In Chapter 6, Recipes, we learned how to delegate costly tasks to multiple local processes, but even though this was an effective approach, it cannot be scaled beyond the boundaries of a single machine. In this section, we are going to see how it's possible to use a similar pattern in a distributed architecture, using remote workers, located anywhere in a network.
The idea is to have a messaging pattern that allows us to spread tasks across multiple machines. These tasks might be individual chunks of work or pieces of a bigger task split using a divide and conquer technique.
If we look at the logical architecture represented in the following figure, we should be able to recognize a familiar pattern:
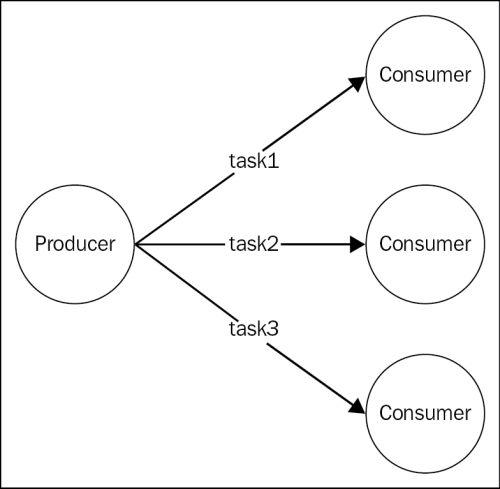
As we can see from the preceding diagram, the publish/subscribe pattern is not suitable for this type of application, as we absolutely don't want a task to be received by multiple workers. What we need instead, is a message distribution pattern similar to a load balancer, that dispatches each message to a different consumer (also called worker, in this case). In the messaging systems terminology, this pattern is known as competing consumers, fan-out distribution, or ventilator.
One important difference with the HTTP load balancers we have seen in the previous chapter, is that, here, the consumers have a more active role. In fact, as we will see later, most of the time it's not the producer that connects to the consumers, but they are the consumers themselves that connect to the task producer or the task queue in order to receive new jobs. This is a great advantage in a scalable system as it allows us to seamlessly increase the number of workers without modifying the producer or adopting a service registry.
Also, in a generic messaging system, we don't necessarily have a request/reply communication between the producer and workers. Instead, most of the time, the preferred approach is to use a one-way asynchronous communication, which enables a better parallelism and scalability. In such an architecture, messages can potentially travel always in one direction, creating pipelines, as shown in the following figure:
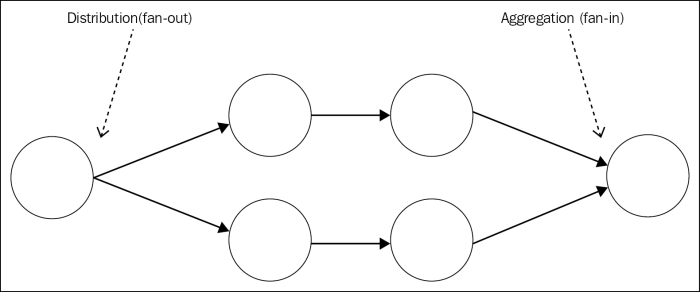
Pipelines allow us to build very complex processing architectures without the burden of a synchronous request/reply communication, often resulting in lower latency and higher throughput. In the preceding figure, we can see how messages can be distributed across a set of workers (fan-out), forwarded to other processing units, and then aggregated into a single node (fan-in), usually called sink.
In this section, we are going to focus on the building blocks of these kinds of architectures, by analyzing the two most important variations: peer-to-peer and broker-based.
We have already discovered some of the capabilities of ØMQ for building peer-to-peer distributed architectures. In the previous section, we used PUB and SUB sockets to disseminate a single message to multiple consumers; now we are going to see how it's possible to build parallel pipelines using another pair of sockets called PUSH and PULL.
Intuitively, we can say that the PUSH sockets are made for sending messages, while the PULL sockets are meant for receiving. It might seem a trivial combination; however, they have some nice characteristics that make them perfect for building one-way communication systems:
- Both can work in connect mode or bind mode. In other words, we can build a
PUSHsocket and bind it to a local port listening for the incoming connections from aPULLsocket, or vice versa, aPULLsocket might listen for connections from aPUSHsocket. The messages always travel in the same direction, fromPUSHtoPULL, it's only the initiator of the connection that can be different. The bind mode is the best solution for durable nodes, as for example, the task producer and the sink, while the connect mode is perfect for transient nodes, as for example, the task workers. This allows the number of transient nodes to vary arbitrarily without affecting the more durable nodes. - If there are multiple
PULLsockets connected to a singlePUSHsocket, the messages are evenly distributed across all thePULLsockets, in practice, they are load balanced (peer-to-peer load balancing!). On the other hand, aPULLsocket that receives messages from multiplePUSHsockets will process the messages using a fair queuing system, which means that they are consumed evenly from all the sources—a round-robin applied to inbound messages. - The messages sent over a
PUSHsocket that doesn't have any connectedPULLsocket, do not get lost; they are instead queued up on the producer until a node comes online and starts pulling the messages.
We are now starting to understand how ØMQ is different from traditional Web services and why it's a perfect tool for building any kind of messaging system.
Now, it's time to build a sample application to see in action the properties of the PUSH/PULL sockets we just described.
A simple and fascinating application to work with would be a hashsum cracker, a system that uses a brute force technique to try to match a given hashsum (MD5, SHA1, and so on) to every possible variation of characters of a given alphabet. This is an embarrassingly parallel workload (http://en.wikipedia.org/wiki/Embarrassingly_parallel), which is perfect for building an example demonstrating the power of parallel pipelines.
For our application, we want to implement a typical parallel pipeline with a node to create and distribute tasks across multiple workers, plus a node to collect all the results. The system we just described can be implemented in ØMQ using the following architecture:
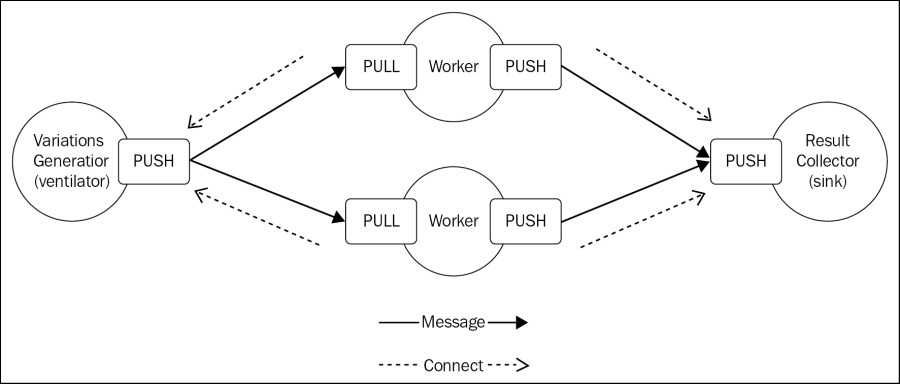
In our architecture, we have a ventilator generating all the possible variations of characters in a given alphabet and distributing them to a set of workers, which in turn calculate the hashsum of every given variation and try to match it against the hashsum given as the input. If a match is found, the result is sent to a results collector node (sink).
The durable nodes of our architecture are the ventilator and the sink, while the transient nodes are the workers. This means that each worker connects its PULL socket to the ventilator and its PUSH socket to the sink, this way we can start and stop how many workers we want without changing any parameter in the ventilator or the sink.
Now, let's start to implement our system by creating a new module for the ventilator, in a file named ventilator.js:
var zmq = require('zmq');
var variationsStream = require('variations-stream');
var alphabet = 'abcdefghijklmnopqrstuvwxyz';
var batchSize = 10000;
var maxLength = process.argv[2];
var searchHash = process.argv[3];
var ventilator = zmq.socket('push'); //[1]
ventilator.bindSync("tcp://*:5000");
var batch = [];
variationsStream(alphabet, maxLength)
.on('data', function(combination) {
batch.push(combination);
if(batch.length === batchSize) { //[2]
var msg = {searchHash: searchHash, variations: batch};
ventilator.send(JSON.stringify(msg));
batch = [];
}
})
.on('end', function() {
//send remaining combinations
var msg = {searchHash: searchHash, variations: batch};
ventilator.send(JSON.stringify(msg));
});To avoid generating too many variations, our generator uses only the lowercase letters of the English alphabet and sets a limit on the size of the words generated. This limit is provided in input as a command line argument (maxLength) together with the hashsum to match (searchHash). We use a library called variations-stream (https://npmjs.org/package/variations-stream) to generate all the variations using a streaming interface.
But the part that we are most interested in analyzing, is how we distribute the tasks across the workers:
- We first create a
PUSHsocket and we bind it to the local port5000, this is where thePULLsocket of the workers will connect to receive their tasks. - We group the generated variations in batches of 10,000 items each and then we craft a message that contains the hash to match and the batch of words to check. This is essentially the task object that the workers will receive. When we invoke
send()over theventilatorsocket, the message will be passed to the next available worker, following a round-robin distribution.
Now, it's time to implement the worker (worker.js):
var zmq = require('zmq');
var crypto = require('crypto');
var fromVentilator = zmq.socket('pull');
var toSink = zmq.socket('push');
fromVentilator.connect('tcp://localhost:5000');
toSink.connect('tcp://localhost:5001');
fromVentilator.on('message', function(buffer) {
var msg = JSON.parse(buffer);
var variations = msg.variations;
variations.forEach(function(word) {
console.log('Processing: ' + word);
var shasum = crypto.createHash('sha1');
shasum.update(word);
var digest = shasum.digest('hex');
if(digest === msg.searchHash) {
console.log('Found! => ' + word);
toSink.send('Found! ' + digest + ' => ' + word);
}
});
});As we said, our worker represents a transient node in our architecture, therefore its sockets should connect to a remote node instead of listening for the incoming connections. That's exactly what we do in our worker, we create two sockets:
- A
PULLsocket that connects to the ventilator, for receiving the tasks. - A
PUSHsocket that connects to the sink, for propagating the results.
Besides this, the job done by our worker is very simple: for each message received we iterate over the batch of words it contains, then for each word we calculate the SHA1 checksum and we try to match it against the searchHash passed with the message. When a match is found, the result is forwarded to the sink.
For our example, the sink is a very basic result collector, which simply prints the messages received by the workers to the console. The contents of the file sink.js are as follows:
var zmq = require('zmq')
var sink = zmq.socket('pull');
sink.bindSync("tcp://*:5001");
sink.on('message', function(buffer) {
console.log('Message from worker: ', buffer.toString());
});It's interesting to see that the sink (as the ventilator) is also a durable node of our architecture and therefore we bind its PULL socket instead of connecting it explicitly to the PUSH socket of the workers.
We are now ready to launch our application, let's start a couple of workers and the sink:
node worker node worker node sink
Then, it's time to start the ventilator, specifying the maximum length of the words to generate and the SHA1 checksum that we want to match. The following is a sample list of arguments:
node ventilator 4 f8e966d1e207d02c44511a58dccff2f5429e9a3b
When the preceding command is run, the ventilator will start generating all the possible words that have a length of at most four characters, distributing them to the set of workers we started, along with the checksum we provided. The results of the computation, if any, will appear in the terminal of the sink application.
In the previous section, we saw how a parallel pipeline can be implemented in a peer-to-peer context. Now we are going to explore this pattern when applied to a fully-fledged message broker, such as RabbitMQ.
In a peer-to-peer configuration, a pipeline is a very straightforward concept to picture in mind. With a message broker in the middle though, the relationship between the various nodes of the system are a little bit harder to understand; the broker itself acts as an intermediary for our communications and often, we don't really know who is on the other side listening for messages. For example, when we send a message using AMQP, we don't deliver it directly to its destination, but instead to an exchange and then to a queue. Finally, it will be for the broker to decide where to route the message, based on the rules defined in the exchange, the bindings, and the destination queues.
If we want to implement a pipeline and a task distribution pattern using a system like AMQP, we have to make sure that each message is received by only one consumer, but this is impossible to guarantee if an exchange can potentially be bound to more than one queue. The solution then, is to send a message directly to the destination queue, bypassing the exchange altogether, this way we can make sure that only one queue will receive the message. This communication pattern is called point-to-point.
Once we are able to send a set of messages directly to a single queue, we are already half-way to implementing our task distribution pattern. In fact, the next step comes naturally: when multiple consumers are listening on the same queue, the messages will be distributed evenly across them, implementing a fan-out distribution. In the context of message brokers, this is better known as the Competing Consumers pattern.
We just learned that exchanges are the point in a broker where a message is multicast to a set of consumers, while queues are the place where messages are load balanced. With this knowledge in mind, let's now implement our brute force hashsum cracker on top of an AMQP broker (as for example, RabbitMQ). The following figure gives an overview of the system we want to obtain:
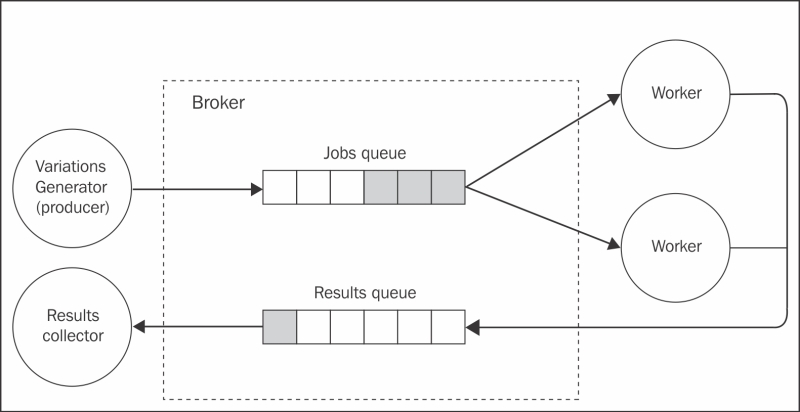
As we discussed, to distribute a set of tasks across multiple workers we need to use a single queue. In the preceding figure, we called this the jobs queue. On the other side of the jobs queue, we have a set of workers, which are competing consumers, in other words, each one will pull a different message from the queue. The result is that multiple tasks will execute in parallel on different workers.
Any result generated by the workers is published into another queue, which we called results queue, and then consumed by the results collector; this is actually equivalent to a sink, or fan-in distribution. In the entire architecture, we don't make use of any exchange, we only send messages directly to their destination queue, implementing a point-to-point communication.
Let's see how to implement such a system, starting from the producer (the variations generator). Its code is identical to the sample we have seen in the previous section except for the parts concerning the message exchange. The producer.js file will look as follows:
var amqp = require('amqplib');
[...]
var connection, channel;
amqp
.connect('amqp://localhost')
.then(function(conn) {
connection = conn;
return conn.createChannel();
})
.then(function(ch) {
channel = ch;
produce();
})
.catch(function(err) {
console.log(err);
});
function produce() {
[...]
variationsStream(alphabet, maxLength)
.on('data', function(combination) {
[...]
var msg = {searchHash: searchHash, variations: batch};
channel.sendToQueue('jobs_queue',
new Buf
fer(JSON.stringify(msg)));
[...]
}
})
[...]
}As we can see, the absence of any exchange or binding makes the setup of an AMQP communication much simpler. In the preceding code, we didn't even need a queue, as we are interested only in publishing a message.
The most important detail though, is the channel.sendToQueue()API, which is actually new to us. As its name says, that's the API responsible for delivering a message straight to a queue—jobs_queue in our example—bypassing any exchange or routing.
On the other side of the jobs_queue we have the workers listening for the incoming tasks. Let's implement their code in a file called worker.js, as follows:
var amqp = require('amqplib');
[...]
var channel, queue;
amqp
.connect('amqp://localhost')
.then(function(conn) {
return conn.createChannel();
})
.then(function(ch) {
channel = ch;
return channel.assertQueue('jobs_queue');
})
.then(function(q) {
queue = q.queue;
consume();
})
[...]
function consume() {
channel.consume(queue, function(msg) {
[...]
variations.forEach(function(word) {
[...]
if(digest === data.searchHash) {
console.log('Found! => ' + word);
channel.sendToQueue('results_queue',
new Buffer('Found! ' + digest + ' => ' + word));
}
[...]
});
channel.ack(msg);
});
};Our new worker is also very similar to the one we implemented in the previous section using ØMQ, except for the part related to the message exchange. In the preceding code, we can see how we first make sure that jobs_queue exists and then we start listening for incoming tasks using channel.consume(). Then, every time a match is found, we send the result to the collector via results_queue, using again a point-to-point communication.
If multiple workers are started, they will all listen on the same queue, resulting in the messages to be load balanced between them.
The results collector is again a trivial module, simply printing any message received to the console. This is implemented in the collector.js file, as follows:
[...]
.then(function(ch) {
channel = ch;
return channel.assertQueue('results_queue');
})
.then(function(q) {
queue = q.queue;
channel.consume(queue, function(msg) {
console.log('Message from worker: ', msg.content.toString());
});
})
[...]Now everything is ready to give our new system a try, we can start by running a couple of workers, which will both connect to the same queue (jobs_queue), so that every message will be load balanced between them:
node worker node worker
Then, we can run the collector module and then producer (by providing the maximum word length and the hash to crack):
node collector node producer 4 f8e966d1e207d02c44511a58dccff2f5429e9a3b
With this, we implemented a message pipeline and the competing consumers pattern using nothing but AMQP.