11
Self-Organization and Biochemical Predestination
By 1968, the chance hypothesis was already suspect. The preceding fifteen years had revealed a cellular realm of stunning complexity, and though it would take several more decades to pinpoint the exact odds of a functioning protein or DNA molecule arising by chance alone, many scientists already had grown skeptical of chance as an explanation for the origin of life. Among them was a young biophysicist at San Francisco State University named Dean Kenyon. As he wrote a year later: “It is sometimes argued in speculative papers on the origin of life that highly improbable events (such as the spontaneous formation of a molecule of DNA and a molecule of DNA polymerase in the same region of space at the same time) become virtually inevitable over the vast stretches of geological time. No serious quantitative arguments, however, are given in support of such conclusions.” Instead, he argued, “such hypotheses are contrary to most of the available evidence.”1 To emphasize the point Kenyon noted: “If the association of amino acids were a completely random event…there would not be enough mass in the entire earth, assuming it was composed exclusively of amino acids, to make even one molecule of every possible sequence of…a low-molecular-weight protein.”2
Kenyon began exploring a different approach. With a Ph.D. from Stanford and having worked under Melvin Calvin, a leading biochemist and origin-of-life researcher at the University of California, Berkeley, Kenyon was steeped in the scientific culture of the late 1960s. He was well aware of Jacques Monod’s conceptual dichotomy between chance and necessity. He understood that the logical alternative to chance was what Monod called necessity, the lawlike forces of physics and chemistry. If chance events couldn’t explain the origin of biological information, then, Kenyon thought, perhaps necessity could. Eventually he and a colleague, Gary Steinman, proposed just such a theory; except that they didn’t call it “necessity.” They called it “predestination”—biochemical predestination. In 1969 Kenyon and Steinman wrote a book by this title. Through the 1970s and early 1980s it became the bestselling graduate-level text on the origin of life and established Kenyon as a leading researcher in the field.
In Biochemical Predestination, Kenyon and Steinman not only presented a new theory about the origin of biological information; they also inaugurated a fundamentally new approach to the origin-of-life problem, one that came to be called “self-organization.” In physics, the term “self-organization” refers to a spontaneous increase in the order of a system due to some natural process, force, or law. For example, as a bathtub drains, a highly ordered structure, a vortex, forms as the water swirls down the drain under the influence of gravity and other physical forces such as the Coriolis force. In this system, a force (gravity) acts on a system (the water in the draining tub) to generate a structure (the vortex), thus increasing the order of the system. Self-organizational theories of the origin of life try to attribute the organization in living things to physical or chemical forces or processes—ones that can be described mathematically as laws of nature.
Of course, the self-organizational theorists recognized that they needed to do more than simply assert that life arose by physical or chemical necessity. They needed to identify a specific lawlike process (or series of processes) that could generate life or critical components of living cells starting from some specific set of conditions. In other words, self-organizational theorists needed to identify deterministic processes that could help overcome the otherwise long odds against the origin of life occurring by chance alone. And that is what Kenyon and those who followed in his wake set out to do. In the process Kenyon and other self-organizational theorists formulated theories that either tried to explain, or circumvented the need to explain, the DNA enigma.
More Than the Sum
What accounts for the difference between a chunk of marble and a great sculpture? What explains the difference between a cloud and a message created from steam by a skywriter? What accounts for the difference between a functioning cell and the various molecules that jointly constitute it? These questions raise the classical philosophical issue of reductionism. Does the whole reduce to the sum of its parts? Or conversely, do the properties of the parts explain the structure and organization of the whole? As with many such questions, the best answer is, “It depends.”
Consider a silver knife, fork, and spoon. The metal in all three has a definite set of chemical properties describable by physical and chemical laws. Silver atoms will react with certain atoms, under certain conditions, but not with others. Silver will melt at certain temperatures and pressures, but not at others. Silver has a certain strength and resistance to shearing. Insofar as these properties reliably manifest themselves under certain specified conditions, they can be described with general laws. Nevertheless, none of these properties of silver accounts for the shape of the various utensils and, therefore, the functions they perform.
From a purely chemical point of view nothing discriminates the silver in a spoon from that in a knife or fork. Nor does the chemistry of these items explain their arrangement in a standard place setting with the fork on the left and the knife and spoon on the right. The chemistry of the silverware is indifferent to how the silver is arranged on the table. The arrangement is determined not by the properties of the silver or by chemical laws describing them, but by the choice of a rational agent to follow a human convention.

Figure 11.1. Dean Kenyon. Printed by permission from Dean Kenyon.
Yet one cannot say the same of every structure. Many objects display a structure and order that results from the chemical properties of their ingredients. For example, a crystal of salt has a lattice structure that exhibits a striking, highly repetitive pattern. This structure results from forces of mutual electrostatic attraction (describable by natural law) among the atoms in the lattice. Similarly, a spiral galaxy has a definite structure that results largely from lawlike forces of gravitational attraction among the stars in the galaxies. Structure does not always defy reduction to chemistry and physics.
What about living cells and the complex molecules they contain? Does their organization derive from the physical and chemical properties of their parts? Do the chemical constituents of proteins or DNA molecules have properties that could cause them to self-organize? Are there physical or chemical forces that make the production of information-rich molecules inevitable under plausible prebiotic conditions? Dean Kenyon thought the answer to these questions might well be yes.
Biochemical Predestination
Like Aleksandr Oparin, whom he credited with inspiration, Kenyon sought to account for the origin of the first life in a series of gradual steps. Like Oparin, Kenyon constructed a scenario describing how life might have arisen through a series of chemical transformations in which more complex chemical structures arose from simpler ones. In Kenyon’s model, simple monomers (e.g., amino acids, bases, and sugars) arose from simpler atmospheric gases and energy; polymers (proteins and DNA) arose from monomers; primitive membranes formed around these polymers; and a primitive metabolism emerged inside these membranes as various polymers interacted chemically with one another. Unlike Oparin, however, who relied on chance variations to achieve some of the chemical transformations, Kenyon relied more exclusively on deterministic chemical reactions. In his scenario, each stage along the way to the origin of life was driven by deterministic chemical processes, including the most important stage, the origin of biological information.
Whereas Oparin had suggested that the process by which monomers arranged themselves into polymers in the prebiotic soup was essentially random, Kenyon and Steinman suggested that forces of chemical necessity had performed the work. Specifically, they suggested that just as electrostatic forces draw sodium (Na+) and chloride (Cl–) ions together into highly ordered patterns within a crystal of salt, amino acids with special affinities for each other might have arranged themselves to form proteins. As the two scientists explained, “In the same fashion that the difference in the nature of reactivity of the units of a growing inorganic crystal determines the final constitution of the three-dimensional crystal array, so differences in reactivities of the various amino acids with one another could possibly serve to promote a defined ordering of sequence in a growing peptide chain.”3
Kenyon and Steinman first came to this idea while performing “di-mer” bonding experiments in the laboratory of Melvin Calvin at the University of California, Berkeley. They wanted to see whether specific amino acids bond more readily with some amino acids than others. Their experimental results suggested that they do. For example, they discovered that glycine forms linkages with alanine twice as frequently as glycine with valine. Moreover, they discovered that these differences in chemical affinity seemed related to differences in chemical structure. Amino acids with longer side chains bond less frequently to a given amino acid than do amino acids with shorter side chains.4 Kenyon and Steinman summarized their findings in a table showing the various differential bonding affinities they discovered.
In the wake of these findings, Kenyon and Steinman proposed that these differences in affinity imposed constraints on the sequencing of amino acids, rendering certain sequences more likely than others. As they put it, “It would appear that the unique nature of each type of amino acid as determined by its side chain could introduce nonrandom constraints into the sequencing process.”5 They further suggested that these differences in affinity might correlate with the specific sequencing motifs typical in functional proteins. If so, the properties of individual amino acids could themselves have helped to sequence the amino-acid chains that gave rise to functional proteins, thereby producing the information the chains contain. Biochemical necessity could thus explain the seeming improbability of the functional sequences that exist in living organisms today. Sequences that would be vastly improbable in the absence of differing bonding affinities might have been very probable when such affinities are taken into account.
Kenyon and Steinman did not attempt to extend this approach to explain the information in DNA, since they favored a protein-first model.6 They knew that proteins perform most of the important enzymatic and structural functions in the cell. They thought that if functional proteins could arise without the help of nucleic acids, then initially they need not explain the origin of DNA and RNA and the information they contained. Instead, they envisioned proteins arising directly from amino acids in a prebiotic soup. They then envisioned some of these proteins (or “proteinoids”) forming membranes surrounding other proteins. Thus, the two were convinced that only later, once primitive metabolic function had arisen, did DNA and RNA need to come on the scene. Kenyon and Steinman did not speculate as to how this had happened, content as they were to think they may have solved the more fundamental question of the origin of biological information by showing that it had arisen first in proteins.
Doubts About Self-Organization
Did Kenyon and Steinman solve the DNA enigma? Was the information necessary to produce the first life “biochemically predestined” to arise on the early earth? Surprisingly, even as their bold self-organizational model grew in popularity among origin-of-life researchers, Kenyon himself began to doubt his own theory.7
Kenyon’s doubts first surfaced in discussions with one of his students at San Francisco State University. In the spring of 1975 near the end of a semester-long upper-division course on evolution, a student began to raise questions about the plausibility of chemical evolution.8 The student—ironically named Solomon Darwin—pressed Kenyon to examine whether his self-organizational model could explain the origin of the information in DNA. Kenyon might have deflected this criticism by asserting that his protein-first model of self-organization had circumvented the need to explain the information in DNA. But by this point he found himself disinclined to make that defense.
For some time Kenyon himself had suspected that DNA needed to play a more central role in his account of the origin of life. He realized that whether functional proteins had arisen before DNA or not, the origin of information-rich DNA molecules still needed explanation, if for no other reason than because information-rich DNA molecules exist in all extant cells. At some point, DNA must have arisen as a carrier of the information for building proteins and then come into association with functional proteins. One way or another, the origin of genetic information still needed to be explained.
Now he faced a dilemma. Having opted for a self-organizational approach, he had only two options for explaining the information in DNA. Either (a) the specific sequences of amino acids in proteins had somehow provided a template for sequencing the bases in newly forming DNA molecules or (b) DNA itself had self-organized in much the same way he and Steinman supposed proteins had. As he reflected more on Solomon Darwin’s challenge, Kenyon realized that neither option was very promising. First, Kenyon knew that to propose that the information in proteins had somehow directed the construction of DNA would be to contradict everything then known about molecular biology. In extant cells, DNA provides the template of information for building proteins and not the reverse. Information flows from DNA to proteins. Moreover, there are several good reasons for this asymmetry. Each triplet of DNA bases (and corresponding RNA codons) specifies exactly one amino acid during transcription and translation. Yet most amino acids correspond to more than one nucleotide triplet or RNA codon. This feature of the genetic code ensures that information can flow without “degeneracy,” or loss of specificity, in only one direction, from DNA to proteins and not the reverse.
Additionally, Kenyon realized that for structural and chemical reasons, proteins made poor candidates for replicators—molecules that can function as easily copied informational templates. Unlike DNA, proteins do not possess two antiparallel strands of identical information and thus cannot be unwound and copied in the way DNA can. Further, proteins are highly reactive once they are unwound (due to exposed amino and carboxl groups and exposed side chains). For this reasons, most “denatured” (unwound) proteins tend to cross-link and aggregate. Others are quickly destroyed in the cell. Either way, denatured proteins tend to lose their structural stability and function. Moreover, they do not regain their original three-dimensional shape or activity once they lose it. By contrast, DNA is a stable, chemically inert molecule that easily maintains its chemical structure and composition while other molecules copy its information. For all these reasons, it seemed difficult to envision proteins serving as replicators of their own stored information. Indeed, as Kenyon later told me, “getting the information out of proteins and into DNA” would pose an insuperable conceptual hurdle.
And there was another difficulty. By the late 1980s new empirical findings challenged the idea that amino-acid bonding affinities had produced the biological information in proteins. Although Kenyon and Steinman had shown that certain amino acids form linkages more readily with some amino acids than with others,9 new studies showed that these differential affinities do not correlate with actual sequencing patterns in large classes of known proteins.10 In other words, differential bonding affinities exist, but they don’t seem to explain (or to have determined) the specific sequences of amino acids that actual proteins now possess. Instead, there was a much more plausible explanation of these new findings, one consistent with the Crick’s central dogma. The amino-acid sequences of known proteins had been generated by the information encoded in DNA—specifically, by the genetic information carried in the DNA of the organisms in which these proteins reside. After all, proteins in extant cells are produced by the gene-expression system. Of course, someone could argue that the first proteins arose directly from amino acids, but now it was clear there was, at the very least, no evidence of that in the sequences of amino acids in known proteins.
All this would later reinforce Kenyon’s conviction that he could not circumvent the need to explain the origin of information in DNA by positing a protein-first model. He would have to confront the DNA enigma.
Kenyon realized that if the information in DNA did not arise first in proteins, it must have arisen independently of them. This meant that the base sequences of DNA (and the molecule itself) must have self-organized under the influence of chemical laws or forces of attraction between the constituent monomers. Yet based upon his knowledge of the chemical structure of the DNA molecule, Kenyon doubted that DNA possessed any self-organizational properties analogous to those he had identified in amino acids and proteins. He was strengthened in this conclusion by reading an essay about DNA by a distinguished Hungarian-born physical chemist and philosopher of science named Michael Polanyi. As it happened, this same essay would shape my own thinking about the viability of self-organizational theories as well.
Life Transcending Physics and Chemistry
I first encountered Dean Kenyon in 1985, sixteen years after the publication of Biochemical Predestination. I was in the audience in Dallas during the presentation in which Kenyon announced that he had come to doubt all current chemical evolutionary theories of the origin of life—including his own. Thus, when I arrived in Cambridge, I already knew that one of the leading proponents of “self-organization” had repudiated his own work. Nevertheless, I did not yet fully appreciate why he had done so. I learned from Charles Thaxton that Kenyon had begun to doubt that his protein-first models eliminated the need to explain the origin of information in DNA. But I didn’t yet see why explaining the DNA enigma by reference to self-organizing chemical laws or forces would prove so difficult.
That began to change as I encountered the work of Michael Polanyi. In 1968, Polanyi published a seminal essay about DNA in the journal Science, “Life’s Irreducible Structure,” and another essay in the Chemical and Engineering News the year before, “Life Transcending Physics and Chemistry.” During my first year of graduate study, I wrote a paper about the two essays and discussed them at length with my supervisor, Harmke Kamminga, since it seemed to me that Polanyi’s insights had profound implications for self-organizational models of the origin of life.
Polanyi’s essays did not address the origin of life question directly, but rather a classical philosophical argument between the “vitalists” and “reductionists” (discussed in Chapter 2). Recall, that for centuries, vitalists and reductionists had argued about whether a qualitative distinction existed between living and nonliving matter. Vitalists maintained that living organisms contained some kind of immaterial “vital force” or spirit, an elan vital that distinguished them qualitatively from nonliving chemicals. Reductionists, for their part, held that life represented merely a quantitatively more complex form of chemistry. Thus, in their view, living organisms, like complex machines, functioned as the result of processes that could be “reduced” or explained solely by reference to the laws of physics and chemistry.
The molecular biological revolution of the 1950s and 1960s seemed to confirm the reductionist perspective.11 The newly discovered molecular mechanisms for storing and transmitting information in the cells confirmed for many biologists that the distinctive properties of life could, as Francis Crick put it in 1966, “be explained in terms of the ordinary concepts of physics and chemistry or rather simple extensions of them.”12 As Richard Dawkins later wrote, the discovery of DNA’s role in heredity “dealt the final, killing blow to the belief that living material is deeply distinct from nonliving material.”13
But had it really? Even if biochemists were no longer looking for some mysterious life force, was it really clear that living things could be explained solely by reference to the laws of physics and chemistry?
Polanyi’s answer turned the classical reductionism-vitalism debate on its head. He did this by challenging an assumption held by reductionists and vitalists alike, namely, that “so far as life can be represented as a mechanism, it [can be] explained by the laws of inanimate nature.”14 Whereas vitalists had argued against reductionism by contesting that life can be understood mechanistically, Polanyi showed that reductionism fails even if one grants that living organisms depend upon many mechanisms and machines. To show this, Polanyi argued that even if living organisms function like machines, they cannot be fully explained by reference to the laws of physics and chemistry.15
Consider an illustration. A 1960s vintage computer has many parts, including transistors, resistors, and capacitors. The electricity flowing through these various parts conforms to the laws of electromagnetism, for example, Ohm’s law (E = IR, or voltage equals current times resistance). Nevertheless, the specific structure of the computer, the configuration of its parts, does not result from Ohm’s or any other law. Ohm’s law (and, indeed, the laws of physics generally) allows a vast ensemble of possible configurations of the same parts. Given the fundamental physical laws and the same parts, an engineer could build many other machines and structures: different model computers, radios, or quirky pieces of experimental art made from electrical components. The physical and chemical laws that govern the flow of current in electrical machines do not determine how the parts of the machine are arranged and assembled. The flow of electricity obeys the laws of physics, but where the electricity flows in any particular machine depends upon the arrangement of its parts—which, in turn, depends on the design of an electrical engineer working according to engineering principles. And these engineering principles, Polanyi insisted, are distinct from the laws of physics and chemistry that they harness.
Polanyi demonstrated that the same thing was true of living things. He did this by showing that communications systems, like machines, defy reduction to physical and chemical law and by showing further that living organisms contain a communications system, namely, the gene-expression system in which DNA stores information for building proteins.
Polanyi argued that, in the case of communications systems, the laws of physics and chemistry do not determine the arrangements of the characters that convey information. The laws of acoustics and the properties of air do not determine which sounds are conveyed by speakers of natural languages. Neither do the chemical properties of ink determine the arrangements of letters on a printed page. Instead, the laws of physics and chemistry allow a vast array of possible sequences of sounds, characters, or symbols in any code or language. Which sequence of characters is used to convey a message is not determined by physical law, but by the choice of the users of the communications system in accord with the established conventions of vocabulary and grammar—just as engineers determine the arrangement of the parts of machines in accord with the principles of engineering.
Thus, Polanyi concluded, communications systems defy reduction to physics and chemistry for much the same reasons that machines do. Then he took a step that made his work directly relevant to the DNA enigma: he insisted that living things defy reduction to the laws of physics and chemistry because they also contain a system of communications—in particular, the DNA molecule and the whole gene-expression system. Polanyi argued that, as with other systems of communication, the lower-level laws of physics and chemistry cannot explain the higher-level properties of DNA. DNA base sequencing cannot be explained by lower-level chemical laws or properties any more than the information in a newspaper headline can be explained by reference to the chemical properties of ink.16 Nor can the conventions of the genetic code that determine the assignments between nucleotide triplets and amino acids during translation be explained in this manner. Instead, the genetic code functions as a higher-level constraint distinct from the laws of physics and chemistry, much like a grammatical convention in a human language.
Polanyi went further, arguing that DNA’s capacity to convey information actually requires a freedom from chemical determinism or constraint, in particular, in the arrangement of the nucleotide bases. He argued that if the bonding properties of nucleotides determined their arrangement, the capacity of DNA to convey information would be destroyed.17 In that case, the bonding properties of each nucleotide would determine each subsequent nucleotide and thus, in turn, the sequence of the molecular chain. Under these conditions, a rigidly ordered pattern would emerge as required by their bonding properties and then repeat endlessly, forming something like a crystal. If DNA manifested such redundancy, it would be impossible for it to store or convey much information. As Polanyi concluded, “Whatever may be the origin of a DNA configuration, it can function as a code only if its order is not due to the forces of potential energy. It must be as physically indeterminate as the sequence of words is on a printed page.”18
DNA and Self-Organization
Polanyi’s argument made sense to me. DNA, like other communication systems, conveys information because of very precise configurations of matter. Was there a law of physics or chemistry that determined these exact arrangements? Were there chemical forces dictating that only biologically functional base sequences and no others could exist between the strands of the double helix? After reading Polanyi’s essays, I doubted this.
I realized that his argument also had profound implications for self-organizational theories of the origin of life. To say that the information in DNA does not reduce to or derive from physical and chemical forces implied that the information in DNA did not originate from such forces. If so, then there was nothing Kenyon could do to salvage his self-organizational model.
But was Polanyi correct? How did we know that the constituent parts of DNA did not possess some specific bonding affinities of the kind that Kenyon and Steinman had discovered in amino acids? Polanyi argued largely on theoretical grounds that the nucleotide bases could not possess such deterministic affinities and still allow DNA to store and transmit information. How do we know that such affinities do not exist?
In 1987 when I first encountered Polanyi’s argument, I did not yet understand the chemical structure of DNA well enough to answer this question. And Polanyi, who no doubt did, did not bother to explain it in his articles. So the question lingered in the back of my mind for several years after completing my Ph.D. Not until the mid-1990s, when I began to make a more systematic evaluation of self-organizational theories, did I find an answer to it.
I remember vividly the day the breakthrough came. I was listening to a colleague, a biologist at Whitworth College, teach a college class about the discovery of the double helix when I noticed something about the chemical structure of DNA on the slide that she had projected on the screen. What I noticed wasn’t anything I hadn’t seen before, but somehow its significance had previously escaped me. It not only confirmed for me Polanyi’s conclusion about the information in DNA transcending physics and chemistry, but it also convinced me that self-organizational theories invoking bonding affinities or forces of attraction would never explain the origin of the information that DNA contains.
Figure 11.2 shows what I saw on the slide that suddenly seized my attention. It portrays the chemical structure of DNA, including the chemical bonds that hold the molecule together. There are bonds, for example, between the sugar and the phosphate molecule forming the two twisting backbones of the DNA molecule. There are bonds fixing individual nucleotide bases to the sugar-phosphate backbones on each side of the molecule. There are also hydrogen bonds stretching horizontally across the molecule between nucleotide bases, forming complementary pairs. The individually weak hydrogen bonds, which in concert hold two complementary copies of the DNA message text together, make replication of the genetic instructions possible. But notice too that there are no chemical bonds between the bases along the longitudinal axis in the center of the helix. Yet it is precisely along this axis of the DNA molecule that the genetic information is stored.

Figure 11.2. Model of the chemical structure of the DNA molecule depicting the main chemical bonds between its constituent molecules. Note that no chemical bonds link the nucleotide bases (designated by the letters in boxes) in the longitudinal message-bearing axis of the molecule. Note also that the same kind of chemical bonds link the different nucleotide bases to the sugar-phosphate backbone of the molecule (denoted by pentagons and circles). These two features of the molecule ensure that any nucleotide base can attach to the backbone at any site with equal ease, thus showing that the properties of the chemical constituents of DNA do not determine its base sequences. Adapted by permission from an original drawing by Fred Hereen.
There in the classroom this elementary fact of DNA chemistry leaped out at me. I realized that explaining DNA’s information-rich sequences by appealing to differential bonding affinities meant that there had to be chemical bonds of differing strength between the different bases along the information-bearing axis of the DNA molecule. Yet, as it turns out, there are no differential bonding affinities there. Indeed, there is not just an absence of differing bonding affinities; there are no bonds at all between the critical information-bearing bases in DNA.19 In the lecture hall the point suddenly struck me as embarrassingly simple: there are neither bonds nor bonding affinities—differing in strength or otherwise—that can explain the origin of the base sequencing that constitutes the information in the DNA molecule. A force has to exist before it can cause something. And the relevant kind of force in this case (differing chemical attractions between nucleotide bases) does not exist within the DNA molecule.
Of course it might be argued that although there are no bonds between the bases that explain the arrangement of bases, there might be either something else about the different sites on the DNA molecule that inclines one base rather than another to attach at one site rather than another. I investigated the possibility with a colleague of mine named Tony Mega, an organic chemist. I asked him if there were any physical or chemical differences between the bases or attachment sites on DNA that could account for base sequencing. We considered this question together for a while, but soon realized that there are no significant differential affinities between any of the four bases and the binding sites along the sugar-phosphate backbone. Instead, the same type of chemical bond (an N-glycosidic bond) occurs between the base and the backbone regardless of which base attaches. All four bases are acceptable; none is chemically favored.
This meant there was nothing about either the backbone of the molecule or the way any of the four bases attached to it that made any sequence more likely to form than another. Later I found that the noted origin-of-life biochemist Bernd-Olaf Küppers had concluded much the same thing. As he explained, “The properties of nucleic acids indicate that all the combinatorially possible nucleotide patterns of a DNA are, from a chemical point of view, equivalent.”20 In sum, two features of DNA ensure that “self-organizing” bonding affinities cannot explain the specific arrangement of nucleotide bases in the molecule: (1) there are no bonds between bases along the information-bearing axis of the molecule and (2) there are no differential affinities between the backbone and the specific bases that could account for variations in sequence.
While I was teaching I developed a visual analogy to help my students understand why these two features of the chemical structure of DNA have such devastating implications for self-organizational models, at least those that invoke bonding affinities to explain the DNA enigma. When my children were young, they liked to spell messages on the metallic surface of our refrigerator using plastic letters with little magnets on the inside. One day I realized that the communication system formed by the refrigerator and magnetic letters had something in common with DNA—something that could help me explain why the information in DNA is irreducible to physical or chemical forces of attraction.
To demonstrate this to my students, I would bring a small magnetic “chalkboard” to class with a message spelled on it, such as “Biology Rocks!” using the same kind of plastic letters that my kids used at home. I would point out that the magnetic forces between the letters and the metallic surface of the chalkboard explain why the letters stick to the board, just as forces of chemical attraction explain why the nucleotides stick to the sugar-phosphate backbone of the DNA. But I would also point out that there are no significant forces of attraction between the individual letters that determine their arrangement, just as there are no significant forces of attraction between the bases in the information-bearing axis of the DNA molecule. Instead, the magnetic forces between the letters and the chalkboard allow numerous possible letter combinations, some of which convey functional or meaningful information and most of which do not.
To demonstrate that the magnetic forces do not dictate any specific letter sequence, I arranged and rearranged the letters on the board to show that they have perfect physical freedom to spell other messages or mere gibberish. I would further note that there are no differential forces of attraction at work to explain why one letter sticks to the chalkboard at one location rather than another. I then pointed out that the same is true of DNA: there are no differential forces of attraction between the DNA bases and the sites on the sugar-phosphate backbone. In the case of the magnetic board nothing about the magnetic force acting on the “B” inclines it to attach to the board at the front of the “Biology Rocks!” sequence rather than at the back or middle. Instead, each letter can attach to the chalkboard at any location, just as any one of the nucleotide bases can attach to any sugar molecule along the sugar-phosphate backbone of DNA. Forces of attraction (N-glycosidic bonds) do explain why the bases in DNA attach to the backbone of the molecules, but they do not explain why any given nucleotide base attaches to the molecule at one site rather than another. Nor, given the absence of chemical bonds between the bases, do any other bonding affinities or chemical forces internal to the molecule explain the origin of DNA base sequencing.
I later learned that Kenyon already had reckoned with these same stubborn facts of molecular biology and reached the same conclusion about the futility of explaining the arrangement of DNA bases by reference to internal bonding affinities. The properties of the building blocks of DNA simply do not make a particular gene, let alone life as we know it, inevitable. Yet the opposite claim is often made by self-organizational theorists, albeit without much specificity. De Duve states, for example, that “the processes that generated life” were “highly deterministic,” making life as we know it “inevitable,” given “the conditions that existed on the prebiotic earth.”21 Yet imagine the most favorable prebiotic conditions. Imagine a pool of all four DNA bases and all necessary sugars and phosphates. Would any particular genetic sequence inevitably arise? Given all necessary monomers, would any particular functional protein or gene, let alone a specific genetic code, replication system, or signal transduction circuitry, inevitably arise? Clearly not.
The most obvious place to look for self-organizing properties to explain the origin of genetic information is in the constituent parts (the monomers) of the molecules that carry that information; but biochemistry makes clear that forces of attraction between the bases in DNA do not explain the specific sequences in these large information-bearing molecules. Because the same is true of RNA, researchers who speculate that life began in a self-organizing RNA world also must confront another sequencing problem,22 in particular, the problem of explaining how information in a functioning RNA molecule could have first arisen in the absence of differential forces of chemical attraction between the bases in RNA.23
The Mystery of the Code
Recall from Chapter 5 that, in addition to the specified information in nucleic acids and proteins, origin-of-life researchers need to account for the origin of the integrated complexity of the gene-expression and-translation system. Recall also that the gene-expression system not only utilizes the digital information inscribed along the spine of the DNA molecule (the genetic text); it also depends on the genetic code or translation system imbedded in the tRNA molecule (along with its associated synthetase proteins). (The genetic code is to the genetic information on a strand of DNA as the Morse code is to a specific message received by a telegraph operator.)
It turns out that it is just as difficult to explain the origin of the genetic code by reference to self-organizational bonding affinities as it is to explain the origin of the genetic “text” (the specific sequencing of the DNA bases). The next several paragraphs describe why in some detail. Those unfamiliar with the relevant facts may find it useful to consult the accompanying figure (Figure 11.3) or to skip ahead and pick up the main thread of the argument beginning with the heading “The Necessity of Freedom.”
Self-organizational theories have failed to explain the origin of the genetic code for several reasons. First, to explain the origin of the genetic code, scientists need to explain the origin of the precise set of correspondences between specific nucleotide triplets in DNA (or codons on the messenger RNA) and specific amino acids (carried by transfer RNA). Yet molecular biologists have failed to find any significant chemical interaction between the codons on mRNA (or the anticodons on tRNA) and the amino acids on the acceptor arm of tRNA to which the codons correspond. This means that forces of chemical attraction between amino acids and these groups of bases do not explain the correspondences that constitute the genetic code.
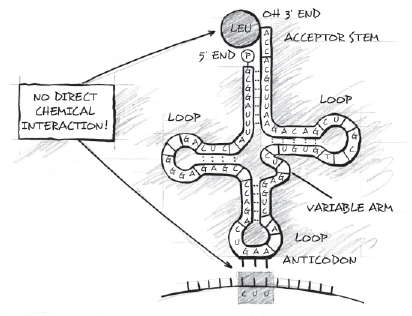
Figure 11.3. The transfer-RNA molecule showing the anticodon on one end of the molecule and an attached amino acid on the other. Notice that there is no direct chemical interaction between the amino acid and the nucleotide codon that specifies it.
Instead, the mRNA codon binds not to the amino acid directly, but to the anticodon triplet on the tRNA molecule. Moreover, the anti-codon triplet and amino acid are situated at opposite ends of tRNA. They do not interact chemically in any direct way. Although amino acids do interact chemically with a nucleotide triplet at the 3' acceptor end of the tRNA molecule, the triplet remains the same in all twenty tRNA molecules, meaning the bonds there do not display any differential affinities that could explain the differing amino-acid assignments that constitute the code. All twenty tRNA molecules have the same final triplet of bases (ACC) at the 3' arm where their amino acids attach. Since all twenty amino acids in all twenty tRNA molecules attach to the same nucleotide sequence, the properties of that nucleotide sequence clearly do not determine which amino acids attach and which do not. The nucleotide sequence is indifferent to which amino acid binds to it (just as the sugar-phosphate backbone in DNA is indifferent to which nucleotide base binds to it). All twenty triplets are acceptable; none is preferred.
Thus, chemical affinities between nucleotide codons and amino acids do not determine the correspondences between codons and amino acids that define the genetic code. From the standpoint of the properties of the constituents that comprise the code, the code is physically and chemically arbitrary. All possible codes are equally likely; none is favored chemically.
Moreover, the discovery of seventeen variant genetic codes has put to rest any doubt about this.24 The existence of many separate codes (multiple sets of codon–amino acid assignments) in different microorganisms indicates that the chemical properties of the relevant monomers allow more than a single set of codon–amino acid assignments. The conclusion is straightforward: the chemical properties of amino acids and nucleotides do not determine a single universal genetic code; since there is not just one code, “it” cannot be inevitable.
Instead, scientists now know the codon–amino acid relationships that define the code are established and mediated by the catalytic action of some twenty separate proteins, the so-called aminoacyl-tRNA synthetases (one for each tRNA anticodon and amino-acid pair). Each of these proteins recognizes a specific amino acid and the specific tRNA with its corresponding anticodon and helps attach the appropriate amino acid to that tRNA molecule. Thus, instead of the code reducing to a simple set of chemical affinities between a small number of monomers, biochemists have found a functionally interdependent system of highly specific biopolymers, including mRNA, twenty specific tRNAs, and twenty specific synthetase proteins, each of which is itself constructed via information encoded on the very DNA that it helps to decode. But such integrated complexity was just what needed explanation in the first place. The attempt to explain one part of the integrated complexity of the gene-expression system, namely, the genetic code, by reference to simple chemical affinities leads not to simple rules of chemical attraction, but instead to an integrated system of large molecular components. One aspect of the DNA enigma leads to another.
Certainly, the chemical interactions between the functional polymers in this complex translation system proceed deterministically. But to explain how a windmill or an operating system or a genetic code works is one thing; to explain how any of them originated is quite another. To claim that deterministic chemical affinities made the origin of this system inevitable lacks empirical foundation. Given a pool of the bases necessary to tRNA and mRNA, given all necessary sugars and phosphates and all twenty amino acids used in proteins, would the molecules comprising the current translation system, let alone any particular genetic code, have had to arise? Indeed, would even a single synthetase have had to arise from a pool of all the necessary amino acids? Again, clearly not.
As origin-of-life biochemists have taught us, monomers are “building blocks.” And like the building blocks that masons use, molecular building blocks can be arranged and rearranged in innumerable ways. The properties of stone blocks do not determine their arrangement in the construction of buildings. Similarly, the properties of biological building blocks do not determine the arrangement of monomers in functional DNA, RNA, or proteins. Nor do they determine the correspondences between DNA bases and the amino acids that constitute the genetic code. Instead, the chemical properties of the building blocks of these molecules allow a vast ensemble of possible configurations and associations, the overwhelming majority of which would have no biological function. Thus, functional genes and proteins are no more inevitable, given the properties of their “building blocks,” than the palace of Versailles was inevitable, given the properties of the bricks and stone used to construct it.
The Necessity of Freedom
As I thought more about the chemical structure of DNA and tRNA, Polanyi’s deeper point about the expression of information requiring chemical indeterminacy, or freedom, came into clearer focus. Polanyi had argued that if “forces of potential energy” determined the arrangement of the bases, “the code-like character” of the molecule “would be effaced by an overwhelming redundancy.”25 I now understood why.
Consider, for example, what would happen if the individual nucleotide bases (A, C, G, T) in the DNA molecule did interact by chemical necessity (along the information-bearing axis of DNA). Suppose that every time adenine (A) occurred in a growing genetic sequence, it attracted cytosine (C) to it,26 which attracted guanine (G), which attracted thymine (T), which attracted adenine (A), and so on. If this were the case, the longitudinal axis of DNA would be peppered with repetitive sequences of ACGT. Rather than being a genetic molecule capable of virtually unlimited novelty and characterized by unpredictable and aperiodic sequences, DNA would contain sequences awash in repetition or redundancy—much like the arrangement of atoms in crystals.
To see why, imagine a group of captive soldiers are told they can type letters to their families at home. The only condition is that they have to begin with the lower case letter a, follow it with the next letter in the alphabet, b, then the next and the next, moving through the entire alphabet, circling back to a at the end and then continuing the process until they have filled in the sheet of typing paper. They are instructed to follow the same process for filling out the front of the envelope. Finally, if they don’t feel up to the task or if they accidentally strike a wrong key, the prison guards will take over the task for them and “do it properly.”
This would, of course, be nothing more than a cruel joke, for the soldiers couldn’t communicate a single bit of information with their letters or even mail the letters to the appropriate addresses—all because the content of the letters was inevitable, strictly governed by the lawlike algorithm forced on them by the prison guards. In the same way, the lawlike forces of chemical necessity produce redundancy (repetition), which reduces the capacity to convey information and express novelty. Instead, information emerges from within an environment marked by indeterminacy, by the freedom to arrange parts in many different ways. As the MIT philosopher Robert Stalnaker puts it, information content “requires contingency.”27
Information theory reveals a deeper reason for this. Recall that classical information theory equates the reduction of uncertainty with the transmission of information, whether specified or unspecified. It also equates improbability and information—the more improbable an event, the more information its occurrence conveys. In the case that a law-like physical or chemical process determines that one kind of event will necessarily and predictably follow another, then no uncertainty will be reduced by the occurrence of such a high-probability event. Thus, no information will be conveyed. Philosopher of science Fred Dretske, the author of an influential book on information theory, explains it this way: “As p(si) [the probability of a condition or state of affairs] approaches 1 [i.e., certainty], the amount of information associated with the occurrence of si goes to 0. In the limiting case when the probability of a condition or state of affairs is unity [p(si) = 1], no information is associated with, or generated by, the occurrence of si. This is merely another way to say that no information is generated by the occurrence of events for which there are no possible alternatives.”28
Dretske’s and Polanyi’s observations were decisive: to the extent that forces of attraction among the members of a sequence determine the arrangement of the sequence, the information-carrying capacity of the system will be diminished or effaced by redundancy.29 Bonding affinities, to the extent they exist, inhibit the production of information, because they determine that specific outcomes will follow specific conditions with high probability.30 Information-carrying capacity is maximized, however, when the opposite situation occurs, namely, when chemical conditions allow many improbable outcomes.
Polanyi appreciated this point, but also its converse. He knew that it was precisely because the sequences of bases in DNA were not biochemically determined (or predestined) that the molecule could store and transmit information. Because any nucleotide can follow any other, a vast array of sequences is possible, which allows DNA to encode a vast number of protein functions. As he explains, “It is this physical indeterminacy of the sequence that produces the improbability of occurrence of any particular sequence and thereby enables it to have a meaning—a meaning that has a mathematically determinate information content equal to the numerical improbability of the arrangement.”31
As noted in Chapter 4, the base sequences in DNA not only possess information-carrying capacity as measured by classical Shannon information theory, they also store functionally specified information; they are specified as well as complex. Clearly, however, a sequence cannot be both specified and complex if it is not at least complex. Therefore, self-organizational forces of chemical necessity, which produce redundant order and preclude complexity, preclude the generation of specified complexity (or specified information) as well. Lawlike chemical forces do not generate complex sequences. Thus, they cannot be invoked to explain the origin of information, whether specified or otherwise.
Conclusion
At a small private conference in 1993, I had a chance to meet and talk with Kenyon personally for the first time. I learned that he had come to the same conclusion about his theory of “biochemical predestination” as I had. It now seemed clear to both of us that there was a significant, in principle, objection to the very idea that chemical attractions could produce information as opposed to simple redundant order. Indeed, if Kenyon had found that bonding affinities between nucleotide bases in DNA determined their sequencing, he would have also discovered that chemists had been mistaken about DNA’s information-bearing properties. Yet no one doubted DNA’s capacity to store information.
But were there other such theories that could explain what Kenyon’s could not? Self-organizational models emphasizing internal bonding affinities had failed, but perhaps models emphasizing lawlike forces external to DNA would succeed. And although simple algorithms like “repeat ATCG” clearly lacked the capacity to convey biological information, perhaps some far more sophisticated algorithm or some dance of forces between a large group of molecules could cause life (or the information it required) to self-organize. By the early 1990s, some researchers were proposing models of just this kind.