So far, we have talked about the types of threats one could encounter in cyberspaces, as well as the main motivations and business models of cybercriminals. We also touched on the differences between threat , vulnerability , and risk in cyberspace. Yet, in many cases, individuals and businesses have numerous misconceptions about cyberthreats and significantly underestimate their propensity to become the victims of cybercrime. Let us first look at some of these misconceptions.
Popular Cybersecurity Misconceptions
Misconception 1: I am too insignificant to be targeted.
Many individuals and businesses believe that they are “too small” or they have “nothing to steal” to be targeted. In the contemporary world, there is no such thing as a system which is not of interest to cybercriminals. No matter how little money you have, no matter how small your business is, if you store or handle some information , it is highly likely that this information can be monetized, and probably in many different ways. Even if the information you hold is only of interest to you or your business and there is no other party on this planet that would ever be interested in it, it still makes sense to steal it and sell it back to you for a ransom. Therefore, it is important to understand that anybody can become a target. Unless you are prepared to take all of your operations offline and not store any data in the digital form (which, in the overwhelming majority of cases, is equivalent to business suicide), there is always a positive probability of being targeted.
In 2018, thousands of individuals and businesses became the target of a ransomware attack which spread through spam emails around the globe. Adversaries mostly targeted business email accounts which could be easily obtained in the public domain. The spam email exercised what is called an “extortion phishing” technique. The email titled “You should be ashamed of yourself”, “You are my victim”, or “Concentrate and don’t get angry” read: “Hi, victim. This is my last warning. I write you because I put a malware on the web page with porn which you have visited …” The senders then claimed that they had obtained personal data and infected the victim’s computer with a virus which allowed them to shoot compromising videos of the victim watching porn. The email demanded a payment in bitcoin in exchange for the destruction of the compromising videos. The phishing email was sent to a large number of untargeted email addresses (i.e., apart from the actual online porn consumers, many other people received the message). As a result, the attack had an effect not only on individuals who frequented the porn websites but also on those who never visited such sites and, yet, were still concerned that their webcams could have been hijacked. So, ransoms were paid not only by those to whom the threat could have been relevant, but also by those who simply were concerned about privacy . The attack had particularly severe consequences in Australia, where the police and the Australian Competition and Consumer Commission had to deal with multiple reports and complaints.1 This example shows that even when people think they have nothing of interest to the cybercriminals, they still may become the victims of various scams.
Misconception 2: Technology is the main weapon of cybercriminals.
It is certainly true that technology is an important tool for cybercriminals, but looking at the types of threats and their history, we see that many of the currently used threats (with several notable exceptions, such as the blockchain-related attacks or AI -informed attacks discussed earlier in this book) existed in the 1960s, 1970s, and 1980s. So, what we observe now (with several exceptions) are often unlikely to be new types of threats; these are essentially old threats “on steroids”. But the increased impact of these threats is mostly due not so much to the development of technology—although the technological component does play a role—but rather to the increased use of hybrid scams, where social engineering and psychological impact are the main methods employed by cybercriminals.
With over 90% of successful breaches worldwide starting with a phishing email, 2 it is clear why cybercriminals concentrate on the psychological tools for planning and implementing the attacks . With technological advances in the area of cybersecurity becoming more and more sophisticated, humans remain the weakest link.
In 2012, a renowned film director, Jake Schreier, released Robot and Frank, a film based on Christopher Ford’s screenplay, in which Frank (Frank Langella), an ex-jewel thief, takes his artificial intelligence (AI) healthcare robot on a heist. The pair target the most expensive house in the neighborhood which seems to have the most sophisticated security system . Yet, Frank explains to his AI companion that “Every security system is designed by security companies , not thieves. It’s not the question of if a thief can break in, it’s how long. They place all the heavy systems where their customers can see them. They’re selling the feel of security.” Frank then explains that one can spend weeks preparing for the robbery trying to decipher the highly advanced security system and making attempts to disable the alarms. Yet, wouldn’t it be much easier just to ring the doorbell and wait for someone to open the door?
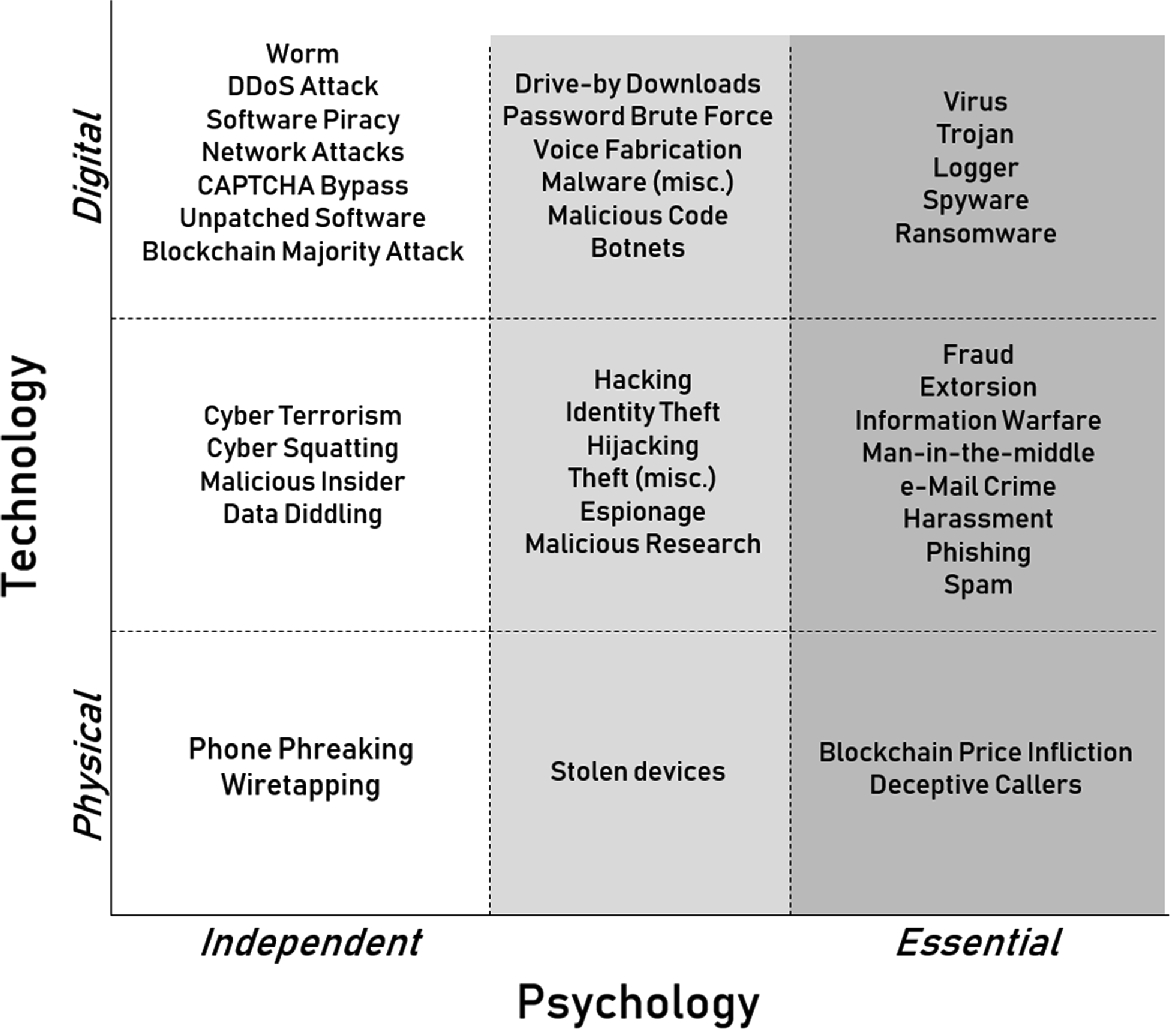
Psycho-technological matrix of cybersecurity threats
For example, phone phreaking in theory can work without any involvement of human psychology and can operate in the physical rather than digital domain. At the same time, a distributed denial-of-service (DDoS) attack requires digital technology but does not rely on human psychology. Threats like cyber terrorism in principle may not rely on human psychology and can use either physical or digital tools . For a range of threats, the psychological component is often needed, although it is not essential. For example, in the physical domain, stealing a device may involve playing tricks on a particular individual but can also be done without their involvement. In the digital domain, an individual’s password can in theory be broken simply using password brute force, yet it often helps to know something about this individual or even trick them into revealing sensitive information which would help the hacker to guess the password. Identity theft may be accomplished physically (by making a simple telephone call) or through digital means, but it often requires at least some human co-operation .
For a number of threats, human psychology is a key component which ensures success. In order to manipulate prices for various bitcoins (blockchain price infliction), one has to influence market price expectations. This can be achieved primarily by physical rather than digital means, particularly through convincing the impactful media to channel “fake news”. Threats like viruses use digital means but require human involvement as the user has to open an email attachment, click on a link, or go to a website in order to set them in motion. Threats such as phishing may use physical or digital tools but rely heavily on social engineering.
Note that of the nine areas of the psycho-technological matrix of cybersecurity threats, only three do not involve human psychology, while six either may to some extent rely on human psychology or have human psychology as a key factor. This shows that social engineering is an important component for the majority of successful attacks, making the weak spots of human psychology the major weapon utilized by cybercriminals.
Misconception 3: It can only happen to me once.
In behavioral science , we often talk about a paradox which we call the “ law of large numbers”. What it boils down to is a very simple psychological phenomenon: most people believe that “probability or chance has memory ”. Imagine that you are playing a game where each coin toss gives you $1 if you are right and nothing if you are wrong. Let’s say, for the sake of argument, that for some reason you prefer betting on heads and you have just played five rounds of the game where heads were turning up on every coin toss, and you won $5 as a result. Now you have an opportunity to place the next bet. Will you bet heads or tails? In this situation, many people would choose tails. Why? They just observed heads come up five times out of five, so they think that getting heads on the next coin toss becomes less probable. This, of course, is a psychological paradox. The chances of getting heads or tails is 50–50 and these chances remain the same no matter how many times you toss the coin.
When we talk about cybersecurity, this paradox is even more prevalent. Once hit by cybercriminals, business owners think it will not happen to them again. This is especially true in the case of ransomware attacks . There is a widespread view that once the ransom is paid and the data is returned, the adversaries will now leave the systems in peace and will not target the same business with a similar attack again. This, of course, is a wrong attitude. Adversaries share information and often disclose targets and code to each other. Therefore, becoming a victim of a cyberattack does not mean that it will not happen to your business again. In fact, it probably makes you a more likely target in the future, as adversaries talk to each other and you might get hit again with very similar tools in a very similar way. In September 2018, British Airways revealed that the personal and financial details of 380,000 customers had been stolen. In October 2018, the same company admitted that 185,000 more customers who made reward bookings using payment cards between April and July 2018 may also have been compromised .3
Misconception 4: I have the best technology on the market to protect me.
Many business owners we talked to during the preparation of this book told us that they outsource security issues to a contractor, who takes care of their system, or that they expect that company, along with Microsoft, Apple , IBM, Google , or other large tech providers, to take responsibility in case of a cybersecurity breach. There are, however, several important caveats here. First, any technological solution, like any sophisticated lock, can be broken. We often talk about using sophisticated technology, such as AI, for detecting threats and preventing adversaries from getting into systems . However, we often forget that adversaries are also using technology and they have exactly the same (if not better) set of tools available to them. Recall that in Chapter 3 we introduced the concept of “zero-day vulnerability ”—an unknown gap in the system. This vulnerability is not visible to the security system designers (despite all the tech they are armed with), yet it may become visible and, ultimately, used (“exploited”) by adversaries.
Furthermore, as we explained above, technology is not everything where cybersecurity is concerned. In his 2017 public talk at Google , Frank Abagnale, a former con man turned security consultant whose story inspired Steven Spielberg’s movie Catch Me If You Can (2002), explained that most cybersecurity breaches result from someone in the organization “doing something they ARE NOT supposed to do” or “failing to do what they ARE supposed to do” [1]. Under these circumstances, it does not matter how amazing your technological solutions are and how many hundreds, thousands, millions of dollars you are spending on buying the next technological wonder or engaging the next technological wizard to fix things for you. What is important is how likely your staff are to do what they ARE NOT supposed to do or fail to do what they ARE supposed to do.
Misconception 5: I am very careful, so I cannot be tricked.
One of the most popular misconceptions is that being careful or cautious somehow decreases the chance of being targeted. The truth is, unfortunately, that it does not matter how careful or careless you are. Even if you are very careful and surrounded by the best cybersecurity minds in the country , there is still a very good chance that a strong enough adversary will succeed in compromising your data or systems .
One would have thought that the US Democratic Party has pretty good cybersecurity and that their staff are well versed in the potential dangers of cyber breaches. After all, most of these people have worked in politics for years and understand not only the responsibility associated with handling and transferring confidential information , but also the reputational consequences of losing such information. Yet, we all know that Hillary Clinton’s presidential campaign in 2016 was sabotaged by a series of breaches later labelled as “Russian influence on” or “Russian involvement in” the elections due to the alleged links to 12 Russian intelligence officers [2]. How do you think the hackers got into the emails and data of some of the most guarded people in the USA? Simple. They used “good old” phishing techniques!
In March 2016, John Podesta, the Clinton campaign chairman, along with other campaign staff, received a spear-phishing email . The adversaries made the email look like a security notification from Google and invited the email recipients to click on the embedded link and change their password (a “spoofing” technique). As a result of this simple trick, the adversaries were able to gain access to John Podesta’s account as well as obtain information on over 50,000 emails mostly belonging to the members of the Democratic Congressional Campaign Committee (DCCC), the Democratic National Committee (DNC), as well as employees and volunteers involved in the Clinton campaign. This information, along with data obtained from social media as well as from other spear-phishing attacks, allowed the adversaries to hack into the accounts of senior members of the Democratic campaign staff team .
In April 2016, the adversaries sent another spear-phishing email which appeared to be a message from a trusted member of the Clinton’s campaign team to all Clinton campaign staff members . The email contained a link to an Excel document titled “hillary–clinton–favorable-rating.xlsx”. Recipients who clicked on the link (and there were many who fell for this trick!) were directed to the website allegedly created by a Russian intelligence organization (GRU4). The website was created with the aim of harvesting further personal data from Democratic Party staff.
The aftermath of this attack had dramatic consequences for the US Democrats. The adversaries published correspondence of the DNC members through WikiLeaks. This correspondence showed a complete absence of impartiality during the Democratic Party preliminaries in 2016. Thousands of embarrassing messages revealed the efforts of many officials to aid Clinton’s campaign and damage the campaign of Bernie Sanders, Clinton’s main opponent. As a result of the controversy, the chairperson of the DNC, Debbie Wasserman Schultz, resigned. To date, many experts believe that this series of events, which started with a spear-phishing email, by and large determined the outcome of the 2016 US presidential elections as it significantly damaged Hillary Clinton’s chances of becoming president.
Why Do We Have Misconceptions About Cybersecurity?
So far, we have looked at five major misconceptions about cybersecurity. The natural question is—why do we have those misconceptions? Unfortunately, the problem is a lot deeper than cybersecurity and the way we, as humans , perceive it. It is related to the fact that digital environments are very new to humanity and we simply have not developed enough understanding of those environments. In other words, we do not have a culture of navigating digital spaces. In physical spaces, by contrast, we feel more confident and seem able to estimate potential risks quite well. For example, those of us who live in urban areas know that wandering around some parts of the city after dark is probably not a very good idea. Yet, in cyber spaces, we do not know which areas are crime -ridden, which are safe, and which are dangerous. As a result, people are quite reckless about everything they generate or do in digital spaces.
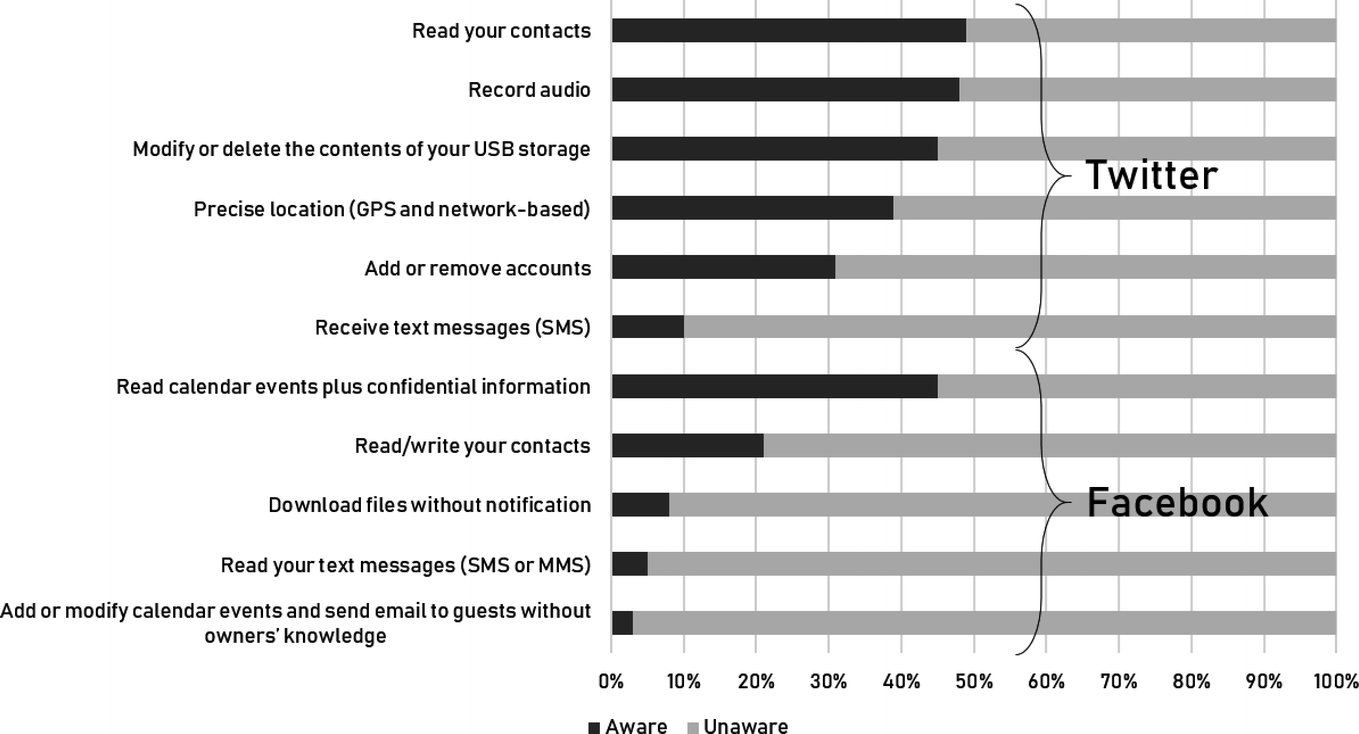
Percentage of UK users aware and unaware about a menu of Facebook and Twitter permissions
Almost none of respondents (3%) knew that Facebook had access to their events calendar—i.e., that the app could add or modify calendar events and send emails to invitees without the calendar owner’s knowledge . Only 5% and 8% of respondents realized that Facebook could read their text messages and download files without notification, respectively. About a fifth of respondents (21%) knew that Facebook could read and write their contacts, whereas 45% were aware that Facebook could view their calendar and other confidential information . With Twitter permissions the situation was slightly, though not massively, better. Specifically, 10% of users understood that Twitter had access to their text messages; 31% knew that Twitter could add and remove accounts; 39% realized that Twitter could track their location ; 45% understood that Twitter could modify or delete the content of their USB storage (e.g., use USB storage to cache photos); 48% knew that Twitter could record audio using their smartphone; and 49% were aware that Twitter could read their contacts. Notice that all these percentages are below 50%.
This illustrates that most people are simply not concerned with the issues of security , safety, and privacy as long as they believe that the benefits of using a particular digital service (in the case of a social media app, we are talking about the ability to share information and get access to information posted by others) outweigh the potential risks (loss of privacy, loss of important private data , etc.). This leads to a situation where many people could be vulnerable to a number of threats; however, their perceived vulnerability (their understanding) of these threats is incredibly low. This is why we see so many people accepting the terms and conditions for apps without even reading what they are.
This, however, does not mean that users do not understand that their data is worth something. As we see from various data sources as well as from our own investigations , people know that their data is valuable. Yet, again, they are rather confused about how much it could cost. In 2015, Digital Catapult UK published a study titled “Trust in Personal Data: The UK Review”, in which they asked a representative sample of the UK population to answer several questions about their personal data. In the study, 60% of respondents revealed that they thought their personal data was worth approximately £30 ($39) per week [3]. The Digital Catapult study measured users’ willingness to accept (or WTA): users were asked how much money they were willing to accept in exchange for selling one week’s worth of their personal data.
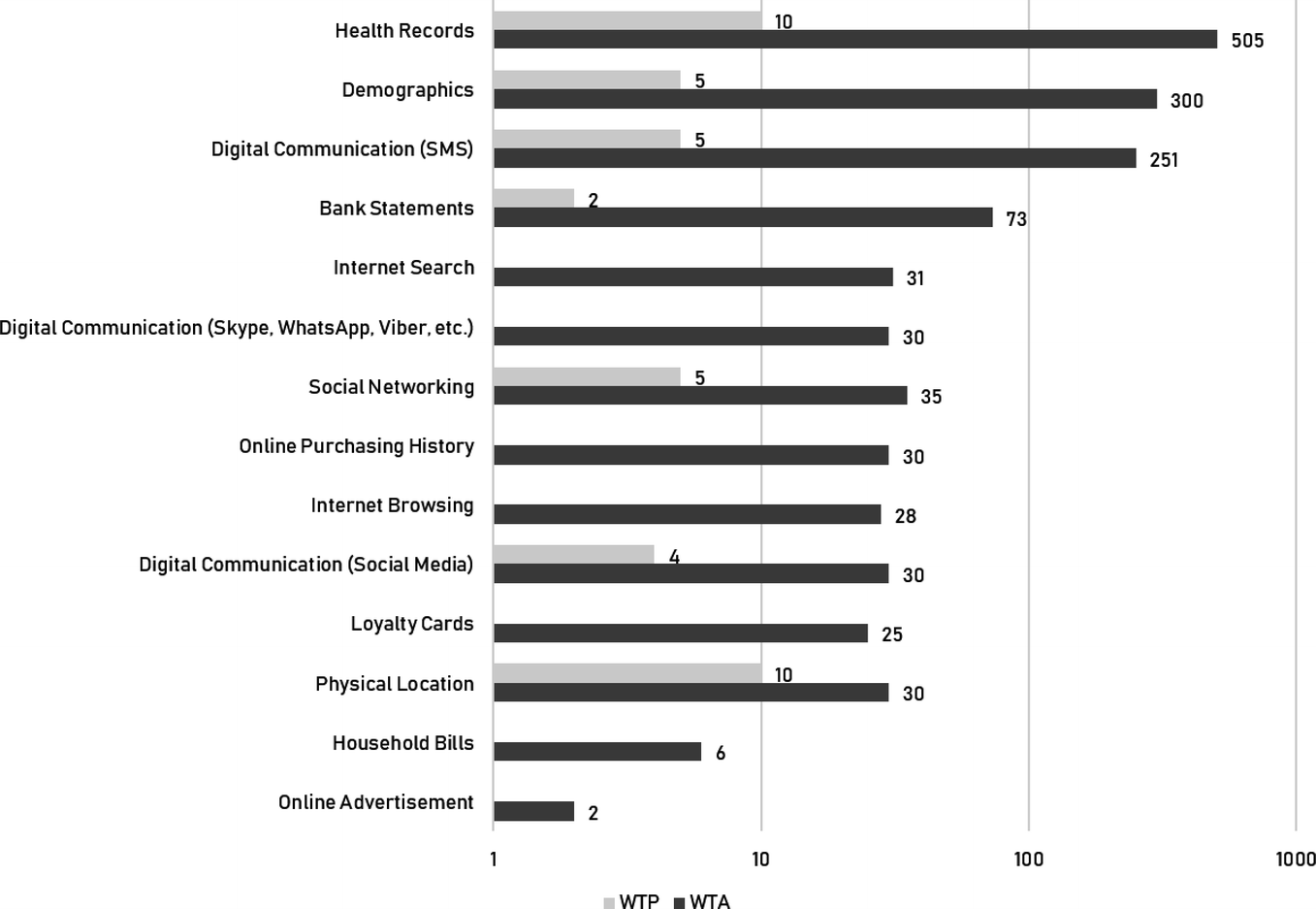
Weekly amount of money in British Pounds which UK users are willing to accept to sell their data (WTA) and willing to pay to protect their data (WTP)
For example, users said that, on average, they would be willing to sell their Bank Statements data for £73 ($95); Digital Communication data for £251 ($328); Demographic data for £300 ($392); and Health Records for £505 ($660). Furthermore, the data revealed interesting disparities between WTP and WTA estimates for the same types of data. It is usual to expect WTA to be higher than WTP, however, for some types of data the difference is surprisingly high (e.g., Health Records data), while for others it is surprisingly low (e.g., Physical Location).
On the one hand, all of this is surprising for the following reasons. First, people often give away many of these types of personal data for free (e.g., Social Networking, Internet Browsing, Internet Search, Physical Location, Loyalty Cards data, Demographic Data, etc.). Second, they are not even trying to protect many types of data, yet they still believe their data is worth something.
On the other hand, these results are quite explainable. High WTA estimates for health records and bank statements data can be explained by the fact that the data in these categories is likely to be very sensitive to individuals. High WTA estimates for demographic data can be rationalized because one week or one year of demographic data is equally valuable (demographic data does not change much with time, or it changes in a very predictable way—e.g., every year you simply become one year older). Therefore, people believe that one week’s worth of demographic data is equivalent to a lifetime’s worth of demographic data and put a large asking price on it. Overall, we observe that people are very confused about the precise price of their data as this price is (i) highly context-dependent to them (you are likely to feel different about your data dependent on what has happened to you in a particular week), and (ii) they do not have experience or a good reference point as to how companies determine the price of personal data. Hence, it is incredibly difficult for individuals to come up with precise numbers.
People also care about who is asking them to provide personal data and why. Think about it: if we ask whether you would be willing to provide some of your personal data so that we could conduct a non-profit research project for the benefit of science or society, you would probably agree. Yet, if we tell you that we would like to collect your data and sell it to the top private-sector bidder for profit, you almost definitely would say “no”. When we conducted a number of surveys with representative samples of the US population, in which we changed the entity asking for the data and the reasons why, we found a large variability in individual estimates. Specifically, in a study of 606 participants from all over the USA, we found that when individuals were asked to provide their data for commercial purposes, the asking price (WTA) was, on average, six times higher than the price (WTA) for the same data when we said it would be used for non-profit research. These results confirm that (i) people often do not realize how much their data is worth, as this is a highly subjective and context-dependent issue; and (ii) people simply do not have enough experience with cyber spaces to be able to understand what a “safe space” is.
Unfortunately, the same is true for businesses. Many businesses, especially small and medium enterprises, have little clue about the market value and worth of the data they hold, which also stems from the fact that even very sophisticated and mature business communities have scant information about the underlying business models of cybercriminals and, as a result, have little idea of the total cost of their data. The Internet offers a wide variety of estimates about the potential losses which various cyberthreats could bring. A simple search will give you hundreds of websites offering numbers and infographics. Yet, it is often not clear how these estimates were obtained and whether and to what extent any of these numbers are reliable.
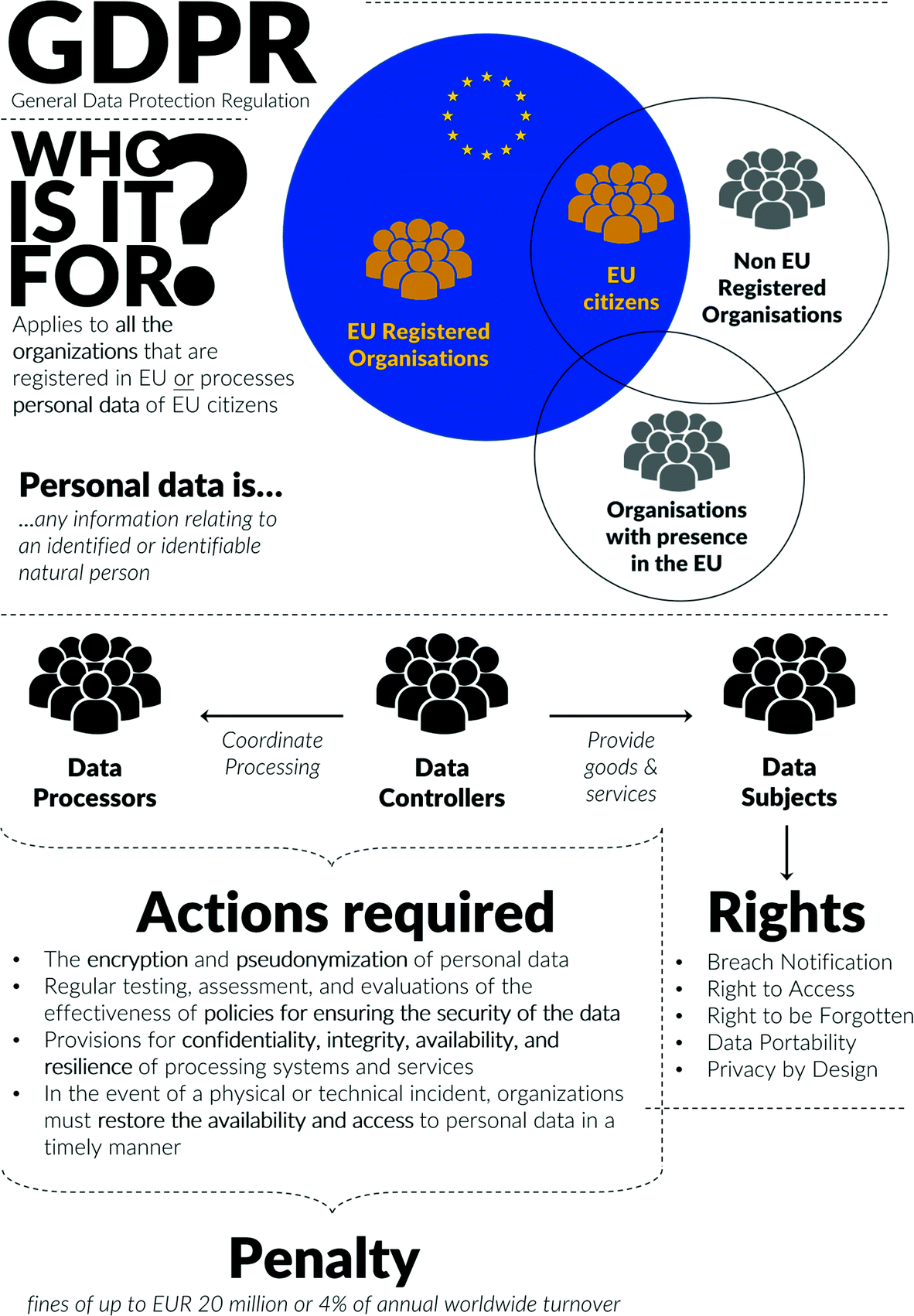
Summary of the General Data Protection Regulation
Even companies that are in the business of selling data often have very arbitrary methods of price setting. In the past, we regularly purchased datasets from large corporations for various research projects and, considering the amount of time and effort it takes to make a database query and produce a dataset, the pricing model seems either to significantly overestimate the value of human labor associated with each request or rather arbitrarily determine how much the data might be worth. So why do various businesses keep purchasing data from the large data vendors such as Google , Facebook , Twitter, among others? Of course, it might be a problem of capacity: some businesses simply do not have the expertise to collect their own data. It might also be a problem of data availability: some data is not in the public domain. But we know that even those businesses who do collect their own data also purchase datasets from large data vendors. You see, Google, Facebook, Twitter, and other digital giants are not selling data, they are selling perceptions . If you, as a business owner, simply ask your IT department to harvest data from publicly available sources, you might have concerns about the data quality (the data might be noisy or irrelevant). Yet, when the data comes with a stamp of a reputable digital giant, you somehow think that the risks associated with data quality are reduced and the data you receive is more valuable (higher quality, more relevant, less noisy, etc.). However, in reality, both datasets (collected by your IT and by a reputable data vendor) may be of equivalent quality: you just perceive the purchased dataset to be “better”. Therefore, the large data vendors are collecting significant premiums which simply represent the difference between the zero or nearly zero supply price for data (as the majority of individuals are giving away their data for free) and a rather large demand price for data which captures the businesses’ desire to “de-risk ” the data they are working with.
Having said all that, it would be wrong to argue that estimates of the value and worth of various data for different types of businesses should not be made. Estimates are very useful to develop effective cybersecurity architecture, understand the costs and benefits of various cybersecurity measures, and determine whether your business needs to outsource cybersecurity issues or purchase cybersecurity insurance policy . All we are trying to say is that caution should be exercised when using such estimates to make sure that they are (i) built based on some rational principles and not arbitrarily; (ii) based on transparent and verifiable methodology; and (iii) presented in ways which would complicate their use by adversaries.
Cybersecurity Statistics and Most Costly Threats
Despite the great variety of literature offering cybersecurity statistics, it is hard to understand the relative cost of various cybersecurity threats as sources of information about cybersecurity and the underlying methodology for conducting various measurement exercises are rarely revealed. In the UK , the Department for Digital, Culture , Media and Sport releases an annual Cyber Security Breaches Survey.5 In its 2018 edition, the survey included answers from 1519 UK businesses (with the exception of sole traders; agriculture, forestry, and fishing businesses) as well as 569 third-sector organizations (charities). According to the survey, 43% of businesses and 19% of charities admitted that they have experienced a cybersecurity attack during the 12 months preceding the survey. 49% of businesses and 24% of charities revealed that they outsourced their cybersecurity to a third-party vendor. The survey also established the most common threats. Phishing comes firmly in first place and splits between two types of activities: fraudulent emails or redirection to fraudulent websites, which represents the lion’s share of adversarial impact (75% in businesses and 74% in charities), and spear-phishing attempts (28% and 27% in businesses and charities, respectively). Viruses, spyware, or malware attacks represent 24% of breaches for businesses and charities. 15% of breaches for businesses and 10% for charities are ransomware attacks, while DoS attacks represent 12% and 13% of experienced threats for businesses and charities, respectively. Brute force attacks such as hacking online bank accounts are infrequent, totaling 8% and 3% for businesses and charities, respectively. Unauthorized use of computing power , networks, and servers by insiders (staff) is related to 7% of breaches targeting businesses and 6% targeting charities. Other types of threats are associated with 5% and 6% of attacks on businesses and charities, respectively. Additionally, 48% of businesses and charities admitted that phishing attacks were the most costly and caused the greatest disruption to their organizations. In terms of monetary costs , the estimates varied greatly between different types of organizations, with large businesses spending, on average, £15,300 ($19,635) to address the problem associated with the harmful outcome of a breach; while medium businesses, small businesses, and charities spent £12,100 ($15,528), £1190 ($1527), and £678 ($870), respectively. Yet, at the same time, estimates revealed that only 11% of their cybersecurity investment went into protecting staff and systems, and only 20% of businesses had cybersecurity training for staff.
Reliable and traceable statistics on US cybersecurity breaches are harder to obtain than those for the UK as the majority of published results come from private entities and large cybersecurity providers. Data in the USA is mostly provided by private cybersecurity surveys. For example, IDC6 conducted a survey of US businesses and released a report in 2018 suggesting that 77% of surveyed American businesses were victims of cyberattacks in the 12 months prior to the survey. In February 2018, the Council of Economic Advisers published a report titled “The Cost of Malicious Cyber Activity to the US Economy”,7 which cited several sources, including the Ponemon Institute , and highlighted that, due to the lack of centralized statistical records, the estimates of the cybercriminal impact on businesses are likely to be biased or inaccurate because they are primarily based on survey data and often highlight the most notorious or publicly available events . The Council conducted its own analysis, using 290 events in the 2013/2014 financial year covering mostly large businesses, and estimated the effect of cyberattacks on market capitalization of the victim companies . Their analysis revealed that businesses in their sample lost , on average, $494 million per event. For comparison, Ponemon came up with a different estimate of $21 million per year using a similar sample of companies. The Council’s report does not provide a comprehensive breakdown of costs by threat, leaving us to rely on other sources. Yet, the landscape seems to be somewhat similar to the UK, as 56% of “1,300 surveyed IT security decision-makers” in the CyberArk Global Advanced Threat Landscape Report 2018 named phishing attacks as the most challenging threat.
The Measurement Problem
Of course, any business owners need to know not only how much various cybersecurity threats might cost on average, but also what is the actual risk and cost associated with each potential threat to their business. Recall that in Chapter 2 we explained the difference between “threat”, “vulnerability ”, and “risk”, and argued that all three are measurable “in principle” or “in theory”. Yet, theory and practice are two different things. The main problem is that in practice the measurement is very difficult. While we do not aim to list all the reasons why the measurement of cyberthreats, vulnerabilities , and risks maybe difficult, we do provide a subset of these reasons below.
Issues with threat measurement
are primarily associated with four main difficulties. First, threats are multiple (see Table 2.1) and for a regular risk management exercise it is often very costly to consider all possible threats. Second, even though the majority of threats we observe today are not new, every once in a while an innovative technique would emerge, and it is extremely hard to anticipate such techniques before they are executed. This primarily concerns attacks executed by AI , machine learning (ML), or deep learning (DL) algorithms. Third, the information sharing and communication of experienced threats between businesses, within businesses, between businesses and consumers, as well as between businesses and policy- makers, is broken. Since the harm from various cyber events is uncertain, information about executed attacks are often reaching the relevant parties too late, thereby providing the adversaries with a competitive advantage as some threats remain undiscovered for a long time. The EU GDPR tried to address this challenge by making the reporting of every instance of a breach relating to consumer data compulsory. Yet, it is too early to say whether the regulation will work and what consequences will be seen in the next few years. Finally, what we seem to observe more and more often are “hybrid” threats, where several threats from our Table 2.1 are mixed, matched, and deployed by adversaries.
Issues with vulnerability measurement
relate to several factors. First of all, vulnerability diagnostics is closely related to the diagnostics of potential threats. Therefore, if one cannot be done systematically and reliably, the other cannot be done either. Second, exploring vulnerabilities efficiently requires putting yourself into the adversaries’ shoes. Yet, not many businesses have enough experience and “maturity” (strategic and expertise readiness) to perform such exercises. Finally, and most importantly, even when the business is mature enough and has a good understanding of the underlying vulnerabilities according to a particular methodology, there is always a possibility that a “zero-day vulnerability”, an unknown and underexplored gap in the system , may exist which still could be exploited by cybercriminals.8
All these issues with threat and vulnerability measurements bring us to the difficulties associated with risk measurement.
Issues with risk measurement
are primarily associated with the fact that it is often not possible to obtain the exact probability measure of cybersecurity risk. The purpose of any traditional risk assessment exercise is to provide exact risk measurement in a form of some discrete value (probability, percentage chance, etc.). Yet, very often it is not possible to pin down the exact probability of some adverse event happening. Naturally, it relates not only to the difficulties in cyber space threat detection and imprecision in vulnerability analytics, but also to the fact that due to the complexity of the cyberspace, traditional tools used for risk detection and management are no longer adequate and need significant revision to effectively address the cybersecurity risks.
In what follows, we expand on this point looking at existing tools to measure and alleviate cybersecurity risks as well as discuss the threats and risks we are likely to face in the future. We will also explore how these new risks could be addressed using a variety of tools.