Modeling is a methodology that's used to identify a topic and derive hidden patterns exhibited by a text corpus. Topic modeling resembles clustering, as we provide the number of topics as a hyperparameter (similar to the one used in clustering), which happens to be the number of clusters (k-means). Through this, we try to extract the number of topics or texts having some weights assigned to them.
The application of modeling lies in the area of document clustering, dimensionality reduction, information retrieval, and feature selection.
There are multiple ways to perform this, as follows:
- Latent dirichlet allocation (LDA): It's based on probabilistic graphical models
- Latent semantic analysis (LSA): It works on linear algebra (singular value decomposition)
- Non-negative matrix factorization: It's based on linear algebra
We will primarily discuss LDA, which is considered the most popular of all.
LDA is a matrix factorization technique that works on an assumption that documents are formed out of a number of topics, and, in turn, topics are formed out of words.
Having read the previous sections, you should be aware that any corpus can be represented as a document-term matrix. The following matrix shows a corpus of M documents and a vocabulary size of N words that makes an M x N matrix. All of the cells in this matrix have the frequency of the words in that particular document:
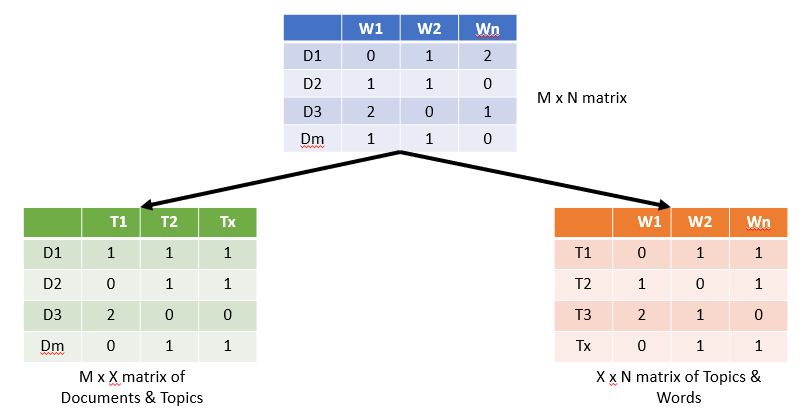
This M x N matrix of Document & Words gets translated into two matrices by LDA: M x X matrix of Documents & Topics and X x N matrix of Topics & Words.