The Modified National Institute of Standards and Technology (MNIST) is in fact the dataset of computer vision for hello world. Considering its release in 1999, this dataset has served as the main fundamental basis for benchmarking classification algorithms.
Our goal is to correctly identify digits from a dataset of tens of thousands of handwritten images. We have curated a set of tutorial-style kernels that cover everything from regression to neural networks:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import seaborn as sns
%matplotlib inline
from sklearn.model_selection import train_test_split
import itertools
from keras.utils.np_utils import to_categorical # convert to one-hot-encoding
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPool2D
from keras.optimizers import SGD
from keras.preprocessing.image import ImageDataGenerator
sns.set(style='white', context='notebook', palette='deep')
np.random.seed(2)
# Load the data
train = pd.read_csv("train.csv")
test = pd.read_csv("test.csv")
Y_train = train["label"]
# Drop 'label' column
X_train = train.drop(labels = ["label"],axis = 1)
Y_train.value_counts()
The output of the preceding code is as follows:

X_train.isnull().any().describe()
Here, we get the following output:
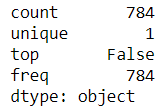
test.isnull().any().describe()
Here, we get the following output:

X_train = X_train / 255.0
test = test / 255.0
By reshaping the image into 3 dimensions, we get the following:
Reshape image in 3 dimensions (height = 28px, width = 28px, canal = 1)
X_train = X_train.values.reshape(-1,28,28,1)
test = test.values.reshape(-1,28,28,1)
Encode labels to one hot vectors
Y_train = to_categorical(Y_train, num_classes = 10)
# Split the dataset into train and the validation set
X_train, X_val, Y_train, Y_val = train_test_split(X_train, Y_train, test_size = 0.1, random_state=2)
By executing the following code, we will be able to see the numbered plot:
pic = plt.imshow(X_train[9][:,:,0])
The output is as follows:

The sequential model is now as follows:
model = Sequential()
model.add(Conv2D(filters = 32, kernel_size = (5,5),padding = 'Same', activation ='relu', input_shape = (28,28,1)))
model.add(Conv2D(filters = 32, kernel_size = (5,5),padding = 'Same', activation ='relu'))
model.add(MaxPool2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Conv2D(filters = 64, kernel_size = (3,3),padding = 'Same', activation ='relu'))
model.add(Conv2D(filters = 64, kernel_size = (3,3),padding = 'Same', activation ='relu'))
model.add(MaxPool2D(pool_size=(2,2), strides=(2,2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(256, activation = "relu"))
model.add(Dropout(0.5))
model.add(Dense(10, activation = "softmax"))
When we define the optimizer, we get the following output:
# Define the optimizer
optimizer = SGD(lr=0.01, momentum=0.0, decay=0.0)
When we compile the model, we get the following output:
# Compile the model
model.compile(optimizer = optimizer, loss = "categorical_crossentropy", metrics=["accuracy"])
epochs = 5
batch_size = 64
Next, we generate the image generator:
datagen = ImageDataGenerator(
featurewise_center=False, # set input mean to 0 over the dataset
samplewise_center=False, # set each sample mean to 0
featurewise_std_normalization=False, # divide inputs by std of the dataset
samplewise_std_normalization=False, # divide each input by its std
zca_whitening=False, # apply ZCA whitening
rotation_range=10, # randomly rotate images in the range (degrees, 0 to 180)
zoom_range = 0.1, # Randomly zoom image
width_shift_range=0.1, # randomly shift images horizontally (fraction of total width)
height_shift_range=0.1, # randomly shift images vertically (fraction of total height)
horizontal_flip=False, # randomly flip images
vertical_flip=False) # randomly flip images
datagen.fit(X_train)
history = model.fit_generator(datagen.flow(X_train,Y_train, batch_size=batch_size),
epochs = epochs, validation_data = (X_val,Y_val),
verbose = 2, steps_per_epoch=X_train.shape[0] // batch_size)
The output can be seen as follows:

We predict the model as follows:
results = model.predict(test)
# select with the maximum probability
results = np.argmax(results,axis = 1)
results = pd.Series(results,name="Label")
results
The output can be seen as follows:
