
There’s nothing like a good fall data harvest. An abundance of information ready to be examined, sorted, compared, combined, and generally made to do whatever it is your killer web app needs it to do. Fulfilling? Yes. But like real harvesting, taking control of data in a MySQL database requires some hard work and a fair amount of expertise. Web users demand more than tired old wilted data that’s dull and unengaging. They want data that enriches... data that fulfills... data that’s relevant. So what are you waiting for? Fire up your MySQL tractor and get to work!
The Mismatch application has a growing database of registered users but they’re ready to see some results. We need to allow users to find their ideal opposite by comparing their loves and hates against other users and looking for mismatches. For every love mismatched against a hate, a couple is that much closer to being the perfect mismatch.
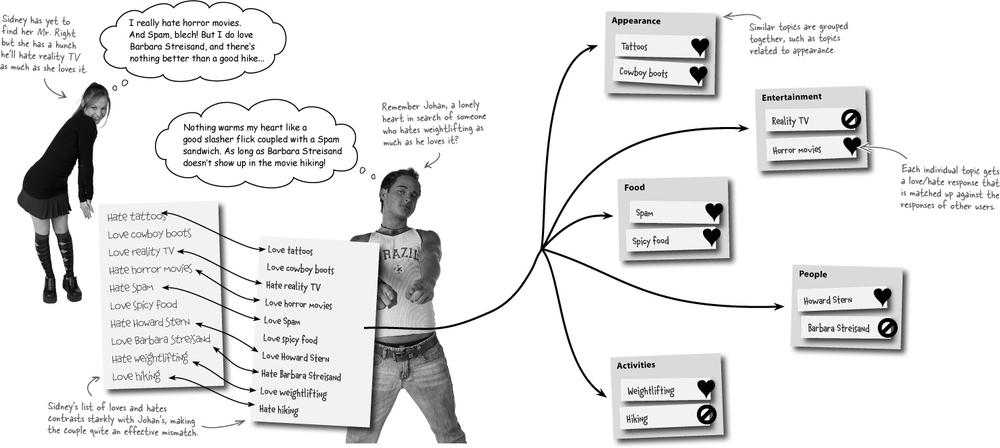
In order to carry out Mismatches between users, we must first figure out how to organize the data that keeps up with what they love and hate. Knowing that it’s going to be stored in a MySQL database isn’t enough. We need to organize these love/hate topics so that they are more manageable, allowing users to respond to related topics, indicating whether they love or hate each one.
Write down how you would organize the Mismatch data into discrete groups of data that could be stored in a database:
__________________________________
__________________________________
__________________________________
Coming up with a data model for an application such as Mismatch is an extremely important step, as it controls an awful lot about how the application is constructed. In the case of Mismatch, we can break down its data needs into three interrelated pieces of data.
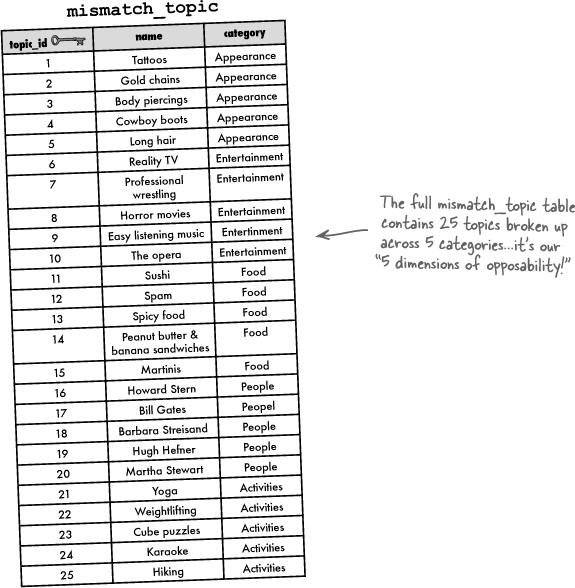
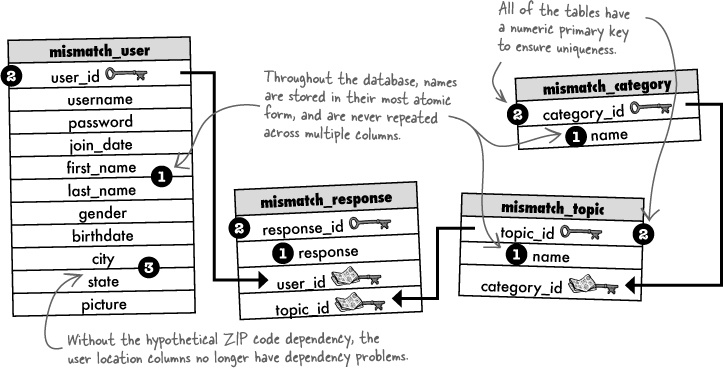
Categories are used to help organize topics. Although they don’t play a direct role in determining a mismatch, they will help make it easier for users to enter responses.
Mismatching takes place with respect to topics, such as tattoos or spicy food, each of which gets a user response—love or hate.
A user describes themselves for mismatching purposes by responding to topics. An individual response is just a love/hate answer to a topic.

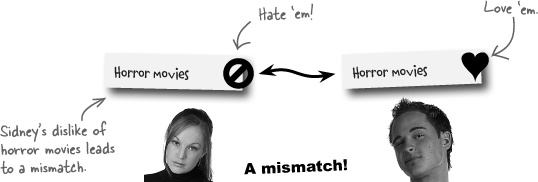
How exactly does this data lead to a mismatch between two users? We compare responses that users have made on each topic. For example, since Sidney and Johan have opposite responses to the topic “Horror movies,” we have a successful mismatch on that particular topic. Figuring the best overall mismatch for a given user involves finding the user who has the most mismatched topics with them.
In order to translate the data requirements of the Mismatch application into an actual database design, we need a schema. A schema is a representation of all the structures, such as tables and columns, in your database, along with how they connect. Creating a visual depiction of your database can help you see how things connect when you’re writing your queries, not to mention which specific columns are responsible for doing the connecting. As an example, let’s take a look at the schema for the original Mismatch database from the previous chapter, which consists of only a single table, mismatch_user.
A description of the data (the tables and columns) in your database, along with any other related objects and the way they all connect is known as a schema.
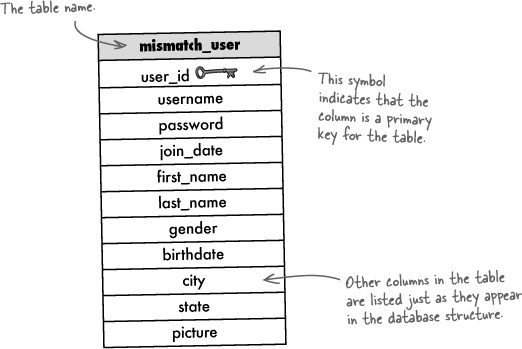
This way of looking at the structure of a table is a bit different than what you’ve seen up until now. Tables have normally been depicted with the column names across the top and the data below. That’s a great way to look at individual tables and tables populated with data, but it’s not very practical when we want to create a structural diagram of multiple tables and how they relate to one another. And Mismatch is already in need of multiple tables...
Creating a diagram of a table lets you keep the design of the table separate from the data that’s inside of it.
Exercise
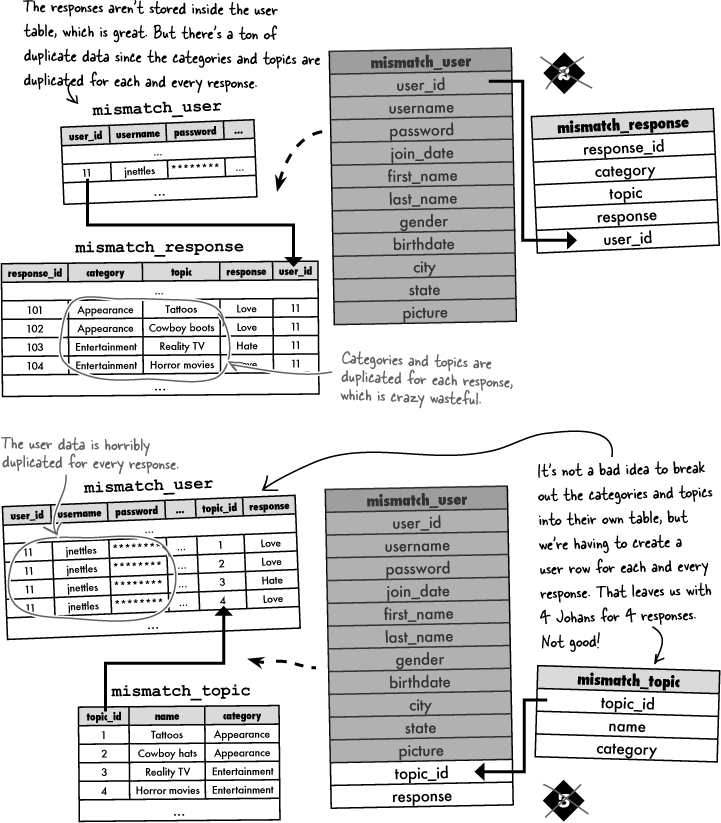
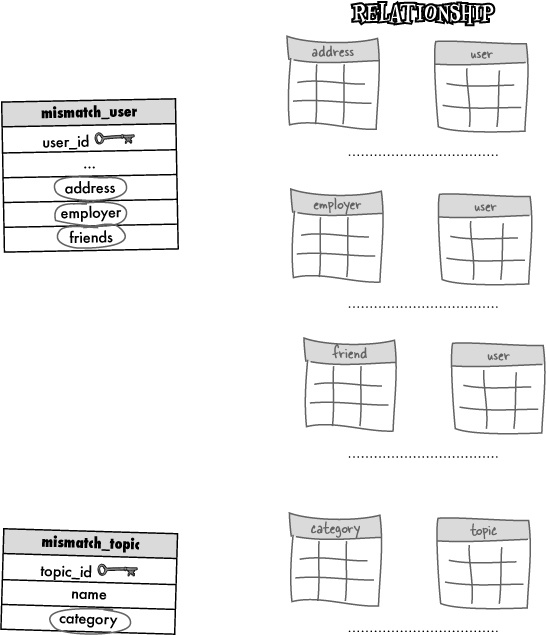
The Mismatch database is in need of storage for user responses to love/hate topics, as well as the topic names and their respective categories. Here are three different database designs for incorporating categories, topics, and responses into the Mismatch database. Circle the schema that you think makes the most sense, and annotate why.
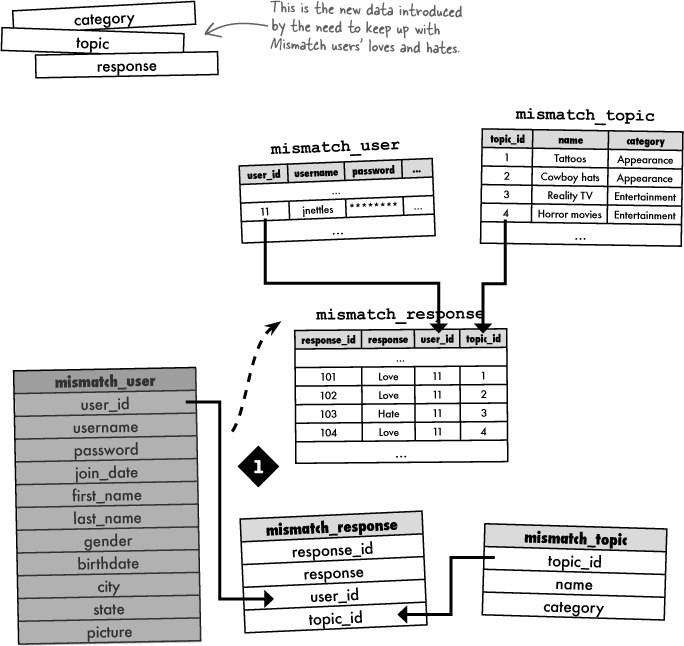
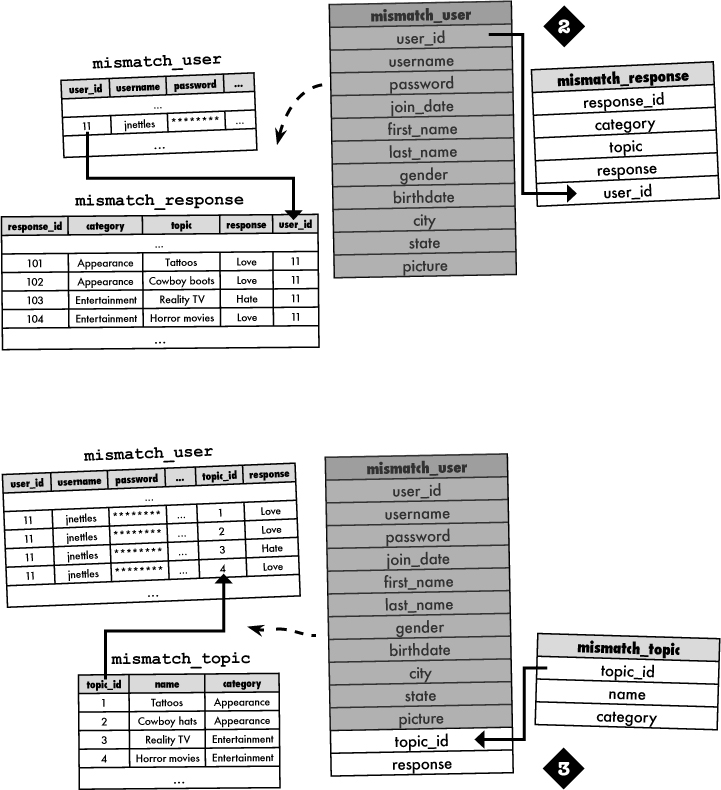
Exercise Solution
The Mismatch database is in need of storage for user responses to love/hate topics, as well as the topic names and their respective categories. Here are three different database designs for incorporating categories, topics, and responses into the Mismatch database. Circle the schema that you think makes the most sense, and annotate why.
Connecting tables together to form a cohesive system of data involves the use of keys. We’ve used primary keys to provide a unique identifier for data within a table, but we now need foreign keys to link a row in one table to a row in another table. A foreign key in a table references the primary key of another table, establishing a connection between the two tables that can be used in queries.
The Mismatch schema from the previous exercise relies on a pair of foreign keys in the mismatch_response table to connect response rows to user and topic rows in other tables.


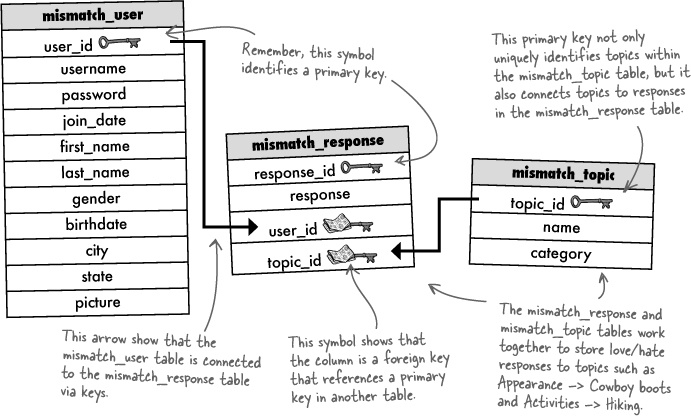
Without foreign keys, it would be very difficult to associate data from one table with data in another table. And spreading data out across multiple tables is how we’re able to eliminate duplicate data and arrive at an efficient database. So foreign keys play an important role in all but the most simplistic of database schemas.
Large arrows show primary keys connecting to foreign keys to wire together tables.
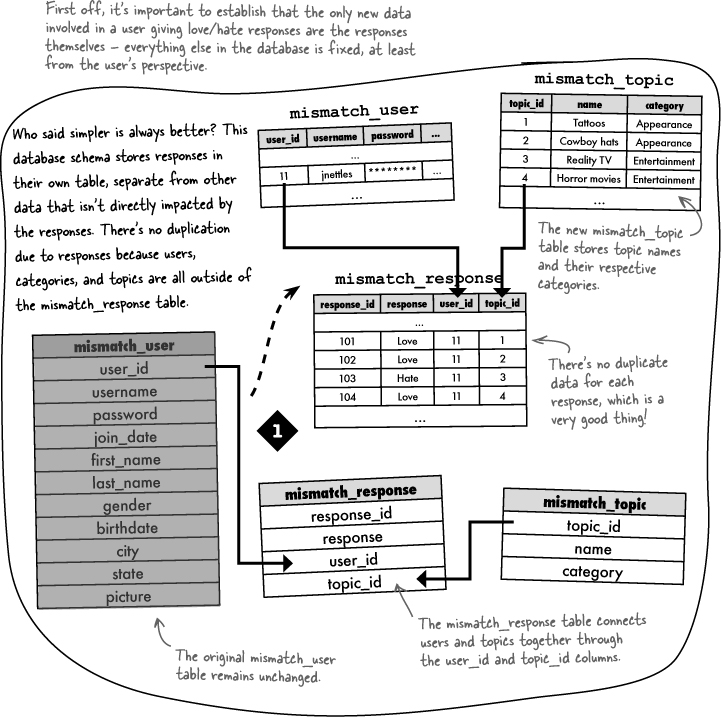
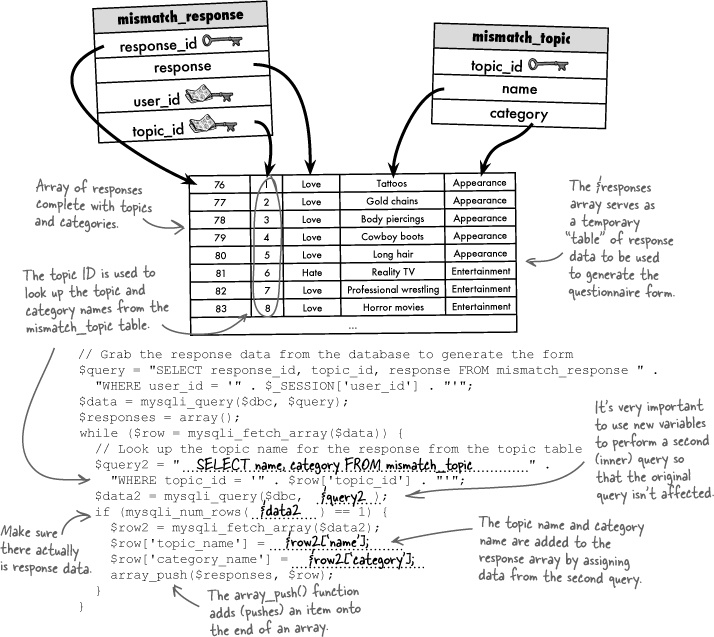
It often helps to visualize data flowing into tables and connecting tables to one another through primary and foreign keys. Taking a closer look at the Mismatch tables with some actual data in them helps to reveal how primary keys and foreign keys relate to one another.
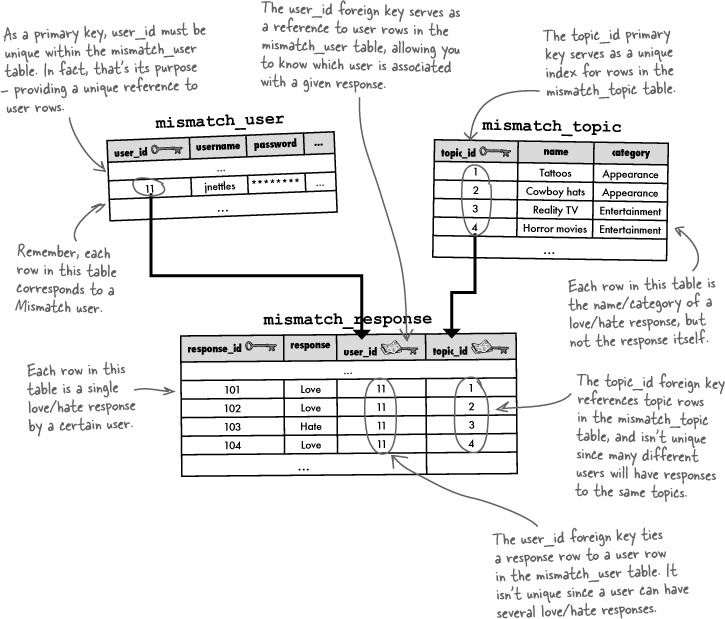
Within the mismatch_response table, you can find out more information about the user who entered a response by looking up the user_id in the mismatch_user table. Similarly, you can find out the name of the topic for the response, as well as its category, by looking up the topic_id in the mismatch_topic table.
Binding together tables with primary keys and foreign keys allows us to connect the data between them in a consistent manner. You can even structure your database so that primary keys and their respective foreign keys are required to match up. This is known as referential integrity, which is a fancy way of saying that all key references must be valid.

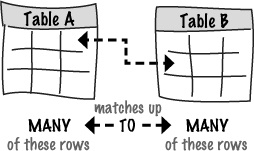
Yes, the direction of the arrows tells us how rows in each table relate to each other.
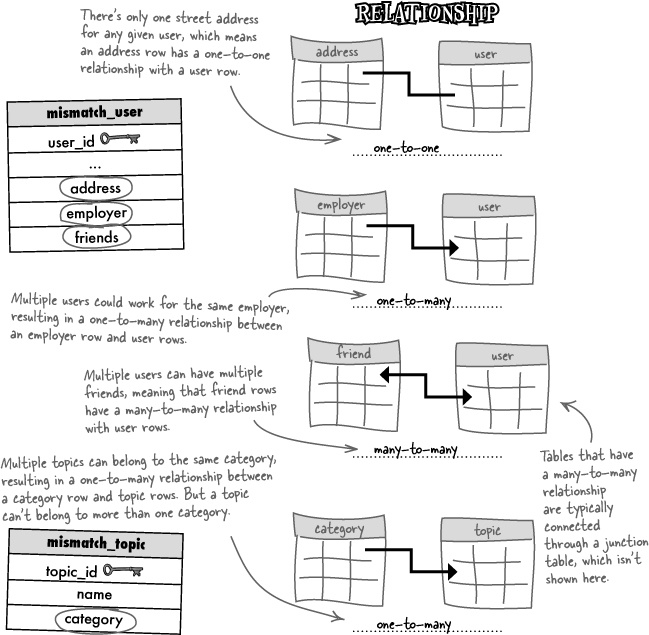
More specifically, they tell us how many rows in one table can have matching rows in another table, and vice-versa. This is a critical aspect of database schema design, and involves three different possible patterns of data: one-to-one, one-to-many, and many-to-many.
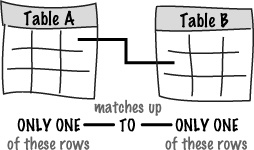
The first pattern, one-to-one, states that a row in Table A can have at most ONE matching row in Table B, and vice-versa. So there is only one match in each table for each row.
As an example, let’s say the Mismatch user table was separated into two tables, one for just the log-in information (Table A) and one with profile data (Table B). Both tables contain a user ID to keep users connected to their profiles. The user_id column in the log-in table is a primary key that ensures user log-in uniqueness. user_id in the profile table is a foreign key, and plays a different role since its job is just to connect a profile with a log-in.
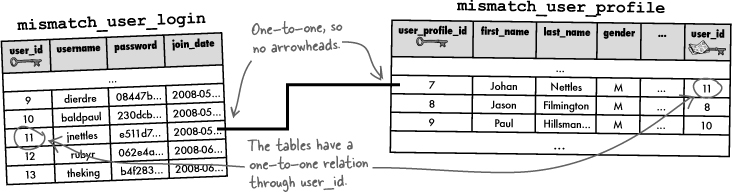
With respect to the two user_id columns, the log-in table is considered a parent table, while the profile table is considered a child table—a table with a primary key has a parent-child relationship to the table with the corresponding foreign key.
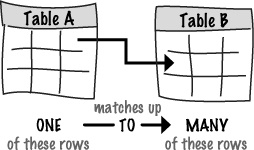
One-to-many means that a row in Table A can have many matching rows in Table B, but a row in Table B can only match one row in Table A. The direction of the arrow in the table diagram always points from the table with one row to the table with many rows.
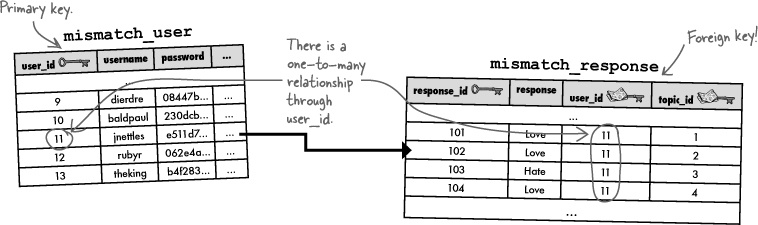
Using the Mismatch database again, the current schema already takes advantage of a one-to-many data pattern. Since a user is capable of having many topic responses (love tattoos, hate hiking, etc.), there is a one-to-many relationship between user rows and response rows. The user_id column connects these two tables, as a primary key in mismatch_user and a foreign key in mismatch_response.
There are no Dumb Questions
One-to-One: exactly one row of a parent table is related to one row of a child table.
One-to-Many: exactly one row of a parent table is related to multiple rows of a child table.
The third and final table row relationship data pattern is the many-to-many relationship, which has multiple rows of data in Table A matching up with multiple rows in Table B... it’s kinda like data overload! Not really. There are plenty of situations where a many-to-many pattern is warranted. Mismatch, perhaps? Let’s have a look.
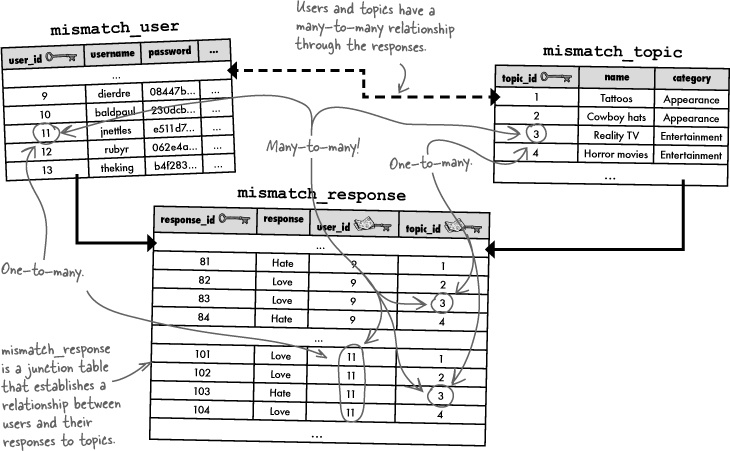
The many-to-many pattern in Mismatch is indirect, meaning that it takes place through the mismatch_response table. But the pattern still exists. Just look at how many of the same user_ids and topic_ids appear in mismatch_response.
In addition to holding the response data, the mismatch_response table is acting as what’s known as a junction table by serving as a convenient go-between for the users and topics. Without the junction table, we would have lots of duplicate data, which is a bad thing. If you aren’t convinced, turn back to the schema exercise near the beginning of the chapter and take a closer look at Design 2. In that design, the mismatch_topic table is folded into the mismatch_response table, resulting in lots of duplicate data.
Many-to-Many: Multiple rows of a parent table are related to multiple rows of a child table.
Name that Relationship
In each of the tables below, there are circled columns that could be moved out into their own tables. Write down if each of the columns is best represented by a one-to-one, one-to-many, or many-to-many relationship with its original table, and then draw the relationship as a line connecting the two tables with appropriate arrowheads.
Name that Relationship Solution
In each of the tables below, there are circled columns that could be moved out into their own tables. Write down if each of the columns is best represented by a one-to-one, one-to-many, or many-to-many relationship with its original table, and then draw the relationship as a line connecting the two tables with appropriate arrowheads.
Hold it right there! Take a second to get the Mismatch database in order so that we can make mismatches.
Download the .sql files for the Mismatch application from the Head First Labs web site at www.headfirstlabs.com/books/hfphp. These files contain SQL statements that build the necessary Mismatch tables: mismatch_user, mismatch_topic, and mismatch_response. Make sure to run the statement in each of the .sql files in a MySQL tool so that you have the initial Mismatch tables to get started with.
When all that’s done, run a DESCRIBE statement on each of the new tables (mismatch_topic and mismatch_response) to double-check their structures. These tables factor heavily into the Mismatch PHP scripts we’re about to put together.
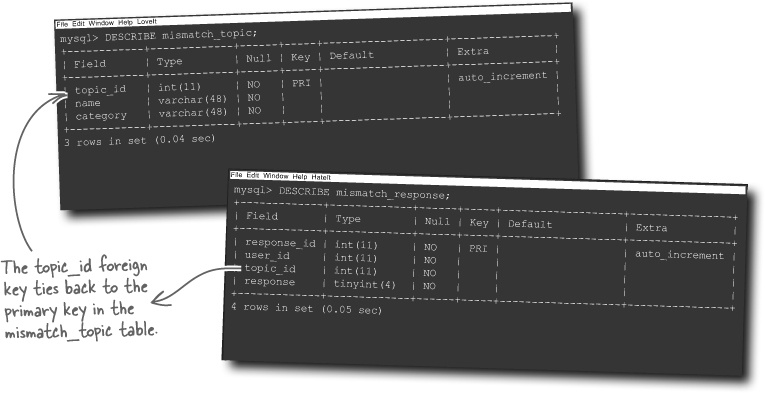

If you start with a well-designed database, every other piece of the application puzzle becomes that much easier to build and assemble.
Getting the database right when initially designing an application is perhaps the best thing you can do to make the development process run smoothly. It may seem like a lot of work up front plotting and scheming about how best to store the data, but it will pay off in the long run. Think about how much more difficult it would be to rework the Mismatch database schema with it full of data.
That’s the big picture benefit of a good database design. Looking at the Mismatch database specifically, we have a user table that is populated by the users themselves through sign-ups and profile edits, and we have a new topic table that contains enough categories and topics to give some decent insight into a person. What we’re still missing to make mismatches is a way to allow the user to enter responses, and then store them away in the response table.
So how exactly do we get love/hate responses from users for each Mismatch topic? The answer is a questionnaire form that allows the user to choose “Love” or “Hate” for each topic in the mismatch_topic table. This form can be generated directly from the responses in the database, with its results getting stored back in the database. In fact, the design of the questionnaire form involves reading and writing responses from and to the mismatch_response table. Here’s a peek at the questionnaire, along with the steps involved in building it.

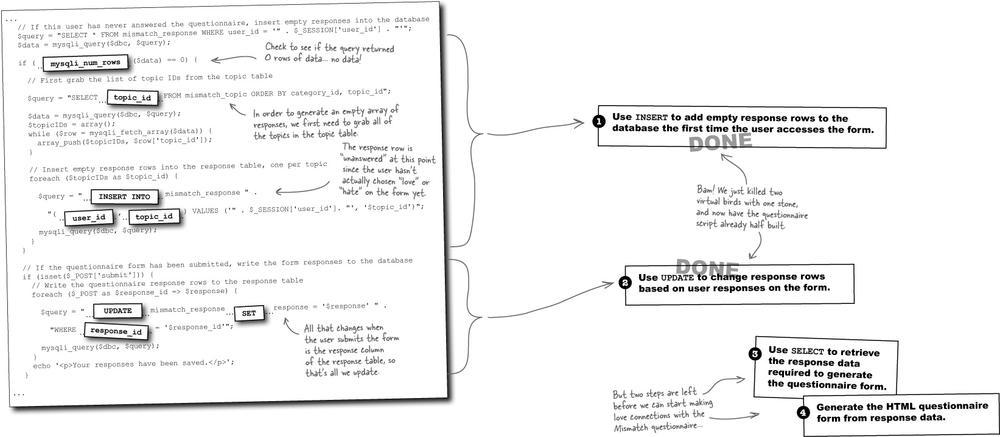
Use
INSERTto add empty response rows to the database the first time the user accesses the form.We’re going to generate the questionnaire form from data in the
mismatch_responsetable, even when the user has never entered any responses. This means we need to “seed” themismatch_responsetable with empty responses the first time a user accesses the questionnaire. Since theresponsecolumn for these rows is empty, neither the “Love” or “Hate” radio buttons are checked when the form is first presented to the user.Use
UPDATEto change response rows based on user responses on the form.When users submit the questionnaire form, we must commit their personal responses to the database. Even then, only responses with checked radio buttons should be updated. In other words, the database only needs to know about the responses that have been answered.
Use
SELECTto retrieve the response data required to generate the questionnaire form.In order to generate the questionnaire form, we need all of the responses for the logged-in user. Not only that, but we need to look up the topic and category name for each response so that they can be displayed in the form—these names are stored in the
mismatch_topictable, notmismatch_response.Generate the HTML questionnaire form from response data.
With the response data in hand, we can generate the HTML questionnaire form as a bunch of input fields, making sure to check the appropriate “Love” or “Hate” radio buttons based on the user responses.
Although it might seem as if we should start out by generating the questionnaire form, the form’s dependent on response data existing in the mismatch_response table. So first things first: we need to “seed” the mismatch_response table with rows of unanswered responses the first time a user accesses the questionnaire. This will allow us to generate the questionnaire form from the mismatch_response table without having to worry about whether the user has actually made any responses.
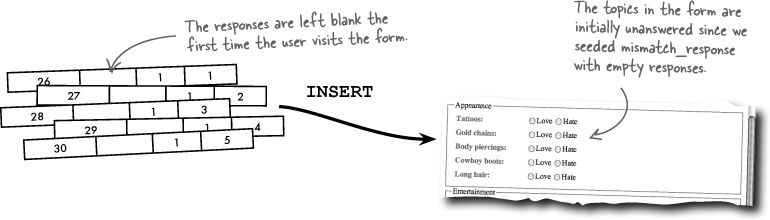
So from the perspective of the questionnaire form, there’s always a row of data in the mismatch_response table for each question in the form. This means that when the user submits the questionnaire form, we just update the rows of data for each response in the form.
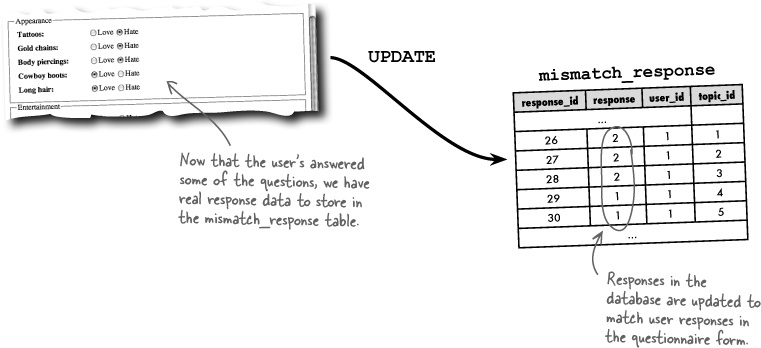
Although storing responses in the Mismatch database is ultimately a two-step process, the first step (INSERT) only takes place once for each user. Once the empty responses are added initially, all future changes to the questionnaire are handled by the second step via SQL UPDATEs.
PHP & MySQL Magnets
The following code takes care of inserting empty responses into the mismatch_response table the first time a user visits the questionnaire form. It also updates the responses when the user makes changes and submits the form. Unfortunately, some of the code has fallen off and needs to be replaced. Use the magnets to fix the missing code.

PHP & MySQL Magnets
The following code takes care of inserting empty responses into the mismatch_response table the first time a user visits the questionnaire form. It also updates the responses when the user makes changes and submits the form. Unfortunately, some of the code has fallen off and needs to be replaced. Use the magnets to fix the missing code.
It’s nothing new that web forms are used to retrieve data from users via text fields, selection lists, radio buttons, etc., but it may not be all that obvious that you can generate HTML forms from database data using PHP. The idea with Mismatch is to dynamically generate an HTML questionnaire form from response data. The Mismatch questionnaire script makes the assumption that response data already exists, which allows it to generate the form from data in the mismatch_response table. We know this assumption is a safe one because we just wrote the code to add empty responses the first time a user visits the form.
Data-driven forms rely on data in a MySQL database to generate HTML form fields.
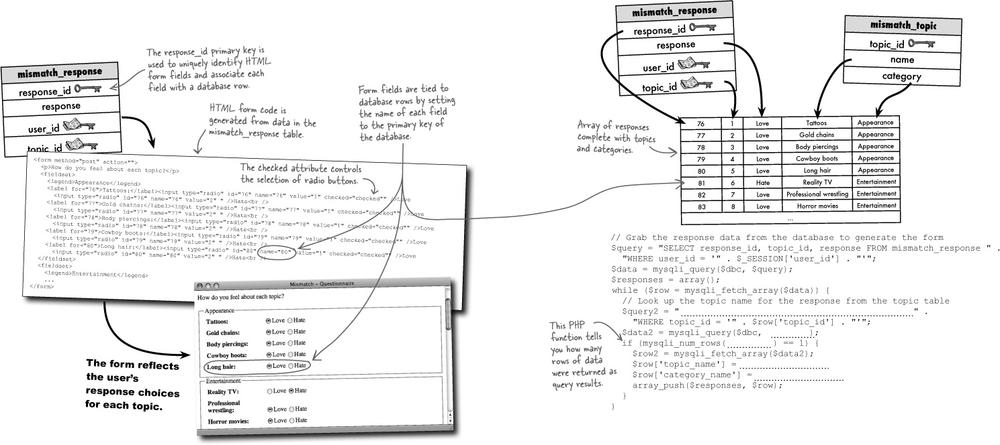
Exercise Solution
The Mismatch response questionnaire is generated from user responses that are stored in the mismatch_response table. In order to generate the code for the HTML form, it’s necessary to read these responses, making sure to look up the name of the topic and category for each response from the mismatch_topic table. The following code builds an array of responses with topics and categories by performing two queries: the first query grabs the responses for a user, while the second query looks up the topic and category name for each response. Problem is, some of the code is missing... fill in the blanks to get it working!

No and Yes, which is why it is important to use the most efficient data type possible to store data in a MySQL database.
When you think about it, a Mismatch response is more like a true/false answer because it’s always either one value (love) or another one (hate). Actually, a third value (unknown) can be useful in letting the application know when the user has yet to respond to a particular topic. So we really need to keep track of three possible values for any given response. This kind of storage problem is ideal for a number, such as a TINYINT. Then you just use different numeric values to represent each possible response.

Minimizing the storage requirements of data is an important part of database design, and in this case a subtle but important part of the Mismatch application. These numeric responses play a direct role in the generation of form fields for the Mismatch questionnaire.
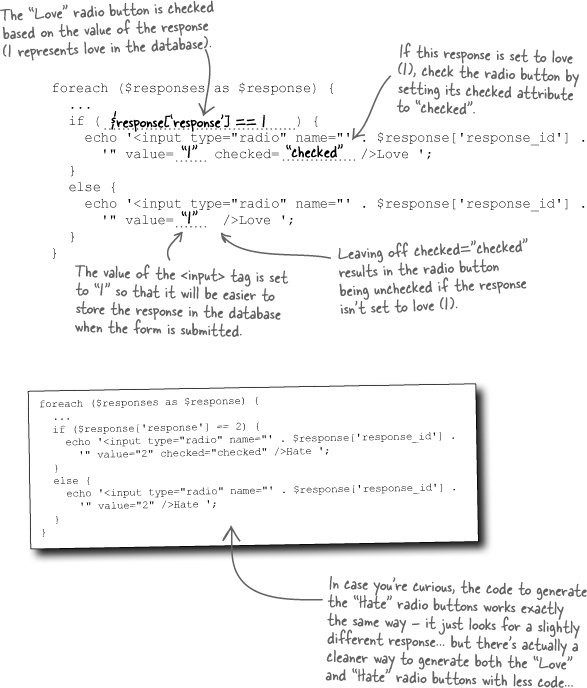
Sharpen your pencil Solution
The following code loops through the Mismatch response array that you just created, generating an HTML form field for each “Love” radio button. Fill in the missing code so that the form field is initially checked if the response is set to love (1). Also, make sure the value of the <input> tag is set accordingly.
Database efficiency isn’t the only kind of efficiency worth considering. There’s also coding efficiency, which comes in many forms. One form is taking advantage of the PHP language to simplify if-else statements. The ternary operator is a handy way to code simple if-else statements so that they are more compact.
The ternary operator can be used to code if-else statements in a more compact form.
? :
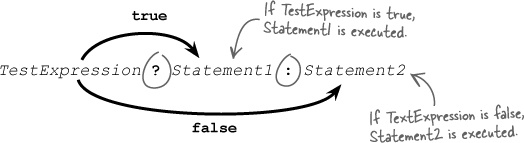
The ternary operator is really just a shorthand way to write an if-else statement. It can be helpful for simplifying if-else statements, especially when you’re making a variable assignment or generating HTML code in response to the if condition. Here’s the same “Love” radio button code rewritten to use the ternary operator:
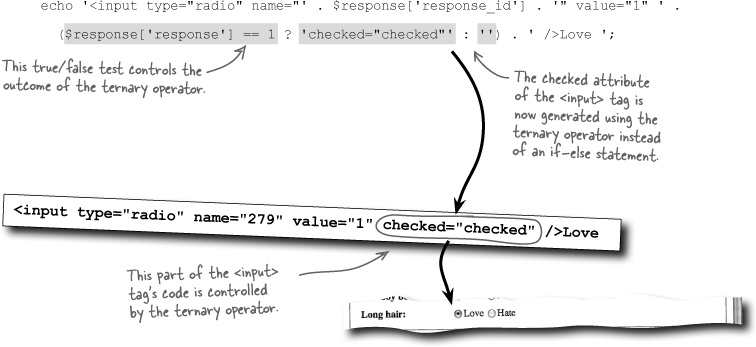
If the response value stored in $response['response'] is equal to 1, then the checked attribute will get generated as part of the <input> tag, resulting in the following checked “Love” radio button:
On the other hand, a response value of anything other than 1 will prevent the checked attribute from being generated, resulting in an <input> tag for the “Love” radio button that is unchecked.
We now have enough pieces of the Mismatch questionnaire form puzzle to use the response array ($responses) we created earlier to generate the entire HTML form. If you recall, this array was built by pulling out the current user’s responses from the mismatch_response table. Let’s go ahead and see the questionnaire generation code in the context of the full questionnaire.php script.

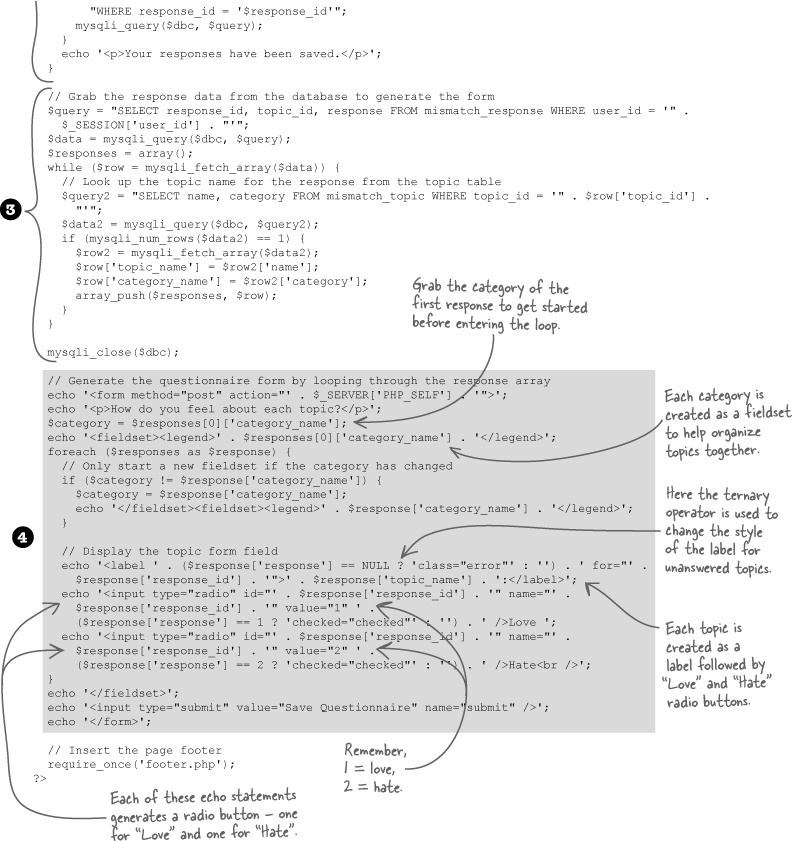
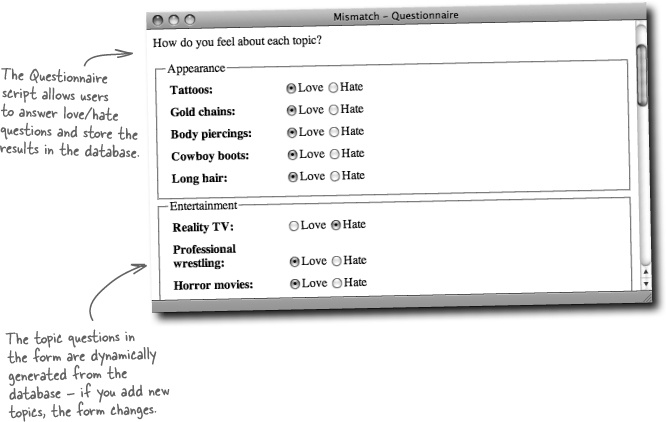
Test Drive
Try out the new Mismatch questionnaire.
Modify Mismatch to use the new Questionnaire script (or download the application from the Head First Labs site at www.headfirstlabs.com/books/hfphp). This requires creating a new questionnaire.php script, as well as adding a “Questionnaire” menu item to the navmenu.php script so that users can access the questionnaire.
Upload the scripts to your web server, and then open the main Mismatch page (index.php) in a web browser. Make sure you log in, and then click the “Questionnaire” menu item to access the questionnaire. Notice that none of the topics have answers since this is your first visit to the questionnaire. Answer the responses and submit the form. Return to the main page, and then go back to the questionnaire once more to make sure your responses are properly loaded from the database.
Try this!
Add a new topic to your own mismatch_topic table with this SQL statement:
INSERT INTO mismatch_topic (name, category) VALUES ('Virtual guitars', 'Activities')Empty all the data from the mismatch_response table with this SQL statement:
DELETE FROM mismatch_response
To simplify the code, Mismatch doesn’t adjust to new topics automatically, at least not when it comes to users who’ve already answered the questionnaire. So you’ll have to empty the mismatch_response table after adding a new topic.
View the questionnaire in the Mismatch application to see the new topic.
Respond to the new topic, submit the form, and check out your saved response.
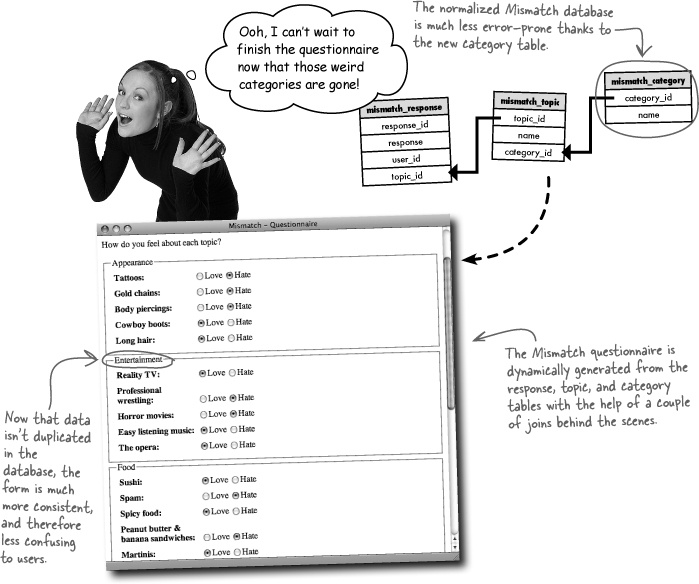
It took some doing, but the Mismatch application dynamically generates the questionnaire from responses stored in the database. This means that any changes made to the database will automatically be reflected in the form—that’s the whole idea of driving the user interface of a web application from a database. But what happens when we have bad data?
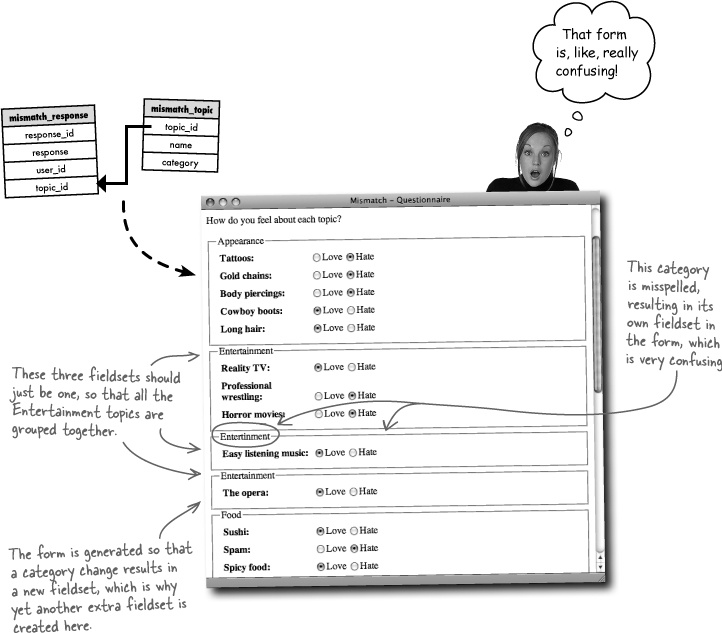
The data is driving the form’s fine, but something’s amiss. It appears that one of the categories has been misspelled in the database, causing the PHP code to generate a separate fieldset for it. This is a big problem because it ruins the effect of using fieldsets to help organize the form and make it easier to respond to topics.
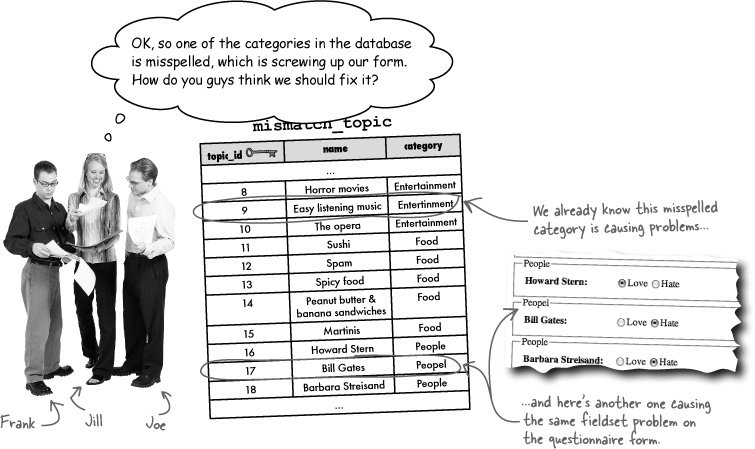
Frank: That’s easy. Just change the name of the category in the mismatch_topic table to the correct spelling.
Joe: But there’s more than one category misspelled. And now that I think about it, I’m not really understanding why the category names have to be stored more than once.
Jill: I agree. We went to the trouble of eliminating duplicate data in designing the database schema, yet here we are with a bunch of duplicate category names. Not only that, but we have a couple that aren’t even correct.
Frank: OK, what about just getting rid of category names and maybe referring to categories by number? Then you wouldn’t run the risk of typos.
Joe: True, but we still need the category names as headings in the questionnaire form.
Jill: Maybe we can refer to categories by number without throwing out the names. That’s sort of what we’re doing with topics already with the mismatch_topic table, right?
Joe: That’s right! We didn’t want to store a bunch of duplicate topic names in the mismatch_response table, so we put the topic names into the mismatch_topic table, and tied topics to responses with numeric keys.
Frank: Are you saying we could solve the duplicate category name problem by creating a new category table?
Jill: That’s exactly what he’s saying. We can create a new mismatch_category table where each category name is stored exactly one time. And then connect categories with topics using primary and foreign keys between mismatch_topic and mismatch_category. Brilliant!
The process of redesigning the Mismatch database to eliminate duplicate data and break apart and connect tables in a logical and consistent manner is known as normalization. Normalization is a fairly deep database design topic that can be intimidating. But it doesn’t have to be. There are enough simple database design techniques we can graft from the basics of normalization to make our MySQL databases much better than if we had just guessed at how data should be laid out.
Here are some very broad steps you can take to begin the database design process that will naturally lead to a more “normal” database:
Normalization means designing a database to reduce duplicate data and improve the relationships between data.
Pick your thing, the one thing you want a table to describe.
Make a list of the information you need to know about your one thing when you’re using the table.
Using the list, break down the information about your thing into pieces you can use for organizing the table.
One fundamental concept in normalization is the idea of atomic data, which is data broken down into the smallest form that makes sense given the usage of a database. For example, the first_name and last_name columns in the Mismatch database are atomic in a sense that they break the user’s name down further than a single name column would have. This is necessary in Mismatch because we want to be able to refer to a user by first name alone.
It might not always be necessary for an application to break a full name down into separate first and last columns, however, in which case name by itself might be atomic enough. So as you’re breaking down the “one thing” of a table into pieces, think about how the data is going to be used, not just what it represents.
Atomic data is data that has been broken down into the smallest form needed for a given database.
To help turn your database design brainstorms into actions, it’s helpful to ask targeted questions of your data. This will help determine how the data fits into a table, and if it has truly been broken down into its appropriate atomic representation. No one ever said splitting the atom was easy, but this list of questions can help.
Making your data atomic is the first step in creating a normal table.



If all this talk about nuclear data and normalcy seems a bit overkill for your modest database, consider what might happen if your web application explodes and becomes the next “big thing.” What if your database grows in size by leaps and bounds in a very short period of time, stressing any weaknesses that might be present in the design? You’d rather be out shopping for your new dot-com trophy car than trying to come up with a retroactive Band-aid fix for your data, which is increasingly spiraling out of control. You yearn for some normalcy.
If you still aren’t convinced, or if you’re stuck daydreaming of that canary yellow McLaren, here are two proven reasons to normalize your databases:
Normalization has its benefits, namely improvements in database size and speed.

You’ve pondered your data for a while and now have a keen appreciation for why it should be normalized, but general ideas only get you so far. What you really need is a concise list of rules that can be applied to any database to ensure normalcy... kinda like a checklist you can work through and use to make sure a database is sufficiently normal. Here goes:
Normalizing a database involves strictly adhering to a series of design steps.
1
2
3
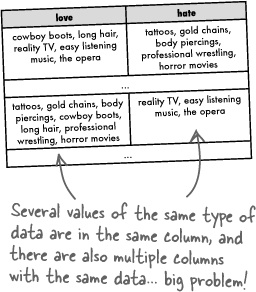
Make sure your columns are atomic.
For a column to truly be atomic, there can’t be several values of the same type of data in that column. Similarly, there can’t be multiple columns with the same type of data.
Give each table its own primary key.
A primary key is critical for assuring that data in a table can be accessed uniquely. A primary key should be a single column, and ideally be a numeric data type so that queries are as efficient as possible.
Make sure non-key columns aren’t dependent on each other.
This is the most challenging requirement of normal databases, and one that isn’t always worth adhering to strictly. It requires you to look a bit closer at how columns of data within a given table relate to each other. The idea is that changing the value of one column shouldn’t necessitate a change in another column.



Exercise
The Mismatch database is in need of a normalization overhaul to solve the problem of duplicate category names. Given the existing database structure, sketch a modified design that solves the duplicate category problem, eliminating the risk of data entry errors. Make sure to annotate the design to explain how it works.
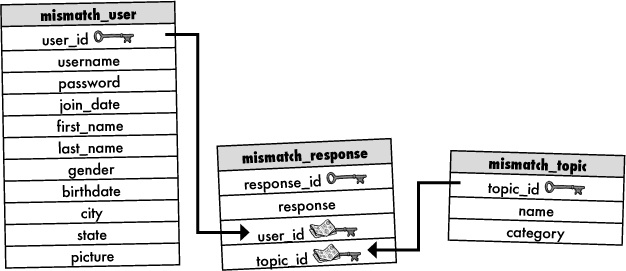
Exercise Solution
The Mismatch database is in need of a normalization overhaul to solve the problem of duplicate category names. Given the existing database structure, sketch a modified design that solves the duplicate category problem, eliminating the risk of data entry errors. Make sure to annotate the design to explain how it works.
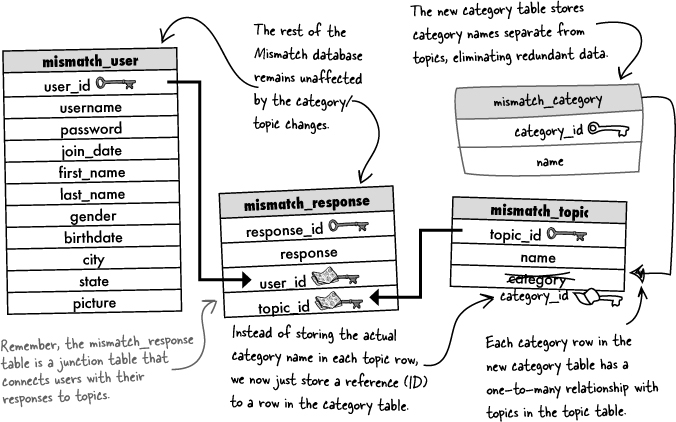
There are no Dumb Questions
In order to take advantage of the new schema, the Mismatch database requires some structural changes. More specifically, we need to create a new mismatch_category table, and then connect it to a new foreign key in the mismatch_topic table. And since the old category column in the mismatch_topic table with all the duplicate category data is no longer needed, we can drop it.

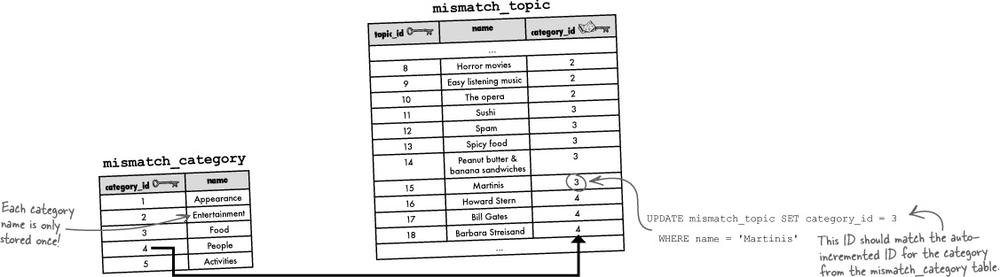
The new mismatch_category table must be populated with category data, which is accomplished with a handful of INSERT statements.
INSERT INTO mismatch_category (name) VALUES ('Appearance')
INSERT INTO mismatch_category (name) VALUES ('Entertainment')
INSERT INTO mismatch_category (name) VALUES ('Food')
INSERT INTO mismatch_category (name) VALUES ('People')
INSERT INTO mismatch_category (name) VALUES ('Activities')The new category_id column must then be populated with data to correctly wire the category of each topic to its appropriate category in the mismatch_category table.
Yes, it is. If you apply the three main rules of normalcy to each of the Mismatch tables, you’ll find that it passes with flying colors. But even if it didn’t, all would not be lost. Just like people, there are degrees of normalcy when it comes to databases. The important thing is to attempt to design databases that are completely normal, only accepting something less when there is a very good reason for skirting the rules.
Make sure your columns are atomic.
Give each table its own primary key.
Make sure non-key columns aren’t dependent on each other.
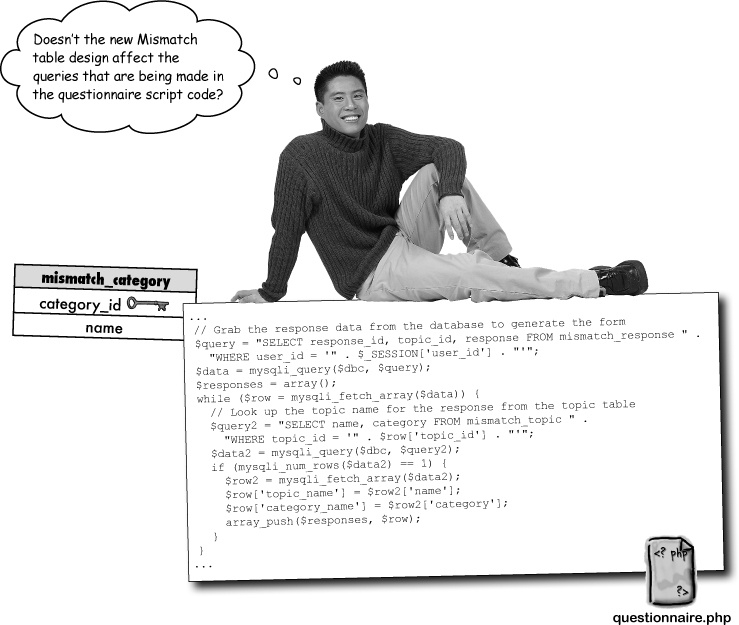
Yes. In fact, most structural database changes require us to tweak any queries involving affected tables.
In this case, changing the database design to add the new mismatch_category table affects any query involving the mismatch_topic table. This is because the previous database design had categories stored directly in the mismatch_topic table. With categories broken out into their own table, which we now know is a great idea thanks to normalization, it becomes necessary to revisit the queries and code them to work with an additional table (mismatch_category).
One problem brought on by normalizing a database is that queries often require subqueries since you’re having to reach for data in multiple tables. This can get messy. Consider the new version of the query that builds the response array to generate the Mismatch questionnaire form:
More tables usually lead to messier queries.
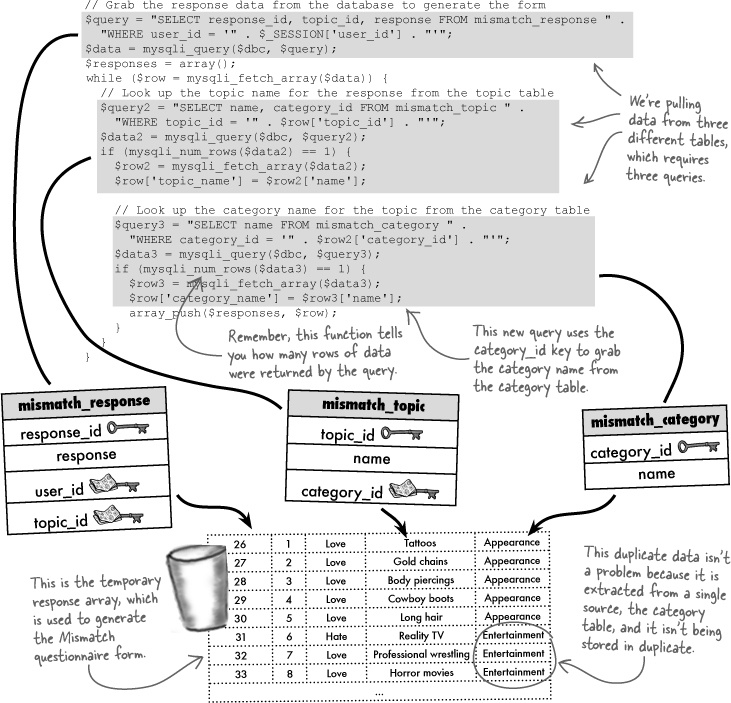
Yikes! Can anything be done about all those nested queries? The solution lies in an SQL feature known as a join, which lets us retrieve results from more than one table in a single query. There are lots of different kinds of joins, but the most popular join, an inner join, selects rows from two tables based on a condition. In an inner join, query results only include rows where this condition is matched.
A join grabs results from multiple tables in a single query.
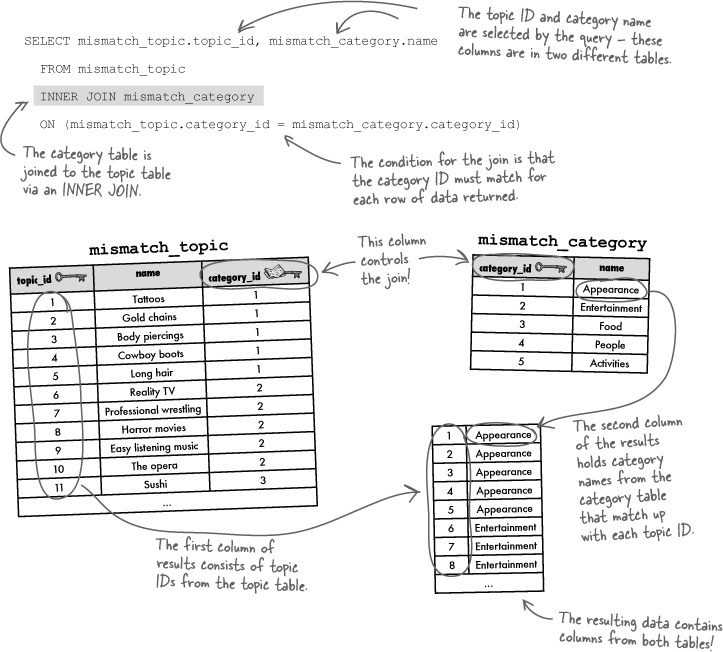
This inner join successfully merges data from two tables that would’ve previously required two separate queries. The query results consist of columns of data from both tables.
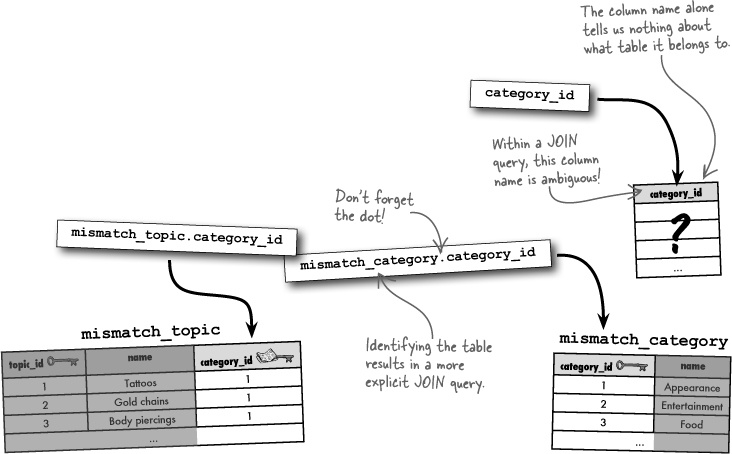
Since joins involve more than one table, it’s important to be clear about each column referenced in a join. More specifically, you must identify the table for each column so that there isn’t any confusion—tables often have columns with the same names, especially when it comes to keys. Just preface the column name with the table name, and a dot. For example, here’s the previous INNER JOIN query that builds a result set of topic IDs and category names:
Dot notation allows you to reference the table a column belongs to within a join.

Without the ability to specify the tables associated with the columns in this query, we’d have quite a bit of ambiguity. In fact, it would be impossible to understand the ON part of the query because it would be checking to see if the category_id column equals itself, presumably within the mismatch_topic table. For this reason, it’s always a good idea to be very explicit about identifying the tables associated with columns when building JOIN queries.
Inner joins don’t stop at just combining data from two tables. Since an inner join is ultimately just a query, you can still use normal query constructs to further control the results. For example, if you want to grab a specific row from the set of joined results, you can hang a WHERE statement on the INNER JOIN query to isolate just that row.
An INNER JOIN combines rows from two tables using comparison operators in a condition.
SELECT mismatch_topic.topic_id, mismatch_category.name
FROM mismatch_topic
INNER JOIN mismatch_category
ON (mismatch_topic.category_id = mismatch_category.category_id)
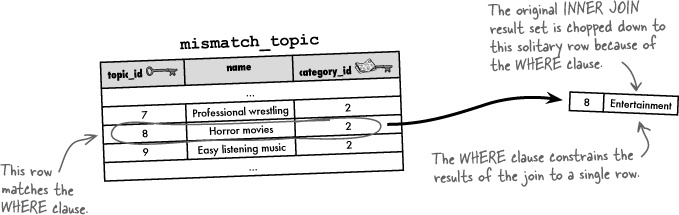
WHERE mismatch_topic.name = 'Horror movies'So what exactly does this query return? First remember that the WHERE clause serves as a refinement of the previous query. In other words, it further constrains the rows returned by the original INNER JOIN query . As a recap, here are the results of the inner join without the WHERE clause:
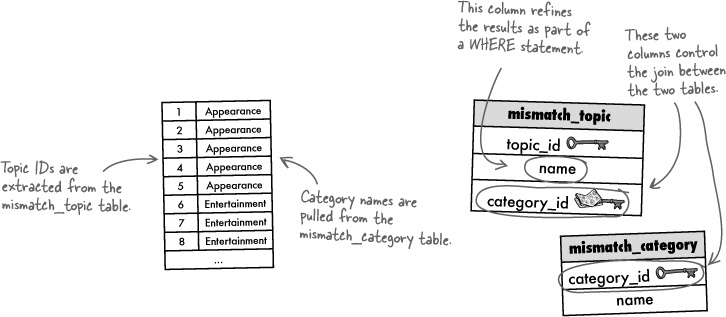
The WHERE clause has the effect of whittling down this result set to a single row, the row whose topic name equals 'Horror movies'. We have to look back at the mismatch_topic table to see which row this is.
Remember that our goal is to simplify the messy Mismatch queries with INNER JOIN. When an inner join involves matching columns with the same name, we can further simplify the query with the help of the USING statement. The USING statement takes the place of ON in an INNER JOIN query, and requires the name of the column to be used in the match. Just make sure the column is named exactly the same in both tables. As an example, here’s the Mismatch query again:
Rewrite ON with USING for more concise inner join queries that match on a common column.

Since the ON part of the query relies on columns with the same name (category_id), it can be simplified with a USING statement:
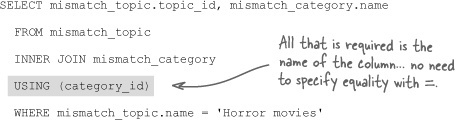
The column names must be the same in order to use the USING statement in an inner join.
Our INNER JOIN query just keeps getting tighter! Let’s take it one step further. When it comes to SQL queries, it’s standard to refer to table and columns by their names as they appear in the database. But this can be cumbersome in larger queries that involve joins with multiple tables—the names can actually make a query tough to read. It’s sometimes worthwhile to employ an alias, which is a temporary name used to refer to a table or column in a query. Let’s rewrite the Mismatch query using aliases.
An alias allows you to rename a table or column within a query to help simplify the query in some way.
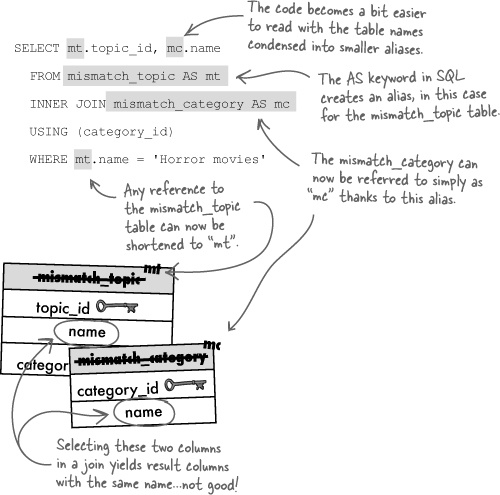
Are aliases only good for writing more compact queries? No, there are some situations where they’re downright essential! A join that would be quite handy in the Mismatch application is retrieving both the topic name and category name for a given topic ID. But the mismatch_topic and mismatch_category tables use the same column name (name) for this data. This is a problem because the result of combining these two columns would leave us with ambiguous column names. But we can rename the result columns to be more descriptive with aliases.
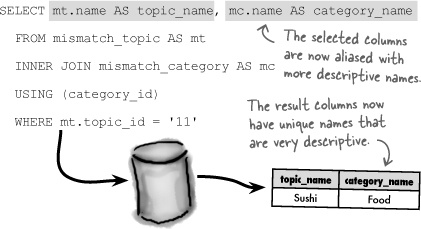
When a column is renamed with an alias, the alias is what appears in the query results.
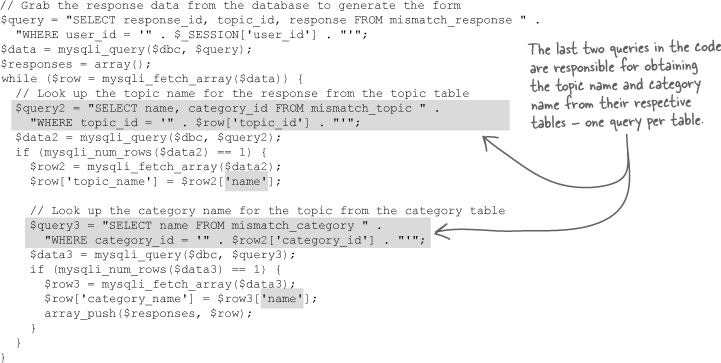
So joins make it possible to involve more than one table in a query, effectively pulling data from more than one place and sticking it in a single result table. The Mismatch query that builds a response array is a perfect candidate for joins since it contains no less than three nested queries for dealing with multiple tables. Let’s start with the original code:
Joins are more efficient and require less code than nested queries.
And here’s the new version of the code that uses a join:
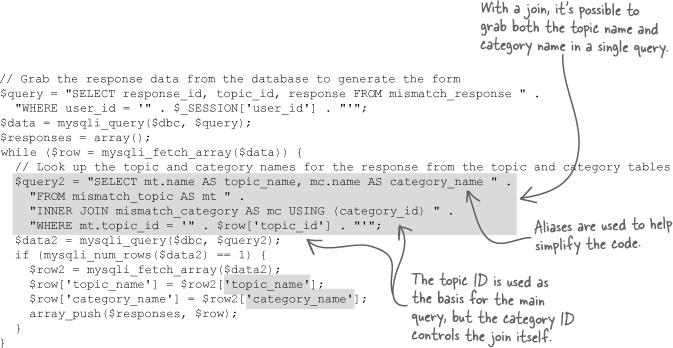

We don’t still need two queries, at least not if we use joins to their full potential.
It is possible to join more than two tables, which is what is truly required of the Mismatch response array code. We need a single query that accomplishes the following three things: retrieve all of the responses for the user, get the topic name for each response, and then get the category name for each response. The new and improved code on the facing page accomplishes the last two steps in a single query involving a join between the mismatch_topic and mismatch_category tables. Ideally, a single query with two joins would kill all three birds with one big join-shaped stone.
Exercise Solution
Following is code that is capable of retrieving response data from the database with one query, thanks to the clever usage of joins. Be clever and write the SQL query that does the joining between the mismatch_response, mismatch_topic, and mismatch_category tables.
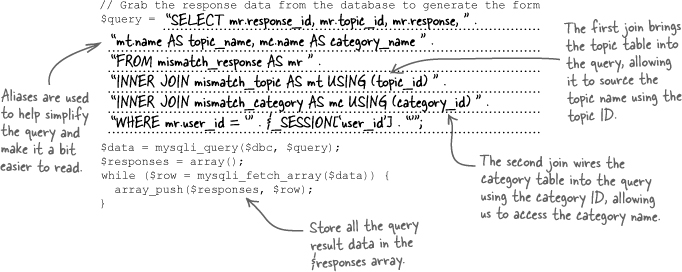
Test Drive
Revamp the Questionnaire script to grab the user’s response data with a single query.
Modify the questionnaire.php script to use inner joins so that the queries that grab the user’s response data are handled in a single query. Upload the new script to your web server, and then navigate to the questionnaire in a web browser. If all goes well, you shouldn’t notice any difference... but deep down you know the script code is much better built!

Mismatch now remembers user responses but it doesn’t yet do anything with them...like finding a mismatch!
The collection of user response data only gets us halfway to a successful mismatch. The Mismatch application is still missing a mechanism for firing Cupid’s arrow into the database to find a love connection. This involves somehow examining the responses for all the users in the database to see who matches up as an ideal mismatch.

It’s definitely doable; we just need a consistent means of calculating how many mismatched topics any two users share.
If we come up with a reasonably simple way to calculate how many mismatched topics any two users share, then it becomes possible to loop through the user database comparing users. The person with the highest number of mismatches for any given user is that user’s ideal mismatch!
Write down how you would go about calculating the “mismatchability” of two users using data stored in the Mismatch database:
____________________________________________________
____________________________________________________
____________________________________________________
If you recall, mismatch responses are stored in the mismatch_response table as numbers, with 0, 1, and 2 all having special meaning in regard to a specific response.

This is the data used to calculate a mismatch between two users, and what we’re looking for specifically is a love matching up with a hate or a hate matching up with a love. In other words, we’re looking for response rows where response is either a 1 matched against a 2 or a 2 matched against a 1.
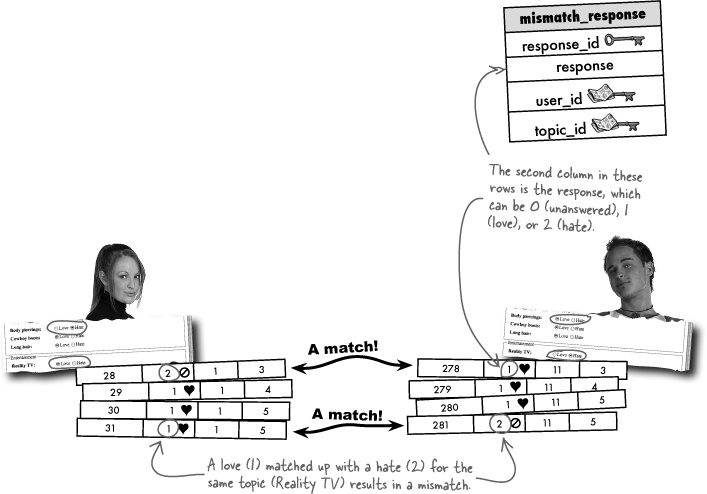
We’re still missing a handy way in PHP code to determine when a mismatch takes place between two responses. Certainly a couple of if-else statements could be hacked together to check for a 1 and a 2, and then a 2 and a 1, but the solution can be more elegant than that. In either scenario, adding together the two responses results in a value of 3. So we can use a simple equation to detect a mismatch between two responses.
If ResponseA + ResponseB = 3, we have a mismatch!
So finding a love connection really does boil down to simple math. That solves the specifics of comparing individual matches, but it doesn’t address the larger problem of how to actually build the My Mismatch script.
Finding that perfectly mismatched someone isn’t just a matter of comparing response rows. The My Mismatch script has to follow a set of carefully orchestrated steps in order to successfully make a mismatch. These steps hold the key to finally satisfying users and bringing meaning to their questionnaire responses.
Grab the user’s responses from the
mismatch_responsetable, making sure to join the topic names with the results.Initialize the mismatch search results, including the variables that keep up with the “best mismatch.”
Loop through the user table comparing other people’s responses to the user’s responses. This involves comparing responses for every person in the database to the user’s corresponding responses. A “score” keeps up with how many opposite responses the user shares with each person.
After each cycle through the loop, see if the current mismatch is better than the best mismatch so far. If so, store this one as the new “best mismatch,” making sure to store away the mismatched topics as well.
Make sure a “best mismatch” was found, then query to get more information about the mismatched user, and show the results.
Step 1 falls under familiar territory since we’ve already written some queries that perform a join like this. But we need to store away the user’s responses so that we can compare them to the responses of other users later in the script (Step 3). The following code builds an array, $user_responses, that contains the responses for the logged in user.

Done
1 | Grab the user’s responses from the |
Step 2 of the My Mismatch script construction process involves setting up some variables that will hold the results of the mismatch search. These variables will be used throughout the My Mismatch script as the search for the best mismatch is carried out:

The next mismatching step requires looping through every user, and comparing their responses to the responses of the logged in user. In other words, we’re taking the logged in user, or mismatcher (Sidney, for example), and going through the entire user table comparing her responses to those of each mismatchee. We’re looking for the mismatchee with the most responses that are opposite of the mismatcher.
Where to begin? How about a loop that steps through the $user_responses array (mismatcher responses)? Inside the loop we compare the value of each element with comparable elements in another array that holds the mismatchee responses. Let’s call the second array $mismatch_responses.
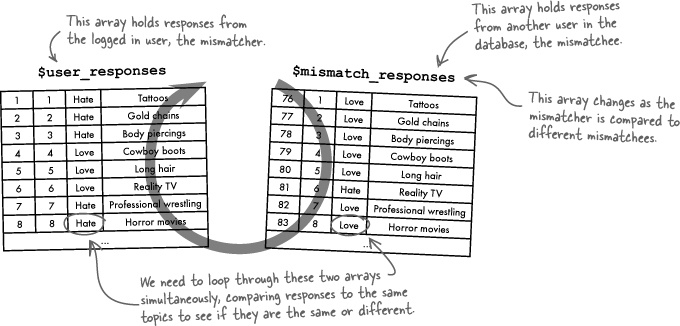
The challenge here is that we need a loop that essentially loops through two arrays at the same time, comparing respective elements one-to-one. A foreach loop won’t work because it can only loop through a single array, and we need to loop through two arrays simultaneously. A while loop could work, but we’d have to create a counter variable and manually increment it each time through the loop. Ideally, we need a loop that automatically takes care of managing a counter variable so that we can use it to access elements in each array.

PHP offers another type of loop that offers exactly the functionality we need for the My Mismatch response comparisons. It’s called a for loop, and it’s great for repeating something a certain amount of known times. For example, for loops are great for counting tasks, such as counting down to zero or counting up to some value. Here’s the structure of a for loop, which reveals how a loop can be structured to step through an array using a loop counter variable ($i).


The shiny new loop that calculates a mismatch score is part of a larger script (mymismatch.php) that takes care of finding a user’s ideal mismatch in the Mismatch database, and then displaying the information.



Test Drive
Modify Mismatch to use the new My Mismatch script (or download the application from the Head First Labs site at www.headfirstlabs.com/books/hfphp). This requires creating a new mymismatch.php script, as well as adding a “My Mismatch” menu item to the navmenu.php script so that users can access the script.
Upload the scripts to your web server, and then open the main Mismatch page (index.php) in a web browser. Make sure you log in and have filled out the questionnaire, and then click the “My Mismatch” menu item to view your mismatch.

Database Schema Magnets
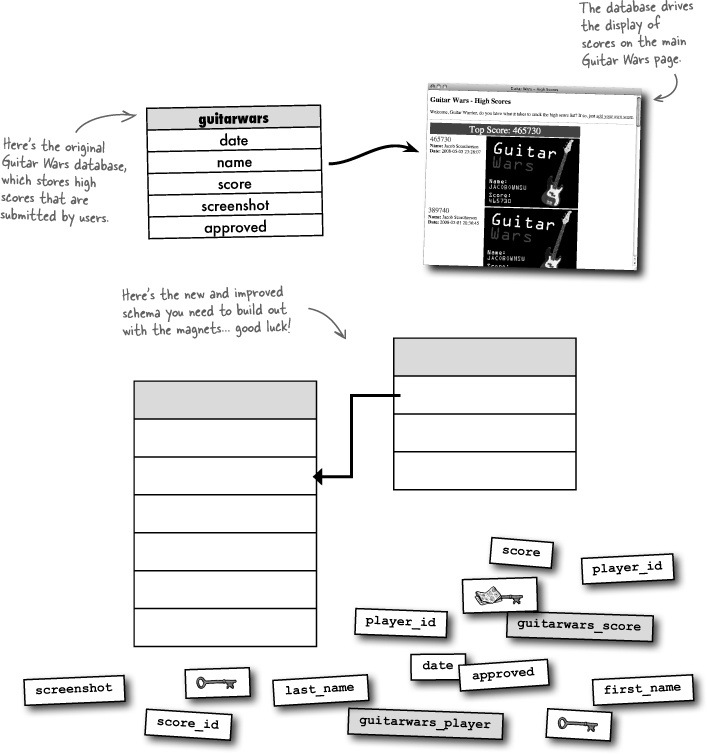
Remember the Guitar Wars application from eons ago? Your job is to study the Guitar Wars database, which could use some normalization help, and come up with a better schema. Use all of the magnets below to flesh out the table and column names, and also identify the primary and foreign keys.
Database Schema Magnets Solution
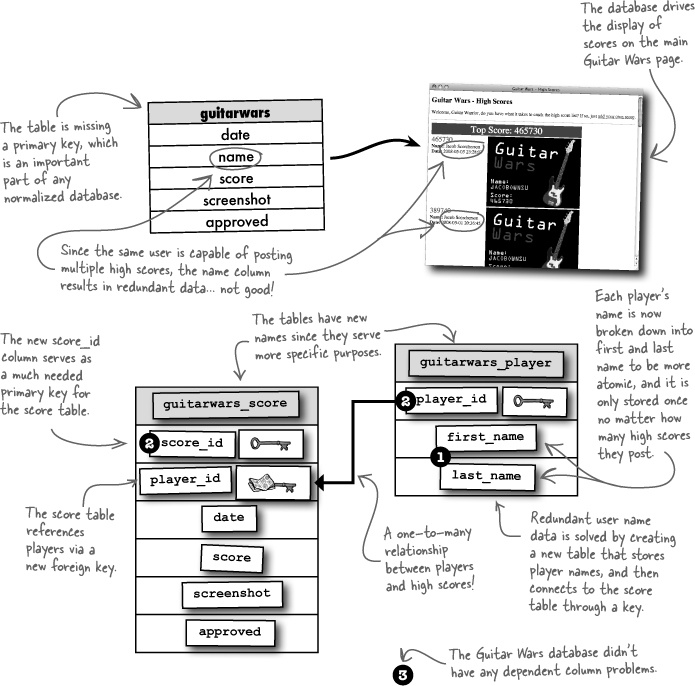
Remember the Guitar Wars application from eons ago? Your job is to study the Guitar Wars database, which could use some normalization help, and come up with a better schema. Use all of the magnets below to flesh out the table and column names, and also identify the primary and foreign keys.
Make sure your columns are atomic.
Give each table its own primary key.
Make sure non-key columns aren’t dependent on each other.
PHP&MySQLcross
Concerned that your own perfect mismatch is still out there waiting to be found? Take your mind off it by completing this crossword puzzle.

Across | Down |
|---|---|
1. A representation of all the structures, such as tables and columns, in your database, along with how they connect. 4. This happens when multiple rows of a table are related to multiple rows of another table. 5. This allows you to convert between different PHP data types. 7. Use this to combine results from one table with the results of another table in a query. 10. The process of eliminating redundancies and other design problems in a database. 11. You can shorten some if-else statements with this handy little operator. 12. When one row of a table is related to multiple rows in another table. | 1. A join makes it possible to get rid of these. 2. A column in a table that references the primary key of another table. 3. When a form is generated from a database, it is considered ---- ------. 6. It’s not nuclear, it’s just data in the smallest size that makes sense for a given database. 8. Rows in two tables have this relationship when there is exactly one row in one table for every row in the other. 9. One of these can help greatly in figuring out the design of a table. 13. A temporary name used to reference a piece of information in a query. |

