Data has been touted as the new oil. Meaning it’s valuable. Very valuable. And big data – involving a wide variety and really huge amounts of it – means it’s big very valuable. You get the picture. Data is fuel to AI and so naturally it’ll want lots of it. What is data? Basically, various forms of information which can be stored, transmitted, analysed and changed. The English word ‘data’, taken from Latin in the seventeenth century and originally meaning ‘things known or assumed facts’ then used in science for the results collected in experiments, began to be used in computing in 1946 to mean ‘transmissible and storable computer information’.
We started creating data, then as time went on we generated more data than before, and now that we all have smart devices we generate mammoth motherlodes of data . . . so we call it big data! Truth is, it’s a very vague term but it comes down to having masses of it (extremely large datasets), many different types of it (names, phone numbers, videos, photos and other stuff) and it streaming in rapidly from data-collecting systems such as smartphone apps or social media or the internet of things (a system of interrelated computing devices, e.g. connected household appliances or fitness wearables and devices that can communicate with each other). But there’s no magic number of data points where a sudden level up occurs and . . .
*BING* ‘Achievement unlocked: BIG DATA!’
Nope. Whether datasets fall under the label of good old-fashioned data or the level-up big data for now remains a subjective measure.
Imagine owning one of the major social media companies with many millions, if not billions, of users. All of them are doing things like writing messages and uploading a million photos of their pets and food. This is definitely when you know you have big data. Where do you store all this data and what do you do with it? Well, as it turns out, massive server (powerful computer) storage systems can help with storing all this data and analysing it. You might own these servers personally or rent ‘space’ and data security services in the cloud from other companies (servers nowhere near you from which you rent data storage, like your cloud photos from your smartphone, and services, like automatically labelling and sorting those photos). Once you have loads of data and you want to understand it, or analyse it to find links and patterns, and your standard spreadsheet program just won’t cut it, this is where various forms of AI will help out.
Now if the data were a stack of different flavoured cupcakes, and the AI were a monkey, it’s going to go bananas over those cupcakes. It’ll consume them, and what will you end up with? A useless monkey who feels sick. But that’s if the data cupcakes are poor in quality, packed full of artificial colours and flavours. If, however, the cupcakes are of good quality, with baked-in nutritious value, you’ll have a happy monkey that’ll be bouncy and useful. Okay, this may be the worst analogy I’ve ever come up with . . .
What I’m saying is, like a diet, data should be clean and of good quality if you’re going to get something useful out of the AI. Feed it poor-quality data and it won’t learn well or with any reasonable level of usefulness. It’s like our AI monkey taking financial advice from ol’ mate Step Uncle Joe who blew all his money on the poker machines – you can’t expect amazing outcomes if the data the AI is learning from isn’t great. This becomes a big problem for the exponential capabilities of AI because humans are then tasked with sourcing high-quality data and creating cleaner datasets for AI, in particular for ML, to learn from (known as training), figuring out what data may be useful and even removing errors or cleaning noisy (difficult to interpret) data. Which in the case of big data is a right pain in the butt. This is where data science and planning can help, rather than just amassing anything and everything.
Even though I had nothing remotely close to big data when I designed my first brain–computer interface (BCI) for my mind-controlled wheelchair, TIM, I learnt this lesson the hard way. While designing my custom ANN, inspired by genetic algorithms in how it improved over time, I started out with some pretty useless data. Unfortunately, it took me months to realise this. Day after day I would stick electrodes to my scalp with conductive gel and use Velcro straps to hold them in place. I became accustomed to looking like a strange human science experiment, which I basically was at the time. I’d focus on various mental tasks and collect loads of electroencephalography (EEG) data (basically collecting brainwaves, as electrical signals of the brain). Every day for three months, I put myself through long days of data collection, often falling asleep because it was so tiring to focus that intently for such extended periods of time.
At the end of those three months I tried training my AI designs, and what did they learn? Zip, nada, zilch! I spent the next month training, updating and retraining the networks. To no avail. Eventually I learnt more about better set-ups for EEG and how to check you have a clean connection resulting in cleaner data collection. It was then I realised I had been trying to train the AI with useless data – the artificial-colours-and-flavours-cupcake variety. I scrapped months of data and started again, making sure I was collecting quality data this time. Sure enough my programs started learning. After I trialled many different learning methods and ran it on a single computer for weeks, it eventually spat out a useful trained AI that had learnt to tell the difference between four different thought patterns to a high degree of accuracy (nearly 90 per cent). This allowed me to make my mind-controlled wheelchair a reality in 2008.
Back to big data. ML can be used to make sense of massive sets of data, ultimately finding potentially useful patterns and differences in that data. We ourselves are great pattern-recognising systems. Our brain even gives us hits of dopamine as a reward chemical when we find interesting patterns – contributing to why you feel good when you solve a puzzle, or if you see an actor in a movie and remember what else they’ve been in you tell everyone around you too. Just so they can get in on some of that sweet dopamine action – cos sharing is caring! With AI there are a range of approaches depending on what the AI system is trying to learn. Take deep learning, an example of ML that has flourished in recent years. Deep learning was a big step in the evolution of AI, allowing such things as a neural network program to receive masses of input data, find the patterns and differences on its own and extract the features that are likely relevant. Once it has learnt in this way, it can classify and contextualise new input data. It can even be designed to continue learning while in operation.
Let’s use an analogy to understand the power of deep learning. Say you have a bunch of photos of animals from around the world and you give them to a young child. They would soon recognise patterns and could start to group the photos in categories of their own choosing. A deep learning system could be given a ton of these unlabelled photos and would not know what was what. But if trained to find patterns in the data through unsupervised learning, it would start to figure out patterns and differences on its own, creating various groups that the photos would fall into. It could recognise over time (and after seeing many, many photos) that if it saw a photo of a dog, it could bucket that into the collection of photos in which it has placed other dogs, without necessarily knowing what they are. Depending on how it learns, it might also throw wolves and other animals into this group. The child would likely do something similar, but then again some children might like to group the photos in terms of colour, so you can never be quite sure how this approach will turn out. The same goes for deep learning AI. The result may determine useful patterns in masses of data that may not have been apparent to the human eye or human-facilitated analyses.
On the other hand, if you were there to help the child learn through sharing your knowledge, you would show them a photo of a dog and let them know it’s a dog. Over time they would recognise what a dog looks like and know one when they saw one. This approach is called supervised learning; with a deep learning AI system, the photos would have been labelled. In semi-supervised learning, only some of the photos would have been labelled by a human. This labelling allows the system to know what the answers are in those cases and then organise the rest of the data in the same way. This is how your smartphone and cloud photo applications can automatically curate albums and even allow you to search for specific things. If you search through digital photo albums to find when you wore that red hat, because the system has already been trained on many other photos online, it already knows what a red hat looks like, and so it can identify which of your photos include a red hat.
When rewards are involved, such as when a deep learning system is trying to learn a game, it often falls under the ML category of reinforcement learning. Desirable actions, such as col-lecting useful items and progressing in the game, are reinforced with rewards (usually programmed as points), while undesirable actions, such as losing lives or having to restart a game, are reinforced with penalties (usually deducted points). This is an approach that works well for games and simulations.
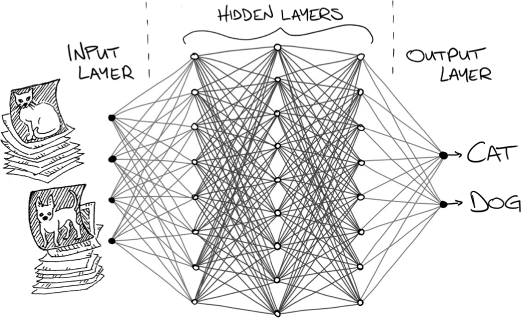
Deep neural networks basically have large sets of artificial neurons in layers, each of which can start looking for different patterns emerging from the range of data they have been fed. If the purpose is image classification to allow an AI to recognise objects like animals, and it has been shown a million pictures of various animals, and a portion of these had dogs in them, many of the neurons will structure themselves to look for various patterns recognisable in the dog photos it has seen. Many other neurons will structure themselves to look for other common features they’ve seen in the large image dataset, such as cats and cows and other animals.
Figure 3: Deep neural networks
The deep part of the learning is down to the multiple layers of these neurons. Just say we had a deep neural network with three hidden layers. The first hidden layer might have neurons that look for tiny patterns in photos, such as edges of various shapes; neurons of the second hidden layer might each look for slightly bigger shapes, such as eyes and nostrils; and neurons of the third hidden layer might individually look for large shapes, such as entire figures of animals. If the trained deep learning system was to then see a new photo of a cat, various neurons would find the shapes they are looking for (particularly those looking for kitty shapes) in this new photo, and so they would activate. Based on the combinations of activated neurons, the system could safely say with a high probability that it’s looking at a cat.
We do something similar within our own brain – though the processes of our brain are far more complex and capable than this approach – but here is something beautiful about what happens with us. A particular type of neuron we possess, known as a mirror neuron, form a physiological basis for empathy – our ability to understand and share the feelings of other people and to learn skills from them by watching. If you find yourself walking through a crowded place like a city, you may walk past hundreds or thousands of people, but if you see a single person look you in the eye and smile at you, you’ll remember it. For the rest of the day. For the rest of the week. Possibly for the rest of the year. And maybe even for the rest of your life.
Why? Well among many other things your brain and body do in that moment in response to receiving the eye contact and the smile, many of your mirror neurons are firing and having a party as they are activated by that kind of interpersonal connection event. Even some of the neurons that fire when you smile yourself will be activated just by seeing someone else doing it. The level of feeling you receive can be indicative of how empathetic you are at that point in time. I say that point in time, because it’s something that can change throughout our lives, meaning we can all work on becoming more empathetic. But isn’t this an awesome thing? We have neurons that will activate when we see someone smile, and even more so when they’re smiling at us.
I’ve witnessed my father work on many of these kinds of technologies over the years, and learnt all about neural networks from him. The RTX robot used these for a range of operations, and there was another machine set up nearby in that lab for experiments on computer vision. A computer was connected to a camera facing down onto a table with a stack of envelopes on it. You would take an envelope and handwrite a postcode, then place it under the camera. With a neural network trained to recognise the shapes of numbers, having learnt from a range of handwritten data, the computer would recognise the numbers written and display it on the old-school tube computer monitor. It would also show the probability for each handwritten digit across all ten digit possibilities, so we could see how certain it was of its classifications and if there was potential confusion with other digits. This process, called optical character recognition, is now used to convert a wide range of handwritten or printed text – from scanned documents, photos and the like – into digital text.
This was the beginning of the 1990s, and the field of AI has taken astronomical leaps since then. In 2015 I met Nolan Bushnell, one of the founding fathers of the video game industry, who in 1972 co-founded the pop-culture-icon company Atari (interestingly, the name is a reference to a check-like position in the game of Go). He was the first person the late Steve Jobs ever worked for. Nolan joined me on stage for a keynote I was giving on robotics and AI at a large creativity conference called Wired For Wonder – an amazing experience to share with a man who has had such a huge influence on computing and games of today. Backstage before we went on, we were sitting and having a chat. He took out his phone and asked me in a deep, American voice, ‘Have you ever played Crossy Road?’ I hadn’t even heard of it at the time, but he showed me this 8-bit endless arcade-style, Frogger-esque mobile hopper game, where you navigate your little character of choice to hop across traffic or across logs over water, avoid trains and collect coins. He handed me the phone and as I played we talked about games of the past. Some of my favourite Atari games were the iconic Space Invaders, Pong and Breakout. Before founding Apple Inc., Steve Jobs and Steve Wozniak had both been involved in the development of Breakout, made to be a one-player version of Pong.
At that time I met Nolan, some significant recent events had seen AI programs by DeepMind Technologies (an AI company from London that had been acquired by Google) independently learn to play 49 different Atari 2600 video games. It learnt through deep reinforcement learning by playing the games many times over and simply figuring out from the pixels on the screen what it could control in the game, and over time working out which actions led to rewards and which led to penalties. It soon outperformed professional human players in more than half of these games, including Space Invaders, Pong and Breakout. What’s more impressive is that it was often able to master these games within a matter of hours.
DeepMind soon went on to create AlphaGo, which toppled Lee Sedol in that historic match of 2016. This system first learnt from a dataset of more than 100,000 Go matches as a basis for its foray into the game. It then played many games against itself through self-play reinforcement learning (where it plays against itself). Move 37 of Game 2, the one that shook Lee Sedol, was significant because AlphaGo calculated that the chance of a human expert playing that move was one in 10,000. It was not a human move and at first looked like a mistake. It soon became apparent that it was strangely brilliant and different. To Lee Sedol, in retrospect, it was creative and beautiful. After five games over five days, AlphaGo emerged the victor, winning four games to one. The following year, now known as AlphaGo Master, it continued improving through playing many professionals. It went on to beat 60 professionals straight, including the world number one, Ke Jie, with three games to nil. It was another significant moment in the advancement of AI, but it didn’t stop there.
Now that the world’s best player in the ancient Chinese game of Go was this AI, the only true opponent would be a newer version of itself. This came in a next-generation version called AlphaGo Zero, which learnt Go in a different way. It was given the basic rules and then learnt from scratch, only playing games against itself through self-play reinforcement learning. It literally started with no prior knowledge of the game and used no human play in its learning. After three days it won 100 games to nil against the version of AlphaGo that defeated Lee Sedol. After 40 days of self-training it even convincingly surpassed the level of AlphaGo Master.
Another step forward and another newer design, AlphaZero, was created as a single system to learn from scratch and teach itself more than just Go. In just 24 hours of learning it beat not only AlphaGo Zero at Go, but also mastered chess and shogi (Japanese chess). This is thanks to its ability to play countless games and learn through experience so quickly that it can rack up much more game play than any human could possibly experience in a lifetime. That’s the power of computing these days. These advancements continue and we will soon see many more mind-boggling capabilities of self-learning AI.
Along the road towards a general AI, these systems will become more adaptable, self-learning many things about the world beyond gaming. Over time, features like improved contextual under-standing, connection, creativity and even emulated self-awareness and curiosity will evolve these technologies even further. It’s not a particularly comforting thought for many, especially when we start to think about the changes the age of automation and AI will bring to the workforce. The age-old question remains: will the destruction of jobs outstrip the opportunities, or vice versa?