- Sigmoid: This type of activation function comes along as follows:

The value of this function ranges between 0 and 1. It comes with a lot of issues:
-
- Vanishing gradient
- Its output is not zero-centered
- It has slow convergence
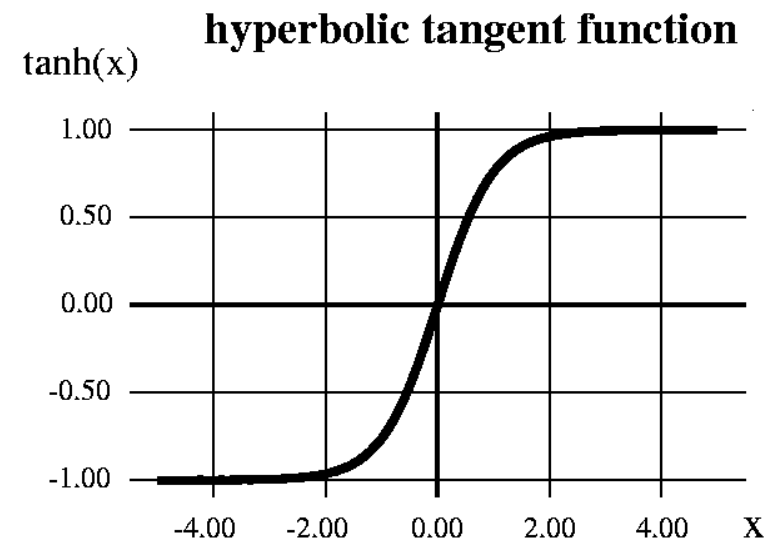
- Hyperbolic tangent function (tanh): The mathematical formula to represent it is this:

The value of this function ranges between -1 and +1. However, it still faces the vanishing gradient problem:
- Rectified Linear Units (ReLU): Mathematically, we represent it in the following manner:
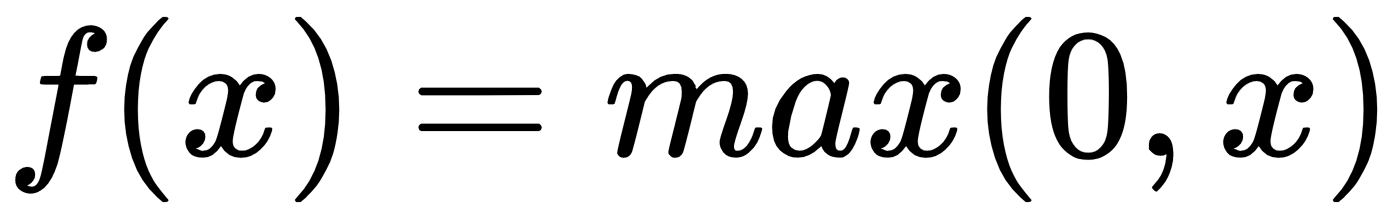
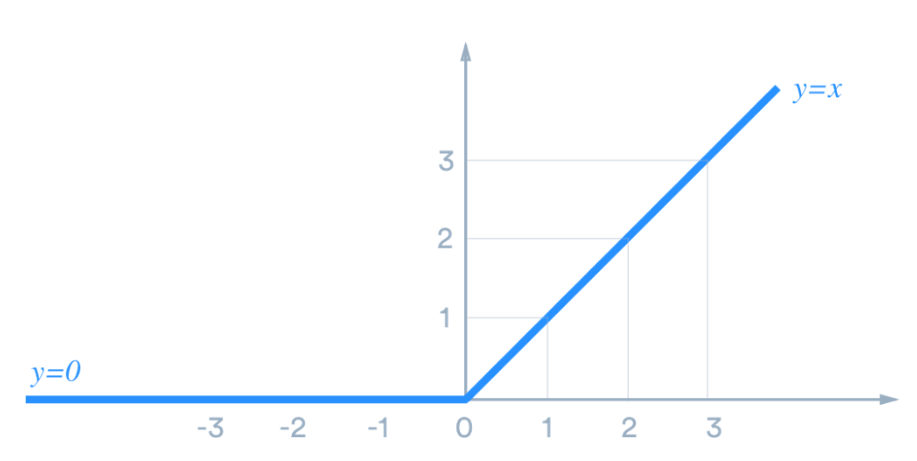
Going by the preceding diagram, ReLU is linear for all positive values, and zero for all negative values. This means that the following are true:
-
- It's cheap to compute as there is no complicated math. The model can therefore take less time to train.
- It converges faster. Linearity means that the slope doesn't hit the plateau when x gets large. It doesn't have the vanishing gradient problem suffered by other activation functions such as sigmoid or tanh.