In high-load applications, caching plays a critical role and is used almost everywhere in the web, from static resources such as web pages, images, and stylesheets, to pure data such as the result of database queries. In this section, we are going to learn how caching applies to asynchronous operations and how a high request throughput can be turned to our advantage.
Before we start diving into this new challenge, let's implement a small demo server that we will use as a reference to measure the impact of the various techniques we are going to implement.
Let's consider a web server that manages the sales of an e-commerce company, in particular, we want to query our server for the sum of all the transactions of a particular type of merchandise. For this purpose, we are going to use LevelUP again for its simplicity and flexibility. The data model that we are going to use is a simple list of transactions stored in the sales sublevel (a section of the database), which is organized in the following format:
transactionId à {amount, item}The key is represented by transactionId and the value is a JSON object that contains the amount of the sale (amount) and the item type.
The data to process is really basic, so let's implement the API immediately in a file named totalSales.js, which will be as follows:
var level = require('level');
var sublevel = require('level-sublevel');
var db = sublevel(level('example-db', {valueEncoding: 'json'}));
var salesDb = db.sublevel('sales');
module.exports = function totalSales(item, callback) {
var sum = 0;
salesDb.createValueStream() //[1]
.on('data', function(data) {
if(!item || data.item === item) { //[2]
sum += data.amount;
}
})
.on('end', function() {
callback(null, sum); //[3]
});
}The core of the module is the totalSales function, which is also the only exported API, this is how it works:
- We create a stream from the
salesDbsublevel that contains the sales transactions. The stream pulls all the entries from the database. - The
dataevent receives each sale transaction as it is returned from the database stream. We add theamountvalue of the current entry to the totalsumvalue, but only if theitemtype is equal to the one provided in the input (or if no input is provided at all, allowing us to calculate the sum of all the transactions, regardless of theitemtype). - At last, when the
endevent is received, we invoke thecallback()method by providing the finalsumas result.
The simple query that we built is definitely not the best in terms of performances. Ideally, in a real-world application, we would have used an index to query the transactions by the item type, or even better, an incremental map/reduce to calculate the sum in real time; however, for our example, a slow query is actually better as it will highlight the advantages of the patterns we are going to analyze.
To finalize the total sales application, we only need to expose the totalSales API from an HTTP server; so, the next step is to build one (the app.js file):
var http = require('http');
var url = require('url');
var totalSales = require('./totalSales');
http.createServer(function(req, res) {
var query = url.parse(req.url, true).query;
totalSales(query.item, function(err, sum) {
res.writeHead(200);
res.end('Total sales for item ' +
query.item + ' is ' + sum);
});
}).listen(8000, function() {console.log('Started')});The server we created is very minimalistic; we only need it to expose the totalSales API.
Before we start the server for the first time, we need to populate the database with some sample data; we can do this with the populate_db.js script that we can find in the code samples dedicated to this section. The script will create 100 K random sales transactions in the database.
Okay! Now, everything is ready in order to start the server; as usual we can do this by executing the following command:
node app
To query the server, simply navigate with a browser to the following URL:
http://localhost:8000?item=book
However, to have a better idea of the performance of our server, we will need more than one request; so, we will use a small script named loadTest.js which sends requests at an interval of 200 ms. The script can be found in the code samples of the book and it's already configured to connect to the URL of the server, so, to run it, just execute the following command:
node loadTest
We will see that the 20 requests will take a while to complete, take note of the total execution time of the test, because we are now going to apply our optimizations and measure how much time we can save.
When dealing with asynchronous operations, the most basic level of caching can be achieved by batching together a set of invocations to the same API. The idea is very simple: if we are invoking an asynchronous function while there is still another one pending, we can attach the callback to the already running operation, instead of creating a brand new request. Take a look at the following figure:

The previous image shows two clients (they can be two different objects, or two different web requests) invoking the same asynchronous operation with exactly the same input. Of course, the natural way to picture this situation is with the two clients starting two separate operations that will complete in two different moments, as shown by the preceding image. Now, consider the next scenario, depicted in the following figure:
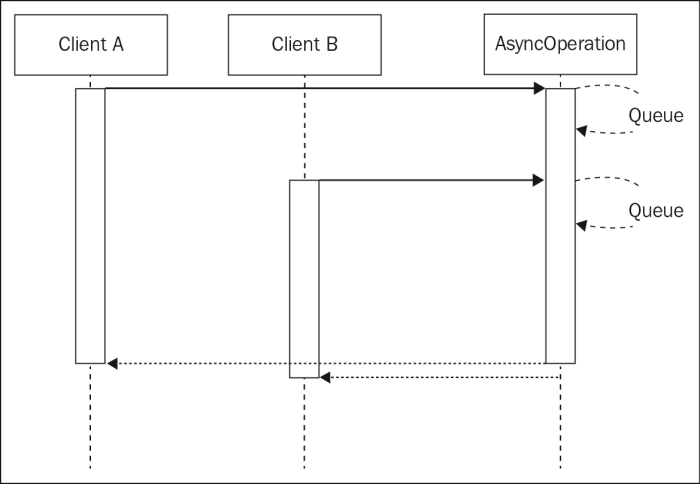
This second image shows us how the two requests—which invoke the same API with the same input—can be batched, or in other words appended to the same running operation. By doing this, when the operation completes, both the clients will be notified. This represents a simple, yet extremely powerful, way to optimize the load of an application while not having to deal with more complex caching mechanisms, which usually require an adequate memory management and invalidation strategy.
Let's now add a batching layer on top of our totalSales API. The pattern we are going to use is very simple: if there is already another identical request pending when the API is invoked, we will add the callback to a queue. When the asynchronous operation completes, all the callbacks in its queue are invoked at once.
Now, let's see how this pattern translates in code. Let's create a new module named totalSalesBatch.js. Here, we're going to implement a batching layer on top of the original totalSales API:
var totalSales = require('./totalSales');
var queues = {};
module.exports = function totalSalesBatch(item, callback) {
if(queues[item]) { //[1]
console.log('Batching operation');
return queues[item].push(callback);
}
queues[item] = [callback]; //[2]
totalSales(item, function(err, res) {
var queue = queues[item]; //[3]
queues[item] = null;
queue.forEach(function(cb) {
cb(err, res);
});
});
}The totalSalesBatch() function is a proxy for the original totalSales() API, and it works as follows:
- If a queue already exists for the
itemtype provided as the input, it means that a request for that particularitemis already running. In this case, all we have to do is simply append thecallbackto the existing queue and return from the invocation immediately. Nothing else is required. - If no queue is defined for the item, it means that we have to create a new request. To do this, we create a new queue for that particular
itemand we initialize it with the currentcallbackfunction. Next, we invoke the originaltotalSales()API. - When the original
totalSales()request completes, we iterate over all the callbacks that were added in the queue for that specificitemand invoke them one by one with the result of the operation.
The behavior of the totalSalesBatch() function is identical to that of the original totalSales() API, with the difference that, now, multiple calls to the API using the same input are batched, thus saving time and resources.
Curious to know what is the performance improvement compared to the raw, non-batched version of the totalSales() API? Let's then replace the totalSales module used by the HTTP server with the one we just created (the app.js file):
//var totalSales = require('./totalSales');
var totalSales = require('./totalSalesBatch');
http.createServer(function(req, res) {
[...]If we now try to start the server again and run the load test against it, the first thing we will see is that the requests are returned in batches. This is the effect of the pattern we just implemented and it's a great practical demonstration of how it works.
Besides that, we should also observe a considerable reduction in the total time for executing the test; it should be at least four times faster than the original test performed against the plain totalSales() API!
This is a stunning result, confirming the huge performance boost we can obtain by just applying a simple batching layer, without all the complexity of managing a full-fledged cache, and more importantly, without worrying about invalidation strategies.
One of the problems with the request-batching pattern is that the faster the API, the fewer batched requests we get. One can argue that if an API is already fast, there is no point in trying to optimize it; however, it still represents a factor in the resource load of an application that, when summed up, can still have a substantial impact. Also, sometimes we can safely assume that the result of an API invocation will not change so often; therefore, a simple request batching will not provide the best performances. In all these circumstances, the best candidate to reduce the load of an application and increase its responsiveness is definitely a more aggressive caching pattern.
The idea is simple: as soon as a request completes, we store its result in the cache, which can be a variable, an entry in the database, or in a specialized caching server. Hence, the next time the API is invoked, the result can be retrieved immediately from the cache, instead of spawning another request.
The idea of caching should not be new to an experienced developer, but what makes this pattern different in asynchronous programming is that it should be combined with the request batching, to be optimal. The reason is because multiple requests might run concurrently while the cache is not set, and when those requests complete, the cache will be set multiple times.
Based on these assumptions, the final structure of the asynchronous request-caching pattern is shown in the following figure:
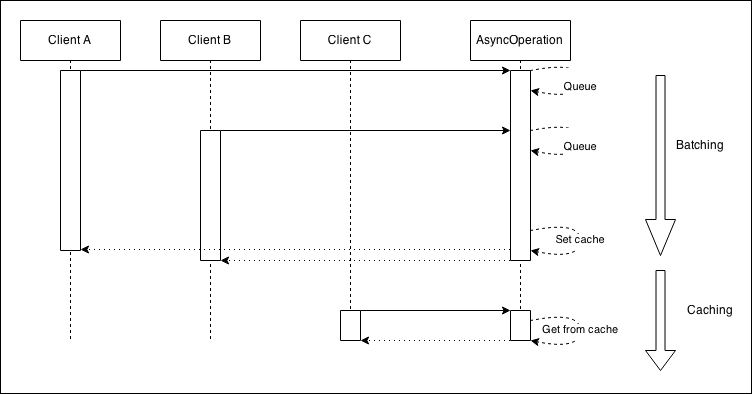
The preceding figure shows us the two phases of an optimal asynchronous caching algorithm:
- The first phase is totally identical to the batching pattern. Any request received while the cache is not set will be batched together. When the request completes, the cache is set, once.
- When the cache is finally set, any subsequent request will be served directly from it.
Another crucial detail to consider is the unleashing Zalgo anti-pattern (we have seen it in action in Chapter 1, Node.js Design Fundamentals). As we are dealing with asynchronous APIs, we must be sure to always return the cached value asynchronously, even if accessing the cache involves only a synchronous operation.
To demonstrate and measure the advantages of the asynchronous caching pattern, let's now apply what we've learned to the totalSales() API. As in the request-batching example, we have to create a proxy for the original API with the sole purpose of adding a caching layer.
Let's then create a new module named totalSalesCache.js that contains the following code:
var totalSales = require('./totalSales');
var queues = {};
var cache = {};
module.exports = function totalSalesBatch(item, callback) {
var cached = cache[item]; //[1]
if(cached) {
console.log('Cache hit');
return process.nextTick(callback.bind(null, null, cached));
}
if(queues[item]) {
console.log('Batching operation');
return queues[item].push(callback);
}
queues[item] = [callback];
totalSales(item, function(err, res) {
if(!err) { //[2]
cache[item] = res;
setTimeout(function() {
delete cache[item];
}, 30 * 1000); //30 seconds expiry
}
var queue = queues[item];
queues[item] = null;
queue.forEach(function(cb) {
cb(err, res);
});
});
}We should straightaway see that the preceding code is in many parts identical to what we used for the asynchronous batching. In fact, the only differences are the following ones:
- The first thing that we need to do when the API is invoked is to check whether the cache is set and if that's the case, we will immediately return the cached value using
callback(), making sure to defer it withprocess.nextTick(). - The execution continues in batching mode, but this time, when the original API successfully completes, we save the result into the cache. We also set a timeout to invalidate the cache after 30 seconds. A simple but effective technique!
Now, we are ready to try the totalSales wrapper we just created; to do that, we only need to update the app.js module as follows:
//var totalSales = require('./totalSales');
//var totalSales = require('./totalSalesBatch');
var totalSales = require('./totalSalesCache');
http.createServer(function(req, res) {
[...]Now, the server can be started again and profiled using the loadTest.js script as we did in the previous examples. With the default test parameters, we should see a 10-percent reduction in the execution time as compared to simple batching. Of course, this is highly dependent on a lot of factors; for example, the number of requests received, and the delay between one request and the other. The advantages of using caching over batching will be much more substantial when the amount of requests is higher and spans a longer period of time.
Note
Memoization is the practice of caching the result of a function invocation. In npm, you can find many packages to implement asynchronous memoization with little effort; one of the most complete packages is memoizee (https://npmjs.org/package/memoizee).
We must remember that in real-life applications, we might want to use more advanced invalidation techniques and storage mechanisms. This might be necessary for the following reasons:
- A large amount of cached values might easily consume a lot of memory. In this case, a Least Recently Used (LRU) algorithm can be applied to maintain constant memory utilization.
- When the application is distributed across multiple processes, using a simple variable for the cache might result in different results to be returned by each server instance. If that's undesired for the particular application we are implementing, the solution is to use a shared store for the cache. Popular solutions are Redis (http://redis.io) and Memcached (http://memcached.org).
- A manual cache invalidation, as opposed to a timed expiry, can enable a longer-living cache and at the same time provide more up-to-date data, but, of course, it would be a lot more complex to manage.
In Chapter 2, Asynchronous Control Flow Patterns, we saw how Promises can greatly simplify our asynchronous code, but they offer an even more interesting application when dealing with batching and caching. If we recall what we said about Promises, there are two properties that can be exploited to our advantage in this circumstance:
- Multiple
then()listeners can be attached to the same promise. - The
then()listener is guaranteed to be invoked at most once and it works even if it's attached after the promise is already resolved. Moreover,then()is guaranteed to be invoked asynchronously, always.
In short, the first property is exactly what we need for batching requests, while the second means that a promise is already a cache for the resolved value and offers a natural mechanism for returning a cached value in a consistent asynchronous way. In other words, this means that batching and caching are extremely simple and concise with Promises.
To demonstrate this, we can try to create a wrapper for the totalSales() API, using Promises, and see what it takes to add a batching and caching layer. Let's see then how this looks like. Let's create a new module named totalSalesPromises.js:
var totalSales = require('./totalSales');
var Promise = require('bluebird'); //[1]
totalSales = Promise.promisify(totalSales);
var cache = {};
module.exports = function totalSalesPromises(item) {
if(cache[item]) { //[2]
return cache[item];
}
cache[item] = totalSales(item) //[3]
.then(function(res) { //[4]
setTimeout(function() {
delete cache[item];
}, 30 * 1000); //30 seconds expiry
return res;
})
.catch(function(err) { //[5]
delete cache[item];
throw err;
});
return cache[item]; //[6]
}The first thing that strikes us is the simplicity and elegance of the solution we implemented in the preceding code. Promises are indeed a great tool, but for this particular application they offer a huge, out-of-the-box advantage. This is what happens in the preceding code:
- First, we require our Promise implementation (
bluebird) and then apply a promisification to the originaltotalSales()function. After doing this,totalSales()will return a Promise instead of accepting a callback. - When the
totalSalesPromises()wrapper is invoked, we check whether a cached Promise already exists for the givenitemtype. If we already have such a Promise, we return it back to the caller. - If we don't have a Promise in the cache for the given
itemtype, we proceed to create one by invoking the original (promisified)totalSales()API. - When the Promise resolves, we set up a time to clear the cache after 30 seconds and we return
resto propagate the result of the operation to any otherthen()listener attached to the Promise. - If the Promise rejects with an error, we immediately reset the cache and throw the error again to propagate it to the promise chain, so any other listener attached to the same Promise will receive the error as well.
- At last, we return the cached promise we just created.
Very simple and intuitive, and more importantly, we were able to achieve both batching and caching.
If we now want to try the totalSalesPromise() function, we will have to slightly adapt the app.js module as well, because now, the API is using Promises instead of callbacks. Let's do it by creating a modified version of the app module named appPromises.js:
var http = require('http');
var url = require('url');
var totalSales = require('./totalSalesPromises');
http.createServer(function(req, res) {
var query = url.parse(req.url, true).query;
totalSales(query.item).then(function(sum) {
res.writeHead(200);
res.end('Total sales for item ' +
query.item + ' is ' + sum);
});
}).listen(8000, function() {console.log('Started')});Its implementation is almost identical to the original app module with the difference that now we use the Promise-based version of the batching/caching wrapper; therefore, the way we invoke it is also slightly different.
That's it! We are now ready to try this new version of the server by running the following command:
node appPromises
Using the loadTest script, we can verify that the new implementation is working as expected. The execution time should be the same as when we tested the server using the totalSalesCache() API.