2
The Feeling of Reality
FROM WORDS TO PICTURES
Gormenghast feels like an entire, coherent world, even though it is nothing of the kind. Yet perhaps this is not so surprising. As we read a novel, we ‘touch’ the supposed fictional world, as it were, one word at a time. Glimpsing fragments through such a narrow window, it is quite likely that gaps and inconsistencies in the whole can slip by unnoticed. Invented stories are notoriously difficult to distinguish from true stories – both feel real. Indeed, fictional worlds, and their characters and castles, can often feel real even to their creators – who ought, one might think, to be particularly aware of their unreality. After all, authors often talk of their characters, and of the entire story, gradually taking on a ‘life of their own’. But of course this is no more than a metaphor: the fictional world and its characters have no existence beyond the words committed to the page.
Now, though, consider the ‘inner world’ composed just of your current sensory experience. Rather than focusing on the unfolding chatter of your stream of consciousness, concentrate instead on your current mental ‘picture’ of the world, with all its colour, detail and clutter of objects. Surely our ‘picture’ of the sensory world isn’t glimpsed, piece by piece, through a narrow window? It seems, instead, to be ‘loaded’ simultaneously into our mind as a coherent and unified whole. If so, surely this ‘inner world’ of momentary experience can’t be incoherent: because we can simultaneously survey the whole, we would immediately spot any gaps or inconsistencies in our sensory experience, wouldn’t we? Stories can have gaps and contradictions, but pictures can’t. Can they?
Yet, as we’ll see in this chapter, our sense of ‘grasping’ the entire visual world before us is also a hoax. Our mental ‘pictures’ of the world can have as many contradictions and gaps as any fictional world or common-sense explanation.
The Swedish artist Oscar Reutersvärd (1915–2002) devoted his life to the creation of ‘impossible objects’ of deceptive simplicity. In Figure 1, three of his famous images are shown on a rather elegant set of Swedish stamps. Each ‘object’, when viewed as a whole, looks like an entirely coherent and unexceptional three-dimensional geometric figure. But on closer inspection, the interpretations of the different parts of the figure just don’t ‘add up’.1
The left-hand stamp in Figure 1 has the general look of a fairly conventional geometric layout – lines of cubes floating in space. But as we consider it more closely, our brain comes to the unsettling realization that the apparent depths in different parts of the image just don’t fit together. What is wrong, exactly? Disturbingly, the 3D interpretation of the parts of the image can’t be made to fit together to create a unified 3D interpretation of the whole. These innocent-looking images, when interpreted in 3D, turn out to be self-contradictory. They look like 3D objects, but they are not.
The phenomenon of ‘impossible objects’ may seem to be no more than a momentarily entrancing party trick, but it provides deep insights into the nature of perception, and a powerful metaphor for the nature of thought.
What, then, do impossible objects tell us? I think we can draw out three conclusions, which will, in various forms, be recurring themes throughout this book. First of all, they tell us that there is something badly wrong with our common-sense ideas about how perception works. According to our common-sense view, the senses map the outer world into some kind of inner copy, so that, when perceiving a book, table or coffee cup, our minds are conjuring up a shadowy ‘mental’ book, table or coffee cup. The mind is a ‘mirror’ of nature.2 But this can’t be right. There can’t be a 3D ‘mental copy’ of these objects – because they don’t make sense in 3D. They are like 3D jigsaw puzzles whose pieces simply don’t fit together. The mind-as-mirror metaphor can’t possibly be right; we need a very different viewpoint – that perception requires inference.

Second, the way we experience impossible objects implies the brain ‘grasps’ different aspects of the image at different times. We scan the different parts of the figures, and find that each, considered in isolation, has a perfectly coherent depth. The 3D interpretations of each part (e.g. a particular strut, cube or plane) seem perfectly consistent. But these interpretations just don’t fit together into a coherent whole. Our brain glimpses, and conceives of, the world fragment by fragment.
The third lesson concerns our misplaced confidence. When viewing an impossible object, we have the overwhelming sense that we are looking at a 3D scene, albeit a peculiar one. But this ‘feeling’ of solidity is completely misguided – we are actually looking at a flat image that has no possible 3D interpretation.3 This is yet another illustration of the illusions of depth. These illusions of depth, which can be both literal, as with impossible figures, and metaphorical, as with stories and explanations, are everywhere.
THE SPARSENESS OF SENSORY EXPERIENCE
So the visual ‘world’ can be contradictory. But is it also full of gaps? This isn’t how things seem. Surveying the room, I have the feeling of simultaneously grasping the clutter of walls, pieces of furniture, rugs, lights, computers, coffee mugs, and scattered books and papers. Surely my intuitions about my own sensory experience can’t be wrong. Can they?
One much-discussed reason that you should be suspicious of your sense of a detailed and multicoloured sensory world comes from basic anatomy. The sensitivity of colour vision falls very rapidly, though smoothly, as we move out from the fovea (the dense pit of specialized colour-detecting ‘cone cells’ in the retina which your eye ‘points’ at any item of interest; see Figure 2). Indeed, outside a few degrees of where you are directly looking, you are close to being completely colour blind. The ‘rod’ cells that dominate most of your visual field can only detect dark and light. So the basic anatomy of the eye tells us that, except for within a few degrees of where we are directing our eyes, we are seeing in black and white. Yet, of course, we have the feeling that our entire ‘subjective visual world’ is richly coloured. This, at least, must be an illusion.

While we are on the subject of the retina, notice that cone cells are not just specialized for detecting colour; they are also specialized for picking up fine detail. It is for this reason that your eye directs the fovea onto the word it is currently attempting to read. Indeed, the sensitivity of vision falls rapidly, but smoothly, as we move out from the fovea; and the rate at which sensitivity declines is not arbitrary but is precisely calibrated so that, within the widest possible range, our perceptual abilities are independent of the size that objects project onto the retina. So we can recognize a friend in the distance, make sense of thumbnail pictures on a computer screen, or read a small font, but equally we can also recognize a looming face, make sense of close-ups from the front row of the cinema, or read a giant billboard from up close. To be able to zoom in or zoom out requires that the smaller the region to be analysed, the more densely our visual ‘resources’ are concentrated.
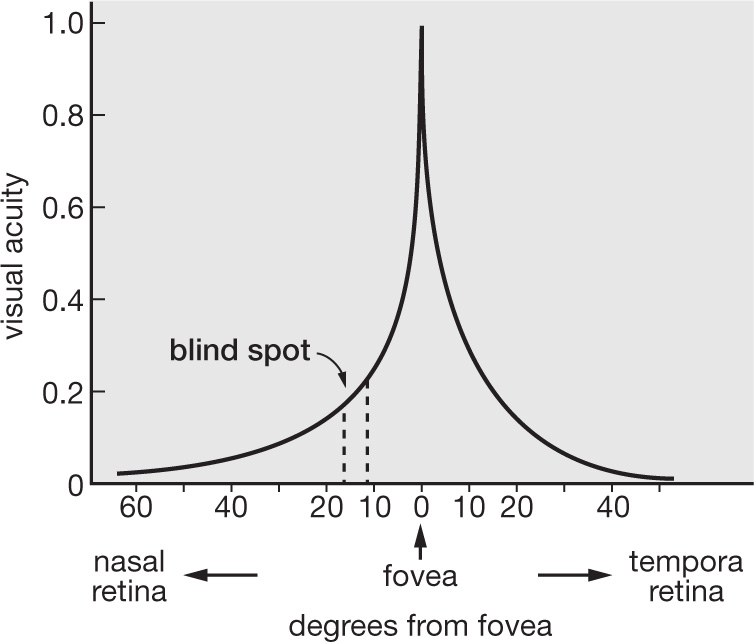
To see just how sharply concentrated our visual powers are, look at the graph of visual acuity (Figure 3) – a measure of the ability to see fine details that is picked up with the well-known chart of letters of diminishing size beloved of opticians – and notice how precisely it mirrors the density of cone cells in the retina (Figure 2). But this observation implies that, not only is the visual periphery colourless, it is also extremely fuzzy. Surveying the room before me, I have the sense that the entire scene is captured by my inner experience in precise detail; yet this too is an illusion – whatever I am not looking at directly is an inchoate blur.

Elementary facts about the anatomy of the eye, then, contradict our most fundamental intuitions about our sensory experience: we see the world through a narrow window of clarity; almost the entire visual field is colourless and blurry. And, putting anatomy to one side, we can sense that some trickery is afoot by considering some of the strange visual images which directly illustrate the ‘narrowness’ of vision. Consider the strange ‘twelve dots’ illusion in Figure 4. There are twelve black dots arranged in three rows of four dots each. The dots are large enough to be seen clearly and simultaneously against a white background. But when arranged on the grid, they seem only to appear when you are paying attention to them. Dots we are not attending to are somehow ‘swallowed up’ by the diagonal grey lines. Interestingly, we can attend to adjacent pairs of items, to lines, to triangles and even squares – although these are highly unstable. But our attention is in short supply; and where we are not attending, the dots disappear.
The limited visual ‘window’ depends, to some extent at least, on where we are looking. Yet we typically have only the vaguest sense of which part of an image or scene we are looking at directly – we have the impression that the entire visual scene is simultaneously ‘grasped’ in pretty much complete detail. We sense that our imagined ‘mental mirror’ appears to reflect the external world equally sharply, across the whole visual field. Figure 5 makes our eye movements visible to us: as you direct your eye across the grid, you see a patch of white dots wherever you are looking. If you turn the picture 45 degrees in either direction, you may find the dots, both black and white, begin to sparkle more intensely. Our visual experience can depend, rather dramatically, on where we are looking – and we are certainly unable to ‘load up’ this entire image into our minds – even though it is actually very simple and repetitive.

Thus our visual grasp of the world is not quite as precise and all-encompassing as it appears to be. Looking at the page in front of me as I type, I have the feeling that I see words everywhere. But this too is an illusion: I can see, roughly, just one word at a time. Consider the following thought experiment. Suppose that all the letters on the page apart from the very word I am currently looking at (with a few letters’ margin around it) were magically scrambled. That is, as soon as I shift my eyes to a new location, only the new patch of letters my eyes ‘land’ on would be transformed into meaningful letters. Each local patch of meaningful text would be ‘created’ just at the very moment I look at it; the rest of text could just as well be meaningless strings of letters. If I can only read one word at a time, then I should be entirely oblivious to all of this scrambling and unscrambling.
The invention of the technology of so-called ‘gaze-contingent’ eye-tracking has made it possible to test this for real. Let us see how this works in a typical experiment. Suppose you are looking at a computer screen, reading the line of text at the top of Figure 6. Your eyes are being monitored by an eye-tracker, and jump across the text as indicated by the circles. Rather than continuously showing the whole sentence, the computer screen displays only a ‘window’ of text (highlighted in Figure 6 by the grey rectangles – though, of course, the rectangles aren’t visible to you – all you see is unadorned text) which shifts to wherever you are looking. Inside the rectangle, the text is displayed as normal; outside the rectangle, the blocks of letters are replaced by blocks of xs.
This procedure means that the display you are looking at is ‘gaze-contingent’: what is displayed on the screen depends on where you are looking at that particular moment. So, as your eye successively hops along the line of text, the display on the computer screen you are looking at shifts, as shown by the successive rows in Figure 6. The ‘window’ of meaningful text follows your eye as it jumps along the line of text – everywhere else there is nothing but blocks of xs.
What, then, is the subjective experience of reading a text that is almost entirely blocks of xs, with a small island of meaningful words, created on the spot, wherever you happen to be looking? If we, in some loose sense, ‘see’ whole screenfuls and pagefuls of text at once, then we should notice, and be rather puzzled by, the existence of the blocks of xs. But do we?
It depends, of course, on the size of the ‘window’. If the window is tiny, then your brain will have the rather bizarre experience of seeing a moving snippet of letters from ‘behind’ a stream of xs. But if the window is long enough, you will perceive nothing unusual – because the xs will be too distant for you to notice them. So you will read the text without noticing anything untoward, even though it is continually mutating before your very eyes. You might wonder if the change-detecting rod cells in the periphery might spot anything amiss – and, as it were, sound the alarm that the text is shifting and not stable. And this might indeed be the case, if it were not that the changes in the display occur while your eye is moving – when, it turns out, you are effectively blind.
So, then, the crucial question is how small can we shrink the window before people notice anything is amiss? It turns out that, remarkably, it can be shrunk to just ten to fifteen characters (as shown in the figure), shifted somewhat to the right of the fixation point8 (the brain is ‘thinking ahead’ slightly, to help plan the next eye movement; so, in languages that read from right to left, such as Hebrew, the window is instead shifted to the left9).

Remarkably, reading proceeds quite normally, even though the only letters you can possibly be identifying are the twelve to fifteen letters of English text that are, at that moment, visible on the screen – the rest can be strings of xs, or Latin, or whatever the experimenter chooses.11 These results suggest that the eye and brain picks up little outside a very narrow ‘window’. Indeed, we can go a bit further: the evidence suggests12 that we can only read one word at time. Indeed, an eye-tracker monitoring your reading right now would show your eye irregularly ‘hopping’ along the line of text, from one word to the next. Sometimes your eyes will jump over short and predictable words, and occasionally jump back a few words when you lose the thread. But, roughly speaking, you read by hopping from one word to the next, reading one word at a time. This puts severe limits on how rapidly we can read. In particular, it implies that speed-reading is simply skimming; there is no way that the brain can ‘take in’ whole lines or paragraphs of text at once.
Right now, then, you are reading these very words through an equally narrow window. Aside from the small window of letters you are directly fixating on, you scarcely recognize any letters at all. And, similarly, severe restrictions apply not just to letters and words, but to our ability to make sense of faces, objects, patterns and entire scenes. Looking at a crowd, it turns out that you can only recognize one person at a time; looking at a colourful scene, you can only report colours or details of things that you are looking at directly.
This does not imply, of course, that you pick up no information at all about objects you are not attending to – just that this information is extremely sparse. While we can imagine that we see a whole page full of words at once, we are seeing just one word at a time. And we are picking up a general impression of something like ‘regular lines of markings’ for the rest of the page. Or when looking at a cluttered scene, we have the general impression of ‘lots of objects’ but can only identify one object at once.
Despite these astonishing results, many psychologists and philosophers have been unwilling to draw the conclusion that the richness of perceptual experience is an illusion – that our senses give us only a tenuous link to the external world. It is tempting to retort that perhaps we cannot report or remember more than one item at a time in the page of text or crowd of faces confronting us, but perhaps we can see far more than we report or remember. Perhaps, in short, there is an inner world of experience, which copies the external world in something close to its full complexity. But this supposedly rich subjective awareness may ‘overflow’ what we can report, because the inner world of experience is fleeting – it disappears even as you start to describe it.
But this reassuring picture can’t be right. If it were, what people would be ‘seeing’ in the gaze-contingent eye-tracking experiment would be blocks of xs with just a narrow window of meaningful letters; and they would perceive the window of meaningful letters shifting as they moved their eyes. But this isn’t what people report at all: they claim to see a completely normal sentence, composed entirely of meaningful words, and they are entirely oblivious to the existence of the blocks of xs, let alone the fact that letters are changing their identities as the eye scans along the line of text. So the ‘overflow’ story doesn’t work: if we could ‘see’ the entire page of text, but report only one word at a time, then the gaze-contingent eye-tracker wouldn’t fool us at all. The fact that we are comprehensively hoodwinked tells us that at no point do we see the full range of text in front of us – we recognize, roughly, one word at a time, and have only the vaguest sense of the rest of the text.
The sense that there is a whole text, or scene, before us arises, then, from the integration of snippets of visual information, as our eyes hop across the visual world. So our sense of a rich visual world should break down if we hold the point of contact between eye and world perfectly still. Indeed, if we could stabilize the visual image projected onto the eye, our perception of a scene, a word, a face, or a page of text should begin to disintegrate. Can this really be right?
We have no good intuitions about this strange situation because, of course, in daily life, our eye is continually in motion. Even when we try steadily to fixate an object, our eye is subject to a little jitter, beyond our conscious control. But what would happen if we could hold the image on our retina precisely still? Given that the eye is continually in motion, this means that the image needs to move with it in perfect synchrony, so that the pattern of light falling on each patch of retina is stabilized. Then, wherever a person looks, they see precisely the same thing.
The problem of stabilizing an image on a continually jiggling eye seems technically challenging – yet, remarkably, this technical challenge was solved as far back as the 1950s by research groups led by psychologist Lorrin Riggs at Brown University in the US, and by physicist R. W. Ditchburn at Reading University in the UK. One solution was to attach a tiny ‘micro-projector’ weighing just one quarter of a gram to the eyeball itself, via a contact lens. As the eye moves, the projector moves with it, so stabilizing the image precisely. And it is onto the fovea that the retinal image is projected. Through clever optics, the image appears to the viewer to be rather small and far away – in reality, though, the micro-projector is no more than an inch from the eye.
So what happens when the retinal image is suddenly made almost perfectly still? We might expect that we should see whatever is projected into our eye exactly as normal, but frozen. But this isn’t at all what happens: within a few seconds, the projected image begins to disappear, either piece by piece, or in its entirety; all that is left is a uniform grey field which sometimes darkens into black. Without warning, though, the whole image or parts of it spontaneously reappear, typically to disintegrate, reorganize or entirely disappear again.13
Retinal stabilization sheds light on perception and, by extension, on thought. Consider, for example, what happens when a person is confronted with nothing more than a straight line. Initially, the brain locks onto and processes this line successfully, but now the brain will attempt to disengage and lock onto a new stimulus. Normally, of course, shifting the eyes will yield new visual stimulation to lock onto, but with a stabilized image, eye movements generate no new visual information. Disengaging from the line, but with nothing to re-engage with, no fresh perceptual interpretation is created – the person experiences nothing more than a blank field. Now and again, the brain re-engages with the only available ‘meaningful’ signal, and the straight line pops back into view. But not for long – our whirring imagination is continually straining to find new material onto which an interpretation can be imposed.
If this is right, then, we should expect simpler stimuli to disappear comprehensively and often – and, indeed, when viewing a simple straight line, people often report that they see nothing but a blank field for as much as 90 per cent of the time. On the other hand, it is possible to engage with a more complex stimulus in a variety of distinct ways, by locking onto different parts of the stimulus, potentially yielding a variety of different patterns. So more complex patterns should be visible far more of the time; they should show ‘dynamic’ shifts of continual disintegration and reorganization; and, crucially, because we can consciously experience only the output of perceptual interpretation, the visible patterns should be composed of meaningful units, rather than an arbitrary scatter of image fragments. And this is exactly what happens.
Consider, for example, the results shown in Figure 7 (opposite). In each ‘strip’ the left-hand picture is the image as projected into the participant’s eye; the other images are a selection of the visual experiences that participants reported, as they experienced the image decompose and recompose itself. Take, first, the drawing of a head (7a), in profile: note first that the visible material tends to correspond to continuous regions of the image (e.g. the upper, lower or left-hand side), rather than a set of arbitrary fragments. Note, in particular, the ‘pure’ profile, disconnected from the rest of the head – it is significant that people ‘lock on’ to this coherent unit, rather than arbitrary outlines (e.g. the fragments of line indicating the hair).

The focus on contiguous, meaningful units becomes even clearer when we consider (7b), where the basic stimulus is the letters H and B jammed up against each other. As might be expected, the individual letters H and B are sometimes seen alone, but also the letter H drops away completely leaving a 3; perhaps most intriguing is that it is possible to ‘lock on’ to a 4, and to obliterate the surrounding fragments that don’t fit. This is an illustration of the delightful imaginative power of the perceptual system. It is no by means obvious, until one examines it closely, that there even is a 4 hidden in the HB figure. Yet the perceptual system finds this pattern spontaneously.
The same pattern is observed in 7c, where the word BEER breaks down into a number of component words, but not, for example, into ‘meaningless’ substrings of letters, such as EE, EER or ER. And in 7d we find that a wire-frame cube breaks down not haphazardly, line by line, but in whole chunks, so that some faces of the cube survive and others disappear. The two illustrations in which the opposite faces only are retained illustrate that the tendency to preserve discrete regions of the image is not an absolute one. Most crucial is that the patterns that the brain locks onto are themselves meaningful. Of course, these specific fragments are meaningful, but most meaningful if we assume that the line-drawing is interpreted as a 3D cube, rather than a 2D flat line-drawing. These observations at least suggest that the ‘locking-on’ process of attention is, in these cases, operating after the brain has interpreted the image in depth. Finally, in 7e, notice how a grid of squares can decompose into various lines of squares, or that our brain may focus just on a single square – notice, as ever, the brain’s preference for meaningful patterns, rather than random subsets of squares.
The strange phenomenology of stabilized images has been known for more than half a century.15 In the intervening years, such findings have largely been viewed as a puzzling curiosity, marginal to the big questions of perception, thought and consciousness. Yet they reveal the very essence of how the mind works. In particular, these phenomena suggest some fundamental principles of the operation of perception, and by extension, thought:
- We ‘see’ only meaningful organizations (or at least the most meaningful organization the brain can find): visual chunks, patterns and whole letters, numbers, words, rather than a random scatter of fragments.
- We see just one meaningful organization at a time (we can see, for example, BEER or PEEP, but we cannot have the experience of seeing both).
- Other sensory information that is not part of this meaningful organization (though clearly and distinctly projected onto the retina at all times), is largely or even entirely ignored, to the point of becoming entirely invisible.
- The brain is continually churning: despite the unaccustomed lack of new input, the brain is desperately attempting to disengage from the current organization, and to find another. When it cannot, the image entirely disappears.
The phenomenology we experience in viewing stabilized images is the closest we have to a ‘window’ onto how we see – a glimpse behind the scenes at the brain’s convincing magic show. And, as we shall explore below, perceiving is a type of thinking. Indeed, it is perhaps the most important type; and all other types of thought are really just extensions of perception (though powerful extensions). Following this line, then, we shall see later in the book that evidence from retinal stabilization foreshadows a theory of thought.
These observations imply, of course, that our beliefs about what we see, whether we are looking at text, objects, faces or colours, are systematically misleading: we see far, far less than we think we do. Indeed, we see the world one snippet at a time; and we can tie snippets together, just as we can link together successive sentences in a story. So the ‘inner world’ of your current sensory experience is also, it turns out, entirely fake. We are able to attend to one word, object or colour at a time – and no more. The ‘inner world of sensation’ feels real, but then so does Gormenghast Castle as we read its description, line by line. In both cases, our brain is successfully piecing together a stream of snippets of information, not simultaneously grasping the ‘whole’. There is no ‘inner realm’ which mirrors the richness and complexity of the outer world. If there were, the gaze-contingent eye-tracker, creating tiny islands of coherence just where we are looking, against a sea of meaningless strings of xs, could not possibly deceive us.
The previous chapter outlined the illusion of explanatory depth – the verbal accounts that we give of our knowledge, motives, desires and dreams turn out to be flimsy improvisations, invented after the fact. In this chapter, we have seen that we are being spectacularly fooled even about the richness and coherence of our own sensory experience. We think we see a detailed, multicoloured world, but we don’t. This is a hoax so astonishing and all-encompassing that it is sometimes known in philosophy and psychology as the ‘grand illusion’.16
Where does this leave us? The sensory world is no more solid than the ‘worlds’ of stories and the supposed bedrock of common-sense explanation. We have the sense of ‘clearly perceiving’ the solid 3D character of impossible objects – just as we have a vivid sense of the layout of Gormenghast Castle and a vivid ‘feeling of understanding’ the people and the world around us. But such understanding is riddled with contradictions. And we have seen that our experience of the sensory world is, to an astonishing degree, also full of gaps – the Grand Illusion has us in its thrall.
The unavoidable conclusion of these findings is that the mind itself is an impossible object : it has only the superficial appearance of solidity. Peake’s visions of Gormenghast Castle, our everyday explanations of physical objects – these feel solid and coherent. But they are all hopelessly confused and contradictory. Our stream of consciousness is no more a ‘projection’ of an inner mental world than Oscar Reutersvärd’s curious figures are projections from some alternative geometrical reality. There is nothing more to the mind than the fleeting contents of our stream of consciousness. And not only that (despite our intuitions to the contrary), consciousness is astonishingly sparse: we create sensations, beliefs and desires; and make pronouncements, carry out actions and make choices, one by one, as required.