CHAPTER 4
Lean Cloud Capacity Management Strategy
This chapter considers the topic with the following sections:
- Lean application service provider strategy (Section 4.1)
- Lean infrastructure service provider strategies (Section 4.2)
- Full stream optimization (Section 4.3)
Lean focuses on optimizing the whole service delivery chain; to avoid confusions over whether costs and savings should accrue to either the application service provider or the infrastructure service provider organization, we shall consider a vertically integrated service provider enterprise that includes several organizations owning and operating different applications that are all hosted on private cloud infrastructure operated by an internal infrastructure service provider organization (i.e., a private cloud). As all savings in this vertically integrated example accrue to the larger enterprise we shall ignore consideration of how costs and savings should be allocated between application service provider organizations and the underlying infrastructure service provider organization. Actual allocation of costs and savings to organizations across the cloud service delivery chain is certainly an important topic that influences business behaviors and decision making, but this work focuses on technical rather than accounting considerations.
4.1 Lean Application Service Provider Strategy
As discussed in Section 2.5.3: Application Capacity Management and shown in Figure 4.1, each application service provider must assure that sufficient capacity is online and ready to serve user demand 24 hours a day, 365 days a year. Too much online capacity is wasteful and increases costs; too little capacity and users will be turned away or endure poor service quality.
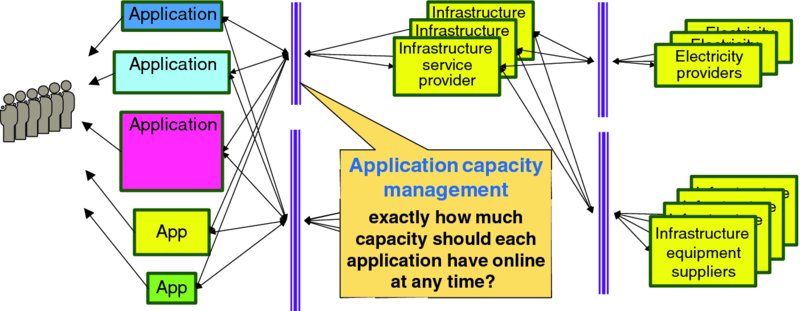
Figure 4.1 Application Service Provider's Capacity Management Problem
Figure 4.2 maps the application service provider's fundamental capacity management problem into the canonical capacity management model of Figure 2.4:
- Some capacity management decision system or process evaluates inputs to decide when an application capacity change action is necessary, such as to immediately add capacity for 100 additional users. Traditionally the capacity management process of Figure 4.2 might be largely manual and repeated every few months. Lean application service providers are likely to evaluate capacity management decisions every few minutes to enable just-in-time online capacity that tracks closely with actual user demand.
- Some capacity action planning/orchestration system or process translates that high-level capacity change order into properly sequenced low-level resource and application configuration change orders, verification actions, synchronizations, and other steps before deeming the application capacity as in service. Application services offered to end users often offer several distinct functions which are implemented via somewhat different suites of application components. For instance, an IP multimedia system (IMS) core delivering voice over LTE (VoLTE) includes a suite of call session control function (CSCF) instances, a subscriber database, various gateway and border elements, application servers, media resource functions, lawful interception elements, management and operations support elements, and so on. Explicit configuration orders are required to adjust online capacity of each element, and growing service capacity of the VoLTE IMS core requires growing several elements in concert. The capacity planning and orchestration element in the decision and planning function of Figure 4.2 would expand a high-level capacity decision, like increase service capacity by 10,000 busy hour call attempts to a tranche of specific configuration change orders for all interrelated elements in the target IMS service core that are necessary to properly grow aggregate online service capacity by the required amount.
- Various configuration change mechanisms actually fulfill the required actions to realize the ordered capacity change.
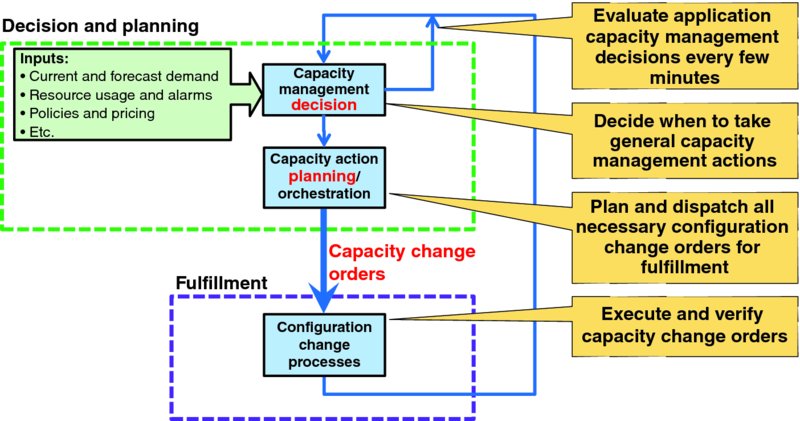
Figure 4.2 Canonical Framing of Application Capacity Management Problem
Figure 4.3 narrows the input–output view of Figure 4.1 to focus on a single application. As application service providers will often operate several instances of each application type in different data centers for business continuity, user service quality and other reasons, Figure 4.3 shows four instances of the target application placed into four geographically distributed cloud data centers. The key cloud characteristic of multi-tenancy enables each of those application service provider organizations to focus on best serving the needs of their end users, independent of the aspirations and actions of other application service providers who happen to share the underlying infrastructure resources.
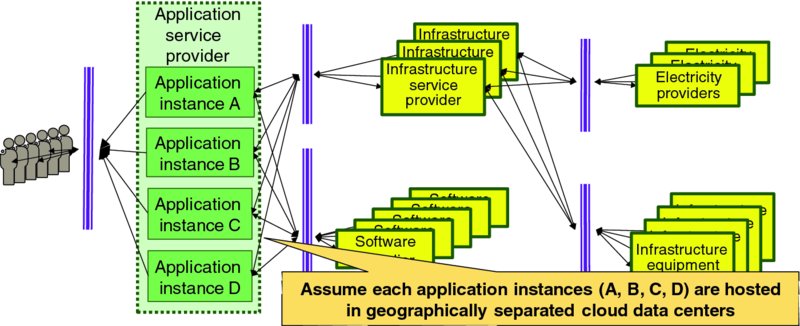
Figure 4.3 Framing the Canonical Cloud Service Delivery Chain
Figure 4.4 highlights four highest-level principles that drive lean application capacity management by an application service provider:
- Pay-as-you-use licensing of sourced software – lean application capacity management assures that the application service provider's infrastructure expense tracks with user demand; pay-as-you-use licensing of sourced software enables another significant expense item to also track with user demand. Shifting the application service provider's business model so that more of their costs track with user demand encourages rapid service innovation and application agility because it lowers the application service provider's financial risk of unsuccessful offerings. Note that just as physical components or goods ordered just in time by manufacturers or retailers have somewhat higher unit cost than when items are ordered in large lots, per user costs with pay-as-you-use arrangements are likely to be somewhat higher than licenses are ordered in large lots.
- Leverage platform-as-a-service functional components, like database as a service, rather than selecting, procuring, installing, operating and maintaining all of the functional components required by the application service. Integrating fully operational functional components offered by some cloud service provider can directly shorten the time to bring a new service to market as well as improving quality and value by leveraging a specialist organization to operated, administer and maintain that functional component.
- Frequent, smaller resource capacity management requests enable the online application capacity to track closely with demand.
- Automation and self-service by end users – embracing application lifecycle automation and self-service by end users enables application capacity to scale up and down with minimal impact of the application service provider's staffing plan. Ideally, the application service provider's operations, administration, maintenance and provisioning (OAM&P) workload is largely driven by the number of application instances rather than by the number of users, so once the application service provider has staffed to monitor and operate, say, a handful geographically separated application instances, the administrative workload should only grow modestly as the number of users served by those instances ramps from 200 to 2000 to 20,000 to 200,000.
- Intelligent user workload placement enables the application service provider to balance user service quality against total cost for the organization by appropriately respecting infrastructure demand management requests.
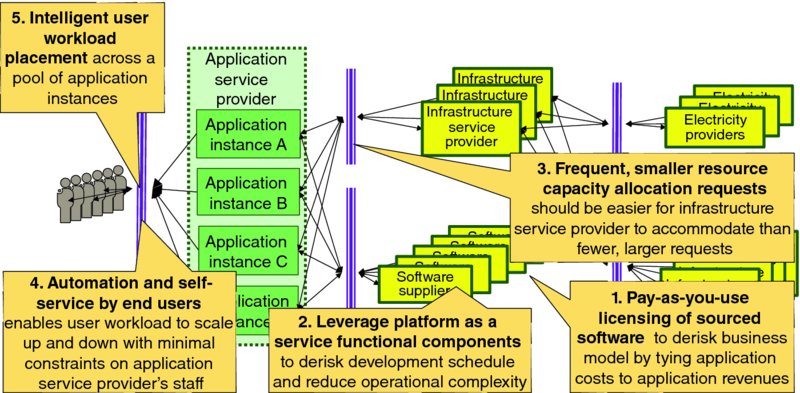
Figure 4.4 Lean Application Capacity Management Considerations
Details and subtleties which are considered in the following sections:
- User workload placement (Section 4.1.1)
- Application performance management (Section 4.1.2)
4.1.1 User Workload Placement
The concept of workload placement was introduced in Section 2.5.3.3: Redistribute Workload between Application Instances. Figure 4.5 visualizes the user workload placement problem in the context of our canonical cloud service delivery chain of Figure 4.3.
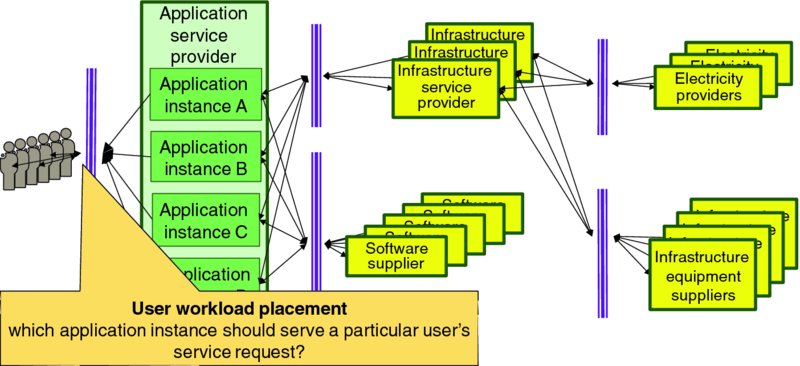
Figure 4.5 User Workload Placement
User workload placement policies are set by application service providers, but may be implemented by network or infrastructure mechanisms like DNS or SDN. The application service provider's workload placement policy is likely to be driven by some or all of the following factors:
- Application instance availability – user workload should not be directed to an application instance that is unavailable due to planned or unplanned service outage.
- Spare online application capacity – user workload should not be directed to an application instance that has insufficient spare online capacity to serve the new user – as well as existing users – with acceptable service quality.
- Infrastructure demand management policy – user workload should not be directed to application instances hosted in cloud data centers with voluntary or mandatory demand management mechanisms engaged.
- Quality of experience considerations – different applications have different sensitivities to the physical distance between the end user and the cloud data center hosting the target application instance. While end users should experience the lowest incremental transport latency when served from the closest application instance, a more geographically distant application instance might be performing better so that the end user's quality of experience would be better if they were served by a more distant application instance.
- Available network throughput – availability of high-quality network bandwidth between the end user and the target data center should be considered. If insufficient network bandwidth is likely to be available to consistently deliver packets between the end user and the target data center with low packet loss, latency, and jitter then a different data center might be a better choice.
- Software release management plans and actions – software updates of cloud-based applications are likely to be more frequent than for traditionally deployed applications with dedicated hardware in part because elastic infrastructure capacity can lower the complexity and user service risk. Thus, placement decisions might be influenced by the status of software release management actions. For instance, workload placement mechanisms may limit the portion of users placed onto a canary testing software release until the release's quality has been validated. After the release is deemed nontoxic and suitable for general use, the workload placement mechanism can migrate user traffic from old release instances to new release instances.
- Infrastructure power management plan – to minimize infrastructure power consumption, infrastructure service providers may drain application workloads from some infrastructure equipment and gracefully migrate it to other infrastructure elements. Application workload placement decisions may consider the infrastructure service provider's power management plan to minimize the user service impact of gracefully decommitting (powering-off) infrastructure capacity during off-peak periods, especially if infrastructure usage pricing rewards them with discounts for embracing infrastructure power management arrangements.
4.1.2 Application Performance Management
Section 2.3: Performance Management proposed that performance management assures that user demand below an application's configured capacity is served with acceptable quality. Application performance management thus focuses on detecting and mitigating situations in which an application's end users fail to enjoy acceptable service quality when the target application instance is operating at or below its nominal online capacity rating. Note that application impact of scheduling delays, resource curtailment, and/or mandatory demand management actions should rapidly become visible to the application performance management system, so those application performance degradations should be marked as such and actions taken by the application service provider to mitigate user service impact that will not conflict with the infrastructure service provider's demand management actions or creating unnecessary infrastructure trouble tickets. Detecting and localizing application performance management problems is beyond the scope of this work, however the following possible corrective actions triggered by application performance management activities may be executed by capacity management mechanisms:
- User workload placement (Section 4.1.1) might direct user traffic to other application instances to lighten the workload on the impaired application instance.
- Application capacity decision and planning processes might grow capacity of the impaired application instance or of another application capacity instance not currently affected by infrastructure service provider demand management actions.
- Application demand management techniques (Section 7.2) might be appro- priate.
4.2 Lean Infrastructure Service Provider Strategies
As discussed in Section 2.5: Three Cloud Capacity Management Problems and illustrated in Figure 4.6, infrastructure service providers have two fundamental capacity-related problems:
- Physical resource capacity management – exactly how much infrastructure equipment is deployed to each data center at any time. Figure 4.7 frames the physical resource capacity management problem in the canonical capacity management model of Figure 2.4. This topic is considered in Section 4.2.1: Physical Resource Capacity Management.
- Virtual resource capacity management – exactly how much infrastructure equipment should be powered on at any time. Direct electric power consumption by physical infrastructure elements that are powered on, as well as indirect expenses for removing waste heat produced by that power dissipation via air conditioning systems, is a significant variable cost for infrastructure service providers. Appropriate unit commitment algorithms, together with intelligent resource placement, migration and demand management actions by virtual resource capacity management mechanisms should enable infrastructure service providers to decommit at least some excess online infrastructure capacity during off-peak periods. This topic is considered in detail in Chapter 9: Lean Infrastructure Commitment.
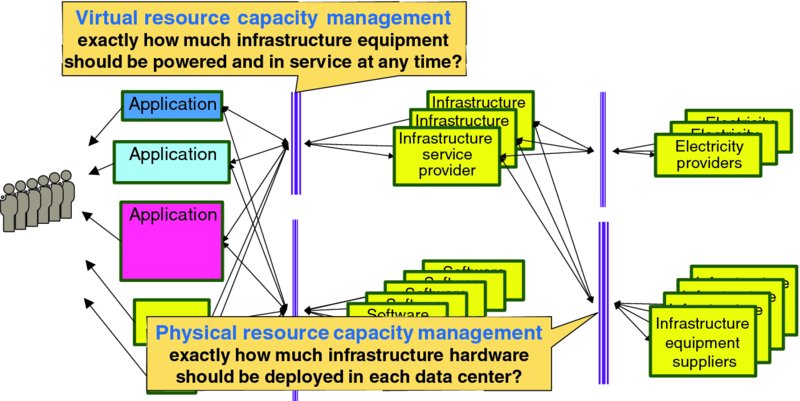
Figure 4.6 Infrastructure Service Provider Capacity Management Problems
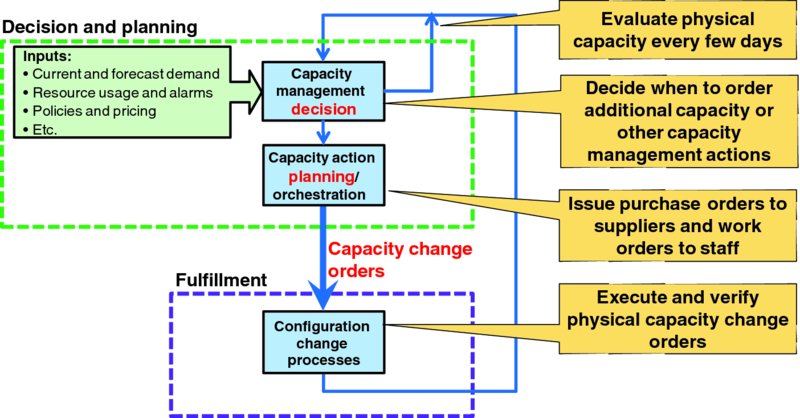
Figure 4.7 Canonical Framing of Physical Resource Capacity Management Problem
At the highest level, the principles that drive lean cloud capacity management can be considered from both the perspective of the infrastructure service provider and from the perspective of application service providers. Figure 4.8 highlights four high-level principles that drive lean infrastructure capacity management:
- Frequent, smaller physical infrastructure capacity orders – while construction of data centers has a long lead time associated with approvals, construction, and installation of power, cooling and other facilities and systems, the commercial off the shelf (COTS) server, storage, and networking gear that directly serves application instances can often be delivered and installed in cloud data centers with much shorter lead times. In addition, server, storage, and networking gear can often be economically deployed in modest increments of capacity, such as by the server (e.g., as discrete rack mounted server units), by the rack of equipment, or even by the shipping container for warehouse scale cloud data centers, rather than fully equipping a cloud data center from day 1. Furthermore, Moore's Law and the relentless pace of technology improvement assures that the cost–performance characteristics of server, storage, and networking gear will improve from quarter to quarter and year to year. Since the same amount of capital will buy more throughput and performance months from now than it will today, one obtains better value by deferring infrastructure purchases until the capacity is needed. Making purchase and deployment decisions more demand driven also reduces the risk that suboptimal equipment will be purchased and that it will then be placed into a suboptimal data center to serve application service provider demand.
- Infrastructure commitment management assures that sufficient physical infrastructure is committed to online service to cover immediate working and reserve capacity needs without wasting electricity on powering equipment and expelling the waste heat to support excess online physical infrastructure capacity. This topic is covered in Chapter 9: Lean Infrastructure Commitment.
- Smaller, more frequent resource allocation and release events with clear grade-of-service expectation simplifies virtual resource management and minimizes demand bullwhip1 compared to larger, less frequent resource allocation and release events.
- Resource scheduling and curtailment, and direct control and voluntary demand management – explicit and honest communications with application service providers about each application component's tolerance for resource scheduling impairments (e.g., during live migration) and resource curtailment, direct control demand management, and voluntary demand management during periods of high demand enables the infrastructure service provider to deliver acceptable service quality to all applications at the lowest total cost for the vertically integrated organization. This topic is covered in Chapter 7: Lean Demand Management.
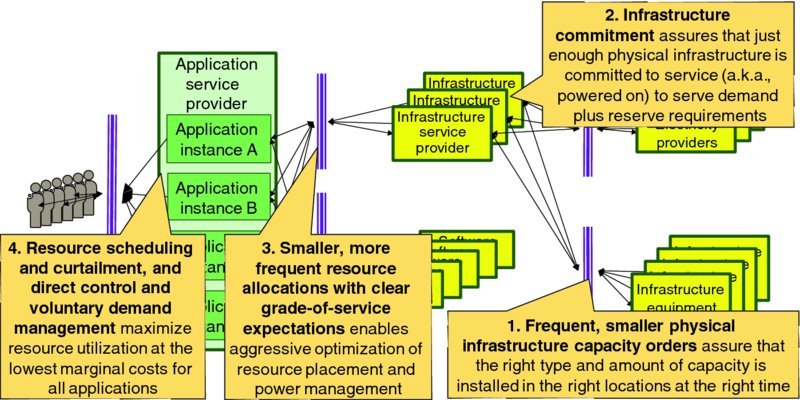
Figure 4.8 Lean Infrastructure Capacity Management Considerations
4.2.1 Physical Resource Capacity Management
Lean infrastructure service providers will install enough physical infrastructure capacity in each data center to serve peak demand forecast for somewhat longer than (perhaps twice) the physical infrastructure capacity fulfillment lead time interval, plus a safety margin. By focusing on efficient processing of smaller and more frequent physical infrastructure capacity fulfillment actions the infrastructure service provider can better deliver demand driven infrastructure capacity. Physical resource capacity management considers:
- Demand for virtual resource capacity – virtual resources are underpinned by physical resource capacity, and thus peak virtual resource demand drives physical equipment needs.
- Scheduling planned maintenance actions for physical infrastructure – planned downtime for physical infrastructure elements to apply software, firmware and hardware patches, updates, upgrades, and retrofits and perform preventive maintenance actions is an essential aspect of assuring highly reliable infrastructure service. As planned maintenance actions will temporarily make target elements unavailable and thus reduce to pool of infrastructure that can be committed to serve load, these actions should be scheduled during lower usage periods.
- Repair policy for physical infrastructure – infrastructure service provider policy will drive whether infrastructure equipment failures are fixed as soon as possible (i.e., on an emergency basis), or whether repairs are scheduled as a planned maintenance action, or whether the failed hardware is retired in place and not repaired so that failed capacity is gone forever.
- Retirement policy for physical infrastructure – electronic equipment like servers and hard disk drives wear out for well-known physical reasons. Wear out appears to infrastructure service providers as an increasing rate of hardware failures after the equipment's designed service lifetime is reached. Given Moore's Law and the pace of technology improvement, it often makes more business sense to schedule retirement of equipment shortly before wear out failures become epidemic to minimize costs associated with hardware failures. Infrastructure service providers should assure that all data written to persistent storage devices has been permanently erased (a.k.a., shredded) before equipment is retired so that no application service provider or end user data is inadvertently divulged.
Selection of suppliers and exact equipment models of physical infrastructure purchased by the infrastructure service provider are beyond the scope of capacity management. Note that every new generation of technology – or cost saving design change – creates a risk of incompatible changes that will impact execution of some application software. While virtualization technology can mitigate much of this risk, infrastructure service providers must carefully evaluate physical infrastructure elements before introducing them to production environments to avoid troubling application service providers with incompatible resources. Minimizing the variety of infrastructure equipment configuration and the number of infrastructure suppliers minimizes complexity overhead (Section 3.3.11).
4.3 Full Stream Optimization
Lean cloud capacity management is fundamentally a complexity versus reward tradeoff that application and infrastructure service provider organizations must decide. Balancing these tradeoffs is challenging because both the accountabilities and impacts, and costs and benefits can be somewhat disconnected between the application and infrastructure organization. For example:
- More aggressive lean infrastructure commitment (Chapter 9) can reduce infrastructure service provider's expenses and reduce waste heat (Section 3.3.14), but this impacts application service providers with waste associated with workload migration (Section 3.3.10).
- More aggressive lean demand management (Chapter 7) by the infrastructure service provider can reduce their waste associated with excess physical infrastructure capacity (Section 3.3.4), but this forces application service providers to mitigate user service impact of the infrastructure service provider's demand management actions by accepting additional complexity overhead (Section 3.3.11) and perhaps workload migration (Section 3.3.10).
Private cloud deployment means that both the application service providers and the infrastructure service provider are in the same larger enterprise, so these full stream optimizations can be evaluated by considering total costs to the larger enterprise. To successfully optimize costs across the organization's “full” service delivery stream, it is important for the organization's accounting rules to advantage overall cost reductions to the larger organization (e.g., the parent corporation) over merely pushing costs from one department to another. The enterprise's cost structure, accounting rules, and other factors should enable methodical analysis and optimization to minimize full stream costs.
Public clouds offer explicit market-based pricing of infrastructure services and resources to application service providers. As cloud infrastructure and associated management and orchestration is a complex service, pricing models may not transparently reflect all of the total costs for both the public cloud operator (i.e., infrastructure service provider) and the cloud consumer (i.e., application service provider). Distortions between the relative costs to the infrastructure service provider and the price charged to application service providers can encourage application service providers to overconsume some resources, and may encourage infrastructure service providers to underdeliver other services. The practical impact of price distortions are familiar to many wireline internet users who pay internet service providers a flat rate for all-you-can-eat internet service with a high nominal throughput (e.g., 10, 25, 50, or even 100 megabits per second), but since the internet service provider sees little direct revenue benefit to building out their infrastructure to maximize network usage the service provider is likely to rely more on relatively inexpensive demand management techniques (e.g., throttling throughput) rather than make expensive investments to build out network capacity. In contrast, when internet service is priced on actual usage (as wireless data services often are), then the service provider has a strong financial incentive to build out network capacity to serve all demand, and thereby maximize their revenue rather than throttling access speeds which risks customer dissatisfaction and churn. Also note that usage-based pricing alters consumers' patterns of demand compared to flat rate all-you-can-eat pricing.
Cloud is still an evolving business, and pricing models will continue to evolve as the business matures and the market fragments. It is thus difficult to make medium- or long-term predictions about the relative prices of different infrastructure resources which makes aggressive optimization of an application's capacity management architecture awkward. For instance, are two 2 virtual CPU (vCPU) virtual machines likely to have the same price as one 4 virtual CPU virtual machine, or will there be some “volume” discount for buying a larger unit of capacity? Will there be transaction costs associated with allocating or deleting a virtual machine instance that alters the total cost of two 2 vCPU virtual machines rather than one 4 vCPU virtual machine? Thus, application service providers should avoid locking-in to a particular infrastructure service provider so that they are not trapped if infrastructure pricing models become untenable for the application service provider's business case. Until these and myriad other pricing details stabilize for public cloud resources, application service providers may be forced to minimize their capacity-related costs based on the pricing model of the public cloud service provider they have selected, and tweak their capacity management policies as those infrastructure pricing models change.
Common technology components like databases and load balancers can be offered “as-a-service” to application service providers to boost full stream operational efficiencies. Rather than having a handful of application service providers invest resources to deploy, operate, and maintain separate database instances to support their overall solution architectures, a platform-as-a-service organization can deploy, operate, and maintain a multi-tenant database that multiple organizations can share. By sharing a common as-a-service technology component, full stream costs for application service providers can be reduced.
4.4 Chapter Review
- ✓ Application service providers (cloud service customers) should focus on application capacity management to serve their end users; cloud infrastructure service providers should focus on both virtual and physical resource capacity management to serve their cloud service customers.
- ✓ Lean application service providers should consider:
- Pay-as-you-use licensing of sourced software to re-risk the cloud service customer's business model by tying application licensing costs to application revenues.
- Leverage platform-as-a-service functional components to de-risk development schedules and reduce operational complexity.
- Frequent, smaller resource capacity allocation requests both enable online capacity to track closer to actual demand and are easier for cloud infrastructure service providers to accommodate.
- Automation and self-service by end users enables user workload to scale up and down with minimal demands and constraints on cloud service provider's staff.
- Intelligent user workload placement across pools of online application capacity enable better user service quality and more efficient resource utilization.
- ✓ Lean cloud infrastructure service providers should consider:
- Frequent, smaller physical infrastructure capacity orders assure that the right type of physical equipment is installed in the right quantity in the right physical locations to optimally serve aggregate cloud service customer demand.
- Infrastructure commitment assures that just enough physical infrastructure is online (a.k.a, committed) to serve cloud service customers' needs.
- Smaller, more frequent resource allocations with clear grade-of- service expectations enable cloud service provider to make optimal resource placement and aggressive operational decisions to minimize waste.
- Resource scheduling, voluntary demand management, infrastructure curtailment, and mandatory demand management to yield lowest marginal costs for infrastructure service provider and all of their cloud service customers.
- ✓ True partnership between cloud service customers and cloud infrastructure service providers can squeeze waste out of the service delivery chain to improve overall efficiency rather than shifting or hiding costs across the cloud service delivery chain.