A typical hybrid application comprises a number of components, built using a variety of technologies, distributed across a range of sites and connected by networks of varying bandwidth and reliability. With this complexity, it is very important to be able to monitor how well the system is functioning, and quickly take any necessary restorative action in the event of failure. However, monitoring a complex system is itself a complex task, requiring tools that can quickly gather performance data to help you analyze throughput and pinpoint the causes of any errors, failures, or other shortcomings in the system.
The range of problems can vary significantly, from simple failures caused by application errors in a service running in the cloud, through issues with the environment hosting individual elements, to complete systemic failure and loss of connectivity between components whether they are running on-premises or in the cloud.
Once you have been alerted to a problem, you must be able to take the appropriate steps to correct it and keep the system functioning. The earlier you can detect issues and the more quickly you can fix them, the less impact they will have on the operations that your business depends on, and on the customers using your system.
It is important to follow a systematic approach, not only when managing hybrid applications but also when deploying and updating the components of your systems. You should try to minimize the performance impact of the monitoring and management process, and you should avoid making the entire system unavailable if you need to update specific elements.
Collecting diagnostic information about the way in which your system operates is also a fundamentally important part in determining the capacity of your solution, and this in turn can affect any service level agreement (SLA) that you offer users of your system. By monitoring your system you can determine how it is consuming resources as the volume of requests increases or decreases, and this in turn can assist in assessing the resources required and the running costs associated with maintaining an agreed level of performance.
This appendix explores the challenges encountered in keeping your applications running well and fulfilling your obligations to your customers. It also describes the technologies and tools that the Windows Azure™ technology platform provides to help you monitor and manage your solutions in a proactive manner, as well as assisting you in determining the capacity and running costs of your systems.
Use Cases and Challenges
Monitoring and managing a hybrid application is a nontrivial task due to the number, location, and variety of the various moving parts that comprise a typical business solution. Gathering accurate and timely metrics is key to measuring the capacity of your solution and monitoring the health of the system. Additionally, well defined procedures for recovering elements in the event of failure are of paramount importance. You may also be required to collect routine auditing information about how your system is used, and by whom.
The following sections describe some common use cases for monitoring and maintaining a hybrid solution, and summarize many of the challenges you will encounter while performing the associated tasks.
Measuring and Adjusting the Capacity of Your System
Description: You need to determine the capacity of your system so that you can identify where additional resources may be required, and the running costs associated with these resources.
In a commercial environment, customers paying to use your service expect to receive a quality of service and level of performance defined by their SLA. Even nonpaying visitors to your web sites and services will anticipate that their experience will be trouble-free; nothing is more annoying to potential customers than running up against poor performance or errors caused by a lack of resources.
 Bharath says: Bharath says: |
|
|---|---|

|
Customers care about the quality of service that your system provides, not how well the network or the cloud environment is functioning. You should ensure that your system is designed and optimized for the cloud as this will help you set (and fulfill) realistic expectations for your users. |
One way to measure the capacity of your system is to monitor its performance under real world conditions. Many of the issues associated with effectively monitoring and managing a system also arise when you are hosting the solution on-premises using your organization's servers. However, when you relocate services and functionality to the cloud, the situation can become much more complicated for a variety of reasons, including:
- The servers are no longer running locally and may be starting up and shutting down automatically as your solution scales elastically.
- There may be many instances of your services running across these servers.
- Applications in the cloud may be multi-tenanted.
- Communications may be brittle and sporadic.
- Operations may run asynchronously.
This is clearly a much more challenging environment than the on-premises scenario. You must consider not just how to gather the statistics and performance data from each instance of each service running on each server, but also how to consolidate this information into a meaningful view that an administrator can quickly use to determine the health of your system and determine the cause of any performance problems or failures. In turn, this requires you to establish an infrastructure that can unobtrusively collect the necessary information from your services and servers running in the cloud, and persist and analyze this data to identify any trends that can highlight scope for potential failure; such as excessive request queue lengths, processing bottlenecks, response times, and so on.
You can then take steps to address these trends, perhaps by starting additional service instances, deploying services to more datacenters in the cloud, or modifying the configuration of the system. In some cases you may also determine that elements of your system need to be redesigned to better handle the throughput required. For example, a service processing requests synchronously may need to be reworked to perform its work asynchronously, or a different communications mechanism might be required to send requests to the service more reliably.
Monitoring Services to Detect Performance Problems and Failures Early
Description: You need to maintain a guaranteed level of service.
In an ideal situation, software never fails and everything always works. This is unrealistic in the real world, but you should aim to give users the impression that your system is always running perfectly; they should not be aware of any problems that might occur.
However, no matter how well tested a system is there will be factors outside your control that can affect how your system functions; the network being a prime example. Additionally, unless you have spent considerable time and money performing a complete and formal mathematical verification of the components in your solution, you cannot guarantee that they are free of bugs. The key to maintaining a good quality of service is to detect problems before your customers do, diagnose their cause, and either repair these failures quickly or reconfigure the system to transparently redirect customer requests around them.
|
Poe says: |
|
|---|---|

|
Remember that testing can only prove the presence and not the absence of bugs. |
If designed carefully, the techniques and infrastructure you employ to monitor and measure the capacity of your system can also be used to detect failures. It is important that the infrastructure flags such errors early so that operations staff can take the proper corrective actions rapidly and efficiently. The information gathered should also be sufficient to enable operations staff to spot any trends, and if necessary dynamically reconfigure the system to add or remove resources as appropriate to accommodate any change in demand.
Recovering from Failure Quickly
Description: You need to handle failure systematically and restore functionality quickly.
Once you have determined the cause of a failure, the next task is to recover the failed components or reconfigure the system. In a live environment spanning many computers and supporting many thousands of users, you must perform this task in a thoroughly systematic, documented, and repeatable manner, and you should seek to minimize any disruption to service. Ideally, the steps that you take should be scripted so that you can automate them, and they must be robust enough to record and handle any errors that occur while these steps are being performed.
Logging Activity and Auditing Operations
Description: You need to record all operations performed by every instance of a service in every datacenter.
You may be required to maintain logs of all the operations performed by users accessing each instance of your service, performance variations, errors, and other runtime occurrences. These logs should be a complete, permanent, and secure record of events. Logging may be a regulatory requirement of your system, but even if is not, you may still need to track the resources accessed by each user for billing purposes.
An audit log should include a record of all operations performed by the operations staff, such as service shutdowns and restarts, reconfigurations, deployments, and so on. If you are charging customers for accessing your system, the audit log should also contain information about the operations requested by your customers and the resources consumed to perform these operations.
An error log should provide a date and time-stamped list of all the errors and other significant events that occur inside your system, such as exceptions raised by failing components and infrastructure, and warnings concerning unusual activity such as failed logins.
A performance log should provide sufficient data to help monitor and measure the health of the elements that comprise your system. Analytical tools should be available to identify trends that may cause a subsequent failure, such as a SQL Azure™ technology platform database nearing its configured capacity, enabling the operations staff to perform the actions necessary to prevent such a failure from actually occurring.
Deploying and Updating Components
Description: You need to deploy and update components in a controlled, repeatable, and reliable manner whilst maintaining availability of the system.
As in the use case for recovering from system failure, all component deployment and update operations should be performed in a controlled and documented manner, enabling any changes to be quickly rolled back in the event of deployment failure; the system should never be left in an indeterminate state. You should implement procedures that apply updates in a manner that minimizes any possible disruption for your customers; the system should remain available while any updates occur. In addition, all updates must be thoroughly tested in the cloud environment before they are made available to live customers.
Cross-Cutting Concerns
This section summarizes the major cross-cutting concerns that you may need to address when implementing a strategy for monitoring and managing a hybrid solution.
Performance
Monitoring a system and gathering diagnostic and auditing information will have an effect on the performance of the system. The solution you use should minimize this impact so as not to adversely affect your customers.
For diagnostic information, in a stable configuration, it might not be necessary to gather extensive statistics. However, during critical periods collecting more information might help you to detect and correct any problems more quickly. Therefore any solution should be flexible enough to allowing tuning and reconfiguration of the monitoring process as the situation dictates.
The policy for gathering auditing information is unlikely to be as flexible, so you should determine an efficient mechanism for collecting this data, and a compact mechanism for transporting and storing it.
Security
There are several security aspects to consider concerning the diagnostic and auditing data that you collect:
- Diagnostic data is sensitive as it may contain information about the configuration of your system and the operations being performed. If intercepted, an attacker may be able to use this information to infiltrate your system. Therefore you should protect this data as it traverses the network. You should also store this data securely.
- Diagnostic data may also include information about operations being performed by your customers. You should avoid capturing any personally identifiable information about these customers, storing it with the diagnostic data, or making it available to the operators monitoring your system.
- Audit information forms a permanent record of the tasks performed by your system. Depending on the nature of your system and the jurisdiction in which you organization operates, regulatory requirements may dictate that you must not delete this data or modify it in any way. It must be stored safely and protected resolutely.
Additionally, the monitoring, management, deployment, and maintenance tasks associated with the components that comprise your system are sensitive tasks that must only be performed by specified personnel. You should take appropriate steps to prevent unauthorized staff from being able to access monitoring data, deploy components, or change the configuration of the system.
Windows Azure and Related Technologies
Windows Azure provides a number of useful tools and APIs that you can employ to supervise and manage hybrid applications. Specifically you can use:
- Windows Azure Diagnostics to capture diagnostic data for monitoring the performance of your system. Windows Azure Diagnostics can operate in conjunction with the Enterprise Library Logging Application Block. Microsoft Systems Center Operations Manager also provides a management pack for Windows Azure, again based on Windows Azure Diagnostics.
- The Windows Azure Management Portal, which enables administrators to provision the resources and websites required by your applications. It also provides a means for implementing the various security roles required to protect these resources and websites. For more information, log in to the Management Portal at http://windows.azure.com.
- The Windows Azure Service Management API, which enables you to create your own custom administration tools, as well as carrying out scripted management tasks from the Windows PowerShell® command-line interface.
|
Bharath says: |
|
|---|---|
|
|
You can configure Remote Desktop access for the roles running your applications and services in the cloud. This feature enables you to access the Windows logs and other diagnostic information on these machines directly, by means of the same procedures and tools that you use to obtain data from computers hosted on-premises. |
The following sections provide more information about the Windows Azure Service Management API and Windows Azure Diagnostics, and summarize good practice for utilizing them to support a hybrid application.
Monitoring Services, Logging Activity, and Measuring Performance in a Hybrid Application by Using Windows Azure Diagnostics
An on-premises application typically consists of a series of well-defined elements running on a fixed set of computers, accessing a series of well-known resources. Monitoring such an application requires being able to transparently trap and record the various requests that flow between the components, and noting any significant events that occur. In this environment, you have total control over the software deployed and configuration of each computer. You can install tools to capture data locally on each machine, and you combine this data to give you an overall view of how well the system is functioning.
In a hybrid application, the situation is much more complicated; you have a dynamic environment where the number of compute nodes (implementing web and worker roles) running instances of your services and components might vary over time, and the work being performed is distributed across these nodes. You have much less control of the configuration of these nodes as they are managed and maintained by the datacenters in which they are hosted. You cannot easily install your own monitoring software to assess the performance and well-being of the elements located at each node. This is where Windows Azure Diagnostics is useful.
Windows Azure Diagnostics provides an infrastructure running on each node that enables you to gather performance and other diagnostic data about the components running on these nodes. It is highly configurable; you specify the information that you are interested in, whether it is data from event logs, trace logs, performance counters, IIS logs, crash dumps, or other arbitrary log files. For detailed information about how to implement Windows Azure Diagnostics and configure your applications to control the type of information that Windows Azure Diagnostics records, see "Collecting Logging Data by Using Windows Azure Diagnostics" on MSDN.
Windows Azure Diagnostics is designed specifically to operate in the cloud. As a result, it is highly scalable while attempting to minimize the performance impact that it has on the roles that are configured to use it. However, the diagnostic data itself is held locally in each compute node being monitored. This data is lost if the compute node is reset. Also, the Windows Azure diagnostic monitor applies a 4GB quota to the data that it logs; if this quota is exceeded, information is deleted on an age basis. You can modify this quota, but you cannot exceed the storage capacity specified for the web or worker role. In many cases you will likely wish to retain this data, and you can arrange to transfer the diagnostic information to Windows Azure storage, either periodically or on demand. The topics "How to Schedule a Transfer" and "How to Perform an On-Demand Transfer" provide information on how to perform these tasks.
|
Markus says: |
|
|---|---|

|
Transferring diagnostic data to Windows Azure storage on demand may take some time, depending on the volume of information being copied and the location of the Windows Azure storage. To ensure best performance, use a storage account hosted in the same datacenter as the compute node running the web or worker role being monitored. Additionally, you should perform the transfer asynchronously so that it minimizes the impact on the response time of the code. |
Windows Azure storage is independent of any specific compute node and the information that it contains will not be lost if any compute node is restarted. You must create a storage account for holding this data, and you must configure the Windows Azure Diagnostics Monitor with the address of this storage account and the appropriate access key. For more information, see "How to Specify a Storage Account for Transfers." Event-based logs are transferred to Windows Azure table storage and file-based logs are copied to blob storage. The appropriate tables and blobs are created by the Windows Azure Diagnostics Monitor; for example, information from the Windows Event Logs is transferred to a table named WADWindowsEventLogsTable, data gathered from performance counters is copied to a table name WADPerformanceCountersTable. Crash dumps are transferred to a blob storage container under the path wad-crash-dumps and IIS 7.0 logs are copied to another blob storage container under the path wad-iis-logfiles.
Guidelines for Using Windows Azure Diagnostics
From a technical perspective, Windows Azure Diagnostics is implemented as a component within the Windows Azure SDK that supports that standard diagnostic APIs. This component is called the Windows Azure diagnostic monitor, and it runs in the cloud alongside each web role or worker role that you wish to gather information about.
You can configure the diagnostic monitor to determine the data that it should collect by using the Windows Azure Diagnostics configuration file, diagnostics.wadcfg. For more information, see "How to Use the Windows Azure Diagnostics Configuration File." Additionally, an application can record custom trace information by using a trace log. Windows Azure Diagnostics provides the DiagnosticMonitorTraceListener class to perform this task, and you can configure this type of tracing by adding the appropriate <system.diagnostics> section to the application configuration file of your web or worker role. See "How to Configure the TraceListener in a Windows Azure Application" for more information.
If you are building a distributed, hybrid solution, using Windows Azure Diagnostics enables you to gather the data from multiple role instances located on distributed compute nodes, and combine this data to give you an overall view of your system. You can use System Center Operations Manager, or alternatively there are an increasing number of third-party applications available that can work with the raw data available through Windows Azure Diagnostics to present the information in a variety of easy to digest ways. These tools enable you to determine the throughput, performance, and responsiveness of your system and the resources that it consumes. By analyzing this information, you can pinpoint areas of concern that may impact the operations that your system implements, and also evaluate the costs associated with performing these operations.
The following list suggests opportunities for incorporating Windows Azure Diagnostics into your solutions:
-
You need to provide a centralized view of your system to help ensure that you meet the SLA requirements of your customers and to maintain an accurate record of resource use for billing purposes. Your organization currently uses System Center Operations Manager to monitor and maintain services running on-premises.
If you have deployed Systems Center Operations Manager on-premises, you can also install the Monitoring Management Pack for Windows Azure. This pack operates in conjunction with Windows Azure Diagnostics on each compute node, enabling you to record and observe the diagnostics for your applications and services hosted in the cloud and integrate it with the data for the other elements of your solution that are running on-premises. This tool is also invaluable for assessing how the services that comprise your system are using resources, helping you to determine the costs that you should be recharging to your customers, if appropriate.
By default, the System Center Monitoring Pack for Windows Azure Applications monitors the deployment state of roles, the state of each hosted service and role, and the performance counters measuring ASP.NET performance, disk capacity, physical memory utilization, network adapter utilization, and processor performance.
Using Systems Center Operations Manager, you can configure alerts that are raised when various measurements exceed specified thresholds. You can associate tasks with these alerts, and automate procedures for taking any necessary corrective action. For example, you can arrange for additional role instances to be started if the response time for handling client requests is too long, or you can send an alert to an operator who can investigate the issue.
For more information, see "System Center Monitoring Pack for Windows Azure Applications."
-
You need to provide a centralized view of your system to help monitor your application and maintain an audit record of selected operations. Your organization does not use System Center Operations Manager.
You can periodically transfer the diagnostic data to Windows Azure storage and examine it by using a utility such as Windows Azure Storage Explorer from Neudesic (see http://azurestorageexplorer.codeplex.com/). Additionally, if you have the Visual Studio® development system and the Windows Azure SDK, you can connect to Windows Azure storage and view the contents of tables and blobs by using Server Explorer. For more information, see "How to View Diagnostic Data Stored in Windows Azure Storage."
However, these tools simply provide very generalized access to Windows Azure storage. If you need to analyze the data in detail it may be necessary to build a custom dashboard application that connects to the tables and blobs in the storage account, aggregates the information gathered for all the nodes, and generates reports that show how throughput varies over time. This enables you to identify any trends that may require you to allocate additional resources. You can also download the diagnostic data from Windows Azure storage to your servers located on-premises if you require a permanent historical record of this information, such as an audit log of selected operations, or you wish to analyze the data offline.
Figure 1 depicts the overall structure of a solution that gathers diagnostics data from multiple nodes and analyzes it on-premises. The diagnostics data is reformatted and copied into tables in a SQL Server database, and SQL Server Reporting Services outputs a series of reports that provide a graphical summary showing the performance of the system.
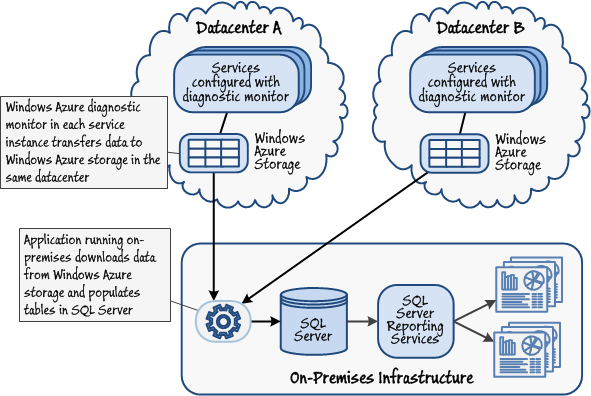 Figure 1
Figure 1
Gathering diagnostic data from multiple nodesAn alternative approach is to use a third party solution. Some that were available at the time of writing include the following:
- Azure Diagnostics Manager from Cerebrata
- AzureWatch from Paraleap Technologies
- ManageAxis from Cumulux
-
You need to instrument your web applications and services to identify any potential bottlenecks and capture general information about the health of your solution.
Applications running in the cloud can use the Windows Azure Diagnostics APIs to incorporate custom logic that generates diagnostic information, enabling you to instrument your code and monitor the health of your applications by using the performance counters applicable to web and worker roles. You can also define your own custom diagnostics and performance counters. The topic "Tracing the Flow of Your Windows Azure Application" provides more information.
It is also useful to trace and record any exceptions that occur when a web application runs, so that you can analyze the circumstances under which these exceptions arise and if necessary make adjustments to the way in which the application functions. You can make use of programmatic features such as the Microsoft Enterprise Library Exception Handling Application Block to capture and handle exceptions, and you can record information about these exceptions to Windows Azure Diagnostics by using the Enterprise Library Logging Application Block. This data can then be examined by using a tool such as System Center Operations Manager with the Monitoring Pack for Windows Azure, providing a detailed record of the exceptions raised in your application across all nodes, and also generating alerts if any of these exceptions require the intervention of an operator.
Note:For more information about incorporating the Logging Application Block into a Windows Azure solution, see "Using classic Enterprise Library 5.0 in Windows Azure" on CodePlex.
For more information about using the Exception Handling Application Block, see "The Exception Handling Application Block." -
Most of the time your web and worker roles function as expected, but occasionally they run slowly and become unresponsive. At these times you need gather additional detailed diagnostic data to help you to determine the cause of the problems. You need to be able to modify the configuration of the Windows Azure diagnostic monitor on any compute node without stopping and restarting the node.
To minimize the overhead associated with logging, only trace logs, infrastructure logs, and IIS logs are captured by default. If you need to examine data from performance counters, Windows® operating system event logs, IIS failed request logs, crash dumps, or other arbitrary logs and files you must enable these items explicitly. An application can dynamically modify the Windows Azure Diagnostics configuration by using the Windows Azure SDK from your applications and services. For more information, see "How to: Initialize the Windows Azure Diagnostic Monitor and Configure Data Sources."
You can also configure Windows Azure Diagnostics for a web or worker role remotely by using the Windows Azure SDK. You can follow this approach to implement a custom application running on-premises that connects to a node running a web or worker role, specify the diagnostics to collect, and transfer the diagnostic data periodically to Windows Azure storage. For more information, see "How to Remotely Change the Diagnostic Monitor Configuration."
Bharath says:
The Windows Azure diagnostic monitor periodically polls its configuration information, and any changes come into effect after the polling cycle that observes them. The default polling interval is 1 minute. You can modify this interval, but you should not make it too short as you may impact the performance of the diagnostic monitor.
Guidelines for Securing Windows Azure Diagnostic Data
Windows Azure Diagnostics requires that the roles being monitored run with full trust; the enableNativeCodeExecution attribute in the service definition file, ServiceDefinition.csdef, for each role must be set to true. This is actually the default value.
The diagnostic information recorded for your system is a sensitive resource and can yield critical information about the structure and security of your system. This information may be useful to an attacker attempting to penetrate your system. Therefore, you should carefully guard the storage accounts that you use to record diagnostic data and ensure that only authorized applications have access to the storage account keys. You should also consider protecting all communications between the Windows Azure storage service and your on-premises applications by using HTTPS.
If you have built on-premises applications or scripts that can dynamically reconfigure the diagnostics configuration for any role, ensure that only trusted personnel with the appropriate authorization can run these applications.
Deploying, Updating, and Restoring Functionality by Using the Windows Azure Service Management API and PowerShell
The Windows Azure Management Portal provides the primary interface for managing Windows Azure subscriptions. You can use this portal to upload applications, and to manage hosted services and storage accounts. However, you can also manage your Windows Azure applications programmatically by using the Windows Azure Service Management API. You can utilize this API to build custom management applications that deploy, configure, and manage your web applications and services. You can also access these APIs through the Windows Azure PowerShell cmdlets; this approach enables you to quickly build scripts that administrators can run to perform common tasks for managing your applications.
The Windows Azure SDK provides tools and utilities to enable a developer to package web and worker roles, and to deploy these packages to Windows Azure. Many of these tools and utilities also employ the Windows Azure Service Management API, and some are invoked by several of the Microsoft Build Engine (MSBuild) tasks and wizards implemented by the Windows Azure templates in Visual Studio.
|
Markus says: |
|
|---|---|
|
|
You can download the code for a sample application that provides a client-side command line utility for managing Windows Azure applications and services from Windows Azure ServiceManagement Sample. You can download the Windows Azure PowerShell cmdlets at http://www.windowsazure.com/en-us/manage/downloads/. |
Guidelines for using the Windows Azure Service Management API and PowerShell
While the Management Portal is a powerful application that enables an administrator to manage and configure Windows Azure services, this is an interactive tool that requires users to have a detailed understanding of the structure of the solution, where the various elements are deployed, and how to configure the security requirements of these elements. It also requires that the user has knowledge of the Windows Live® ID and password associated with the Windows Azure subscription for your organization, and any user who has this information has full authority over your entire solution. If these credentials are disclosed to an attacker or another user with malicious intent, they can easily disrupt your services and damage your business operations.
The following scenarios include suggestions for mitigating these problems:
-
You need to provide controlled access to an operator to enable them to quickly perform everyday tasks such as configuring a role, provisioning services, or starting and stopping role instances. The operator should not require a detailed understanding of the structure of the application, and should not be able to perform tasks other than those explicitly mandated.
This is a classic case for using scripts incorporating the Windows Azure PowerShell cmdlets. You can provide a series of scripts that perform the various tasks required, and you can parameterize them to enable the operator to provide any additional details, such as the filename of a package containing a web role to be deployed, or the address of a role instance to be taken offline. This approach also enables you to control the sequence of tasks if the operator needs to perform a complex deployment, involving not just uploading web and worker roles, but also provisioning and managing SQL Azure databases, for example.
To run these scripts, the operator does not need to be provided with the credentials for the Windows Azure subscription. Instead, the security policy enforced by the Windows Azure Service Management API requires that the account that the operator is using to run the scripts is configured with the appropriate management certificate, as described in the section "Guidelines for Securing Management Access to Azure Subscriptions" later in this appendix. The fewer operators that know the credentials necessary for accessing the Windows Azure subscription, the less likely it is that these credentials will be disclosed to an unauthorized third party, inadvertently or otherwise.
Scripting also provides for consistency and repeatability, reducing the chances of human error on the part of the operator, especially when the same series of tasks must be performed across a set of roles and resources hosted in different datacenters.
The disadvantage of this approach is that the scripts must be thoroughly tested, verified, and maintained. Additionally, scripts are not ideal for handling complex logic, such as performing error handling and graceful recovery.
Poe says:
A script that creates or updates roles should deploy these roles to the staging environment in one or more datacenters for testing prior to making them available to customers. Switching from the staging to production environment can also be scripted, but should only be performed once testing is complete. -
You need to provide controlled access to an operator to enable them to quickly perform a potentially complex series of tasks for configuring, deploying, or managing your system. The operator should not require a detailed understanding of the structure of the application, and should not be able to perform tasks other than those explicitly mandated.
This scenario is an extension of the previous case, except that the operations are more complex and potentially more error-prone. In this scenario, it may be preferable to use the Windows Azure Service Management API directly from a custom application running on-premises. This application can incorporate a high degree of error detection, handling, and retry logic (if appropriate). You can also make the application more interactive, enabling the operator to specify the details of items such as the address of a role to be taken offline, or the filename of a package to deploy, through a graphical user interface with full error checking. A wizard oriented approach is easier to understand and less error prone than expecting the operator to provide a lengthy string of parameters on the command line as is common with the scripted approach.
A custom application also enables you to partition the tasks that can be performed by different operators or roles; the application can authenticate the user, and only enable the features and operations relevant to the identity of the user or the role that the user belongs to. However, you should avoid attempting to make the application too complex; keep the features exposed simple to use, and implement meaningful and intelligent default values for items that users must select.
A custom application should audit all operations performed by each user. This audit trail provides a full maintenance and management history of the system, and it must be stored in a secure location.
Markus says:
The Windows Azure Service Management API is actually a wrapper around a REST interface; all service management requests are actually transmitted as HTTP REST requests. Therefore, you are not restricted to using Windows applications for building custom management applications; you can use any programming language or environment that is capable of sending HTTP REST requests. For more information, see "Windows Azure Service Management REST API Reference." Of course, the disadvantage of this approach is that, being interactive, such an application cannot easily be used to perform automated routine tasks scheduled to occur at off-peak hours. In this case, the scripted approach or a solution based on a console-mode command-line application may be more appropriate.
-
You are using Systems Center Operations Manager to monitor the health of your system. If a failure is detected in one or more elements, you need to recover from this failure quickly.
System Center Operations Manager can raise an alert when a significant event occurs or a performance measure exceeds a specified threshold. You can respond to this alert in a variety of ways, such as notifying an operator or invoking a script. You can exploit this feature to detect the failure of a component in your system and run a PowerShell script that attempts to restart it. For more information, see the topic "Enable Notification Channels."
Guidelines for Securing Management Access to Windows Azure Subscriptions
The Windows Azure Service Management API ensures that only authorized applications can perform management operations, by enforcing mutual authentication using management certificates over SSL.
When an on-premises application submits a management request, it must provide the key to a management certificate installed on the computer running the application as part of the request. A management certificate must have a key length of at least 2048 bits and must be installed in the Personal certificate store of the account running the application. This certificate must also include the private key.
The same certificate must also be available in the management certificates store in the Windows Azure subscription that manages the web applications and services. You should export the certificate from the on-premises computer as a .cer file without the private key and upload this file to the Management Certificates store by using the Management Portal. For more information about creating management certificates, see the topic "How to: Manage Management Certificates in Windows Azure."
|
Poe says: |
|
|---|---|
|
|
Remember that the Windows Azure SDK includes tools that enable a developer to package web and worker roles, and to deploy these packages to Windows Azure. These tools also require you to specify a management certificate. However, you should be wary of letting developers upload new versions of code to your production site. This is a task that must be performed in a controlled manner and only after the code has been thoroughly tested. For this reason, you should either refrain from provisioning your developers with the management certificates necessary for accessing your Windows Azure subscription, or you should retain a separate Windows Azure subscription (for development purposes) with its own set of management certificates if your developers need to test their own code in the cloud. |
More Information
All links in this book are accessible from the book's online bibliography available at: http://msdn.microsoft.com/en-us/library/hh968447.aspx.
- Management Portal at http://windows.azure.com.
- "Collecting Logging Data by Using Windows Azure Diagnostics" at
http://msdn.microsoft.com/en-us/library/gg433048.aspx. - "How to Schedule a Transfer" at
http://msdn.microsoft.com/en-us/library/windowsazure/gg433085.aspx. - "How to Perform an On-Demand Transfer" at
http://msdn.microsoft.com/en-us/library/windowsazure/gg433075.aspx. - "How to Specify a Storage Account for Transfers" at
http://msdn.microsoft.com/en-us/library/windowsazure/gg433081.aspx. - "How to Use the Windows Azure Diagnostics Configuration File" at
http://msdn.microsoft.com/en-us/library/windowsazure/hh411551.aspx. - "How to Configure the TraceListener in a Windows Azure Application" at
http://msdn.microsoft.com/en-us/library/hh411522.aspx. - "System Center Monitoring Pack for Windows Azure Applications" at
http://pinpoint.microsoft.com/en-us/applications/system-center-monitoring-pack-for-windows-azure-applications-12884907699. - Windows Azure Storage Explorer from Neudesic at
http://azurestorageexplorer.codeplex.com/. - "How to View Diagnostic Data Stored in Windows Azure Storage" at
http://msdn.microsoft.com/en-us/library/windowsazure/hh411547.aspx. - Azure Diagnostics Manager from Cerebrata at http://www.cerebrata.com/Products/AzureDiagnosticsManager/Default.aspx.
- AzureWatch from Paraleap Technologies at http://www.paraleap.com/.
- "Tracing the Flow of Your Windows Azure Application" at http://msdn.microsoft.com/en-us/library/windowsazure/hh411529.aspx.
- "Using classic Enterprise Library 5.0 in Windows Azure" at http://entlib.codeplex.com/releases/view/75025#DownloadId=336804.
- "The Exception Handling Application Block" at http://msdn.microsoft.com/en-us/library/ff664698(v=PandP.50).aspx.
- "How to: Initialize the Windows Azure Diagnostic Monitor and Configure Data Sources" at http://msdn.microsoft.com/en-us/library/windowsazure/gg433049.aspx.
- "How to Remotely Change the Diagnostic Monitor Configuration" at http://msdn.microsoft.com/en-us/library/windowsazure/gg432992.aspx.
- Download the code for a sample application that provides a client-side command line utility for managing Windows Azure applications and services from "Windows Azure ServiceManagement Sample" at
http://code.msdn.microsoft.com/windowsazure/Windows-Azure-CSManage-e3f1882c. - Download the Windows Azure PowerShell cmdlets from
http://www.windowsazure.com/en-us/manage/downloads/. - "Windows Azure Service Management REST API Reference" at http://msdn.microsoft.com/en-us/library/windowsazure/ee460799.aspx.
- "Enable Notification Channels" at http://technet.microsoft.com/en-us/library/dd440882.aspx.
- "How to: Manage Management Certificates in Windows Azure" at http://msdn.microsoft.com/en-us/library/windowsazure/gg551721.aspx.