In the previous section, we learned why streams are so powerful, but also that they are everywhere in Node.js, starting from its core modules. For example, we have seen that the fs module has createReadStream() for reading from a file and createWriteStream() for writing to a file, the http request and response objects are essentially streams, and the zlib module allows us to compress and decompress data using a streaming interface.
Now that we know why streams are so important, let's take a step back and start to explore them in more detail.
Every stream in Node.js is an implementation of one of the four base abstract classes available in the stream core module:
stream.Readablestream.Writablestream.Duplexstream.Transform
Each stream class is also an instance of EventEmitter. Streams, in fact, can produce several types of events, such as end, when a Readable stream has finished reading, or error, when something goes wrong.
One of the reasons why streams are so flexible is the fact that they can handle not only binary data, but practically, almost any JavaScript value; in fact they can support two operating modes:
These two operating modes allow us to use streams not only for I/O, but also as a tool to elegantly compose processing units in a functional fashion, as we will see later in the chapter.
Note
In this chapter, we will discuss mainly the Node.js stream interface also known as Version 2, which was introduced in Node.js 0.10. For further details about the differences with the old interface, please refer to the official Node.js blog at http://blog.nodejs.org/2012/12/20/streams2/.
A readable stream represents a source of data; in Node.js, it's implemented using the Readable abstract class that is available in the stream module.
There are two ways to receive the data from a Readable stream: non-flowing and flowing. Let's analyze these modes in more detail.
The default pattern for reading from a Readable stream consists of attaching a listener for the readable event that signals the availability of new data to read. Then, in a loop, we read all the data until the internal buffer is emptied. This can be done using the read() method, which synchronously reads from the internal buffer and returns a Buffer or String object representing the chunk of data. The read() method has the following signature:
readable.read([size])
Using this approach, the data is explicitly pulled from the stream on demand.
To show how this works, let's create a new module named readStdin.js, which implements a simple program that reads from the standard input (a Readable stream) and echoes everything back to the standard output:
process.stdin
.on('readable', function() {
var chunk;
console.log('New data available');
while((chunk = process.stdin.read()) !== null) {
console.log(
'Chunk read: (' + chunk.length + ') "' +
chunk.toString() + '"'
);
}
})
.on('end', function() {
process.stdout.write('End of stream');
});The read() method is a synchronous operation that pulls a data chunk from the internal buffers of the Readable stream. The returned chunk is, by default, a Buffer object if the stream is working in binary mode.
The data is read exclusively from within the readable listener, which is invoked as soon as new data is available. The read() method returns null when there is no more data available in the internal buffers; in such a case, we have to wait for another readable event to be fired - telling us that we can read again - or wait for the end event that signals the end of the stream. When a stream is working in binary mode, we can also specify that we are interested in reading a specific amount of data by passing a size value to the read() method. This is particularly useful when implementing network protocols or when parsing specific data formats.
Now, we are ready to run the readStdin module and experiment with it. Let's type some characters in the console and then press Enter to see the data echoed back into the standard output. To terminate the stream and hence generate a graceful end event, we need to insert an EOF (End-Of-File) character (using Ctrl + Z on Windows or Ctrl + D on Linux).
We can also try to connect our program with other processes; this is possible using the pipe operator (|), which redirects the standard output of a program to the standard input of another. For example, we can run a command such as the following:
cat <path to a file> | node readStdin
This is an amazing demonstration of how the streaming paradigm is a universal interface, which enables our programs to communicate, regardless of the language they are written in.
Another way to read from a stream is by attaching a listener to the data event; this will switch the stream into using the
flowing mode where the data is not pulled using read(), but instead it's pushed to the data listener as soon as it arrives. For example, the readStdin application that we created earlier will look like this using the flowing mode:
process.stdin
.on('data', function(chunk) {
console.log('New data available');
console.log(
'Chunk read: (' + chunk.length + ')" ' +
chunk.toString() + '"'
);
})
.on('end', function() {
process.stdout.write('End of stream');
});The flowing mode is an inheritance of the old version of the stream interface (also known as Streams1), and offers less flexibility to control the flow of data. With the introduction of the Streams2 interface, the flowing mode is not the default working mode; to enable it, it's necessary to attach a listener to the data event or explicitly invoke the resume() method. To temporarily stop the stream from emitting data events, we can then invoke the pause() method, causing any incoming data to be cached in the internal buffer.
Now that we know how to read from a stream, the next step is to learn how to implement a new Readable stream. To do this, it's necessary to create a new class by inheriting the prototype of stream.Readable. The concrete stream must provide an implementation of the _read() method, which has the following signature:
readable._read(size)
The internals of the Readable class will call the _read() method, which in turn will start to fill the internal buffer using push():
readable.push(chunk)
To demonstrate how to implement the new Readable streams, we can try to implement a stream that generates random strings. Let's create a new module called randomStream.js that will contain the code of our string generator. At the top of the file, we will load our dependencies:
var stream = require('stream');
var util = require('util');
var chance = require('chance').Chance();Nothing special here, except that we are loading a npm module called chance (https://npmjs.org/package/chance), which is a library for generating all sorts of random values, from numbers to strings to entire sentences.
The next step is to create a new class called RandomStream and that specifies stream.Readable as its parent:
function RandomStream(options) {
stream.Readable.call(this, options);
}
util.inherits(RandomStream, stream.Readable);In the preceding code, we call the constructor of the parent class to initialize its internal state, and forward the options argument received as input. The possible parameters passed through the options object include:
- The
encodingargument that is used to convertBufferstoStrings(defaults tonull) - A flag to enable the object mode (
objectModedefaults tofalse) - The upper limit of the data stored in the internal buffer after which no more reading from the source should be done (
highWaterMarkdefaults to 16 KB)
Okay, now that we have our new RandomStream constructor ready, we can proceed with implementing the _read() method:
RandomStream.prototype._read = function(size) {
var chunk = chance.string(); //[1]
console.log('Pushing chunk of size:' + chunk.length);
this.push(chunk, 'utf8'); //[2]
if(chance.bool({likelihood: 5})) { //[3]
this.push(null);
}
}
module.exports = RandomStream;The preceding method is explained as follows:
- The method generates a random string using
chance. - It pushes the string into the internal reading buffer. Note that, since we are pushing a
String, we also specify the encoding,utf8(this is not necessary if the chunk is simply a binaryBuffer). - It terminates the stream randomly, with a likelihood of 5 percent, by pushing
nullinto the internal buffer to indicate anEOFsituation or, in other words, the end of the stream.
We can also see that the size argument given in input to the _read() function is ignored, as it is an advisory parameter. We can simply just push all the available data, but if there are multiple pushes inside the same invocation, then we should check whether push() returns false, as this would mean that the internal buffer has reached the highWaterMark limit and we should stop adding more data to it.
That's it for RandomStream; we are not ready to use it. Let's create a new module named generateRandom.js in which we instantiate a new RandomStream object and pull some data from it:
var RandomStream = require('./randomStream');
var randomStream = new RandomStream();
randomStream.on('readable', function() {
var chunk;
while((chunk = randomStream.read()) !== null) {
console.log("Chunk received: " + chunk.toString());
}
});Now, everything is ready for us to try our new custom stream. Simply execute the generateRandom module as usual and watch a random set of strings flowing on the screen.
A writable stream represents a data destination; in Node.js, it's implemented using the Writable abstract class, which is available in the stream module.
Pushing some data down a writable stream is a straightforward business; all we need to do is to use the write() method, which has the following signature:
writable.write(chunk, [encoding], [callback])
The encoding argument is optional and can be specified if chunk is String (defaults to utf8, ignored if chunk is Buffer); the callback function instead is called when the chunk is flushed into the underlying resource and is optional as well.
To signal that no more data will be written to the stream, we have to use the end() method:
writable.end([chunk], [encoding], [callback])
We can provide a final chunk of data through the end() method; in this case the callback function is equivalent to registering a listener to the finish event, which is fired when all the data written in the stream has been flushed into the underlying resource.
Now, let's show how this works by creating a small HTTP server that outputs a random sequence of strings:
var chance = require('chance').Chance();
require('http').createServer(function (req, res) {
res.writeHead(200, {'Content-Type': 'text/plain'}); //[1]
while(chance.bool({likelihood: 95})) { //[2]
res.write(chance.string() + '\n'); //[3]
}
res.end('\nThe end...\n'); //[4]
res.on('finish', function() { //[5]
console.log('All data was sent');
});
}).listen(8080, function () {
console.log('Listening');
});The HTTP server that we created writes into the res object, which is an instance of http.ServerResponse and also a Writable stream. What happens is explained as follows:
- We first write the head of the HTTP response. Note that
writeHead()is not a part of theWritableinterface; in fact, it's an auxiliary method exposed by thehttp.ServerResponseclass. - We start a loop that terminates with a likelihood of five percent (we instruct
chance.bool()to returntruefor 95 percent of the time). - Inside the loop, we write a random string into the stream.
- Once we are out of the loop, we call
end()on the stream, indicating that no more data will be written. Also, we provide a final string to be written into the stream before ending it. - Finally, we register a listener for the
finishevent, which will be fired when all the data has been flushed into the underlying socket.
We can call this small module, entropyServer.js, and then execute it. To test the server, we can open a browser at the address http://localhost:8080, or use curl from the terminal as follows:
curl localhost:8080
At this point, the server should start sending random strings to the HTTP client that you chose (please bear in mind that some browsers might buffer the data, and the streaming behavior might not be apparent).
Note
An interesting curiosity is the fact that http.ServerResponse is actually an instance of the old Stream class (http://nodejs.org/docs/v0.8.0/api/stream.html). It's important to state, though, that this does not affect our example, as the interface and behavior on the writable side remain almost the same in the newer stream.Writable class.
Similar to a liquid flowing in a real piping system, Node.js streams can also suffer from bottlenecks, where data is written faster than the stream can consume it. The mechanism to cope with this problem consists of buffering the incoming data; however, if the stream doesn't give any feedback to the writer, we might incur a situation where more and more data is accumulated into the internal buffer, leading to undesired levels of memory usage.
To prevent this from happening, writable.write() will return false when the internal buffer exceeds the highWaterMark limit. The Writable streams have a highWaterMark property, which is the limit of the internal buffer size beyond which the write() method starts returning false, indicating that the application should now stop writing. When the buffer is emptied, the drain event is emitted, communicating that it's safe to start writing again. This mechanism is called
back-pressure.
Note
The mechanism described in this section is similarly applicable to Readable streams. In fact, back-pressure exists in the Readable streams too, and it's triggered when the push() method, which is invoked inside _read(), returns false. However, it's a problem specific to stream implementers, so we will deal with it less frequently.
We can quickly demonstrate how to take into account the back-pressure of a Writable stream, by modifying the entropyServer that we created before:
var chance = require('chance').Chance();
require('http').createServer(function (req, res) {
res.writeHead(200, {'Content-Type': 'text/plain'});
function generateMore() { //[1]
while(chance.bool({likelihood: 95})) {
var shouldContinue = res.write(
chance.string({length: (16 * 1024) – 1}) //[2]
);
if(!shouldContinue) { //[3]
console.log('Backpressure');
return res.once('drain', generateMore);
}
}
res.end('\nThe end...\n', function() {
console.log('All data was sent');
});
}
generateMore();
}).listen(8080, function () {
console.log('Listening');
});The most important steps of the previous code can be summarized as follows:
- We wrapped the main logic into a function called
generateMore(). - To increase the chances of receiving some back-pressure, we increased the size of the data chunk to 16 KB - 1 Byte, which is very close to the default
highWaterMarklimit. - After writing a chunk of data, we check the return value of
res.write(); if we receivefalse,it means that the internal buffer is full and we should stop sending more data. In this case, we exit from the function, and register another cycle of writes for when thedrainevent is emitted.
If we now try to run the server again, and then generate a client request with curl, there is a good probability that there will be some back-pressure, as the server produces data at a very high rate, faster than the underlying socket can handle.
We can implement a new Writable stream by inheriting the prototype of stream.Writable and providing an implementation for the _write() method. Let's try to do it immediately while discussing the details along the way.
Let's build a Writable stream that receives objects in the following format:
{
path: <path to a file>
content: <string or buffer>
}For each one of these objects, our stream has to save the content part into a file created at the given path. We can immediately see that the input of our stream are objects, and not strings or buffers; this means that our stream has to work in object mode.
Let's call the module toFileStream.js and, as the first step, let's load all the dependencies that we are going to use:
var stream = require('stream');
var fs = require('fs');
var util = require('util');
var path = require('path');
var mkdirp = require('mkdirp');Next, we have to create the constructor of our new stream, which inherits the prototype from stream.Writable:
function ToFileStream() {
stream.Writable.call(this, {objectMode: true});
};
util.inherits(ToFileStream, stream.Writable);Again, we had to invoke the parent constructor to initialize its internal state; we also provide an options object that specifies that the stream works in an object mode (objectMode: true). Other options accepted by stream.Writable are as follows:
Finally, we need to provide an implementation for the _write() method:
ToFileStream.prototype._write = function(chunk, encoding, callback) {
var self = this;
mkdirp(path.dirname(chunk.path), function(err) {
if(err) {
return callback(err);
}
fs.writeFile(chunk.path, chunk.content, callback);
});
}
module.exports = ToFileStream;This is a good time to analyze the signature of the _write() method. As you can see, the method accepts a data chunk, an encoding (which makes sense only if we are in the binary mode and the stream option decodeStrings is set to false). Also, the method accepts a callback function, which needs to be invoked when the operation completes; it's not necessary to pass the result of the operation but, if needed, we can still pass an error that will cause the stream to emit an error event.
Now, to try the stream that we just built, we can create a new module, called for example, writeToFile.js, and perform some write operations against the stream:
var ToFileStream = require('./toFileStream');
var tfs = new ToFileStream();
tfs.write({path: "file1.txt", content: "Hello"});
tfs.write({path: "file2.txt", content: "Node.js"});
tfs.write({path: "file3.txt", content: "Streams"});
tfs.end(function() {
console.log("All files created");
});With this, we created and used our first custom Writable stream. Run the new module as usual to check its output.
A Duplex stream is a stream that is both Readable and Writable. It is useful when we want to describe an entity that is both a data source and a data destination, as for example, network sockets. Duplex streams inherit the methods of both stream.Readable and stream.Writable, so this is nothing new to us. This means that we can read() or write() data, or listen for both the readable and drain events.
To create a custom Duplex stream, we have to provide an implementation for both _read() and _write(); the options object passed to the Duplex() constructor is internally forwarded to both the Readable and Writable constructors. The options are the same as those we already discussed in the previous sections, with the addition of a new one called allowHalfOpen (defaults to true) that if set to false will cause both the parts (Readable and Writable) of the stream to end if only one of them does.
The Transform streams are a special kind of Duplex stream that are specifically designed to handle data transformations.
In a simple Duplex stream, there is no immediate relationship between the data read from the stream and the data written into it (at least, the stream is agnostic to such a relationship). Think about a TCP socket, which just sends and receives data to and from the remote peer; the socket is not aware of any relationship between the input and output. The following diagram illustrates the data flow in a Duplex stream:
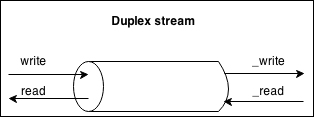
On the other side, Transform streams apply some kind of transformation to each chunk of data that they receive from their Writable side and then make the transformed data available on their Readable side. The following diagram shows how the data flows in a Transform stream:
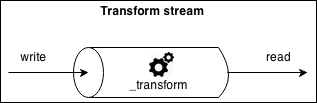
From the outside, the interface of a Transform stream is exactly like that of a Duplex stream. However, when we want to build a new Duplex stream we have to provide the _read() and _write() methods while, for implementing a new Transform stream, we have to fill in another pair of methods: _transform() and _flush().
Let's show how to create a new Transform stream with an example.
Let's implement a Transform stream that replaces all the occurrences of a given string. To do this, we have to create a new module named replaceStream.js. As always, we will start building the module from its dependencies, creating the constructor and extending its prototype with the parent stream class:
var stream = require('stream');
var util = require('util');
function ReplaceStream(searchString, replaceString) {
stream.Transform.call(this, {decodeStrings: false});
this.searchString = searchString;
this.replaceString = replaceString;
this.tailPiece = '';
}
util.inherits(ReplaceStream, stream.Transform);We assume that the stream will handle only text, so we initialize the parent constructor by setting the decodeStrings options to false; this allows us to receive strings instead of buffers inside the _transform() method.
Now, let's implement the _transform() method itself:
ReplaceStream.prototype._transform = function(chunk, encoding,
callback) {
var pieces = (this.tailPiece + chunk) //[1]
.split(this.searchString);
var lastPiece = pieces[pieces.length - 1];
var tailPieceLen = this.searchString.length - 1;
this.tailPiece = lastPiece.slice(-tailPieceLen); //[2]
pieces[pieces.length - 1] = lastPiece.slice(0, -tailPieceLen);
this.push(pieces.join(this.replaceString)); //[3]
callback();
}The _transform() method has practically the same signature as that of the _write() method of the Writable stream but, instead of writing data into an underlying resource, it pushes it into the internal buffer using this.push(), exactly as we would do in the _read() method of a Readable stream. This confirms how the two sides of a Transform stream are actually connected.
The _trasform() method of ReplaceStream implements the core of our algorithm. To search and replace a string in a buffer is an easy task; however, it's a totally different story when the data is streaming and possible matches might be distributed across multiple chunks. The procedure followed by the code can be explained as follows:
- Our algorithm splits the chunk using the
searchStringfunction as a separator. - Then, it takes the last item of the array generated by the operation and extracts the last
searchString.length - 1characters. The result is saved into thetailPiecevariable and it will be prepended to the next chunk of data. - Finally, all the pieces resulting from
split()are joined together usingreplaceStringas a separator and pushed into the internal buffer.
When the stream ends, we might still have a last tailPiece variable not pushed into the internal buffer. That's exactly what the _flush() method is for; it is invoked just before the stream is ended and this is where we have one final chance to finalize the stream or push any remaining data before completely ending the stream. Let's implement it to complete our ReplaceStream class:
ReplaceStream.prototype._flush = function(callback) {
this.push(this.tailPiece);
callback();
}
module.exports = ReplaceStream;The _flush() method takes in only a callback that we have to make sure to invoke when all the operations are complete, causing the stream to be terminated. With this, we completed our ReplaceStream class.
Now, it's time to try the new stream. We can create another module called replaceStreamTest.js that writes some data and then reads the transformed result:
var ReplaceStream = require('./replaceStream');
var rs = new ReplaceStream('World', 'Node.js');
rs.on('data', function(chunk) {
console.log(chunk);
});
rs.write('Hello W');
rs.write('orld!');
rs.end();To make life a little bit harder for our stream, we spread the search term (which is World) across two different chunks; then using the flowing mode we read from the same stream, logging each transformed chunk. Running the preceding program should produce the following output:
Hel lo Node.js !
Note
There is a fifth type of stream that is worth mentioning: stream.PassThrough. Unlike the other stream classes that we presented, PassThrough is not abstract and can be instantiated straightaway without the need to implement any method. It is, in fact, a Transform stream that outputs every data chunk without applying any transformation.
The concept of Unix pipes was invented by Douglas Mcllroy; this enabled the output of a program to be connected to the input of the next. Take a look at the following command:
echo Hello World! | sed s/World/Node.js/g
In the preceding command, echo will write Hello World! to its standard output, which is then redirected to the standard input of the sed command (thanks to the pipe | operator); then sed replaces any occurrence of World with Node.js and prints the result to its standard output (which, this time, is the console).
In a similar way, Node.js streams can be connected together using the pipe() method of the Readable stream, which has the following interface:
readable.pipe(writable, [options])
Very intuitively, the pipe() method takes the data that is emitted from the readable stream and pumps it into the provided writable stream. Also, the writable stream is ended automatically when the readable stream emits an end event (unless, we specify {end: false} as options). The pipe() method returns the writable stream passed as an argument allowing us to create chained invocations if such a stream is also Readable (as for example a Duplex or Transform stream).
Piping two streams together will create a suction which allows the data to flow automatically to the writable stream, so there is no need to call read() or write(); but most importantly there is no need to control the back-pressure anymore, because it's automatically taken care of.
To make a quick example (there will be tons of them coming), we can create a new module called replace.js which takes a text stream from the standard input, applies the replace transformation, and then pushes the data back to the standard output:
var ReplaceStream = require('./replaceStream');
process.stdin
.pipe(new ReplaceStream(process.argv[2], process.argv[3]))
.pipe(process.stdout);The preceding program pipes the data that comes from the standard input into a ReplaceStream and then back to the standard output. Now, to try this small application, we can leverage a Unix pipe to redirect some data into its standard input, as shown in the following example:
echo Hello World! | node replace World Node.js
This should produce the following output:
Hello Node.js
This simple example demonstrates that streams (and in particular text streams) is an universal interface, and pipes are the way to compose and interconnect almost magically all these interfaces.
Note
The error events are not propagated automatically through the pipeline. Take for example this code fragment:
stream1
.pipe(stream2)
.on('error', function() {});In the preceding pipeline, we will catch only the errors coming from stream2, which is the stream that we attached the listener to. This means that, if we want to catch any error generated from stream1, we have to attach another error listener directly to it. We will later see a pattern that mitigates this inconvenience (combining streams). Also, we should notice that if the destination stream emits an error it gets automatically unpiped from the source stream, causing the pipeline to break.
We now present some npm packages that might be very useful when working with streams.
We already mentioned how the streams interface changed considerably between the 0.8 and 0.10 branches of Node.js. Traditionally, the interface supported until Node.js 0.8 is called Streams1, while the newer interface supported by Node.js 0.10 is called Streams2. The core team did a great job in maintaining backward-compatibility, so that applications implemented using the Streams1 interface will continue to work with the 0.10 branch; however, the vice versa is not true, so using Streams2 against Node.js 0.8 will not work. Also, the upcoming 0.12 release will probably be shipped with a new version of the stream interface, Streams3, and so on until the interface stabilizes.
Note
The streams interface, as of version 0.10, is still marked as unstable on the official documentation (http://nodejs.org/docs/v0.10.0/api/stream.html).
Thankfully, we have an option to shield our code from these changes; it's called readable-stream (https://npmjs.org/package/readable-stream), a npm package that mirrors the Streams2 and Streams3 implementations of the Node.js core. In particular, using the 1.0 branch of readable-stream we can have the Streams2 interface available even if we run our code against Node.js 0.8. If instead we choose the 1.1 branch (probably 1.2 when Node.js 0.12 will be released) we get the Streams3 interface regardless of the version of the Node.js platform used.
The readable-stream package is a drop-in replacement for the core stream module (depending on the version), so using it is as simple as requiring readable-stream instead of stream:
var stream = require('readable-stream');
var Readable = stream.Readable;
var Writable = stream.Writable;
var Duplex = stream.Duplex;
var Transform = stream.Transform;Protecting our libraries and applications from the changes of the still unstable streams interface can greatly reduce the defects that originate from platform incompatibilities.
Note
For a detailed rationale on the use of readable-stream you can refer to this excellent article written by Rod Vagg: http://www.nearform.com/nodecrunch/dont-use-nodes-core-stream-module/
The way we created custom streams so far does not exactly follow the Node way; in fact, inheriting from a base stream class violates the small surface area principle and requires some boilerplate code. This does not mean that streams were badly designed; in fact, we should not forget that since they are a part of the Node.js core they must be as flexible as possible in order to enable userland modules to extend them for a broad range of purposes.
However, most of the time we don't need all the power and extensibility that prototypal inheritance can give, but usually what we want is just a quick and an expressive way to define new streams. The Node.js community, of course, created a solution also for this. A perfect example is through2 (https://npmjs.org/package/through2), a small library which simplifies the creation of Transform streams. With through2, we can create a new Transform stream by invoking a simple function:
var transform = through2([options], [_transform], [_flush])
In a similar way, from2 (https://npmjs.org/package/from2) allows us to easily and succinctly create Readable streams with code such as the following:
var readable = from2([options], _read)
The advantages of using these little libraries will be immediately clear as soon as we start showing their usage in the rest of the chapter.
Note
The packages through (https://npmjs.org/package/through) and from (https://npmjs.org/package/from) are the original libraries built on top of Streams1.