Callbacks are the materialization of the handlers of the reactor pattern and they are literally one of those imprints that give Node.js its distinctive programming style. Callbacks are functions that are invoked to propagate the result of an operation and this is exactly what we need when dealing with asynchronous operations. They practically replace the use of the return instruction that, as we know, always executes synchronously. JavaScript is a great language to represent callbacks, because as we know, functions are first class objects and can be easily assigned to variables, passed as arguments, returned from another function invocation, or stored into data structures. Also, closures are an ideal construct for implementing callbacks. With closures, we can in fact reference the environment in which a function was created, practically, we can always maintain the context in which the asynchronous operation was requested, no matter when or where its callback is invoked.
Note
If you need to refresh your knowledge about closures, you can refer to the article on the Mozilla Developer Network at https://developer.mozilla.org/en-US/docs/Web/JavaScript/Guide/Closures.
In this section, we will analyze this particular style of programming made of callbacks instead of the return instructions.
In JavaScript, a callback is a function that is passed as an argument to another function and is invoked with the result when the operation completes. In functional programming, this way of propagating the result is called continuation-passing style, for brevity, CPS. It is a general concept, and it is not always associated with asynchronous operations. In fact, it simply indicates that a result is propagated by passing it to another function (the callback), instead of directly returning it to the caller.
To clarify the concept, let's take a look at a simple synchronous function:
function add(a, b) {
return a + b;
}There is nothing special here; the result is passed back to the caller using the return instruction; this is also called direct style, and it represents the most common way of returning a result in synchronous programming. The equivalent continuation-passing style of the preceding function would be as follows:
function add(a, b, callback) {
callback(a + b);
}The add() function is a synchronous CPS function, which means that it will return a value only when the callback completes its execution. The following code demonstrates this statement:
console.log('before');
add(1, 2, function(result) {
console.log('Result: ' + result);
});
console.log('after');Since add() is synchronous, the previous code will trivially print the following:
before Result: 3 after
Now, let's consider the case where the add() function is asynchronous, which is as follows:
function addAsync(a, b, callback) {
setTimeout(function() {
callback(a + b);
}, 100);
}In the previous code, we simply use setTimeout() to simulate an asynchronous invocation of the callback. Now, let's try to use this function and see how the order of the operations changes:
console.log('before');
addAsync(1, 2, function(result) {
console.log('Result: ' + result);
});
console.log('after');The preceding code will print the following:
before after Result: 3
Since setTimeout() triggers an asynchronous operation, it will not wait anymore for the callback to be executed, but instead, it returns immediately giving the control back to addAsync(), and then back to its caller. This property in Node.js is crucial, as it allows the stack to unwind, and the control to be given back to the event loop as soon as an asynchronous request is sent, thus allowing a new event from the queue to be processed.
The following image shows how this works:
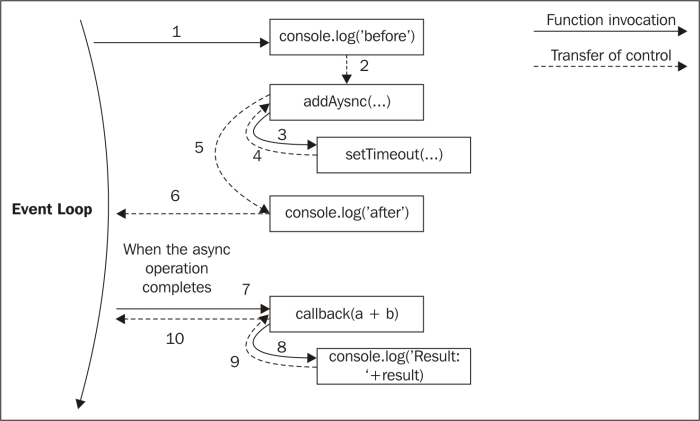
When the asynchronous operation completes, the execution is then resumed starting from the callback provided to the asynchronous function that caused the unwinding. The execution will start from the Event Loop, so it will have a fresh stack. This is where JavaScript comes in really handy, in fact, thanks to closures it is trivial to maintain the context of the caller of the asynchronous function, even if the callback is invoked at a different point in time and from a different location.
There are several circumstances in which the presence of a callback argument might make you think that a function is asynchronous or is using a continuation-passing style; that's not always true, let's take, for example, the map() method of the Array object:
var result = [1, 5, 7].map(function(element) {
return element – 1;
});Clearly, the callback is just used to iterate over the elements of the array, and not to pass the result of the operation. In fact, the result is returned synchronously using a direct style. The intent of a callback is usually clearly stated in the documentation of the API.
We have seen how the order of the instructions changes radically depending on the nature of a function - synchronous or asynchronous. This has strong repercussions on the flow of the entire application, both in correctness and efficiency. The following is an analysis of these two paradigms and their pitfalls. In general, what must be avoided, is creating inconsistency and confusion around the nature of an API, as doing so can lead to a set of problems which might be very hard to detect and reproduce. To drive our analysis, we will take as example the case of an inconsistently asynchronous function.
One of the most dangerous situations is to have an API that behaves synchronously under certain conditions and asynchronously under others. Let's take the following code as an example:
var fs = require('fs');
var cache = {};
function inconsistentRead(filename, callback) {
if(cache[filename]) {
//invoked synchronously
callback(cache[filename]);
} else {
//asynchronous function
fs.readFile(filename, 'utf8', function(err, data) {
cache[filename] = data;
callback(data);
});
}
}The preceding function uses the cache variable to store the results of different file read operations. Please bear in mind that this is just an example, it does not have error management, and the caching logic itself is suboptimal. Besides this, the preceding function is dangerous because it behaves asynchronously until the cache is not set—which is until the fs.readFile() function returns its results—but it will also be synchronous for all the subsequent requests for a file already in the cache—triggering an immediate invocation of the callback.
Now, let's see how the use of an unpredictable function, such as the one that we defined previously, can easily break an application. Consider the following code:
function createFileReader(filename) {
var listeners = [];
inconsistentRead(filename, function(value) {
listeners.forEach(function(listener) {
listener(value);
});
});
return {
onDataReady: function(listener) {
listeners.push(listener);
}
};
}When the preceding function is invoked, it creates a new object that acts as a notifier, allowing to set multiple listeners for a file read operation. All the listeners will be invoked at once when the read operation completes and the data is available. The preceding function uses our inconsistentRead() function to implement this functionality. Let's now try to use the createFileReader() function:
var reader1 = createFileReader('data.txt');
reader1.onDataReady(function(data) {
console.log('First call data: ' + data);
//...sometime later we try to read again from
//the same file
var reader2 = createFileReader('data.txt');
reader2.onDataReady(function(data) {
console.log('Second call data: ' + data);
});
}); The preceding code will print the following output:
First call data: some data
As you can see, the callback of the second operation is never invoked. Let's see why:
- During the creation of
reader1, ourinconsistentRead()function behaves asynchronously, because there is no cached result available. Therefore, we have all the time to register our listener, as it will be invoked later in another cycle of the event loop, when the read operation completes. - Then,
reader2is created in a cycle of the event loop in which the cache for the requested file already exists. In this case, the inner call toinconsistentRead()will be synchronous. So, its callback will be invoked immediately, which means that also all the listeners ofreader2will be invoked synchronously. However, we are registering the listeners after the creation ofreader2, so they will never be invoked.
The callback behavior of our inconsistentRead() function is really unpredictable, as it depends on many factors, such as the frequency of its invocation, the filename passed as argument, and the amount of time taken to load the file.
The bug that we've just seen might be extremely complicated to identify and reproduce in a real application. Imagine to use a similar function in a web server, where there can be multiple concurrent requests; imagine seeing some of those requests hanging, without any apparent reason and without any error being logged. This definitely falls under the category of nasty defects.
Isaac Z. Schlueter, creator of npm and former Node.js project lead, in one of his blog posts compared the use of this type of unpredictable functions to unleashing Zalgo. If you're not familiar with Zalgo, you are invited to find out what it is.
Note
You can find the original Isaac Z. Schlueter's post at http://blog.izs.me/post/59142742143/designing-apis-for-asynchrony.
The lesson to learn from the unleashing Zalgo example is that it is imperative for an API to clearly define its nature, either synchronous or asynchronous.
One suitable fix for our inconsistentRead() function, is to make it totally synchronous. This is possible because Node.js provides a set of synchronous direct style APIs for most of the basic I/O operations. For example, we can use the fs.readFileSync() function in place of its asynchronous counterpart. The code would now be as follows:
var fs = require('fs');
var cache = {};
function consistentReadSync(filename) {
if(cache[filename]) {
return cache[filename];
} else {
cache[filename] = fs.readFileSync(filename, 'utf8');
return cache[filename];
}
}We can see that the entire function was also converted to a direct style. There is no reason for the function to have a continuation-passing style if it is synchronous. In fact, we can state that it is always a good practice to implement a synchronous API using a direct style; this will eliminate any confusion around its nature and will also be more efficient from a performance perspective.
Please bear in mind that changing an API from CPS to a direct style, or from asynchronous to synchronous, or vice versa might also require a change to the style of all the code using it. For example, in our case, we will have to totally change the interface of our createFileReader() API and adapt it to work always synchronously.
Also, using a synchronous API instead of an asynchronous one has some caveats:
- A synchronous API might not be always available for the needed functionality.
- A synchronous API will block the event loop and put the concurrent requests on hold. It practically breaks the Node.js concurrency, slowing down the whole application. We will see later in the book what this really means for our applications.
In our
consistentReadSync() function, the risk of blocking the event loop is partially mitigated, because the synchronous I/O API is invoked only once per each filename, while the cached value will be used for all the subsequent invocations. If we have a limited number of static files, then using consistentReadSync() won't have a big effect on our event loop. Things can change quickly if we have to read many files and only once. Using synchronous I/O in Node.js is strongly discouraged in many circumstances; however, in some situations, this might be the easiest and most efficient solution. Always evaluate your specific use case in order to choose the right alternative.
Another alternative for fixing our inconsistentRead() function is to make it purely asynchronous. The trick here is to schedule the synchronous callback invocation to be executed "in the future" instead of being run immediately in the same event loop cycle. In Node.js, this is possible using process.nextTick(), which defers the execution of a function until the next pass of the event loop. Its functioning is very simple; it takes a callback as an argument and pushes it on the top of the event queue, in front of any pending I/O event, and returns immediately. The callback will then be invoked as soon as the event loop runs again.
Let's apply this technique to fix our inconsistentRead() function as follows:
var fs = require('fs');
var cache = {};
function consistentReadAsync(filename, callback) {
if(cache[filename]) {
process.nextTick(function() {
callback(cache[filename]);
});
} else {
//asynchronous function
fs.readFile(filename, 'utf8', function(err, data) {
cache[filename] = data;
callback(data);
});
}
}Now, our function is guaranteed to invoke its callback asynchronously, under any circumstances.
Another API for deferring the execution of code is setImmediate(), which—despite the name—might actually be slower than process.nextTick(). While their purpose is very similar, their semantic is quite different. Callbacks deferred with process.nextTick() run before any other I/O event is fired, while with setImmediate(), the execution is queued behind any I/O event that is already in the queue. Since process.nextTick() runs before any already scheduled I/O, it might cause I/O starvation under certain circumstances, for example, a recursive invocation; this can never happen with setImmediate(). We will learn to appreciate the difference between these two APIs when we analyze the use of deferred invocation for running synchronous CPU-bound tasks later in the book.
In Node.js, continuation-passing style APIs and callbacks follow a set of specific conventions. These conventions apply to the Node.js core API but they are also followed virtually by every userland module and application. So, it's very important that we understand them and make sure that we comply whenever we need to design an asynchronous API.
In Node.js, if a function accepts in input a callback, this has to be passed as the last argument. Let's take the following Node.js core API as an example:
fs.readFile(filename, [options], callback)
As you can see from the signature of the preceding function, the callback is always put in last position, even in the presence of optional arguments. The motivation for this convention is that the function call is more readable in case the callback is defined in place.
In CPS, errors are propagated as any other type of result, which means using the callback. In Node.js, any error produced by a CPS function is always passed as the first argument of the callback, and any actual result is passed starting from the second argument. If the operation succeeds without errors, the first argument will be null or undefined. The following code shows you how to define a callback complying with this convention:
fs.readFile('foo.txt', 'utf8', function(err, data) {
if(err)
handleError(err);
else
processData(data);
});It is a good practice to always check for the presence of an error, as not doing so will make it harder for us to debug our code and discover the possible points of failures. Another important convention to take into account is that the error must always be of type Error. This means that simple strings or numbers should never be passed as error objects.
Propagating errors in synchronous, direct style functions is done with the well-known throw command, which causes the error to jump up in the call stack until it's caught.
In asynchronous CPS however, proper error propagation is done by simply passing the error to the next callback in the CPS chain. The typical pattern looks as follows:
var fs = require('fs');
function readJSON(filename, callback) {
fs.readFile(filename, 'utf8', function(err, data) {
var parsed;
if(err)
//propagate the error and exit the current function
return callback(err);
try {
//parse the file contents
parsed = JSON.parse(data);
} catch(err) {
//catch parsing errors
return callback(err);
}
//no errors, propagate just the data
callback(null, parsed);
});
};The detail to notice in the previous code is how the callback is invoked when we want to pass a valid result and when we want to propagate an error.
You might have seen from the readJSON() function defined previously that in order to avoid any exception to be thrown into the fs.readFile() callback, we put a try-catch block around JSON.parse(). Throwing inside an asynchronous callback, in fact, will cause the exception to jump up to the event loop and never be propagated to the next callback.
In Node.js, this is an unrecoverable state and the application will simply shut down printing the error to the stderr interface. To demonstrate this, let's try to remove the try-catch block from the readJSON() function defined previously:
var fs = require('fs');
function readJSONThrows(filename, callback) {
fs.readFile(filename, 'utf8', function(err, data) {
if(err)
return callback(err);
//no errors, propagate just the data
callback(null, JSON.parse(data));
});
};Now, in the function we just defined, there is no way of catching an eventual exception coming from JSON.parse(). Let's try, for example, to parse an invalid JSON file with the following code:
readJSONThrows('nonJSON.txt', function(err) {
console.log(err);
});This would result in the application being abruptly terminated and the following exception being printed on the console:
SyntaxError: Unexpected token d at Object.parse (native) at [...]/06_uncaught_exceptions/uncaught.js:7:25 at fs.js:266:14 at Object.oncomplete (fs.js:107:15)
Now, if we look at the preceding stack trace, we will see that it starts somewhere from the fs.js module, practically from the point at which the native API has completed reading and returned its result back to the fs.readFile() function, via the event loop. This clearly shows us that the exception traveled from our callback into the stack that we saw, and then straight into the event loop, where it's finally caught and thrown in the console.
This also means that wrapping the invocation of readJSONThrows() with a try-catch block will not work, because the stack in which the block operates is different from the one in which our callback is invoked. The following code shows the anti-pattern that we just described:
try {
readJSONThrows('nonJSON.txt', function(err, result) {
[...]
});
} catch(err) {
console.log('This will not catch the JSON parsing exception');
}The preceding catch statement will never receive the JSON parsing exception, as it will travel back to the stack in which the exception was thrown, and we just saw that the stack ends up in the event loop and not with the function that triggers the asynchronous operation.
We already said that the application is aborted the moment an exception reaches the event loop; however, we still have a last chance to perform some cleanup or logging before the application terminates. In fact, when this happens, Node.js emits a special event called uncaughtException just before exiting the process. The following code shows a sample use case:
process.on('uncaughtException', function(err){
console.error('This will catch at last the ' +
'JSON parsing exception: ' + err.message);
//without this, the application would continue
process.exit(1);
});It's important to understand that an uncaught exception leaves the application in a state that is not guaranteed to be consistent, which can lead to unforeseeable problems. For example, there might still have incomplete I/O requests running, or closures might have become inconsistent. That's why it is always advised, especially in production, to exit anyway from the application after an uncaught exception is received.