Chapter 19
Ten Phenomenal Resources for Open Data
IN THIS CHAPTER
 Accessing open data from government sources
Accessing open data from government sources
Getting data from the World Bank
Looking at private sources of open data
Exploring the world of open spatial data
Open data is part of a larger trend toward a less restrictive, more open understanding of the idea of intellectual property, a trend that’s been gaining tremendous popularity over the past decade. Think of open data as data that has been made publicly available and is permitted to be used, reused, built on, and shared with others. Maybe you’ve heard of open-source software, open hardware, open-content creative work, open access to scientific journals, and open science. Along with open data, they’re all part of the aptly named open movement — a movement committed to the notion that content (including raw data from experiments) should be shared freely.
The distinguishing feature of open licenses is that they have copyleft instead of copyright. With copyleft, the only restriction is that the source of the work must be identified, sometimes with the caveat that derivative works can’t be copyrighted with a more restrictive license than the original. If the second condition is in force, successfully commercializing the work itself becomes difficult, although people often find plenty of other indirect, creative avenues of commercialization.
 Be aware that sometimes work that’s labeled as open may not fit the accepted definition. You’re responsible for checking the licensing rights and restrictions of the open data you use.
Be aware that sometimes work that’s labeled as open may not fit the accepted definition. You’re responsible for checking the licensing rights and restrictions of the open data you use.
People often confuse open licenses with Creative Commons licenses. Creative Commons is a not-for-profit organization that’s dedicated to encouraging and spreading creative works by offering a legal framework through which usage permissions can be granted and obtained so that sharing parties are safe from legal risks when building on and using work and knowledge that’s been openly shared. Some Creative Commons licenses are open, and some explicitly forbid derivative works and/or commercialization.
As part of more recent open government initiatives, governments around the world began releasing open government data. Governments generally provide this data so that it can be used by volunteer analysts and civic hackers — programmers who work collaboratively to build open-source solutions that use open data to solve social problems — in an effort to benefit society at large. In 2013, the G8 nations (France, the United States, the United Kingdom, Russia, Germany, Japan, Italy, and Canada) signed a charter committing themselves to open data, prioritizing the areas of national statistics, election results, government budgets, and national maps.
The open government movement promotes government transparency and accountability, nurtures a well-informed electorate, and encourages public engagement. To put it in computing terms, open government facilitates a read/write relationship between a government and its citizenry.
Digging Through data.gov
The Data.gov program (at www.data.gov) was started by the administration of former US president Barrack Obama to provide open access to nonclassified US government data. Data.gov data is being produced by all departments in the executive branch — the White House and all cabinet-level departments — as well as datasets from other levels of government. By mid-2014, you could search for over 100,000 datasets by using the Data.gov search. The website is an unparalleled resource if you’re looking for US-government-derived data on the following indicators:
- Economic: Find data on finance, education, jobs and skills, agriculture, manufacturing, and business.
- Environmental: Looking for data on energy, climate, geospatial, oceans, and global development? Look no further.
- STEM industry: Your go-to place for anything related to science, technology, engineering, or mathematics — data on energy science and research, for example.
- Quality of life: Here you can find data on weather patterns, health, and public safety.
- Legal: If your interests lean in a more legalistic direction, Data.gov can help you track down data on law and ethics.
 Data.gov’s data policy makes federal data derived from this source extremely safe to use. The policy says, “U.S. Federal data available through Data.gov is offered free and without restriction. Data and content created by government employees within the scope of their employment are not subject to domestic copyright protection.” And because it comes in countless formats — including XLS, CSV, HTML, JSON, XML, and geospatial — you can almost certainly find something you can use.
Data.gov’s data policy makes federal data derived from this source extremely safe to use. The policy says, “U.S. Federal data available through Data.gov is offered free and without restriction. Data and content created by government employees within the scope of their employment are not subject to domestic copyright protection.” And because it comes in countless formats — including XLS, CSV, HTML, JSON, XML, and geospatial — you can almost certainly find something you can use.
Datasets aren’t the only things that are open on Data.gov. You can also find over 60 open-source application programming interfaces (APIs) available on the platform. You can use these APIs to create tools and apps that pull data from government departments listed in the Data.gov data catalog. The catalog itself uses the popular open-source CKAN API. (CKAN here is short for Comprehensive Knowledge Archive Network.) Even the code used to generate the Data.gov website is open source and is published on GitHub (at https://github.com/ckan/ckan), in case you’re interested in digging into that.
Data.gov allocates hundreds of thousands of dollars in prizes per year for app development competitions. If you’re an app developer looking for a fun side project that has the potential to provide you with financial rewards while also offering you an opportunity to make a positive impact on society, check out the Data.gov competitions. Examples of popular apps developed in these competitions are an interactive global hunger map and an app that calculates and tracks bus fares, routes, and connections in Albuquerque, New Mexico, in real-time.
Checking Out Canada Open Data
For many decades, Canada has been a world leader for its data collection and publication practices. Both The Economist and the Public Policy Forum have repeatedly named Statistics Canada — Canada’s federal department for statistics — as the best statistical organization in the world.
If you take a look at the Canada Open Data website (http://open.canada.ca), the nation’s strong commitment to data is overwhelmingly evident. At this site, you can find over 200,000 datasets. Among the 25 most popular offerings on the site are datasets that cover the following indicators:
- Environmental: Areas here include topics like natural disasters and fuel consumption ratings.
- Citizenship: Permanent resident applications, permanent resident counts, foreign student entry counts, and other items can be found here.
- Quality of life: Here you’ll find cost-of-living trends, automobile collision statistics, and disease surveillance, for example.
Canada Open Data issues its open data under an open government license — a usage license that’s issued by a government organization to specify the requirements that must be met in order to lawfully use or reuse the open data that the organization has released. Canada Open Data releases data under the Open Government License — Canada. You are required to acknowledge the source every time you use the data, as well as provide backlinks to the Open Government License — Canada page, at
Diving into data.gov.uk
The United Kingdom got off to a late start in the open government movement. Data.gov.uk (http://data.gov.uk) was started in 2010, and by mid-2014, only about 20,000 datasets were yet available. Like Data.gov (discussed in the section “Digging through Data.gov,” earlier in this chapter), data.gov.uk is also powered by the CKAN data catalog.
Although data.gov.uk is still playing catch-up, it has an impressive collection of ordnance survey maps old enough — 50 years or more — to be out of copyright. If you’re looking for world-renowned, free-to-use survey maps, data.gov.uk is an incredible place for you to explore. Beyond its stellar survey maps, data.gov.uk is a useful source for data on the following indicators:
- Environmental (data.gov.uk’s most prolific theme): They provide a range of data sets, including data on weather, floods, rivers, air quality, and geology.
- Government spending: The data sets in this collection include all payments of over £25,000 by government departments.
- Societal: These data sets include important information on employment rates, benefits, household finances, poverty, and population.
- Health: Visit this section to explore statistics about smoking, drugs and alcohol, medicine performance, and hospitals.
- Education: This section contains the data you’d need on students, training, qualifications, and the National Curriculum.
- Business and economic: This section of the website provides information on a variety of topics, including small business, industry, imports and exports, and trade.
Interestingly, the dataset most frequently downloaded from data.gov.uk is a dataset that covers the Bona Vacantia division — the government division charged with tracking the complicated processes involved in determining the proper inheritance of British estates.
Like the Canada Open Data website (see the preceding section), data.gov.uk uses an Open Government License, which means you’re required to acknowledge the data source every time you use it, as well as provide backlinks to the data.gov.uk Open Government License page at www.nationalarchives.gov.uk/doc/open-government-licence.
Although data.gov.uk is still young, it’s growing quickly, so check back often. If you can’t find what you’re looking for, the data.gov.uk website has tools you can use to specifically request the datasets you want to see.
Checking Out US Census Bureau Data
The US Census is held every ten years, and since 2010, the data has been made freely available at www.census.gov. Statistics are available down to the level of the census block — which aggregates by 30-person counts, on average. The demographics data provided by the US Census Bureau can be extremely helpful if you’re doing marketing or advertising research and need to target your audience according to the following classifications:
- Age
- Average annual income
- Household size
- Gender or race
- Level of education
In addition to its census counts on people in the United States, the bureau conducts a census of businesses. You can use this business census data as a source for practical industry research to tell you information such as the number of businesses, the number of employees, and the size of payroll per industry per state or metropolitan area.
Lastly, the US Census Bureau carries out an annual American Community Survey to track demographics with a statistically representative sample of the population during non-census years. You can check this data if you need specific information about what has happened during a particular year or set of years.
Some census blocks have a population density that’s far greater than average. When you use data from these blocks, remember that the block data has been aggregated over a person count that’s greater than the average 30-person count of census blocks.
With respect to features and functionality, the US Census Bureau has a lot to offer. You can use QuickFacts (www.census.gov/programs-surveys/sis/resources/data-tools/quickfacts.html) to quickly source and pull government data from the US federal, state, county, or municipal level.
If you’d like to download and further explore US Census data as well as census and survey data from other countries, head over to IPUMS (www.ipums.org/). This organization stores data on countries the world over, including US Census data from 1850-present, but makes it all easily downloadable into R for free!
Accessing NASA Data
Since its inception in 1958, NASA has made public all its nonclassified project data. It has been in the open data game so long that NASA has tons of data! NASA datasets have been growing even faster with recent improvements in satellite and communication technology. In fact, NASA now generates 4 terabytes of new earth-science data per day — that’s equivalent to over a million MP3 files. Many of NASA’s projects have accumulated data into the petabyte range.
NASA’s open data portal is called DATA.NASA.GOV (http://data.nasa.gov). This portal is a source of all kinds of wonderful data, including data about
- Astronomy and space (of course!)
- Climate
- Life sciences
- Geology
- Engineering
Some examples from its hundreds of datasets are detailed data on the color of Earth’s oceans, a database of every lunar sample and where it’s stored, and the Great Images in NASA (GRIN) collection of historically significant photographs.
Wrangling World Bank Data
The World Bank is an international financial institution that provides loans to developing countries to pay for capital investment that will lead (one hopes) to poverty reduction and some surplus so that the recipient nations can repay the loan amounts over time. It provides loans to developing countries to pay for capital investment that will lead (one hopes) to poverty reduction and some surplus so that the recipient nations can repay the loan amounts over time. Because World Bank officers need to make well-informed decisions about which countries would be more likely to repay their loans, they’ve gathered an enormous amount of data on member nations. They’ve made this data available to the public at the World Bank Open Data page (http://data.worldbank.org).
If you’re looking for data to buttress your argument in a truly interesting data-journalism piece that’s supported by global statistics, the World Bank should be your go-to source. No matter the scope of your project, if you need data about what’s happening in developing nations, the World Bank is the place to go. You can use the website to download entire datasets or simply view the data visualizations online. You can also use the World Bank’s Open Data API to access what you need.
World Bank Open Data supplies data on the following indicators (and many, many more):
- Agriculture and rural development: Here you’ll find data on major contract awards, contributions to financial intermediary funds, forest area, and rural population size data.
- Economy and growth: For the Big Picture — data on gross domestic product (GDP), gross capital formation, and agricultural value-added data, for example — no source is more exhaustive than World Bank Open Data.
- Environment: Data here can tell you all about methane emissions, nitrous oxide emissions, and water pollution.
- Science and technology: You can track patent applications and trademark applications data.
- Financial sector: Research the health (or lack thereof) of a national economy by looking at a nation’s bank capital-to-assets ratio, foreign direct investment, market capitalization, and new or supplemental project data.
- Poverty income: For a clear sense of how a country’s poorer population is faring, analyze the data associated with gross national income (GNI) per capita, income shares, and the poverty gap.
World Bank Data also includes microdata — sample surveys of households and businesses in developing countries. You can use microdata to explore variations in your datasets.
Getting to Know Knoema Data
Knoema (pronounced “no-mah”) purports to be the largest repository of public data on the web. The Knoema platform houses a staggering 500+ databases, in addition to its 150 million time series — 150 million collections of data on attribute values over time, in other words. Knoema includes, but isn’t limited to, all these data sources:
- Government data from industrial nations: Data from Data.gov, Canada Open Data, data.gov.uk, and Eurostat.
- National public data from developing nations: Data from countries such as India and Kenya.
- United Nations data: Includes data from the Food and Agriculture Organization, the World Health Organization, and many other UN organizations.
- International organization data: There’s more to the international scene than the United Nations, so if you’re looking for data from organizations such as the International Monetary Fund and the Organization for Economic Co-operation and Development, Knoema is where you want to be.
- Corporate data from global corporations: Knoema offers data made public by private corporations such as British Petroleum and BASF.
Knoema is an outstanding resource if you’re looking for international data on agriculture, crime statistics, demographics, economy, education, energy, environment, food security, foreign trade, health, land use, national defense, poverty, research and development, telecommunications, tourism, transportation, or water.
In addition to being an incredible data source, Knoema is a multifaceted tasking platform. You can use the Knoema platform to make dashboards that automatically track all your favorite datasets. You can use the platform’s data visualization tools to quickly and easily see your data in a tabular or map format. You can use the Knoema Data Atlas (http://knoema.com/atlas) to drill down among categories and/or geographic regions and quickly access the specific datasets you need. As an individual, you can upload your own data and use Knoema as a free hosting service.
Although a lot of Knoema’s data is pretty general, you can still find some surprisingly specific data as well. If you’re having a hard time locating data on a specific topic, you might have luck finding it on the Knoema platform. Figure 19-1 illustrates just how specific Knoema data can be.
FIGURE 19-1: The index of insect records in Knoema’s search.
Queuing Up with Quandl Data
Quandl (www.quandl.com) is a Toronto-based website that aims to be a search engine for numeric data. Unlike most search engines, however, its database isn’t automatically generated by spiders that crawl the web. Rather, it focuses on linked data that’s updated via crowdsourcing — updated manually via human curators, in other words.
Because most financial data is in numeric format, Quandl is an excellent tool for staying up-to-date on the latest business informatics. As you can see in Figure 19-2, a search for Apple returns over 4,700 datasets from 11 different sources with time series at the daily, weekly, monthly, quarterly, or annual level. Many of these results are related to the United Nations’ agricultural data. If you’re looking for data on Apple, you can narrow the scope of your search by replacing the Apple search term with the company’s stock abbreviation, AAPL.
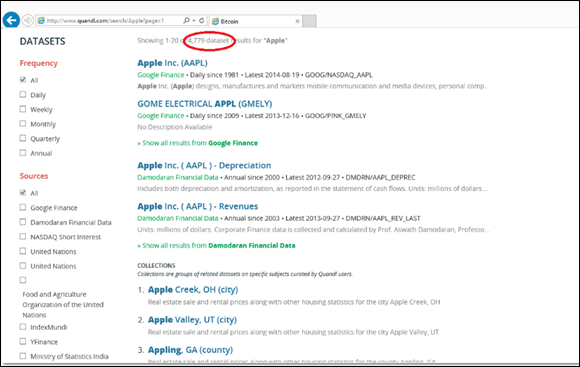
FIGURE 19-2: The index of Apple records in a Quandl search.
The Quandl database includes links to over 10 million datasets (although it uses a generous metric in declaring what distinguishes one dataset from another). Quandl links to 2.1 million UN datasets and many other sources, including datasets in the Open Financial Data Project, the central banks, real estate organizations, and well-known think tanks.
You can browse Quandl data and get instant charts based on what you find. If you sign up for a free registered account, you can download as much data as you want or use the Quandl application programming interface (API). The Quandl Application Programming Interface (API) includes wrappers to accommodate platforms such as Java, Python, Julia, R, MATLAB, Excel, and Stata, among others. (In case you’re new to wrappers, think of them as a collection of functions that make it easier to interact with an API. They're language-specific and are sometimes called “wrappers” because they wrap the API calls into easy-to-use functions.)
Exploring Exversion Data
Modeled after GitHub — the cloud-hosted platform across which programmers can collaboratively share and review code — Exversion aims to provide the same collaborative functionality around data that GitHub provides around code. The Exversion platform offers version control functionality and hosting services for uploading and sharing your data. To illustrate how Exversion works, imagine a platform that would allow you to first fork (or copy) a dataset and then make the changes you want. Exversion would be there to keep track of what has changed from the original set and every change that you make to it. Exversion also allows users to rate, review, and comment on datasets.
Datasets hosted on the Exversion platform are either provided by a user or created by a spider that crawls and indexes open data to make it searchable from a single application programming interface (API). As with GitHub, with a free user account, all the data you upload to Exversion is public. If you’re willing to pay for an account, you can create your own, private data repositories. Also, with the paid account, you gain the option to share your data with selected users for collaborative projects.
When you work on collaborative projects, version control becomes vitally important — rather than learn this lesson the hard way, just start your project on a version-enabled application or platform. This approach will save you from a lot of problems in the future.
Exversion is extremely useful in the data-cleanup stage. Most developers are familiar with data-cleanup hassles. Imagine that you want to use a particular dataset, but in order to do so, you must insert tabs in all the right places to make the columns line up correctly. Meanwhile, the other 100 developers out there working with that dataset are doing exactly the same thing. In contrast, if you download, clean, and then upload the data to Exversion, other developers can use it and don’t have to spend their time doing the same work later. In this way, everyone can benefit from each other’s work, and each individual person can spend more time analyzing data and less time cleaning it.
Mapping OpenStreetMap Spatial Data
OpenStreetMap (OSM) is an open, crowd-sourced alternative to commercial mapping products such as Google Maps and ESRI ArcGIS Online. In OSM, users create, upload, or digitize geographic data into the central repository.
 The OSM platform is quite robust. Governments and private companies have started contributing to, and pulling from, the shared datasets. Even corporations as big as Apple are relying on OSM data. OSM now has over 1 million registered users. To illustrate how a person can create data in OSM, imagine that someone links the GPS system on their mobile phone to the OSM application. Because of this authorization, OSM can automatically trace the routes of roads while the person travels. Later, this person (or another OSM user) can go to the OSM online platform to verify and label the routes.
The OSM platform is quite robust. Governments and private companies have started contributing to, and pulling from, the shared datasets. Even corporations as big as Apple are relying on OSM data. OSM now has over 1 million registered users. To illustrate how a person can create data in OSM, imagine that someone links the GPS system on their mobile phone to the OSM application. Because of this authorization, OSM can automatically trace the routes of roads while the person travels. Later, this person (or another OSM user) can go to the OSM online platform to verify and label the routes.
The data in OSM isn’t stored as maps, but rather as geometric and text representations — points, lines, polygons, and map annotation — so all of OSM’s data can be quickly downloaded from the website and easily assembled into a cartographic representation via a desktop application.