- Import the following packages:
import numpy as np
import neurolab as nl
- Read the input file:
in_file = 'words.data'
- Consider 20 data points to build the neural network based system:
# Number of datapoints to load from the input file
num_of_datapoints = 20
- Represent the distinct characters:
original_labels = 'omandig'
# Number of distinct characters
num_of_charect = len(original_labels)
- Use 90% of data for training the neural network and the remaining 10% for testing:
train_param = int(0.9 * num_of_datapoints)
test_param = num_of_datapoints - train_param
- Define the dataset extraction parameters:
s_index = 6
e_index = -1
- Build the dataset:
information = []
labels = []
with open(in_file, 'r') as f:
for line in f.readlines():
# Split the line tabwise
list_of_values = line.split('t')
- Implement an error check to confirm the characters:
if list_of_values[1] not in original_labels:
continue
- Extract the label and attach it to the main list:
label = np.zeros((num_of_charect , 1))
label[original_labels.index(list_of_values[1])] = 1
labels.append(label)
- Extract the character and add it to the main list:
extract_char = np.array([float(x) for x in list_of_values[s_index:e_index]])
information.append(extract_char)
- Exit the loop once the required dataset has been loaded:
if len(information) >= num_of_datapoints:
break
- Convert information and labels to NumPy arrays:
information = np.array(information)
labels = np.array(labels).reshape(num_of_datapoints, num_of_charect)
- Extract the number of dimensions:
num_dimension = len(information[0])
- Create and train the neural network:
neural_net = nl.net.newff([[0, 1] for _ in range(len(information[0]))], [128, 16, num_of_charect])
neural_net.trainf = nl.train.train_gd
error = neural_net.train(information[:train_param,:], labels[:train_param,:], epochs=10000, show=100, goal=0.01)
- Predict the output for the test input:
p_output = neural_net.sim(information[train_param:, :])
print "nTesting on unknown data:"
for i in range(test_param):
print "nOriginal:", original_labels[np.argmax(labels[i])]
print "Predicted:", original_labels[np.argmax(p_output[i])]
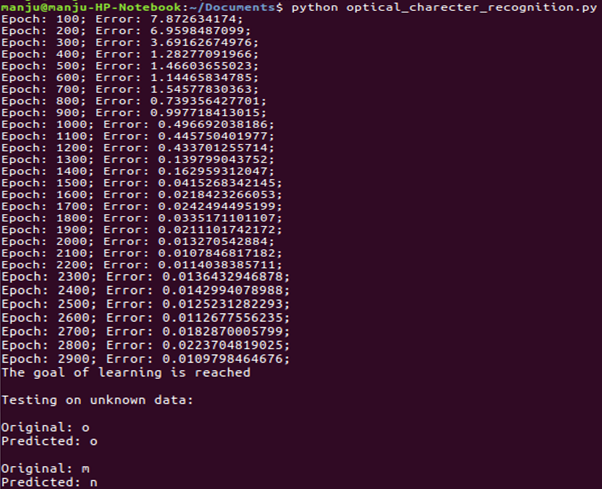
- The result obtained when optical_character_recognition.py is executed is shown in the following screenshot: