Chapter 8
Lean Reserves
The goal of lean cloud capacity management – to sustainably achieve the shortest lead time, best quality and value, and highest customer delight at the lowest cost – requires that some reserve capacity be held to mitigate the service quality impact of failures and other situations. At the highest level, reserve capacity is used to mitigate the risk of a service being driven into a capacity emergency which causes parties in the service delivery chain to accrue waste from inadequate capacity (Section 3.3.5). Severe capacity emergencies can have dire business consequences including customer churn, liquidated damages liabilities, loss of market share, and loss of market value. Thus, one must deploy sufficient spare or reserve capacity to mitigate the risk of inadequate capacity without squandering resources on excessive capacity.
This chapter considers lean reserves via the following sections:
- What is reserve capacity? (Section 8.1)
- Uses of reserve capacity (Section 8.2)
- Reserve capacity as a feature (Section 8.3)
- Types of reserve capacity (Section 8.4)
- Limits of reserve capacity (Section 8.5)
- Ideal reserve (Section 8.6)
8.1 WHAT IS RESERVE CAPACITY?
Figure 8.1 (a copy of Figure 3.2) illustrates reserve capacity alongside working capacity and excess capacity. Working capacity is mean (average) demand so consider it the average level of demand across any particular capacity decision and planning window. For example, if application capacity decision and planning is evaluated every 5 minutes, then working capacity should be considered for each of those 5-minute intervals. Random variance covers the maximum and minimum levels of demand in the particular capacity decision and planning window to reflect the most extreme moments of demand in the window, such as demand intensity in the busiest seconds of the window. Reserve capacity is an increment of capacity above the forecast working capacity that is held online to mitigate risks to assure that user demand can be served with acceptable latency and overall quality. Reserve capacity should be significantly greater than peak demand (i.e., peak random variance plus mean demand in the time window) to mitigate the risk of failures, extreme surges in demand, and so on. Reserve capacity is typically expressed as a percentage of capacity above forecast mean demand.
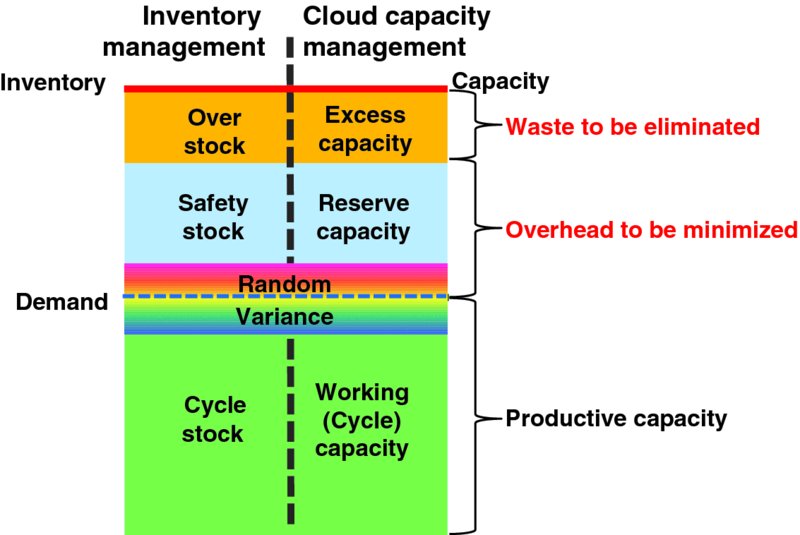
Figure 8.1 Reserve Capacity (copy of Figure 3.2)
Figure 8.2 visualizes capacity for a hypothetical application across several capacity decision and planning cycles. The points on the lower dotted line illustrate the forecast working capacity and the points on the upper dotted line show the total forecast demand plus reserve target capacity. The policy for this hypothetical example is to maintain reserve capacity of nominally 50% above forecast mean demand. The solid lines represent the actual mean and peak demand in each window. Note that while the actual mean demand is close to the forecast working capacity, the working plus reserve capacity significantly exceeds the peak actual demand because sufficient reserve capacity is held to mitigate the risk of events like unforecast surges in demand, failures, and so on; since no such event occurred in that window, that reserve was not fully consumed. Reserve capacity is somewhat like life insurance: you hold it to mitigate the financial consequences of a death. Just because the insured ultimately did not die during the term of insurance does not reduce the prudence of hedging risk during the term of insurance.
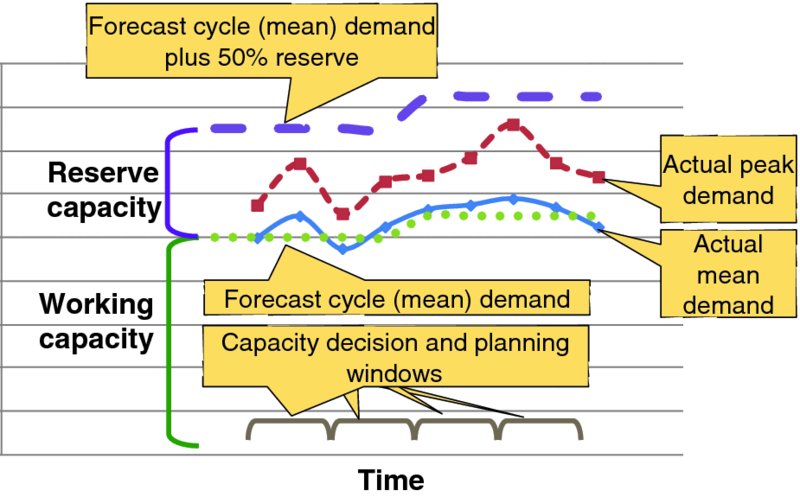
Figure 8.2 Sample Capacity Estimates and Actuals
8.2 USES OF RESERVE CAPACITY
Reserve capacity is used to mitigate an ensemble of unforeseen circumstances including:
- Random demand peaks (Section 8.2.1)
- Component or resource failure (Section 8.2.2)
- Infrastructure element failure (Section 8.2.3)
- Infrastructure resource curtailment or demand management action (Section 8.2.4)
- Demand exceeding forecast (Section 8.2.5)
- Lead time demand (Section 8.2.6)
- Catastrophic failures and force majeure events (Section 8.2.7)
8.2.1 Random Demand Peaks
As explained in Section 1.5: Demand Variability, random variations in service demand across the shortest time scales overlay onto cyclical patterns of demand. As explained in Chapter 7: Lean Demand Management, techniques like buffers, queues, and resource scheduling enable modest and momentary random bursts of demand to be served with acceptable service quality, albeit perhaps with slightly higher service latency. Reserve capacity enables random peaks to be promptly served rather than creating a persistent backlog of work that increases service latency and diminishes user quality of experience for some or all users.
8.2.2 Component or Resource Failure
Highly available applications maintain redundant online capacity sufficient to recover service impacted following a failure event with minimal user impact. No single point of failure means that an application has been appropriately designed and sufficient redundant capacity is held online that any single failure event can be mitigated with minimal user service impact. Practically, this means that sufficient spare application component capacity is held online that the entire offered load can be served with acceptable service quality immediately following the largest single failure event that can impact the target application.
Application capacity failure group size is driven by two footprints:
- Application component size – governs exactly how much application capacity is lost when that application component fails.
- Infrastructure affinity group size – infrastructure service providers naturally seek to consolidate application workloads onto the smallest practical number of infrastructure servers to minimize power consumption. In extreme cases, an application service provider might theoretically consolidate all application components that were not explicitly excluded via anti-affinity rules onto a single infrastructure component. Were that single infrastructure component to fail, then all of the hosted components would simultaneously become unavailable. Thus, sufficient spare application component capacity must be maintained online for highly available applications to mitigate the user service impact of such a failure. Independent administrative domains (e.g., availability zones) or physical sites (e.g., geographic redundancy) are large-scale mechanisms to limit failure group sizes.
Note that recovering from a component or resource failure can produce a larger transient capacity impact, in that more capacity than merely replacing the failed component may be required to acceptably recover service. For example, if a component directly serving X users fails, then recovering service for those X users may require not only sufficient service capacity to replace the failed component, but also sufficient spare capacity from supporting elements such as user identification, authentication and authorization components, data stores of user information and so on, to fully recover all impacted users within the maximum acceptable time. While the failure recovery workload surge for ordinary failures may be sufficiently small that it can be served via normal spare capacity, catastrophic failure or disaster recovery scenarios often put such a large correlated recovery-related workload on systems that sufficient spare capacity must be carefully engineered to assure that recovery time objectives (RTO) can be met.
8.2.3 Infrastructure Element Failure
Occasional infrastructure element failures are inevitable and those failed elements may be out of service awaiting repair for hours or longer. Infrastructure service providers hold some reserve capacity so that application service provider requests for virtual resources – including requests to restore (a.k.a., repair) application component capacity lost due to infrastructure element failures – can be rapidly and reliably fulfilled.
8.2.4 Infrastructure Resource Curtailment or Demand Management Action
As discussed in Chapter 7: Lean Demand Management, infrastructure service providers may occasionally curtail resource throughput or activate voluntary or mandatory demand management actions. Application service providers can use reserve capacity to mitigate service impact of these infrastructure demand management actions.
8.2.5 Demand Exceeding Forecast
Forecasting future demand is inherently difficult and error prone. Beyond predicting whether demand will broadly increase, remain constant, or decline, unforeseen – and hence hard to predict – events can occur which impact demand. Natural disasters like earthquakes, events of regional significance like terrorist attacks, commercial, entertainment, or other events can lead to unforecast surges in demand. Reserve capacity can minimize the user service impact of unforeseen surges in demand. Both application service providers and infrastructure service providers must account for the risk that their forecasts of demand are occasionally outstripped by actual demand.
8.2.6 Lead Time Demand
Reserve capacity is held to cover increases in demand that occur before additional capacity can be brought into service. Figure 8.3 illustrates the timeline of capacity decision, planning, and fulfillment. As discussed in Section 3.8: Cadence, capacity decision and planning cycles repeat on a regular cadence; let us assume a 5-minute cadence for a hypothetical application. At the start of the decision and planning cycle, some system retrieves current usage, performance, alarm, demand forecast and other information, and applies business logic to that information to decide if a capacity change is necessary. If yes, then the capacity planning function determines exactly what capacity change action to order (e.g., which specific application instance needs to execute exactly what capacity change action) and dispatches that order – or perhaps multiple orders for capacity changes for complex applications or solutions – to the appropriate system for fulfillment. Appropriate fulfillment systems then execute the required capacity configuration change action.
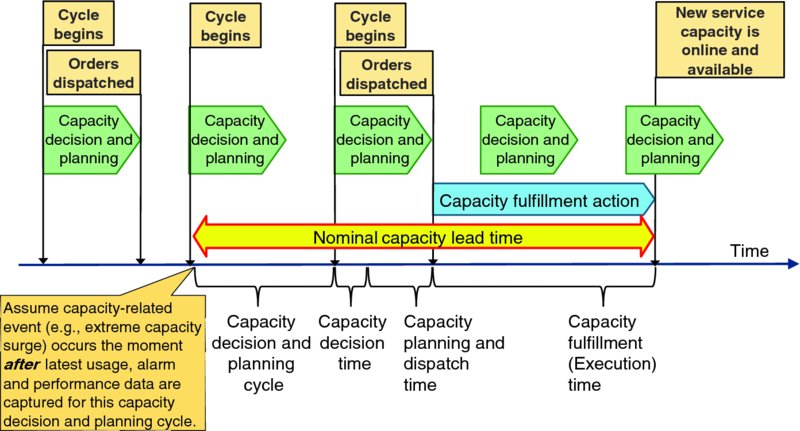
Figure 8.3 Capacity Lead Time
Capacity lead time is thus the sum of:
- Capacity decision time – time to apply operational policy criteria to current data to decide if a capacity change action is now necessary; if yes, then capacity planning and dispatch is triggered. The capacity decision process repeats at the start of each capacity decision and planning cycle.
- Capacity planning and dispatch time – after deciding that a capacity change is necessary, the capacity decision and planning systems must select exactly which application instances must be reconfigured and dispatch proper capacity change orders to appropriate fulfillment systems.
- Capacity fulfillment time – fulfillment of application capacity growth typically involves:
- Allocating and configuring new virtual resources
- Loading and initializing application software in new virtual resources
- Integrating new application component(s) with online application components and supporting systems
- Verifying proper operation of the new application capacity
- Marking the new application capacity as online and available for service
Fulfillment of application capacity degrowth typically involves:
- Draining user traffic from targeted application component
- Orderly shutdown of the targeted application component, including flushing all usage records and other data held by the targeted component to persistent storage
- Orderly release of virtual resources
Capacity fulfillment actions take time to complete, and some variability in completion time is likely. For instance, variability in the time it takes the infrastructure service provider to allocate and deliver requested virtual resources cascades as variability in capacity fulfillment time.
Occasionally a failure will occur in allocation, configuration, startup, or some other aspect of capacity fulfillment. Detecting and backing-out the failure will take time, yet not fulfill the requested capacity change action. Thus, another fulfillment action must be attempted which inevitably delays the time until the new capacity arrangement is online and available to serve user demand. As a rough estimate, one can assume that detecting and mitigating a failed capacity fulfillment action will take one lead time period, and a second lead time period will be consumed for decision, planning, and fulfillment to mitigate failure of the first fulfillment action. Thus, capacity decision and planning should manage capacity growth actions at least two normal lead time intervals into the future, so sufficient time is available to detect, mitigate, and resolve occasional failures in the fulfillment process.
8.2.7 Catastrophic Failures and Force Majeure Events
Force majeure or other extreme events can render some or all of the applications in a data center unavailable or unusable. Strikes, riots, and other events of regional significance can also render a physical data center inaccessible or unreachable for a time. Business continuity concerns drive organizations to carefully plan and prepare to survive catastrophic (e.g., force majeure) failure events. Note that the impact of force majeure and disaster events will likely render normal reserve capacity inoperable by simultaneously impacting all collocated reserve capacity. Thus, somewhat different emergency reserve capacity arrangements are typically used to mitigate catastrophic events; Section 8.4.8: Emergency Reserves considers this topic.
8.3 RESERVE CAPACITY AS A FEATURE
Reserve capacity is often explicitly monetized via two qualities of service tiers:
- Best effort service is typically not fully protected with reserve capacity, so failure or contingency situations might yield user service degradation or outage.
- Guaranteed quality of service maintains sufficient reserve capacity to mitigate user service impacts.
While a best effort service may make little or no provision to mitigate any of the risks enumerated in Section 8.2: Uses of Reserve Capacity, guaranteed quality of service offerings would be engineered to mitigate the risks covered by the service quality guarantee.
Even without an explicit quality of service guarantee, service providers should set a service level objective to engineer their service for. Reserve capacity beyond the needs of the service provider's service level objectives is excess application capacity (Section 3.3.2), excess online infrastructure capacity (Section 3.3.3), and/or excess physical infrastructure capacity (Section 3.3.4).
8.4 TYPES OF RESERVE CAPACITY
Section 5.10: Demand and Reserves explained that the power industry considers operating reserves in two orthogonal dimensions:
- Supply versus demand – is reserve capacity produced by increasing the supply of service capacity (i.e., starting another generator or infrastructure server) or by reducing current service demand (e.g., curtailing resource delivery to some users or activating a mandatory demand management mechanism)? As shown in Figure 8.4, reserve capacity techniques can be conveniently visualized these two dimensions on a reserve capacity map. Supply oriented capacity reserves include:
- Automatic infrastructure power management controls (Section 8.4.1)
- Utilize application reserve capacity (Section 8.4.2)
- Place/migrate demand into underutilized capacity (Section 8.4.3)
- Grow online capacity (Section 8.4.4)
-
Emergency reserves (Section 8.4.8)
Demand oriented reserves include:
- Service curtailment/degradation (Section 8.4.5)
- Mandatory demand shaping (Section 8.4.6)
- Voluntary demand shaping (Section 8.4.7)
- Fulfillment time – how quickly is additional service capacity available?
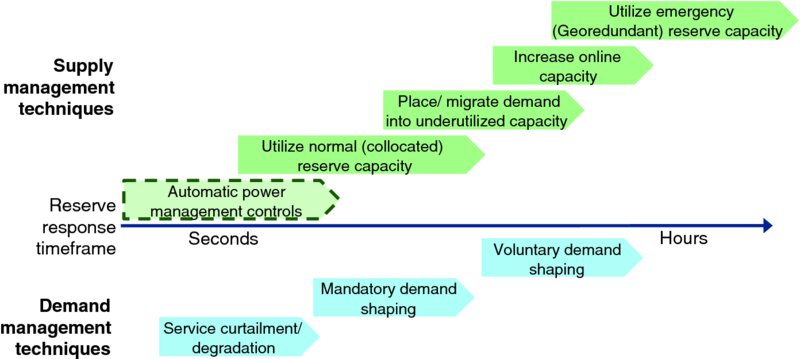
Figure 8.4 Technique versus Timeframe Reserve Capacity Overview
8.4.1 Automatic Infrastructure Power Management Controls
Just as power generating equipment has mechanisms that automatically control power output of generation equipment over some range of normal operational variations, modern electronic components and ICT equipment implement advanced power management mechanisms that implement automatic control of throughput over a small operational range via techniques like adjusting clock frequencies and operating voltages. While these automatic mechanisms are not typically considered capacity reserve techniques, deactivating advanced power management mechanisms that were engaged may make somewhat more infrastructure capacity available to serve demand.
8.4.2 Utilize Application Reserve Capacity
When load shared reserve capacity mechanisms are used, surges in demand naturally utilize an application's reserve capacity.
8.4.3 Place/Migrate Demand into Underutilized Capacity
Uneven distribution of workload across pools of fungible application components or application instances makes redistributing new, or perhaps even existing, demand from more utilized components or instances to less heavily utilized components or instances useful. Potentially workload can also be shifted away from a stressed or poorly performing component to another application instance that has spare capacity.
8.4.4 Grow Online Capacity
Growing online capacity of an existing application instance is the normal way to increase application capacity.
8.4.5 Service Curtailment/Degradation
When service demand outstrips online capacity, one can limit or throttle the service throughput delivered to some or all consumers. Readers will be familiar with service curtailment in the contest of broadband internet service: download speed (i.e., service throughput) slows due to congestion during heavy usage periods.
8.4.6 Mandatory Demand Shaping
In capacity emergencies, application or infrastructure service providers can unilaterally pause, suspend, cancel, or terminate active workloads. Activating mandatory demand shaping actions often impacts the service user and forces them to take the trouble of executing mitigating actions which is generally counter to the lean principle of respect.
8.4.7 Voluntary Demand Shaping
Voluntary demand shaping measures give the service consumer the opportunity to gracefully shift their pattern of demand at the earliest convenient moment, thereby sparing them the trouble of having to mitigate service impact of an ill-timed or ill-planned mandatory demand management action.
8.4.8 Emergency Reserves
A single force majeure or disaster event can render an entire data center, including all virtual resources and applications hosted on physical equipment in the impacted data center, unreachable or otherwise unavailable for service. Natural disasters like earthquakes can simultaneously impact some or all data centers in the vicinity of the event. The fundamental business problem is recovering impacted user service and application data to one or more alternate application instances running in data centers that were not directly impacted by the disaster event.
Critical and important applications are explicitly engineered for disaster recovery so that after a disaster or force majeure event renders a cloud data center unavailable or otherwise inaccessible for service, then user service can be restored in a geographically distant data center which would not have been affected by the same force majeure event. Recovery performance is quantitatively characterized by RTO (RTO) and recovery point objective (RPO) (RPO), which are visualized in Figure 8.5. Note that disaster RTOs are generally far more generous than the maximum acceptable service impact duration for non-catastrophic incidents.
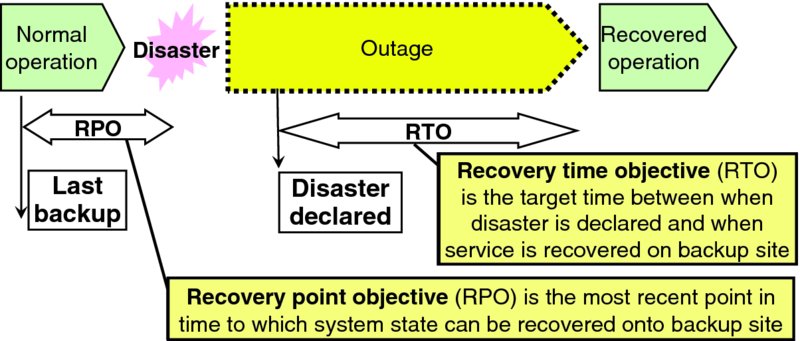
Figure 8.5 Recovery Time and Point Objectives
Very short RTO and RPO values often require disaster recovery capacity to be online and synchronized with current data prior to the disaster event, which means that sufficient disaster recovery capacity must be online 24/7 to recover application capacity for the largest expected disaster event because the timing of disaster events is generally unpredictable. Generous RTO values may enable some, most, or all disaster recovery capacity to be allocated on the fly following a disaster event.
There are a range of application recovery strategies into geographically distant cloud data centers; for simplicity, let us consider two basic disaster recovery architectures:
- All active georedundancy – independent online application instances are deployed to multiple geographically dispersed data centers across a geographic region, and all application data are replicated across all online instances. Note that the geographic region must be large enough that no single disaster event can simultaneously impact all or most data centers, but small enough that some or all regional data centers could serve any regional user with acceptable service quality. When a force majeure event renders the application instance in one data center unavailable, impacted users are redirected to application instances in data centers that were not impacted. Short RTO targets will require application instances to carry sufficient online reserve capacity to “instantly” recover impacted users without having to grow on-the-fly. Longer RTO targets give nonimpacted application instances time to grow application capacity after the disaster event and still recover impacted users within the RTO requirement.
- On-the-fly application disaster recovery – application service provider maintains backup or replica copies of current application data and binaries at one or more data centers in the region. Data replication or backup mechanisms are configured to assure that the application's RPO will be met. Following a disaster event, the application service provider selects a data center to host replacement application instance(s), copies application data and binaries to that data center (if it was not prepositioned in the recovery data center), and instantiates a new application instance of sufficient capacity to serve all impacted users. The data center selection, application data transfer, virtual resource allocation and configuration, application startup, configuration, and acceptance testing must complete fast enough that the newly instantiated application has enough time to recover user service for the stipulated portion of end users (e.g., 90% of all nominally active users) can recover service within the specified RTO.
Roles and responsibilities alignment will dictate what role the infrastructure service provider of the impacted data center, the recovery data center, and/or a disaster recovery as-a-service provider play to support the application service provider.
A unique challenge around disaster recovery is that a data center represents a large footprint of failure that simultaneously impacts all applications hosted in that data center. Thus, application service providers for all impacted applications will likely activate disaster recovery plans at the same time and may end up competing for virtual resource allocations and throughput to serve the surging workload associated with disaster recovery. In aggregate, this likely surge in resource allocation requests may be far beyond what the infrastructure service provider's management and orchestration systems normally process. A surge in network traffic to retrieve recovery data and prepare recovery capacity may cause congestion of networking infrastructure and facilities which can slow disaster recovery time. Thus, resource allocation and provisioning may take significantly longer and be somewhat less reliable in disaster emergencies, so RTO planning should allow extra time for congestion-related affects.
Disaster recovery as a service and other cloud offerings may enable application service providers to configure application capacity somewhat leaner than they might have for traditional disaster recovery deployment models. In addition, automated service, application, and resource lifecycle management mechanisms can shorten execution time and improve execution quality for disaster recovery actions.
8.5 LIMITS OF RESERVE CAPACITY
Both application service provider and infrastructure service provider organizations must make sensible financial decisions to remain sustainable business. One financial decision considers the risk tolerance for having insufficient capacity instantaneously available to serve customer demand compared to the cost of maintaining actual or optioned capacity to serve increasingly unlikely extreme demand surges. For example, at some point it may be cheaper for an application or infrastructure service provider to pay penalties for rare capacity emergency incidents rather than to carry sufficient capacity to fully mitigate service impact of all possible capacity emergency incidents. Accepting greater risk of tardy or limited service availability during capacity emergencies will lower reserve capacity requirements (and hence costs) but customer satisfaction and good will may be impacted when a capacity emergency incident occurs.
8.6 IDEAL RESERVE
The ideal level of reserve capacity is considered separately as:
- Normal (co-located) reserve (Section 8.6.1)
- Emergency (geographically distributed) reserve (Section 8.6.2)
8.6.1 Normal (Co-located) Reserve
Affinity rules typically request that virtual resources hosting an application instance's components are co-located, ideally in the same rack, chassis, or even server blade, to maximize performance. Reserve capacity is normally collocated with the working capacity so that users served by that reserve capacity are likely to experience the same quality of service as users served by working capacity.
Just as safety stock inventory levels are set based on probabilistic service level (i.e., probability that sufficient inventory will be on hand to serve demand) rather than engineering for absolute certainty, ideal reserve is also determined based on a probabilistic service level target that sufficient capacity will be available to serve offered workload with acceptable quality of service. The higher the service level objective the greater the quantity of reserve capacity that must be held online to mitigate the remote probability of extreme events that require even more capacity to mitigate.
Normal, co-located reserve capacity optimally mitigates:
- Random demand peaks (Section 8.2.1) – actual random demand fluctuations often exhibit consistent statistical variations, so applying the target service level to historical demand offers one estimate of reserve capacity required to mitigate this variation.
- Component or resource failure (Section 8.2.2) – reserve capacity required to mitigate a single component or resource failure is equal to the capacity impacted by the worst case single failure event. Practically this means that one component instance of capacity should be held in reserve for highly available services.
- Infrastructure element failure (Section 8.2.3) – failure of a single physical infrastructure element can simultaneously impact all virtual resources hosted on the impacted element. Therefore, care must be taken not to place both primary and protecting components for any single application instance onto the same infrastructure element failure group so that an infrastructure failure does not simultaneously impact both an application's primary and protecting components and thereby overwhelm the application's high availability architecture. Application service providers stipulate anti-affinity rules to infrastructure service providers to assure that no single infrastructure element will overwhelm the application's high availability mechanisms and exceed the application service provider's reserve capacity.
- Infrastructure resource curtailment or demand management action (Section 8.2.4) – historic performance of infrastructure service qualities guide the application service provider to estimate how much reserve capacity is appropriate to hold to mitigate this risk.
- Demand exceeding forecast (Section 8.2.5) – accuracy of historic mean and peak forecasts against actual demand should guide the application service provider when estimating appropriate levels of reserve to mitigate this risk.
- Lead time demand (Section 8.2.6) – historic data on latency, latency variation, and reliability of capacity fulfillment actions should guide the service provider on estimating the right level of reserve to mitigate this risk.
Ideal single-event reserve capacity is the maximum of the capacities necessary to mitigate each of the individual risks above. Longer fulfillment times, less frequent capacity decision and planning cycles, and less reliable capacity fulfillment actions bias one to engineer sufficient reserve capacity to mitigate two failure events occurring before additional capacity can be brought online. As a starting point, one might consider an ideal reserve of perhaps twice the maximum capacity required to mitigate any one of the single risks above. Continuous improvement activities driven by lean cloud computing principles can drive ideal lean reserve targets down over time.
8.6.2 Emergency (Geographically Distributed) Reserve
Catastrophic failures and force majeure events (Section 8.2.7) simultaneously impact most or all application components hosted in a physical data center, thereby impacting most or all working and normal (co-located) reserve capacity at the impacted site inoperable. Thus, these events must be mitigated via reserves located in a data center not impacted by the force majeure or catastrophic event. Emergency reserve capacity is typically engineered to be sufficiently distant from the original site so that no single force majeure or catastrophic event would impact both sites; ideally emergency reserve capacity is hundreds of miles away from the original site. The emergency reserve capacity might be owned and operated by the same infrastructure service provider or by a different infrastructure service provider. The application service provider typically arranges for emergency reserve capacity in advance to shorten the service recovery time following a disaster event. Some application service providers will opt for disaster-recovery-as-a-service offerings rather than managing and maintaining emergency reserve capacity themselves. Mutual aid arrangements in which other organization serve the impacted organization's user traffic might also be considered. Perfect emergency (geographically distributed) reserve is the minimum capacity necessary to recover user service within the RTO of a disaster or force majeure event
Emergency reserves are characterized by two key parameters:
- Capacity – sufficient emergency reserve capacity must be available to mitigate the impact of total loss of the data center hosting the largest application capacity in the recovery region.
- Activation time – what is the maximum allowable time to bring sufficient emergency reserve capacity to full readiness so that impacted users can begin recovering service? Long activation times can likely be served by starting entirely new application instances in nonimpacted cloud data centers. Shorter recovery times can be served by consuming the normal (co-located) reserve (Section 8.6.1) of application instances in the recovery region but not in the impacted data center, and then growing capacity on-the-fly to both build out sufficient emergency recovery capacity and to rebuild normal (co-located) reserve inventory in data centers across the recovery region. The shortest RTOs require maintaining sufficient normal (co-located) reserve capacity across some or all application instances across the recovery region to mitigate the capacity loss of an entire data center of application capacity without having to grow application capacity in on the fly to recover user service. The application instances in other data centers recovering service will, of course, have to rebuild their normal (co-located) reserve capacity (plus additional reserves to protect the recovered user demand), but rebuilding that reserve inventory is not in the critical path of disaster recovery.
8.7 CHAPTER REVIEW
- ✓ Capacity can usefully be factored into three categories:
- Working (cycle) capacity to cover cyclical demand in a time window (e.g., a 5-minute period)
- Reserve capacity to cover random demand peaks, component or resource failures, demand exceeding forecast, lead time demand, and so on in a time window (e.g., a 5-minute period)
- Waste, which is any capacity beyond that needed for both working capacity and reserve capacity in a time window (e.g., a 5-minute period). Waste is an overhead to be eliminated.
- ✓ Reserve capacity is used to mitigate an ensemble of unforeseen circumstances including:
- Random demand peaks (Section 8.2.1)
- Component or resource failure (Section 8.2.2)
- Infrastructure element failure (Section 8.2.3)
- Infrastructure resource curtailment or demand management action (Section 8.2.4)
- Demand exceeding forecast (Section 8.2.5)
- Lead time demand (Section 8.2.6)
- Catastrophic failures and force majeure events (Section 8.2.7)
- ✓ Reserve capacity can usefully be classified on two dimensions:
- Supply versus demand – does reserve fundamentally increase the current supply of capacity or reduce demand on the current capacity?
- Fulfillment time – how quickly is additional capacity made available for use?
- ✓ Supply oriented capacity reserves include:
- Automatic infrastructure power management controls (Section 8.4.1)
- Utilize application reserve capacity (Section 8.4.2)
- Place/migrate demand into underutilized capacity (Section 8.4.3)
- Grow online capacity (Section 8.4.4)
-
Emergency reserves (Section 8.4.8)
- ✓ Demand oriented reserves include:
- Service curtailment/degradation (Section 8.4.5)
- Mandatory demand shaping (Section 8.4.6)
- Voluntary demand shaping (Section 8.4.7)