CHAPTER 6
Application Capacity Management as an Inventory Management Problem
6.1 The Application Capacity Management Service Delivery Chain
Figure 6.1 visualizes the production chain of application service delivered to end users: software is hosted on physical infrastructure which is powered by electricity; the application service is monitored by application service provider's OAMP systems and staff; and the resulting service is delivered to end users across the Internet.
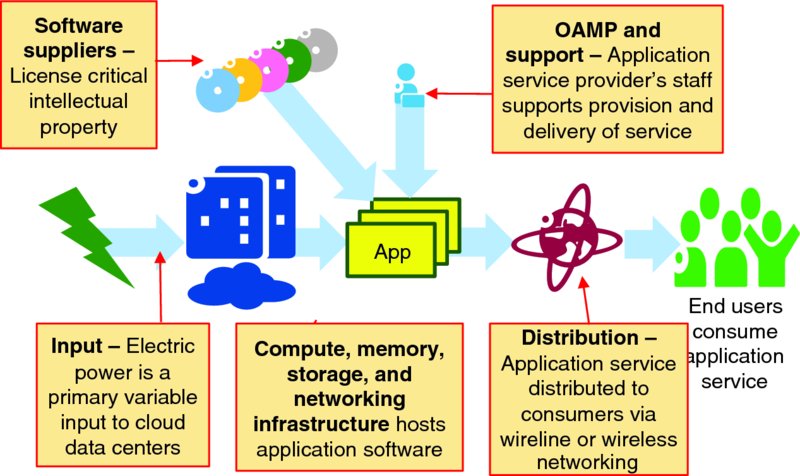
Figure 6.1 Application Service as a Production Chain
Figure 6.2 highlights how application service providers are challenged to have sufficient inventory of service capacity online to meet instantaneous customer demand without wasting money on carrying excess inventory of compute, memory, storage, and infrastructure hosting unneeded online service capacity. Note the similarities of the application capacity management problem to the newsvendor problem1: instead of deciding how many of each day's newspapers to purchase, the application service provider must decide how much application capacity to hold online for the next few minutes.
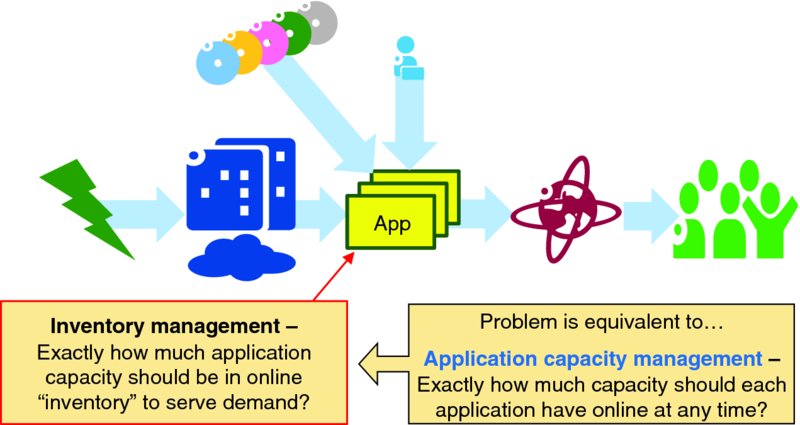
Figure 6.2 Application Capacity Management as an Inventory Management Problem
This chapter analyzes application capacity management as an inventory management problem to gain deeper understanding of the fundamental business, operational, and technical considerations in three parts:
- Traditional application service production chain (Section 6.2) – reviews the factors that traditionally drove application service providers to adopt a supply-driven or push model of capacity management.
- Elasticity and demand-driven capacity management (Section 6.3) – considers how cloud eliminates the factors that drove adoption of supply-driven, push capacity management and enable application service providers to adopt more agile demand-driven, pull-capacity management models.
- Application service as retail analog (Section 6.4) – there are significant parallels between running an application service business and operating a number of trendy retail stores. Thinking about intangible application capacity as tangible retail merchandise that must be managed as inventory is a useful way to identify important aspects of application capacity management.
6.2 Traditional Application Service Production Chain
Figure 6.1 visualizes application service production chain. Walking “up” the service production chain from end user consumption shows the following links:
- End users consume application service via some device like a smartphone, laptop, connected car, intelligent thermostat, etc. Often the end users pay application service providers directly for the service, such as to stream a video or download an e-book. In other cases an organization, such as a corporation or advertiser, pays the application service provider for service delivered to end users.
- Wireline or wireless access and wide area networking services deliver application service to end users. Often most or all of the networked delivery costs are covered by the end user or organization as part of their network access service.
- Application service is actually produced by appropriately integrating:
- Software licensed from suppliers and/or developed by the application service provider staff.
- Compute, memory, storage, and networking resources in some data center that hosts application software and which is operated by infrastructure service provider staff.
- Data center that houses the physical compute, memory, storage, and networking hardware, and provides power, environmental control (thermal and humidity management), network connectivity, and physical security.
- Bespoke software that integrates sourced software, platform-as-a-service functional components, user facing on-demand self-service systems, the application service provider's operations, and business support systems with the underlying virtual resources and automated lifecycle management offered by the infrastructure as a service provider.
- Operations, administration, maintenance and provisioning systems, policies and staff to support application software, end users and general interworking issues.
End users generally prefer applications that are instantly available on demand (e.g., like electric light available at the flip of a switch) rather than, say, pizza that they expect to wait 15 to 30 minutes for. After all, how many seconds will you wait for a webpage to load before simply surfing to some competitor's site? Characteristics of traditional application deployment models led application service providers to adopt a supply-driven model in which they would initially deploy a large supply (think inventory) of application capacity and wait for demand to materialize. This supply-driven (a.k.a., “push”) deployment model was often sensible because:
- Application capacity had a long lead time, because physical compute, memory, storage, and networking hardware had to be delivered, installed, and brought into service, and the lead time was often weeks or months.
- Transaction costs of capacity fulfillment orders was high because processes were largely manual and physical logistics was often required.
- The most cost-effective hardware capacity was offered in moderate to large increments of capacity, such as a full chassis or rack mounted server unit.
Thus, application service providers would often engineer to peak forecast demand, plus a safety margin, and then focus on minimizing the cost per unit of service capacity for the peak plus safety margin capacity. After having brought all of that application capacity into service, the application service provider would often unsuccessfully struggle to generate customer demand to utilize all the deployed service capacity. Traditional application deployment on dedicated hardware often made it commercially impractical to salvage excess capacity and repurpose it for some other application, so once installed, excess application capacity was often stranded as a sunk cost to the application service provider. However, if the application service provider underestimated application demand and thus deployed too little traditional capacity, then the lead time of weeks or months to grow capacity meant that unforecast demand for an application beyond deployed capacity had to be made to wait or be turned away outright, thereby creating an opportunity for competitors to seize market share.
Thus, application service providers would routinely make a high-stake business gamble about the level of demand for an application several months or quarters in advance and then invest to deploy that much capacity (often plus a safety margin). If they guessed too low then they risked turning away business and market share; if they guessed too high then they would be carrying capacity that would never generate revenue. Application service providers thus had the traditional supply-driven inventory problem: they piled capacity high so they could sell it cheap, but if customer demand did not materialize then they were left with a potentially huge pile of unsold inventory to essentially scrap. As a result, application service providers were more reluctant to deploy new and unproven services and applications because the upfront investments in capacity might be lost if the service was not successful.
6.3 Elasticity and Demand-Driven Capacity Management
The essential characteristics of cloud computing largely nullify the factors from the previous section that traditionally drove application service providers to take a supply-driven approach to their inventory of service capacity. Consider those factors one at a time:
- Assumption: deploying application capacity has a long lead time – the essential cloud characteristic of rapid elasticity stipulates “resources can be rapidly and elastically adjusted, in some cases automatically, to quickly increase or decrease resources” (ISO/IEC 17788). Cloud infrastructure service providers can often deliver virtual resources in minutes or less.
- Assumption: the transaction costs of capacity fulfillment actions are high – the essential cloud characteristic of on-demand self-service stipulates “cloud service customer can provision computing capabilities, as needed, automatically or with minimal interaction with the cloud service provider” (ISO/IEC 17788). By automating capacity decision, planning and fulfillment actions, the transaction costs of capacity management actions can be dramatically lower than for traditional deployments.
- Assumption: the most cost-effective resource capacity is offered in moderate to large increments of capacity – the virtual resources offered by infrastructure service providers to application service providers are routinely made available in much smaller units of capacity than the native hardware offers. Consider that a thermal generating plant from Chapter 5: Electric Power Generation as Cloud Infrastructure Analog offers far more power than any residential customer could possibly consume, so the electric power company sells vastly smaller unit of electricity; likewise, a warehouse scale cloud data center filled with shipping containers packed with thousands of servers offers far more compute power than the majority of application service providers wish to consume, so the infrastructure service provider will offer those resources in a small set of popular sizes for short or long periods of time. For example, rather than having to grow capacity of an application software component one physical blade at a time which might provide 16 CPU cores of processing capacity, an infrastructure service provider can offer a much smaller unit of capacity virtual machine (e.g., 1, 2, or 4 virtual CPU cores) so that online application capacity can track much closer to demand than with traditional units of physical capacity like blades, servers, or racks of compute, memory, storage, and networking capacity.
- Assumption: it is commercially impractical to salvage and repurpose excess resource capacity – the essential cloud characteristic of rapid elasticity and scalability assures that “resources can be rapidly adjusted to increase or decrease resources” (ISO/IEC 17788). The essential cloud characteristic of measured service means that “the [cloud service] customer may only pay for the resources that they use. From the [cloud service] customers' perspective, cloud computing offers the users value by enabling a switch from a low efficiency asset utilization business model to a high efficiency one” (ISO/IEC 17788). Thus, resources no longer needed by the application service provider can be released and the infrastructure service provider will reassign those resources to other applications.
After discarding these historic assumptions, application service providers can abandon the capital intensive and commercially risky supply-driven capacity/inventory deployment model in favor of a more agile demand-driven capacity/inventory model. Rather than engineering for a peak long-term forecast demand plus a safety margin, a demand-driven model engineers capacity for near-term forecast of cyclical demand, plus a safety margin for random variations, forecasting errors, capacity fulfillment issues, and other contingencies. As cyclical (e.g., daily, weekly, monthly) application demand grows (and eventually shrinks), the application's online capacity grows (and eventually shrinks) with it. Instead of focusing on the lowest cost per unit of application capacity in inventory (which may or may not ever sell), demand-driven capacity deployment focuses on the lowest cost per user actually served.
An application service provider's revenue is generally tied to the user service demand that is actually fulfilled and charged for. By shifting the application service provider's costs of production from a largely fixed capacity-driven approach to a usage-based, demand-driven model de-risks the application service provider's business case by more closely aligning their costs with their revenues. As cloud infrastructure providers enable demand-driven capacity management of the compute, memory, storage, and networking infrastructure – as well as the physical data centers that host that equipment – that supports application services, one naturally considers driving other costs of service production to also track with service demand:
- Licenses for both application and OAMP software – having shifted the application service provider's infrastructure costs for compute, memory, storage, and networking to a usage-based cost model, it becomes commercially desirable for the application service provider to shift the licensing costs for sourced software supporting both production application capacity and associated business, operations and management systems to a usage-based model to align software costs with service usage and thus revenue.
- OAMP staff – infrastructure service providers can grow or shrink the compute, memory, storage, and networking capacity allocated to an application service provider in minutes, and software license fees can track with actual service usage, but human staff supporting operations, administration, maintenance and provisioning cannot easily scale up and down because of the availability of appropriate staff and the investment required to appropriately train them. Aggressive automation of application OAMP activities, including on-demand self-service provisioning by application users themselves, both minimizes OAMP staff as a constraint on elastic application capacity management and lowers the application service provider's variable costs to serve user demand.
6.4 Application Service as Retail Analog
Transforming an application service business from a traditional capacity-driven model to an agile demand-driven model requires a significant shift in the application service provider's policies, practices, and business models. The general nature of this transformation can be understood by considering the parallels between running a retail store and a demand-driven application service business. Instead of delivering application service from cloud data centers over the Internet to end users, imagine that the application service provider is offering some products to customers out of retail stores.
A retailer places stores in optimal locations to serve their target market and then must assure that sufficient inventory is stocked in each store to serve all customer demand (with service level probability, see Section 6.4.3: Service Level). Effectively, the application capacity management problem can be viewed as an inventory management problem, albeit inventory management of a regenerative asset like a hotel room rather than a consumable inventory item like a sweater on a store shelf. To illustrate this point, consider how the following inventory management statements apply equally well to both management of trendy retail stores and application capacity management. The square brackets “[]” give formal definitions of inventory management terminology from Wiley.
- Organizations want to adopt a lean strategy [a business strategy that aims at doing every operation using the least possible resource – people, space, stock, equipment, time, etc.] based on just-in-time [an approach that organizes operations to occur at exactly the time they are needed] inventory [a list of the items held in stock (often taken as being the stock itself)] management to minimize their operating expenses.
- In addition to cycle stock [normal stock used during operations], organizations maintain safety stock [a reserve of materials that is not normally needed, but is held to cover unexpected circumstances] to assure an acceptable end-user service level [a measure of the proportion of customer demand met from stock (or some equivalent measure)].
- Orders [a message from an organization to a supplier requesting a delivery of materials] for new inventory (service capacity) take a finite lead time [the total time between ordering materials and having them delivered and available for use].
Figure 6.3 illustrates the parallel of inventory management by replacing “capacity decision and planning” processes from the canonical capacity management diagram of Figure 2.4 with “inventory management process” and “configuration change process” with suppliers and distributors who fulfill inventory orders. The inputs that the inventory management process uses are slightly different from capacity management decision and planning processes. Both current, historic, and forecast demand, and policies and pricing remain relevant inputs; but instead of resource usage and alarms, the inventory management processes consider their current inventory position.
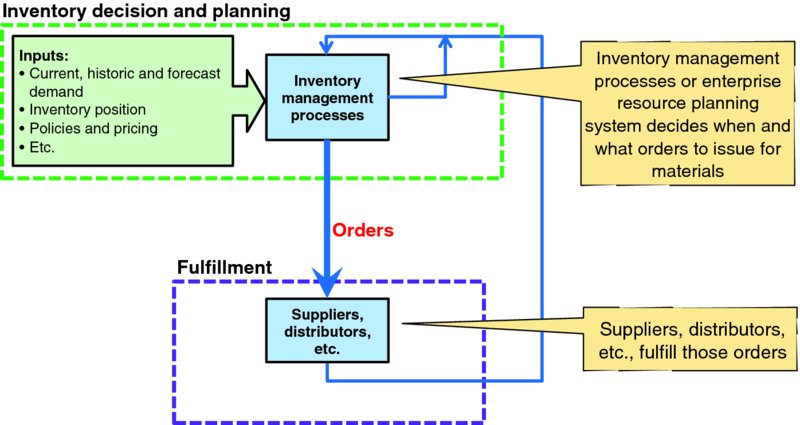
Figure 6.3 Inventory Management in the Canonical Capacity Management Framework
This analogy is explored in the following sections:
- Locational consideration (Section 6.4.1)
- Inventory and capacity (Section 6.4.2)
- Service level (Section 6.4.3)
- Inventory carrying costs (Section 6.4.4)
- Inventory decision, planning, and ordering (Section 6.4.5)
- Agility (Section 6.4.6)
- Changing consumption patterns (Section 6.4.7)
6.4.1 Locational Consideration
The notion of locational marginal value was introduced in Section 5.8: Location of Production Considerations. Different businesses have different locational marginal value sensitivity. For example, coffee shops and convenience stores have high locational sensitivity as few customers will travel very far for those offerings; amusement parks have lower sensitivity to locational marginal value as many parents and children will willingly (if reluctantly) endure a long ride to a big amusement park. Likewise, highly interactive applications with strict real-time responsiveness expectations place a high value in being located physically close to end users, while batch-oriented and offline applications are far less sensitive to the geographic separation between end users and the data center that hosts the application instance that serves them.
6.4.2 Inventory and Capacity
Inventory or stock is often considered either:
- Working or cycle stock (or inventory), defined by Wiley as “normal stock used during operations.” In the context of an application, this is online capacity that is engaged actually serving workload; components dedicated to protecting working capacity (e.g., standby units) are considered safety stock rather than working stock.
- Safety stock (or inventory) is redundant (i.e., standby units, like the spare tire in your car) or spare online capacity to serve surges in workload or protect service following failure. Note that some inventories, such as airline seats and hotel rooms, are managed with nominally negative safety stocks because the conversion rate of reservations to actual demand is often significantly less than 100%.
Demand is defined by Wiley as “the amount of materials wanted by customers,” demand is often called offered workload in the context of application elasticity. Figure 6.4 visualizes cycle stock, safety stock, capacity, and demand for a regenerative asset, like online application capacity.
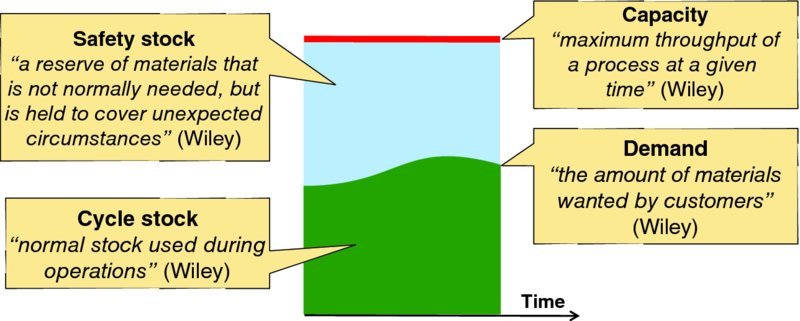
Figure 6.4 Capacity, Demand, and Inventory
6.4.3 Service Level
Service level is defined by Wiley as “a measure of the proportion of customer demand met from stock (or some equivalent measure).” Traditionally, service level is one minus the probability that a users' demand will not be promptly served due to stock out.
In the context of application capacity, service level is related to service accessibility (see Section 1.3.1: Application Service Quality) which is the probability that an attempt to access a service will be successful because sufficient application capacity is available online, as opposed to the application instance being in overload or otherwise unavailable for service. Note that the reliability, latency, and overall quality of the service delivered by the application to the end user is a performance management concern rather than a capacity management concern; after all, if the application and allocated resources are delivering poor service quality, then that is a performance (or service assurance) problem. The root cause of a performance problem could be faulty capacity management, but the service quality problem would be diagnosed via performance or fault management mechanisms rather than via capacity decision, planning, or fulfillment mechanisms.
6.4.4 Inventory Carrying Costs
Cost models for physical infrastructure are mature and well understood to include some or all of the following costs:
- Option costs – costs associated with carrying the “call option” to instantiate (nominally “buy”) a new application instance, such as storing an application image, configuration, and application data in a particular cloud data center. Beyond the cost of options for infrastructure capacity, carrying options for addition software licenses and OAMP capacity may also cost money.
- Start-up costs – costs associated with starting up a new retail store, or instantiating a new application instance. Start-up costs include both the costs to allocate resources and to carry those resources until application capacity is online and ready to serve user demand (when charging shifts to overhead and capacity holding costs).
- Overhead (holding) costs – the ongoing costs for infrastructure resources for pure overhead for management visibility, control, and other functions not associated with serving workload, along with software licensing fees for OAMP system software and staff monitoring those systems.
- Capacity (holding) costs – the ongoing costs for infrastructure resources hosting application service capacity, as well as software licensing fees associated with that capacity.
- Capacity change order cost – each capacity change order has some transactional cost which covers costs for both the application service provider and infrastructure service provider, as well as usage costs for testing new capacity before it is brought into service, or costs for holding capacity while traffic drains away gracefully, etc.
- Shutdown costs – costs associated with gracefully terminating an online application instance, such as holding resources while traffic is being drained and data are flushed to persistent storage.
These prices charged by infrastructure service providers might be discounted based on resource reservations/commitments, purchase volume, time-of-day, day-of-week, or other factors. Note that the cloud business is still immature and actual infrastructure pricing models (e.g., what transactions and resources are separately billed and what are included, and thus “free” to the application service provider) are likely to evolve over time. While public cloud service providers necessarily offer transparent market-based pricing, the cost and pricing models for private cloud infrastructure are not well understood or mature yet.
In addition to direct costs or chargebacks to infrastructure service supplier(s), application service providers may also be subject to indirect costs:
- Lost sales – defined by Wiley as “when customer demand cannot be met, and the customer withdraws their demand (perhaps moving to another supplier).” Lost sales can cause loss of goodwill for impacted users… and perhaps even non-impacted users.
- Shortage costs – defined by Wiley as “costs associated with each shortage (which may be dependent or independent of the amount of shortage or its duration).” These are often framed as liquidated damage penalties for breaching service-level agreements.
- Expedite costs – infrastructure suppliers may charge more for urgent, rushed, expedited, or unplanned resource allocations. If so, then incremental expedite costs should be considered when expediting infrastructure capacity to mitigate an overload “emergency.”
Application service provider's overall objective is similar to what the electric power industry calls economic dispatch, which essentially maps to: operation of application instances to deliver acceptable quality service to end users at the lowest cost, recognizing any operational limits of software, infrastructure, or networking facilities.
6.4.5 Inventory Decision, Planning, and Ordering
Inventory management is a critical factor for a retailer, just as capacity management is a critical factor for an application service provider. Critical order fulfillment characteristics that impact inventory decision and planning for both physical inventory and application capacity are:
- Order lead time (Section 6.4.5.1) – lead time for fulfilling orders is a primary factor that drives inventory management. The longer the lead time, the greater the risk that demand in that interval will change unexpectedly due to unforecast factors. Even if the typical lead time is short, one must consider the maximum lead time when planning inventory levels and orders because one does not always know in advance exactly when an order will be successfully delivered.
- Order completeness (Section 6.4.5.2) – rich end user services are often implemented via suites of interworking applications and components seamlessly communicating across high-quality networking facilities. A single under-configured element in that service chain can create a bottleneck that impacts service quality for at least some users. Thus it is important that capacity changes are reliably completed for all specified events so that the omitted element does not become a (perhaps hard to locate) bottleneck that precludes other service capacity from being fully utilized.
- Order reliability (Section 6.4.5.3) is a risk in the cloud industry today, but may fade as the industry matures… which likely explains why order reliability is not traditionally called out as a critical performance indicator for traditional supply chain management.
There are a number of inventory management models to decide timing and size of orders ranging from ad hoc or rule-of-thumb approaches to more sophisticated safety stock and scientific methods.
6.4.5.1 Order Lead Time
Lead time is defined by Wiley as “the total time between ordering materials and having them delivered and available for use.” Lead time for elastic application capacity growth has four primary components:
- Resource provisioning latency – Resource provisioning latency is the time it takes for the infrastructure service provider to allocate, configure, and initialize requested virtual machine (VM) and other resource instances. This latency can vary significantly across infrastructure-as-a-service implementations, as well as exhibiting statistical variations for a single infrastructure provider (Stadil, 2013). Latency can also vary significantly based on configuration of the requested resource (Mao and Humphrey, 2012).
- Application component initialization latency – After booting the guest OS in a newly provisioned VM instance, the application component software must initialize. The initialization time is driven by the configuration complexity of the application component itself, including how many other application components and other applications the component must access to retrieve and load configuration, credential, and other data and establish necessary sessions, connections, and contexts.
- Testing latency – Testing verifies that newly allocated and configured application components are fully operational and are ready to serve users with acceptable quality. This testing is designed to rapidly detect resource errors such as dead on arrival or misconfigured virtual infrastructure resources, platform, service, or application components. Note that this runtime testing is materially different from background testing such as Simian Army activities because this latency directly impacts the time it takes to fulfill a particular capacity change order.
- Synchronization latency – To assure that consistently high service quality is delivered to end users, critical applications will not normally bring new service capacity online until:
- Inter-application capacity linkages are complete. For example, if additional application logic capacity requires additional DBMS capacity to serve users with acceptable quality, then there is no point in bringing the application logic capacity into service before the necessary DBMS capacity is online.
- New capacity has passed appropriate diagnostics and tests.
- The new capacity is appropriately protected by the application's high availability mechanisms. In other words, critical applications do not create simplex exposure risks by rushing unprotected capacity into production.
The nature of the service provided by the elastically grown component will determine how quickly new capacity can be engaged with user traffic; while components offering stateless, connectionless service can be engaged nearly instantly, components offering stateful and/or connection-oriented service often ramp up with new sessions and service requests rather than engaging pre-existing user sessions/service requests.
The lead time to start up a new application instance is likely to be materially longer from the lead time to add capacity to a preexisting application instance, because more components must be started, more thorough testing is generally prudent, and more elaborate synchronization is required to assure that the application instance is fully operational before user traffic can be safely applied. Lead time to instantiate release updates, upgrades, and retrofits can be materially longer than for ordinary application instance start-up because application configuration and user data might require conversion or migration processing.
Both shrinking application capacity and gracefully shutting down an online application instance also take time to complete, but the time is not in the critical path of user service delivery.
6.4.5.2 Order Completeness
The importance of order completeness is easily understood in the context of traditional manufacturing: an automobile needs both a driver's side rear view mirror and a passenger's side rearview mirror, and one cannot finish building a car without both mirrors. A supplier delivering a partial order with only driver's side mirrors today probably does not meet the automobile manufacturer's business needs because the manufacturer needs a complete order with both passenger's and driver's side mirrors to build cars.
Order completeness has a direct analogy to application capacity management in that complex applications may require that several components be grown simultaneously to increase service capacity, such as growing both processing capacity to directly serve a user and storage capacity to host the users' volatile and persistent work products; providing processing capacity without necessary storage or storage capacity with necessary processing capacity does not permit acceptable service to be delivered to users, so it does not meet the application service provider's business needs.
6.4.5.3 Order Reliability
Infrastructure capacity change orders will occasionally fail outright such as due to resources delivered by the infrastructure service provider being dead on arrival or otherwise inoperable. Thus, application service provider elasticity decision and planning processes must be prepared to mitigate occasional failures of requested capacity change orders. As the industry matures the reliability of capacity fulfillment actions is likely to improve significantly.
6.4.6 Agility
Store owners often strive for an agile portfolio of products where new items (think stock keeping units or SKUs) are trialed with limited inventory. If customer demand materializes, then demand-driven inventory management will increase the stock to serve that demand. If customer demand fails to materialize, then the residual inventory will be disposed of and another new product offering will replace it on the shelf.
Agility for a product retailer is inherently simpler than agility for a service provider because while a retailer must source and stock a new product from a manufacturer or distributor, a service provider often needs to develop, integrate, and test a new service before offering it to end users. Sophisticated application service providers are likely to strive for similar service agility in trialing new service variants and options. Agile development and delivery processes are key to enabling service agility, but elastic scalability of resource capacity is a key enabler. Capacity for popular service variants and options will quickly be ramped up to serve increasing demand; capacity for unpopular offerings will be retired.
6.4.7 Changing Consumption Patterns
Some innovative retailers have succeeded by changing buying patterns of their customers, such as how “big box” retailers enticed customers to purchase previously unheard of quantities of products to gain greater discounts (e.g., 24 rolls of toilet paper or 12 rolls of paper towels in a single retail package). Rapidly elastic capacity undoubtedly creates new opportunities to change – and hopefully expand – users' patterns of service demand, but those innovations are beyond the scope of this paper.
6.5 Chapter Review
- Online application or virtual resource capacity is a perishable and regenerative asset like a hotel room or an airline seat: if the capacity is not consumed at the time, then it is wasted, like an empty seat on a commercial airline flight.
- Application capacity management can usefully be modeled as a just-in-time inventory management problem with order lead times for capacity fulfillment actions, and so on.
- Capacity change fulfillment lead times become a key performance indicator to minimize to improve the performance of lean, demand-driven just-in-time capacity management.