Chapter 5 – Amazon DocumentD
B
Amazon DocumentDB Introduction
Amazon DocumentDB (DocumentDB) -- like RDS, Aurora and Neptune -- is yet another managed, platform-based data service offered by AWS, and thereby streamlines many mundane database admin tasks generally performed by DBAs. Also like Aurora and Neptune, DocumentDB is equipped with solid-state virtual storage facilities which are optimized for database workloads and deliberately engineered to significantly improve database performance, reliability, and availability. DocumentDB also
promotes high availability by enabling automatic failover to read replicas and data replication across availability zones.
Like Neptune, DocumentDB provides a fundamentally different alternative to SQL-based relational database approaches such as RDS, Aurora and Redshift (Redshift will be addressed next in Chapter 6). Instead, DocumentDB is an example of a
document database
(aka “document-oriented database” or “document store”) and boasts compatibility with
MongoDB
which is also categorized as a
NoSQL
database service
.
NoSQL, in this case, essentially means that DocumentDB provides a non-relational approach to managing semi-structured data based on key-value pairs and document storage. In particular, DocumentDB stores semi-structured data as documents in its document database. Documents are
self-describing
basically because they are composed of key-value pairs defined in a
JSON
-like format (i.e.,
BSON
, a binary representation of JSON).
40
DocumentDB’s compatibility with MongoDB suggests that applications developed using widely available MongoDB APIs, drivers, utilities and tools -- supported by many contemporary and popular programming languages -- will run compatibly in DocumentDB.
A document database -- in contrast to a relational database -- is very appealing to certain applications programmers who are comfortable with using the format of a document for accessing and changing data in a program. Application data can then be saved to a database in the same intuitive document format. For example, applications developers who advocate an
agile
software development approach (i.e., routinely anticipating frequent database design changes, in contrast to a more structured
waterfall
methodology) might prefer the flexibility offered by a document database.
41,42
This perspective differs from well-known SQL-based relational approaches, such as those database engines supported by RDS, for manipulating data stored in tables, rows and columns.
-
Collection
: A DocumentDB collection is a set of documents and corresponds to a table in an RDBMS database engine.
-
Document
: A document stores semi-structured data and uses key-value pairs (fields with values) to self-describe the structure of the data (i.e., the data schema) within the document. Each JSON-like formatted document, therefore, corresponds
to a row in a relational table. Differently formatted documents can be maintained in a document database.
-
Field
: Each document is composed of one or more fields each defined as a key-value pair. A field, therefore, somewhat corresponds to a column of a row in a relational table.
-
Embedded Document
:
Key-values pairs can be nested in a document thereby enabling complex documents which contain other embedded
documents. An embedded document groups fields at a lower level.
-
Object Id
: An object id is a required field serving as a document’s unique identifier and, therefore, corresponds to the concept of a primary key for a row in a relational table. The object id can be specified when a document is created or, otherwise, is automatically generated.
-
Array
: An array is a field mapped to a list of multiple values, such as an array of numbers or an array of character strings as values.
An example of a simple document is provided as follows:
{
"SSN": "123-45-6789",
“EmployeeID”: “PER-0001”,
"Name": "Random A. Person",
"DOB": "1990-01-01",
“Jobtitle”: “sales person”,
"Street": "1000 Any Street",
"City": "Any Town",
"State-Province": "NY",
"Country": "USA"
}
A subset of MongoDB CRUD operations (i.e., for creating, reading, updating, and deleting documents) is summarized as follows:
-
insertOne
: Analogous to a SQL INSERT statement, this operation creates a new document and inserts it into a specified collection. This operation creates the specified collection if it does not already exist.
-
insertMany
: Inserts an array of multiple documents into a specified collection. This operation also creates the specified collection if it does not already exist.
-
find
: Analogous to a SQL SELECT statement, this operation retrieves one or more documents from a specified collection. Various options are possible for specifying search criteria and specific fields to be returned.
-
updateOne
: Analogous to a SQL UPDATE statement, this operation updates a single document within a specified collection based on search criteria. Values for existing fields can be modified or new fields can be added to the document.
-
updateMany
: This method updates all documents that satisfy specified search criteria for a specified collection.
-
deleteOne
: Analogous to a SQL DELETE statement, this operation removes a single document from a specified collection based on search criteria.
-
deleteMany
: This method removes all documents that satisfy specified search criteria from a specified collection.
Documentation for many
additional MongoDB operations
including usage examples and variations of the above sampled operations is readily and freely available online.
4
4
DocumentDB Clusters
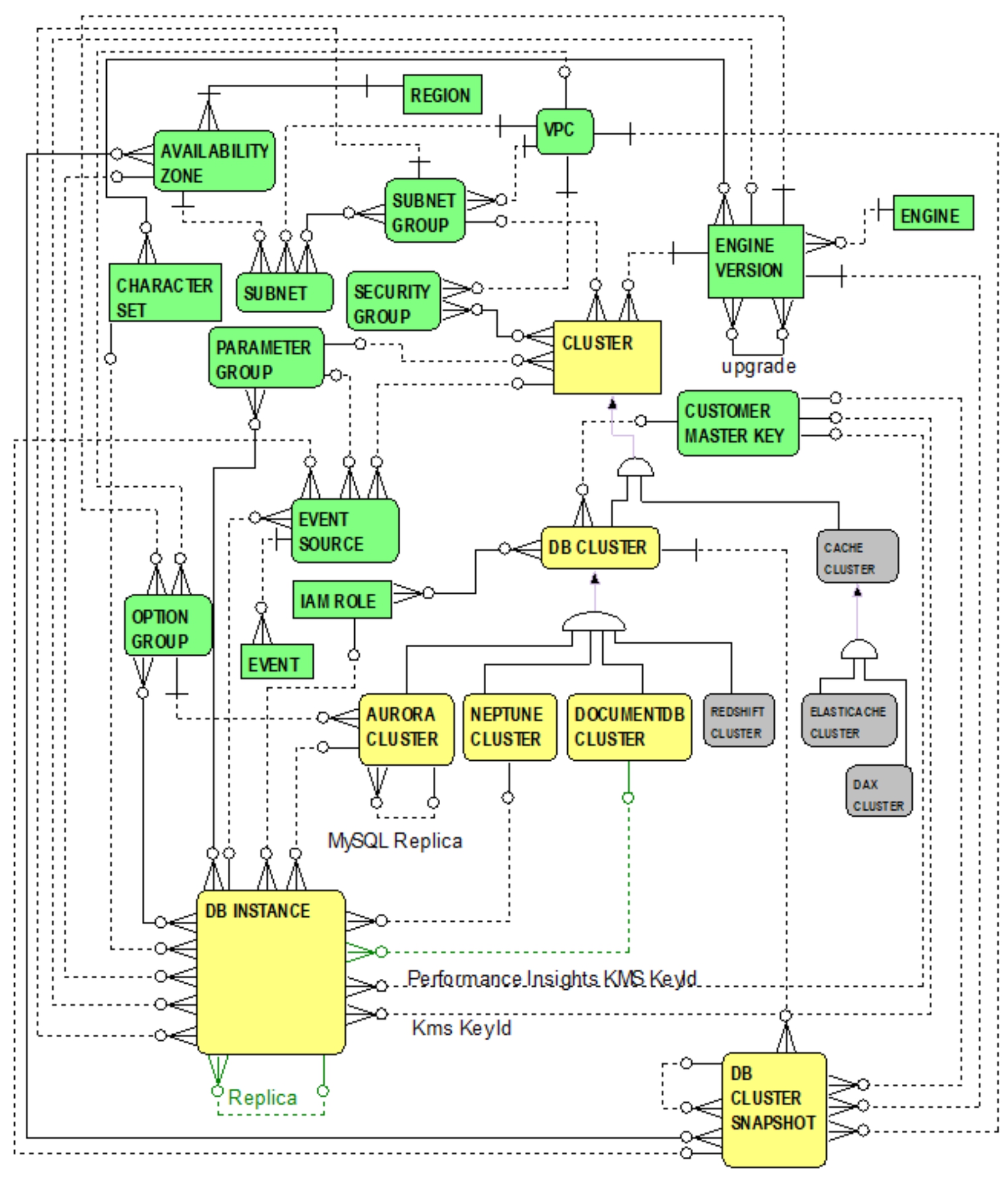
DocumentDB clusters are very similar to Aurora and Neptune clusters. However, a few noteworthy differences again justify differentiating DocumentDB clusters (from Aurora and Neptune clusters) by establishing a new entity, the DOCUMENTDB CLUSTER entity. Figure 5.1 introduces entities and relationships focusing on DocumentDB cluster fundamental concepts.
Figure 5.1 DocumentDB Entities and Relationships, Basic Concept
s
Figure 5.1 highlights the DOCUMENTDB CLUSTER entity and reaffirms the explanation of the CLUSTER entity and its sub-type hierarchy -- but this time emphasizing support for DocumentDB clusters. DocumentDB -- similar to Aurora and Neptune -- also enables the provisioning of a cluster of DB instances, consisting of a primary DB instance and as many as 15 read replica DB instances. The DOCUMENTDB CLUSTER entity -- at the same level as the AURORA CLUSTER, NEPTUNE CLUSTER and REDSHIFT CLUSTER entities -- is a sub-type of the DB CLUSTER entity. Each DOCUMENTDB cluster is a kind of
DB cluster and, therefore, directly inherits attributes and relationships from the DB CLUSTER entity. Indirectly, it also inherits attributes and relationships from the CLUSTER entity.
More specifically, as a sub-type of the DB CLUSTER entity, a DocumentDB cluster (i.e. the
document data maintained by all of its cluster DB instances) is optionally encrypted using a KMS customer master key, and benefits from one or more IAM roles enabling DocumentDB to access other AWS services on behalf of the DocumentDB cluster. From Figure 5.1 and as mentioned in the previous chapter, recall that a DocumentDB cluster -- as a kind of
DB cluster -- can be backed up by one or more DB cluster snapshots.
Common attributes inherited by the DOCUMENTDB CLUSTER entity from the DB CLUSTER entity include the following sample attributes also noted in previous chapters for Aurora and Neptune and repeated here for the reader’s convenience:
-
backup retention period:
The number of days that automatic backups are saved prior to being purged.
-
database name:
Identifies the name of the DB cluster’s initial database.
-
master username:
The master username for logging into the cluster’s DB instances.
-
storage encrypted:
Indicates whether or not the cluster’s data is encrypted.
Indirectly inherited from the CLUSTER entity, a DocumentDB cluster can serve as a source for event notifications and is associated with many security groups, a single subnet group, parameter group, and engine version. This means that a cluster of DB instances for a DocumentDB cluster has:
- A set of security groups for controlling access to DocumentDB cluster instances.
- A subnet group within whose subnets DocumentDB cluster instances can be launched.
- A single parameter group specifying parameters for configuring all cluster instances.
- The DocumentDB engine version for all cluster instances.
Common attributes indirectly inherited by the DOCUMENTDB CLUSTER entity from the CLUSTER entity include the sample attributes noted in previous chapters, repeated here as follows:
-
cluster identifier:
A user-supplied cluster identifier.
-
cluster create time:
The time when the cluster was created.
-
status:
Indicates the current state of the cluster.
-
endpoint:
Specifies the cluster’s access information (i.e., DNS host name and port number) enabling applications to connect to the cluster.
-
preferred maintenance window:
Identifies the time period when maintenance activities (e.g., system upgrades) are preferred.
The one-to-many relationship from DOCUMENTDB CLUSTER entity to the DB INSTANCE entity indicates that each DocumentDB cluster is composed of one or more DB instances (i.e., all DB instances running the same DocumentDB engine version). One DB instance is primary and the remaining servers are read replicas. For example, when creating a DocumentDB cluster via the DocumentDB console, a user specifies the total number of DB instances to be launched for the cluster. This includes the primary DB instance -- automatically created for reading, writing and modifying data to the cluster volume -- and the remaining DB instances created as read replicas. By default a primary instance and two additional read replica DB instances are launched.
From 5.1, the three optional one-to-many relationships from AURORA CLUSTER, NEPTUNE CLUSTER and DOCUMENTDB CLUSTER entities to the DB INSTANCE entity are meant to convey that each DB instance is exclusively either: 1) a member of an Aurora cluster, or 2) a member of a Neptune cluster, or 3) a member of a DocumentDB cluster, or 4) neither … simply a standalone RDS instance not participating in a cluster.
One or more replica DB instances -- possibly in separate availability zones for achieving high availability -- can be added to a DocumentDB cluster using the DocumentDB console, CLI, or API. After a DocumentDB cluster is created, conventional MongoDB tools and utilities (e.g., the
MongoDB Shell
for connecting and executing CRUD commands,
45
as well as MongoDB drivers and APIs for a variety of programming languages.) running on client EC2 instances are used for developing DocumentDB applications.
As for Aurora and Neptune, the one-to-many reflexive relationship from the DB INSTANCE entity to itself also applies to DB instances for a DocumentDB cluster. This indicates that possibly many DB instances can serve as read replicas for a primary DB instance (i.e., a primary DB instance is synchronized to possibly many read replicas). From a data modeling perspective, note that for Aurora and Neptune this fact is substantiated -- in API documentation for both Aurora and Neptune -- by the presence of a Read Replica Source DBInstance Identifier
as an attribute of the DB Instance
data type. For a read replica DB instance, this attribute contains the ID of the primary DB instance (i.e., the replica’s source DB instance) and amounts to a foreign key. This attribute, however, is omitted from the
DB Instance
data type in the DocumentDB developer guide. Nevertheless, from the standpoint of creating a conceptual data model, this concept still applies to DocumentDB and is valid for describing the notion of data replication from the primary instance to its read replicas.
In addition to previously described attributes inherited from its super-type hierarchy (i.e., foreign keys and other attributes inherited from the CLUSTER and DB CLUSTER entities), noteworthy examples of attributes pertinent to the DOCUMENTDB CLUSTER entity include:
-
multi AZ
: Indicates high availability in that DB instances are provisioned in more than one availability zone
.
-
preferred backup window:
If automatic backups are enabled, this indicates the time range, a user-defined daily time window, when automated backups are created.
-
earliest restorable time:
For restoring a cluster to a specific point-in-time, the earliest possible time in the past the cluster can be recovered.
-
latest restorable time:
For restoring a cluster to a specific point-in-time, the latest possible time in the past the cluster can be recovered.
DocumentDB, Neptune and Aurora Cluster Comparison
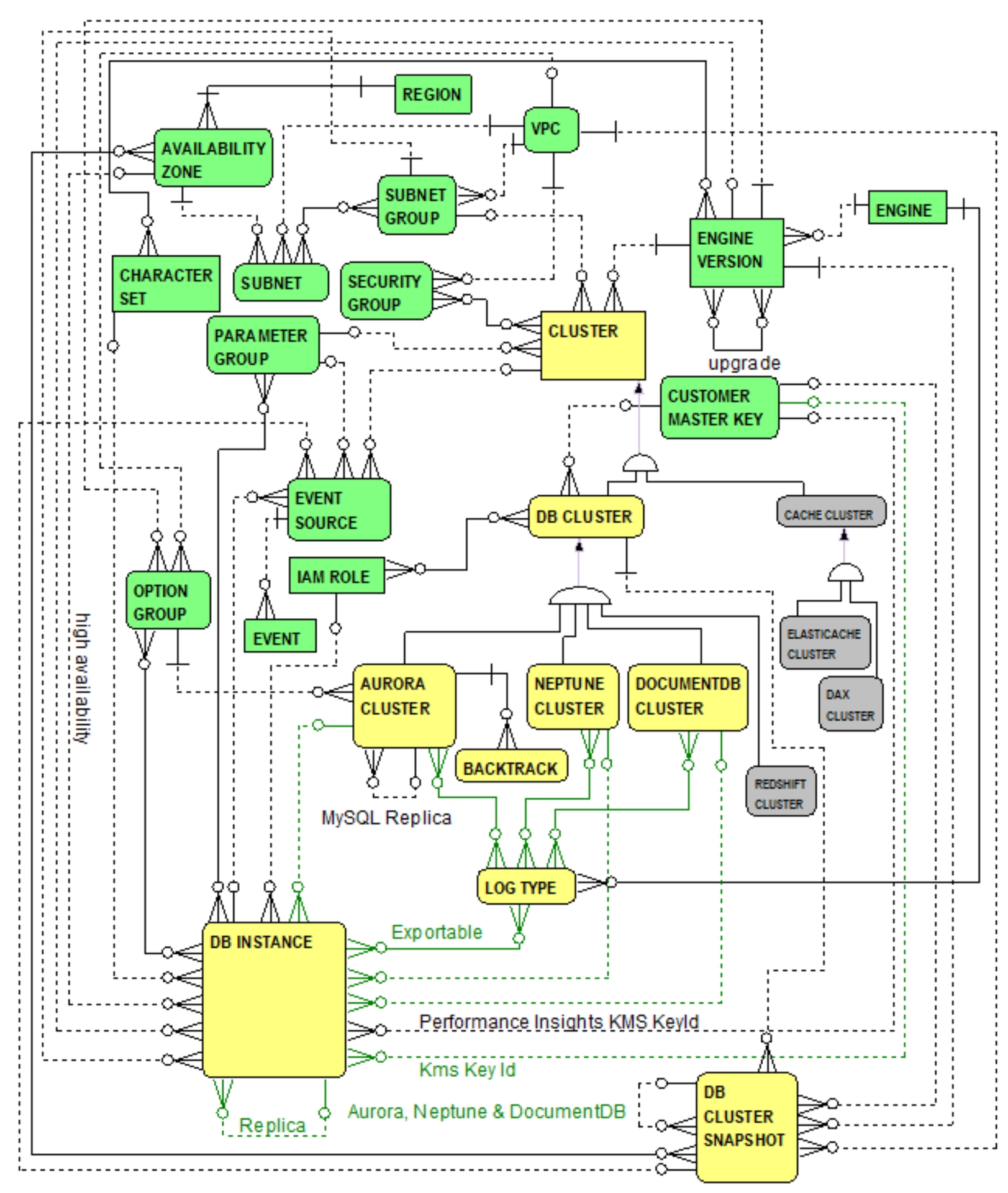
Clearly from the previous section, DocumentDB clusters are similar to Aurora and Neptune clusters. DocumentDB clusters, however, have several noteworthy differences in contrast to Aurora and Neptune clusters which justify establishing the DOCUMENTDB CLUSTER entity as a separate sub-type of the DB CLUSTER entity. Figure 5.2 first highlights DocumentDB, Aurora and Neptune similarities.
Figure 5.2 DocumentDB, Aurora and Neptune Similarities
From Figure 5.2, the following similarities are highlighted (i.e., relationships highlighted in green):
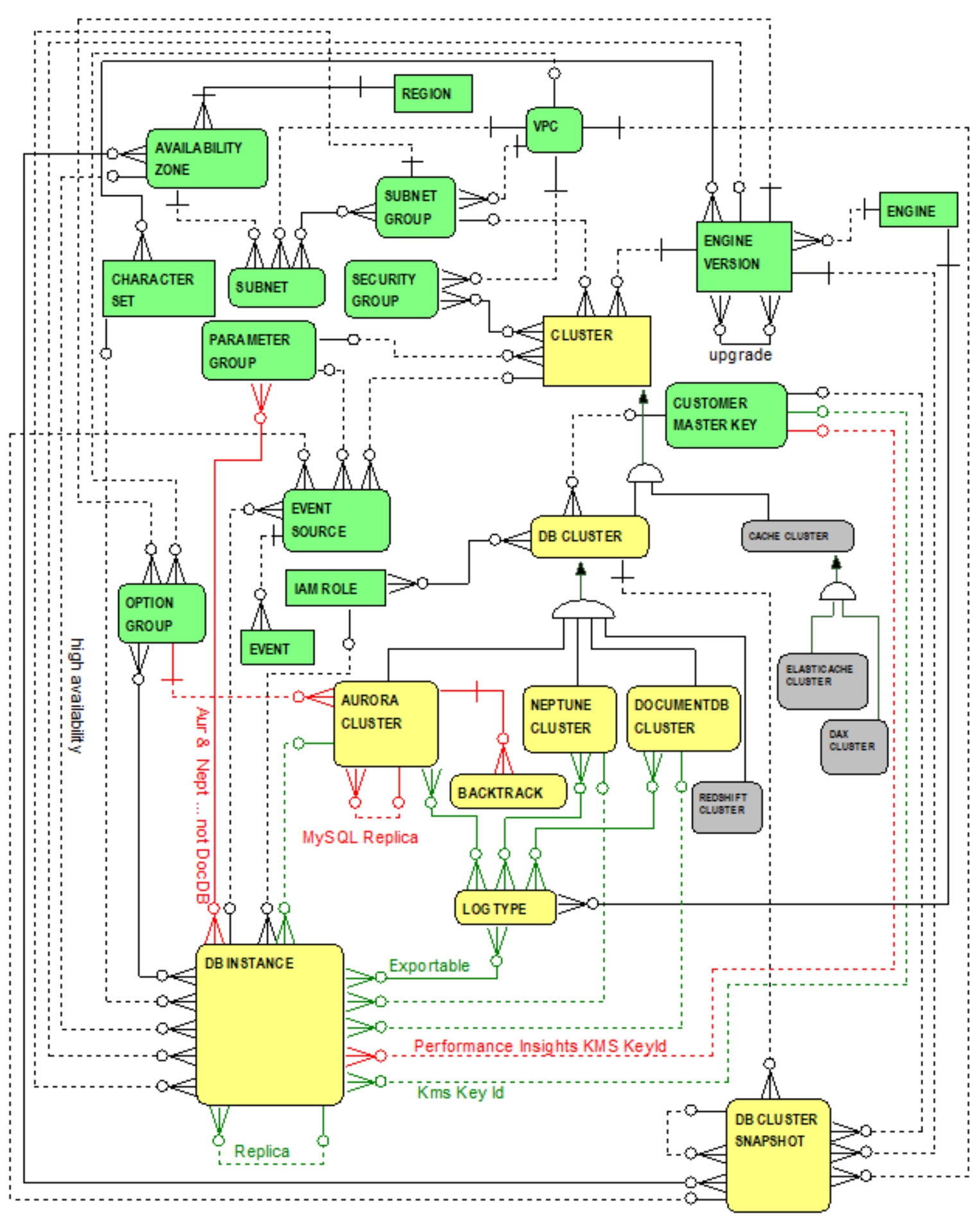
Figure 5.3 highlights DocumentDB, Aurora and Neptune differences.
Figure 5.3 DocumentDB, Aurora and Neptune Differences
From Figure 5.3, the following differences are highlighted (i.e., relationships highlighted in red):
- Unlike Aurora, both DocumentDB and Neptune do not support backtracking and serverless clusters. Lack of DocumentDB and Neptune support for backtracking and serverless clusters means that the following attributes -- conveniently repeated here from the previous chapter -- are applicable to Aurora clusters but are not applicable
to DocumentDB and Neptune
clusters:
-
backtrack consumed change records
: The count of backtrack change records retained for the cluster.
-
backtrack window
: Amount of time in seconds for which a backtrack may be wanted, (e.g., a target backtrack window of 48 hours).
-
earliest backtrack time
: The earliest time for which a DB cluster backtrack can be requested (e.g., based on accumulated change records and available storage).
-
DB engine mode
: Indicates the engine mode (e.g., serverless, provisioned).
-
max capacity
: For a serverless cluster, the maximum capacity in terms of Aurora capacity units
(ACUs) expressing the peak capacity (i.e. compute and memory) to which Aurora can automatically expand.
- Unlike Aurora, both DocumentDB and Neptune do not support
cross-region replication. Note the one-to-many reflexive relationship from the AURORA CLUSTER entity to itself. Comparable reflexive relationships for DOCUMENTDB CLUSTER and NEPTUNE CLUSTER entities are not applicable to DocumentDB and Neptune clusters.
- Unlike Aurora, both DocumentDB and Neptune do not support
the concept of option groups. Specifically, the one-to-many relationship from the OPTION GROUP entity to the AURORA CLUSTER entity -- reflecting the default option group applicable to all DB instances in an Aurora cluster -- is not applicable to DocumentDB and Neptune clusters.
- Similarly, the many-to-many relationship between the DB INSTANCE and OPTION GROUP entities -- reflecting the option groups applicable to DB instances -- is not applicable to
DocumentDB and Neptune DB instances.
- The one-to-many relationship between CUSTOMER MASTER KEY and DB INSTANCE entities -- labelled “Performance Insights KMS Key Id” for encrypting Performance Insights metrics data -- is not applicable to DocumentDB and Neptune DB instances.
- Unlike Aurora and Neptune, DocumentDB does not support parameter groups for DB instances. Figure 5.3 is appropriately annotated to reflect that the many-to-many relationship between the PARAMETER GROUP and DB INSTANCE entities is irrelevant to DocumentDB.
The astute data modeling student might infer (i.e., by noting the similarities between the DOCUMENTDB CLUSTER and NEPTUNE CLUSTER entities and their shared differences with the AURORA CLUSTER entity) that perhaps DocumentDB and Neptune clusters might be generalized to yet another higher level of abstraction for hosting their common relationships and attributes (i.e., that the DOCUMENTDB CLUSTER and NEPTUNE CLUSTER entities become sub-types of a new super-type entity beneath the DB CLUSTER super-type). Such could be done. The author, however, chose not to so. Why? Simply because abstracting these to a higher level would introduce an additional layer of complexity to the conceptual model. Exploring such (i.e., modifying Figure 5.1 to depict the suggested super-type) is deferred as an exercise for curious data modeling students.
Recall from the explanation of a conceptual data model (CDM) and a more detailed logical data model (LDM) in the Introduction, that such an exercise might arguably be more appropriate and justifiable when evolving to an LDM from a CDM.