Chapter 9 – Amazon Quantum Ledger Databas
e
Amazon QLDB Introduction
You, the relentless reader and indefatigable data professional (in the final lap of this excursion into cloud database services), are now challenged with fathoming yet another noteworthy and innovative database paradigm -- compliments of the Amazon Quantum Ledger Database service (Amazon QLDB). Amazon QLDB, an additional managed AWS database service, is remarkably different from previously described AWS database services.
QLDB’s appeal and purpose is focused on applications requiring a
ledger
database.
65
Briefly, a
ledger
is used in financial accounting for recording business transactions in terms of debits and credits to accounts. Ledgers are also frequently paired with the concept of
journals
where initial transaction details are sequentially recorded (i.e., as accounting
entries
) prior to being posted to ledger accounts.
66
For QLDB, a ledger database is a data repository for
System of Record
(SOR) applications requiring complete, accurate, sequential, and unambiguous transaction history.
67
Such repositories are trusted to be the authoritative, single-version-of-truth, and secure source of data for an enterprise’s mission critical and proprietary information. Obvious examples of SOR apps crucially requiring trustworthy history include …
-
eCommerce
Online Order Tracking and Fulfilment: Requiring detailed process history from order entry, item picking, packing, and shipping logistics through final delivery.
-
Banking
: Deposits, withdrawals, and transaction history of bank accounts.
-
Product Recall Tracking
: Tracking the bill-of-material (as-built), change history of component parts, and maintenance of complex manufactured product assemblies (e.g., aircraft engines, automobiles, etc.).
The challenge of maintaining verifiable records for proprietary and mission critical data is far from trivial. Techniques for implementing change history for conventional database paradigms include extra effort required for …
- Custom software development (e.g., for triggers, stored procedures, and audit reports in relational systems).
- Database enhancements for maintaining change history (e.g., implementation of partitioned tables, separate history tables, log files, and audit trails).
- Database administration effort for assuring high availability and disaster recovery (e.g., automatic replication of data to backup repositories).
Despite the above extra effort, C-level executives continue to be restless and nervous about data confidentiality, integrity, and availability. CxO sleepless nights are provoked by cyber-security worries surrounding fraud, espionage, sabotage -- from both external and internal threats. Privileged users (e.g., system administrators, super users, users with root access, etc.) can surreptitiously and fraudulently compromised data integrity, access intellectual property, or modify proprietary software. So, additional effort to allay such concerns can result in pricey policies, processes, and people (e.g., for implementing
separation of duties
-- SOD) to help prevent fraud, error, data loss, or data exfiltration.
6
8
Examples of QLDB features mitigating such concerns and significantly distinguishing QLDB from previously described database services are summarized in subsequent subsections.
SQL-based Access to Document Data
QLDB blends familiar concepts from both relational and document database approaches for maintaining ledger information. Specifically, the foundation of a QLDB ledger is defined in terms of one or more tables
-- indeed reminiscent of RDBMS tables but also similar to DynamoDB’s reuse of the table concept for its TABLE entity (as previously described in Chapter 7). However, unlike RDBMS and DynamoDB terminology (i.e., where tables respectively consist of one or more rows or items), each ledger table in QLDB consists of one or more documents
reminiscent of document database engines such as DocumentDB (as previously described in Chapter 5). One might describe QLDB as a quasi-relational-document approach for ledger databases.
QLDB documents are similar to DocumentDB documents. Both are schemaless and support an open content JSON-like file format. Furthermore, QLDB’s document format, known as
Amazon Ion
, is actually a superset of the JSON open-standard format and is notably more robust by supporting data types beyond those of DocumentDB.
69
Examples of additional data types offered by Amazon Ion include
blobs
,
clobs
(i.e., for
b
inary
l
arge
ob
jects and
c
haracter
l
arge
ob
jects) and new data types for more precisely specifying numbers (i.e., as integers, decimals, and floating point numbers).
Respectful of SQL’s global familiarity and reminiscent of SPARQL’s SQL-like approach for accessing Neptune graph data (as previously described in Chapter 4), the QLDB data manipulation language for creating, reading, updating, and deleting documents in ledger tables is also comparable to SQL (i.e., SQL basic DML commands: INSERT, SELECT, UPDATE, DELETE). In particular, the QLDB DML is enabled by
PartiQL
, an open source query language, developed by Amazon. PartiQL was expressly built for flexibly accessing diverse data formats including relational tables, semi-structured document data, and complex nested documents. Furthermore, PartiQ
L
supports extensions to SQL to streamline access to QLDB documents. PartiQL tutorials and detailed specifications are readily available online.
70
Especially noteworthy is PartiQL’s extended SQL syntax which includes a dot notation
and aliasing
of nested data. This enables direct, intuitive access to multi-level, nested data embedded within documents. A simple familiar example of a nested document is a grouping of PO Items
nested within a Purchase Order
. The following illustrates a PartiQL INSERT statement for inserting a simple Purchase Order document in ION format
…
INSERT INTO
PurchaseOrder
{
'POId' : 'PO123456789',
'CustomerId' : 'Any Random Customer',
'OrderDate' : `2019-12-25T`,
'
POItems
' :
[
{ 'ItemId' : 'Random Widget A' , 'Qty' : 1, 'UnitPrice': 1.75},
{ 'ItemId' : 'Random Widget B' , 'Qty' : 2, 'UnitPrice': 2.75},
{ 'ItemId' : 'Random Widget C' , 'Qty' : 3, 'UnitPrice': 3.75}
]
}
The indented list of 'POItems
' implies a one-to-many relationship -- that the Purchase Order requests one or more purchase order items. The traditional relational approach creates separate tables for PurchaseOrder and POItem with referential integrity enabling joins between the two tables. PartiQL supports table joins but also (via its dot notation and aliasing) promotes direct linkage to nested data. This concisely enables selection, filtering, and aggregating nested data within complex documents. This approach provides an option for fewer tables and obviates convoluted join conditions especially for documents embedding multiple levels of nested data. The following PartiQL SELECT statement is a simple example illustrating access to nested data with “poi
” as the alias for the nested “POItems
” in the above document …
SELECT po.POId, po.OrderDate,
poi
.ItemId,
poi
.Qty
FROM PurchaseOrder AS po, @po.
POItems
AS
poi
WHERE po.CustomerId = 'Any Random Customer'
In essence, PartiQL’s aliasing and dot notation elevates the stature of nested data by more succinctly, intuitively, and efficiently traversing and flattening parent/child associations within documents. This is reminiscent of Gremlin’s graph query language paradigm (as described in Chapter 4) for elevating edge relationships to higher importance for simplifying access to highly connected data.
Built-in History and Change Data Capture
QLDB obviates custom software development for maintaining transaction history by automatically capturing all application changes to QLDB ledger documents. Software development and DBA effort for designing and implementing traditionally used “bread-and-butter” techniques (e.g., triggers, stored procedures, partitioned tables, and history tables in relational engines) as mechanisms for maintaining transaction history is unnecessary -- is
history -- in QLDB.
QLDB documents are also referred to as document revisions
since a complete history of all revisions to documents is maintained for ledger tables. A QLDB ledger is basically a journal
of transactions maintained within an append-only
data repository. A journal maintains a complete, chronological record of all ledger modifications
.
When inserting a new document into a ledger table (via a PartiQL INSERT statement, as illustrated above), QLDB stores the document in the journal as the initial document revision with an automatically generated unique identifier (i.e., a document ID) and a version number of 0. Each document revision in the journal is uniquely identified by combining the document ID and version number (i.e., a composite primary key).
When updating one or more fields of an existing document (via a PartiQL UPDATE statement), QLDB appends a new document revision (i.e., an after-image reflecting the changes) into the journal. The new document revision inherits the same document ID of the previous revision but the version number is incremented by 1. Since the journal is an append only
repository, the previous document revision is not physically altered. An UPDATE statement does not actually modify the existing revision previously situated in the journal, but instead results in committing a new document revision for reflecting the change. The new document revision with a later version number supersedes (without replacing) the previous version and becomes current. Essentially, a journal maintains a log of transactions each of which committed one or more document revisions to ledger tables. Deleting an existing document (via a PartiQL DELETE statement) also results in appending a new document revision, reflecting a logical deletion, into the journal.
Note that QLDB, borrowing again from relational vocabulary, is also endowed with views
for distinguishing a table’s current document data from historical document revisions. The user
view is the default view for accessing current application data (i.e., the latest, non-deleted document revisions in the journal). Another view, the committed
view, is similarly used for accessing current application data but also projects automatically generated metadata (e.g., document ID, version, a transaction ID, transaction date/time, etc.). PartiQL also equips its SELECT statement syntax with a history function
for accessing the history of prior document revisions including both application data and system generated metadata.
Immutability
Clearly from the previous narrative, a PartiQL UPDATE statement for changing a document does not directly affect the current document revision but instead results in constructing a new document revision. A change to the current document revision renders it history in deference to (and superseded by) the changes reflected in the new (now current) revision. All PartiQL INSERTs, UPDATEs and DELETEs are indisputably journalized -- only appended to the journal -- and thus they do not allow for prior history be modified or physically removed.
The automatic, complete and accurate recording of all change history (data and metadata) leads one to surmise that a journal’s data integrity is virtually unchallengeable -- meaning that document revisions (both current and history) cannot be intentionally or accidentally modified after being committed to the journal. But how does QLDB do this?
The undergirding conceptual detail for logging transactions (i.e., the data structure and content comprising the journal) exploits concepts and terminology resonating with
blockchain
technology -- yet another database paradigm but radically different from previously described database services. Blockchain technology deals with ledgers that are implemented across a decentralized, distributed network of cooperating servers (i.e., in a
peer-to-peer network). The peer servers collaborate and collectively agree (e.g., using a
consensus algorithm
) without relying on any central authority. You, as a proud and esteemed IT professional (unless having lived totally under an RDBMS rock, or like an ostrich with your head stuck entirely in RDBMS sand), are likely well aware of cryptocurrency controversies and implementations of blockchain technology (e.g., Bitcoin and open source blockchain frameworks such as Ethereum and Hyperledger Fabric).
71
Adopting similar vocabulary, a QLDB journal consists of a chain of blocks
. Each ledger transaction results in persisting one or more blocks of data, which are serially chained (i.e., linked) and appended to the journal. Application data and system-generated metadata are stored in the chain of blocks. Specifically, each transaction results in committing one or more blocks and each block consists of one or more data entries
. Document revisions resulting from PartiQL DML statements along with metadata -- including the actual statements that committed document revisions -- are stored as block entries (More about this later … Describing the detailed structure of each block is deferred to a subsequent section of this chapter). One might pontificate, therefore, that QLDB by blending relational, document and blockchain concepts uniquely represents a quasi relational-document-blockchain database approach.
A journal’s transaction log consisting of these chained blocks is intuitively immutable given that QLDB automatically logs history, is innately incapable of modifying or deleting history, and reflects changes to current documents by displacing them with new revisions. But, in addition, QLDB provides a mathematical process for verifying the integrity of document revisions. How does QLDB purport to do this? Read on …
Verifiability
Recall for ElastiCache replication groups (as previously described in Chapter 8) that a hashing algorithm (i.e., the CRC16 hashing algorithm) facilitates access to cached data partitioned across multiple cache nodes. Hashing techniques are also used by QLDB but for a different purpose -- as the basis for verifying that transaction data has not been transformed, tampered or tarnished in any way since initially committed to the journal.
As previously noted, each document revision maintains both application data and document metadata. In addition to the examples of previously noted document metadata (i.e., document ID, a version number, a transaction ID, etc.), each block also maintains an assortment of
SHA-256
(
S
ecure
H
ash
A
lgorithm) hash codes.
72
SHA-256 is a
cryptographic hash function
-- a mathematical algorithm -- that accepts any given data as input and maps it to a 256 bit hash code (aka
digest
,
signature
,
fingerprint
,
checksum
).
73
In essence, the hash code represents a condensed summarization of the input data. SHA-256 hash codes are the key ingredient for verifying data integrity because of the
high likelihood
that any changes to the input data will result in a different hash value.
74
Each block in the journal is equipped with multiple hash codes. Examples of block attributes whose values are SHA-256 hash codes include block hash
(i.e., the hash value for all data within a block, aka blockHash
) and previous block hash
(i.e., the hash value for the previous block in the chain, aka previousBlockHash
). The block hash
becomes the previous block hash
for the next block in the chain and is, therefore, also ingested within the next block’s block hash
. The previous block hash
is thus inextricably intermeshed with the block hash
.
Each document revision stored within a block is also summarized with a SHA-256 hash value.
QLDB provides a verification process to confirm data integrity for any designated document revision within a block. The QLDB verification process is briefly summarized as follows:
-
Request a Digest
: A digest is a file (stored in Amazon ION format) and is requested via the Amazon QLDB console or QLDB API. A digest file includes yet another SHA-256 hash, the digest hash
. A digest hash condenses a ledger’s full change history up to and including the journal’s last saved block (aka the tip
of the journal) at the time the digest is requested. A digest file is a key component for verifying a document’s data integrity. Any document committed to any block within the digest’s scope can be verified.
A digest file applies the concept of a
Merkle Tree
-- a concept also shared with blockchain technology.
75
The digest’s SHA-256 hash is based on a binary tree structure of hash codes starting with the bottom nodes of the tree which are the SHA-256 hash codes for journal blocks. Block hashes are sequentially paired (e.g., 1
st
block hash paired with 2
nd
block hash … 3
rd
block hash paired with 4
th
block hash, etc.) and concatenated. The result is then rehashed to create a new hash node (aka a
proof hash
) at a higher level in the tree structure. Proof hashes at the higher level of the tree are next paired, concatenated and rehashed to higher levels (consisting of new
proof hashes
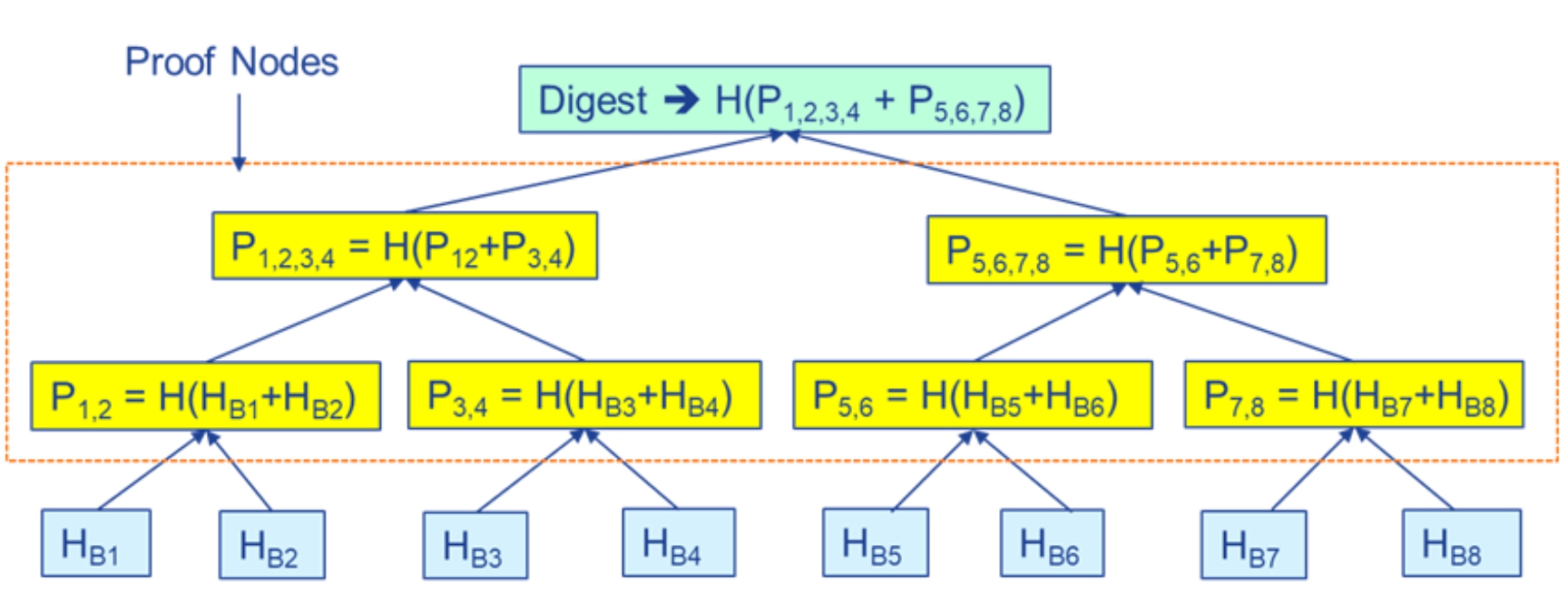
) as necessary. Figure 9.1 proposes a simple example.
Figure 9.1 Digest Binary Tree … Simple Example
In Figure 9.1, lowest level nodes (HB1
, HB2
, etc.) represent block hashes. Next higher level nodes (P1,2
, P3,4
, etc.) represent proof hashes from lower level block hashes that have been paired, concatenated, and rehashed. These proof hash nodes are then similarly processed resulting in the next higher level of proof hash nodes (P1,2,3,4
and P5,6,7,8
), which in turn are likewise rehashed. The end result is the digest hash code at the top of the tree.
The digest file also contains a digest tip address
which identifies the location of the last block consumed in the digest. The saved digest file can then be used for verifying data integrity of any document stored in a block up to an including the last block identified in the digest tip address.
-
Identify Document To Be Verified:
Metadata for identifying the specific document to be verified must be retrieved from the ledger. As previously noted, a document’s system-generated metadata can be accessed via a SELECT statement using the committed
view. The retrieved metadata includes the unique document id (metadata.id
) and a block address (blockaddress).
The block address includes a sequence number (blockaddress.sequenceNo)
for helping identify the document’s block location in the journal.
-
Start Verification:
The QLDB console provides a verify document
form enabling a user to specify the document to be verified by entering the ledger name, document id and block address. Form options are also provided for specifying the digest to be used for verification by either selecting an existing digest file or manually entering the digest hash and digest tip address from a saved digest file. The user can then choose to initiate the verification process.
-
Verification Proof:
QLDB recycles another concept familiar to blockchain technology and cryptography -- Merkle Audit Proofs
-- as the foundation for verifying a document’s integrity.76
A Merkle audit proof essentially provides a short-cut method for checking integrity without the need for sequentially traversing the chain of blocks and recalculating hash codes for possibly much of a ledger’s entire document history. Instead, a much smaller number of the digest’s tree nodes are needed. Specifically, only hashes from a subset of the nodes in the binary tree for the digest (specified in the previous step) participate in the verification process. This subset of hashes is referred to as the audit path
from the block of the document to be audited (leaf node) to the digest (i.e., the root hash).
After the user initiates the verification process, QLDB provides what is referred to as a proof
-- an ordered list of node hashes (from the digest’s node tree) for computing (i.e., rehashing) other hashes (for missing nodes not included in the ordered list) at higher levels in the tree. A recalculated hash is then combined with that of another given proof node hash (i.e., the next proof node hash in the ordered list) yielding another recalculated hash, and so on. This tree climbing process ultimately results in recalculating the digest hash. The recalculated digest hash should be equal to the originally calculated digest hash as saved in the digest file -- thus confirming the document’s integrity.
Figure 9.2 modifies the colors in Figure 9.1 highlighting a simple audit path for verifying a document
.
 Figure 9.2 Audit Path Example
Figure 9.2 Audit Path Example
In Figure 9.2, suppose that node HB5
is the block that contains the document whose integrity is to be verified. The ordered list of hashes that QLDB provides (shown in green) are HB6
, P7,8
, P1,2,3,4
respectively required to calculate higher level hashes (shown in yellow) P5,6
,
P5,6,7,8
and finally the digest at the top of the tree.
QLDB Basic Entities and Relationships
Figure 9.3 introduces QLDB basic entities and relationships.
Figure 9.3 QLDB Basic Entities and Relationships
In Figure 9.3, the LEDGER entity reflects the set of all ledger databases controlled by QLDB. A ledger in QLDB is intuitively at the same level as that of a database in a relational engine. QLDB can support many ledgers in the same sense that a relational engine, such as OracleDB, can support many databases. The one-to-many relationship from the LEDGER entity to the LEDGER TABLE entity reflects that each ledger in QLDB is defined in terms of one or more tables, again reminiscent of relational tables -- and also reminiscent of DynamoDB’s reuse of the table concept for its TABLE entity (as previously described in Chapter 7)
.
The one-to-many relationship from the LEDGER TABLE entity to the DOCUMENT entity reflects that each ledger table in QLDB consists of one or more documents -- unlike RDBMS and DynamoDB terminology where tables respectively consist of one or more rows
or items
. As previously noted …
- Documents are equivalently described as document revisions
since a complete history of all revisions to documents are maintained for a table.
- A document ID and version number are automatically generated and combine to uniquely identify each document revision.
- Documents are schemaless
and obey Amazon Ion format.
- Documents include metadata attributes (in addition to document ID and version number) such as a transaction ID, a timestamp, and SHA-256 hash value.
The one-to-many relationship from the LEDGER TABLE entity to the INDEX entity reflects that each ledger table can be defined with one or more table indexes for more efficiently accessing document data. The INDEX entity is reminiscent of secondary indexes and the SECONDARY INDEX entity defined for DynamoDB (previously described in Chapter 5). Each QLDB table index is a single field in a key-value pair for a document. Tables and indexes can be interactively created via QLDB console and its Query editor
by respectively exercising PartiQL CREATE TABLE and CREATE INDEX commands.
QLDB Journal Entities and Relationships
Figure 9.4 extends Figure 9.3 by blending it with entities and relationships describing the QLDB journal concepts.
Figure 9.4 QLDB Journal Basic Concept
s
In Figure 9.4, the JOURNAL entity reminds us that each QLDB ledger maintains a complete, chronological journal of all ledger transactions. The one-to-one relationship between the LEDGER and JOURNAL entities emphasizes the tight semantic coupling between the concept of a QLDB ledger and a journal. One could argue that they are interdependent -- that a QLDB ledger cannot exist without a journal and that a journal cannot exist unlinked to a ledger (i.e., an existence dependency
). One could then infer further that both entities should be commingled into a single LEDGER entity -- that there is no need for a separate JOURNAL entity in a conceptual data model. A journal is an indelible component of QLDB ledger but distinct from other ledger components, such as separate QLDB storage supporting table indexes (aka indexed storage
). Separate LEDGER and JOURNAL entities are proposed in Figure 9.4 in deference to QLDB documentation which appears to regard these as distinct concepts.
The one-to-many relationship between the JOURNAL entity and the STRAND entity reveals that each journal is composed of at least one or more strands
-- perhaps a method for partitioning journal content into multiple threads. Note that QLDB currently supports only a single journal strand, but one might forecast future support for multiple strands (e.g., a proactive design option for enhancing latency).
The one-to-many relationship between the STRAND entity and the BLOCK entity reveals that each strand is composed of at one or more blocks. The BLOCK entity’s one-to-one reflexive relationship conveys the “chain” in the chain-of-blocks concept reminiscent of blockchain technology. Each block can be chained to a prior block in the sequence of blocks. All but the initial block is chained to a prior block and the last block (tip of the journal) indeed has not yet been chained by a subsequent block. Hence, this one-to-one reflexive relationship is optional in both directions, since there exists the possibility of blocks without a predecessor or subsequent block. Therefore, in essence, a journal is simply the historical collection of all the blocks that have been committed in a ledger.
Attributes of the BLOCK entity include the strand id (strandId
), a block sequence number (sequenceNo
), transaction id (transactionId
), a time stamp for the block (blockTimestamp
), the block hash (blockHash
), and the previous block’s hash (previousBlockHash
).
The TRANSACTION entity reflects all the transactions executed for committing documents to the journal. The one-to-many relationship between the TRANSACTION entity and the BLOCK entity reveals that each successful transaction generates at least one and possibly many blocks --- but each block must be tied to a single transaction.
So, more precisely, a journal is the historical collection of all the blocks that have been committed by transactions to a ledger. The one-to-many relationship between the TRANSACTION and STATEMENT entities reveals that one or more PartiQL statements were executed for each transaction committed to the journal. Each statement must be tied to a single transaction.
The one-to-many relationship between the BLOCK and ENTRY entities is a reminder that each block, as previously noted, is composed of at least one or more entries, within which transaction details (e.g., document revisions) are stored. Actually, the content of each block is implemented in Amazon ION format. The sample attributes noted above for the BLOCK entity (i.e., strandId
, sequenceNo
, transactionId
, blockTimestamp
,
blockHash
, and previousBlockHash
) are included in the block’s ION structure as name/value pairs (aka fields). Additional entries are included with nested lower level entries. Examples include:
- A revisions
entry with a nested list of document revisions (i.e., nested entries) each containing a document’s application data and metadata.
- A transactionInfo
entry
with a nested list of PartiQL statements associated with the block’s transaction.
Therefore, the ENTRY entity in Figure 9.4 connotes a general term for both high level entries and lower level nested entries (nested data objects) within a block. The ENTRY entity’s one-to-many reflexive relationship portrays this hierarchy of entries that can be composed of lower level entry objects.
The one-to-one relationship between the ENTRY entity and the DOCUMENT entity reveals that an entry can map to a table document (i.e., a single document revision), but that a document must be tied to a single entry of a block. In reality, previously noted attributes for the DOCUMENT entity (e.g., document ID, version number, SHA-256 hash value, etc.) are implemented as fields within the document’s associated block entry.
Likewise, the one-to-one relationship between the ENTRY entity and the STATEMENT entity reveals that an entry can map to a single statement executed for the transaction, but that each statement must be tied to a single entry of a block. Fields for the statement in the entry includes the text of the statement itself and its start time.
The STATEMENT entity, therefore, is indirectly associated with the TRANSACTION entity via its relationship to the ENTRY entity. The one-to-many relationship between the TRANSACTION and STATEMENT entities is really an inferred
relationship. It in fact is redundant because it can be inferred from other relationships (i.e. relationships navigating from STATEMENT to ENTRY to BLOCK and finally to TRANSACTION entities). Figure 9.4 highlights that the one-to-many relationship between the TRANSACTION and STATEMENT entities is an inferred relationship.