
compactions of small tables such
as the hbase:meta is not slowed
due to larger compactions taking
up most of the threads. The value
of the setting is the threshold for
a compaction to be considered a
large compaction.
hbase.hstore.compaction. The maximum number of key/ 10 kv.max value pairs read and write in a
batch in a compaction. Lower
the value if KeyValues are big,
causing OutOfMemoryExceptions .
Increase the value if rows are
wide and small.
hbase.server. By default, events such as 1000
compactchecker.interval. MemStore flush determine
multiplier when a scan is made to check if
a compaction is necessary. But,
due to infrequent writes it may
be necessary to perform a check
if a compaction is required at a
specified interval. The hbase.
server.thread.wakefrequency
setting multiplied by hbase.
server.thread.wakefrequency
determines the frequency at
which a check is performed for
CHAPTER 11 ■ COMPACTIONS
Pluggable compactions, which make use of different algorithms, may also be used, such as compactions based on statistics (which keys/files are commonly accessed and which are not).
Summary
In this chapter, I discussed compactions. The topics covered including the different kinds of compactions (minor compactions and major compactions), compaction policy, the function of compactions, and versions, delete markers, expired rows, and region splitting in relation to compactions. I also discussed regions, data locality, write throughput, and encryption in relation to compactions. Configuration properties for compactions were also discussed. In the next chapter, I will discuss RegionServer failover.
Apache HBase provides automatic failover on RegionServer crashes. When a RegionServer crashes, the HBase cluster and the data remain available. When a RegionServer crashes, all the regions on the RegionServer migrate to another RegionServer. The Master handles RegionServer failures by assigning the regions handled by the failed RegionServer to another RegionServer.
A RegionServer crash is different from an administrator stopping a RegionServer, which allows for the RegionServer to close the regions and shut down properly and for the Master to reassign the closed regions.
MTTR (Mean Time to Recover) is the average time required to recover from a failed RegionServer. The objective of MTTR for HBase regions metric is to detect failure of a RegionServer and restore access to the failed regions as soon as possible. The Role of the ZooKeeper
The ZooKeeper has the all-important role of detecting RegionServer crashes and notifying the Master so that the Master may perform the failover to another RegionServer. If no RegionServers are failing, there is no actual value to track in the logs of the ZooKeeper. However, since RegionServers do fail, the ZooKeeper is highly available and it is useful for managing the transfer of the queues in the event of a failure. The ZooKeeper coordinates, communicates, and shares state between the Master/s and the RegionServer. The ZooKeeper is a client/server system for distributed coordination and it provides an interface similar to a filesystem, consisting of nodes called znodes, which may contain transient data. When a RegionServer starts, it creates a sub-znode for describing its online state. For example, a sub-znode could be /hbase/rs/host1 . The active Master registers in the /hbase/master znode. A sub-znode used in region assignment/reassignment is the znode for unassigned regions, /hbase/unassigned/<region name> .
HBase Resilience
HBase is resilient to failures while being consistent. HBase implements consistency by having a single RegionServer responsible for a region, which is a subset of data. The resilience to failure is implemented in the HDFS, a distributed filesystem. © Deepak Vohra 2016 99
D. Vohra, Apache HBase Primer , DOI 10.1007/978-1-4842-2424-3_12 CHAPTER 12 ■ REGION FAILOVER
1. HBase puts table data in HFiles, which are stored in HDFS. HDFS replicates the blocks of the HFiles, three times by
default.
2. HBase keeps a commit log called a write-ahead log (WAL), also stored in the HDFS and also replicated three times by default.
Rebuilding a certain RegionServer can take approximatively 10-15 minutes or even more, so even the latest improvements of HBase can only provide timeline-consistent read access using standby RegionServers. This can be a serious problem for sensitive or critical apps.
Phases of Failover
Before I discuss region server failover, I will discuss the write path to HBase, also shown in Figure 12-1 . The client contacts the RegionServer directly for a write. The RegionServer is collocated with a datanode. The HBase table data is written to the local datanode and subsequently replicated to other datanodes with three replicas by default. The ZooKeeper keeps a watch on all of the RegionServers.
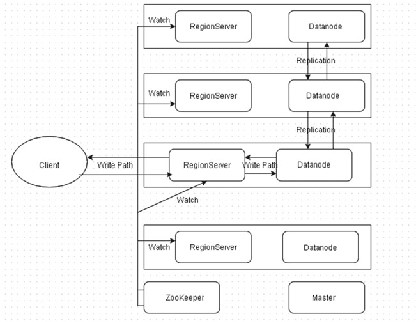
Figure 12-1. The write path to HBase
CHAPTER 12 ■ REGION FAILOVER
The phases in failover involve failure detection and the recovery process, as follows: 1. Failure Detection: Detect the RegionServer crash. 2. Data Recovery: Recover the writes in progress, which involves
reading the WAL and recovering the edits that were not
flushed.
3. Regions Reassignment: Reassign/reallocate the regions offlined due to failure to other RegionServer/s.
The three phases (crash detection, data recovery, and region reassignment) are shown in Figure 12-2 . The ZooKeeper is shown detecting the RegionServer crash. The ZooKeeper notifies the Master about the RegionServer crash. The Master performs data recovery using the WAL logs. The Master also performs the region reassignment to other RegionServers. The Master notifies the client about the RegionServer failure and the client disconnects from the failed RegionServer. The failover process is shown in Figure 12-2 .
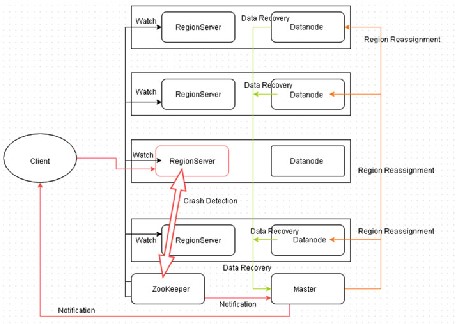
Figure 12-2. Failover process
Next, I will discuss these phases in slightly more detail.
CHAPTER 12 ■ REGION FAILOVER
Failure Detection
Detecting RegionServer failure due to a crash is performed by the ZooKeeper. Each RegionServer is connected to the ZooKeeper and the Master monitors these connections. When a ZooKeeper detects that a RegionServer has crashed, the ZooKeeper ends the RegionServer’s session and notifies the Master about the RegionServer. The Master declares the RegionServer as unavailable by notifying the client. The Master starts the data recovery process and subsequent region reassignment.
The MTTR is influenced by the zookeeper.session.timeout setting (default is 90000 ms) in hbase-default.xml / hbase-site.xml . If the RegionServer crashes, it could be 90 secs before the ZooKeeper finds out about the crash and times-out the session. But, the ZooKeeper can find out sooner than the configured timeout. The Master finds about the crash from the ZooKeeper and starts the failover to another RegionServer. The Master performs data recovery using the edits stored in the WAL and performs region reassignment. The zookeeper.session.timeout may be lowered to reduce the MTTR. A smaller timeout could lead to false positives.
Data Recovery
Data recovery makes use of the edits stored in the WALs. A single WAL consisting of multiple files for all the user regions in a RegionServer is kept. One logical WAL is created per region. One physical WAL is created per RegionServer. WALs are chronologically ordered sets of files and only the last one is open for writing. Every edit is appended to a WAL and sequential writes that sync very well are made to a WAL. Sequential reads for replication and crash recovery are performed.
The Master is able to recover writes in progress from the WAL if a RegionServer crash occurs. The Master reads the edits from the WAL and replays (rewrites) them on another region server, to which region/s have been reassigned. When a RegionServer crashes, the recovery of WAL is started. The recovery is performed in parallel and random RegionServers pick up the WAL logs and split them by edits-per-region into separate files on the HDFS. Subsequently, the regions are reassigned to random RegionServers (not necessarily the same that picked up the WALs) and each RegionServer reads the edits from the respective edits-per-region log split files to recover the correct region state. New data may be written to HBase during WAL replay.
The recovery process is slowed down if it is not just a RegionServer crash, but also the node (machine) on which the RegionServer is running has crashed. As WAL logs are replicated three times, with one of the replicas being on HDFS datanode on the same node (machine) as the RegionServer, 1/3 (33%) of replicas have become unavailable. During data recovery, 33% of reads go the failed datanode first and are redirected to a non-failed datanode. The recovery process has access to only two of the three replicas, which could slow down the recovery process. Having more than the default replicas could alleviate the slow recovery due to machine crash. Also, HBase writes are also written to the crashed datanode and the NameNode has to re-replicate the lost data to bring the replica count to the configured.
CHAPTER 12 ■ REGION FAILOVER
Regions Reassignment
The objective is to reassign the regions as fast as possible. The ZooKeeper has an important role in the reassignment. Reassignment is performed by the ZooKeeper and requires synchronization between the Master and the RegionServers through the ZooKeeper.
From these phases, the failure detection takes about 30-90 seconds. Data recovery is about 10 secs and region reassignment is 10 seconds.
After the RegionServer failover is complete, the client connects on a RegionServer to which the data has been recovered and the regions reallocated. Failover and Data Locality
HBase eventually achieves locality for a region after a flush or compaction. In a RegionServer failover, data locality may be lost if a RegionServer is assigned regions with non-local HFiles, resulting in none of the replicas being local. But as new data written in the region or table is compacted and HFiles are rewritten, they will become local to the RegionServer.
Data locality is low when a region is moved as a result of load balancing or a RegionServer crash and failover. Most of the data is not local unless the files are compacted. When writing a data file, provide hints to the NameNode for locations for block replicas. The load balancer should assign a region to one of the affiliated nodes on a server crash to keep data locality and SSR. Data locality reduces data loss probability. Configuration Properties
The configuration properties affecting region failover are shown in Table 12-1 . Table 12-1. Properties Affecting Region Failover
zookeeper.session. ZooKeeper Session timeout. Increasing 90000 timeout the zookeeper session timeout can be
a fast first fix, for instance, for garbage
collection pauses.
hbase.regionserver. Interval between messages from 3000 Summary
In this chapter, I discussed region failover including the role of the ZooKeeper. HBase is designed to be resilient to failures while being consistent at the same time. The phases of failover, which include failure detection and recovery process, are discussed. In the next chapter, I will discuss creating column families.

Columns, including the column values, are grouped into column families for performance reasons. A column family is both the logical and physical grouping of columns. A column consists of a column family and a column qualifier. A fully qualified column name consists of a prefix, which is the column family name, followed by a : (colon) and the column qualifier. For example, if a table has a single column family cf1 , which has column qualifiers col1 , col2, and col3 , the columns in the table would be cf1:col1 , cf1:col2 , and cf1:col3 . The column family name must be composed of printable characters while the column qualifier can be any bytes. Column families must be declared when a table is created, but the column qualifiers may be created on an as-needed basis dynamically. Each row in a table has the same column families even though a column family may not store any data. A table can be defined as a sparse set of rows stored in column families. The maximum number of row versions is configured per column family. All column family members are stored together on disk. Empty cells in a table are not stored at all, not even as null values. As a store is defined per column family, each StoreFile (HFile) stored on disk is per column family, which implies that the data for a column family is stored separately on disk. The storage characteristics of a column family include the following:
1. Are the values cached in memory?
2. How is the data compressed?
3. Are the row keys encoded?
All columns within a column family share the same characteristics such as versioning and compression.
Cardinality
The cardinality of a column family is the number of rows in the column family. If a column family’s data is spread across several regions and region servers, the mass scans of the column family become less efficient.
© Deepak Vohra 2016 105
D. Vohra, Apache HBase Primer , DOI 10.1007/978-1-4842-2424-3_13 CHAPTER 13 ■ CREATING A COLUMN FAMILY
Number of Column Families
The number of column families should be kept low, 2 or 3. HBase presently doesn’t perform well on column families above 2 or 3. In general, selecting fewer column families reduces the amount of data to be scanned. Presently, compactions and flushing are performed on a per-region basis, which needlessly flushes and compacts column families that do not need it and introduces unnecessary I/O network load. It is recommended to have one column family; if the second or third column family is added, the query should run on one column family at a time. Having more than a few column families causes several files to be open per region. Several column families also incur class overhead per column family. Several column families could cause compaction storms because StoreFiles are created per column family. Several column families would generate several column families.
Column Family Compression
Column family compression is a best practice and deflates data on disk. But in memory (MemStore), or while being transferred between RegionServer and client, the data is inflated. Therefore, compression does not eliminate the effect of oversized column family, oversized keys, or oversized column names, which are recommended to be kept short. The compression could be BLOCK or RECORD . The type of compression to use depends on the data used. For example, if table has a single column that stores a blob of text data and only one version is required to be kept, BLOCK compression is recommended because it spans multiple rows for the best compression ratio. If a table has variable number of rows containing text data and multiple versions are used, RECORD compression is recommended because the compression is applied per record or row. Compression ratios are generally better for BLOCK compression, therefore it’s recommended for use with blobs of text data. Access times are better for RECORD compression because a single row is fetched at a time.
Column Family Block Size
The block size is configurable per column family and is 64k by default. If the cell values are expected to be large, make the block size large. The StoreFile index size is reduced if the block size is large; as a result, a StoreFile index requires less memory. Bloom Filters
A bloom filter is used to ascertain if a given column exists in a given row. A bloom filter adds an extra index, which incurs a storage overhead in memory and an updata overhead in time. The purpose of a bloom filter is to reduce the lookup time, which makes them especially suitable if a column family has a large number of variably named columns with each cell having a small amount of data. Inserting new items and checking for existing items is speeded up with a bloom filter. Deletion is slowed as it requires rebuilding the index.
CHAPTER 13 ■ CREATING A COLUMN FAMILY
IN_MEMORY
The IN_MEMORY characteristic of a column family makes cell values to be kept in memory more preferably than normal. IN_MEMORY speeds up certain kinds of read/write patterns. The disadvantage is that it consumes more RAM and may interfere with HDFS backups because data is or might be written to disk less frequently. An example of a blocksize command when describing table is as follows:
BLOCKSIZE => '12345', IN_MEMORY => 'false', BLOCKCACHE => 'true'}]} MAX_LENGTH and MAX_VERSIONS
MAX_LENGHT and MAX_VERSIONS affect the function of a column family. MAX_LENGTH is how many bytes can be stored in each cell, with a default of max size of a 32-bit signed integer. If the data to be stored per cell is large, use a higher value. MAX_VERSIONS is the maximum number of supported versions with a default of 3.
The main factors to be considered when creating column families are as follows: 1. The access pattern and size characteristics of all members of
a column family should be the same because they are stored together.
2. The number of column families should be kept low, preferable 1 and at the most 2 or 3.
3. The column family name must be printable because it is used as directory name in the filesystem; the column qualifier can be any arbitrary bytes.
4. The maximum number of row versions should be set to a very high level, such as hundreds or more.
5. Sorting per column family can be used to convey application logic or access pattern.
6. The column family name and column qualifier name must be kept short because cell coordinates, which are {rowkey, col umnfamily:columnqualifier,timestamp} , accompany a cell value through the system. The column family and column qualifier names should be in the range of 1-3 characters each.
Summary
In this chapter, I discussed how to create a column family. In the next chapter, I will discuss RegionServer splits.


A table’s data is stored in regions. A single table’s data can be stored in one or more regions. A region is a sorted set consisting of a range of adjacent rows stored together. A table’s data can be stored in one or more regions depending on how many rows are stored in a region. RegionServers manage data stored in regions. When HBase starts, the Master assigns regions to RegionServers. If required for load balancing, the Master also reassigns regions across the RegionServers. As discussed in Chapter 9 , when the number of row keys in a region becomes too large, the region splits into approximately two equal halves, and this is called auto-sharding . Regions split automatically or manually with growing data as a region becomes too large. A RegionServer does not compact and splits in parallel. For example, a table’s row keys are not stored in the same region; a table's row keys are distributed across the cluster stored on different regions on different RegionServers.
The basic unit of horizontal scalability in HBase is a region. Rows are shared by regions. When a region becomes too large, it splits at the middle row key into approximately two equal regions. For example, in Figure 14-1 , the region has 12 rows and it splits into two regions with 6 rows each.
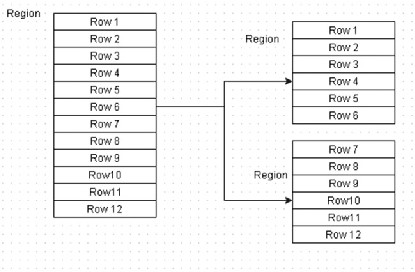
Figure 14-1. A region splits into two regions at the middle row key
© Deepak Vohra 2016 111
D. Vohra, Apache HBase Primer , DOI 10.1007/978-1-4842-2424-3_14 CHAPTER 14 ■ REGION SPLITTING
Region splitting was discussed in detail in Chapter 9 . Compactions and region splits
was discussed in Chapter 11 .
Managed Splitting
Managed or manual splitting was also introduced in Chapter 9 . Managed splitting is
recommended only for workloads. By default, automatic splitting is configured and recommended. To use managed splitting, first disable automatic splitting by setting hbase.hregion.max.filesize to a very large value that is unlikely to be reached, such as 100GB. Managed splitting may be performed with pre-splitting or later as a rolling split of all regions in an existing table, both with the org.apache.hadoop.hbase.util. RegionSplitter utility. Certain workload characteristics benefit from manual splitting. 1. Data (~ 1k) that would grow instead of being replaced. 2. Data growth is roughly uniform across all regions. 3. OLTP workload in which data loss cannot be tolerated.
The following are some of the reasons to perform managed splitting , in addition to the ones discussed in Chapter 9 :
1. Data splits are needed with growing amounts of data
debugging and profiling, and this is easier with manual
splitting. Issues such as data offlining bugs, unknown number of regions, automatically named and constantly renamed
regions are some of the issues with automatic regions.
2. The compaction algorithm may be finely tuned. Staggered time-based major compactions can be used to spread out the network I/O load and prevent split/compaction storms when regions reach the same data size at the same time.
3. Region boundaries are known and invariant.
4. Mitigates region creation and movement under load.
5. All of these issues would also be handled by automatic load balancing when found but even the best of row key designs may not get the same result as manual splitting, and load
distribution is fixed and faster with manual splitting.
CHAPTER 14 ■ REGION SPLITTING
Pre-Splitting
Pre-splitting , introduced in Chapter 9 , is the process of creating a table with the specified number of pre-split regions. Ordinarily, in a new table, the row key range is not known and the row key to split a region is undeterminable. As a result, only a single region is created by default in a new table. But a table could be created with a pre-specified number of splits. To prevent compaction storms that occur due to the uniform data growth in a large series of regions resulting in same-sized regions, the optimal number of pre-splits depends on the largest StoreFile in a region. The largest region should be just big enough so that it is compacted only during timed major compaction and an optimal number of pre-split regions is 10. When selecting the number of pre-splits, it is better to select fewer and perform rolling splits later.
Configuration Properties
The configuration properties for region splitting are discussed in Table 14-1 . CHAPTER 14 ■ REGION SPLITTING

CHAPTER 14 ■ REGION SPLITTING
The sequence used in region splitting is as follows:
1. The client sends write requests to the RegionServer.
2. The write requests accumulate in memory.
3. When the MemStore is filled and reaches a threshold, the data stored in memory is written to HFiles on disk with a process called memstore flush.
4. As store files accumulate, the region server compacts them to fewer, larger files using a compaction policy.
5. The amount of data in a region grows.
6. The RegionServer consults a region split policy to determine if the region should be split.
7. A region split request is added to a queue.
But how is a region actually split? Is it split at a certain row key? What happens to the split regions? What happens to the region split? The following sequence is used by the RegionServer in a split:
1. When the RegionServer decides to split a region, it starts a split transaction. The RegionServer acquires a shared lock on the table to prevent schema modifications during the split. Next, it creates a znode in ZooKeeper in /hbase/region-
in-transition/region-name and sets the znode state to
SPLITTING. The Master finds about the split process having started as it monitors the /hbase/region-in-transition znode.
2. The RegionServer creates a subdirectory called .splits in the region directory in HDFS. The splitting region is taken offline. Any request a client sends to a splitting region gets the NotServingRegionException .
3. The RegionServer creates subdirectories in the .splits directory for the regions to be generated and also creates the data structures.
4. The RegionServer splits the store files to create two reference files per store file in the region to be split. The reference files point to the region-to-be-split's files.
5. The RegionServer creates the region directories in HDFS and transfers the reference files to the region directories.
CHAPTER 14 ■ REGION SPLITTING
6. The RegionServer sends a Put request to the hbase:meta table to set the region-to-be-split offline and information about the new regions to be created. Individual entries for the regions to be created are not yet added to the hbase:meta table. Clients that scan the hbase:meta table find the region-to-be-split as split but won't find the regions created yet. The znode state of the new regions in ZooKeeper is SPLITTING_NEW . If the Put to hbase:meta succeeds, the region has been effectively split. If the RegionServer fails before the RPC completes successfully, the Master and the next RegionServer opening the region clean the dirty state about the region split. If the hbase:meta update completes successfully, the region split is rolled
forward by the Master. If the split fails, the splitting region state is made OPEN from SPLITTING and the two new regions’ state are made OFFLINE from SPLITTING_NEW .
7. The RegionServer opens the two new regions created in parallel.
8. The RegionServer adds the new regions to hbase:meta and the new regions are online.
9. Subsequently, clients are able to find the new regions and send requests to them. Client caches are cleared. Clients get information about new regions from hbase:meta .
10. The RegionServer updates znode /hbase/region-in-transition/region-name in ZooKeeper to the SPLIT state. The new regions’ states are made OPEN from SPLITTING_NEW . The Master finds about the states from the znode. The load balancer may reassign the new regions to other region
servers if required. The region split process is complete. The references to the old region in hbase:meta and HDFS are
removed on compactions in the new regions. The Master
periodically checks if the new regions still refer to the old
region. If not, the old region is removed.
When creating splits with Admin.createTable(byte[] startKey, byte[] endKey, numRegions) , the split strategy used is Bytes.split .
Summary
In this chapter, I discussed region splitting, including the two kinds of splitting: automatic and managed splitting. I also discussed when managed splitting is a suitable option and on what workloads. Pre-splitting, which creates pre-split regions, was also discussed. Some configuration properties used for region splitting are listed and the procedure used for region splitting was discussed. In the next chapter, I will discuss defining the row keys for optimal read performance and locality.

The primary data access pattern is by row key. No design-time way to specify row keys exists because to HBase they are simply byte arrays. When designing for optimal read performance , it is important to first understand the read path. 1. The read request is made by a client.
2. HBase identifies the files that store the rows.
3. The block index in each file identifies the block in which the row is found.
4. HBase performs a scan to fetch all the key/value pairs for the request.
5. A copy is stored in the block cache in memory before a row is returned to the client. Block cache stores the data in memory for subsequent reads. The data in the cache gets dropped with a LRU algorithm when the cache gets filled.
When scanning a file block, the following scenarios are possible: 1. No data that satisfies the read request is available. 2. HBase scans multiple blocks if a row spans multiple blocks. Table Key Design
Table keys should prevent data skew; keys should distribute data storage and processing to all RegionServers for the design to scale well and perform well, making use of all the resources of a cluster. Avoid using monotonically increasing values of time series data as row keys. Such a design could cause a single region to be a hot spot because all the key values are next to each other and belong to the same region. The row key length should be as short as is reasonable, still keeping the key suitable for data access. A tradeoff has to be made between the better Get / Scan properties of a longer key and keeping the key short.
© Deepak Vohra 2016 117
D. Vohra, Apache HBase Primer , DOI 10.1007/978-1-4842-2424-3_15 CHAPTER 15 ■ DEFINING THE ROW KEYS
Filters
In a table scan in which only the row keys are needed (no column families or column qualifiers, or values or timestamps), add a FilterList with the MUST_PASS_ALL operator to the scanner using the setFilter . The filter list should include both the FirstKeyOnlyFilter and a KeyOnlyFilter .
FirstKeyOnlyFilter Filter
The FirstKeyOnlyFilter only returns the first KV from each row. The FirstKeyOnlyFilter filter can be used more efficiently to perform row count operations. KeyOnlyFilter Filter
The KeyOnlyFilter only returns the key component of each KV (the value is rewritten as empty). The KeyOnlyFilter filter can be used to fetch all of the keys without having to also fetch all of the values. Using the FirstKeyOnlyFilter/KeyOnlyFilter combination results in minimal network traffic to the client for a single row. The combination results in a worst-case scenario of a RegionServer reading a single value from a disk. Bloom Filters
Enabling bloom filters on tables reduces the number of block reads. Some storage overhead is involved but the read performance benefit outweighs it. Bloom filters are generated when an HFile is stored. Bloom filters are stored at the end of each HFile. Bloom filters are loaded into memory. Bloom filters provide a check on row and column levels. Bloom filters can filter entire store files from reads, which is useful when data is grouped. Bloom filters are also useful when many misses (missing keys) are expected during reads.
Scan Time
Blocks storing data required for a query are identified quickly in the order of ~O(3), but scanning the block to fetch the data takes more time, O(n), in which n is the number of key values stored in a block. Therefore, it is important to create tables with an optimal block size, which also utilizes cache optimally. Partial key scans should be used when feasible. Sequential Keys
HBase stores row keys lexciographically, which provides fast, random lookup given a startKey and a stopKey . Sequential keys are suitable for read performance. Sequential keys make use of block cache. Sequential keys provide locality. Sequential keys can cause RegionServer hotspotting, which may be alleviated by using one of the following:
• Random keys: Random keys do compromise the ability to fetch given a startKey and a stopKey.
CHAPTER 15 ■ DEFINING THE ROW KEYS
• Salting row keys with a prefix and bucketing row keys across regions: Prefixing row keys provides spread. Numbered prefixes are recommended. Row keys are sorted by prefix first. Row keys of bucketed records are not in one sequence as before but records in each sequence preserve their original sequence. Multiple scans based on the original startKey and stopKey running in parallel scan multiple buckets and merge data. Salted keys provide the best compromise between read and write performance.
• Key field swap/promotion
Based on the access pattern, either use random keys or sequential keys. Random keys are best for random access patterns. Sequential keys are best when the access pattern involves a range of keys. Hashing provides spread but is not suitable for range scans. Defining the Row Keys for Locality Locality may be implemented using schema design. HBase stores data lexicographically by row key, which implies that rows with row keys close to each other are stored together. Sequential reads of range of rows is efficient and requires access of fewer regions and region servers. Sequential keys are the most suitable for locality because they fetch data from a single or fewer regions/RegionServers. Sequential keys make use of block cache. Sequential keys can cause RegionServer hotspotting but the issue is alleviated by using salting or splitting regions while keeping them small.
The new key after salting is defined as follows:
new_row_key = (++index % BUCKETS_NUMBER) + original_key where
• index is the numeric/sequential component of the row ID. • BUCKETS_NUMBER is the number of buckets the new row key is to be
spread across. As records are spread, each bucket preserves the sequential notion of original record IDs.
• original_key is the original key.
Use bulk import for sequential keys and reads.
In a Webtable, pages in the same domain are grouped together into contiguous rows by reversing the hostname component of the URLs.
Summary
In this chapter, I discussed defining the row keys for optimal performance and locality. In the next chapter, I will discuss the HBaseAmin c la s s .


The org.apache.hadoop.hbase.client.HBaseAdmin is a Java interface for managing the HBase database table metadata and also for general administrative functions. HBase is used to create, drop, list, enable, and disable tables. HBase is also used to add and drop column families. A HBaseAdmin instance may be created using one of the constructors HBaseAdmin(org.apache.hadoop.conf.Configuration c) or HBaseAdmin(HConnection connection) .
HBaseConfiguration conf = new HBaseConfiguration(); conf.set("hbase.master","localhost:60000");
HBaseAdmin admin=new HBaseAdmin(conf);
An HConnection may be obtained from HConnectionManager as follows: HBaseConfiguration conf = new HBaseConfiguration(); conf.set("hbase.master","localhost:60000");
HConnection connection = HConnectionManager.createConnection(conf); HBaseAdmin admin=new HBaseAdmin(connection);
Subsequently, HBaseAdmin method/s may be invoked. For example, TableName tableName=TableName.valueOf('test');
HTableDescriptor hTableDescriptor=new HTableDescriptor(tableName); HColumnDescriptor cf1 = new HColumnDescriptor("cf1".getBytes()); HColumnDescriptor cf2 = new HColumnDescriptor("cf2".getBytes()); hTableDescriptor.addFamily(cf1);
hTableDescriptor.addFamily(cf2);
admin.createTable(hTableDescriptor);
HBaseAdmin instances do not override a Master restart. The methods for the different functions of the HBaseAdmin class are discussed in Table 16-1 . © Deepak Vohra 2016 123
D. Vohra, Apache HBase Primer , DOI 10.1007/978-1-4842-2424-3_16 Add column addColumn(byte[] tableName, HColumnDescriptor column)
addColumn(String tableName, HColumnDescriptor column) addColumn(TableName tableName, HColumnDescriptor column )
Create table createTable(HTableDescriptor desc)
createTable(HTableDescriptor desc, byte[][]
splitKeys)
createTable(HTableDescriptor desc, byte[] startKey, byte[] endKey, int numRegions)
createTableAsync(HTableDescriptor desc, byte[][] splitKeys)
Delete column deleteColumn(byte[] tableName, String columnName) deleteColumn(String tableName, String columnName) deleteColumn(TableName tableName, byte[] columnName )
Compact a table or a compact(byte[] tableNameOrRegionName) column family compact(byte[] tableNameOrRegionName, byte[]
columnFamily)
compact(String tableNameOrRegionName)
compact(String tableOrRegionName, String columnFamily) Delete table/s deleteTable(byte[] tableName)
deleteTable(String tableName)
deleteTable(TableName tableName)
deleteTables(Pattern pattern)
deleteTables(String regex)
Disable table/s disableTable(byte[] tableName)
disableTable(String tableName)
disableTable(TableName tableName)
disableTableAsync(byte[] tableName)
disableTableAsync(String tableName)
disableTableAsync(TableName tableName)
disableTables(Pattern pattern)
disableTables(String regex)
Enable table enableTable(byte[] tableName)
enableTable(String tableName)
enableTable(TableName tableName)
enableTableAsync(byte[] tableName)
enableTableAsync(String tableName)
enableTableAsync(TableName tableName)
enableTables(Pattern pattern)
Find if HBase is checkHBaseAvailable(org.apache.hadoop.conf. running Configuration conf). Static method Assign and unassign assign(byte[] regionName)
a region to a region unassign(byte[] regionName,
server boolean force)
Run balancer balancer()
Close region closeRegion(byte[] regionname, String serverName) closeRegion(ServerName sn, HRegionInfo hri)
closeRegion(String regionname, String serverName) Flush table flush(byte[] tableNameOrRegionName)
flush(String tableNameOrRegionName)
Get online regions getOnlineRegions(ServerName sn)
Get table names getTableNames()
getTableNames(Pattern pattern)
getTableNames(String regex)
Get table regions getTableRegions(byte[] tableName)
getTableRegions(TableName tableName)
Find if the Master is isMasterRunning()
running
Find if a table is isTableAvailable(byte[] tableName)
available isTableAvailable(byte[] tableName, byte[][] splitKeys)
isTableAvailable(String tableName)
isTableAvailable(String tableName, byte[][]
splitKeys)
isTableAvailable(TableName tableName)
isTableAvailable(TableName tableName, byte[][]
splitKeys)
Find if a table is isTableDisabled(byte[] tableName)
enabled or disabled isTableDisabled(String tableName) isTableDisabled(TableName tableName)
isTableEnabled(byte[] tableName)
isTableEnabled(String tableName)
isTableEnabled(TableName tableName)
List tables and table listTableNames()
names listTables()
listTables(Pattern pattern)
Run a major majorCompact(byte[] tableNameOrRegionName) compaction majorCompact(byte[] tableNameOrRegionName, byte[]
columnFamily)
majorCompact(String tableNameOrRegionName)
majorCompact(String tableNameOrRegionName, String columnFamily)
Merge regions mergeRegions(byte[] encodedNameOfRegionA, byte[] encodedNameOfRegionB, boolean forcible)
Modify column modifyColumn(byte[] tableName, HColumnDescriptor descriptor)
modifyColumn(String tableName, HColumnDescriptor descriptor)
modifyColumn(TableName tableName, HColumnDescriptor descriptor)
Modify table modifyTable(byte[] tableName, HTableDescriptor htd) modifyTable(String tableName, HTableDescriptor htd) modifyTable(TableName tableName, HTableDescriptor htd)
Move a region move(byte[] encodedRegionName, byte[] destServerName) Offline a region offline(byte[] regionName)
Shutdown HBase shutdown()
cluster
Split a table or a region split(byte[] tableNameOrRegionName) split(byte[] tableNameOrRegionName, byte[]
splitPoint)
split(String tableNameOrRegionName)
split(String tableNameOrRegionName, String
splitPoint)
Shutdown the Master stopMaster()
Stop a RegionServer stopRegionServer(String hostnamePort) Find if table exists tableExists(byte[] tableName)
tableExists(String tableName)
CHAPTER 16 ■ THE HBASEADMIN CLASS
From HBase 0.99.0 onward the HBaseAdmin class is not a client API and is replaced with the org.apache.hadoop.hbase.client.Admin interface. An instance of Admin may be created from a Connection with Connection.getAdmin() . Connection should be unmanged obtained with the org.apache.hadoop.hbase.client.ConnectionFactory. createConnection(org.apache.hadoop.conf.Configuration conf) instance method. The Admin interface has similar methods as HBaseAdmin . The HBaseAdmin class is an internal class from 1.0.
Connection connection = ConnectionFactory.createConnection(config); Admin admin=connection.getAdmin();
Summary
In this chapter, I discussed the HBaseAdmin class. In the next chapter, I will discuss the Get Java class.

Given a table and row key, you can use the get() operation to return specific versions of that row. The org.apache.hadoop.hbase.client.Get class is used to perform Get operations on a single row. Given a row with row key of row1 in a table named table1 , the column value for a column with column family cf1 and column qualifier col1 is obtained as follows.
The org.apache.hadoop.hbase.TableName class represents a table name. Create a TableName instance:
TableName tableName=TableName.valueOf('table1'); The HBase configuration is represented with the org.apache.hadoop.hbase.
HBaseConfiguration class. Create an HBaseConfiguration instance: HBaseConfiguration conf = new HBaseConfiguration(); conf.set("hbase.master","localhost:60000");
The org.apache.hadoop.hbase.client.HConnection interface represents a client connection to an HBase cluster. Create an instance of HConnection using the static method createConnection(org.apache.hadoop.conf.Configuration conf) in org. apache.hadoop.hbase.client.HConnectionManager . Supply the HBaseConfiguration instance as the arg.
HConnection connection = HConnectionManager.createConnection(conf); T h e org.apache.hadoop.hbase.client.HTable class is used to communicate with
a table. Create an HTable instance using the TableName instance and the HConnection instance.
HTable hTable= new HTable(tableName, connection); Alternatively, an HTable instance may be created using the HTable constructor
HTable(org.apache.hadoop.conf.Configuration conf, String tableName) . HTable hTable= new HTable(conf,"table1");
© Deepak Vohra 2016 129
D. Vohra, Apache HBase Primer , DOI 10.1007/978-1-4842-2424-3_17 CHAPTER 17 ■ USING THE GET CLASS
Create a Get instance using the Get(byte[] row) constructor . Get get = new Get(Bytes.toBytes("row1"));
The Get class provides several methods to set attributes of the Get operation such as maximum number of versions, the timestamps, column families, and columns. The Get class methods are discussed in Table 17-1 .
Table 17-1. Get Class Methods
addColumn(byte[] family, Adds column family and column Get byte[] qualifier) qualifier. Multiple column families
and column qualifiers may be set by
invoking the method multiple times
in succession.
addFamily(byte[] family) Adds a column family Get
setCacheBlocks(boolean Sets whether blocks should be void cacheBlocks) cached
setMaxResultsPerColumnFamily Sets maximum results per column Get (int limit) family
setMaxVersions() Sets all versions to be fetched Get
setMaxVersions(int Sets the maximum number of Get maxVersions) versions
setRowOffsetPerColumnFamily Sets a row offset per column family Get (int offset)
setTimeRange(long minStamp, Sets a time range Get
long maxStamp)
setTimeStamp(long timestamp) Sets a timestamp for a specific Get The setTimeStamp(long timestamp) method in Get is used to get versions of
columns with a specific timestamp. Set the timestamp on the Get as follows: long explicitTimeInMs = 555;
get=get.setTimeStamp(explicitTimeInMs);
Multiple timestamps may be set as follows:
long explicitTimeInMs1 = 555;
long explicitTimeInMs2 = 123;
long explicitTimeInMs3 = 456;
get=get.setTimeStamp(explicitTimeInMs1).setTimeStamp(explicitTimeInMs2).setT imeStamp(explicitTimeInMs3);
CHAPTER 17 ■ USING THE GET CLASS
Get the data from a specified row as follows using the get(Get get) method in HTable. A Result object, which represents a single row result, is returned. To test if a row has columns, use the exists(Get get) method.
if(hTable.exists(get))
Result r = hTable.get(get);
The key/value pairs in the Result r may be output as follows using the raw() method, which returns a KeyValue[] :
for(KeyValue kv : r.raw()){
System.out.print(new String(kv.getRow()) + " ");
System.out.print(new String(kv.getFamily()) + ":");
System.out.print(new String(kv.getQualifier()) + " ");
System.out.print(kv.getTimestamp() + " ");
System.out.println(new String(kv.getValue()));
}
T h e HTable class provides the get(List<Get> gets) method to get multiple rows and the exists(List<Get> gets) method to test if columns exist in the rows to be fetched. The return value of exists(List<Get> gets) is an array of Boolean.
Get the latest version of a specified column value using the getValue(byte[] family,byte[] qualifier ) method in Result. The cf1:col1 column value is fetched as follows:
byte[] b = r.getValue(Bytes.toBytes("cf1"), Bytes.toBytes("col1")); The byte[] may be output as a String .
String valueStr = Bytes.toString(b);
System.out.println("GET: " + valueStr);
Get all versions of a specified column, like cf1:col1 , as follows using the getColumn(byte[] family, byte[] qualifier) method: List<KeyValue> listKV = r.getColumn(Bytes.toBytes("cf1"), Bytes. toBytes("col1"));
The key/value pairs in List<KeyValue> may be output as follows: for(KeyValue kv : listKV){
System.out.print(new String(kv.getRow()) + " ");
System.out.print(new String(kv.getFamily()) + ":");
System.out.print(new String(kv.getQualifier()) + " ");
System.out.print(kv.getTimestamp() + " ");
System.out.println(new String(kv.getValue()));
}
CHAPTER 17 ■ USING THE GET CLASS
The method getColumn(byte[] family, byte[] qualifier) and raw() are deprecated in 0.98.6. In later versions, the getColumnLatestCell(byte[] family, byte[] qualifier) method, which returns a Cell, and the rawCells() method, which returns Cell[] , may be used.
The Result class also provides other methods for other purposes or functions, some which are discussed in Table 17-2 . Some of these methods, such as getColumnLatestCell and tk, are available in later versions of HBase only.
Table 17-2. Result Class Methods
Find if a column has containsColumn(byte[] family, byte[] qualifier) boolean a value or is empty. containsColumn(byte[] family, int foffset,
int flength, byte[] qualifier, int qoffset,
int qlength)
containsEmptyColumn(byte[] family, byte[]
qualifier)
containsEmptyColumn(byte[] family, int
foffset, int flength, byte[] qualifier, int
qoffset, int qlength)
containsNonEmptyColumn(byte[] family,
byte[] qualifier)
containsNonEmptyColumn(byte[] family, int
foffset, int flength, byte[] qualifier, int
qoffset, int qlength)
Get all cells for a getColumnCells(byte[] family, byte[] qualifier) List<Cell> specific column.
Get a specific cell getColumnLatestCell(byte[] family, byte[] Cell version for a column. qualifier)
Get the row key. getRow() byte[]
Get the latest getValue(byte[] family, byte[] qualifier) byte[]
version of a specified
column.
Get the latest version getValueAsByteBuffer(byte[] family, byte[] ByteBuffer of a specified column qualifier)
as ByteBuffer .
Find if cell is empty. isEmpty() boolean
Get the value of the value() byte[]
first column.
Summary
In this chapter, I discussed the Get class. In the next chapter, I will discuss the HTable Java class.

The checkAndPut() method in the HTable class is used to put data in a table if a row/ column family/column qualifier ➤ value matches an expected value. If it does, a new value specified with a Put is put in the table. If not, the new value is not put. The method returns true if the new value is put and returns false if the new value is not put. Before discussing the checkAndPut() method, however, let’s discuss the put(Put put) method, which puts data without first performing a check.
Configuration conf = HBaseConfiguration.create(); HTable table = new HTable(conf, "table1");
Put put = new Put(Bytes.toBytes("row1"));
put.add(Bytes.toBytes("cf1"), Bytes.toBytes("col1"),