
The different sections of a KeyValue are discussed in Table 2-4 . Key Length The key length. Using the key length and the value length
information, direct access to the value may be made without using the key.
Value Length The value length. Using the key length and the value length information, direct access to the value may be made without using the key.
Row Length The row length
Row The row
Column Family Length The column family length
Column Family The column family
Column Qualifier The column qualifier
Time Stamp The timestamp
Key Type The key type
HFile data files are immutable once written. HFiles are generated by flush or compactions (sequential writes). HFiles are read randomly or sequentially. HFiles are big in size with a flush size of tens of GB. Data blocks have a target size represented by BLOCKSIZE in the column family descriptor, which is 64KB by default. The target size is an uncompressed and unencoded size. Index blocks (leaf, intermediate, root) also have a target size configured with the hfile.index.block.max.size with a default value of 128KB.
Bloom filters may be used to improve read efficiency. Bloom filters may be enabled per column family. Bloom filter blocks have a target size configured with io.storefile. bloom.block.size with a default value of 128KB.
HFile v2
To improve performance when large quantities of data are stored, the HFile format has been modified. One of the issues with v1 is that the data and meta indexes and large bloom filters need to be loaded in memory, which slows down the loading process and also uses excessive memory and cache. Starting with HBase 0.92, the HFile v2 introduces multi-level indexes and a block-level bloom filter for improved speed, memory, and cache usage.
HFile v2 introduces a block-level index as an inline-block. Instead of having a monolithic index and a bloom filter in memory, the index and bloom filter are broken per block, thus reducing the load on the memory. The block-level index is called a leaf index . Block-level indexing creates a multi-level index, an index per block. The data block structure is shown in Figure 2-7 . The meta and intermediate index blocks are optional.
CHAPTER 2 ■ APACHE HBASE AND HDFS
Figure 2-7. D a ta b lo c k s tr u c tu r e
The last key in each block is kept to create an intermediate index to make the multi-level index B-tree like.
The block header consists of a block type instead of the “magic” in v1. The block type is a description of the block content, such as the data, leaf index, bloom, meta, root index, meta index, file info, bloom meta, and trailer. For fast forward and backward seeks, three new fields have been added for compressed/uncompressed/offset previous block, as shown in Figure 2-8 .

Figure 2-8. Block header
Encoding
Data block encoding may be used to improve compression as sorting is used and keys are very similar in the beginning of the keys. Data block encoding also helps by limiting duplication of information in keys by taking advantage of some of the fundamental designs and patterns of HBase: sorted row keys and/or the schema of a given table. The general purpose compression algorithm does not use encoding and the key/value length is stored completely even if a row has a key similar to the preceding key. In HBase 0.94, the prefix and diff encodings may be chosen. In prefix encoding, a new column called Prefix Length is added for the common length bytes equal in the previous row. Just the difference from the previous row is stored in each row. The first row has to be stored completely because no previous row exists. The different types of encodings, including the no encoding format, are shown in Figure 2-9 .

Figure 2-9. Different types of encodings
CHAPTER 2 ■ APACHE HBASE AND HDFS
In diff encoding , the key is not considered as a sequence of bytes but the encoder splits each key and compresses each section separately for improved compression. As a result, the column family is stored once only. One byte describes the key layout. Key length, value length, and type may be omitted if equal to the previous row. The timestamp is signed and is stored as a difference from the previous row.
The data block encoding feature is not enabled by default. To enable the feature, DATA_BLOCK_ENCODING = PREFIX | DIFF | FAST_DIFF has to be set in the table info. Compaction
Compaction is the process of creating a larger file by merging smaller files. Compaction can become necessary if HBase has scanned too many files to find a result but is not able to find a result. After the number of files scanned exceeds the limit set in hbase.hstore. compaction.max , parameter compaction is performed to merge files to create a larger file. Instead of searching multiple files, only one file has to be searched. Two types of compaction are performed: minor compaction and major compaction . Minor compaction just merges two or more smaller files into one. Major compaction merges all of the files. In a major compaction, deleted and duplicate key/values are removed. Compaction provides better indexing of data, reducing the number of seeks required to reach a block that could contain the key.
KeyValue Class
The main methods in the KeyValue class are discussed in Table 2-5 . Table 2-5. KeyValue Class Methods
getRow() Returns the row of the KeyValue . To be used on the client side. getFamily() Returns the column family of the KeyValue . To be used on the
client side.
getQualifier() Returns the column qualifier of the KeyValue . To be used on the client side.
getTimestamp() Returns the timestamp.
getValue() Returns the value of the KeyValue as a byte[] .To be used on the client side.
getBuffer() Returns the byte[] for the KeyValue . To be used on the server side. CHAPTER 2 ■ APACHE HBASE AND HDFS
When data is added to HBase, the following sequence is used to store the data: 1. The data is first written to a WAL called HLog .
2. The data is written to an in-memory MemStore .
3. When memory exceeds certain threshold, data is flushed to disk as HFile (also called a StoreFile ).
4. HBase merges smaller HFiles into larger HFiles with a process called compaction.
The HBase architecture in relation to the HDFS is shown in Figure 2-10 .

Figure 2-10. Apache HBase architecture in relation to HDFS
HBase consists of the following components:
1. Master
2. RegionServers
3. Regions within a RegionServer
4. MemStores and HFiles within a Region
CHAPTER 2 ■ APACHE HBASE AND HDFS
HBase is based on HDFS as the filesystem. The ZooKeeper coordinates the different components of HBase. HBase may be accessed using Java Client APIs, external APIs, and the Hadoop FileSystem API. The Master coordinates the RegionServers. A Region is a subset of a table’s rows, such as a partition. A RegionServer serves the region’s data for reads and writes. The ZooKeeper stores global information about the cluster. The .META. tables list all of the regions and their locations. The –ROOT- table lists all of the .META. tables.
The HBase objects stored in the Datanodes may be browsed from the NameNode web application running at port 50070. The HDFS directory structure for HBase data files is as follows (also shown in Figure 2-11 ):
/hbase/<Table>/<Region>/<ColumnFamily>/<StoreFile> <Table> is the HBase table.
<Region> is the region.
<ColumnFamily> is the column family.
<StoreFile> is the store file or HFile.
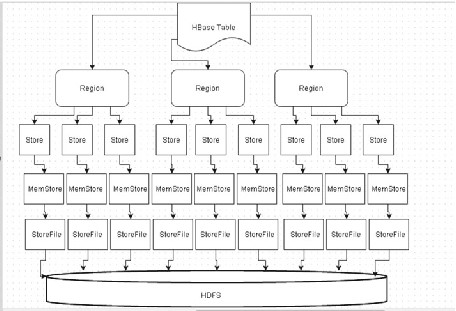
Figure 2-11. HDFS directory structure for HBase data files
The HDFS directory structure for the WAL is as follows:
/hbase/.logs/<RegionServer>/<HLog>
A StoreFile (HFile) is created every time the MemStore flushes. CHAPTER 2 ■ APACHE HBASE AND HDFS
As a store corresponds to a column family (CF), the preceding diagram can be redrawn as shown in Figure 2-12 .
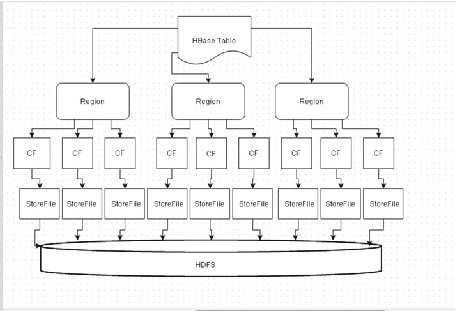
Figure 2-12. A store is the same as a column family
Data Locality
For efficient operation, HBase needs data to be available locally, for which it is a best practice to run a HDFS node on each RegionServer. HDFS has to be running on the same cluster as HBase for data locality. Region/RegionServer locality is achieved via HDFS block replication. The following replica placement policy is used by DFSClient : 1. The first replica is placed on a local node.
2. The second replica is placed on a different node in the same rack.
3. The third replica is placed on a node in another rack.
The replica placement policy is shown in Figure 2-13 .
CHAPTER 2 ■ APACHE HBASE AND HDFS

Figure 2-13. Replica placement policy
HBase eventually achieves locality for a region after a flush or compaction. In a RegionServer failover, data locality may be lost if a RegionServer is assigned regions with non-local HFiles, resulting in none of the replicas being local. But as new data is written in the region, or the table is compacted and HFiles are rewritten, they will become local to the RegionServer.
Table Format
HBase provides tables with a Key:Column/Value interface with following properties: • Dynamic columns (qualifiers), no schema required
• “Fixed” column groups (families)
• table[row:family:column]=value
HBase Ecosystem
The HBase ecosystem consists of Apache Hadoop HDFS for data durability and reliability (write-ahead log) and Apache ZooKeeper for distributed coordination, and built-in support for running Apache Hadoop MapReduce jobs, as shown in Figure 2-14 .
CHAPTER 2 ■ APACHE HBASE AND HDFS

Figure 2-14. HBase ecosystem
HBase Services
HBase architecture has two main services: HMaster and HRegionServer, as shown in Figure 2-15 .
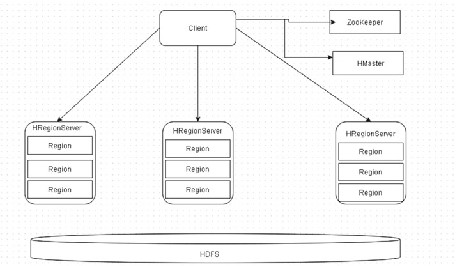
Figure 2-15. HBase architecture services
The RegionServer contains a set of Regions and is responsible for handling reads and writes. The region is the basic unit of scalability and contains a subset of a table’s data as a contiguous, sorted range of rows stored together. The Master coordinates the HBase cluster, including assigning and balancing the regions. The Master handles all the admin operations including create/delete/modify of a table. The ZooKeeper provides distributed coordination.
CHAPTER 2 ■ APACHE HBASE AND HDFS
Auto-sharding
A region is a subset of a table’s data. When a region has too much data, the region splits into two regions. The region ➤ RegionServer association is stored in a System Table called hbase:meta . The .META. location is stored in the ZooKeeper. An example region split is shown in Figure 2-16 .

Figure 2-16. An example of a region split
The Write Path to Create a Table The write path to create a table consists of the following sequence (and is shown in Figure 2-17 ):
1. The client requests the Master to create a new table with the following HBase shell command, for example:
hbase>create 'table1','cf1'
2. The Master stores the table information, the schema.
3. The Master creates regions based on key-splits if any are provided. If no key-splits are provided, a single region is
created by default.
4. The Master assigns the regions to the RegionServers. The region ➤ Region Server assignment is written to a system
table called .META.
CHAPTER 2 ■ APACHE HBASE AND HDFS
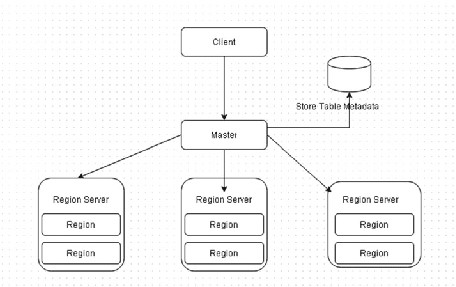
Figure 2-17. The write path to create a table
The Write Path to Insert Data
The write path for inserting data is as follows (and is shown in Figure 2-18 ): 1. I n v o k e table.put(row-key:family:column,value) . 2. The client gets the .META. location from the ZooKeeper. 3. The client scans .META. for the RegionServer responsible for
handling the key.
4. The client requests the RegionServer to insert/update/delete the specified key/value.
5. The RegionServer processes and dispatches the request to the region responsible for handling the key. The insert/update/ delete operation is written to a WAL. The KeyVaues are added to the store named MemStore. When the MemStore becomes full, it is flushed to a StoreFile on the disk.
CHAPTER 2 ■ APACHE HBASE AND HDFS
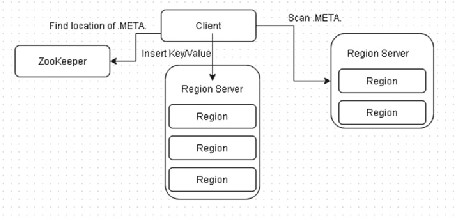
Figure 2-18. The write path to insert data
The Write Path to Append-Only R/W HBase files in HDFS are append-only and immutable once closed. KeyValues are stored in memory (MemStore) and written to disk (StoreFile/HFile) when memory is full. The RegionServer is able to recover from the WAL if a crash occurs. Data is sorted by key before writing to disk. Deletes are inserts but with the “remove flag.” See Figure 2-19 .
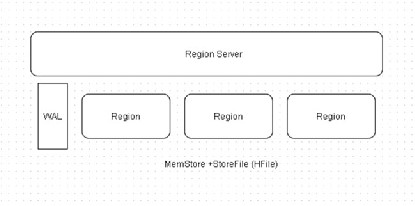
Figure 2-19. The write path for append-only read/write
CHAPTER 2 ■ APACHE HBASE AND HDFS
The Read Path for Reading Data The read path for reading data is as follows (and is shown in Figure 2-20 ): 1. The client gets the .META. location from the ZooKeeper. 2. The client scans .META. for the RegionServer responsible for
handling the key.
3. The clients request the RegionServer to get the specified key/ value.
4. The RegionServer processes and dispatches the request to the region responsible for handling the key. MemStore and store files are scanned to find the key. The key, when found, is returned to the client.

Figure 2-20. T h e r e a d p a th
The Read Path Append-Only to Random R/W Each flush of the MemStore creates a new store file. Each file has key/values sorted by a key. Two or more files can contain the same key (updates/deletes). To find a key, scan all of the files with some optimizations. To filter files, the startKey/endKey may be used. A bloom filter may also be used to find the file with the key.
HFile Format
The HFile format is designed for sequential writes with append (k,v) and large sequential reads. Records are grouped into blocks, as shown in Figure 2-21 , because they are easy to split, easy to read, easy to cache, easy to index (if records are sorted), and suitable for block compression (snappy, lz4, gz).
CHAPTER 2 ■ APACHE HBASE AND HDFS
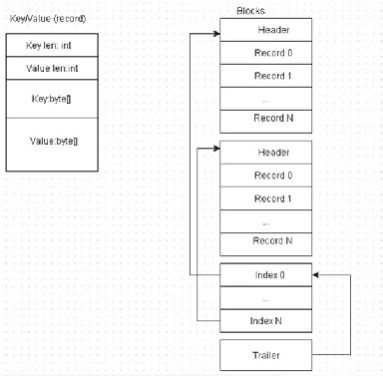
Figure 2-21. Records are split into blocks
The Java class org.apache.hadoop.hbase.io.hfile.HFile represents the file format for HBase. HFile essentially consists of sorted key/value pairs with both the keys and values being a byte array.
Data Block Encoding
Block encoding (Figure 2-22 ) makes it feasible to compress the key. Keys are sorted and a similar prefix can be added as a separate column with common key length bytes. Timestamps are similar and only the diff can be stored. The type is “put” most of the time. A file contains keys from one column family only.
CHAPTER 2 ■ APACHE HBASE AND HDFS

Figure 2-22. Data block encoding
Compactions
Compactions reduce the number of files to search during a scan by merging smaller files into one large file. Compactions remove the duplicated keys (updated values). Compactions remove the deleted keys. Old files are removed after merging. Pluggable compactions make use of different algorithms. Compactions are based on statistics (which keys/files are commonly accessed and which are not). Snapshots
A snapshot is a set of metadata information such as the table “schema” (column families and attributes), the region’s information (startKey, endKey); the list of store files, and the list of active WALs. A snapshot is not a copy of the table. Each RegionServer is responsible for taking its snapshot. Each RegionServer sores the metadata information needed for each region and the list of store files, WALs, region startKeys/endKeys. The Master orchestrates the RSs and the communication is done via the ZooKeeper. A two-phase commit like transaction (prepare/commit) is used. A table can be cloned from a snapshot.
hbase>clone_snapshot 'snpashotName', 'tableName' Cloning creates a new table with data contained in the snapshot. No data copies are
involved. HFiles are immutable and shared between tables and snapshots. Data may be inserted/updated/removed from the new table without affecting the snapshot, original
CHAPTER 2 ■ APACHE HBASE AND HDFS
tables, and the cloned tabled. On compaction or table deletion, files are removed from disk and if files are referenced by a snapshot or a cloned table, the file is moved to an “archive” directory and deleted later when no references to the file exist. The HFileSystem Class
The org.apache.hadoop.hbase.fs.HFileSystem class is an encapsulation for the org. apache.hadoop.fs.FilterFileSystem object that HBase uses to access data. The class adds the flexibility of using separate filesystem objects for reading and writing HFiles and WALs.
Scaling
The auto-sharding feature of HBase dynamically redistributes the tables when they become too large. The smallest data storage unit is a region, which has a subset of a table’s data. A region contains a contiguous, sorted range of rows that are stored together. Starting with one region, when the region becomes too large, it is split into two at the middle key, creating approximately two equal halves, as shown in Figure 2-23 .
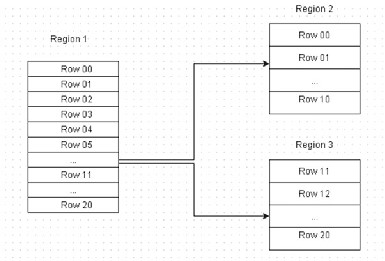
Figure 2-23. Region splitting
HBase has a master/slave architecture. The slaves are called RegionServers, with each RegionServer being responsible for a set of regions, and with each region being served by one RegionServer only. The HBase Master coordinates the HBase cluster’s administrative operations. At startup, each region is assigned to a RegionServer and the Master may move a region from one RegionServer to the other for load balancing.
CHAPTER 2 ■ APACHE HBASE AND HDFS
The Master also handles RegionServer failures by assigning the regions handled by the failed RegionServer to another RegionServer. The Region ➤ RegionServer mapping is kept in a system table called .META. . From the .META. table, it can be found which region is responsible for which key. In read/write operations, the Master is not involved at all and the client goes directly to the RegionServer responsible to serve the requested data.
For Put and Get operations, clients don’t have to contact the Master and can directly contact the RegionServer responsible for handling the specified row. For a client scan, the client can directly contact the RegionServers responsible for handling the specified set of keys. The client queries the .META. table to identify a RegionServer. The .META. table is a system table used to track the regions. The . META. table contains the RegionServer names, region identifiers (Ids), the table names, and startKey for each region, as shown in Figure 2-24 . By finding the startKey and the next region’s startKey, clients are able to identify the range of rows in a particular region. The client contacts the Master only for creating a table and for modifications and deletions. The cluster can keep serving data even if the Master goes down.
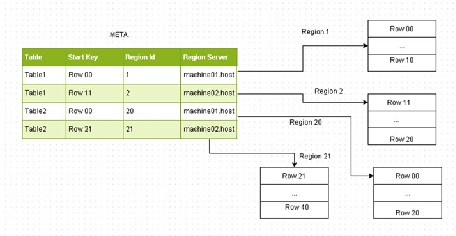
Figure 2-24. The .META. table
To avoid having to get the region location again and again, the client keeps a cache of region locations. The cache is refreshed when a region is split or moved to another RegionServer due to balancing or assignment policies. The client receives an exception when the cache is outdated and cache is refreshed by getting updated information from the .META. table.
The .META. table is also a table like the other tables and client has to find from ZooKeeper on which RegionServer the .META. table is located. Prior to HBase 0.96, HBase design was based on a table that contained the META locations, a table called -ROOT- . With HBase 0.96, the -ROOT- table has been removed and the META locations are stored in the ZooKeeper, as shown in Figure 2-25 .
CHAPTER 2 ■ APACHE HBASE AND HDFS
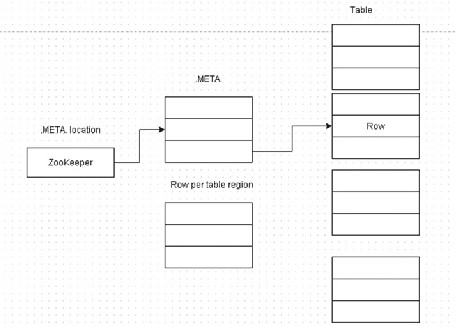
Figure 2-25. The .META. table locations are stored in the ZooKeeper
HBase Java Client API
The HBase Java client API is used mainly for the CRUD (Create/Retrieve/Update/Delete) operations. The HBase Java Client API provides two main interfaces, as discussed in Table 2-6 .
Table 2-6. HBase Java Client API Interfaces
org.apache.hadoop.hbase. The HBaseAdmin is used to manage HBase database table client.HBaseAdmin metadata and for general administrative functions such as
create, drop, list, enable, and disable tables. HBaseAdmin is also used to add and drop table column families.
org.apache.hadoop.hbase. HTable is used to communicate with a single HBase client.HTable table. The class is not thread-safe for reads and writes.
In a multi-threaded environment, HTablePool should
be used. The interface communicates directly with the
RegionServers for handling the requested set of keys.
HTable is used by a client for get/put/delete and all other
CHAPTER 2 ■ APACHE HBASE AND HDFS
Random Access
For random access on a table that is much larger than memory, HBase cache does not provide any advantage. HBase does not need to retrieve the entire file block from HDFS into memory for the data requested. Data is indexed by key and retrieved efficiently. To maximize throughput, keys are designed such that data is distributed across the servers in clusters equally. HBase blocks are the unit of indexing (also caching and compression) designed for fast random access. HDFS blocks are the unit of filesystem distribution. Tuning HDFS block size compared to HBase parameters has performance impacts.
HBase stores data in large files with sizes in the order of magnitude of 100s of MB to a GB. When HBase wants to read, it first checks the MemStore for data in memory from a recent update or insertion. If it’s not in memory, HBase finds HFiles with a range of keys that could contain the data. If compactions have been run only one HFile. An HFile contains a large number of data blocks that are kept small for fast random access. At the end of the HFile an index references these blocks and keeps the range of keys in each block and offset of the block in the HFile. When an HFile is first read, the index is loaded into memory and kept in memory for future accesses.
1. HBase performs a binary search in the index, first in memory, to locate the block that could potentially contain the key.
2. When the block is located, a single disk seek is performed to load the block that is to be subsequently checked for the key.
3. The loaded 64k HBase block is searched for the key and, if found, the key-value is returned.
Small block sizes provide efficient disk usage when performing random accesses, but this increases the index size and memory requirements.
Data Files (HFile)
Data files are immutable once written. Data files are generated by flush or compactions (sequential writes). Data files are read randomly ( preads ) or sequentially. Big in size, the flushsize could be tens of GBs. All data is in blocks. The target size of data blocks is 64KB by default and is set in the BLOCKSIZE column family descriptor. The target size is the uncompressed and unencoded size. Index blocks (leaf, intermediate, root) also have a target size, which is set in hfile.index.block.max.size and is 128KB by default. Bloom filter blocks have a target size set with io.storefile.bloom.block.size and is 128KB by default.
The data file format for HFile v2 is shown in Figure 2-26 .
CHAPTER 2 ■ APACHE HBASE AND HDFS
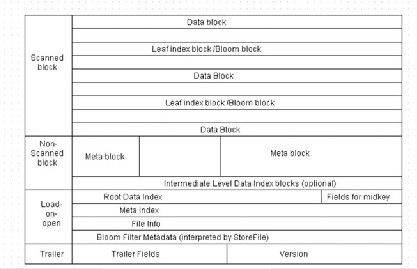
Figure 2-26. Data file format for HFile v2
I/O happens at block boundaries. A random read consists of disk seek plus reading a whole block sequentially. Read blocks are put into block cache so that they do not have to be read again. Leaf index blocks and bloom filter blocks also are cached. Smaller block sizes are used for faster random access. Smaller block sizes provide smaller read and faster in-block search. But smaller blocks lead to a larger block index and more memory consumption. For faster scans, use larger block sizes. The number of key-value pairs that fit an average block may also be determined. The block format is shown in Figure 2-27 .

Figure 2-27. B lo c k f o r m a t
Compression and data block encoding (PREFIX, DIFF, FAST_DIFF, PREFIX_TREE) minimizes file sizes and on-disk block sizes.
Reference Files/Links
When a region is split at a splitkey reference, files are created referring to the top or bottom section of the store file that is split. HBase archives data/WAL files but archives them such as /hbase/.oldlogs and /hbase/.archive. HFileLink is a kind of application-specific hard/soft link. HBase snapshots are logical links to files with backrefs.
CHAPTER 2 ■ APACHE HBASE AND HDFS
Write-Ahead Logs
One logical WAL is created per region. One physical WAL is created per RegionServer. WALs are rolled frequently using the following settings:
• hbase.regionserver.logroll.multiplier with a default of 0.95 • hbase.regionserver.hlog.blocksize with the default the same
as file system block size
WALs are chronologically ordered set of files and only the last one is open for writing. If the hbase.regionserver.maxlogs with a default of 32 is exceeded, a force flush is caused. Old log files are deleted as a whole. Every edit is appended. Sequential writes from WAL that sync very frequently at the rate of hundreds of time per sec. Only sequential reads from replication and crash recovery. One log file per RegionServer limits the write throughput per RegionServer.
Data Locality
HDFS local reads are called short-circuit reads.
HDFS local reads (Figure 2-28 ) bypass the datanode layer and directly go to the OS files. Hadoop 1.x implementation is as follows:
CHAPTER 2 ■ APACHE HBASE AND HDFS
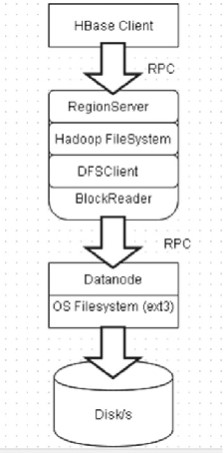
Figure 2-28. L o c a l r e a d s
DFSClient asks the local datanode for local paths for a block. Datanode verifies that the user has permission. The client gets the path for the block and opens the file with FileInputStream .
The hdfs-site.xml settings for a local read are as follows: dfs.block.local-path-access.user=hbase
dfs.datanode.data.dir.perm = 750
The hbase-site.xml settings for a local read are as follows: dfs.client.read.shortcircuit=true
CHAPTER 2 ■ APACHE HBASE AND HDFS
The Hadoop 2-0 implementation of HDFS local reads includes the following settings: • Keep the legacy implementation
• Use Unix Domain sockets to pass the File Descriptor (FD) • The datanode opens the block file and passes FD to the
BlockReaderLocal running in Regionserver process
• More secure than the 1.0 implementation
• Windows also supports domain sockets, needed to implement native APIs
• Local buffer size is set with dfs.client.read.shortcircuit. buffer.size
• BlockReaderLocal fills the whole buffer every time HBase tries to read an HfileBlock
• dfs.client.read.shortcircuit.buffer.size = 1MB vs. 64KB HFile block size
• SSR buffer is direct buffer in Hadoop 2, but not in Hadoop 1 • Local buffer size = Number of regions x Number of stores x
number of avg store files x number of avg blocks per file x SSR buffer size
For example, 10 regions x 2 x 4 x 1GB/64MB x 1MB = 1.28GB of non-heap memory usage.
Checksums
HDFS checksums are not inlined. They are two files per block, one for data and one for checksums, as shown in Figure 2-29 .
CHAPTER 2 ■ APACHE HBASE AND HDFS
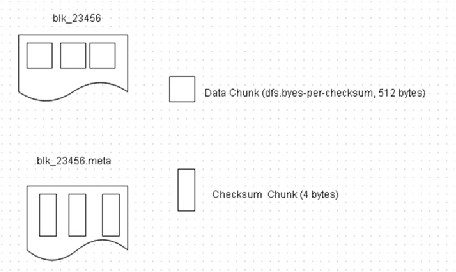
Figure 2-29. Two files per block
Random positioned read causes two seeks. HBase checksums are included with
0.94. HFile v 2-1 writes checksums per HFile block. The HFile data block chunk and the Checksum chunk are shown in Figure 2-30 . HDFS checksum verification is bypassed on block read as checksum verification is done by HBase. If the HBase checksum fails, revert to checksum verification from HDFS for some time. Use the following settings: hbase.regionserver.checksum.verify = true
hbase.hstore.bytes.per.checksum =16384
hbase.hstore.checksum.algorithm=CRC32C
Do not set
dfs.client.read.shortcircuit.skip.checksum = false CHAPTER 2 ■ APACHE HBASE AND HDFS
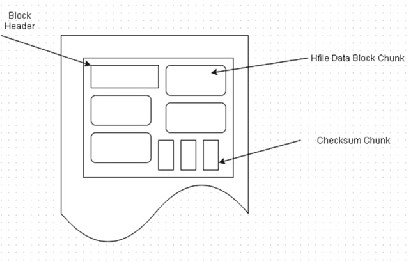
Figure 2-30. The HFile data block chunk and the Checksum chunk
Data Locality for HBase
Data locality is low when a region is moved as a result of load balancing or region server crash and failover. Most of the data is not local unless the files are compacted. When writing a data file, provide hints to the NameNode for locations for block replicas. The load balancer should assign a region to one of the affiliated nodes upon server crash to keep data locality and SSR. Data locality reduces data loss probability. MemStore
When a RegionServer receives a write request, it directs the request to a specific region, with each region storing a set of rows. Row data can be separated in multiple column families. Data for a particular column family is stored in HStore, which is comprised of MemStore and a set of HFiles. The MemStore is kept in the RegionServer’s main memory and HFiles are written to HDFS. Initially, a write request is written to the MemStore and when a certain memory threshold is exceeded, the MemStore data gets flushed to an HFile. The MemStore is used because data is stored on HDFS by row key.
As HDFS is designed for sequential reads/writes with no file modifications. HBase is not able to efficiently write data to disk as it is received because the written data is not sorted and not optimized for future retrieval. HBase buffers last received data in memory (MemStore), sorts it before flushing, and writes to HDFS using sequential writes. Some of the other benefits of MemStore are as follows:
CHAPTER 2 ■ APACHE HBASE AND HDFS
1. MemStore is an in-memory cache for recently added data, which is useful when last-written data is accessed more
frequently than older data
2. Certain optimizations are done on rows/cells in memory before writing to persistent storage
Every MemStore flush creates one HFile per column family. When reading HBase, first check if the requested data is in the MemStore and, if not found, go to the HFile to get the requested data. Frequent MemStore flushes can affect reading performance and bring additional load to the system. Every flush creates an HFile, so frequent flushes will create several HFiles, which will affect the read performance because HBase must read several HFiles. HFiles compaction alleviates the read performance issue by compacting multiple smaller files into a larger file. But compaction is usually performed in parallel with other requests and it could block writes on region server.
Summary
In this chapter, I discussed how HBase stores data in HDFS, including the read-write path and how HBase communicates with the NameNode and the Datanode. I discussed the HBase storage architecture and the HFile format used for storing data. Data encoding, compactions, and replica placement policy were also discussed. In the next chapter, I will discuss the characteristics that make an application suitable for Apache HBase.

Apache HBase is designed to be used for random, real-time, relatively low latency, read/ write access to big data. HBase’s goal is to store very large tables with billions/millions of rows and billions/millions of columns on clusters installed on commodity hardware.
The following characteristics make an application suitable for HBase: • Large quantities of data in the scale of 100s of GBs to TBs and PBs.
Not suitable for small-scale data
• Fast, random access to data
• Variable, flexible schema. Each row is or could be different • Key-based access to data when storing, loading, searching,
retrieving, serving, and querying
• Data stored in collections. For example, some metadata, message data, or binary data is all keyed into the same value
• High throughput in the scale of 1000s of records per second • Horizontally scalable cache capacity. Capacity may be increased
by just adding nodes
• The data layout is designed for key lookup with no overhead for sparse columns
• Data-centric model rather than a relationship-centric model. Not suitable for an ERD (entity relationship diagram) model
• Strong consistency and high availability are requirements. Consistency is favored over availability
• Lots of insertion, lookup, and deletion of records
• Write-heavy applications
• Append-style writing (inserting and overwriting) rather than heavy read-modify-write
© Deepak Vohra 2016 45
D. Vohra, Apache HBase Primer , DOI 10.1007/978-1-4842-2424-3_3 CHAPTER 3 ■ APPLICATION CHARACTERISTICS
Some use-cases for HBase are as follows:
• Audit logging systems
• Tracking user actions
• Answering queries such as
• What are the last 10 actions made by the user?
• Which users logged into the system on a particular day? • Real-time analytics
• Real-time counters
• Interactive reports showing trends and breakdowns
• Time series databases
• Monitoring system
• Message-centered systems (Twitter-like messages and statuses) • Content management systems serving content out of HBase • Canonical use-cases such as storing web pages during crawling of
the Web
HBase is not suitable/optimized for
• Classical transactional applications or relational analytics • Batch MapReduce (not a substitute for HDFS)
• Cross-record transactions and joins
HBase is not a replacement for RDBMS or HDFS. HBase is suitable for • Large datasets
• Sparse datasets
• Loosely coupled (denormalized) records
• Several concurrent clients
HBase is not suitable for
• Small datasets (unless many of them)
• Highly relational records
• Schema designs requiring transactions
CHAPTER 3 ■ APPLICATION CHARACTERISTICS
Summary
In this chapter, I discussed the characteristics that make an application suitable for Apache HBase. The characteristics include fast, random access to large quantities of data with high throughput. Application characteristics not suitable were also discussed. In the next chapter, I will discuss the physical storage in HBase.


The filesystem used by Apache HBase is HDFS, as discussed in Chapter 2 . HDFS is an
abstract filesystem that stores data on the underlying disk filesystem. HBase indexes data into HFiles and stores the data on the HDFS Datanodes. HDFS is not a general purpose filesystem and does not provide fast record lookups in files . HBase is built on top of HDFS and provides fast record lookups and updates for large tables . HBase stores table data as key/value pairs in indexed HFiles for fast lookup. HFile, the file format for HBase, is based on the TFile binary file format. HFile is made of blocks, with the block size configured per column family. The block size is 64k. If the key/value exceeds 64k of data, it’s not split across blocks but the key/value is read as a coherent block. The HFile is replicated three times for durability, high availability, and data locality. Data files are stored in the format discussed in Chapter 2 and the HFileSystem.create(Path path) method is used to create the HFile data files.
A HBase client communicates with the ZooKeeper and the HRegionServers. The HMaster coordinates the RegionServers. The RegionServers run on the datanodes. Each RegionServer is collocated with a datanode, as shown in Figure 4-1 .

Figure 4-1. RegionServer collocation with a datanode
The storage architecture of HBase is discussed in more detail in Chapter 2 and shown in Figure 2-3.
© Deepak Vohra 2016 51
D. Vohra, Apache HBase Primer , DOI 10.1007/978-1-4842-2424-3_4 CHAPTER 4 ■ PHYSICAL STORAGE
Summary
In this chapter, I discussed how HBase physically stores data in HDFS, with each RegionServer being collocated with a datanode. In the next chapter, I will discuss the column family and the column qualifier.

Column qualifiers are the column names, also known as column keys. For example, in Figure 5-1 , Column A and Column B are the column qualifiers. A table value is stored at the intersection of a column and a row. A row is identified by a row key. Row keys with the same user ID are adjacent to each other. The row keys form the primary index and the column qualifiers form the per row secondary index. Both the row keys and the column keys are sorted in ascending lexicographical order.
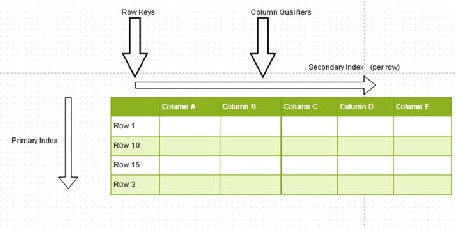
Figure 5-1. Column qualtifiers
Each row can have different column qualifiers, as shown in Figure 5-2 . HBase stores the column qualifier with a certain value which is part of the row key. Apache HBase doesn’t limit the number of column qualifiers, which means that the creation of long column qualifiers can require a lot of storage.
© Deepak Vohra 2016 53
D. Vohra, Apache HBase Primer , DOI 10.1007/978-1-4842-2424-3_5 CHAPTER 5 ■ COLUMN FAMILY AND COLUMN QUALIFIER
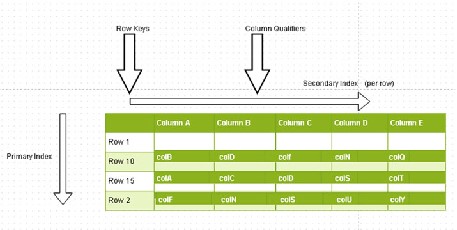
Figure 5-2. Different column qualifiers
The HBase data model consists of a table, which consists of multiple rows. A row consists of a row key and one or more columns, and the columns have values associated with them. Rows are sorted lexicographically and stored. To store related rows adjacent or near each other, a common row key pattern is usually used. A column, which stores a value, consists of a column family name and a column qualifier delimited by a : (colon). For example, column family cf1 could consist of column qualifiers (or column keys) c1 , c2, and c3 . A column family consists of a collocated set of columns. Each column family has a set of storage properties such as whether the column values are to be cached in memory, how the row keys are encoded, or how data is compressed. A column’s family is used for performance reasons. Each row in a table has the same column family/ies, although a row does not have to store a value in each column family. A column qualifier is the actual column name to provide an index for a column. A column qualifier is added to a column family with the two separated by a : (colon) to make a column. Though each row in a table has the same column families, the column qualifiers associated with each column family can be different. Column qualifiers are the actual column names, or column keys. For example, the HBase table in Figure 5-3 consists of column families cf1 , cf2, and cf3 . And column family cf1 consists of column qualifiers c1 , c2 , and c3 while column family cf2 consists of column qualifiers c2 , c4 , and c5 , and column family cf3 consists if column qualifiers c4 , c6 , and c7 . Column families are fixed when a table is created; column qualifiers are not fixed when a table is created and are mutable and can vary from row to row. For example, in Figure 5-3 , the table has three column families ( cf1 , cf2 , and cf3 ) and each row has different column qualifiers associated with each column family and each column. Some rows do not store data in some of the column families while other rows have data in each of the column families. For example, Row-1 has data stored in each of the column families while Row-10 has only two of the column families and Row-15 has only one column family.
CHAPTER 5 ■ COLUMN FAMILY AND COLUMN QUALIFIER
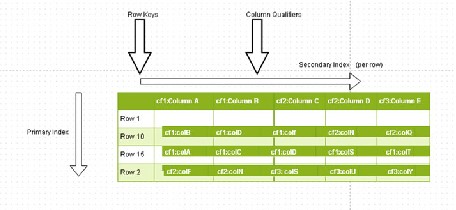
Figure 5-3. Using column qualifiers
What makes a HBase table sparse is that each row does not have to include all the column families. Each column family is stored in its own data file. As a result, some data files may not include data for some of the rows if the rows do not store data in those column families.
A KeyValue consists of the key and a value, with the key being comprised of the row key plus the column family plus the column qualifier plus the timestamp, as shown in Figure 5-4 . The value is the data identified by the key. The timestamp represents a particular version.

Figure 5-4. Key and value
As another representation, a row is shown to have a row key and two column families. Column Family 1 has three column qualifiers associated with it. ColQ1 column qualifier has three versions , and each version is associated with a different value, as shown in Figure 5-5 .
CHAPTER 5 ■ COLUMN FAMILY AND COLUMN QUALIFIER
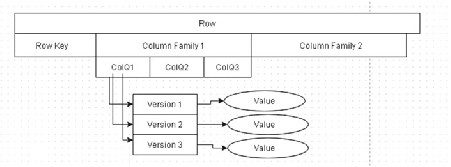
Figure 5-5. Relationship between column qualifier, version, and value
The essential differences between a column family and a column qualifier are listed in Table 5-1 .
Table 5-1. Differences Between a Column Family and a Column Qualifier Mutability Not mutable Mutable
Schema Each row has same column Each row can have different families. column qualifiers within a
column family.
Column notation Column family is the prefix, for Column qualifier is the suffix, example cf1:col1 . All column for example cf2:col2 .
members of a column family
have the same prefix.
Empty A column family must not A column qualifier could be be empty when identifying a empty; for example, cf1: is a column. column in column family cf1
with an empty column qualifier.
Number Any number, storage space Any number, storage space permitting.
Storage unit Data stored per column family Data is not stored per column in a separate data file called a qualifier. A HFile could have HFile. several column qualifiers
CHAPTER 5 ■ COLUMN FAMILY AND COLUMN QUALIFIER
It is recommended to use a few column families because each column family is stored in its own data file and too many column families can cause many data files to be open. Compactions may be required with several column families.
The following is an example of a data file HFile for column family cf1 : 123 cf1 col1 val1 @ ts1
123 cf1 col2 val2 @ ts1
235 cf1 col1 val3 @ ts1
235 cf1 col2 val4 @ ts1
235 cf1 col2 val5 @ ts2
The HFile has two row keys, 123 and 235 . Row key 123 has two column qualifiers associated with it: col1 and col2 . Each of the column qualifiers has a value associated with it and a timestamp. Row key 235 has two column qualifiers, also col1 and col2 , but col2 has two versions or timestamps associated with it ( ts1 and ts2 ). Summary
In this chapter, I introduced the column family and the column qualifier and the relationship between the two. In the next chapter, I will discuss row versioning.

When data is stored in HBase, a version (also called a timestamp ) is required for each value stored in a cell. The timestamp is created automatically by the RegionServer or may be supplied explicitly. By default, the timestamp is the time at the RegionServer when the data was written. Alternatively, the timestamp may be set explicitly. Timestamps are stored in descending order in an HFile, which implies the most recent timestamp is stored first. The timestamp identifies a version and must be unique for each cell. A {row, column, version} tuple specifies a cell in a table. A KeyValue consists of the key and a value with the key being comprised of the row key + column Family + column qualifier + timestamp , as shown in Figure 5-4. The value is the data identified by the key. The timestamp represents a particular version.
Each column consists of any number of versions, which implies that any number of tuples in which the row and column are the same and only the version is different could be created. Typically, the version is the timestamp. The version applies to the actual data stored in a cell, the intersection of a row key with a column key. Coordinates for a cell are row key ➤ column key ➤ version. As an example, a row is shown to have a row key and two column families. Column Family 1 has three column qualifiers associated with it. The ColQ1 column qualifier has three versions, and each version has a different value, as shown in Figure 6-1 .

Figure 6-1. An example of a column qualifier with three versions
© Deepak Vohra 2016 59
D. Vohra, Apache HBase Primer , DOI 10.1007/978-1-4842-2424-3_6 CHAPTER 6 ■ ROW VERSIONING
Physical coordinates for a cell are region directory ➤ column family directory ➤ row key ➤ column family name ➤ column qualifier ➤ version.
The row and column keys are stored as bytes and the versions as long integers. The versions are stored in decreasing order so that when reading a StoreFile the most recent version is found first.
Doing a Put on a table always creates a new version of a cell identified by a timestamp. By default, currentTimeMillis is used to create the timestamp. The version may be specified explicitly on a per column basis. The long value of a version can be a time in the past or the future or a non-time long value. An existing version may be overwritten by doing a Put at exactly the same {row, column, version} with a different or same value.
The org.apache.hadoop.hbase.client.Put class is used to perform Put operations for a single row. To perform a Put, first instantiate a Put object for which the constructors listed in Table 6-1 are provided.
Table 6-1. Put Class Constructors
Put(byte[] row) Creates a Put object for the specified row byte array. Put(byte[] rowArray, int Creates a Put object from the specified row array rowOffset, int rowLength) using the given offset and row length. Put(byte[] rowArray, int Creates a Put object from the specified row array rowOffset, int rowLength, using the given offset, row length, and timestamp. long ts)
Put(byte[] row, long ts) Creates a Put object for the specified row byte array and timesamp.
Put(ByteBuffer row) Creates a Put object for the specified row byte buffer.
Put(ByteBuffer row, long ts) Creates a Put object for the specified row byte buffer and timestamp.
After a Put object has been created, columns may be added to it using one of the overloaded addColumn methods (shown in Table 6-2 ), each of which returns a Put object.
addColumn(byte[] family, Adds a column using the specified column family, byte[] qualifier, byte[] column qualifier, and value, each of type byte[] . The value) version or timestamp is created implicitly.
addColumn(byte[] family, Adds a column using the specified column family, byte[] qualifier, long ts, column qualifier, timestamp, and value, each of type byte[] value) byte[] except the timestamp, which is of type long .
The version or timestamp is created explicitly.
addColumn(byte[] family, Adds a column using the specified column family ByteBuffer qualifier, long of type byte[] , column qualifier of type ByteBuffer, ts, ByteBuffer value) timestamp of type long , and value of type
ByteBuffer . The version or timestamp is created
The versions are configurable for a column family. In CDH 5 (>=0.96), the maximum number of versions is 1 by default. In earlier CDH (<0.96), the maximum number of versions defaults to 3. The default setting may be configured with hbase.column.max. version in hbase-site.xml . The maximum number of versions may be altered using the alter command with HColumnDescriptor.DEFAULT_VERSIONS . For example, the following command sets the maximum number of versions to 5 for column family cf1 in table table1 :
alter ‘table1', NAME => ‘cf1', VERSIONS => 5
Excess versions are removed during major compactions. The minimum number of versions may also be set and defaults to 0, which implies the feature is disabled and no minimum is configured. For example, the following alter command sets the minimum number of versions to 1 in column family cf1 in table table1 : alter ‘table1', NAME => ‘cf1', MIN_VERSIONS => 1 Versions Sorting