Chapter Summary
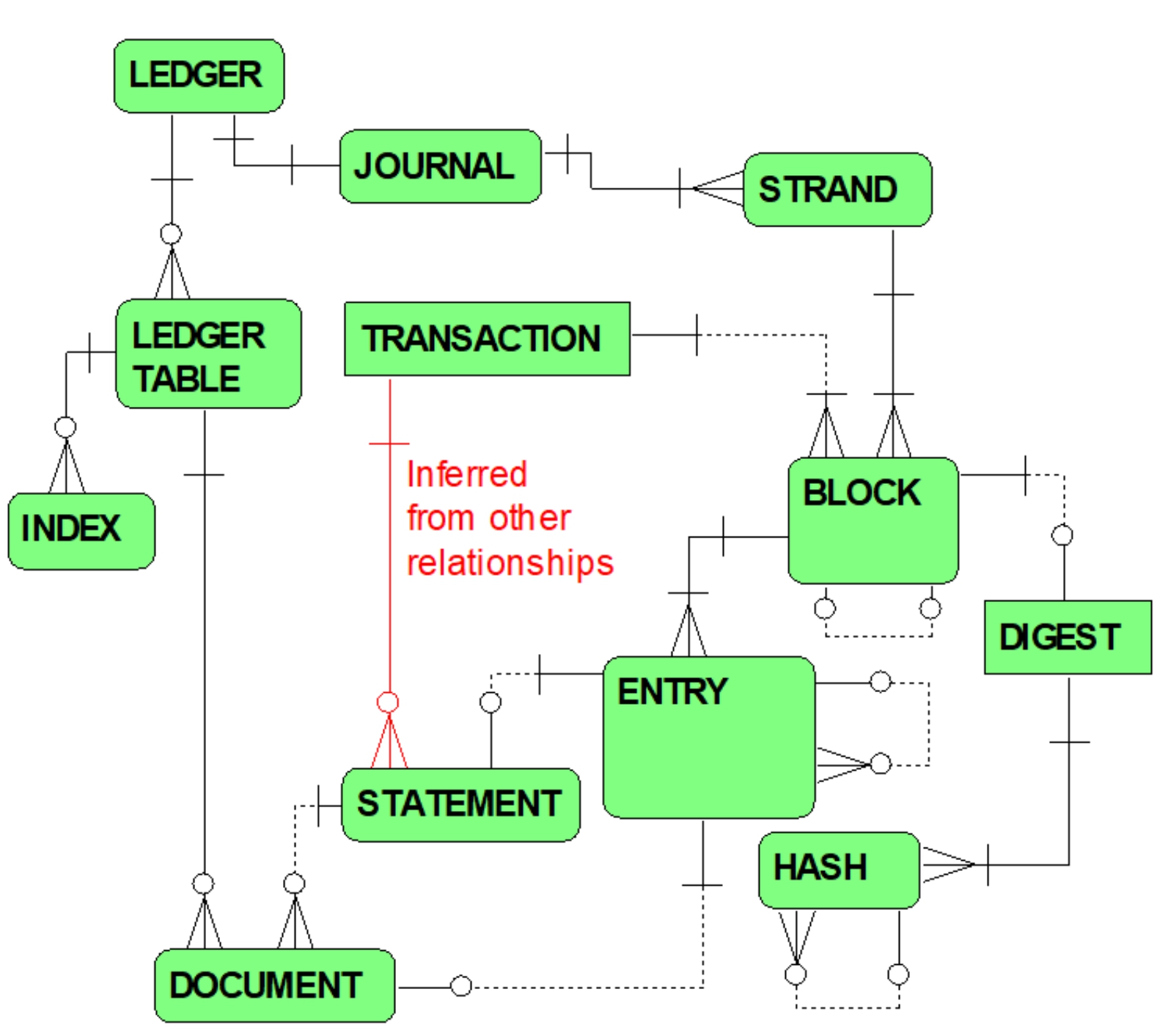
Figure 9.6 summarizes QLDB concepts addressed in this chapter.
Figure 9.6 QLDB Concepts Summar
y
Amazon QLDB, a managed AWS database service, is remarkably different from previously described AWS database services. QLDB focuses on apps requiring a
ledger
database. For QLDB, a ledger database is a data repository for
System of Record
(SOR) apps requiring complete, accurate, transaction history. Examples of SOR apps include eCommerce (online order tracking), Banking (account transaction history), and Product Recall (tracking change history of complex product assemblies). Techniques for implementing change history for conventional database paradigms include extra effort required for custom software development, database enhancements, and database administration. Effort is also required to mitigate internal cyber-security threats to data confidentiality, integrity, and availability (e.g., for implementing
separation of duties
… SOD).
QLDB features distinguishing it from previously described database services include SQL access to documents, built-in change data capture, immutability, and verifiability.
SQL-based Access to Documents:
A QLDB ledger is defined in terms of one or more tables
. Unlike RDBMS and DynamoDB terminology (i.e., where tables respectively consist of one or more rows or items), each ledger table consists of one or more documents
(i.e., similar to DocumentDB)
.
QLDB documents are
schemaless
and formatted in
Amazon Ion
, a superset of the JSON open-standard format. Amazon ION extensions to JSON files include
blobs
,
clobs
and data types for specifying integers, decimals, and floating point numbers. The QLDB DML is
PartiQL
,
an open source query language developed by Amazon. Comparable to SQL, PartiQL was expressly built for flexibly accessing a variety of data formats including relational tables, semi-structured document data, and complex nested documents. PartiQL supports an extended SQL syntax. Its extensions include a
dot notation
and
aliasing
of nested data, enabling direct access to nested data embedded within documents (e.g.,
PO Items
nested within a
Purchase Order
).
Built-in History and Change Data Capture:
QLDB automatically captures changes to ledger documents. Traditional mechanisms for maintaining transaction history are obviated (e.g., triggers, stored procedures, partitioned tables, etc.). QLDB documents are also referred to as document revisions
since a complete history of all revisions is maintained for ledger tables. A QLDB ledger is basically a journal
of transactions maintained within an append-only
data repository.
Each document revision inserted into a ledger table (via a PartiQL INSERT statement) is uniquely identified by combining an automatically generated document ID and version number -- a composite primary key. When an existing document is updated (via a PartiQL UPDATE statement), QLDB appends a new document revision to the journal (same document ID, but the version number is incremented by 1). The previous document revision is not physically altered. A new document revision for reflecting the change supersedes (without replacing) the previous version and becomes current. Deleting an existing document (via a PartiQL DELETE statement) also results in appending a new document revision into the journal.
QLDB supports views
. The default user
view is used for accessing current application data, but no metadata. The committed
view enables access to current info and also includes automatically generated metadata (e.g., document ID, version, a transaction ID, transaction date/time, etc.). PartiQL also provides a history function
for accessing the history (app data and metadata) of prior document revisions.
Immutability:
All PartiQL INSERTs, UPDATEs and DELETEs are journalized such that data can only be appended to the journal -- not allowing prior history to be modified or physically removed. Document revisions (both current and history) cannot be modified after being committed to the journal.
The journal data structure recycles concepts and terminology resonating with
blockchain
technology. A QLDB journal consists of a
chain of blocks
. Each ledger transaction results in persisting one or more blocks of data -- serially chained (i.e., linked) and appended to the journal. Application data and system-generated metadata are stored in the chain of blocks. Each transaction results in committing one or more blocks and each block consists of one or more data
entries
. Document revisions, metadata, and the actual PartiQL statements that committed document revisions are stored as block entries.
A journal’s transaction log consisting of these chained blocks is intuitively immutable given that QLDB automatically logs history, does not modify or delete history, and reflects changes by appending new revisions
.
Verifiability:
QLDB uses hashing techniques for verifying that transaction data has not been transformed since initially committed to the journal. Each block maintains an assortment of
SHA-256
(
S
ecure
H
ash
A
lgorithm) hash codes. SHA-256 is a
cryptographic hash function
that maps any given data input to a 256 bit hash code -- a condensed summarization of the input data. Altering input data results (with high likelihood) in a different hash value -- the key for verifying data integrity. Examples of block attributes whose values are SHA-256 hash codes include
block hash
(i.e. the hash value for all data within a block) and
previous block hash
(i.e., the hash value for the previous block in the chain). The
block hash
becomes the
previous block hash
for the next block in the chain. Each document revision stored within a block is also summarized with a SHA-256 hash value
.
QLDB’s data integrity verification process is summarized as follows:
-
Request a Digest
: A digest is a file (in Amazon ION format, requested via the Amazon QLDB console or QLDB API) that includes yet another SHA-256 hash, the digest hash
. A digest hash condenses a ledger’s full change history up to the last block of the journal. Any document committed to any block within the digest’s scope can be verified. A digest file uses a binary tree structure (Merkle Tree
)
to calculate the digest’s SHA-256 hash. Hash codes for blocks are paired, concatenated, and hashed resulting in proof hashes
at a higher level in the tree structure. Proof hashes are similarly combined for higher level proof hashes --ultimately resulting in the digest hash code at the top of the tree. The digest file also contains a digest tip address
which identifies the location of the last block consumed in the digest.
-
Identify Document To Be Verified:
Metadata for identifying the specific document to be verified must be retrieved from the ledger -- the unique document id (metadata.id
) and a block address (blockaddress).
-
Start Verification:
The QLDB console provides a verify document
form enabling a user to start the verification process by specifying the document to be verified (ledger name, document id and block address) and either selecting an existing digest file or manually entering the digest hash and digest tip address from a saved digest file.
-
Verification Proof:
QLDB uses the concept of a Merkle Audit Proof
for verifying a document’s integrity. Hashes from only a subset of the hash nodes in the digest’s binary tree are used. This subset of hashes is referred to as the audit path
from the block of the document to be audited (leaf node) to the digest (i.e., the root hash). QLDB provides a proof
-- an ordered list of node hashes (from the digest’s node tree) for computing (i.e., rehashing) other hashes (for missing nodes not included in the ordered list) at higher levels in the tree. The process of recalculating hashes climbs up the tree -- resulting in recalculating the digest hash. A recalculated digest hash equal to the originally calculated digest hash as saved in the digest file confirms the document’s integrity.