
HBase Primer

Deepak Vohra
Apache HBase Primer
Deepak Vohra
White Rock, British Columbia
Canada
ISBN-13 (pbk): 978-1-4842-2423-6 ISBN-13 (electronic): 978-1-4842-2424-3 DOI 10.1007/978-1-4842-2424-3
Library of Congress Control Number: 2016959189
Copyright © 2016 by Deepak Vohra
This work is subject to copyright. All rights are reserved by the Publisher, whether the whole or part of the material is concerned, specifically the rights of translation, reprinting, reuse of illustrations, recitation, broadcasting, reproduction on microfilms or in any other physical way, and transmission or information storage and retrieval, electronic adaptation, computer software, or by similar or dissimilar methodology now known or hereafter developed. Trademarked names, logos, and images may appear in this book. Rather than use a trademark symbol with every occurrence of a trademarked name, logo, or image we use the names, logos, and images only in an editorial fashion and to the benefit of the trademark owner, with no intention of infringement of the trademark.
The use in this publication of trade names, trademarks, service marks, and similar terms, even if they are not identified as such, is not to be taken as an expression of opinion as to whether or not they are subject to proprietary rights.
While the advice and information in this book are believed to be true and accurate at the date of publication, neither the authors nor the editors nor the publisher can accept any legal responsibility for any errors or omissions that may be made. The publisher makes no warranty, express or implied, with respect to the material contained herein.
Managing Director: Welmoed Spahr
Lead Editor: Steve Anglin
Technical Reviewer: Massimo Nardone
Editorial Board: Steve Anglin, Pramila Balan, Laura Berendson, Aaron Black, Louise Corrigan, Jonathan Gennick, Robert Hutchinson, Celestin Suresh John, Nikhil Karkal, James Markham, Susan McDermott, Matthew Moodie, Natalie Pao, Gwenan Spearing
Coordinating Editor: Mark Powers
Copy Editor: Mary Behr
Compositor: SPi Global
Indexer: SPi Global
Artist: SPi Global
Distributed to the book trade worldwide by Springer Science+Business Media New York, 233 Spring Street, 6th Floor, New York, NY 10013. Phone 1-800-SPRINGER, fax (201) 348-4505, e-mail orders-ny@springer-sbm.com , or visit www.springeronline.com . Apress Media, LLC is a
California LLC and the sole member (owner) is Springer Science + Business Media Finance Inc (SSBM Finance Inc). SSBM Finance Inc is a Delaware corporation. For information on translations, please e-mail rights@apress.com , or visit www.apress.com .
Apress and friends of ED books may be purchased in bulk for academic, corporate, or promotional use. eBook versions and licenses are also available for most titles. For more information, reference our Special Bulk Sales–eBook Licensing web page at www.apress.com/bulk-sales .
Any source code or other supplementary materials referenced by the author in this text are available to readers at www.apress.com . For detailed information about how to locate your
book’s source code, go to www.apress.com/source-code/ . Readers can also access source code
at SpringerLink in the Supplementary Material section for each chapter. Printed on acid-free paper

About the Author ............................................................................ xiii
About the Technical Reviewer ......................................................... xv
Introduction ................................................................................... xvii
■ 1
■ Chapter 1: Fundamental Characteristics ........................................ 3
■ Chapter 2: Apache HBase and HDFS ............................................... 9
■ Chapter 3: Application Characteristics ......................................... 45
■ 49
■ Chapter 4: Physical Storage ......................................................... 51
■ Chapter 5: Column Family and Column Qualifi er .......................... 53
■ Chapter 6: Row Versioning ........................................................... 59
■ Chapter 7: Logical Storage ........................................................... 63
■ 67
■ Chapter 8: Major Components of a Cluster ................................... 69
■ Chapter 9: Regions ....................................................................... 75
■ Chapter 10: Finding a Row in a Table ........................................... 81
■ Chapter 11: Compactions ............................................................. 87
■ Chapter 12: Region Failover ......................................................... 99
■ Chapter 13: Creating a Column Family ....................................... 105
■ CONTENTS AT A GLANCE
■ 109
■ Chapter 14: Region Splitting....................................................... 111
■ Chapter 15: Defi ning the Row Keys ............................................ 117
■ 121
■ Chapter 16: The HBaseAdmin Class............................................ 123
■ Chapter 17: Using the Get Class ................................................. 129
■ Chapter 18: Using the HTable Class ............................................ 133
■ 135
■ Chapter 19: Using the HBase Shell ............................................. 137
■ Chapter 20: Bulk Loading Data ................................................... 145
Index .............................................................................................. 149

About the Author ............................................................................ xiii
About the Technical Reviewer ......................................................... xv
Introduction ................................................................................... xvii
■ 1
■ Chapter 1: Fundamental Characteristics ........................................ 3
Distributed ............................................................................................... 3
Big Data Store ......................................................................................... 3
Non-Relational ......................................................................................... 3
Flexible Data Model ................................................................................. 4
Scalable ................................................................................................... 4
Roles in Hadoop Big Data Ecosystem ...................................................... 5
How Is Apache HBase Different from a Traditional RDBMS? ................... 5
Summary ................................................................................................. 8
■ Chapter 2: Apache HBase and HDFS ............................................... 9
Overview ................................................................................................. 9
Storing Data .......................................................................................... 14
HFile Data fi les- HFile v1 ....................................................................... 15
HBase Blocks ........................................................................................ 17
Key Value Format .................................................................................. 18
HFile v2 ................................................................................................. 19
Encoding................................................................................................ 20
■ CONTENTS
Compaction ........................................................................................... 21
KeyValue Class ...................................................................................... 21
Data Locality .......................................................................................... 24
Table Format ......................................................................................... 25
HBase Ecosystem .................................................................................. 25
HBase Services ..................................................................................... 26
Auto-sharding ........................................................................................ 27
The Write Path to Create a Table ........................................................... 27
The Write Path to Insert Data ................................................................ 28
The Write Path to Append-Only R/W ...................................................... 29
The Read Path for Reading Data ........................................................... 30
The Read Path Append-Only to Random R/W ........................................ 30
HFile Format .......................................................................................... 30
Data Block Encoding ............................................................................. 31
Compactions ......................................................................................... 32
Snapshots ............................................................................................. 32
The HFileSystem Class .......................................................................... 33
Scaling .................................................................................................. 33
HBase Java Client API............................................................................ 35
Random Access ..................................................................................... 36
Data Files (HFile) ................................................................................... 36
Reference Files/Links ............................................................................ 37
Write-Ahead Logs .................................................................................. 38
Data Locality .......................................................................................... 38
Checksums ............................................................................................ 40
Data Locality for HBase ......................................................................... 42
■ CONTENTS
MemStore .............................................................................................. 42
Summary ............................................................................................... 43
■ Chapter 3: Application Characteristics ......................................... 45
Summary ............................................................................................... 47
■ 49
■ Chapter 4: Physical Storage ......................................................... 51
Summary ............................................................................................... 52
■ Chapter 5: Column Family and Column Qualifi er .......................... 53
Summary ............................................................................................... 57
■ Chapter 6: Row Versioning ........................................................... 59
Versions Sorting .................................................................................... 61
Summary ............................................................................................... 62
■ Chapter 7: Logical Storage ........................................................... 63
Summary ............................................................................................... 65
■ 67
■ Chapter 8: Major Components of a Cluster ................................... 69
Master ................................................................................................... 70
RegionServers ....................................................................................... 70
ZooKeeper ............................................................................................. 71
Regions ................................................................................................. 72
Write-Ahead Log .................................................................................... 72
Store ...................................................................................................... 72
HDFS...................................................................................................... 73
Clients ................................................................................................... 73
Summary ............................................................................................... 73
■ CONTENTS
■ Chapter 9: Regions ....................................................................... 75
How Many Regions? .............................................................................. 76
Compactions ......................................................................................... 76
Region Assignment ................................................................................ 76
Failover .................................................................................................. 77
Region Locality ...................................................................................... 77
Distributed Datastore ............................................................................ 77
Partitioning ............................................................................................ 77
Auto Sharding and Scalability ............................................................... 78
Region Splitting ..................................................................................... 78
Manual Splitting .................................................................................... 79
Pre-Splitting .......................................................................................... 79
Load Balancing ...................................................................................... 79
Preventing Hotspots .............................................................................. 80
Summary ............................................................................................... 80
■ Chapter 10: Finding a Row in a Table ........................................... 81
Block Cache ........................................................................................... 82
The hbase:meta Table .......................................................................... 83
Summary ............................................................................................... 85
■ Chapter 11: Compactions ............................................................. 87
Minor Compactions ............................................................................... 87
Major Compactions ............................................................................... 88
Compaction Policy ................................................................................. 88
Function and Purpose ........................................................................... 89
Versions and Compactions .................................................................... 90
Delete Markers and Compactions ......................................................... 90
Expired Rows and Compactions ............................................................ 90
■ CONTENTS
Region Splitting and Compactions ........................................................ 90
Number of Regions and Compactions ................................................... 91
Data Locality and Compactions ............................................................. 91
Write Throughput and Compactions ...................................................... 91
Encryption and Compactions................................................................. 91
Confi guration Properties ....................................................................... 92
Summary ............................................................................................... 97
■ Chapter 12: Region Failover ......................................................... 99
The Role of the ZooKeeper .................................................................... 99
HBase Resilience ................................................................................... 99
Phases of Failover ............................................................................... 100
Failure Detection ................................................................................. 102
Data Recovery ..................................................................................... 102
Regions Reassignment ........................................................................ 103
Failover and Data Locality ................................................................... 103
Confi guration Properties ..................................................................... 103
Summary ............................................................................................. 103
■ Chapter 13: Creating a Column Family ....................................... 105
Cardinality ........................................................................................... 105
Number of Column Families ................................................................ 106
Column Family Compression ............................................................... 106
Column Family Block Size ................................................................... 106
Bloom Filters ....................................................................................... 106
IN_MEMORY ........................................................................................ 107
MAX_LENGTH and MAX_VERSIONS ..................................................... 107
Summary ............................................................................................. 107
■ CONTENTS
■ 109
■ Chapter 14: Region Splitting....................................................... 111
Managed Splitting ............................................................................... 112
Pre-Splitting ........................................................................................ 113
Confi guration Properties ..................................................................... 113
Summary ............................................................................................. 116
■ Chapter 15: Defi ning the Row Keys ............................................ 117
Table Key Design ................................................................................. 117
Filters .................................................................................................. 118
FirstKeyOnlyFilter Filter ........................................................................................ 118
KeyOnlyFilter Filter ............................................................................................... 118
Bloom Filters ....................................................................................... 118
Scan Time ............................................................................................ 118
Sequential Keys ................................................................................... 118
Defi ning the Row Keys for Locality ..................................................... 119
Summary ............................................................................................. 119
■ 121
■ Chapter 16: The HBaseAdmin Class............................................ 123
Summary ............................................................................................. 127
■ Chapter 17: Using the Get Class ................................................. 129
Summary ............................................................................................. 132
■ Chapter 18: Using the HTable Class ............................................ 133
Summary ............................................................................................. 134
■ CONTENTS
■ 135
■ Chapter 19: Using the HBase Shell ............................................. 137
Creating a Table ................................................................................... 137
Altering a Table .................................................................................... 138
Adding Table Data ................................................................................ 139
Describing a Table ............................................................................... 139
Finding If a Table Exists ....................................................................... 139
Listing Tables ....................................................................................... 139
Scanning a Table ................................................................................. 140
Enabling and Disabling a Table............................................................ 141
Dropping a Table .................................................................................. 141
Counting the Number of Rows in a Table ............................................ 141
Getting Table Data ............................................................................... 141
Truncating a Table ............................................................................... 142
Deleting Table Data ............................................................................. 142
Summary ............................................................................................. 143
■ Chapter 20: Bulk Loading Data ................................................... 145
Summary ............................................................................................. 147
Index .............................................................................................. 149

Deepak Vohra is a consultant and a principal member of
the NuBean software company. Deepak is a Sun-certified
Java programmer and Web component developer. He has
worked in the fields of XML, Java programming, and Java
EE for over seven years. Deepak is the coauthor of Pro
XML Development with Java Technology (Apress, 2006).
Deepak is also the author of the JDBC 4.0 and Oracle
JDeveloper for J2EE Development, Processing XML
Documents with Oracle JDeveloper 11g, EJB 3.0 Database
Persistence with Oracle Fusion Middleware 11g , and Java
EE Development in Eclipse IDE (Packt Publishing). He
also served as the technical reviewer on WebLogic: The
 Definitive Guide (O’Reilly Media, 2004) and Ruby
Definitive Guide (O’Reilly Media, 2004) and Ruby
Programming for the Absolute Beginner ( Cengage
Learning PTR, 2007).

Massimo Nardone has more than 22 years of
experience in security, web/mobile development, and
cloud and IT architecture. His true IT passions are
security and Android. He has been programming and
teaching how to program with Android, Perl, PHP, Java,
VB, Python, C/C++, and MySQL for more than 20 years.
Technical skills include security, Android, cloud, Java,
MySQL, Drupal, Cobol, Perl, web and mobile
development, MongoDB, D3, Joomla, Couchbase,
C/C++, WebGL, Python, Pro Rails, Django CMS, Jekyll,
Scratch, etc.
He currently works as Chief Information
 Security Office (CISO) for Cargotec Oyj. He holds four
Security Office (CISO) for Cargotec Oyj. He holds four
international patents (PKI, SIP, SAML, and Proxy areas).
He worked as a visiting lecturer and supervisor for
exercises at the Networking Laboratory of the Helsinki University of Technology (Aalto University). He has also worked as a Project Manager, Software Engineer, Research Engineer, Chief Security Architect, Information Security Manager, PCI/SCADA Auditor, and Senior Lead IT Security/Cloud/SCADA Architect for many years. He holds a Master of Science degree in Computing Science from the University of Salerno, Italy.
Massimo has reviewed more than 40 IT books for different publishing companies, and he is the coauthor of Pro Android Games (Apress, 2015).

Apache HBase is an open source NoSQL database based on the wide-column data store model. HBase was initially released in 2008. While many NoSQL databases are available, Apache HBase is the database for the Apache Hadoop ecosystem.
HBase supports most of the commonly used programming languages such as C, C++, PHP, and Java. The implementation language of HBase is Java. HBase provides access support with Java API, RESTful HTTP API, and Thrift.
Some of the other Apache HBase books have a practical orientation and do not discuss HBase concepts in much detail. In this primer level book, I shall discuss Apache HBase concepts. For practical use of Apache HBase, refer another Apress book: Practical Hadoop Ecosystem .


Apache HBase is the Hadoop database. HBase is open source and its fundamental characteristics are that it is a non-relational, column-oriented, distributed, scalable, big data store. HBase provides schema flexibility. The fundamental characteristics of Apache HBase are as follows.
Distributed
HBase provides two distributed modes. In the pseudo-distributed mode, all HBase daemons run on a single node. In the fully-distributed mode , the daemons run on multiple nodes across a cluster. Pseudo-distributed mode can run against a local file system or an instance of the Hadoop Distributed File System (HDFS) . When run against local file system, durability is not guaranteed. Edits are lost if files are not properly closed. The fully-distributed mode can only run on HDFS. Pseudo-distributed mode is suitable for small-scale testing while fully-distributed mode is suitable for production. Running against HDFS preserves all writes.
HBase supports auto-sharding, which implies that tables are dynamically split and distributed by the database when they become too large.
Big Data Store
HBase is based on Hadoop and HDFS, and it provides low latency, random, real-time, read/ write access to big data. HBase supports hosting very large tables with billions of rows and billions/millions of columns. HBase can handle petabytes of data. HBase is designed for queries of massive data sets and is optimized for read performance. Random read access is not a Apache Hadoop feature as with Hadoop the reader can only run batch processing, which implies that the data is accessed only in a sequential way so that it has to search the entire dataset for any jobs needed to perform.
Non-Relational
HBase is a NoSQL database. NoSQL databases are not based on the relational database model. Relational databases such as Oracle database, MySQL database, and DB2 database store data in tables, which have relations between them and make use of © Deepak Vohra 2016 3
D. Vohra, Apache HBase Primer , DOI 10.1007/978-1-4842-2424-3_1 CHAPTER 1 ■ FUNDAMENTAL CHARACTERISTICS
SQL (Structured Query Language) to access and query the tables. NoSQL databases, in contrast, make use of a storage-and-query mechanism that is predominantly based on a non-relational, non-SQL data model. The data storage model used by NoSQL databases is not some fixed data model; it is a flexible schema data model. The common feature among the NoSQL databases is that the relational and tabular database model of SQL-based databases is not used. Most NoSQL databases make use of no SQL at all, but NoSQL does not imply absolutely no SQL is used, because of which NoSQL is also termed as “not only SQL.”
Flexible Data Model
In 2006 the Google Labs team published a paper entitled “BigTable: A Distributed Storage System for Structured Data" ( http://static.googleusercontent.com/media/research. google.com/en//archive/bigtable-osdi06.pdf ). Apache HBase is a wide-column data store based on Apache Hadoop and on BigTable concepts. The basic unit of storage in HBase is a table . A table consists of one or more column families , which further consists of columns . Columns are grouped into column families. Data is stored in rows . A row is a collection of key/value pairs. Each row is uniquely identified by a row key. The row keys are created when table data is added and the row keys are used to determine the sort order and for data sharding , which is splitting a large table and distributing data across the cluster.
HBase provides a flexible schema model in which columns may be added to a table column family as required without predefining the columns. Only the table and column family/ies are required to be defined in advance. No two rows in a table are required to have the same column/s. All columns in a column family are stored in close proximity.
HBase does not support transactions. HBase is not eventually consistent but is a strongly consistent at the record level. Strong consistency implies that the latest data is always served but at the cost of increased latency. In contrast, eventual consistency can return out-of-date data.
HBase does not have the notion of data types, but all data is stored as an array of bytes. Rows in a table are sorted lexicographically by row key, a design feature that makes
it feasible to store related rows (or rows that will be read together) together for optimized scan.
Scalable
The basic unit of horizontal scalability in HBase is a region . Rows are shared by regions. A region is a sorted set consisting of a range of adjacent rows stored together. A table’s data can be stored in one or more regions. When a region becomes too large, it splits into two at the middle row key into approximately two equal regions. For example, in Figure 1-1 , the region has 12 rows, and it splits into two regions with 6 rows each.
CHAPTER 1 ■ FUNDAMENTAL CHARACTERISTICS
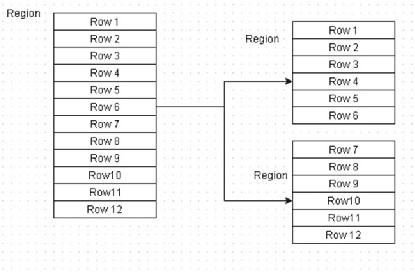
Figure 1-1. Region split example
For balancing, data associated with a region can be stored on different nodes in a cluster.
Roles in Hadoop Big Data Ecosystem HBase is run against HDFS in the fully-distributed mode; it also has the same option available in the pseudo-distributed mode. HBase stores data in StoreFiles on HDFS. HBase does not make use of the MapReduce framework of Hadoop but could serve as the source and/or destination of MapReduce jobs.
Just as Hadoop, HBase is designed to run on commodity hardware with tolerance for individual node failure. HBase is designed for batch processing systems optimized for streamed access to large data sets. While HBase supports random read access, HBase is not designed to optimize random access. HBase incurs a random read latency which may be reduced by enabling the Block Cache and increasing the Heap size.
HBase can be used for real-time analytics in conjunction with MapReduce and other frameworks in the Hadoop ecosystem, such as Apache Hive. How Is Apache HBase Different from a Traditional RDBMS?
HBase stores data in a table, which has rows and column just as a RDBMS does, but the databases are mostly different, other than the similar terminology. Table 1-1 shows the salient differences.
Schema Fixed schema Flexible schema
Data volume Small to medium (few Big Data (hundreds of thousand or a million rows). millions or billions rows). PB TB of data.
Primary query language SQL Get, Put, Scan shell
commands.
Data types Typed columns No data types
Relational integrity Supported Not supported
Joins Supports joins, such as Does not provide built-in
equi-joins and outer-joins support for joins. Joins using
MapReduce.
Data structure Highly structured and Un-structured, semi-statically structured. Fixed structured, and structured. data model. Flexible data model.
Transactions Supported Not supported
Advanced query language Supported Not supported
Indexes Primary, secondary, B-Tree, Secondary indexes
Clustered
Consistency Strongly consistent. CAP Strongly consistent. ACID theorem consistency.
Scalability Provides some level of Highly scalable with
scalability with vertical horizontal scalability in
scaling in which additional which additional servers
capacity may be added to a may be added. Scales
server linearly.
Distributed Distributed to some extent Highly distributed Real-time queries Supported
Triggers Supported Provides RDBMS-
like triggers through
coprocessors
Hardware Specialized hardware and Commodity hardware and less hardware more hardware
Stored procedures Supported Provides stored procedures
through coprocessors
Java Does not require Java Requires Java
High Availability Supported Ultra-high availability
Fault tolerant Fault tolerant to some extent Highly fault tolerant Normalization Required for large data sets Not required Object-oriented Because of the complexity The key-value storage makes programming model of aggregating data, using HBase suitable for object-
JOINS using an object- oriented programming
oriented programming model. Supported with
model is not suitable. client APIs in object-
oriented languages such as
PHP, Ruby, and Java.
Administration More administration Less administration with auto-sharding, scaling, and
rebalancing
Architecture Monolithic Distributed
Sharding Limited support. Manual Auto-sharding
server sharding. Table
partitioning.
Write performance Does not scale well Scales linearly
Single point of failure With single point of failure Without single point of failure
Replication Asynchronous Asynchronous
Storage model Tablespaces StoreFiles (HFiles) in HDFS
Compression Built-in with some RDBMS Built-in Gzip compression in storage engine/table/
index. Various methods
available to other RDBMS.
Caching Standard data/metadata In-memory caching
cache with query cache
Primary data object Table Table
Read/write throughput 1000s of queries per second Millions of queries per second
Security Authentication/ Authentication/
Authorization Authorization
Row-/Column- Oriented Row-oriented Column-oriented Sparse tables Suitable for sparse tables Not optimized for sparse
tables
Wide/narrow tables Narrow tables Wide tables
MapReduce integration Not designed for MR Well integrated CHAPTER 1 ■ FUNDAMENTAL CHARACTERISTICS
Summary
In this chapter, I discussed the fundamental characteristics of big data store Apache HBase, which are its distributedness, scalability, non-relational, and flexible model. I also discussed HBase's role in the Hadoop big data ecosystem and how is HBase different from traditional RDBMS. In the next chapter, I will discuss how HBase stores its data in a H D F S .

Apache HBase runs on HDFS as the underlying filesysystem and benefits from HDFS features such as data reliability, scalability, and durability. HBase stores data as Store Files ( HFiles ) on the HDFS Datanodes. HFile is the file format for HBase and org.apache.hadoop.hbase. io.hfile.HFile is a Java class. HFile is an HBase-specific file format that is based on the TFile binary file format. A Store File is a lightweight wrapper around the HFile. In addition to storing table data HBase also stores the write-ahead logs (WALs ), which store data before it is written to HFiles on HDFS. HBase provides a Java API for client access. HBase itself is a HDFS client and makes use of the Java class DFSClient . References to DFSClient appear in the HBase client log messages and HBase logs as HBase makes use of the class to connect to NameNode to get block locations for Datanode blocks and add data to the Datanode blocks. HBase leverages the fault tolerance provided by the Hadoop Distributed File System (HDFS) . HBase requires some configuration at the client side (HBase) and the server side (HDFS). Overview
HBase storage in HDFS has the following characteristics :
• Large files
• A lot of random seeks
• Latency sensitive
• Durability guarantees with sync
• Computation generates local data
• Large number of open files
HBase makes use of three types of files:
• WALs or HLogs
• Data files (also known as store files or HFile s)
• 0 length files: References (symbolic or logical links)
Each file is replicated three times. Data files are stored in the following format in which "userTable" and "table1" are example tables, and "098345asde5t6u" and "09jhk7y65" are regions, and "family" and "f1" are column families, and "09ojki8dgf6" and "90oifgr56" are the data files:
© Deepak Vohra 2016 9
D. Vohra, Apache HBase Primer , DOI 10.1007/978-1-4842-2424-3_2 CHAPTER 2 ■ APACHE HBASE AND HDFS
hdfs://localhost:41020/hbase/userTable/098345asde5t6u/family/09ojki8dgf6 hdfs://localhost:41020/hbase/userTable/09drf6745asde5t6u/family/09ojki8ddfre5 hdfs://localhost:41020/hbase/table1/09jhk7y65/f1/90oifgr56
Write-ahead logs are stored in the following format in which "server1" is the region server: hdfs://localhost:41020/hbase/.logs/server1,602045,123456090 hdfs://localhost:41020/hbase/.logs/server1,602045,123456090/server1%2C134r5
Links are stored in the following format in which "098eerf6" is a region, "family" is a column family and "8uhy67" is the link:
hdfs://localhost:41020/hbase/.hbase_snapshot/usertable_snapshot/098eerf6/ family/8uhy67
Datanode failure is handled by HDFS using replication. HBase provides real-time, random, read/write access to data in the HDFS. A data consumer reads data from HBase, which reads data from HDFS, as shown in Figure 2-1 . A data producer writes data to HBase, which writes data to HDFS. A data producer may also write data to HDFS directly.

Figure 2-1. Apache HBase read/write path
HBase is the most advanced user of HDFS and makes use of the HFileSystem (an encapsulation of FileSystem ) Java API. HFileSystem has the provision to use separate filesystem objects for reading and writing WALs and HFiles. The HFileSystem. create(Path path) method is used to create the HFile data files and HLog W A L s .
HBase communicates with both the NameNode and the Datanodes using HDFS Client classes such as DFSClient . HDFS pipelines communications, including data writes, from one Datanode to another as shown in Figure 2-2 . HBase write errors, including communication issues between Datanodes, are logged to the HDFS logs and not the HBase logs. Whenever feasible HBase writes are local, which implies that the writes are to a local Datanode. As a result, Region Servers should not get too many write errors. Errors may be logged in both HDFS and HBase but if a Datanode is not able to replicate data blocks, errors are written to HDFS logs and not the HBase logs.
CHAPTER 2 ■ APACHE HBASE AND HDFS

Figure 2-2. Apache HBase communication with NameNode and Datanode
The hdfs-site.xml configuration file contains information like the following: • The value of replication factor
• NameNode path
• Datanode path of the local file systems where you want to store the Hadoop infrastructure
A HBase client communicates with the ZooKeeper and the HRegionServers . The HMaster coordinates the RegionServers. The RegionServers run on the Datanodes. When HBase starts up, the HMaster assigns the regions to each RegionServer, including the regions for the –ROOT- and .META. ( hbase:meta catalog table in later version) tables. The HBase table structure comprises of Column Families (or a single Column Family), that group similar column data. The basic element of distribution for an HBase table is a Region, which is further comprised of a Store per column family. A Region is a subset of a table’s data. A set of regions is served by a RegionServer and each region is served by only one RegionServer. A Store has an in-memory component called the MemStore and a persistent storage component called an HFile or StoreFile. The DFSClient is used to store and replicate the HFiles and HLogs in the HDFS datanodes. The storage architecture of HBase is shown in Figure 2-3 .
CHAPTER 2 ■ APACHE HBASE AND HDFS

Figure 2-3. Apache HBase storage architecture
As shown in Figure 2-3 , the HFiles and HLogs are primarily handled by the HRegions but sometimes even the HRegionServers have to perform low-level operations. The following flow sequence is used when a new client contacts the ZooKeeper quorum to find a row key:
1. First, the client gets the server name that hosts the –ROOT- region from the ZooKeeper. In later versions, the –ROOT-
region is not used and the hbase:meta table location is stored directly on the ZooKeeper.
2. Next, the client queries the server to get the server that hosts the .META. tables. The –ROOT- and .META. server info is
cached and looked up once only.
3. Subsequently, the client queries the .META. server to get the server that has the row the client is trying to get.
4. The client caches the information about the HRegion in which the row is located.
5. The client contacts the HRegionServer hosting the region directly. The client does not need to contact the .META. server again and again once it finds and caches information about the location of the row/s.
6. The HRegionServer opens the region and creates a HRegion object. A store instance is created for each HColumnFamily for each table. Each of the store instances can have StoreFile instances, which are lightweight wrappers around the HFile storage files. Each HRegion has a MemStore and a HLog
instance.
CHAPTER 2 ■ APACHE HBASE AND HDFS
HBase communicates with HDFS on two different ports:
1. Port 50010 using the ipc.Client interface. It is configured in HDFS using the dfs.datanode.ipc.address configuration parameter.
2. Port 50020 using the DataNode class. It is configured in HDFS using the dfs.datanode.address configuration parameter.
Being just another HDFS client, the configuration settings for HDFS also apply to HBase. Table 2-1 shows how the HDFS configuration settings pertain to retries and timeouts.
Table 2-1. HDFS Configuration Settings
ipc.client.connect.max. Number of tries a HBase client core-default.xml retries will make to establish a server
connection. Default is 10. For
SASL connections, the setting is
hard coded at 15 and cannot be
reconfigured.
ipc.client.connect.max. Number of tries an HBase client will core-default.xml retries.on.timeouts make on socket timeout to establish
a server connection. Default is 45.
dfs.client.block.write. Number of retries HBase makes to hdfs-default.xml retries write to a datanode before signaling
a failure. Default is 3. After hitting the
failure threshold, the HBase client
reconnects with the NameNode
to get block locations for another
datanode.
dfs.client.socket- The time before which an HBase hdfs-default.xml timeout client trying to establish socket
connection or reading times out.
Default is 60 secs.
dfs.datanode.socket. The time before which a write hdfs-default.xml write.timeout operation times out. Default is 8
CHAPTER 2 ■ APACHE HBASE AND HDFS
Storing Data
Data is written to the actual storage in the following sequence: 1. The client sends an HTable.put(Put) request to the
HRegionServer. The org.apache.hadoop.hbase.client. HTable class is used to communicate with a single HBase
table. The class provides the put(List<Put> puts) and the put(Put put) methods to put some data in a table. The org. apache.hadoop.hbase.client.Put class is used to perform Put operations for a single row.
2. The HRegionServer forwards the request to the matching HRegion.
3. Next, it is ascertained if data is to be written to the WAL, which is represented with the HLog class. Each RegionServer has a HLog object. The Put class method setWriteToWAL(boolean write) , which is deprecated in HBase 0.94, or the
setDurability(Durability d) method is used to set if data is to be written to WAL. Durability is an enum with values listed in Table 2-2 ; Put implements the Mutation abstract class,
which is extended by classes implementing put, delete, and append operations.
Table 2-2. D u r a b ilit y E n u m s
ASYNC_WAL Write the Mutation to the WAL asynchronously as soon as possible. FSYNC_WAL Write the Mutation to the WAL synchronously and force the entries
to disk.
SKIP_WAL Do not write the Mutation to the WAL.
SYNC_WAL Write the Mutation to the WAL synchronously.
The WAL is a standard sequence file ( SequenceFile ) instance. If data is to be written to WAL, it is written to the WAL.
1. After the data is written (or not) to the WAL, it is put in the MemStore . If the MemStore is full, data is flushed to the disk.
2. A separate thread in the HRegionServer writes the data to an HFile in HDFS. A last written sequence number is also saved.
The HFile and HLog files are written in subdirectories of the root directory in HDFS for HBase, the /hbase directory. The HLog files are written to the /hbase/.logs directory. A sub-directory for each HRegionServer is created within the .logs directory. Within the HLog file, a log is written for each HRegion.
CHAPTER 2 ■ APACHE HBASE AND HDFS
For the data files (HFiles), a subdirectory for each HBase table is created in the /hbase directory. Within the directory (ies) corresponding to the tables, subdirectories for regions are created. Each region name is encoded to create the subdirectory for the region. Within the region’s subdirectories, further subdirectories are created for the
column families. Within the directories for the column family, the HFile files are stored. As a result, the directory structure in HDFS for data files is as follows: /hbase/<tablename>/<encoded-regionname>/<column-family>/<filename>
The root of the region directory has the .regioninfo file containing metadata for the region. HBase regions split automatically if the HFile data file’s storage exceeds the limit set by the hbase.hregion.max.filesize setting in the hbase-site.xml/hbase-default.xml configuration file. The default setting for hbase.hregion.max.filesize is 10GB. When the default storage requirement for a region exceeds the hbase.hregion. max.filesize parameter value, the region splits into two and reference files are created in the new regions. The reference files contain information such as the key at which the region was split. The reference files are used to read the original region data files. When compaction is performed, new data files are created in a new region directory and the reference files are removed. The original data files in the original region are also removed.
Each /hbase/table directory also contains a compaction.dir directory, which is used when splitting and compacting regions.
HFile Data files- HFile v1
Up to version 0.20, HBase used the MapFile format. In HBase 0.20, MapFile is replaced by the HFile format. HFile is made of data blocks, which have the actual data, followed by metadata blocks (optional), a fileinfo block, the data block index, the metadata block index, and a fixed size trailer, which records the offsets at which the HFile changes content type. <data blocks><meta blocks><fileinfo><data index><meta index><trailer>
Each block has a “magic” at the start. Blocks are in a key/value format. In data blocks, both the key and the value are a byte array. In metadata blocks, the key is a String and the value is a byte array. An empty file structure is as follows:
<fileinfo><trailer>
The HFile format is based on the TFile binary file format. The HFile format version 1 is shown in Figure 2-4 .

Figure 2-4. HFile file format
CHAPTER 2 ■ APACHE HBASE AND HDFS
The different sections of the HFile are discussed in Table 2-3 . Table 2-3. HFile Sections
Data The data blocks in which the HBase table data is stored. The actual data is stored as key/value pairs. It’s optional, but most likely an HFile has data.
The list of records in a data block are stored in the following format: Key Length: int
Value Length: int
Key: byte[]
Value: byte[]
Meta The metadata blocks. The meta is the metadata for the data stored in HFile. Optional. Meta blocks are writtern upon file close. RegionServer’s StoreFile uses metadata blocks to store a bloom filter, which is used to avoid reading a file if there is no chance that the key is present. A bloom filter just indicates that maybe the key is in the file. The file/s still need to be scanned to find if the key is in the file.
FileInfo FileInfo is written upon file close. FileInfo is a simple Map with key/ value pairs that are both a byte array. RegionServer’s StoreFile uses FileInfo to store Max SequenceId, the major compaction key, and timerange info. Max SequenceId is used to avoid reading a file if the file is too old. Timerange is used to avoid reading a file if the file is too new. Meta information about the HFile such as MAJOR_COMPACTION_KEY , MAX_SEQ_ID_KEY , hfile.AVG_KEY_LEN , hfile.AVG_VALUE_LEN , hfile. COMPARATOR , hfile.LASTKEY
The format of the FileInfo is as follows:
Last Key: byte[]
Avg Key Length: int
Avg Value Length: int
Comparator Class: byte[]
Data Index Records the offset of the data blocks. The format of the data index is as follows:
Block Begin: long
Block Size: int
Block First Key: byte[]
Meta Index Records the offset of the meta blocks. The format of the meta index is as follows:
Block Begin: long
Block Size: int
Trailer Has pointers to the other blocks and is written last. The format of the Trailer is as follows:
FileInfo Offset: long
Data/Meta Index Offset: long
Data/Meta Index Count: long
Total Bytes: long
Entry Count: long
Compression Codec: int
On load, the following sequence is followed:
1. Read the trailer
2. Seek Back to read file info
3. Read the data index
4. Read the meta index
Each data block contains a “magic” header and KeyValue pairs of actual data in plain or compressed form, as shown in Figure 2-5 .
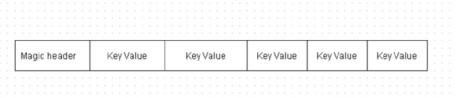
Figure 2-5. A d a ta b lo c k
HBase Blocks
The default block size for an HFile file is 64KB, which is several times less than the minimum HDFS block size of 64MB. A minimum block size between 8KB and 1MB is recommended for the HFile file. If sequential access is the primary objective, a larger block size is preferred. A larger block size is inefficient for random access because more data has to be decompressed. For random access, small block sizes are more efficient but have the following disadvantages:
1. They require more memory to hold the block index
2. They may be slower to create
3. The smallest feasible block size is limited to 20KB-30KB because the compressor stream must be flushed at the end of each data block
CHAPTER 2 ■ APACHE HBASE AND HDFS
The default minimum block size for HFile may be configured in hbase-site.xml with the hfile.min.blocksize.size parameter. Blocks are used for different purpose in HDFS and HBase. In HDFS, blocks are the unit of storage on disk. In HBase, blocks are the unit of storage for memory. Many HBase blocks fit into a single HBase file. HBase is designed to maximize efficiency from the HDFS file system and fully utilize the HDFS block size.
Key Value Format
The org.apache.hadoop.hbase.KeyValue class represents a HBase key/value. The KeyValue format is as follows:
<keylength> <valuelength> <key> <value>
A KeyValue is a low-level byte array structure made of the sections shown in Figure 2-6 .

Figure 2-6. A KeyValue
The key has the following format:
<rowlength> <row> <columnfamilylength> <columnfamily> <columnqualifier> <timestamp> <keytype>