Fuzzing can be broadly categorized as smart and dumb fuzzing. In technical terms, it is known as Mutation fuzzing and Generation fuzzing. Providing random data as input is what fuzzing is all about. The input can be entirely random with no relation and knowledge about what the desired input should look like, or the input can be generated emulating valid input data with some alteration (hence the name generation fuzzing).
Mutation fuzzing, or Dumb fuzzing, employs a faster approach using sample data, but it lacks understanding of the format and structure of the desired input. Using Mutation fuzzing, you can create your fuzzer without much effort. The Mutation fuzzing technique uses a sample input and mutates it in a random way. For each fuzzing attempt, the data is mutated resulting in different input on subsequent fuzzing attempts. Bit flipping is one of methods that a Mutation fuzzer can use. A Dumb fuzzer could be as simple as piping the output of /dev/random into the application.
Mutation fuzzers may not be intelligent, but you will find many applications getting tripped over by such simple fuzzing technique. Mutation fuzzing will not work for a more complex application that expects data in a specific format, and it will reject the malformed data before it is even processed.
Generation-based fuzzer, or intelligent fuzzer as it is more commonly known, takes a different approach. These fuzzers have an understanding of the format and structure of the data that the application accepts. It generates the input from scratch based on that format. Generation-based fuzzers require prior understanding and intelligence in order to build the input that makes sense to the application. Adding intelligence to the fuzzer prevents the data from been rejected as in the case of Mutation fuzzing. Generation fuzzing uses a specification or RFC, which has detailed information about the format. An intelligent fuzzer works as a true client injecting data and creating dynamic replies based on response from the application.
Generation-based fuzzers are more difficult to design and require more effort and time. The increase in efforts results in a more efficient fuzzer that can find deeper bugs that are beyond the reach of Mutation fuzzers.
Fuzzing can be used to test a wide variety of software implementations. Any piece of code taking input can be a candidate of fuzzing. Some of fuzzing's most common uses are as follows:
- Network protocol fuzzing
- File fuzzing
- User interface fuzzing
- Web application fuzzing
Vulnerabilities in the implementation of network protocol pose a serious security issue. A flaw in the protocol can allow an attacker to gain access over a vulnerable machine over the internet. If the network protocol is well documented, the information can be used to create a smart fuzzer and different test cases against which the behavior of the protocol could be tested.
Network protocols are usually based on the client-server architecture, where client initiates a connection and the server responds. Therefore, the protocol needs to be tested in both the directions first by making a connection to the server, fuzzing it with test cases, and then acting as the server waiting for clients to connect to which the fuzzer responds back, testing the behavior of the protocol on the client. Protocol fuzzers are also known as remote fuzzers.
Attackers are increasingly using client-side attacks. Sending malicious Word documents, PDF files, and images are a few tricks that the attacker may use. In file fuzzing, you intentionally send a malformed file to the software and test its behavior. The software crashing as the file is opened might indicate the presence of the vulnerability. Common vulnerabilities identified by file fuzzing are stack overflows, heap overflows, integer overflows, and format string flaws, which can be turned into remote code execution attacks. Using file fuzzing, you can either create a malformed file header or manipulate specific strings inside the file format. FileFuzz and SKIPEfile are two file fuzzing tools.
Using file fuzzing, you can target the following:
- Document viewers
- Media players
- Web browsers
- Image processing programs
- Compression software
Thick client software that comes with a graphical user interface can also be fuzzed using malformed input. The input fields in these applications should be tested against buffer overflow vulnerabilities. Ideally, any application accepting input can be tested using fuzzing.
Fuzzing web applications is an active area of research in the security field. Web applications are increasingly becoming more complex due to mashup of multiple technologies and third-party integration, which makes it an attractive option for fuzzing. Using fuzzing, you can not only identify cross site scripting and SQL flaws but it will also help you unearth vulnerabilities in sections of the application that might have been overlooked in earlier testing phases. We will discuss more on web application fuzzing later in this chapter.
Web browsers have recently grabbed the attention of security researchers. A browser is similar to normal software that is fuzzed using a file fuzzer, but it deserves additional attention due to its interaction with web applications. Brower fuzzing has been the most common and effective way to find out bugs in a browser. The file format that web browsers usually deal with is HTML. Fuzzing with malformed web pages could expose flaws in the rendering engine of the browser. Since the browser is normally used to open web pages hosted on a remote server, a malicious user hosting an evil web page could exploit a vulnerable browser. Mangleme and Crossfuzz are two well-known browser fuzzers.
Specialized fuzzing software do a great job when testing common file formats and well-documented software, but they are not effective against proprietary software and code. This gave rise to fuzzing frameworks as creating a fuzzer from scratch for each application is not feasible.
A framework is a conceptual structure that is used to build something useful based on the rules specified by it. A fuzzing framework is a collection of libraries and acts a generic fuzzer using which you can create fuzzing data for different targets. These frameworks can be used to exhaustively test a protocol or a custom-built application.
Using a fuzzing framework, you can create a fuzzer in a lesser time to test your proprietary software. You won't have to design a fuzzer from scratch, as the inbuilt libraries do most of the work. The aim of a fuzzing framework is to provide a reusable, flexible, and quick development environment to build a fuzzer.
Some of the most mature and widely used frameworks are as follows:
- Sulley
- SPIKE
- Peach
Creating a fuzzer using a framework requires some scripting skills, as you need to customize and extend it to fit your needs. These frameworks are developed in different languages with SPIKE framework written in C language, while Sulley and Peach are developed in Python.
Out of the three frameworks listed in the preceding paragraph, I prefer the Sulley fuzzing framework as it is a feature rich and consists of additional components that are not usually found in fuzzers. It not only creates data representation but also monitors the target to locate the exact crash condition. It uses something known as agents to monitor the health of the target under fuzzing conditions and resets the target after fuzzing is complete.
Note
Additional information on the Sulley framework can be found at https://github.com/OpenRCE/sulley.
A detailed analysis of fuzzing frameworks is beyond the scope of the book, but if you are testing a custom-built software or web application, the fuzzing framework should be part of your armory.
Fuzzing requires a few preparatory steps before you attack the target. The following diagram shows the building blocks of a fuzzing test:
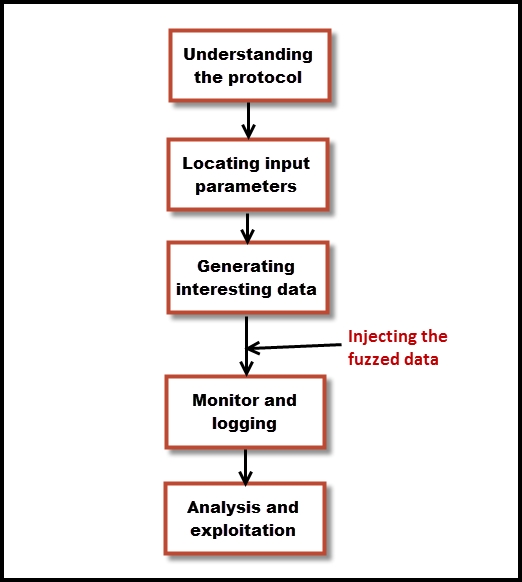
The typical steps involved in fuzzing are described next:
- Understanding the protocol: Understanding of the protocol used in the application is the first and most important step when fuzzing. Unless you gain knowledge about the protocol used by the application, it would be difficult to develop test cases. If you are testing a proprietary network protocol, you need the information on how the packets are generated and its correct format.
- Locating the input parameters: The target that you are fuzzing is likely to be taking input through different methods. A web application accepts inputs from various parameters in the web form. The different header fields of the HTTP protocol also act as an input to the application and become a candidate for fuzzing. Passing inputs via the command line and files in different formats are other ways through which applications accept data.
- Generating interesting data: The aim of fuzzing is to provide abnormal data as input to the target which it usually does not expect to receive. The task of the fuzzer is to generate data that creates a crash condition despite being accepted by the target. Generating intelligent data is what differentiates good fuzzers from the others.
- Injecting the fuzzed data: Once the input parameter and fuzzing data is ready, it's time to send it across to the target if it's on the network.
- Monitor and logging: As the fuzzer starts fuzzing, you need to monitor the target and wait for the application to hit a crash condition due to the inappropriate data passed to it. This crash condition should be logged and the data that caused the crash should be captured. The most ideal way is to capture a memory dump of the application when it crashes.
- Analysis and exploitation: It is not necessary that a crash condition would lead to an exploitable situation. You need to analyze the data and if you have captured the memory dump at post–mortem, using a debugger would help you understand the reason behind the crash and the data causing it.
So far, we discussed fuzzing as a general security testing technique against a target. Fuzzing also plays an important role when you are doing a penetration test of a web application. It can reveal vulnerabilities such as improper input validation and insufficient boundary checks. These flaws could result in the exposure of web application environment details such as OS version, application version, and database details or even a buffer overflow condition that can be exploited to execute a a remote code execution attack. Any web application that is built on the HTTP protocol specification can be fuzzed.
Over the years, developing web applications has become increasingly easy. Programming languages have become more user friendly, which has resulted in more organizations developing web applications in-house. Unfortunately, developing a secure web application with all the major vulnerabilities closed is a difficult task. Web applications take inputs from different parameters such as URL, headers, and form fields and this data if not validated correctly results in flaws that attackers exploit.
Parameters passed using the GET request with URIs can be fuzzed. When the application is injected with a malicious URI, it can respond differently depending on the data injected.
A request URI might include the following parameters:
/[path]/[page].[extension]?[name]=[value]
Here's an example of the request sent via GET:
/docs/task.php?userid=101
Fuzzing each parameter could lead the attacker to a new section in the application that a normal user is unable to see. For example, fuzzing the path parameter could result in a path traversal attack. Similarly, fuzzing the page parameter with predictable names could lead to information leakage.
Fuzzing the name parameter could result in privilege escalation by changing the userid value to the ID of a user with administrative rights. At the end, fuzzing the value parameter could reveal XSS, command injection, and SQL injection flaws.
Many applications capture data from the header sent by the client to perform some tasks on the server side. For example, the application would rely on the user-agent value to decide the contents to be delivered back to the user. If the application does not perform proper input validation on the user-agent string, it can be exploited by an attacker.
The following header fields should be fuzzed to find if they can be exploited:
ReferrerContent-LengthHostAccept languageCookieUser-Agent
SQL injection, cross-site scripting, command injection, and buffer overflow flaws could be found by fuzzing the header fields. By fuzzing the cookie value, the hacker can predict session IDs of other user and hijack sessions. If additional cookies are stored to share data between the server and the client, it should be fuzzed to find out if it's vulnerable to any SQL or XSS flaw.
A web form containing different parameters should be thoroughly fuzzed to test the input validation implemented by the application. The application developer should set correct bound checks for every field and reject data beyond it. For example, an input field for the PIN code should only accept numbers. The application should also discard any type of script tags in the input that could result in an XSS flaw.
Monitoring the web application for an exception is a bit different. The fuzzing activity would not usually crash the application and generate a memory dump that could be analyzed in a debugger. You need to rely on the error messages returned by the application and HTTP codes. A status code of 403 indicates that the resource you were trying to access is restricted and you are not authorized to view it, a 404 error code states that the web page that you are trying to access is unavailable, and a 500 error code indicates an internal server error.
Some web application would reply back with error messages that reveal the internals of the application such as a SQL error message. Using this, you can infer whether the application can be exploited further.
Note
The entire list of HTTP error codes can be found at http://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html
You will often see a 404 error code if you are fuzzing using random data.
In Kali Linux 2.0, you can find different tools that can be used for fuzzing at Applications | Web Application Analysis:
- Burp Suite
- Owasp-zap
- Powerfuzzer
- WebScarab
- Webslayer
- Websploit
- Wfuzz
- Xsser
A few of the preceding tools have been used before and not exclusively used for fuzzing, but include fuzzing as an additional feature. Burp Suite, Owasp-zap, and WebScarab are powerful proxy interception tools that have inbuilt fuzzing options.
Burp intruder is a tool within the Burp Suite that can fuzz the different parameters in web applications. You can automate the task of injecting fuzzed data and the results will be displayed when complete. Using the intruder, you can find flaws such as XSS, directory traversal, SQL, and command injection.
Setting up the intruder is a multi-step process:
- First, you need to configure the Burp proxy so that it intercepts the connection. Next, the important part is to identify the vulnerable request and parameters that you need to fuzz.
- Once you have intercepted the request, right-click on it and click on Send to Intruder, as shown in the following screenshot:

- Click on the Intruder tab, where you will see the requests that you have sent from the previous step:
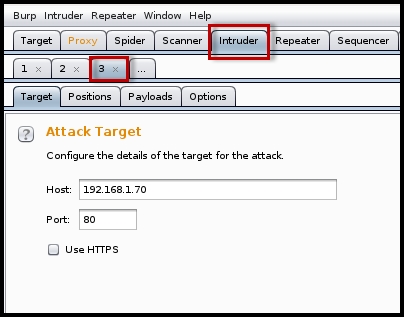
The important task here is to mark the locations in the request that you want to fuzz. The Intruder section has four sub-tabs: Target, Positions, Payloads, and Options. Every request that you send to the intruder is numbered, as shown in the preceding screenshot.
- Select the request that you sent to the intruder under which you will see the four tabs:
- Target: The Target option is self-explanatory and should be left as it is, if you are targeting the same application for which you intercepted the connection.
- Positions: Under the Positions tab, you need to define the location at which you want to insert the fuzzing payload. For example, if you want to fuzz the
userIDparameter in the URL, you need to select the specific position where the parameter falls in the URL. You can also select multiple positions where you want to insert the payload. Burp intruder uses different attack types when fuzzing:- Sniper: Each of the selected parameter is fuzzed using a single payload sequentially. This method is useful when testing multiple parameters for a specific vulnerability such as an XSS flaw.
- Battering ram: In this method, the payload is sent to all the selected parameters at the same time. Then, the parameters are fuzzed using the second payload, and so on. This attack method is useful when you require the same input to be inserted at multiple locations at the same time. An example would be when you are fuzzing the
IDfield and want to change the value of that parameter at multiple locations. - Pitchfork: In this method, each parameter is fuzzed using a defined payload. It makes use of multiple payload sets. While fuzzing, it inserts the payload from each set into specific positions. This attack method is useful when you want to fuzz using a combination of payload, inserting the data into multiple locations at the same time. When fuzzing multiple parameters such as
Itemcodeand its price in an ecommerce web application, this method could be useful; you can fuzz both the parameters at the same time as both are related to each other. - Cluster bomb: The aim of this attack method is to test the parameters using all the combinations of the payload, and this is useful when you require different and unrelated data to be inserted in multiple locations.
- Payloads: The fuzzing data is often called a payload. Here, you can define the various payloads and different options to generate the fuzzing data. The Payloads section contains multiple options and the important ones are listed as follows:
- Simple list: This is most basic way to import the payload through a text file.
- Runtime file: If you have a good repository of payload, you can import it during runtime.
- Custom iterator: This will create a combination of characters based on a defined template.
- Character substitution: This will import a preset list of payloads and create multiple payloads by substituting characters in it.
- Case substitution: As the name suggests, it will import the list of payload and switch the case of the character useful when fuzzing the
passwordfield.
- Options: Under the Options tab, you can make some performance tweaks. You can also enable the DOS mode (not recommended in a production environment). The Grep - Match and Grep - Extract options are useful when dealing with the response from the server. It can match specific values returned by the server such as SQL errors and internal functions and flag that request. Using the Grep - Extract option, you can pull out specific values of interest from the response.
- In the following example, we are using the fuzzing to identify sub directories under the website. From the Payload options, I have selected the Sniper attack method. By default, when you send a request to the intruder, it will find out all parameters suitable for fuzzing and will mark them with the
§symbol.If you want to select the parameters yourself, click on Clear § and mark the values by pointing the cursor to the specific positon and click on Add §. Since I am fuzzing the sub directories, I will add the marker in the
GETrequest header: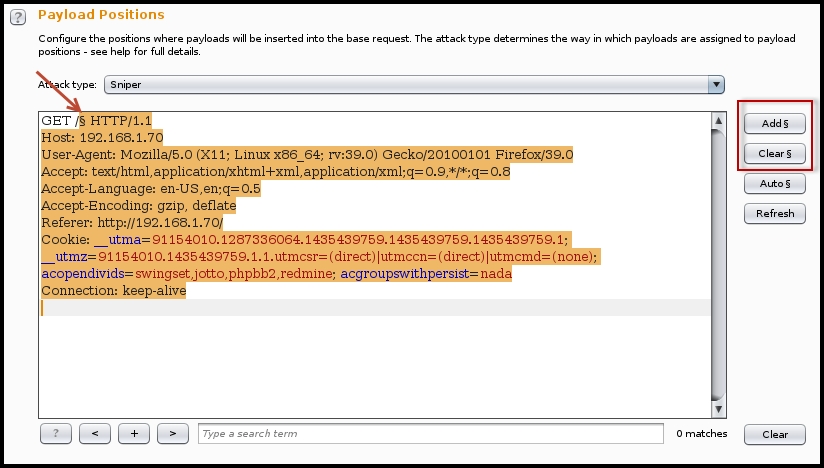
- Once you have decided on the parameters that you want to fuzz, you need to define the payload. In this example, I am importing a payload file during runtime:
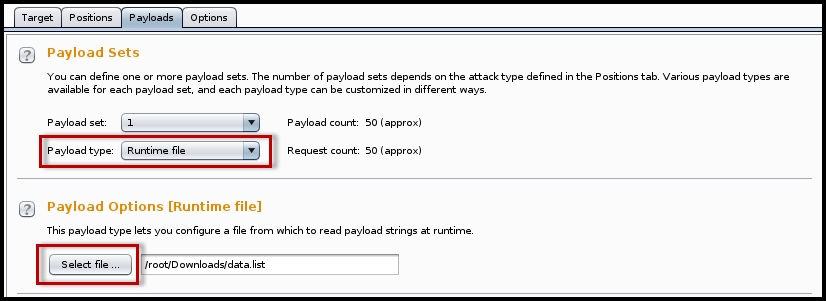
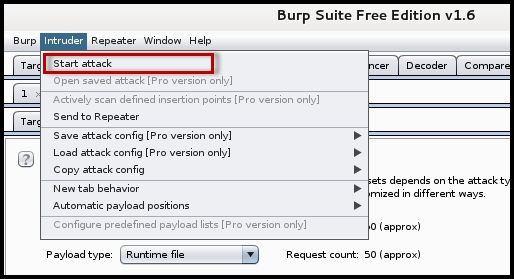
- The final step is to start the fuzzing attack by selecting the Start attack option under the Intruder menu at the top:
A new window will open and you will see intruder working and populating the Results tab. It logs every request sent and its response received. The Length and Status columns can help you interpret the fuzzing results. As seen in the following screenshot, the status for the payload
railsgoatis200, which means it was able to find a subdirectory by that name: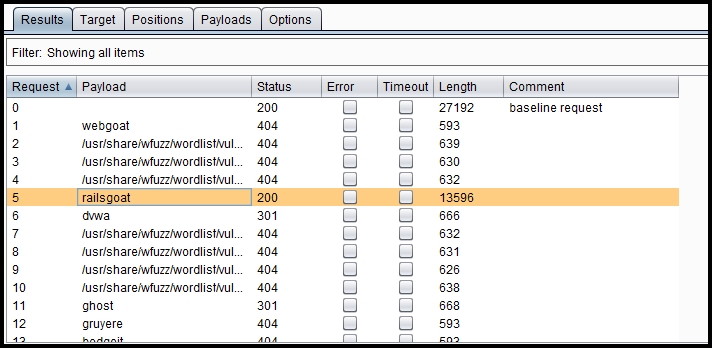
To assist you in the task of interpreting the results, you can use the error strings from fuzzdb to find interesting error messages. fuzzdb is an open source database containing a list of server response messages, common resource names, and malicious inputs for fuzzing. The
errors.txtfile from fuzzdb can be imported in the Grep - Match option of intruder: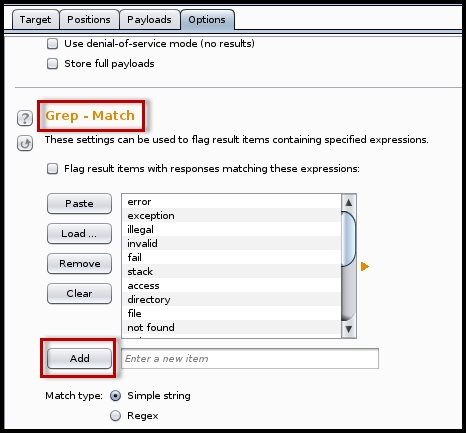
This option will search the response pages generated by the intruder payload for occurrence of the error messages; SQL errors, PHP parsing errors, and Microsoft scripting error messages are a few of them. The error messages in the response page could help you identify if the application is vulnerable.
The GitHub project for fuzzdb is hosted at https://github.com/rustyrobot/fuzzdb. The original project was on Google Code and relevant information for it can be found at https://code.google.com/p/fuzzdb/. The errors.txt file can be found at https://code.google.com/p/fuzzdb/source/browse/trunk/regex/errors.txt.
PowerFuzzer is a completely automated tool for fuzzing. It does not include many configuration options and is a one click tool. It can be useful when you want to identify any cross-site scripting and injection flaws.
You only need to specify the target URL and click on Scan; the other settings are optional. You can exclude a particular path if you want and can also specific a username and password or a cookie if the application requires authentication: