Chapter 8 – Amazon ElastiCach
e
Amazon ElastiCache Introduction
Analogous to DAX, Amazon ElastiCache (ElastiCache) is another managed caching service that facilitates the implementation of scalable clusters of cache nodes. Caching services -- introduced in the previous chapter -- offer a phenomenal opportunity for improving response time latency by swiftly responding to queries with in-memory data and thereby minimizing an application’s need to access data stored on slower hard disk drives or solid state storage devices. Also similar to DAX, ElastiCache -- as a managed service -- alleviates worries surrounding admin tasks, such as provisioning servers, installing and upgrading software, managing capacity changes, dealing with server or cluster failures, etc.
ElastiCache supports two general options for caching data in memory based on well-known, open-source software initiatives: the
Memcached
cache engine
52
and the
Redis
(
RE
mote
DI
ctionary
S
erver) cache engine.
53
Multiple engine versions are supported for each of these two options. High level pros and cons for comparing and contrasting Memcached and Redis cache engines are briefly summarized as follows:
- Both Memcached and Redis cache engines …
- Deliver a NoSQL key-value store
for maintaining and manipulating in-memory data as key-value pairs.54
- Enable data partitioning across multiple nodes.
- Promote high availability by allowing cluster nodes to be distributed among multiple
availability zones.
- Enable capacity adjustment in response to changes in demand by allowing cluster nodes to be appropriately added or removed.
- In addition to the above capabilities, the Redis cache engine offers a robust set of bonus options including:
- Data encryption for data in-transit and data at-rest.
- Replication of data across multiple cluster nodes, read replicas,
for improving response times and high availability.
- Failure detection and automatic failover (i.e.,
similar to DAX clusters, automatic failover of the primary node
to a read replica
node).
- Creation of backups for recovery of existing clusters or populating data in new clusters.
The ElastiCache caching service is similar to the DAX caching approach -- as described in the previous chapter -- but is subtly different relating to how the application interfaces with ElastiCache and a back-end database (if any). The ElastiCache caching process is briefly summarized in terms of using a
lazy loading
caching strategy as follows:
55
- Assume that an application equipped with appropriate Memcached or Redis client API software is deployed running on an EC2 instance.
- Assume that the application, in addition to exploiting ElastiCache, also requires a back-end database.
- When retrieving data, the application initially requests data from an ElastiCache cluster via either Redis or Memcached API commands.
- If a cache hit occurs, ElastiCache returns the data to the application, thereby freeing the application from having to access the back-end database.
- If a cache miss occurs (i.e., requested data is not found or expired in cache), the application then follows up with an additional request for directly accessing the database.
- The application then issues appropriate API commands for writing the fresh data to ElastiCache so as to facilitate future retrievals (i.e., cache hits).
Recall from the previous chapter that the DAX client intercepts an application’s DynamoDB API requests and transparently acts (i.e., if a DAX cache miss occurs) as an intermediary to DynamoDB storage. For DAX, the application issues DynamoDB API requests and is oblivious to DAX caching activity. Application code works the same with or without DAX. But ElastiCache is different. An application using ElastiCache issues Memcached or Redis commands for accessing cached data and, independently, might also issue separate DML statements for accessing a possible back-end database. ElastiCache processes the command from the application and, unlike DAX, is oblivious of any back-end database. ElastiCache interfaces only with the application. If a cache miss occurs, ElastiCache does not come to the rescue by retrieving the data, like DAX, from a back-end database
Note that the lazy load strategy caches only requested data (i.e., as a result of a cache miss) and can be implemented with a
time to live
(i.e., TTL, an integer value) indicator specifying the number of seconds after which the key
expires
.
56
Any attempt to access expired data in cache is considered to be a cache miss resulting in potentially
stale
data being refreshed from the database -- and of course resetting the TTL.
An alternative or supplement to the lazy loading strategy is known as the
write through
caching strategy.
57
In this case, whenever the application inserts or updates data in its database, it also updates the cache. Cached data, therefore, is always current and consistent with a back-end database.
The Redis and Memcached data manipulation approaches for creating, reading, updating and deleting in-memory data substantially diverge from previously described DBMS engines. The architecture and design details of the Memcached and Redis cache engines are well beyond the intent and scope of this immediate conceptual data modeling endeavor for graphically summarizing fundamental ElastiCache concepts. Fortunately however, abundantly detailed
ElastiCache documentation
is readily and freely available (i.e., separate user guides for Memcached and Redis cache engines, ElastiCache API documentation, and AWS CLI Command Reference for ElastiCache).
58
These documents provide plentiful information -- and additional references -- allowing for fully evaluating the capabilities, features, functions, benefits and limitations of each of these alternatives. Specific application use cases are also identified where one caching approach might be considerably more enticing than the other. The following sections respectively introduce specific Redis and Memcached concepts helpful for understanding ElastiCache data model diagrams about to be revealed.
Redis Introduction
The primary focus of Redis is to always access and manipulate data within a cache server’s random access memory (RAM). For some use cases, Redis obviates, or at least diminishes, the need for persisting data in a back-end database. This focus epitomizes a substantial shift from previously described DMBS approaches which emphasize maintaining data on secondary storage devices (i.e., HDDs or SSDs). The Redis approach contrasts with DAX where cached in-memory data acts as an intermediary to data stored in a DynamoDB database. Redis combines both an in-memory cache and, secondarily, allows for storing data on disk for persisting in-memory data. But Redis data stored on disk is not directly accessed or manipulated. Redis CRUD operations are entirely performed in-memory. Redis in-memory data can be backed up in snapshots. Changes to Redis in-memory data can also be written to log files. Snapshots and log files serve as the basis for recovering in-memory data to support restarting servers and automatic failover from the primary node to a read replica. Confidence in automatic failover, high availability, and disaster recovery capabilities render (for some applications) a backend database as an afterthought and possibly not a fundamental requirement.
In addition to its in-memory focus, the Redis data manipulation language (i.e., DML) is by itself yet another major shift from the DML paradigms of previously described RDBMS and NoSQL approaches. The major difference is that Redis DML commands do not neatly map to previously noted SQL or NoSQL CRUD commands (e.g., for accessing relational tables, graph vertices, documents, etc.). Instead, Redis deals with higher level
abstract data types
which transcend fundamental DBMS table and column concepts. Redis exceeds the expectations of a conventional key-value store and is, therefore, also described as a
data structures server
.
59
Redis provides a set of commands specific to each of its supported abstract data types.
Examples
of such higher-level Redis data structures, concepts and associated commands include the following:
60
-
Strings
: A Redis String is simply a sequence of bytes and serves as the foundation for other Redis data structures. Akin to a blob
data type (supported by RDBMs such as Oracle DB and IBM Db2),61
a Redis string contains binary
-saf
e
data (i.e., any kind of data either binary or text data) up to maximum of 512 megabytes.62
For example, a Redis key is itself a string whose value can be mapped to another string. A simple use case is a string holding the result set of a SQL query from a relational database. This result set (i.e., a character string) is then mapped to a Redis key whose string value is the actual text of the SQL query. This key-value pair can then be cached for later retrieval.
Redis provides many commands for accessing and manipulating strings including commands for setting and getting string and substring values, incrementing and decrementing integer and floating values,
appending bytes to the end of string, and setting the TTL expiration of a key. Specific examples of String related commands include:
-
SET, GET
: Separate commands for respectively assigning a string value and fetching the string value for a specified key. For the SET command, the Redis command line interface provided by the Redis client accepts characters for setting a string’s value. A programming language API is typically used for moving binary data to a string. To use the Redis CLI SET command for binary data, the binary data must first be encoded (i.e., serialized
using a
Base64
encoding standard).63
Encoded binary data is acceptable input for the SET command.
-
SETRANGE, GETRANGE
: Separate commands for respectively setting a substring value and fetching a substring value for a specified key.
-
MSET, MGET
: Separate commands for respectively setting string values and fetching string values for multiple keys.
-
INCRBY
, DECRBY
: Separate commands for respectively incrementing and decrementing an integer value by a specified number.
-
APPEND
: Attaches (i.e., concatenates) a value to the current string value of a specified key.
-
SETEX
: Specifies a value for setting the TTL expiration of a key.
-
LPUSH
: Inserts new elements at the head of a list (i.e., at the left)
-
RPUSH
: Inserts new elements at the end of a list (i.e., at the right)
-
LRANGE
: Retrieves a range of elements from a list by specifying the first and last elements to be extracted.
-
SAD
D
: Inserts new elements to a Set.
-
SUNION
: Returns a Set whose elements are the union between multiple Sets.
-
SISMEMBER
: Determines if an element is a member of the set by returning either a 1 or 0 (i.e., respectively indicating true or false).
-
Sorted Sets
: Akin to an ordinary Set, a sorted set is a series of unique values but each value is linked to a score
-- a floating point number -- which can be used for sorting the set. Unlike an ordinary Set -- but similar to a List -- Sorted Sets enable retrieving a range of elements. Examples of Sorted Set related commands include:
-
ZADD
: Similar to SADD for ordinary Sets, ZADD inserts new elements along with their associated score to a Sorted Set.
-
ZRANGE
: Similar to LRANGE for Lists, ZRANGE retrieves a range of elements from a Sorted Set -- sorted from highest to lowest score -- by specifying the first and last elements to be extracted.
-
ZREVRANGE
: Similar to ZRANGE, but ZREVRANGE rev
erses the sort
order.
-
Hashes
: Comparable to a row in a relational database, a Hash is simply a mapping of one or more key-value pairs (i.e., string fields mapped to string values) associated with a unique hash key
. A Hash essentially represents the data structure for any specific object of interest to an application. Redis Hash commands allow access or updates to a single field or multiple fields at a time.
Examples of Hash related commands include:
-
HMSET
: Sets multiple fields of the Hash for a specified hash key field.
-
HMGET
: Returns an array of values for a specified hash key field and specified field names.
-
HEXISTS
: For a specified hash key field, HEXISTS verifies that a specified hash field exists.
-
Pub/Sub
: Beyond the above samples of supported abstract data types, Redis also facilitates the implementation of a variety of application capabilities such as pub/sub services for pub
lishing messages to channel
sub
scribers. Publishers (i.e., message senders) post messages to a channel, which links to message receivers who previously subscribed to the channel. Examples of Pub/Sub related commands include:
-
SUBSCRIBE
: Enables a receiver to subscribe to (i.e., listen for messages from) one or more specified channels.
-
PUBLISH
: Enables a publisher to post a message to a specified channel.
-
UNSUBSCRIBE
: Discontinues the receipt of messages from one or more specified channels.
Memcached Introduction
Memcached is less robust compared to Redis especially in terms of supported data structures. Unlike Redis, Memcached is not a professed data structure server. Lists, Sets, Sorted Sets, Hashes, and Pub/Sub services are not supported. Memcached simply provides an ordinary, conventional key-value store where strings are the only supported data type. Memcached essentially enables a large in-memory hash table. Simply stated, a key string value is mapped to another string value. A Memcached string, like a Redis string, is a block of raw data consisting of a sequence of bytes. The string size can be configured up to a maximum of 128 megabytes, substantially smaller than Redis strings, but more than adequate for enabling solutions satisfying requirements for many business-critical caching use cases. Unlike Redis, Memcached strings are not binary-safe. Binary data cannot be directly assigned to a Memcached string value without encoding. As previously mentioned for setting Redis string values using the Redis SET CLI command, values moved to Memcached strings must be encoded (e.g., pre-serialized using
Base64
).
Like Redis, Memcached APIs for manipulating string values are supported by many familiar, popular programming languages. Examples of Memcached string related commands include:
-
Set Data
:
Specifies a new or existing key and maps a new value to the specified key (i.e., overwriting the value for an existing key).
-
Add Data
:
Adds a new key and sets its value but does not overwrite the value for an existing key. The command fails if the specified key already exists.
-
Replace Data
:
Specifies an existing key and replaces its current value. The command fails if the specified key does not exist.
-
Append Data
:
Specifies an existing key and appends (i.e., attaches) data to the end (i.e., after the last byte) of the current value. The command fails if the specified key does not exist.
-
Prepend Data
:
The opposite of Append Data, this inserts data in front of the current value of an existing key.
-
Get Data
:
This is used to access the value stored at one or more specified keys. If a specified key does not exist, nothing is returned.
-
Delete Key
:
This is used to remove an existing key-value pair from the cache.
-
Incr
:
For strings with integer values, this increments the numeric value of an existing key by a specified positive value.
-
Decr
:
For strings with integer values, this decrements the numeric value of an existing key by a specified positive value.
ElastiCache Clusters
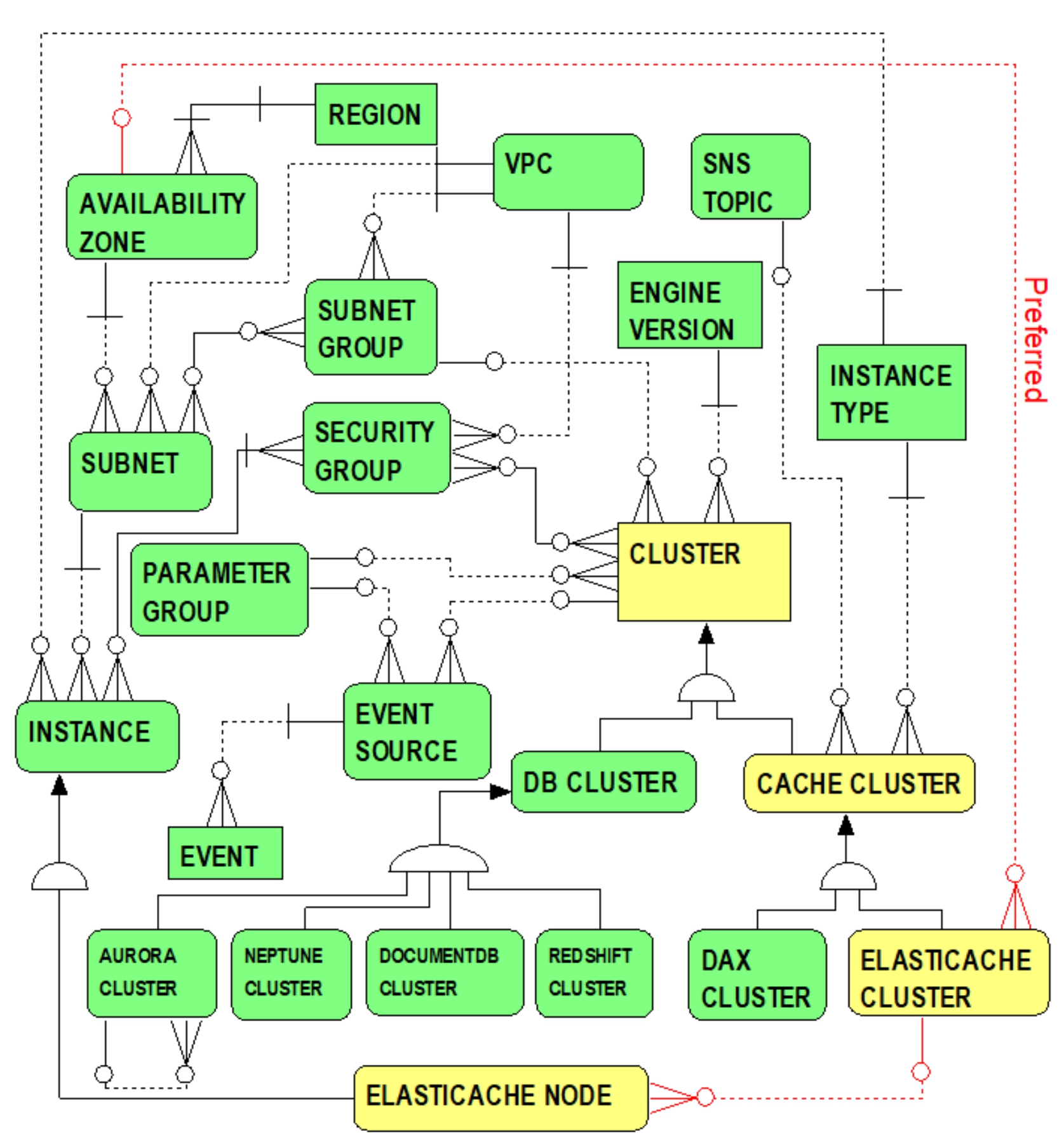
Figure 8.1 portrays where ElastiCache clusters fit relative to the overall super-type cluster hierarchy and further focuses on entities and relationships specific to ElastiCache.
Figure 8.1 Entities and Relationships … ElastiCache Clusters
From Figure 8.1, the CACHE CLUSTER entity (as previously noted in Chapter 7) represents the subset of all cache clusters, both DAX and ElastiCache clusters. The ELASTICASHE CLUSTER entity is a kind of
cache cluster (i.e., a sub-type of the CACHE CLUSTER entity) and, therefore, directly inherits relationships and attributes from its parent CACHE CLUSTER super-type entity and indirectly inherits relationships and attributes from the its grandparent CLUSTER super-type entity. Similar to the name clash described previously when dubbing the DAX CLUSTER entity (i.e., recall that a DAX cluster is simply referred to as a “Cluster” in the DynamoDB API documentation), note also that the entity name “ELASTICASHE CLUSTER” and the term “ElastiCache cluster”, used herein, correspond to the “Cache Cluster” data type referred to in the ElastiCache API documentation (i.e., the Amazon ElastiCache API Reference).
As previously noted, because of the need -- and greater good -- for generalizing the cache cluster concept to a higher level, it was necessary to hijack the name “Cache Cluster” for the super-type CACHE CLUSTER entity so as to represent all cache clusters (i.e., ElastiCache and DAX cache clusters) not just ElastiCache clusters. Apologies are again offered for any confusion created by this additional name confiscation
.
The CACHE CLUSTER entity, in addition to inheriting higher level relationships to its super-type CLUSTER entity (i.e., many security groups, a single subnet group, a parameter group, an engine version, and a source for event notifications) and CLUSTER attributes, provides additional relationships and attributes common to all cache clusters in general. The one-to-many relationships from the INSTANCE TYPE entity and the SNS TOPIC entity to the CACHE CLUSTER entity imply that the ELASTICASHE CLUSTER entity -- as a sub-type of the CACHE CLUSTER entity -- is indirectly associated with (i.e., inherits) a single instance type (i.e., all nodes in an ElastiCashe cluster have the same node type) and is also indirectly associated with (i.e., inherits) an SNS topic for communicating event notifications (e.g. email, text messages, etc.) triggered when ElastiCashe cluster life events transpire.
Common attributes inherited by the ELASTICASHE CLUSTER entity from the CACHE CLUSTER entity include the sample attributes noted in the previous chapter: instance type
(foreign key), sns topic
(foreign key), and total nodes
(i.e., the total number of nodes in the ElastiCashe cluster).
Indirectly inherited from the CLUSTER entity, an ElastiCashe cluster can serve as a source for event notifications, and is associated with many security groups, a single subnet group, parameter group, and engine version. This means that a cluster of ElastiCashe nodes has:
- A set of security groups for controlling access to ElastiCashe cluster nodes.
- A subnet group within whose subnets ElastiCashe cluster nodes can be launched.
- A single parameter group specifying parameters for configuring all ElastiCashe cluster nodes.
- The ElastiCashe engine version for all cluster nodes.
Common attributes indirectly inherited by the ELASTICASHE CLUSTER entity from the CLUSTER entity include the sample attributes noted in previous chapters which, for convenience, are replicated here as follows:
-
cluster identifier:
A user-supplied cluster identifier.
-
cluster create time:
The time when the cluster was created.
-
status:
Indicates the current state of the cluster.
-
endpoint:
Specifies the cluster’s access information (i.e., DNS host name and port number) enabling applications to connect to the cluster.
-
preferred maintenance window:
Identifies the time period when maintenance activities (e.g., system upgrades) are preferred.
In addition to the above attributes inherited from its super-type hierarchy, noteworthy examples of attributes peculiar to the ELASTICACHE CLUSTER entity include:
-
at rest encryption enabled
: Indicates whether or not encryption is enabled for data at-rest.
-
transit encryption enabled
: Indicates whether or not encryption is enabled for data in-transit.
-
snapshot retention limit
: For automatically created cluster snapshots, this indicates the number of days such backups are preserved before automatically being deleted. A value = 0 indicates that automatic backups are disabled.
-
snapshot window
: Specifies the daily time range when cluster snapshots are created.
Figure 8.1 also highlights additional relationships peculiar to the ELASTICACHE CLUSTER entity. The one-to-many relationship from AVAILABILITY ZONE entity to the ELASTICACHE CLUSTER entity indicates that each ElastiCache cluster can be associated with a single preferred availability zone
in which cluster nodes would rather be located (i.e., when nodes are not to be launched in multiple availability zones).
The one-to-many relationship from the ELASTICACHE CLUSTER entity to the ELASTICACHE NODE entity indicates that each ElastiCache cluster controls one or more ElastiCache node instances. However, the rules underlying this one-to-many relationship are subtly different depending on whether the ElastiCache cluster is a Memcached cluster or a Redis cluster.
For Memcached, an ElastiCache cluster controls one to a maximum of 20 ElastiCache nodes. If two or more ElastiCache nodes are provisioned for a Memcached cache engine, data is partitioned among those nodes. Partitioning means distributing cached data among multiple Memcached nodes such that each node contains a subset of key-value pairs. For a Memcached cluster, the concepts of primary node and read replica nodes do not apply. Memcached nodes are each independent of one another such that each node is oblivious to which key-value pairs are stored in its memory or the memory of other cache nodes. Memcached nodes are functionally equivalent. A hashing algorithm chooses the target node for retrieving, storing, or modifying a key-value pair. Why again is partitioning good? To facilitate and enhance scaling, performance and availability.
But for Redis, an ElastiCache cluster (i.e., within the scope of this one-to-many relationship) can have only one node
-- not many nodes. This circumstance is referred to as a Redis standalone cluster
(i.e., a cluster with only a single ElastiCache node running the Redis client). So in general, for emphasis, an ElastiCache cluster
can be composed of one or more ElastiCache nodes, but for a Redis standalone cluster
there is only one node. In other circumstances, an ElastiCache cluster for Redis can indeed control many more than 20 nodes, but the conceptual data model to account for such requires extensive enhancement, which is deferred as the subject of the next section, for introducing the concept of Replication Groups
.
Note in Figure 8.1 that the ELASTICACHE NODE entity is also a sub-type of the INSTANCE entity indicating that an ElastiCache node is a kind of
EC2 instance.
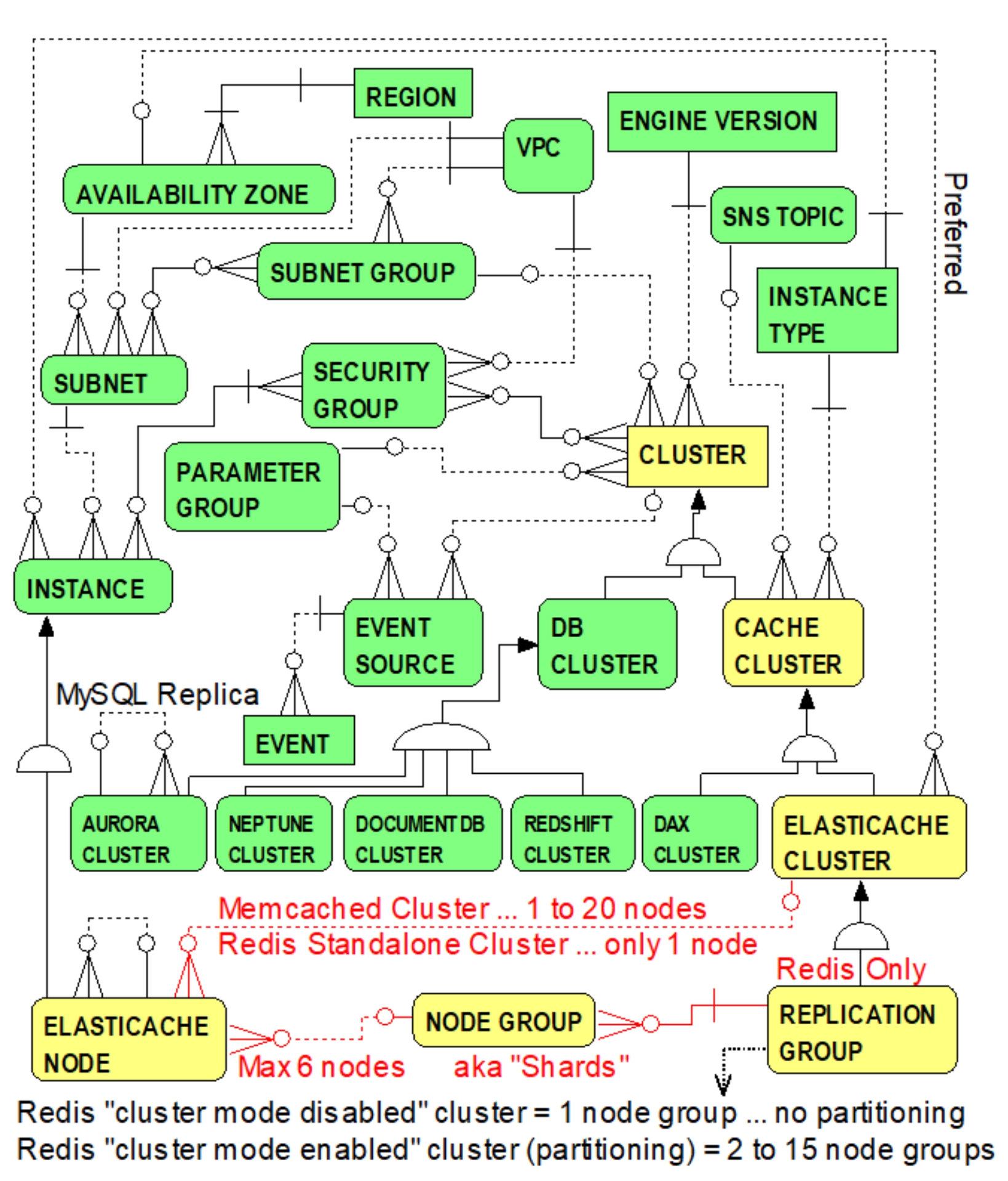
Figure 8.2 enhances 8.1 by appropriately annotating the one-to-many relationship from the ELASTICACHE CLUSTER entity to the ELASTICACHE NODE entity to emphasize the distinction between Memcached clusters and Redis standalone clusters.
Figure 8.2 Memcache vs. Redis …. One-to-Many ElastiCache Nodes
From Figure 8.2, the one-to-many relationship from the ELASTICACHE CLUSTER entity to the ELASTICACHE NODE entity is annotated, above the relationship line, to reflect that a Memcached ElastiCache cluster controls 1 to a maximum of 20 Memcached nodes. The annotation below the relationship line reflects that a Redis standalone cluster
can control only one Redis node.
ElastiCache Replication Groups
Figure 8.2 also introduces the concept of ElastiCache Replication Groups and the REPLICATION GROUP entity. Essentially, a replication group is an ElastiCache cluster
for Redis
which enables the provisioning of multiple Redis nodes. Replication groups
also deliver options for replicating in-memory data and
partitioning data across Redis nodes
.
64
The REPLICATION GROUP entity is shown as a sub-type of the ELASTICACHE CLUSTER entity. From a data modeling perspective, each replication group is a special case of an ElastiCashe cluster (i.e., a replication group is
a kind of
ElastiCashe cluster). To emphasize, a replication group is an ElastiCashe cluster but an ElastiCashe cluster (e.g., a Memcached cluster or Redis standalone cluster as described in the previous section) is not necessarily a replication group.
So, why are replication groups special ElastiCashe clusters? Because there are special relationships and attributes that apply specifically to the REPLICATION GROUP entity which do not apply to its parent ELASTICACHE CLUSTER entity. More specifically, a replication group clusters Redis nodes into one or more node groups
(aka shards
… not to be confused with DAX stream “shards” and the SHARD entity introduced in the previous chapter) to facilitate data replication and partitioning.
The one-to-many relationship from the ELASTICACHE CLUSTER entity to the NODE GROUP entity emphasizes that each replication group can be made up of one or more node groups. The one-to-many relationship from the NODE GROUP entity to the ELASTICACHE NODE entity emphasizes that each node group consists of one or more ElastiCache nodes. Note in Figure 8.2 that this relationship is annotated to reflect that each node group consists
of a maximum of 6 nodes. Unlike Memcached, Redis node groups re-introduce the concepts of primary nodes
and read replica
nodes. One node, the primary node,
is the one and only node in the node group used for both reading and writing data. In addition to the primary node, up to 5 nodes can be established in a node group as read replica nodes. Data written to the primary node is cloned asynchronously to potentially several replica nodes (for enhanced scalability) by enabling data retrievals distributed among several nodes. The one-to-many reflexive relationship from the ELASTICACHE NODE entity to itself indicates that the primary node of a Redis node group can have one or more ElastiCache nodes as read replicas.
Figure 8.2 is also annotated to emphasize special ElastiCache jargon to describe a replication group consisting of a single node group. Such is referred to as a Redis (cluster mode
disabled
) cluster
. In this case, a single node group supports replication but disables data partitioning which requires at least 2 node groups. A replication group consisting of at least 2 node groups -- thereby enabling partitioning -- is referred to as a Redis (cluster mode
enabled
) cluster
and can be partitioned up to a maximum of 15 node groups. In either case, a node group with a primary node and at least one replica node enables automatic failover to a replica node in the event of primary node failure. The replica node is promoted to become the primary node. ElastiCache refers to this as Multi-AZ wit
h
automatic failover
.
Note that the terminology used in the ElastiCache console emphasizes the term cluster
rather than replication group
for all of the above cases. The ElastiCache console uses the term cluster
for Redis (cluster mode enabled) clusters
, Redis (cluster mode disabled) clusters, Redis standalone clusters, and Memcached clusters. The terminology emphasized in ElastiCache API and CLI documentation reserves the term cluster
for Memcached and Redis standalone clusters (e.g., the CreateCacheCluster API action), and uses the term replication group
for Redis (cluster mode enabled) clusters and Redis (cluster mode disabled) clusters (e.g., the CreateReplicationGroup API action). Respectively using the names ELASTICACHE CLUSTER and REPLICATION GROUP for the entity names in Figure 8.2 is an attempt at maintaining compatibility within the data model and consistency with vocabulary nuances in ElastiCache documentation.
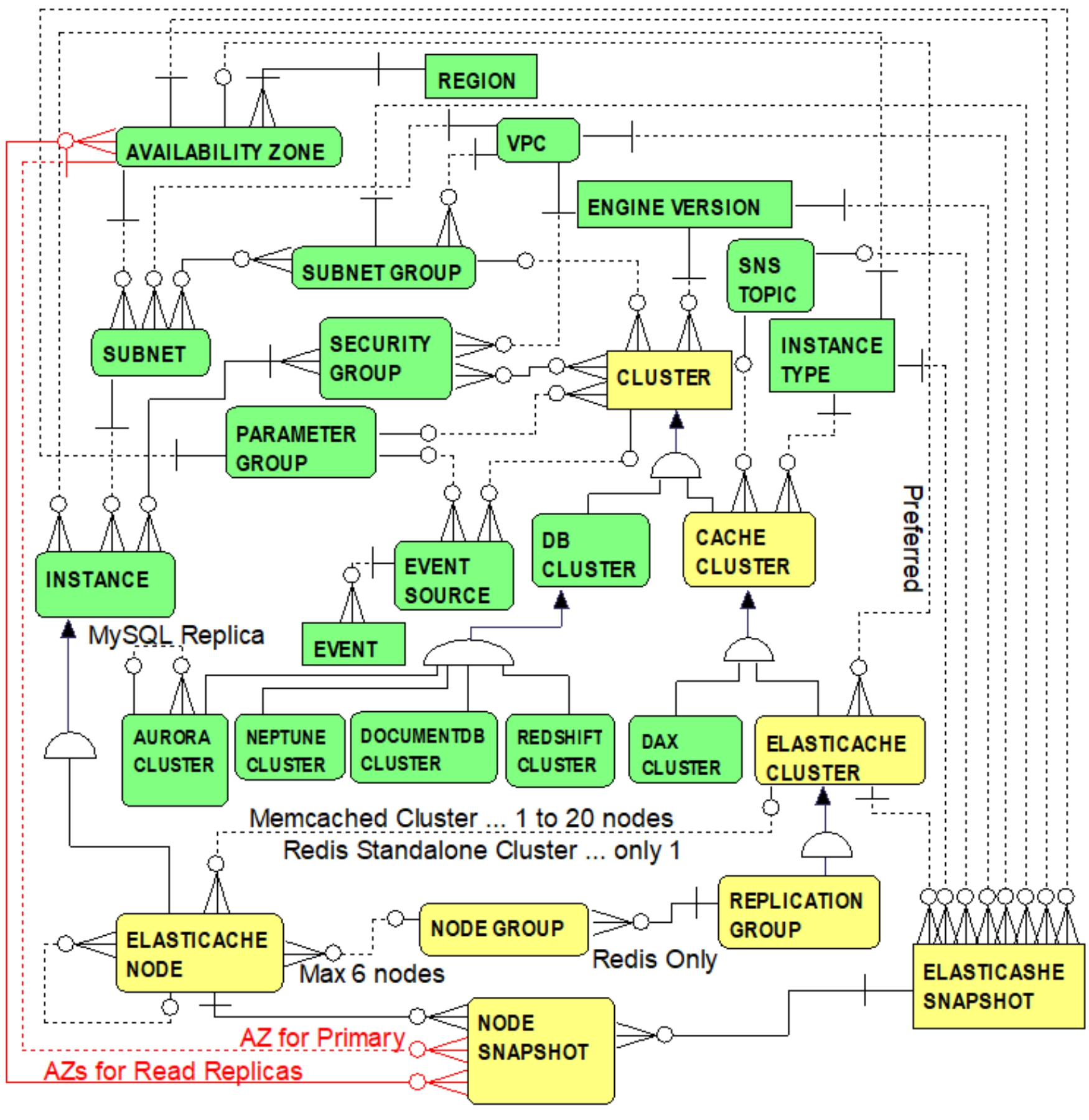
ElastiCache Backups
Figure 8.3 introduces the concept of ElastiCache snapshots.
Figure 8.3 Entities and Relationships … ElastiCache Backups
From Figure 8.3, the one-to-many relationship from the ELASTICACHE CLUSTER entity to the ELASTICACHE SNAPSHOT entity indicates that each ElastiCache cluster (e.g., all primary nodes provisioned for a Redis ElastiCache cluster) can be backed up by one or more ElastiCache snapshots
. Backups in this context apply only to Redis clusters. The ELASTICACHE SNAPSHOT entity (similar to the DB CLUSTER SNAPSHOT entity previously introduced in Chapter 3) duplicates crucial relationships (i.e., for the ELASTICACHE CLUSTER, CACHE CLUSTER, and CLUSTER entities) in order to fulfil its destiny to accurately restore an ElastiCache cluster if and when necessary. These duplicated relationships include one-to-many relationships from INSTANCE TYPE, SNS
TOPIC, ENGINE VERSION, VPC, SUBNET GROUP, AVAILABILITY ZONE, and PARAMETER GROUP entities to the ELASTICACHE SNAPSHOT entity. These relationships reflect the essential state of the Redis ElastiCache cluster at the time of the backup (i.e., the instance type, SNS topic, engine version, VPC, subnet group, availability zone, and parameter group in effect at the time of snapshot creation).
In addition to attributes derived from the above noted one-to-many relationships to the ELASTICACHE SNAPSHOT entity (i.e., foreign keys), noteworthy examples of additional attributes of the ELASTICACHE SNAPSHOT entity include:
-
snapshot name:
The snapshot name either automatically generated or chosen by the user (i.e., for a manual snapshot
).
-
snapshot retention limit:
The number of days that a snapshot is saved after which it is removed from storage (i.e., for automatically created snapshots). Manual snapshots are not removed automatically and must be removed explicitly (e.g., via a DeleteSnapshot
API call). For manual snapshots, snapshot retention limit
is the value that was stored for the backed-up cluster and is otherwise disregarded.
-
snapshot source:
Indicates a value of either “automated” or “manual” respectively reflecting whether the snapshot was automatically generated or requested by the user.
-
snapshot status:
Reflects the snapshot status having valid values such as “creating,” “available,” “deleting,” etc.
The NODE SNAPSHOT entity in Figure 8.3 resolves a many-to-many relationship between the ELASTICACHE NODE and ELASTICACHE SNAPSHOT entities. Specifically, an ElastiCache node can be included on many snapshots and, clearly, a snapshot can backup many ElastiCache nodes. The NODE SNAPSHOT entity resolves this relationship by reflecting the node group configuration
information (e.g., availability zones) for each node included in the snapshot. Indeed, only one node from each node group actually needs to be backed up. The one-to-many relationship from the ELASTICACHE NODE entity to the NODE SNAPSHOT entity reflects that each node snapshot must be associated with a single ElastiCache node. For a Redis (cluster mode enabled) cluster,
the primary node of each node group is backed up.
For a Redis (cluster mode disabled) cluster, any node within the single node group can be selected for use during the backup process. This allows the option of backing up a read replica instead of the primary node and thereby enabling the primary node to respond to requests unperturbed by the backup process.
The one-to-many relationship from the AVAILABILITY ZONE entity to the NODE SNAPSHOT entity identifies the availability zone for the node group’s primary node at the time the snapshot was taken. The many-to-many relationship between the
AVAILABILITY ZONE entity and NODE SNAPSHOT entity identifies the availability zones for each replica node within the node group.
In addition to attributes derived from the above noted one-to-many relationships to the NODE SNAPSHOT entity (i.e., foreign keys), noteworthy examples of additional attributes of the NODE SNAPSHOT entity include:
-
snapshot create time
: The date and time at which point the node’s cache data was accessed for creating the backup.
-
cache node create time:
The date and time at which point the node itself was created within the cluster for which the snapshot was created.
-
node group id:
The unique identifier (i.e., either the user supplied id or the Redis supplied id) for the node group in which the backed-up node is included.
-
slots:
For partitioning data across node groups, this specifies a range of values between 0 and 16383 (e.g., “8000-12000”) for the keyspace
associated with the node group. A total of 16384 hash slots are used by the Redis hashing algorithm
in determining the slot for a specified key (i.e., a CRC16 hashing algorithm). If this slot range is unspecified, key spaces are equally distributed by ElastiCache between the node groups.
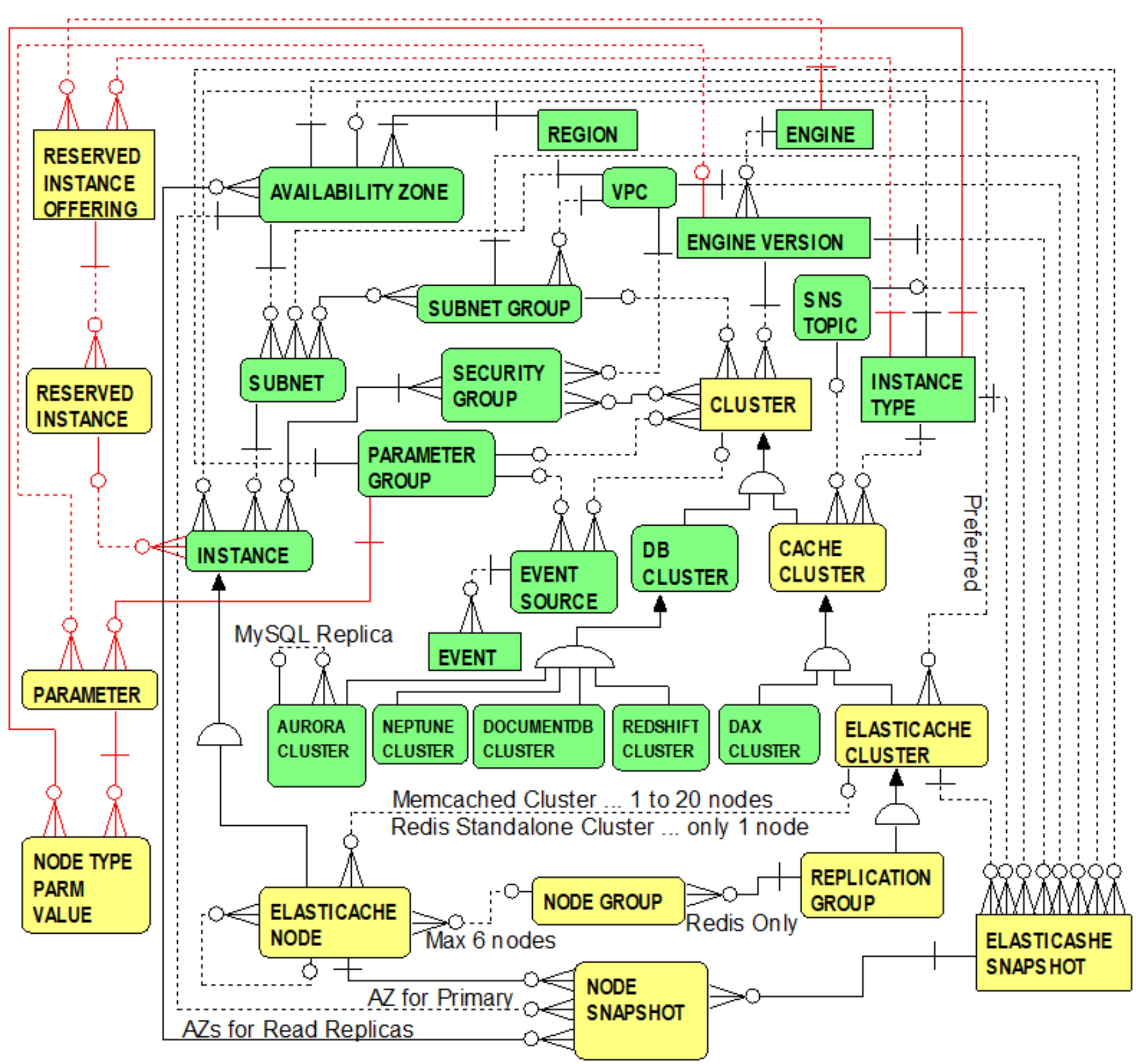
ElastiCache Reserved Instances, Node Type Parameters
ElastiCache (like RDS, Aurora and Redshift) enables purchasing reserved instances for cache nodes thereby offering considerable cost savings compared to on-demand pricing. Figure 8.4 extends Figure 8.3 by emphasizing that reserved instances and the concept of node type parameters
also apply to ElastiCache clusters.
Figure 8.4 Reserved Instances, Node Type Parameters
From Figure 8.4, the RESERVED INSTANCE OFFERING entity and RESERVED INSTANCE entity are re-introduced (from Chapter 2, Figure 2.4) highlighting reserved instance fundamental concepts. Recall that the RESERVED INSTANCE OFFERING
entity represents the starting point when a user searches for discount offerings prior to actually purchasing reserved instances. The one-to-many relationship from the INSTANCE TYPE entity to the RESERVED INSTANCE OFFERING entity indicates that each reserved instance offering applies to a single instance type (i.e., a cache node type). Each reserved instance offering can spawn one or more reserved instances, as represented by the one-to-many relationship between the RESERVED INSTANCE OFFERING entity and the RESERVED INSTANCE entity. Also recall that the one-to-many relationship between the RESERVED INSTANCE and INSTANCE entities suggests that each reserved instance (i.e., the discounted pricing associated with each reserved instance) can apply to one or more actually running cache nodes.
Note also the NODE TYPE PARM VALUE entity in Figure 8.4. This resolves a many-to-many relationship between the INSTANCE TYPE and PARAMETER entities reflecting that specific values of parameters can differ depending on the cache node type. Attributes of the NODE TYPE PARM VALUE entity include node type
, parameter name
, and the parameter value
specific to the node type. Each cache node type can have many parameters for which special values apply. Examples of Memcached parameter names whose values vary depending on the cache node type include max cache memory (i.e., max_cache_memory)
and number of threads (i.e., num_threads).