Chapter 7
Generating Insights with Software Applications
IN THIS CHAPTER
 Monetizing data directly with no-code and low-code
Monetizing data directly with no-code and low-code
Getting a grip on relational databases and SQL
Designing great relational databases
Doing data science tasks with SQL functions
Using Excel spreadsheets to examine your data
Formatting and summarizing data in spreadsheets
Automating tasks in Excel spreadsheets
In this day and age, when it seems that every company wants to hire data scientists with extensive experience programming in R and Python, it only makes sense for technology vendors to offer tools that help democratize the data insights that are generated by data scientists. There simply aren’t enough data scientists to go around, and even if there were — the whole world doesn’t need to be a data scientist. We need to be able to show up and create value in our own areas of expertise. The business world needs that from us as well.
In this chapter, you see some incredibly powerful low-code or no-code tools for generating more profits, faster, from the data you’re already working with, without the downtime of needing to learn to build complicated predictive models in R or Python.
Choosing the Best Tools for Your Data Science Strategy
Data science strategy can best be described as a technical plan that maps out each and every element required to lead data science projects that increase the profitability of a business. In Chapter 6, I talk about how R and Python are often part of the plan, which may make you think that, when it comes to data science strategy, Python and R are the obvious answers to this question: “Which tools do I need for my strategy to succeed?” Is the obvious answer always the best answer? I think not. A data strategy that relies only on data science to improve profits from data is a limited one, cutting itself off at the pass by insisting on the use of code to monetize data.
For example, imagine that a human resources (HR) professional, without needing to write even one line of code, is able to build a software application that automatically collects applicant data, reads that data into an Applicants SQL database, and then executes an automated response to each applicant based on the manual determination of the HR personnel who is processing employment applications. Where appropriate, the software automatically moves candidates forward in the hiring process. This no-code application eliminates the need for manual data entry, data clean-up, email follow-up, and candidate forwarding. That’s a lot of time (money, in other words) saved right there.
Do you know of any prebuilt software whose vendor could come in and configure it to create this type of system setup in-house? Yes, you probably do, but that’s a lengthy, expensive, and inflexible route to take, considering that the same outcome is now possible in a no-code environment like Airtable — a collaborative, intuitive, cloud-based SQL-esque solution that acts and works like both a spreadsheet and database at the same time. These days, in my business, all of our data warehousing and project management take place inside Airtable, and I’m able to build applications off that platform while collaborating with ten team members, all for just $10 per month.
No-code is a type of development platform that leverages graphical user interfaces in a way that allows both coders and noncoders alike to build their own software applications. If your start-up or small business has no complex data architecture, it’s entirely possible to house your company's data in a no-code environment and not have to worry about integrating that data and platform with other data systems you might have.
If your company is larger and more mature, you may want to look into low-code options — platforms that allow users to build applications without needing to use any code whatsoever, but that do require a small bit of code to configure on the back end in order to enable data integration with the rest of the company's data systems and sources. Commonly used low-code solutions are Google Forms and Microsoft Access for self-service data collection and integration.
With respect to data strategy, what we’re really talking about here is leveraging low-code and no-code solutions to deploy and directly monetize more of your company’s data, without needing to train existing team members, or hire experienced data scientists. The idea is to equip all knowledge workers with intuitive data technologies they can use right away to start getting better results from data themselves, without the intervention of data specialists — a true democratization of data and data monetization across the business, in other words.
Bridging the gap between no-code, low-code, SQL, and spreadsheets, SQL databases and spreadsheet applications such as Excel and Google Sheets provide just the no-code and low-code environments that knowledge workers can start using today to increase the productivity and profitability of their company's data. These technologies are so accessible and represent so much upside potential to modern businesses that I’m including high-level coverage of them in the pages that follow.
Getting a Handle on SQL and Relational Databases
Some data professionals are resistant to learning SQL because of the steep learning curve involved. They think, “I am not a coder and the term Structured Query Language sure sounds like a programming language to me.” In the case of SQL, though, it is not a programming language — as you’ll soon see. As far as the upside potential goes of learning to use SQL to query and access data, it’s worth the small degree of hassle.
SQL, or Structured Query Language, is a standard for creating, maintaining, and securing relational databases. It’s a set of rules you can use to quickly and efficiently query, update, modify, add, or remove data from large and complex databases. You use SQL rather than Python or a spreadsheet application to do these tasks because SQL is the simplest, fastest way to get the job done. It offers a plain and standardized set of core commands and methods that are easy to use when performing these particular tasks. In this chapter, I introduce you to basic SQL concepts and explain how you can use SQL to do cool things like query, join, group, sort, and even text-mine structured datasets.
 Although the SQL standard is lengthy, a user commonly needs fewer than 20 commands, and the syntax is human-readable — for example, if you need to pull data on employees in the Finance department who earn more than $50,000 per year in salary, you could use a SQL statement like the one shown in Figure 7-1. Making things even easier, SQL commands are written in ALL CAPS, which helps to keep the language distinct and separate in your mind from other programming languages.
Although the SQL standard is lengthy, a user commonly needs fewer than 20 commands, and the syntax is human-readable — for example, if you need to pull data on employees in the Finance department who earn more than $50,000 per year in salary, you could use a SQL statement like the one shown in Figure 7-1. Making things even easier, SQL commands are written in ALL CAPS, which helps to keep the language distinct and separate in your mind from other programming languages.
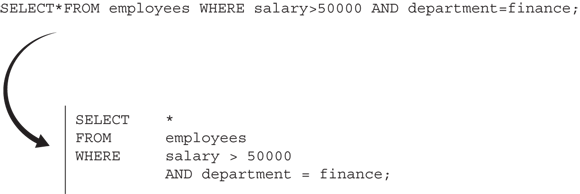
FIGURE 7-1: An example of how SQL is human-readable.
Although you can use SQL to work with structured data that resides in relational database management systems, you can’t use standard SQL as a solution for handling big data. (Unfortunately, you just can’t handle big data using relational database technologies.) I give you more solutions for handling big data in Chapter 2, where I discuss data engineering and its components. For now, suffice it to say that SQL is simply a tool you can use to manipulate and edit structured data tables. It’s nothing exceedingly innovative, but it can be helpful to use SQL for the data querying and manipulation tasks that often arise in the practice of data science. In this chapter, I introduce the basics of relational databases, SQL, and database design.
Although the name Structured Query Language suggests that SQL is a programming language, don’t be misled. SQL is not a programming language, like R or Python. Rather, it’s a language of commands and syntax that you can use to create, maintain, and search relational database systems. SQL supports a few common programming forms, like conditionals and loops, but to do anything more complex, you’d have to import your SQL query results into another programming platform and then do the more complex work there.
 SQL has become so ubiquitous in the data field that its passionate users commonly debate whether SQL should be pronounced “ess-cue-el” or “see-quel.” Most users I’ve met lean toward the latter.
SQL has become so ubiquitous in the data field that its passionate users commonly debate whether SQL should be pronounced “ess-cue-el” or “see-quel.” Most users I’ve met lean toward the latter.
One fundamental characteristic of SQL is that you can use it on only structured data that sits in a relational database. SQL database management systems (DBMSs) optimize their own structure with minimal user input, which enables blazing-fast operational performance.
An index is the lookup table. You create it in order to index, point to, and “look up” data in tables of a database. Although SQL DBMSs are known for their fast structured database querying capabilities, this speed and effectiveness are heavily dependent on good indexing. Good indexing is vital for fast data retrieval in SQL.
Similar to how different web browsers comply with, add to, and ignore different parts of the HTML standard in different ways, SQL rules are interpreted a bit differently, depending on whether you’re working with open-source products or commercial vendor software applications. Because not every SQL solution is the same, it’s a good idea to know something about the benefits and drawbacks of some of the more popular SQL solutions on the market. Here are two popular open-source SQL implementations commonly used by data scientists:
- MySQL: By far the most popular open-source version of SQL, MySQL offers a complete and powerful version of SQL. It’s used on the back end of millions of websites.
- PostgreSQL: This software adds object-oriented elements to SQL’s relational language, making it popular with programmers who want to integrate SQL objects into their own platforms’ object model.
Other powerful commercial SQL implementations, such as Oracle and Microsoft SQL Server, are great solutions as well, but they’re designed for use in a more traditional business context rather than as a data science tool.
As you might guess from the name, the most salient aspect of relational databases is that they’re relational — they’re composed of related tables, in other words. To illustrate the idea of a relational database, first imagine an Excel spreadsheet with rows, columns, and predefined relationships between shared columns. Then imagine having an Excel workbook with many worksheets (tables), in which every worksheet has a column with the same name as a column in one or more other worksheets. Because these worksheets have a shared relationship, if you use SQL you can use that shared relationship to look up data in all related worksheets. This type of relationship is illustrated in Figure 7-2.
The primary key of a table is a column of values that uniquely identifies every row in that table. A good example of primary keys is the use of ISBN numbers for a table of books or employee ID numbers for a table of employees. A foreign key is a column in one table that matches the primary key of another and is used to link tables.
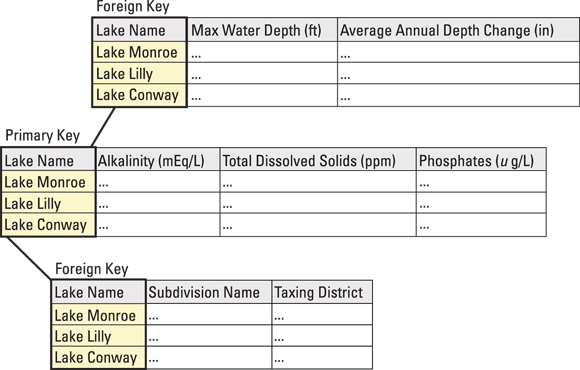
FIGURE 7-2: A relationship between data tables that share a column.
Keeping the focus on terminology, remember that proper database science often associates particular meanings to particular words, as you can see in this list:
- Columns, called fields, keys, and attributes
- Rows, called records
- Cells, called values
Database science uses a lot of synonyms. For simplicity’s sake, I try to stick to using the words column, row, and cell. And because primary key and foreign key are standard terms, I use them to describe these two special column types.
The main benefits of using relational database management systems (RDBMSs, for short) is that they’re fast, they have large storage and handling capacity (compared to spreadsheet applications such as Excel), and they’re ideal tools to help you maintain data integrity — the consistency and accuracy of data in your database. If you need to make quick-and-accurate changes and updates to your datasets, you can use SQL and a RDBMS.
Let the following scenario serve as an illustration. This data table describes films and lists ratings from viewers:
id title genre rating timestamp rating
1 The Even Couple NULL 2011-08-03 16:04:23 4
2 The Fourth Man Drama 2014-02-19 19:17:16 5
2 The Fourth Man Drama 2010-04-27 10:05:36 4
3 All About Adam Drama 2011-04-05 21:21:05 4
3 All About Adam Drama 2014-02-21 00:11:07 3
4 Dr. Yes Thriller NULL
What happens if you find out that All About Adam is a comedy rather than a drama? If the table were in a simple spreadsheet, you’d have to open the data table, find all instances of the film, and then manually change the genre value for that record. That’s not so difficult in this sample table because only two records are related to that film. But even here, if you forget to change one of these records, this inconsistency would cause a loss of data integrity, which can cause all sorts of unpredictable problems for you down the road.
In contrast, the relational database solution is simple and elegant. Instead of one table for this example, you’d have three:
Film id title
1 The Even Couple
2 The Fourth Man
3 All About Adam
4 Dr. Yes
Genre id genre
2 Drama
3 Drama
4 Thriller
Rating timestamp id rating
2011-08-03 16:04:23 1 4
2014-02-19 19:17:16 2 5
2010-04-27 10:05:36 2 4
2011-04-05 21:21:05 3 4
2014-02-21 00:11:07 3 3
The primary key for the Film and Genre tables is id. The primary key for the Rating table is timestamp — because a film can have more than one rating, id is not a unique field and, consequently, it can't be used as a primary key. In this example, if you want to look up and change the genre for All About Adam, you’d use Film.id as the primary key and Genre.id as the foreign key. You'd simply use these keys to query the records you need to change and then apply the changes systematically. This systematic approach eliminates the risk of stray errors.
Investing Some Effort into Database Design
If you want to ensure that your database will be useful to you for the foreseeable future, you need to invest time and resources into excellent database design. If you want to create databases that offer fast performance and error-free results, your database design has to be flawless, or as flawless as you can manage. Before you enter any data into a data table, first carefully consider the tables and columns you want to include, the kinds of data those tables will hold, and the relationships you want to create between those tables.
Every hour you spend planning your database and anticipating future needs can save you countless hours down the road, when your database might hold a million records. Poorly planned databases can easily turn into slow, error-ridden monstrosities — avoid them at all costs.
Keep just a few concepts in mind when you design databases:
- Data types
- Constraints
- Normalization
In the next few sections, I help you take a closer look at each topic.
Defining data types
When creating a data table, one of the first things you have to do is define the data type of each column. You have several data type options to choose from:
- Text: If your column is to contain text values, you can classify it as a Character data type with a fixed length or a Text data type of indeterminate length.
- Numerical: If your column is to hold number values, you can classify it as a Numerical data type. These can be stored as integers or floats.
- Date: If your column is to hold date- or time-based values, you can designate this as a Date data type or Date-Time data type.
Text data types are handy, but they’re terrible for searches. When you use a text field to do a search or select query, SQL will cause the computer to call up each of the data objects individually, instead of searching and sorting through them in-memory — in other words, processing data within the computer’s memory, without actually reading and writing its computational results onto the disk.
Designing constraints properly
Think of constraints, in the context of SQL, as rules you use to control the type of data that can be placed in a table. As such, they’re an important consideration in any database design. When you’re considering adding constraints, first decide whether each column is allowed to hold a NULL value. (NULL isn't the same as blank or zero data; it indicates a total absence of data in a cell.)
For example, if you have a table of products you’re selling, you probably don’t want to allow a NULL in the Price column. In the Product Description column, however, some products may have long descriptions, so you might allow some of the cells in this column to contain NULL values.
Within any data type, you can also constrain exactly what type of input values the column accepts. Imagine that you have a text field for Employee ID, which must contain values that are exactly two letters followed by seven numbers, like this: SD0154919. Because you don't want your database to accept a typo, you’d define a constraint that requires all values entered into the cells of the Employee ID column to have exactly two letters followed by seven numbers.
Normalizing your database
After you’ve defined the data types and designed constraints, you need to deal with normalization — structuring your database so that any changes, additions, or deletions to the data have to be made only once and won’t result in anomalous, inconsistent data. There are many different degrees and types of normalization (at least seven), but a good, robust, normalized SQL database should have at least the following properties:
- Primary keys: Each table has a primary key, which is a unique value for every row in that column.
- Nonredundancy of columns: No two tables have the same column, unless it’s the primary key of one and the foreign key of the other.
- No multiple dependencies: Every column’s value must depend on only one other column whose value does not in turn depend on any other column. Calculated values — values such as the total for an invoice, for example — must therefore be done on the fly for each query and should not be hard-coded into the database. This means that zip codes should be stored in a separate table because they depend on three columns — address, city, and state.
-
Column indexes: As you may recall, in SQL an index is a lookup table that points to data in tables of a database. When you make a column index — an index of a particular column — each record in that column is assigned a unique key value that’s indexed in a lookup table. Column indexing enables faster data retrieval from that column.
It’s an excellent idea to create a column index for frequent searches or to be used as a search criterion. The column index takes up memory, but it increases your search speeds tremendously. It’s easy to set up, too. Just tell your SQL DBMS to index a certain column, and then the system sets it up for you.
 If you’re concerned that your queries are slow, first make sure that you have all the indexes you need before trying other, perhaps more involved, troubleshooting efforts.
If you’re concerned that your queries are slow, first make sure that you have all the indexes you need before trying other, perhaps more involved, troubleshooting efforts. -
Subject-matter segregation: Another feature of good database design is that each table contains data for only one kind of subject matter. This isn’t exactly a normalization principle per se, but it helps to achieve a similar end.
Consider again the film rating example, from an earlier section:
Film id title
1 The Even Couple
2 The Fourth Man
3 All About Adam
4 Dr. Yes
Genre id genre
2 Drama
3 Drama
4 Thriller
Rating timestamp id rating
2011-08-03 16:04:23 1 4
2014-02-19 19:17:16 2 5
2010-04-27 10:05:36 2 4
2011-04-05 21:21:05 3 4
2014-02-21 00:11:07 3 3I could have designated
Genreto be a separate column in theFilmtable, but it's better off in its own table because that allows for the possibility of missing data values (NULLs). Look at theFilmtable just shown. Film 1 has no genre assigned to it. If theGenrecolumn were included in this table, thenFilm 1would have aNULLvalue there. Rather than have a column that contains aNULLvalue, it's much easier to make a separate Genre data table. The primary keys of the Genre table don’t align exactly with those of the Film table, but they don’t need to when you go to join them.
NULL values can be quite problematic when you’re running a SELECT query. When you're querying based on the value of particular attribute, any records that have a NULL value for that attribute won’t be returned in the query results. Of course, these records would still exist, and they may even fall within the specified range of values you’ve defined for your query, but if the record has a NULL value, it's omitted from the query results. In this case, you’re likely to miss them in your analysis.
Any data scientist worth their salt must address many challenges when dealing with either the data or the science. SQL takes some of the pressure off when you’re dealing with the time-consuming tasks of storing and querying data, saving precious time and effort.
Narrowing the Focus with SQL Functions
When working with SQL commands, you use functions to perform tasks, and arguments to more narrowly specify those tasks. To query a particular set from within your data tables, for example, use the SELECT function. To combine separate tables into one, use the JOIN function. To place limits on the data that your query returns, use a WHERE argument. As I say in the preceding section, fewer than 20 commands are commonly used in SQL. This section introduces SELECT, FROM, JOIN, WHERE, GROUP, MAX(), MIN(), COUNT(), AVG(), and HAVING.
The most common SQL command is SELECT. You can use this function to generate a list of search results based on designated criteria. To illustrate, imagine the film-rating scenario mentioned earlier in this chapter with a tiny database of movie ratings that contains the three tables Film, Genre, and Rating.
To generate a printout of all data FROM the Rating table, use the SELECT function. Any function with SELECT is called a query, and SELECT functions accept different arguments to narrow down or expand the data that is returned. An asterisk (*) represents a wildcard, so the asterisk in SELECT * tells the interpreter — the SQL component that carries out all SQL statements — to show every column in the table. You can then use the WHERE argument to limit the output to only certain values. For example, here is the complete Rating table:
Rating timestamp id rating
2011-08-03 16:04:23 1 4
2014-02-19 19:17:16 2 5
2010-04-27 10:05:36 2 4
2011-04-05 21:21:05 3 4
2014-02-21 00:11:07 3 3
If you want to limit your ratings to those made after a certain time, you'd use code like that shown in Listing 7-1.
LISTING 7-1: Using SELECT, WHERE, and DATE() to Query Data
SELECT * FROM Rating
WHERE Rating.timestamp >= date('2014-01-01')
timestamp id rating
2014-02-19 19:17:16 2 5
2014-02-21 00:11:07 3 3
In Listing 7-1, the DATE() function turns a string into a date that can then be compared with the timestamp column.
You can also use SQL to join columns into a new data table. Joins are made on the basis of shared (or compared) data in a particular column (or columns). You can execute a join in SQL in several ways, but the ones listed here are probably the most popular:
- Inner join: The default
JOINtype; returns all records that lie in the intersecting regions between the tables being queried - Outer join: Returns all records that lie outside the overlapping regions between queried data tables
- Full outer join: Returns all records that lie both inside and outside the overlapping regions between queried data tables — in other words, returns all records for both tables
- Left join: Returns all records that reside in the leftmost table
- Right join: Returns all records that reside in the rightmost table
Be sure to differentiate between an inner join and an outer join, because these functions handle missing data in different ways. As an example of a join in SQL, if you want a list of films that includes genres, you use an inner join between the Film and Genre tables to return only the results that intersect (overlap) between the two tables.
To refresh your memory, here are the two tables you're interested in:
Film id title
1 The Even Couple
2 The Fourth Man
3 All About Adam
4 Dr. Yes
Genre id genre
2 Drama
3 Drama
4 Thriller
Listing 7-2 shows how you’d use an inner join to find the information you want.
LISTING 7-2: An Inner JOIN Function
SELECT Film.id, Film.title, Genre.genre
FROM Film
JOIN Genre On Genre.id=Film.id
id title genre
2 The Fourth Man Drama
3 All About Adam Drama
4 Dr. Yes Thriller
In Listing 7-2, I name specific columns (Film.title and Genre.genre) after the SELECT command. I do this to avoid creating a duplicate id column in the table that results from the JOIN — one id from the Film table and one id from the Genre table. Because the default for JOIN is inner, and inner joins return only records that are overlapping or shared between tables, Film 1 is omitted from the results (because of its missing Genre value).
If you want to return all rows, even ones with NULL values, simply do a full outer join, like the one shown in Listing 7-3.
LISTING 7-3: A Full Outer JOIN
SELECT Film.id, Film.title, Genre.genre
FROM Film
FULL JOIN Genre On Genre.id=Film.id
id title genre
1 The Even Couple NULL
2 The Fourth Man Drama
3 All About Adam Drama
4 Dr. Yes Thriller
To aggregate values so that you can figure out the average rating for a film, use the GROUP statement. (GROUP statement commands include MAX(), MIN(), COUNT(), or AVG().)
Listing 7-4 shows one way you can aggregate values in order to return the average rating of each film. The SELECT function uses the AS statement to rename the column to make sure it was properly labeled. The Film and Ratings tables had to be joined and, because Dr. Yes had no ratings and an inner join was used, that film was left out.
LISTING 7-4: Using a GROUP Statement to Aggregate Data
SELECT Film.title, AVG(rating) AS avg_rating
FROM Film
JOIN Rating On Film.id=Rating.id
GROUP BY Film.title
title avg_rating
All About Adam 3.5
The Even Couple 4.0
The Fourth Man 4.5
To narrow the results even further, add a HAVING clause at the end, as shown in Listing 7-5.
LISTING 7-5: A HAVING Clause to Narrow Results
SELECT Film.title, AVG(rating) AS avg_rating
FROM Film
JOIN Rating On Film.id=Rating.id
GROUP BY Film.title
HAVING avg_rating >= 4
title avg_rating
The Even Couple 4.0
The Fourth Man 4.5
The code in Listing 7-5 limits the data your query returns so that you get only records of titles that have an average rating greater than or equal to 4.
Though SQL can do some basic text mining, packages such as Natural Language Toolkit in Python (NLTK, at www.nltk.org) and General Architecture for Text Engineering (GATE, at https://gate.ac.uk) are needed in order to do anything more complex than count words and combinations of words. These more advanced packages can be used for preprocessing data in order to extract linguistic items such as parts of speech or syntactic relations, which can then be stored in a relational database for later querying.
Making Life Easier with Excel
Microsoft Excel holds a special place among data science tools. It was originally designed to act as a simple spreadsheet. Over time, however, it has become the people’s choice in data analysis software. In response to user demands, Microsoft has added more and more analysis and visualization tools with every release. As Excel advances, so do its data munging and data science capabilities. (In case you’re curious, data munging involves reformatting and rearranging data into more manageable formats that are usually required for consumption by other processing applications downstream.) Excel 2013 includes easy-to-use tools for charting, PivotTables, and macros. It also supports scripting in Visual Basic so that you can design scripts to automate repeatable tasks.
The benefit of using Excel in a data science capacity is that it offers a fast-and-easy way to get up close and personal with your data. If you want to browse every data point in your dataset, you can quickly and easily do this using Excel. Most data scientists start in Excel and eventually add other tools and platforms when they find themselves pushing against the boundaries of the tasks Excel is designed to do. Still, even the best data scientists out there keep Excel as an important tool in their tool belt. When working in data science, you might not use Excel every day, but knowing how to use it can make your job easier.
If you’re using Excel spreadsheets for data analysis but finding it to be rather buggy and clunky, I recommend that you instead test out Google Sheets — Google’s cloud-based version of an Excel spreadsheet. It can be run offline on your computer, and it offers an ease-of-use and a set of collaborative features that simply aren’t available within the Microsoft Office environment today. Google Sheets offers all the same functions discussed in this chapter, using all the same commands as Excel spreadsheets, but most users find Sheets to be a far more intuitive, extensible tool for data analysis, visualization, and collaboration.
Although you have many different tools available to you when you want to see your data as one big forest, Excel is a great first choice when you need to look at the trees. Excel attempts to be many different things to many different kinds of users. Its functionality is well-compartmentalized in order to avoid overwhelming new users while still providing power users with the more advanced functionality they crave. In the following sections, I show you how you can use Excel to quickly get to know your data. I also introduce Excel PivotTables and macros and tell you how you can use them to greatly simplify your data clean-up and analysis tasks.
Using Excel to quickly get to know your data
If you’re just starting off with an unfamiliar dataset and you need to spot patterns or trends as quickly as possible, use Excel. Excel offers effective features for exactly these purposes. Its main features for a quick-and-dirty data analysis are
- Filters: Filters are useful for sorting out all records that are irrelevant to the analysis at hand.
- Conditional formatting: Specify a condition, and Excel flags records that meet that condition. By using conditional formatting, you can easily detect outliers and trends in your tabular datasets.
- Charts: Charts have long been used to visually detect outliers and trends in data, so charting is an integral part of almost all data science analyses.
To see how these features work in action, consider the sample dataset shown in Figure 7-3, which tracks sales figures for three employees over six months.
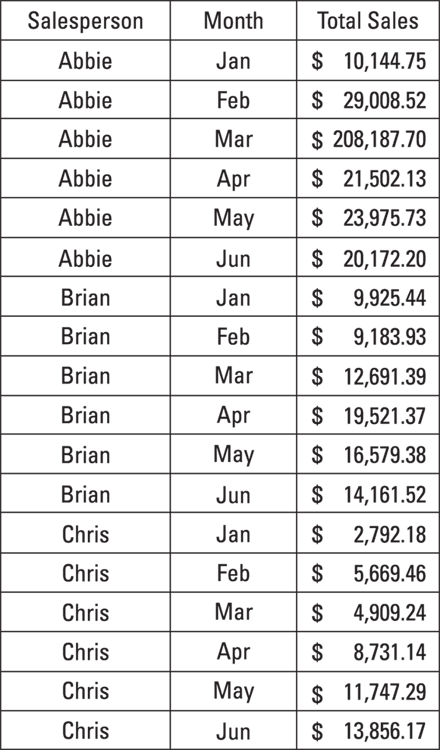
FIGURE 7-3: The full dataset that tracks employee sales performance.
Filtering in Excel
To narrow your view of your dataset to only the data that matters for your analysis, use Excel filters to filter out irrelevant data from the data view. Simply select the data and click the Home tab’s Sort & Filter button, and then choose Filter from the options that appear. A little drop-down option then appears in the header row of the selected data so that you can select the classes of records you want to have filtered from the selection. Using the Excel Filter functionality allows you to quickly and easily sort or restrict your view to only the subsets of the data that interest you the most.
Take another look at the full dataset shown in Figure 7-3. Say you want to view only data related to Abbie’s sales figures. If you select all records in the Salesperson column and then activate the filter functionality (as just described), from the drop-down menu that appears you can specify that the filter should isolate only all records named Abbie, as shown in Figure 7-4. When filtered, the table is reduced from 18 rows to only 6 rows. In this particular example, that change doesn’t seem so dramatic, but when you have hundreds, thousands, or even a million rows, this feature comes in very, very handy.
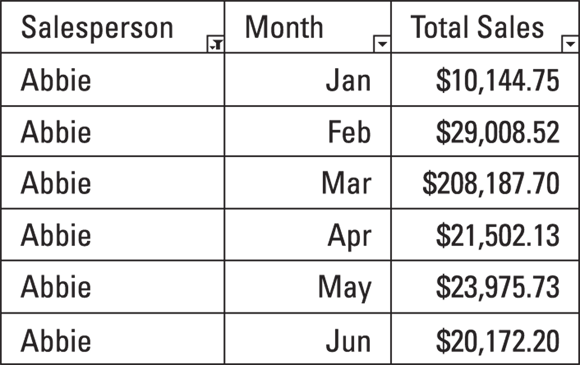
FIGURE 7-4: The sales performance dataset, filtered to show only Abbie’s records.
 Excel lets you store only up to 1,048,576 rows per worksheet.
Excel lets you store only up to 1,048,576 rows per worksheet.
Using conditional formatting
To quickly spot outliers in your tabular data, use Excel’s Conditional Formatting feature. Imagine after a data entry error that Abbie’s March total sales showed $208,187.70 but was supposed to be only $20,818.77. You're not quite sure where the error is located, but you know that it must be significant because the figures seem off by about $180,000.
To quickly show such an outlier, select all records in the Total Sales column and then click the Conditional Formatting button on the Ribbon’s Home tab. When the button’s menu appears, choose the Data Bars option. Doing so displays the red data bar scales shown in Figure 7-5. With data bars turned on, the bar in the $208,187.70 cell is so much larger than any of the others that you can easily see the error.
If you want to quickly discover patterns in your tabular data, you can choose the Color Scales option (rather than the Data Bars option) from the Conditional Formatting menu. After correcting Abbie’s March Total Sales figure to $20,818.77, select all cells in the Total Sales column and then activate the Color Scales version of conditional formatting. Doing so displays the result shown in Figure 7-6. From the red-white-blue heat map, you can see that Abbie has the highest sales total and that Brian has been selling more than Chris. (Okay, you can’t see the red-white-blue in my black-and-white figures, but you can see the light-versus-dark contrast.) Now, if you only want to conditionally format Abbie’s sales performance relative to her own total sales (but not Brian and Chris’ sales), you can select only the cells for Abbie (and not the entire column).
Excel charting to visually identify outliers and trends
Excel’s Charting tool gives you an incredibly easy way to visually identify both outliers and trends in your data. An XY (scatter) chart of the original dataset (refer to Figure 7-3) yields the scatterplot shown in Figure 7-7. As you can see, the outlier is overwhelmingly obvious when the data is plotted on a scatter chart.

FIGURE 7-5: Spotting outliers in a tabular dataset with conditional formatting data bars.

FIGURE 7-6: Spotting outliers in a tabular dataset with color scales.
Alternatively, if you want to visually detect trends in a dataset, you can use Excel’s Line Chart feature. The data from Figure 7-6 is shown as a line chart in Figure 7-8. It’s worth mentioning, I’ve fixed the outlier in this line graph, which is what allows the Y-axis to have a more readable scale compared to Figure 7-7.
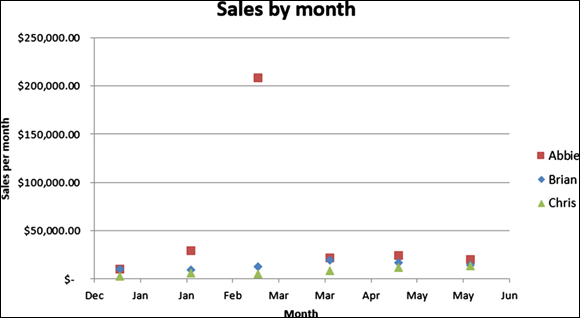
FIGURE 7-7: Excel XY (scatter) plots provide a simple way to visually detect outliers.
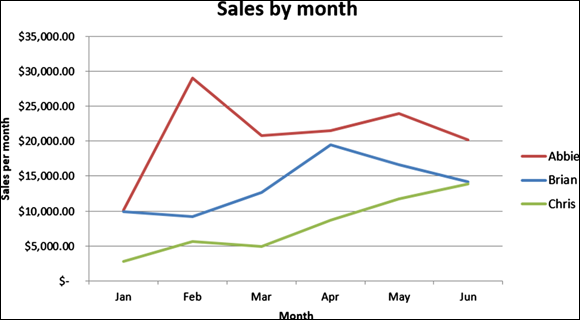
FIGURE 7-8: Excel line charts make it easy to visually detect trends in data.
As you can clearly see from the figure, Chris’s sales performance is low — last place among the three salespeople but gaining momentum. Because Chris seems to be improving, maybe management would want to wait a few months before making any firing decisions based on sales performance data.
Reformatting and summarizing with PivotTables
Excel developed the PivotTable to make it easier for users to extract valuable insights from large sets of spreadsheet data. If you want to generate insights by quickly restructuring or reclassifying your data, use a PivotChart. One of the main differences between a traditional spreadsheet and a dataset is that spreadsheets tend to be wide (with a lot of columns) and datasets tend to be long (with a lot of rows). Figure 7-9 clearly shows the difference between a long dataset and a wide spreadsheet.
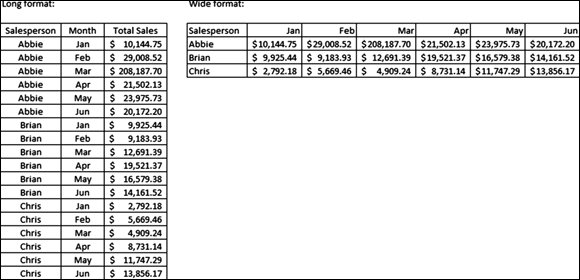
FIGURE 7-9: A long dataset and a wide spreadsheet.
A PivotTable is a table that’s derived from data that sits within a spreadsheet. The pivot allows for grouping, rearrangement, display, and summary of the raw data that’s stored within the underlying spreadsheet.
The way that Excel is designed leads many users to intuitively prefer the wide format — which makes sense because it’s a spreadsheet application. To counter this preference, however, Excel offers the pivot table feature so that you can quickly convert between long and wide formats. You can also use PivotTables to quickly calculate subtotals and summary calculations on your newly formatted and rearranged data tables.
Creating PivotTables is easy: Just select all cells that comprise the table you seek to analyze. Then click the PivotTable button on the Insert tab. This action opens the Create PivotTable dialog box, where you can define where you want Excel to construct the PivotTable. Select OK and Excel automatically generates a PivotField Interface on the page you’ve specified. From this interface, you can specify the fields you want to include in the PivotTable and how you want them to be laid out.
The table shown in Figure 7-10 was constructed using the long-format sales performance data shown in Figure 7-9. It’s an example of the simplest possible PivotTable that can be constructed, but even at that, it automatically calculates subtotals for each column and those subtotals automatically update when you make changes to the data. What’s more, PivotTables come with PivotCharts — data plots that automatically change when you make changes to the PivotTable filters based on the criteria you’re evaluating.

FIGURE 7-10: Creating a wide data table from the long dataset via a PivotTable.
You can do a lot more sophisticated analytical work in Excel than just creating PivotTables, although they are handy. Over on the companion website to this book, http://www.businessgrowth.ai/, I give you some basic training in how to use Excel and XLMiner to implement data science without needing to touch a single line of code.
Automating Excel tasks with macros
Macros are prescripted routines written in Visual Basic for Applications (VBA). You can use macros to decrease the amount of manual processing you need to do when working with data in Excel. For example, within Excel, macros can act as a set of functions and commands that you can use to automate a wide variety of tasks. If you want to save time (and hassle) by automating Excel tasks that you routinely repeat, use macros.
To access macros, first activate Excel’s Developer tab from within the Options menu on the File tab. (In other words, after opening the Options menu, choose Customize Ribbon from your choices on the left and then click to select the Developer check box in the column on the right.) Using the Developer tab, you can record a macro, import one that was created by someone else, or code your own in VBA.
To illustrate macros in action, imagine that you have a column of values and you want to insert an empty cell between each one of the values, as shown in Figure 7-11. Excel has no easy, out-of-the-box way to make this insertion. Using Excel macros, however, you can ask Excel to record you while you step through the process one time, and then assign a key command to this recording to create the macro. After you create the macro, every time you need to repeat the same task in the future, just run the macro by pressing the key command, and the script then performs all required steps for you.

FIGURE 7-11: Using a macro to insert empty cells between values.
Macros have an Absolute mode and a Relative mode. The Absolute mode refers to a macros routine that runs absolutely the way you recorded it — all the way down to the spreadsheet cell positions in which the routine was recorded. Relative mode macros run the same routine you record but can be placed in whatever cell position you need within the spreadsheet.
When you record a macro, it records in Absolute mode by default. If you want it to record the macro in Relative mode instead, you need to select the Use Relative References option before recording the macro.
For a more formal definition of Absolute and Relative macros, consider this:
- Relative: Every action and movement you make is recorded as relative to the cell that was selected when you began the recording. When you run the macro in the future, it will run in reference to the cell that’s selected, acting as though that cell were the same cell you had initially selected when you recorded the macro.
- Absolute: After you start recording the macro, every action and movement you make is repeated when you run the macro in the future, and those actions or movements aren’t made in any relative reference to whatever cell was active when you started recording. The macro routine is repeated exactly as you recorded it.
In the preceding example, the macro was recorded in Relative mode. This enables the macro to be run continuously, anywhere, and on top of results from any preceding macros run. Since, in this scenario, the macro recorded only one iteration of the process, if it had been recorded in Absolute mode, every time it was run the macro would have kept adding a space between only the one and two values. In other words, it would not have operated on any cells other than the ones it was recorded on.
Macro commands aren’t entered into Excel’s Undo stack. If you use a macro to change or delete data, you’re stuck with that change.
Test your macros first and save your worksheets before using them so that you can revert to the saved file if something goes wrong.
Excel power users often graduate to programming their own macros using VBA. Because VBA is a full-fledged programming language, the possibilities from pairing Excel with VBA are almost endless. Still, ask yourself this question: If you’re going to invest time in learning a programming language, do you need to work within the confines of Excel’s spreadsheet structure? If not, you might consider learning a scientific computing language, like R or Python. These open-source languages have a more user-friendly syntax and are much more flexible and powerful.