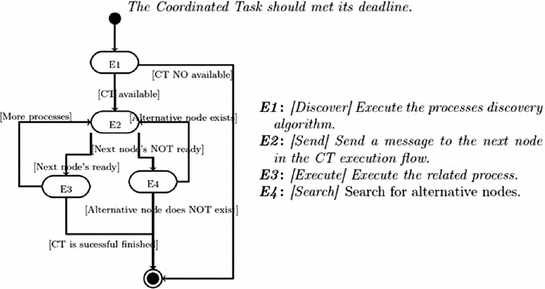
Algorithm for executing a coordinated task
 .
.
 is the time used by the process discovery procedure, and it is obtained by the node which detects the event. This node is also in charge of starting the process discovery algorithm.
is the time used by the process discovery procedure, and it is obtained by the node which detects the event. This node is also in charge of starting the process discovery algorithm. is the time needed to transmit the data. To determine
is the time needed to transmit the data. To determine  , it is required to find out the actual network capacity. However, how to do this is still an open issue. Here, an approach similar to that in [9] is followed. So, using the results, the transmission time (
, it is required to find out the actual network capacity. However, how to do this is still an open issue. Here, an approach similar to that in [9] is followed. So, using the results, the transmission time ( ) is calculated by using Eq. 5.9. Notice that, Eq. 5.9 considers that no message is sent in parallel.
) is calculated by using Eq. 5.9. Notice that, Eq. 5.9 considers that no message is sent in parallel.
 is the message length in kbytes. This value is obtained from the response to the discovery message.
is the message length in kbytes. This value is obtained from the response to the discovery message.Finally,  is the time used by the nodes to execute its assigned processes. It is calculated by simply adding all the worst execution time of each process. These worst execution values are transmitted as a field of the response to the discovery message. Each node obtains these values as presented in [9].
is the time used by the nodes to execute its assigned processes. It is calculated by simply adding all the worst execution time of each process. These worst execution values are transmitted as a field of the response to the discovery message. Each node obtains these values as presented in [9].
 ) satisfies Eq. 5.10, where
) satisfies Eq. 5.10, where  represents the CT deadline.
represents the CT deadline.
Scheduling Analysis
As stated before, commonly, periodic tasks represent the major demand for real-time systems. The need for periodic tasks arises from data acquisition by sensors, control loops, and monitoring systems, among others. Such activities need to be executed cyclically, at specific rates, derived from the requirements of the application. When the application consists of several concurrent tasks with individual time restrictions, the operating system must ensure that each periodic instance is regularly activated at its own rate and be completed before its deadline. For making a schedulable activation, it has to accomplish that the runtime of the task is less or equal to its deadline. In general, if all activations finish before or at the deadline, it is said that the real-time system is schedulable [3].
Feasibility and Optimality. As mentioned before, a valid scheduling is schedulable if each of its tasks is complete before its deadline. It is said that a set of tasks is schedulable regarding a scheduling algorithm if it uses such an algorithm, always producing a feasible scheduling [1]. The most used criterion to measure the performance of a scheduling algorithm is its ability to find a feasible scheduling for a set of tasks, always if such a scheduling exists. A scheduling algorithm is optimal if it always produces a feasible scheduling or what is the same if the set of tasks is feasible to be scheduled. On the contrary, if the optimal algorithm fails to find a feasible scheduling, it can be concluded that the set of tasks cannot be scheduled by another algorithm. Additionally to the criteria based on feasibility, other performance measures include the average value and the maximum finalisation value of a task regarding its deadline (lateness), how much it takes (tardiness), the response time, and the miss rate [1].
Most preemptive scheduling algorithms are priority driven. In this kind of scheduling, each task has associated a priority value, so the active task with the highest priority is always executed. These schedulers are sub-divided into schedulers with fixed priority and schedulers with dynamic priority. Fixed priority schedulers assign an initial priority value to each task, which is kept constant during the whole execution. On the contrary, if the priority of the task changes during execution, then the scheduler is said to be dynamic [4]. To carry out such a kind of scheduling, it is assumed that the time taken by the system to change context is negligible [21].
In particular, four basic algorithms for managing periodic tasks have been developed and extensively used: Rate Monotonic (RM) [8], Deadline Monotonic (DM) [22], Earliest Deadline First (EDF) [8], Least Laxity First (LLF) [2]; the first two make use of fixed priorities, while the other two use dynamic priorities.
In theory, schedulability is developed in two phases: the first phase, analysis, obtains as a result whether the set of tasks is schedulable or not by the selected algorithm; and the second phase, in which the tasks are scheduled. In the case of a dynamic algorithm, scheduling is carried out during execution time [4].
5.2 Consensus and Routing Algorithms
Here several approaches for selecting rates or taking decisions are presented since this definition is basic in order to configure proper mobile distributed systems.
Consensus Algorithms.
The consensus is one of the most widely studied problems in distributed systems. There are several proposals of algorithms for solving the consensus problem, which has been classified into regular, hierarchical, and random. They share some common characteristics, such as they are mainly composed of two operations: proposal and decision, as well as rounds. Each round is composed of both proposal and decision operations. In the proposal operation, a value is postulated to be broadcasted. In the decision operation, a function is applied each round to determine what value is chosen among all those proposals to be the result of that round. The result of the round may be a general consensus, or simply, a previous stage for another round [23].
Considering the notation previously used, a graph  represents the network, in which V is the set of all nodes in the network, and E is the set of all edges. Let A be the set of all nodes that participate in the consensus, such that
represents the network, in which V is the set of all nodes in the network, and E is the set of all edges. Let A be the set of all nodes that participate in the consensus, such that  . Each node proposes a link from itself to any of its neighbours at one hop. This is described using the notation as
. Each node proposes a link from itself to any of its neighbours at one hop. This is described using the notation as  , in which y is a neighbor at one hop, and c is the cost associated to that link. For simplicity, this is expressed just as P(c) [23].
, in which y is a neighbor at one hop, and c is the cost associated to that link. For simplicity, this is expressed just as P(c) [23].
Regular Consensus. This is also known as “flooding consensus”. In this kind of consensus algorithm, each node proposes a value, representing which neighbour node y to communicate, in order to reach a certain destiny. The actual node broadcasts this information, so it is evaluated by the other nodes with which it has a connection. If any node disconnects at any moment, its information is still taken into consideration by the other nodes [23].
Hierarchical Consensus. In the hierarchical consensus, all nodes are ordered regarding certain priority. The node with the highest priority imposes its value to all the others, as rounds pass. No node can broadcast its value if its superior has not done so. If the highest priority node disconnects before broadcasting its value, then the value of the following node in the hierarchy is broadcasted. If this node does not fail, then its value is imposed on the rest of the nodes [23].
Random Consensus. This variant of consensus algorithms assures an integrity in the agreement. Each node has an initial value, which the node proposes through the primitive P(c). This algorithm is carried out in rounds, each one composed of two phases. In the first phase, each node proposes a value. If when receiving the proposal of the neighbouring nodes it is detected a predominant value, this value is decided as the result, and it is proposed in the next phase of the round. However, if the node does not find a predominant value, then randomly selects a value among the initial values, and proposes it as the result of the next round.
Average Consensus. This variant of the consensus algorithms ensures convergence in the agreement. Each node proposes an initial value, using the primitive P(c). The algorithm makes use of two rounds, in which (a) an initial value is proposed, and (b) a value is proposed as result, which is the average of the received values.
Routing Algorithms
In a wireless network, nodes may act as routers, allowing the communication of a source node with a destiny node by a series of point-to-point communications or hops from one routing node to the next. Hence, when a communication is requested, it has to be determined if a route exists that may connect the source node with the destiny node. Also, if a route is found, it has to be decided whether to use it or not. If there is no available route, it has to be decided what to do with the communication request.
Each one of these steps represents aspects of the routing problem. The selection of an available route constitutes such a routing problem, requiring that the available routes be defined. Such a definition may be the set of all the allowed routes given the structure of the network, or a convenient subset. This should include a description of the procedure to find routes and to select which route to use if there are more than one available routes. The decision to perform or not a communication through an available route is known as flow control [24].
An important feature of the communication network is that it should allow a route from a source node to a destiny node. If such a route does not change through time, it is called a static route, whereas if it does tend to change, it is called a dynamic route. In general, a routing algorithm is used to determine such a route [25]. There are two well-known routing algorithms for this, proposed by Bellman-Ford and by Dijkstra.
Deterministic.
Completely adaptive.
Partially adaptive.
Adaptive Routing Algorithm. Dynamic routing algorithms allow to adapt to the traffic or topology changes of a network. A dynamic algorithm can be periodically executed, or directly as a response to the changes in the network. Nevertheless, adaptive routing algorithms are prone to route oscillations and loops.
5.3 Computer Network Design
Real-Time Design
- 1.
Identify all the tasks that compose an application, as well as their time restrictions, such as deadline, period, activation time, etc., which have to be accomplished.
- 2.
Specify the way in which to perform interruption management and context change.
- 3.
Establish the way in which priorities are assigned to tasks.
- 4.
Specify the way in which tasks are manipulated so they present certain kind of relation.
- 5.
Perform the correspondent scheduling analysis.
- 6.
Implement the proposed model.
- 1.
Clock synchronisation. Synchronisation is a more complex issue in distributed systems than it is in centralised systems since synchronisation in distributed systems requires the use of distributed algorithms. In practice, when there is a computer system or network with n nodes, the corresponding n clocks tend to oscillate at different rates, which implies an asynchronous execution. The difference between the time values is known as clock distortion
 .
. - 2.
Event-driven systems and time-driven systems. A real-time system is driven by events when the system is able to sense a significative event (using a sensor) and generates an interruption. On the other hand, a real-time system is time-driven when it is handled by a clock interruption each
 time units. This is known as clock mark. Detecting an event in this kind of real-time systems happens in the clock mark just next to the occurrence of the event. Thus, the selection of a value for
time units. This is known as clock mark. Detecting an event in this kind of real-time systems happens in the clock mark just next to the occurrence of the event. Thus, the selection of a value for  should be carefully carried out: if it is too small, the real-time system would have a lot of clock interruptions, wasting time during the revision of the interruptions; if it is too large, crucial events could pass unnoticed.
should be carefully carried out: if it is too small, the real-time system would have a lot of clock interruptions, wasting time during the revision of the interruptions; if it is too large, crucial events could pass unnoticed. - 3.
Predictability. This is an inherent feature of real-time systems. It should be clear that the system accomplishes all its time limits, even during peak loads. The statistical analysis of behaviour, assuming independent events, show the frequent existence of errors, since there are common unexpected correlations between events. Random behaviour seldom occurs in a real-time system.
Timelines. This means that results not only have to be correct but also have to occur within time restrictions.
Design for maximum load.
Predictability.
Fault tolerance.
Maintenance.
Continuous operation.
In computing, a process can be defined as the change of the state in the memory due to the action of the processor. As such, a process has an execution thread and can be composed of a finite set of tasks. A task is the sequential execution of code that does not suspend itself. Normally, tasks can be subdivided into smaller units of work, namely, jobs, execution instances, or subtasks. In general, the processor executes tasks in a certain order determined by a set of rules, known as a scheduling algorithm. This algorithm establishes that a task can exist in several states. A task is executing if the task has been chosen for execution or waiting to be assigned to the processor by the scheduling algorithm. A task waiting to be assigned is also known as a ready to execute task. An active task is that has been allocated on a ready to execute queue.
Several operating systems allow the dynamic activation of tasks. An executing task can be temporarily suspended at any moment, and hence, if a more important task requires execution, it can make use of the processor immediately. In this case, the executing task is interrupted and placed on the ready to execute queue, while the processor is assigned to the most important task in the ready to execute queue.
Restrictions
- 1.
Restrictions imposed by the operating systems.
- 2.
Time restrictions.
- 3.
Precedence restrictions.
- 4.
Mutual exclusion restrictions, due to shared resources.
A time restriction is strict if the user requires validation that the system always satisfies its time restrictions. In contrast, a time restriction is flexible if there is no need for such a constant validation, but only that the system statistically satisfies some time restrictions.
 executing in real-time can be characterized by a subset of the following parameters (Fig. 5.10):
executing in real-time can be characterized by a subset of the following parameters (Fig. 5.10):Activation time
 . It is the time in which a task is ready for execution; it is also referred as release time.
. It is the time in which a task is ready for execution; it is also referred as release time.Consumption time
 .
.Period
 .
.Absolut deadline
 .
.Relative deadline
 .
.Start time

Final time

Response time

Latency
 :
:Laxitud o excedente
 :
:Phase
 :
:
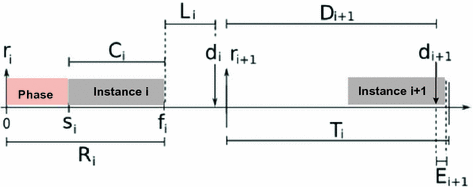
Parameters of a subtask executing in real-time
 ). From the graph structure, it can be noticed that task
). From the graph structure, it can be noticed that task  is the only task that can start execution since it has no predecessor. Finishing the execution of
is the only task that can start execution since it has no predecessor. Finishing the execution of  , both
, both  and
and  are able to start execution. Task
are able to start execution. Task  can start execution only when
can start execution only when  has finished, while
has finished, while  has to wait until both
has to wait until both  and
and  finish their respective executions.
finish their respective executions.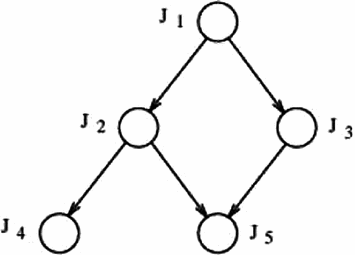
An acyclic directed graph describing the relations of five tasks
Mutual Exclusion Restrictions. This kind of restrictions is commonly due to concurrent execution of tasks, which share resources. Consistency problems may arise if two or more tasks make use of shared resources. To secure the consistency, concurrent tasks have to use access protocols, that commonly guarantee mutual exclusion when race conditions arise among concurrent tasks. Hence, these protocols assure a (mutually exclusive) sequential access to the shared resources. In general, most operating systems provide with synchronisation mechanisms that can be used for developing the access protocols.
The Scheduling Problem
- 1.
A set of n tasks
 ,
, - 2.
a set of m processors
 , and
, and - 3.
a set of r kinds of resources
 .
.
Besides, there can be some specifications about precedence relations among tasks, as well as time restrictions associated with each task. Thus, scheduling means to assign resources R and processors P to the tasks in  , aiming to complete all the tasks under the imposed restrictions.
, aiming to complete all the tasks under the imposed restrictions.
Off-line Scheduling Algorithms
Usually, the feasibility of scheduling is defined in terms of accomplishing time restrictions (deadlines, task dependencies, and so on). For the off-line scheduling algorithms, the solution search space can be represented as a search tree, in which each node represents the assignation of a task to a processor. Any branch to a leaf represents a schedule, although it is not necessarily feasible. A partial scheduling is a route between any pair of nodes in the tree.
Once assignation has been done by each node in the tree, the algorithm traverses the tree by means of a deep search, running all those branches that do not offer a feasible scheduling, i.e., do not accomplish with the specified restrictions. When the search finishes, each possible route represents a possible schedule. In case of which there is more than one feasible schedule, the objective is to find the optimal schedule, in which optimality is defined as a function that has to be maximised or minimised. Examples of these functions are the average load, the maximum workload, reducing execution time, reducing execution latency, etc.
On-line Scheduling Algorithms
Periodic Tasks Scheduling. The existence of periodic tasks in a computing system is due to the need to produce a response, acquire, and process data with certain regularity. Basically, the scheduling strategies distribute processor time so the temporal restrictions are satisfied.
Here, three periodic tasks scheduling techniques are reviewed: rate monotonic (RM), earliest deadline first (EDF), and deadline monotonic (DM). These algorithms are based on priority, which requires that the processor remains idle only when no executing task requires such resources. Algorithms based on priority can be static or dynamic. In a static algorithm, all tasks are divided into subsets. In contrast, in a dynamic algorithm, ready for execution tasks are placed on a queue, and are dispatched to processors for their execution as soon as a processor is made available.
These techniques are widely used in real-time systems, since using these algorithms it is possible to specify a criterion for the use of the available resources in a system. Scheduling algorithms allow the rational utilisation of resources, and occasionally, with the adequate conditions, they can reach optimal solutions. Unfortunately, it is simply not possible to establish rules that define when there are optimal conditions for implementing a specific approach, and totally take advantage of the resources.
- 1.
Tasks are totally preemptive and, besides, the exchange between tasks has a negligible cost.
- 2.
Only processing requirements are significative. Memory and I/O are negligible.
- 3.
All tasks are independent, this is, there is no precedence relationship.
- 4.
All tasks are periodic.
- 5.
Relative deadlines of tasks are equal to their periods.
In this scheduling algorithm, priorities are fixed, since they are assigned based on the period: the task with the shortest period is the one with the highest priority. In other words, for a finite set of periodic tasks  , whose periods
, whose periods  accomplish that
accomplish that  , the task with the identifier
, the task with the identifier  is the one with the highest priority.
is the one with the highest priority.
 :
:
- 1.
Tasks are totally preemptive, and the cost of such a property is negligible.
- 2.
Only processing requirements are significative. Memory, I/O, and other requirements are negligible.
- 3.
All tasks are independent. There is no precedence relationship.
- 4.
All tasks are periodic.
- 5.
Periodic tasks do not have the same relative deadline.
- 1.
All tasks
 have the same worst execution time
have the same worst execution time  .
. - 2.
Tasks are totally preemptive, and the cost of this is negligible.
- 3.
All tasks are independent. There is no precedence relationship.
Multiple processor systems require a communication media for the information exchange. Depending on characteristics of the memory architecture, there are two types of multiprocessor systems: shared memory, which implies the existence of a physical memory, shared among the processors of the system, and distributed memory, in which processors do not have a common memory, but communicate using I/O operations.
Shared memory multiprocessor systems are commonly tightly coupled systems, this is, the communication time between processor is very small when compared with the processing time of a task, and thus, can be ignored. Hence, communication is reduced to read and write operations over the shared memory. Distributed memory multiprocessor systems, in contrast, are loosely coupled, since the communication time between processors tends to be comparable to the processing time of tasks.
Real-time scheduling of distributed systems with multiple processors poses two subproblems: assigning tasks to processors, and scheduling of tasks on individual processors. The problem of assigning tasks refers to how to divide the set of tasks, and then, how to assign them to processors. The assigning tasks problem can be static or dynamic.
Static Assingning
Balancing Algorithm. This algorithm consists of a centralised data structure, i.e., a queue, which maintains tasks in incremental order, according to their utilisation. So, tasks are removed one by one from the data structure, each time sending them to the node with the least utility [29].
The objective function to minimize in this algorithm is  , where u is the average utilization of the processors in the system, and
, where u is the average utilization of the processors in the system, and  is the utilization value of processor i. This algorithm is factible when the number of processors in the system is odd.
is the utilization value of processor i. This algorithm is factible when the number of processors in the system is odd.
Algorithm Next-Fit for Rate Monotonic. In this algorithm [8], a set of tasks is divided, so each subset of tasks is assigned to a processor that makes use of Rate Monotonic for scheduling. This algorithm attempts to use the least number of possible processors. This algorithm, when compared with the balancing algorithm, does not require that the set of processors be given beforehand or predetermined. This algorithm classifies different tasks depending on their utilisation. One or more processors are assigned to a certain kind of task. The essence of this algorithm is grouping tasks with a similar utilisation for their execution.
 belongs to class k, such that
belongs to class k, such that  , if and only if:
, if and only if:
 ) has the status of underloaded if its utilization is not larger than a pre-established value Th, (
) has the status of underloaded if its utilization is not larger than a pre-established value Th, ( ). A processor is overloaded if this value is over such a pre-established value (
). A processor is overloaded if this value is over such a pre-established value ( ). In this algorithm, a processor sends its information only when its status changes from overloaded to underloaded, or vice versa.
). In this algorithm, a processor sends its information only when its status changes from overloaded to underloaded, or vice versa.Scheduling of Coordinated Tasks
- 1.
Mapping processes to nodes.
- 2.
Provide mechanisms that nodes require to perform the coordinated task.
- 3.
Provide a communication infrastructure.
- 4.
Monitor the execution status of a coordinated task.
- 5.
Guarantee that at the end nodes release their used resources.
Consensus is a procedure, this is, a finite number of steps whose purpose is reaching an agreement about some value. An important aspect of achieving consensus, applied for many practical situations, is that consensus should be achieved in the presence of faults. Achieving consensus in a distributed system without faults seems not to be a real challenge. It is enough to exchange messages with the needed information to achieve an agreement [30]. In contrast, when a decision is taken even in the presence of faults, or if the consensus interacts with a scheduling algorithm, the problem seems more interesting.
Agreements in the consensus not only allow establishing the value of some important variables in distributed systems. In practice, a consensus is very important to maintain consistency in some systems. Consensus has been studied based on different types of system models: for time models, as synchronous and asynchronous models; for fault models, under byzantine, crash, or due to communication faults. Regarding asynchronous systems, the consensus is restricted by the result produced by Fischer, Lynch, and Patterson (FLP), which assures that it is impossible to reach a deterministic consensus in an asynchronous system [31].
5.4 Control Design Using Local Mobile Conditions
Energy consumption for mobile nodes is an interesting and important issue in order to determine how confident is a node in the network and how stable maybe the system, however, a deep exploration in the issue is out of the scope of this book, interesting references have studied this issue as follows.
Routing Information Protocol (RIP)
Each node builds a unidimensional array (a vector) that contains the distances (costs) to all nodes and distributes such a vector to their immediate neighbours. Initially, it is assumed that each node is aware of the link cost to each one of its immediate neighbours. A fallen link is considered to have an infinite cost [32].
The routing protocols are different from the graph model previously described. In a group of networks, the aim of routers is to learn how to re-send packets to several networks. Thus, instead of considering the cost of reaching other routers, routers broadcast the costs for reaching a particular network.
RIP is the most direct implementation of routing by distance vector. A router that makes use of RIP sends calls every 30 s. It also sends calls when there is a change in its routing table. In practice, the protocol attempts to reach the target in less than 16 hops. In fact, 16 hops are equivalent to an infinite distance [32].
Open Shortest Path First (OSPF)
routing by link state is the second more used routing protocol. The initial considerations are the same as RIP. It is assumed that each node is able to detect the state of the links which communicate with immediate neighbours (connected or disconnected) and the cost of each link [32].
In practice, each router independently obtains its own routing table from the state packet of link 5. This is used to perform Dijkstra’s Search Forward algorithm.
Optimized Link State Routing (OLSR)
OLSR is a proactive routing protocol that distributes jobs to establish connections between nodes in an ad-hoc wireless network. Flooding (direct broadcast of information throughout all the network) is inefficient and very costly for a mobile wireless network, due to bandwidth limitations and scarce channel quality. OLSR provides an efficient mechanism for information broadcast, based on Multipoint Relays (MPR) [33]. Using MPR, instead of allowing each node to re-transmit any received message (as stated in classic flooding), all nodes in the network select among their neighbours a set of multipoint relays. These are in charge of retransmitting the messages sent by the actual node. The other neighbours cannot re-transmit. This reduces the traffic generated by a flooding [33].
Independently of the way for electing them, the set of MPRs of a node should verify that they are able to reach all the neighbours at a distance of two hops from the actual node. This is a covering criterion of the MPR [33].
Topology Control (TC) messages are periodically and asynchronously sent. Through these, nodes inform about the close network topology. In contrast with HELLO, TC messages are global and should reach to all nodes in the network.
Temporally-Ordered Routing Algorithm (TORA)
TORA is a distributed routing protocol for mobile wireless networks. This protocol aims for a high degree of scalability using a flat algorithm, this is a non-hierarchical routing algorithm. This algorithm attempts to suppress the propagation of control messages to the most far away levels of the network. TORA builds up and maintains a directed acyclic graph, with root in its destiny [34].
TORA is a reactive protocol, characterised by providing to the sender node, not only one, but multiple trajectories to arrive at its destination. The procedure is as follows: each node performs a copy of TORA for each destiny, and the protocol creates, maintains, and cancels the routing trajectories. TORA associates a weight to each node of the network, depending on its destiny. Thus, messages move from a node with larger weight to a node with less weight, while routes discovered by QRY (query) packets are updated with those of type UPD (Update) [34].
The node that responds makes use of the UPD packet, adding its weight. UPD packets are broadcasted, so this allows to all nodes in the middle to conveniently update their weights. From this, all nodes aiming to a far or unreachable destiny increase their local weight up until reaching an allowed maximum value, while a node that finds a close neighbour with a weight tending to infinity will change trajectory [34].
The TORA protocol supports the Internet MANET Encapsulation Protocol (IMEP), which provides a trustworthy expedition service for routing protocols. Adding into a unique block IMEP and TORA messages reduce the network overhead and test the state of neighbouring nodes. To obtain such an addition, it is periodically used the exchange of two messages, known as BEACON and HELLO [34].
Related Work
In an ad-hoc network, all nodes send a HELLO message to check their connectivity with their neighbouring nodes. In this scheme, each node keeps an information table about its neighbouring nodes. The agent node broadcasts a request to all neighbouring nodes, and these resend this request to their neighbours, and so on. When all neighbours are covered, a convercast message is sent with the node address, and its adjacency matrix considering all its neighbours. When this message is received, the agent node obtains the adjacency matrix of one hop for each node in all the network. It may be the case that a node receives more than two messages. In this case, the node checks the sequence number of the message, and stores it or updates the adjacency matrix with the larger sequence number [35].
Another important related work in this area refers to the routing algorithms that attempt to avoid or diminish the use of broadcast. This is the case of the Bypass Routing algorithm [36], which behaves as a recovery mechanism for routes and local errors. Essentially, this algorithm recovers from a failed route. First, the node searches for an alternative route in its route cache memory. If the route exists, the node patches the broken route with an alternative route.
In the context of consensus algorithms, one of the most outstanding related work regarding our case study is the voting algorithm using a weight average [37]. This algorithm proposes a novel way to incorporate consensus using the average of the received votes as initial values.
5.5 Concluding Remarks
the mobile computing is studied considering consensus and routing algorithms as the respective strategies for local agreements in order to provide a coherence in particular movements. This sort of strategy and integrated to scheduling approximation lead us to a more complex time delay behaviour that modifies the relationship of local sensor-controller and controller-actuator time delays as presented in the last part of this chapter.