CHAPTER 7
Lean Demand Management
Demand management enables peaks in demand to be smoothed by shifting the pattern of consumption, such as shifting airline passengers from an overbooked flight to a later flight that has available seats. Demand management techniques enable resource utilization of cloud infrastructure equipment to be increased significantly beyond what is practical with server virtualization alone. For example, a vertically integrated service provider who owns and operates both many applications and the underlying physical compute, memory, storage, and network infrastructure can minimize aggregate capital costs and operational expenses by strategically smoothing aggregate demand to enable higher utilization of a smaller pool of resources than would otherwise be possible.
As explained in Section 1.5: Demand Variability, application workloads often have both cyclical patterns of demand and random variations of demand. Applications that directly serve human users often have cyclical demand patterns tied to human cycles of sleep, work, travel, and leisure, while batch-oriented and machine-to-machine applications are often not necessarily tied to human cycles of demand. Different types of applications have different tolerances to random infrastructure service variations as well. For example, real-time interactive applications like conversational voice/video have very strict resource scheduling requirements to assure bearer traffic is delivered isochronously; in contrast, software backup applications are far more tolerant of occasional resource stalls and curtailment. By intelligently shaping demand of many individual applications, aggregate infrastructure demand can be smoothed to achieve significantly higher physical resource utilization than what is possible with virtualization technologies alone.
A key business challenge is to appropriately balance the infrastructure service provider's benefit from demand management (i.e., higher resource utilization of less capital equipment) against the inconvenience and trouble imposed on virtual resource consumers (i.e., application service providers) who have their patterns of service use altered. Thus, the lean goal of sustainably achieving the shortest lead time, best quality and value, and highest customer delight at the lowest cost is applicable to demand management as it is to capacity management. Demand management is considered in several sections:
- Infrastructure demand management techniques (Section 7.1)
- Application demand management techniques (Section 7.2)
- Full stream analysis methodology (Section 7.3)
7.1 Infrastructure Demand Management Techniques
As shown in Figure 7.1, infrastructure service providers have a range of techniques to regulate capacity in order to try and smooth demand variations from microseconds to seconds to minutes to hours to days to months. Many of these techniques need to be very carefully considered before applying because:
- Poorly executed demand management can lead to loss of customers
- Doing nothing can lead to service collapse
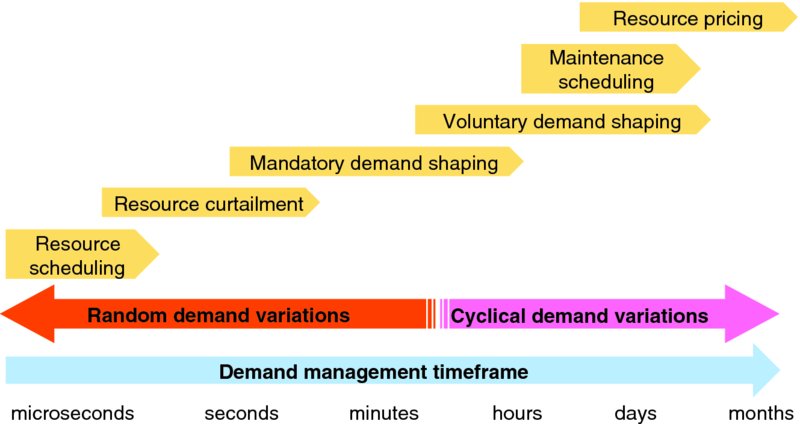
Figure 7.1 Infrastructure Demand Management Techniques
Infrastructure service providers have a range of techniques, so smooth demand variations from microseconds to seconds to minutes to hours to days to months:
- Resource scheduling (Section 7.1.1)
- Resource curtailment (Section 7.1.2)
- Mandatory demand shaping (Section 7.1.3)
- Voluntary demand shaping (Section 7.1.4)
- Scheduling maintenance actions (Section 7.1.5)
- Resource pricing (Section 7.1.6)
Note that the response timeframe of demand management techniques dictates whether they are largely automatic or largely human-driven. Techniques that operate over seconds or less (e.g., resource scheduling and curtailment) must operate automatically based on preconfigured policies. Demand management techniques that operate across hours or days (e.g., resource pricing, maintenance scheduling, voluntary demand shaping) often rely on human decisions, and thus have a slower response time.
7.1.1 Resource Scheduling
Time shared operating systems have been time slice multiplexing access for multiple applications onto finite physical hardware via context switching for decades. Each application gets slices of time, and assuming that the scheduling is prompt, the end user seldom noticed that their application is actually sharing finite hardware resources with several other independent application instances. Queuing and buffering infrastructure requests like network packets to be transmitted to another entity or processed as input is a mechanism for enabling more efficient resource scheduling. Time shared operating systems and virtualization technologies rely on this technique.
7.1.2 Resource Curtailment
When demand outstrips supply, service providers often curtail service delivery until supply catches up to demand or demand declines. Some services curtail delivery based on technical rather than policy factors, like activating rate limiting mechanisms that slow service delivery during periods of congestion or when a customer's service usage exceeds some threshold. Other services curtail resources based on policy decisions, like a supplier allocating a greater share of limited inventory to their best customers.
Managed resource curtailment policies often take the form of different grades of service (GoS) in which one class of consumers (e.g., a supplier's “best customers”) might be treated differently from others. Different applications have different sensitivities to resource curtailment, and thus different application service providers accrue different costs for resource curtailment. For example, interactive real-time communications service quality is far more sensitive to bursts of packet loss than offline or batch applications like backup or distribution of software updates which can tolerate additional latency required to timeout and retransmit lost packets. Thus, an application service provider offering interactive real-time communications is likely to value minimal packet loss (i.e., dropping packets is a type of resource curtailment) more than a provider of an offline or batch application that is less sensitive to resource curtailment like packet loss. The ICT industry often uses the notion of GoS to differentiate the relative sensitivities of application demands to resource curtailment; “high” GoS are assured minimal service curtailment at the expense of lower GoS which endure greater curtailment. By charging higher prices for higher GoS, infrastructure service providers can differentiate applications that can technically and commercially accept resource curtailment when necessary from applications that cannot tolerate resource curtailment. When appropriate prices are set for both non-curtailable and curtailable GoS, and cloud infrastructure reliably assures full resource deliver to non-curtailable resources and bounded resource curtailment of other GoS, then all parties can efficiently maximize their business value.
7.1.3 Mandatory Demand Shaping
We shall call demand management actions that are taken unilaterally by the infrastructure service provider without explicit prior consent of the impacted application service provider mandatory. While mandatory demand shaping mechanisms are inherently faster and more predictable for the infrastructure service provider than voluntary demand shaping actions, they can negatively impact application service providers' satisfaction because mandatory mechanisms coerce their applications' compliance and may not provide sufficient lead time to gracefully reduce their demand. The fundamental challenge with mandatory demand shaping mechanisms is assuring that application user service is not materially impacted when demand shaping is activated. Applications that cannot support impromptu (from the application's perspective) activation of the infrastructure service provider's demand management mechanism should not be coerced with mandatory demand management under normal circumstances.
Beyond resource curtailment, mandatory demand shaping actions that an infrastructure service provider can take fall into several broad categories:
- Denying resource allocations – infrastructure service provider can simply refuse resource allocation requests from some or all customers when demand reaches certain thresholds.
- Imposing resource quotas or other hard limits on resource allocation, resource consumption, or some other aspect of demand.
- Moving workloads – work can be moved off of an overloaded hardware element gracefully via live migration of virtual machine instances or via less graceful techniques, up to and including terminating a specific application component and relying on high availability or self-healing functions to restore user service onto less heavily loaded infrastructure equipment.
- Rolling blackouts (i.e., suspending workloads) – the infrastructure can suspend – or even terminate – execution of individual application components, such as spot VM instances offered by Amazon Web Services' EC2.
7.1.4 Voluntary Demand Shaping
Service providers sometimes request customers to voluntarily reduce service demand, such as:
- Airlines offering ticketed passengers on overbooked flights financial compensation to be reticketed onto a later flight
- Power companies asking data center operators to switch to their private backup power (e.g., battery and/or diesel generator) and disconnect from the grid during a power emergency
- Industrial or commercial power users reducing electricity consumption during heat waves or periods of intense power demand in exchange for lower rates or other consideration
There is inherently a lag time with voluntary demand shaping mechanisms because after the service provider decides to request voluntary demand shaping action, the following actions must occur:
- Service customers must be notified.
- Individual service customers must consider their particular situation before deciding whether or not to alter their immediate pattern of demand. For example, is the airline offering enough financial compensation to a ticketed passenger to even consider accepting a bump, and does a later flight accommodate their personal plans?
- Service demand must actually be reduced by the customers.
Thus, actual timing, magnitude, and shape of voluntary demand shaping actions are inherently unpredictable.
7.1.5 Scheduling Maintenance Actions
Infrastructure service providers can schedule planned maintenance events during off-peak periods to reduce demand during busy periods or execute repairs or capacity growth actions on an emergency basis to maximize operational capacity.
7.1.6 Resource Pricing
Resource pricing can influence patterns of demand over the longer term. Stronger pricing signals – such as deeper discounts for resources in off-peak periods – will often shape demand more dramatically than weaker price signals.
7.2 Application Demand Management Techniques
As shown in Figure 7.2, application demand management actions operate over several time horizons from microseconds to seconds, minutes to hours, days to months:
- Queues and buffers (Section 7.2.1)
- Load balancers (Section 7.2.2)
- Overload controls (Section 7.2.3)
- Explicit demand management Actions (Section 7.2.4)
- Scheduling maintenance actions (Section 7.2.5)
- User pricing strategies (Section 7.2.6)
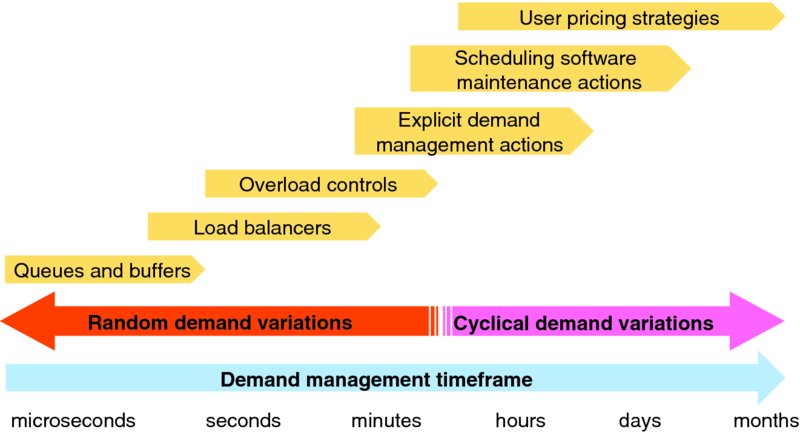
Figure 7.2 Application Demand Management Options
7.2.1 Queues and Buffers
Applications use queues and buffers to smooth out random application workload variations at the finest time scales.
7.2.2 Load Balancers
Load balancer components can implement a broad range of policies ranging from simple round-robin workload distribution to dynamic and adaptive workload distribution based on policies, measurements, and other factors. Load balancers can intelligently shift workloads away from components with lower performance or higher latency (e.g., because infrastructure resources have been explicitly or implicitly curtailed to those components) to optimally balance the workload to naturally mitigate some level of throughput or performance variation across fungible instances in a load balanced pool of components.
7.2.3 Overload Controls
Inevitably, user demand will occasionally exceed an application's online capacity, meaning that the full demand cannot be served with acceptable quality; this condition is called overload. Well-engineered applications will automatically detect overload conditions and engage congestion control mechanisms to:
- Assure continuous management visibility and controllability of the overloaded application by the service provider's operations systems and staff
- If possible, serve at least some of the demand with acceptable quality
Congestion control mechanisms may:
- enable admission control, such as not accepting new session requests when insufficient spare capacity is available to serve them;
- defer non-critical activities;
- reject service requests when the application has insufficient spare capacity to serve those requests with acceptable quality, such as by returning code 503 service unavailable to some clients.
7.2.4 Explicit Demand Management Actions
Application service providers can execute explicit demand management action such as:
- Redirect new user sessions – new or existing user workload can be redirected to other application instances that have spare capacity.
- Migrate active sessions to another application instance to shift demand to another application instance in a different data center.
In extreme circumstances application service providers can impose service quotas or other restrictions on service usage and not accept new customers.
7.2.5 Scheduling Maintenance Actions
Application service providers often have some flexibility in scheduling software release management actions (e.g., patching, upgrade, update) and trials of prototype and new application services and releases. As each release instance carries resource overhead that runs alongside the production instance, these release management actions create additional infrastructure demand that can often be rescheduled for the convenience of the infrastructure service provider. Some scheduled maintenance actions like software release management or preventive maintenance of infrastructure servers will remove target infrastructure capacity from service for at least a portion of the scheduled maintenance period. Thus, non-emergency infrastructure maintenance activities are routinely scheduled for off-peak periods.
7.2.6 User Pricing Strategies
If application service providers offer discounts to end users that are aligned with the infrastructure service provider's pricing discounts, then some end users will voluntarily alter their demand patterns.
7.3 Full Stream Analysis Methodology
To smooth aggregate infrastructure demand for an infrastructure service provider, one must balance the costs of deploying and activating demand management mechanisms, including potential loss of customer good will if their quality of experience is materially impacted, against the larger organization's savings for deploying and operating less infrastructure equipment. Ideally, lean cloud capacity management is a win/win/win in that:
- the infrastructure service provider is able to serve more application demand with less infrastructure equipment;
- application service providers that voluntarily accept occasional voluntary demand management, mandatory (direct control) demand management, resource curtailment and increased scheduling latency reap significant cost savings; and
- when properly engineered and executed, end user quality of experience is not materially impacted by demand management actions.
More efficient operation by both infrastructure service provider and application service providers lowers their costs, and some of those savings can be shared with stakeholders via lower costs.
Figure 7.3 offers a basic methodology to achieve win/win/win with lean demand management:
- Analyze applications' natural demand patterns (Section 7.3.1) – understand how cyclical and random demand variations of target applications are likely to fit together to smooth resource demand.
- Analyze applications' tolerances (Section 7.3.2) – understand how well target applications can tolerate infrastructure demand management mechanisms to smooth resource demand.
- Create attractive infrastructure pricing models (Section 7.3.3) – all parties benefit when attractive pricing models entice application service providers to voluntarily adjust their resource allocation configurations and demand patterns to enable the infrastructure service provider to optimally manage cloud infrastructure resources.
- Deploy optimal infrastructure demand management models (Section 7.3.4) – the infrastructure service provider deploys policies to simultaneously deliver acceptable service quality to all hosted application instances at a low cost, and share the savings with application service providers who permit their resource usage to be managed and their demand patterns to be shaped.
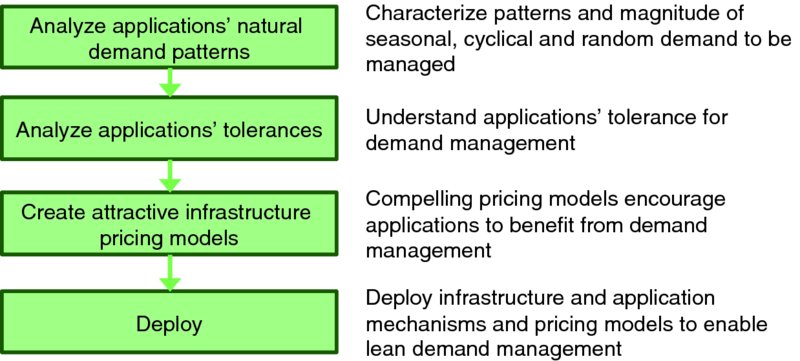
Figure 7.3 A Demand Planning Model for Lean Cloud Computing Capacity
7.3.1 Analyze Applications' Natural Demand Patterns
Demand planning factors to consider for each application workload in the organization's portfolio include:
- Shape of seasonal, cyclical, and random patterns of demand – applications that serve human users tend to have demand patterns that reflect human cycles of work, sleep, travel, and entertainment/relaxation, and since humans have little appetite for delayed gratification, most user-facing application services have relatively inflexible cyclical patterns of demand. In contrast, many machine-to-machine applications like software update and batch-oriented jobs have flexible cyclical patterns of demand in that they must run, say, every day but there is little difference to the customer if the application runs in an off-peak period. Scheduling flexible applications into the demand troughs of the inflexible applications shapes aggregate demand to improve resource utilization and reduce capacity demand. The application's pattern of random demand must also be analyzed to properly predict the appropriate levels of reserve capacity to hold. Many applications exhibit seasonality with usage patterns that vary across days of the week, weeks of the month, or quarter and time of year which must also be considered.
- Locational marginal value – the concept of locational marginal value was discussed in Section 5.8: Location of Production Considerations and Section 6.4.1: Locational Consideration. Different applications will have different locational marginal value for compute, memory, storage, and networking infrastructure. Real-time interactive applications may be highly latency sensitive and thus place a high value on being close to end users, while batch-oriented and non-interactive applications may be relatively insensitive to the distance between end users and the compute, memory, storage, and networking capacity hosting the application instance that serves those users. Resource demand from applications with low locational marginal value can be placed across a geographic region to smooth demand at individual data centers.
- Resource “SKU” minimization – larger pools of identically configured resources (think stock keeping units or SKUs) are easier for the infrastructure service provider to manage than pools of non-identically configured resources. This is why, for example, modern operating systems partition hard disk drives into fixed size “blocks” of storage which can be uniformly allocated and manipulated rather than trying to allocate exact units of storage on physical devices. Selecting the smallest suite of standard resource configurations (e.g., small, medium, large, and extra large virtual machine instances) to serve targeted application demand simplifies the infrastructure service provider's operational complexity, and thus costs. Therefore, a fundamental architectural decision is how to map application components into the finite number of standard resource configurations that are supported by the infrastructure service provider.
7.3.2 Analyze Applications' Tolerances
Different applications will have different sensitivities or tolerance to different infrastructure demand management strategies. Before one can determine the optimal demand management strategy, one needs to understand how tolerant each application is to different infrastructure demand management strategies. This should enable the infrastructure service provider to identify the cheapest and best demand management actions. Just as cyclical and random patterns of demand vary over a broad range of time scales, applications have different tolerances to demand management techniques that work across different time frames:
- Tolerance to variability of real-time resource scheduling – some applications have strict needs for real-time resource scheduling because latency added by the infrastructure in access to CPU scheduling or networking will directly impact latency of a user service that has strict latency requirements. For example, if a packet carrying voice or video data in an interactive communications service is delayed by tens or hundreds of milliseconds then it may arrive at the far end too late to be rendered to the other party and thus that party's device must attempt to mask or conceal that packet loss in the least objectionable way. As the frequency of those events increase, the user's quality of experience decreases, thus making real-time resource scheduling critical to that application. In contrast, a streaming video playback service that buffers, say, 15 seconds of content on the client's device is far more tolerant to occasionally being stalled or preempted by some infrastructure scheduling function.
- Tolerance to resource curtailment – some applications gracefully tolerate modest and isolated resource curtailment, such as pools of fungible worker components that are served by a load balancer component. For example, if resources are curtailed to one of the worker components, then that component's transaction latency and/or throughput should falloff; an intelligent load balancer will detect that falloff and can shift work load to other workers in the pool to gracefully adapt to the isolated resource curtailment of one (or perhaps a small number of) components.
- Tolerance for direct control demand management – some application components will gracefully tolerate impromptu live migration events or other direct control demand management actions that the infrastructure service provider might wish to take.
- Flexibility of cyclical patterns of demand – some patterns of resource usage can easily be timeshifted to off-peak infrastructure usage periods (e.g., to the middle of the night) while others cannot be timeshifted.
- Tolerance for voluntary control demand management – application components will have different abilities to alter their patterns of resource usage based on infrastructure service provider request. User workload placement (Section 4.1.1) is another implementation mechanism for voluntary application demand management. Infrastructure service providers may offer pricing or other commercial considerations to application service providers who allow the infrastructure service provider to have some control or influence over the resources consumed by the application. For example, an infrastructure service provider might credit an application service provider for every hour of voluntary demand curtailment that the application service provider executes during designated capacity emergency events.
Robust applications are designed to automatically detect and mitigate failure scenarios, including overload and component failures. These robustness mechanisms are likely to offer some resilience when confronted with aggressive infrastructure demand management actions.
7.3.3 Create Attractive Infrastructure Pricing Models
A perfect infrastructure pricing model is one that simultaneously offers attractive prices to application service provider organizations and gives the infrastructure service provider sufficient demand management flexibility to smooth aggregate resource demand while delivering acceptable service quality to customers while minimizing overall costs to all organizations. Thus, infrastructure pricing should be set so that application demand that is more flexible and manageable get greater discounts, while application components with the strictest real-time resource service needs to pay full price during peak usage periods. Ideally, the infrastructure pricing model motivates both application service providers and infrastructure service providers to squeeze non-value-added and wasteful activities out of the end-to-end process and both parties share the savings.
Operationally, the infrastructure service provider may have a small number of GoS for resources (e.g., virtual machine or Linux container instances) such as:
- Strict real time – minimal resource scheduling latency and no resource curtailment
- Real time – small resource scheduling latency with occasional and modest resource curtailment is acceptable
- Normal – occasional live migration and modest resource scheduling latency and resource curtailment is acceptable
- Economy – workload can be curtailed, suspended, and resumed at infrastructure service provider's discretion
In private cloud or other situations where fine grained pricing models may not be practical, infrastructure service provider diktat can certainly coerce aggressive demand management practices. However, less coercive arrangements in which application service providers benefit somehow from proactively smoothing their cyclical pattern of demand and offering the infrastructure service provider some degree of direct (e.g., mandatory) or indirect (e.g., voluntary) on-the-fly demand management are more appropriate in the win:win partnership across the service delivery chain that lean strives for. For example, quality of service settings for virtualized compute, networking, and storage could be tied to support of demand management techniques: application service provider organizations that reject even voluntary demand management mechanisms might be assigned a lower grade of service.
7.3.4 Deploy Optimal Infrastructure Demand Management Models
Infrastructure service providers can deploy sufficient physical infrastructure to serve peak cyclical demand in the infrastructure capacity lead time interval, plus a margin of safety capacity. The infrastructure service provider's unit commitment process assures that sufficient infrastructure capacity is online to serve real-time demand (see Chapter 9: Lean Infrastructure Commitment). If resource demand approaches or exceeds online or physical capacity, then appropriate resource scheduling, curtailment, mandatory and/or voluntary demand management actions are activated. In the case of voluntary demand management actions, appropriate status information is pushed to application service provider's management systems and staff to alter workload placement policies or take other actions. If voluntary demand management actions are insufficient, then mandatory demand management mechanisms can be activated.
7.4 Chapter Review
- Cyclical demand variations occur seasonally, across days of the week, and hours of the day, so average demand can often be predicted fairly accurately. Random variations in demand occur across minutes, seconds, milliseconds, microseconds. While it is hard to predict the exact demand at an instant in time, the variance in demand can often be accurately estimated.
- Cyclical patterns in user demand can be shaped by resource pricing and voluntary demand shaping mechanisms. Cyclical demand by service providers themselves can be shaped by intelligently scheduling operations and maintenance actions.
- Random variations in demand are generally addressed by resource scheduling and workload queueing mechanisms.
- Resource curtailment, overload controls, and mandatory demand management mechanisms can be activated when less draconian methods are insufficient.
- Intelligently interlocking cloud service customer and cloud service provider capacity and demand management strategies and mechanisms enables lean cloud computing's goal to sustainably achieve the shortest lead time, best quality and value, highest customer delight at the lowest cost.