Chapter Summary
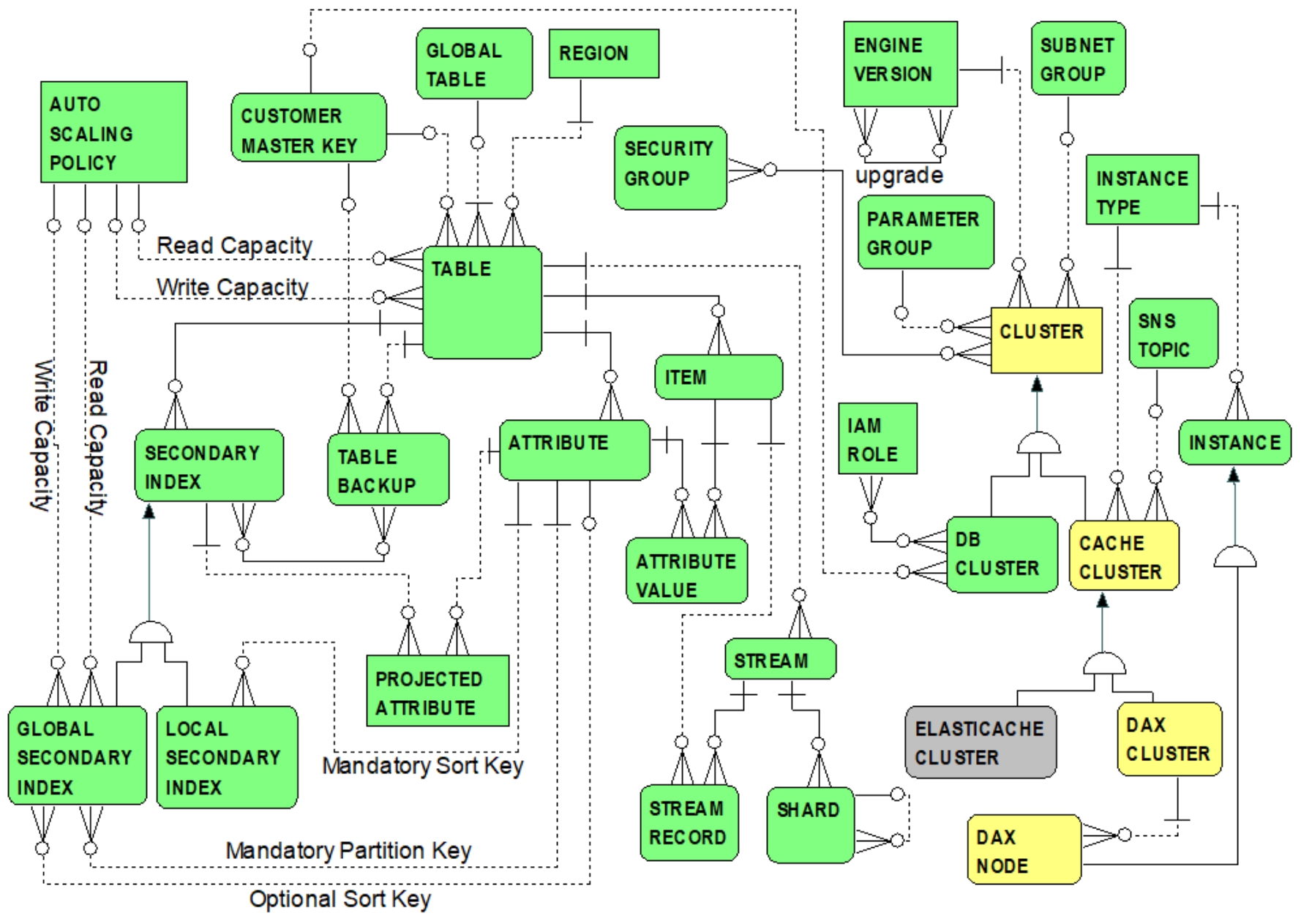
Figure 7.5 summarizes DynamoDB basic concepts.
Figure 7.5 DynamoDB Entity Relationship Summary
Amazon DynamoDB -- like Neptune and DocumentDB -- is a managed NoSQL database service offered by AWS. DynamoDB supports both structured and semi-structured data based on key-value pairs and document storage (JSON documents). DynamoDB partitions data among SSDs and balances workload across server resources to satisfy latency and storage needs. DynamoDB replicates data across availability zones and automatically expands and repartitions storage without service interruption.
DynamoDB suits internet scale
apps (e.g., e-commerce shopping carts) and is totally serverless, thereby obviating provisioning primary DB instances, replica DB instances, leader nodes or compute nodes as for previously described database services. Upfront capacity planning for new apps is simplified because DynamoDB can automatically scale resources to accommodate on-demand traffic. Capacity is specified in terms of throughput requirements
instead of provisioning instances. Even though a NoSQL approach, DynamoDB supports tables
. Throughput requirements are specified in terms of expected reads and writes on DynamoDB tables. DynamoDB transparently reserves sufficient servers and spreads data requests to accommodate anticipated throughput. Data partitions are also allocated to support throughput when additional storage is required. Separate provisioned throughput
settings for read capacity units
(RCUs) and write capacity units
(WCUs) are specified for each table. If I/O traffic exceeds RCUs or WCUs, DynamoDB throttles and retries data requests without requiring special application logic
.
Auto Scaling:
DynamoDB exploits auto scaling policies
(AWS Application Auto Scaling) for adjusting throughput settings based on a table’s actual I/O traffic (i.e., target utilization percentage
and upper/lower limits for RCUs/WCUs are specified).
Reserved Capacity:
DynamoDB also provides cost saving opportunities by allowing for reserved capacity. However -- unlike RDS, Aurora, and Redshift where the purchase of reserved instances
is offered -- DynamoDB offers the upfront purchase of RCUs and WCUs.
Tables and CRUD:
DynamoDB’s NoSQL approach supports a data manipulation language other than SQL for CRUD data operations -- but basic concepts for DynamoDB and the relational approach are comparable. Both include the definition of database tables
. For RDBMS approaches, tables are defined in terms of columns
whose values are maintained in table rows
. DynamoDB tables are composed of items
maintaining values of attributes
(name-value pairs). Document data types (e.g., the “map” data type) support nesting collections of attributes (i.e., for supporting JSON files). DynamoDB tables are schemaless
providing greater flexibility for defining tables and inserting items into a table. A PK (consisting of either one or two attributes) is required when defining DynamoDB tables. Other attributes and data types are not required to be defined when a DynamoDB table is created. Each item in a DynamoDB table can consist of its own set of different attributes and data types -- rather than an RDBMS, where columns apply to all rows and are normally defined when creating a relational table.
CRUD data operations for DynamoDB include: PutItem
for adding an item to a table; GetItem
for retrieving a single item by its primary key; Query
enables retrieval of multiple items based on query filters; UpdateItem
updates a single item; DeleteItem
deletes one item at a time.
Global Tables:
DynamoDB supports global tables
for automatically replicating information across multiple regions. A global table is made up of a group of replica tables
with the same table name, primary key, and AWS account -- but each replica table is located in a different region. Global tables essentially implement a multimaster
database such that changes in any replica table are automatically propagated to other tables in the group. Global tables obviate app development effort and promote high availability, improved latency, world-wide customer access, disaster recovery, and business continuity.
Streams:
DynamoDB provides Streams
for tracking and capturing changes to table items -- aka change data capture (CDC) for inserts, updates, and deletions. Captured changes may then be used for triggering actions (e.g., sending email notifications for alerting events). A stream record
, capturing a table item’s primary key and “before” or “after” modifications, is stored for every modification to a table item. Stream records are clustered into groups known as shards
which are automatically created and deleted as necessary by DynamoDB.
DynamoDB Accelerator (DAX):
DAX is a
caching
service promoting rapid response times and cost savings for certain use cases. A caching service applies the
Pareto principle
(aka the 80/20 rule) to in-memory data retrieval (i.e., for apps where a relatively small amount of data is most frequently accessed). DAX enables provisioning a cluster of cache servers (aka cache cluster
nodes)
. DAX assumes that an EC2 instance,
running DAX client software, executes DynamoDB API data requests. DAX client software sends all data requests to the DAX cluster. If DAX finds the data in cache (i.e., a
cache hit
of data previously retrieved from Dynamo tables), then DAX directly replies to the application. If requested data is not found (a
cache miss
), DAX transfers the request to DynamoDB and returns DynamoDB’s response to the application.
DAX Clusters:
A DAX cluster is a kind of
cache cluster which in turn is a kind of
cluster. Because a DAX cluster is a kind of
cache cluster, a DAX cluster inherits a single instance type (i.e., all nodes in a DAX cluster have the same node type) and an SNS topic for communicating event notifications. Because a cache cluster is a kind of
cluster, a DAX cluster indirectly inherits security groups, a subnet group, a parameter group, an engine version, and is a source for event notifications.
DAX Nodes:
A DAX cluster controls a group of one or more nodes and uses vocabulary similar to Aurora and Neptune (i.e., a primary
node and possibly many read replica
nodes). Unlike Redshift nodes (i.e., for MPP and data partitioning), the caching responsibilities for DAX nodes are substantially different. DAX balances DynamoDB API read operations among all DAX cluster nodes. Both the primary node and read replicas can process read operations. DAX maintains both an Item Cache
(for table items accessed by PK) and a Query Cache
(for result sets
from previous queries -- accessed by query parameter values). The primary node performs write operations
to DynamoDB tables. Any changes to cached data on the primary node are synchronized to read replica nodes.
By default, retrievals are eventually consistent
(i.e., data retrieved from cache might be inconsistent with most recent table updates but close enough for most practical purposes). For mission critical apps intolerant of stale
data, DynamoDB optionally overrides eventually consistent read
behavior in favor of strongly consistent reads
(i.e., cache access is bypassed with direct access to fresh data).
DAX read replicas promote scalability (horizontal and vertical) and high availability (automatically failing over to a read replica if a primary node fails).