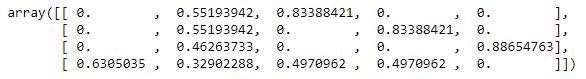The following are the steps for executing TF-IDF in Python:
- Import the library, as follows:
from sklearn.feature_extraction.text import TfidfVectorizer
- Let's make a corpus by adding four documents, as follows:
corpus = ['First document', 'Second document','Third document','First and second document' ]
- Let's set up the vectorizer:
vectorizer = TfidfVectorizer()
- We extract the features out of the text as follows:
X = vectorizer.fit_transform(corpus)
print(vectorizer.get_feature_names())
print(X.shape)
The output is as follows:

- Here comes the document term matrix; every list indicates a document:
X.toarray()
We get the following output: