Chapter 39: Client/Server Concepts
Historically, the term client/server has been applied to two-tier, localized computer systems. A client/server environment is typically used to service a single company, using a local area network (LAN), or sometimes a wide area network (WAN), where a multitude of client computers are connected to a single server computer. The server computer quite literally serves up information. The client computer consumes information provided by the server computer. Of course, there is a two-way interaction between the client computer and server computer, such that client computers can also send information back to server computers.
In an Access environment, client/server architecture is not applied only as a historical term; it includes environments where an Access database communicates with a server database engine running on the same computer, as well as server databases running on other computers.

This chapter uses the database named Chapter39.accdb. If you have not already copied it onto your machine from the CD, you’ll need to do so now.
The Parts of Client/Server Architecture
A client/server setup is essentially one or more client computers (workstations) running some kind of application. That client application is connected (usually through a network) to a server computer. The application’s features, such as input screens and reports, provide an interface to the data that the application uses. The data is stored on the server computer, not the client computer. In many client/server environments, the only activity that occurs on the client computer is the interaction between the user and the application.
The ideal example of client/server architecture is the Internet. The Internet is really nothing more than a wide area network that connects computers using the TCP/IP networking protocol. Each computer running a Web browser is a client that connects to resources provided by Web servers. Very little data is stored on the client computers, while vast amounts of data may be kept on the Web servers. The primary purpose of the Web browser application running on the client computers is to provide an interface to the data provided by the Web server computers.
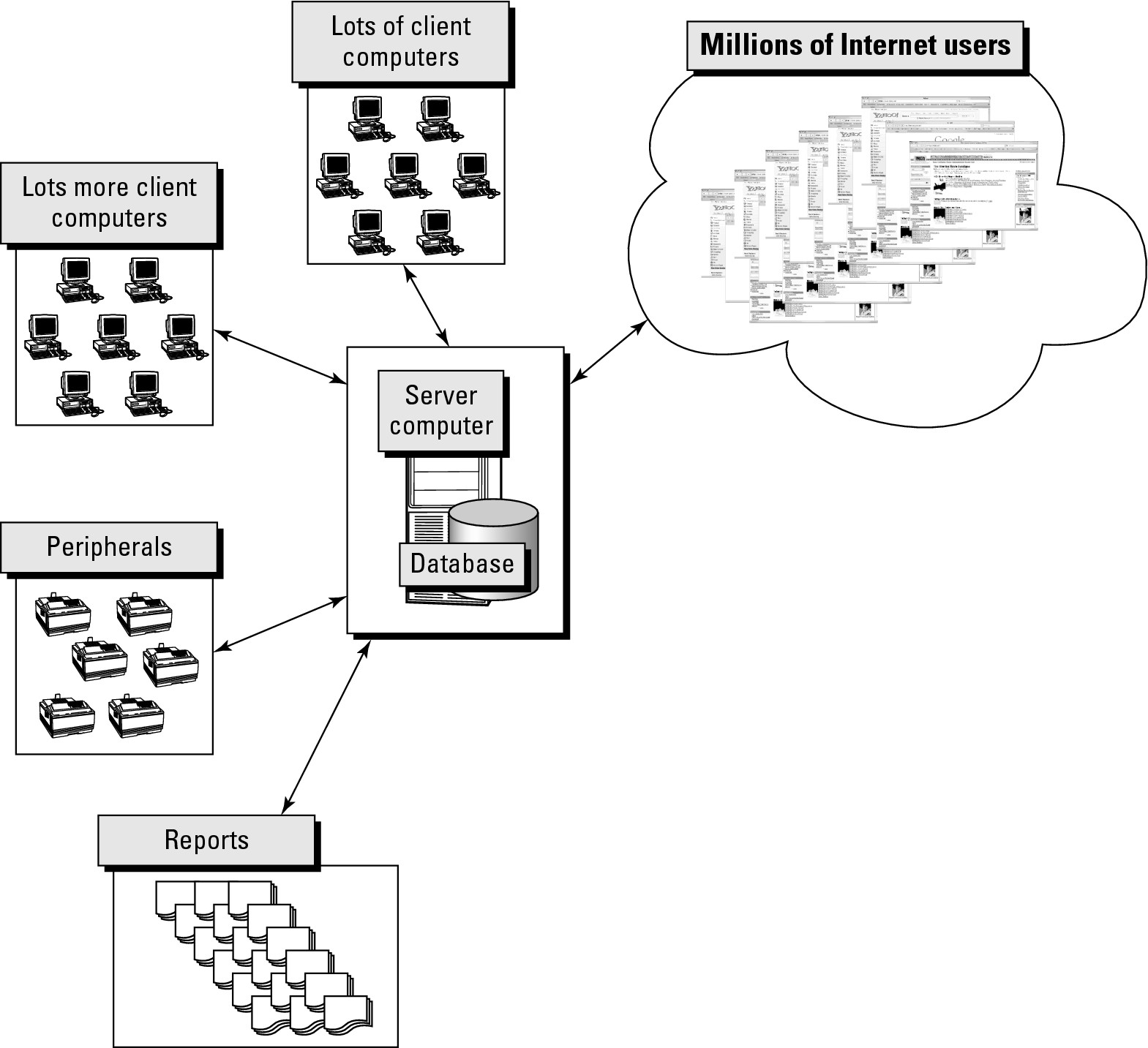
Examine the diagram shown in Figure 39-1. Everything is connected to the central server computer. All of the client computers, the Internet browsers shown in the cloud, and even the printer are effectively client applications of one form or another.
Figure 39-1
A client/server computer system layout
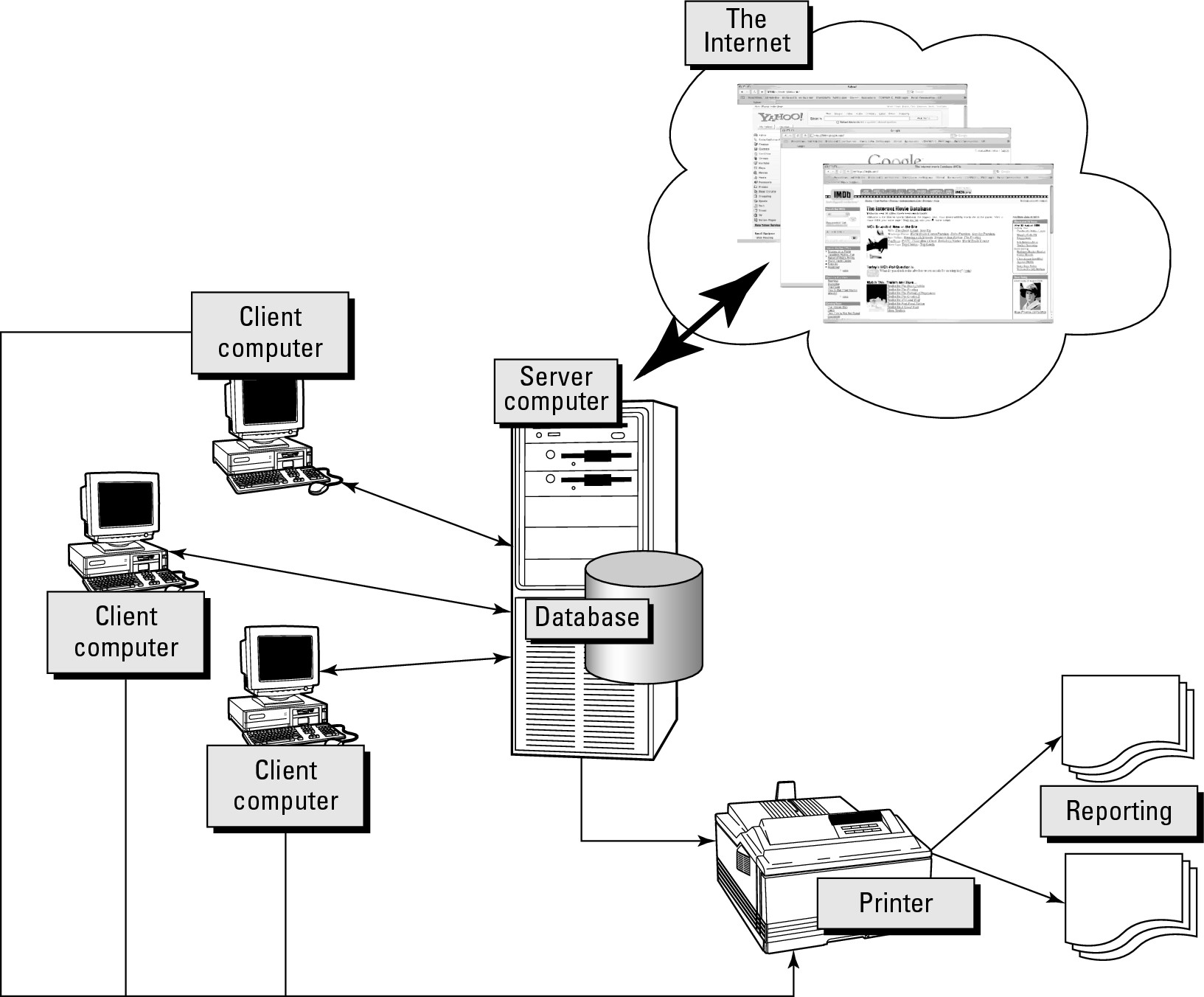

The printer shown in Figure 39-1 produces reports and is connected to both client computers and the server computer. In this case, a printer is both a client to the server computer, as well as a resource provided by the server.
Applications
From looking at Figure 39-1, you now know how the terms client and server are used when considering a computer system as a whole. The next thing to explore is what exactly runs on the different computers. In Figure 39-1, you can see that a large cloud is used to represent the Internet in general. Within that large cloud, you can see web browsers connected to various well-known Web sites. Every time you go to Yahoo! on your computer at home, your home computer becomes a client computer connected to the Yahoo! Web site. The combination of your browser program plus the software running from Yahoo! computers (servers) into your browser on your computer is a client/server application.
An application is a program running locally on a client computer. The application performs the operation of connecting the client computer to a server computer. The server computer can be somewhere on the local network or located on the Internet. Figure 39-2 and Figure 39-3 show two different applications. Both of these are Access 2007 entry forms found in the Chapter39.accdb example database.
Figure 39-2
An automobile products application entry screen (an Access 2007 form)
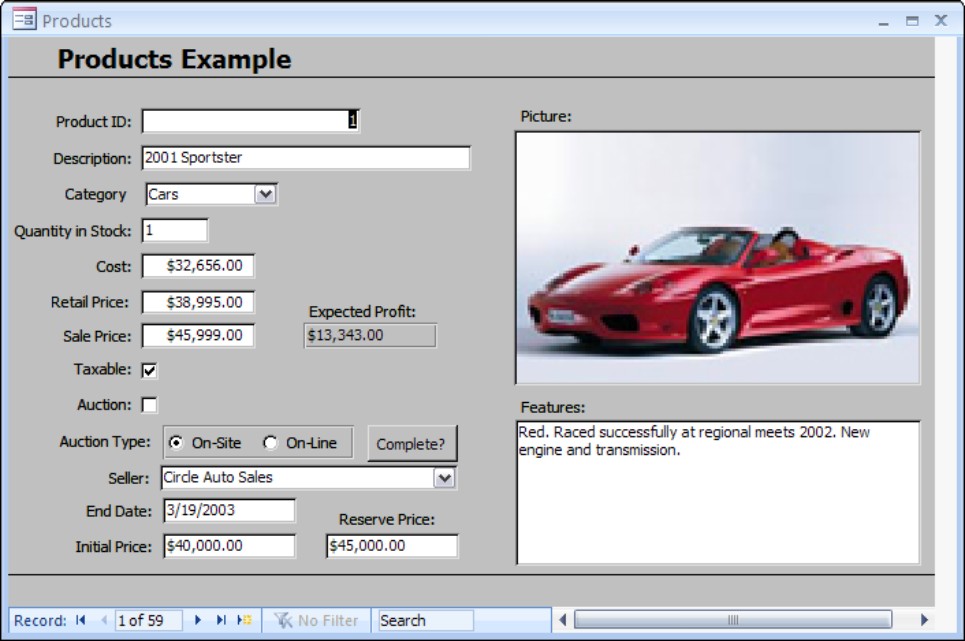
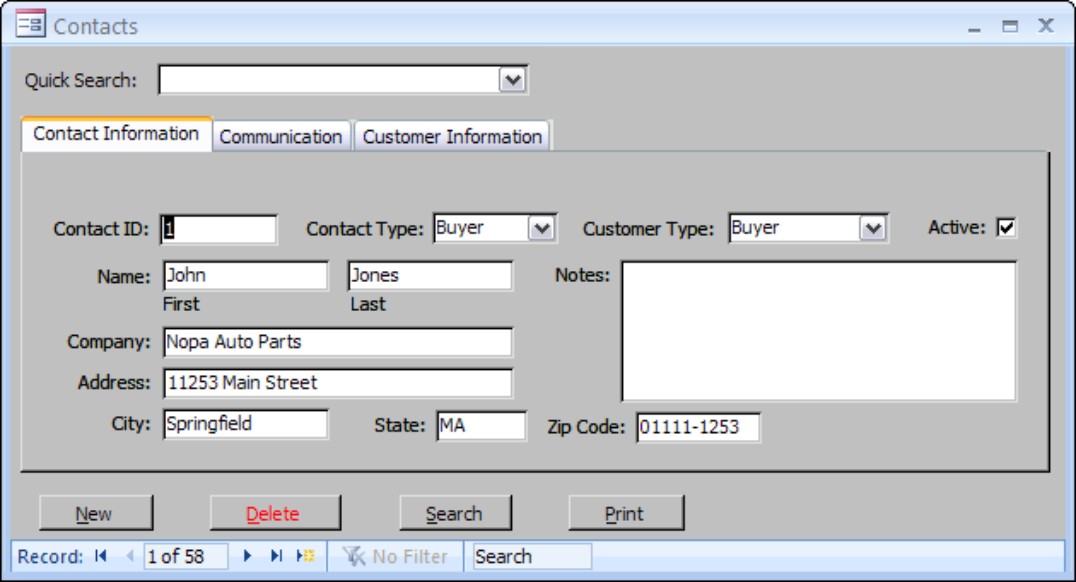
Figure 39-3
A contacts application entry screen (an Access 2007 form)
The back office
You may have heard of the expression back office, referring to the computers that store a company’s data. The back-office section of a client/server computer system is normally unseen by the users of client computers. More than one server computer can be involved in a single application. Server computers can be running databases, such as SQL Server or Oracle. Server computers can be used to form a performance funneling structure and data between database servers and client applications. These funneling-type computers include functions such as acting as Web servers and application servers.
Back-office computers perform the function of providing data to client applications. Back-office computers, such as database servers and Web servers, are almost always invisible to end users. The operation and existence of database and Web server computers is transparent to application users because users do not interact directly with the server computers.
The database
A database is used primarily to store data. In general, larger and more scalable database engines like SQL Server provide features well beyond the capabilities of Microsoft Access. One particular difference between a server database engine like SQL Server and Access is with respect to specialized database objects supported by server database engines. These specialized database objects are stored procedures, user-defined functions, and triggers.
A stored procedure is a block of commands that operates against data in the database. A user-defined function is similar to a stored procedure except that it returns a single value. A trigger is an event detector, which executes a sequence of commands when a specific event occurs with the database. These objects add intelligence and logic that determines how data stored in the database is handled by the database server.
Access has its equivalent of stored procedures, functions, and triggers, in the form of macros, modules, and class modules (see Figure 39-4).
Figure 39-4
Access uses macros, modules, and class modules for coded functionality.
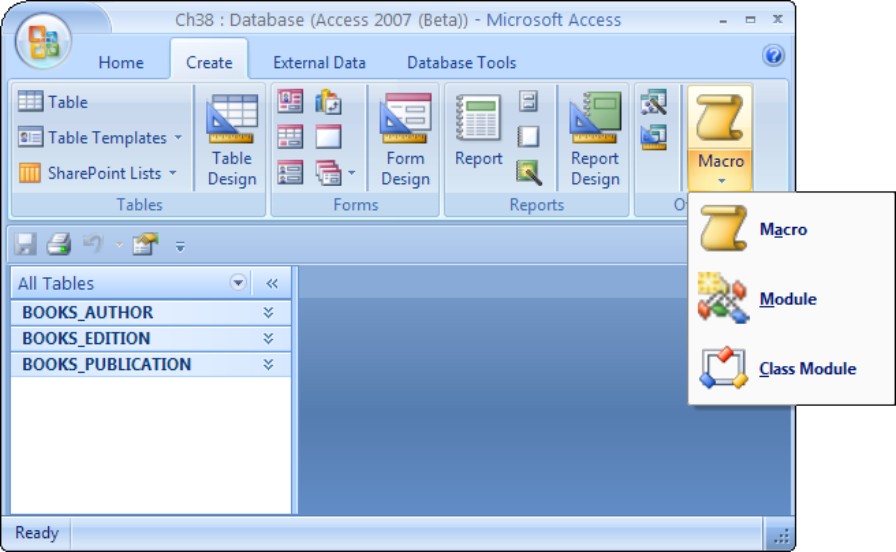
In general, a macro stores a sequence of commands and parameters for later automated repetition. Modules and class modules can be used to create blocks of code, which are stored in an Access database. These three objects all perform a similar function to that of stored procedures in a server database, in that they execute sequences of commands. Those commands typically act on data stored within an Access database, but they can do much more, such as modify the user interface or interact with the user.
In reality, an Access database is not suitable for the extreme processing power that requires a server-based database computer system. This role is more suited to database engines like SQL Server and Oracle Database. Microsoft intends for Access to be used primarily as a single-user or workgroup database system, not to drive Web sites or to support applications used by hundreds or thousands of simultaneous users. Access processes its data locally, on the user’s computer. When an Access database is split, and the back-end .accdb resides on a file server, Access pulls data from the back-end database and processes it on the user’s computer.
In contrast, server database engines like SQL Server and Oracle, process data on the server computer, and only deliver requested data to the client application. The client-side application is responsible for supporting the user interface, and responding to user input. This division of operations is the primary difference between a file-oriented database system like Access and a server database engine like SQL Server.
Concurrency is a measure of how many users a computer system can service simultaneously. Scalability is a measure of how much concurrency, processing and physical throughput a computer system can handle. Performance is a measure of how fast a computer system responds to user requests. Generally speaking, a fast response is better than a slow response.
However, Access also fulfills the dual role of both database and application development. Also, Access 2007 uses its own database engine (called the Access Database Engine), which does not provide the multiuser/multitasking capabilities of SQL Server. For example, in addition to coding in stored procedures, databases like SQL Server and Oracle also support highly specialized database objects as in the following:
• View: A stored query definition containing no data. A view is not a physical copy of data. The data are extracted when the view is requested by a client application.
• Cluster: Physical copies of entire columnar sections of heavily accessed tables, especially in SQL joins. Clusters do not automatically refresh.
• Clustered index: A special type of index that the physical order of records in a table matches the table’s primary index.
• Identity fields: Maintains sequential index counters. Typically used to generate surrogate primary keys for creation of new records in a table in a relational database. Access does allow auto counters.
A surrogate key is where an integer identifier is used to replace a primary key in a table.
• Temporary table: Used to temporarily store data, usually for intermediary steps in larger operations.
• Partitioning and Parallel Processing: Physical splitting of tables into separate partitions, including parallel processing on multiple partitions, or individual operations performed on individual partitions. Querying a small portion of a table is called partition pruning.
All of the objects described above generally have very specific tasks, roles, or functions. Access 2007 (Access Database Engine) and Access 2003 and before (Jet database engine) do not have objects of the capacity and scope listed above. Server-based database engines such as SQL Server and Oracle Database are much more powerful than Access 2007 and can simultaneously service hundreds or even thousands of users. Furthermore, SQL Server and Oracle databases often contain millions and millions of records that must be made available to a user within seconds.
On the other hand, Access a supports sophisticated forms-and-reports packages. SQL Server and Oracle Database do not have built-in application tools, and you must use other tools to build interfaces to SQL Server or Oracle data.
A huge improvement of the Access Database Engine over the Jet database engine is that the Access 2007 database engine has built-in integration with SharePoint Services capabilities (see Chapter 23). The Access Database Engine handles all of the complexity of communicating with SharePoint operating on a remote server located across the Internet.
Web servers and application servers
These types of servers perform a very specific function and usually were not present in historical, single-company-LAN, client/server environments. On a most basic level, a Web server and an application server perform exactly the same function. They both form a kind of a processing and pooling funnel between application computers and back-end server computers.
Figure 39-5 illustrates that the difference between the computers shown in Figure 39-1 and those shown in Figure 39-5 is a difference of scale and scalability. In Figure 39-5, there is much more interrogation and direct access to the database on the single-server computer. That single-server computer is limited as to how much load it can manage and continue to not irritate users by running too slowly.
Figure 39-5
A database server can be overloaded by too many users.
Overloading a database server can be prevented by using an intermediary server of some kind. This intermediary can be a Web server or an application server, as shown in Figure 39-6.
An application server is typically used to serve applications in a largescale client/server environment. Application servers often perform “load balancing” by directing user requests to server computers that are less busy than heavily used servers. A Web server is used to serve applications in an Internet environment, and may simultaneously service many hundreds of users. A Web server is generally focused on the management of connections, by sharing database server connections among many Internet connections, switching between each end user. The Web server uses connection pooling to share the resources of the database among all the concurrent user connections.
Figure 39-6
Web and application server computers manage back-end server access.
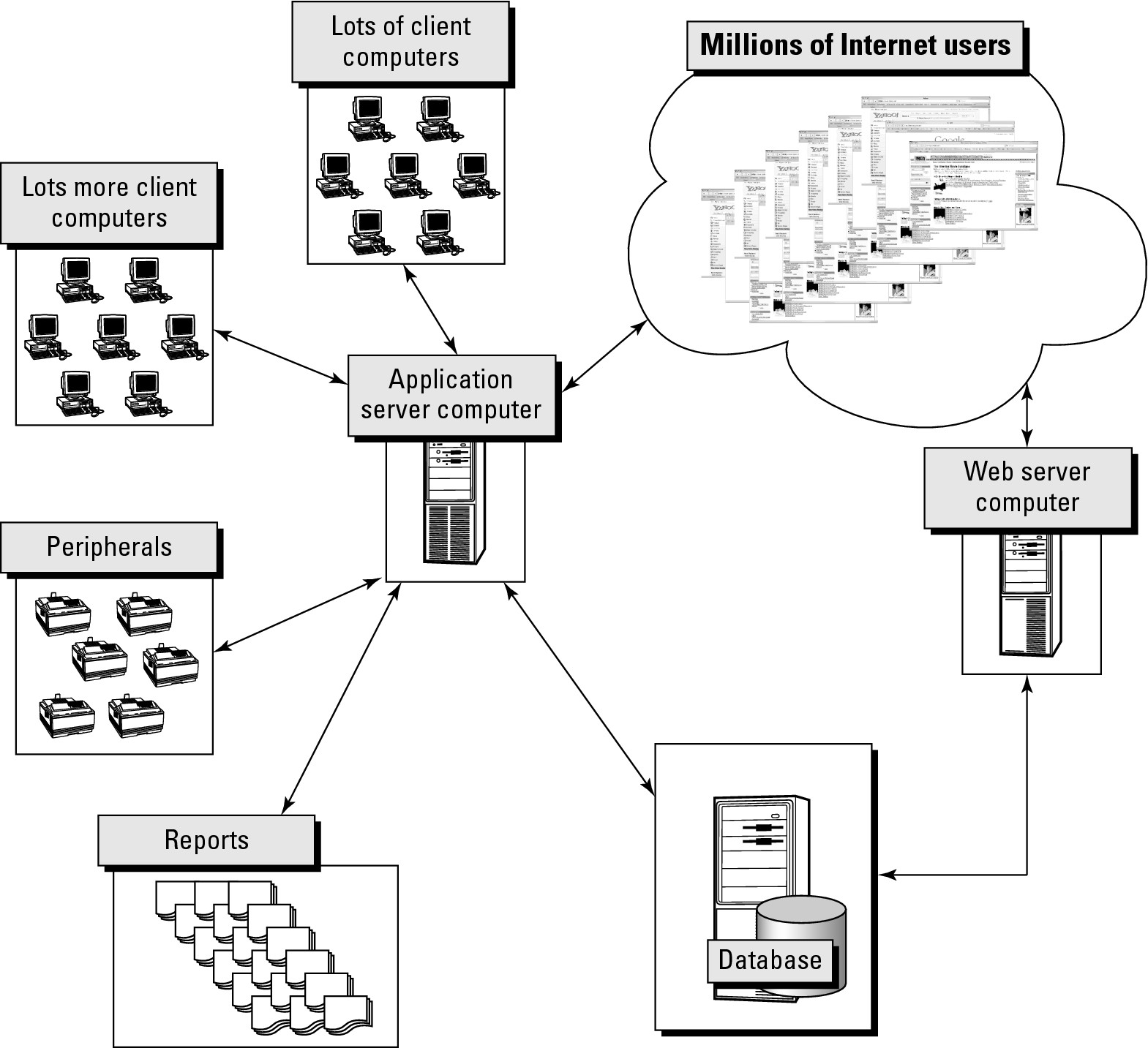
An application server is less often used for connection pooling than Web servers because the scale of the number of connections is much reduced. An application server is better suited to maintain frequently used data in a dedicated computer, as well as performing load balancing.
Multitier Architecture
So, what is a multitier computer system? Database systems can be thought of as consisting of three major components: the data, the business logic that determines how data are handled by the application, and a user interface that interacts with the user. Each of these three components is a tier of a multitier system.
A tier is a logical construct. It’s a way of segregating an application’s activities. Very often, the tier is physical as well as logical, but physical separation of tiers is not a requirement of client/server applications.
Other database architectures involve two tiers, and sometimes only a single tier. Most Access applications are, quite frankly, written as single-tier database applications. Access forms are most often bound directly to a data source, and very often the specification for extracting the data is contained within the ControlSource properties of the forms, reports, and controls in these applications.
An Access application that uses VBA code to extract data and populate forms can be considered a two-tier database application, but even then, reports are almost always directly bound to a record source in the database.
Two-tier systems
Most client/server database systems have been built as two-tier systems. This type of architecture is typical of a company running one or only a few applications, against a database across a LAN.
In case you’re wondering, splitting an Access database into front and back ends is not considered client/server. One of the fundamental characteristics of client/server databases is that processing takes place on both the client end and the server end of the application. The front-end processing is primarily involved with managing and maintaining the user interface, which involves interacting with the user, validating the user’s input, and preparing the data for delivery to the database engine. The server-side processing includes extracting and manipulating data before sending to the client side, as well as receiving data sent from the client and storing that data in the database tables.
When an Access database has been split into two pieces and the portion containing the tables has been moved to another computer, no processing ever takes place on the back-end computer. You don’t have to install software on the “server” computer in order to place the back-end database on it. Access is, and has always been, a file-based database system. The .accdb file used by an Access 2007 application is really nothing more than a data file, much as a Word document is contained within a file. No processing is required on the part of the computer holding the file in order for Access to use the data stored within the .accdb file.
Three-tier systems
A three-tier computer system is where the Web servers and application servers come in to use. In this case, the resulting architecture is the same as that shown in Figure 39-6, and for all the same reasons described previously.
Many client/server databases are written as three-tier systems. The data-management tier runs on the server computer, while the user interface is managed on the client-side workstation. The business logic is often split between the client and server computers. Data validation, user notification, and data transformation often take place within the user interface, usually in the programming code under the forms and reports. The server computer may also implement business logic in the form of user-defined functions and stored procedures that validate and verify data before storing it in the database’s tables.
What Is an OLTP Database?
Historically a client/server database served clients in one company over a small-scale LAN. Online Transaction Processing (OLTP) is a term used to describe a scaled-up client/server database. The primary difference is that the OLTP-type database is intended to service a much greater number of users, usually over the Internet. The result of OLTP databases for the Internet was the introduction of Web servers and specialized functionality inside relational databases to cater to enormously increased capacity requirements of the Internet.
An OLTP database is also a transaction-processing database. A transaction is change (adding, updating, or deleting a record, or changing a table) to the database. So, OLTP databases are built for large capacity operations (like the Internet) and are primarily used to change data. In other words, the primary purpose of an OLTP database is to allow access to small amounts of data (at any one time) to large numbers of users.
An OLTP database provides rapid access to small amounts of data and large numbers of users at the same. An OLTP database is built with these purposes in mind. Access can be used as a very small scale Internet database. Many Internet databases contain terabytes of data. Additionally, these very large Internet OLTP databases are extremely complex from a hardware architectural perspective and support advanced operations such as:
• Replication: A process of copying database changes, in real-time, to one or more computers, typically across a WAN but sometimes across a LAN. The most complex form of replication is master-to-master replication, where data changes are gradually propagated and, thus, equally distributed, both to and from many equivalent master databases across a network of fully integrated databases. The WAN could be global or in the same company.
• Standby failover: This is specialized database that continually copies changes made in a primary database, in real-time. If an error situation occurs on the primary database, the standby database fails over and becomes the primary database. Some companies could have multiple standby databases, distributed all over the world. There could even be standbys of standbys.
• Clusters and grids: This is a term used to describe gluing one or more computers together, such that many computers behave as a single, far-more-powerful computer.
Advanced features such as replication, failover, and clustering are requirements of high-performance, high-capacity database systems. These features require the specialized capabilities of server database engines like SQL Server and Oracle and are simply not possible with a desktop database system like Microsoft Access.
Access, Client/Server, and Multiple Tiers
Access is really a combination of an application development system, plus a database engine. The target market for Access as a database development system is not large-scale operations.
Most often, client-side applications that use server-provided data are built with tools like Visual Studio.NET or the Java programming language. These development systems provide no database capabilities themselves, yet, they support all the features needed by client-side database applications. A relatively simple application written in Visual Basic .NET or Microsoft Access is able to work with terabytes of data stored in SQL Server, without having to support all of the database operations supported by a server database engine.
Where does Access 2007 fit?
Now just imagine a scenario with an Access 2007 database on a single desktop computer. Then add an application or two, or maybe 10 or 20 different applications. These applications are all written in that same Access database. Next, imagine that the single computer, with the Access database supports hundreds of simultaneous users. If you’ve had any experience with Access, or a similar tool, such as dBase or Paradox, you’ll know that this kind of scaled-up scenario is likely to drive the programmer to another job.
Microsoft has never represented Access as a strong candidate for an application servicing thousands of simultaneous users. Instead, Microsoft has always primarily represented Access as a single-user database system, or, at most, a workgroup database. Over time, of course, the capabilities built into Access have improved to the point that Access is now a valid tool for building client-side applications that hook into server-provided data. As mentioned earlier in this chapter, Access 2007 seamlessly uses data provided by SharePoint Services, no matter where that data is located. Similarly, Access is also able to use data provided by Microsoft SQL Server or Oracle, located on the local network or anywhere on the Internet.
Access has severe limitations in client/server environments and, realistically, cannot be used to drive an Internet site. Even in large-scale computer systems, a tool like Access has a place as a front-end development tool.
Access as a database repository
Access is used as a database repository throughout this book. The basic relational database consists of the ability to create tables containing fields and records, the ability to establish and enforce relationships between those tables. The application layer of an Access database adds commands allowing changes to data and commands allowing reading of data. Access has all this and then some. However, as a database repository (a thing to shove data into and change the data), Access has all that it needs. Figure 39-7 shows a picture of data stored in records (sometimes called rows) in a table in an Access database.
Figure 39-7
A database repository stores fields into records and into tables.
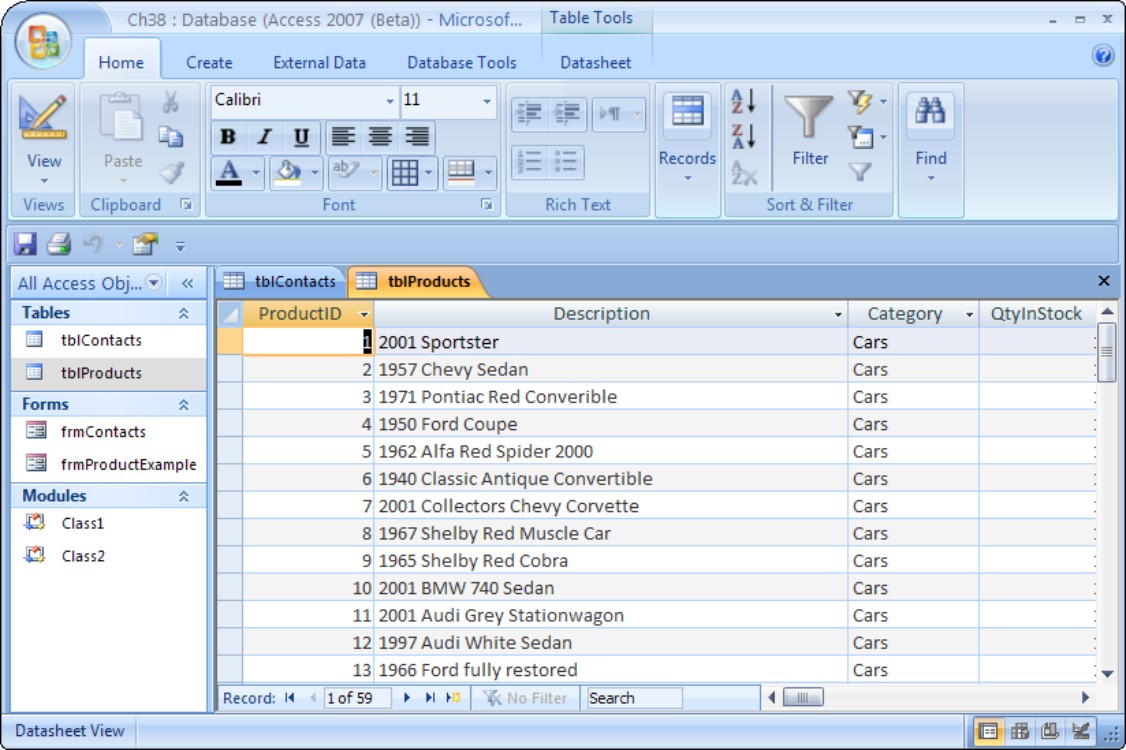
Figure 39-8 shows a table structure in Access, detailing the table’s fields, data types, and specifications for each field.
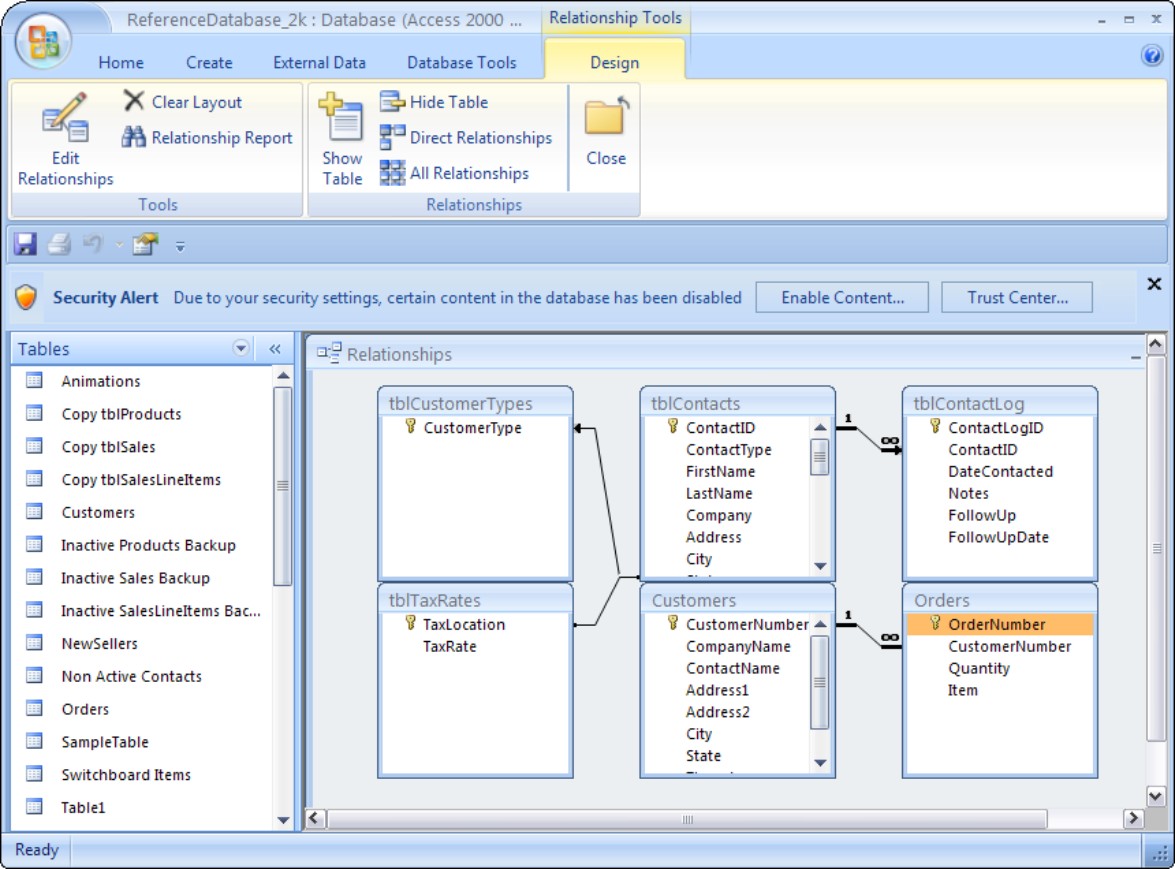
Figure 39-9 shows relationships established and enforced between various tables inside an Access database.
Figure 39-8
A database repository stores data into tables with field and data-type definitions.

Figure 39-9
A relational database allows relationships between related tables.
Access as both database and application
The real beauty and value of Access 2007 can be summarized in the following points:
• Versatile: Access is a highly versatile tool.
• Multifunctional: Access can be used as a database or an application SDK, or both.
• Very easy to use: Most importantly, Access is very easy to use. The interfaces are all graphical and all intuitive with end users in mind.
So, scalability, Internet databases, data warehouses are really not the target user population of Access, except in smaller organizations. So all those things are unimportant with respect to Access as a database and an application SDK.
Access as an Internet database
Although an Access database can be used to drive an Internet site, this practice is not recommended. The Access database engine just can’t hold up to hundreds or thousands of simultaneous requests. Performance is sure to suffer, and database corruption is virtually guaranteed in such an environment. For any measure of scalability something like SQL Server is best. And SharePoint is increasingly a viable data repository for Access applications, or, at the very least, portions of the data provided by an Access 2007 application. Utilizing SharePoint Services and Access in tandem might allow adequate servicing of a small-scale Internet database, or perhaps a localized company or educational intranet.
Summary
This chapter has provided the basis for understanding the differences between an Access desktop application and a full-blown client/server database produced with a database engine such as SQL Server. Access 2007 is a fine development tool for producing client-side user interfaces to server-provided data. Access’s excellent report writer, its superior forms designer, and VBA code combined to produce powerful and useful front ends for SQL Server and Oracle database data.
Microsoft SharePoint Services represents the future of client/server computing. Access 2007 seamlessly integrates SharePoint data. The user is unaware whether the data he sees on an Access form or report resides on his desktop computer, on the local network, or across the Internet. This level of remote data integration was simply not practical with previous versions of Access but is made possible by the new features in Access 2007.