While there are a variety of applications for the concept of mean time between failures (MBTF), this metric is perhaps most often used in the manufacturing industry. MTBF measures the average amount of uptime a mechanical or electrical system has before some kind of failure interrupts normal operation. This concept is perhaps best conveyed in the following diagram:
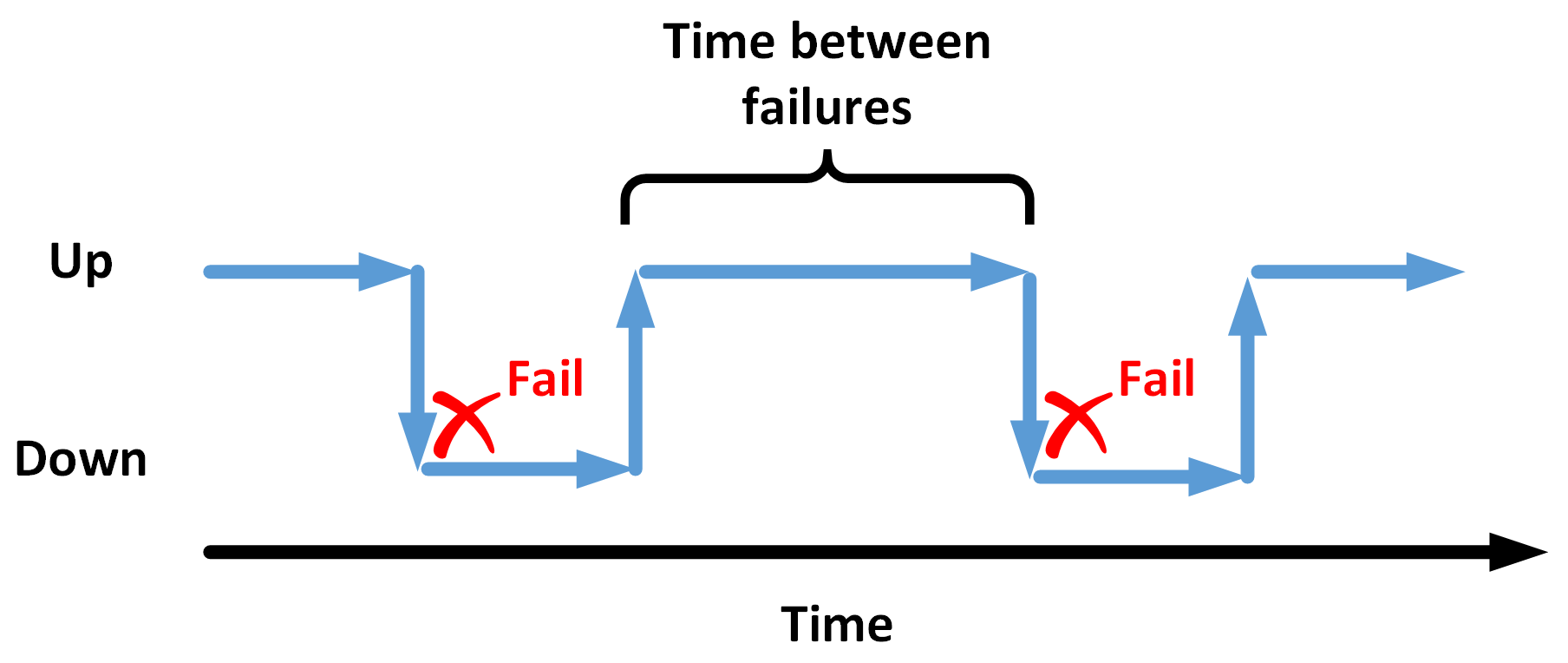
Starting from the left of the preceding diagram, the machine or system is operational up until the point of failure. At this point, the machine or system must be repaired. After repairs have been completed, the system is operational once again, up until the point of a second failure. The time between the system becoming operational after the first failure and the time of the second failure is the time between failures. MTBF averages this amount of time between failures over the life of the system or many similar systems. This can be a key metric when considering things such as productivity and system reliability. In addition, MTBF can help organizations weigh the cost-benefit of more frequent or less frequent preventative maintenance schedules and can even be used to assist in predicting future failures.
This recipe demonstrates how to calculate MTBF given the repair log of a set of machines. In addition to MTBF, an associated metric, mean down time (MDT), is also presented, along with a demonstration of the potential predictive value of MTBF.