Containment comes after identifying an event and concluding that action is required to limit its impact. Entities must understand the fundamentals of containment, the steps necessary to gather information on the event’s characteristics, and how to identify the population of affected systems and users and quarantine those systems until the situation is resolved and business is back to normal. These actions are undertaken by internal resources or outside experts. A strategy built around objectives drives containment. The common approach is to identify the symptoms, quarantine the systems, and get back to business as soon as possible. Some approaches seek to confirm attribution to specific attack groups and monitor the attacker’s movements. Another strategy is to quickly identify all affected systems and prepare each for eradication. There may be some cases in which following an attacker’s movements is prudent, but for many organizations, the risk of observing and not acting is high.
Containment works best when the incident response team knows its actions and references playbooks and checklists for guidance. Establishing fundamental action plans using playbooks is important. At a minimum, playbooks for addressing malware, denial of service, lost assets, data theft and unauthorized use or misuse of assets are important. Teams must also manage executive expectations during this time. Focus is necessary to identify the indicators of events and catch all systems affected. It is reasonable to keep leadership updated on progress and next steps but not to speculate or attempt to draw conclusions without complete information.
Indicators of Compromise
Indicators of compromise are artifacts and evidence observed inside information systems confirming the existence of attacker actions. These indicators of compromise (IOCs) include virus signatures, changes to file systems and registries and outbound and inbound connections to and from known malicious URLs and domains, to name a few. Threat intelligence documenting indicators from known threat groups adds context to investigations. When indicators point to potential threat actors as the source of an attack, the response team may be able to quickly ascertain the systems affected, by searching for the known indicators of that group.
Containment Fundamentals
Unplugging the network cable
Putting the machine in sleep mode (Powering it off causes volatile memory loss and the loss of forensic evidence.)
Isolating the machine, so that it cannot receive data via changes to DNS and firewall rules
After the systems are isolated, images should be taken for use during the investigation. As those images are analyzed, identification and imaging of other affected systems are completed as well. As more and more systems are taken offline, productivity issues will ensue, and communication with the business is vital. Several open source and commercial solutions are available, such as Volatility, Rekal, and EnCase. File system and memory images are key here.
Once all identified systems are imaged, the response team correlates the data from each to further identify IOCs not yet investigated. The response team’s goal is to identify as comprehensive a list of affected systems as possible. Attribution is not always necessary. In fact, for most entities, it is the last thing the response team should focus on. The focus should first be to contain the event and prepare for eradication.
Choosing a Containment Strategy
If incident response objectives are to identify, contain, and eradicate incidents as quickly as possible before any damage is done to sensitive data assets, what is the strategy for doing this? First, entities must assess the capabilities for containing events and incidents once they are identified. Small and medium-size organizations possess limited resources for responding properly to events, identifying indicators, uncovering them in information systems, and taking forensic images. These are specialized skills not often possessed internally. The strategy discussed in Chapter 5 engages outside entities to monitor detective capabilities such as data loss prevention, log correlation and security event management solutions. The strategy starts with identifying the event, working in concert with the third parties providing support to identify the IOCs and searching through the environment to locate other end points at which these indicators are present. The strategy then dictates eradicating the event and restoring systems, topics covered in Chapter 9.
The examples below outline specific types of containment but are not all-encompassing. Not every attack requires its own playbook, for example, attacks against a web application or server. The threat actor may exploit a vulnerability and gain access to the application or server. During the attack, the adversary may use rootkits, malware, and other tools to move laterally, elevate privileges, and maintain persistence. Playbooks may exist for the malware, rootkits, and unauthorized use of elevated privileges, but documentation about responding to web attacks or specific web vulnerabilities may not exist. A forensic investigation would lead to the web vulnerability as the source of the attack, with remediation occurring during the recovery phase.
Malware and Ransomware Outbreaks
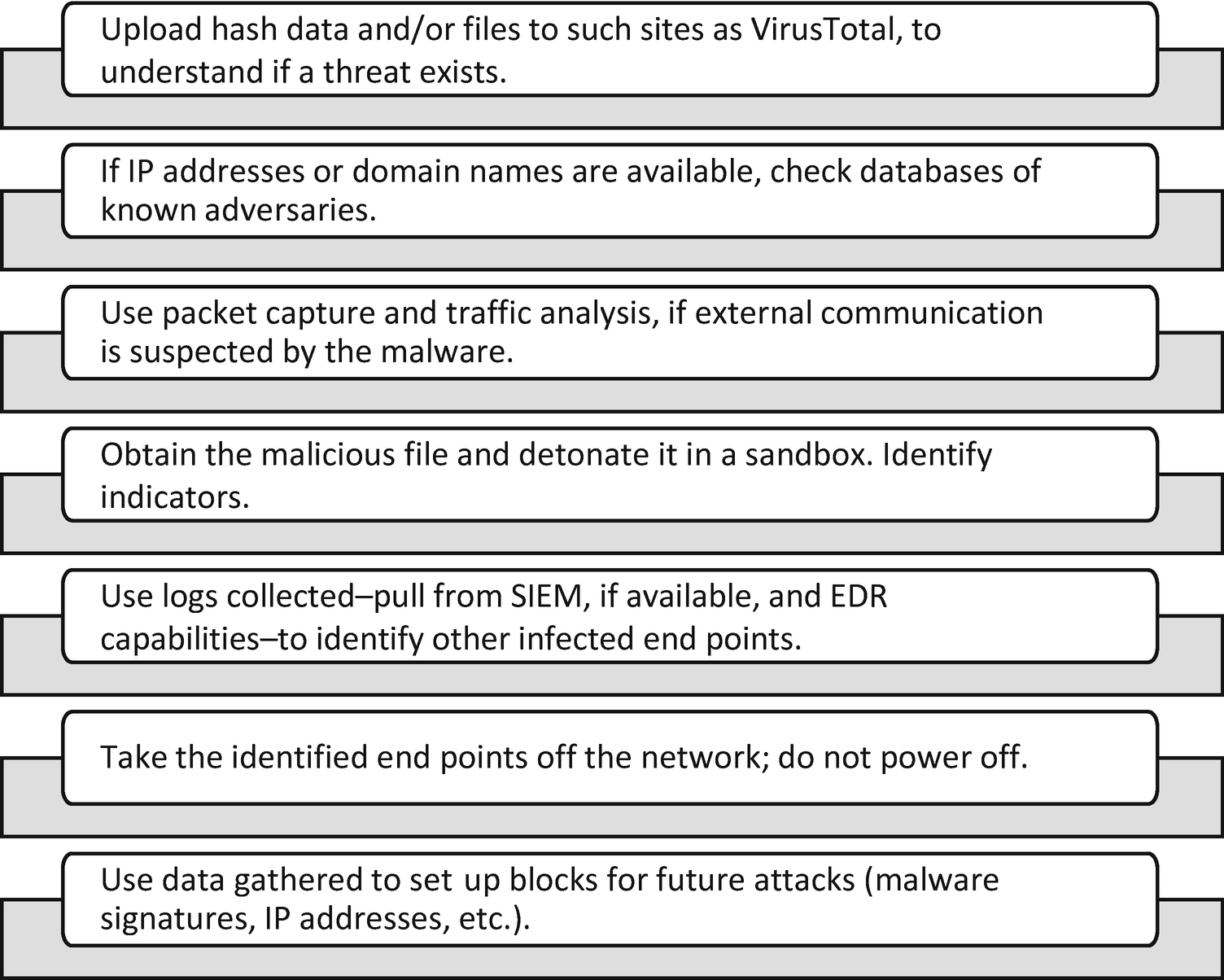
Typical steps taken to contain malware and ransomware outbreaks
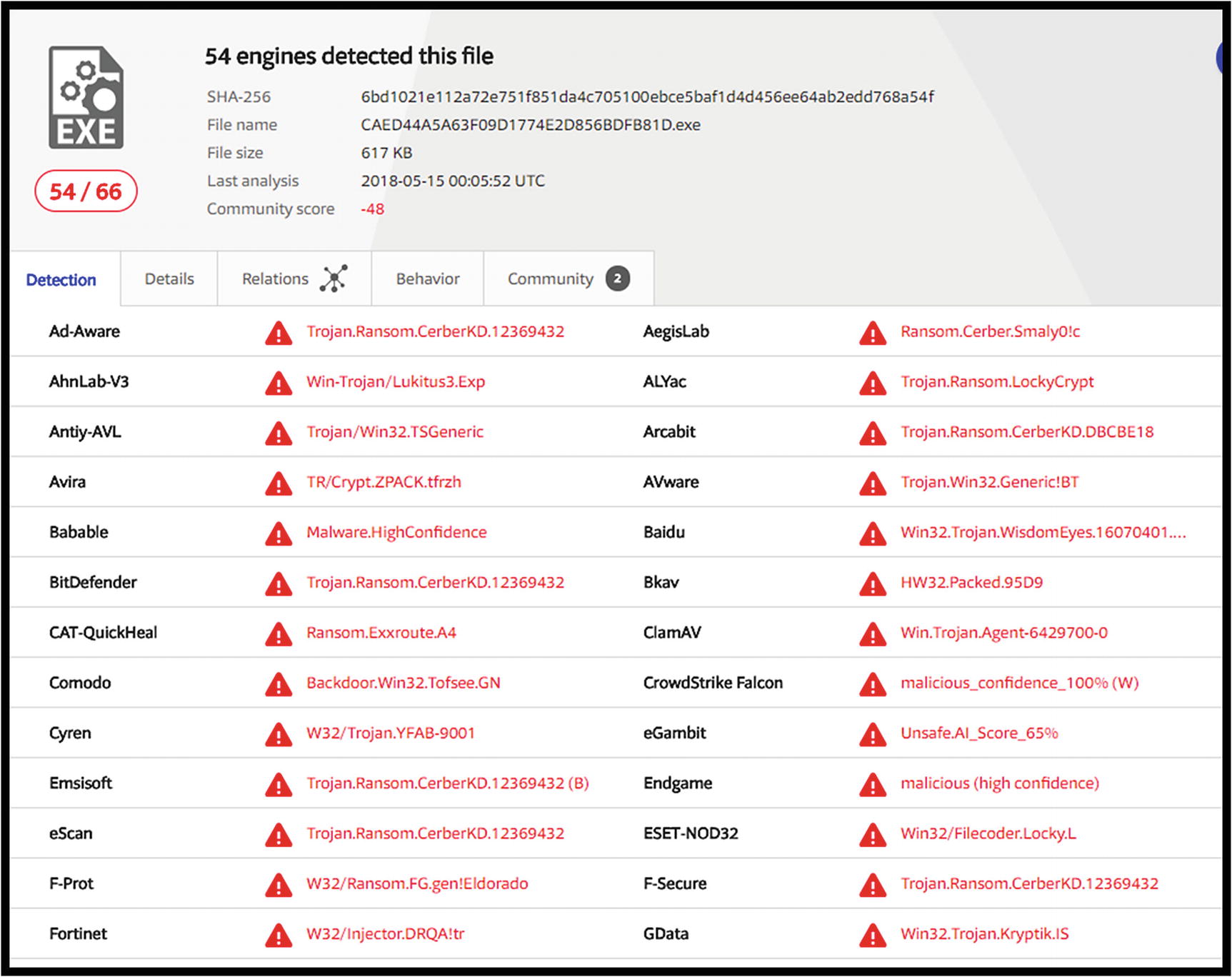
Image of initial results of Locky Ransomware analysis available at VirusTotal.com
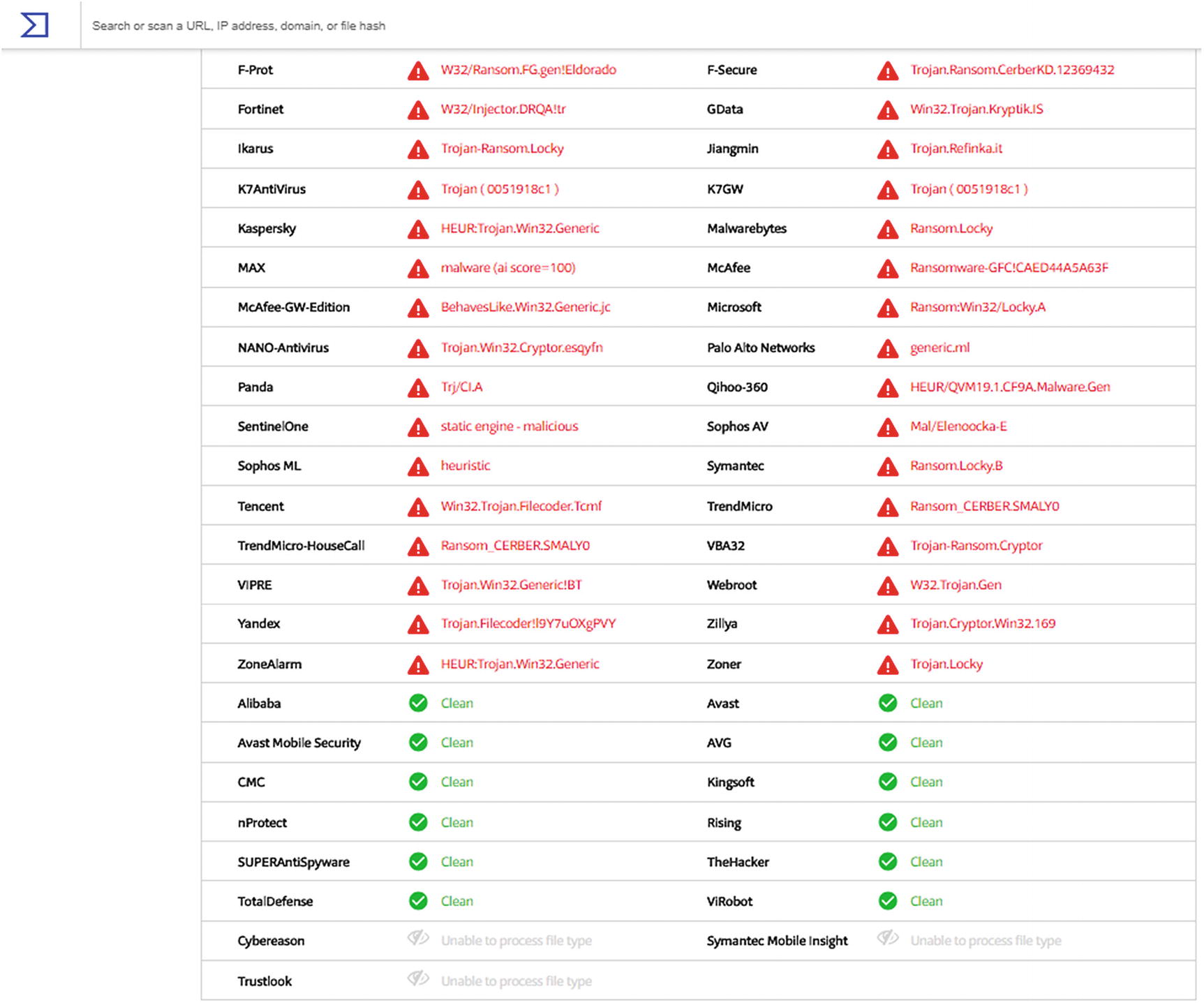
Results for the remaining 44 engines , from the VirusTotal analysis of Locky Ransomware
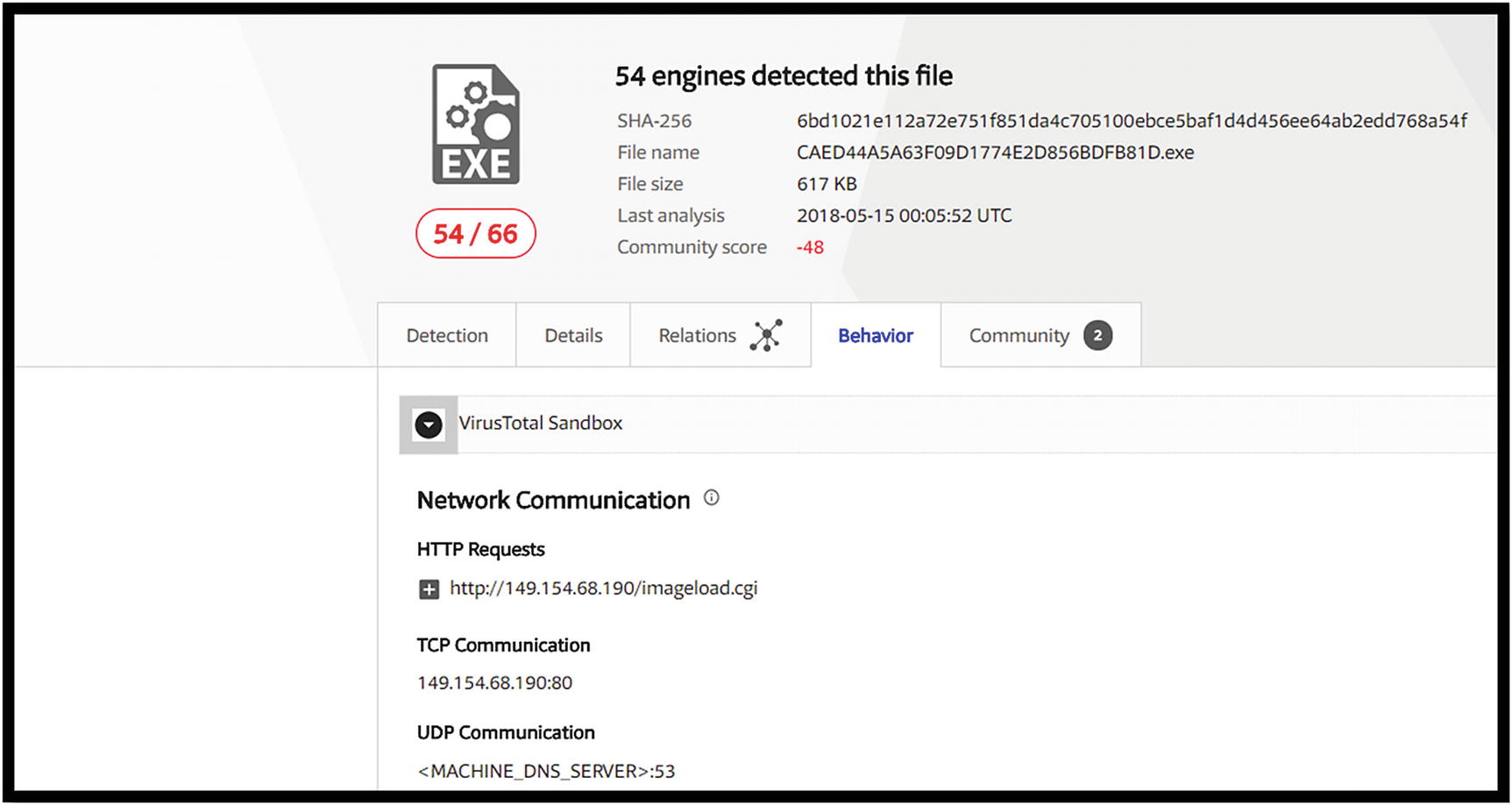
Network communications identified by VirusTotal for the Locky Ransomware malware
VirusTotal shows Locky connections to 149.154.68.190 using HTTP and 149.154.68.190:80 on TCP. The UDP connection attempts to connect to the DNS server on port 53.
Files opened and read by Locky and identified by VirusTotal
Locky opens several files, notably systems files. It also reads several systems files and several in the Python library. These are indicators the incident response team can use.
Snippets of files written and moved by Locky
The process and service actions of Locky and modules loaded, snippet only, for Locky
Locky opened the SERVICES_ACTIVE_DATABASE - localhost service manager and the RASMAN, WebClient, and LanmanWorkstation services.
Caution
Attachments uploaded to VirusTotal for scanning are kept in the database. Be careful of what is uploaded, because the contents of the documents uploaded are publicly available.
Uploading the file or executable normally allows VirusTotal to provide associated domain names or IP addresses, if available. VirusTotal also lets you upload domain names and IP addresses for analysis. Learning the domain where the malware originated might lead to detecting command and control (C2) traffic, or, at least, equip the entity to block those domains and IPs from further communication inside the organization. Malware often communicates externally to C2 servers. These servers deliver instructions to the malware at specific intervals, based on call-backs to the C2 server. Detecting the history of calls to C2 sites by the malware is possible with packet capture software such as WireShark. WireShark is an open source tool with many features for capturing and analyzing traffic for investigative purposes. The key to detecting C2 communication is knowing what to look for, based on the initial analysis of the malware. In its article “Detecting and Analyzing Locky Ransomware,” Digital Guardian displayed the malicious domain and IP used by the ransomware to download the malicious executable file 765f46vb.exe.1 Once initiated, Locky connected to 177.185.194.115, http://comprecaldas.com . No matter the tool utilized, tying these indicators back to machines making connections helps the incident response team detect other infected machines on the network.
Are files created and deleted?
Are registry changes made?
Does the malware attempt to connect outside the network?
Four Tools Commonly Used to Conduct Dynamic Analysis of Malware
Tool | Purpose |
|---|---|
ProcMon | A.k.a. Process Monitor, this tool is available through Microsoft Sysinternals and monitors file system and service behavior, noting any changes made by the malware. |
RegShot | In Windows environments, RegShot takes before and after snapshots of the registry. Once the malware is detonated in the sandbox, a second snapshot is taken. |
Process Explorer | Another free Microsoft tool, Process Explorer displays services and the associated dynamic link libraries (DLLs) attached. |
Detonating malware in a sandbox running ProcMon captures file system changes made by the malware and the starting and stopping of services. RegShot highlights changes made to registry settings by the malware, and Process Explorer shows services running, such as those captured by ProcMon. However, there is one exception, analysts can review the DLLs attached to those services. DLLs are libraries used to share code among applications and programs in Windows. Malware uses DLLs the same way, and threat hunters identify DLLs used by malware can search for DLLs attached to the processes run by malware as additional means for confirming that a machine or system is affected by the attack.
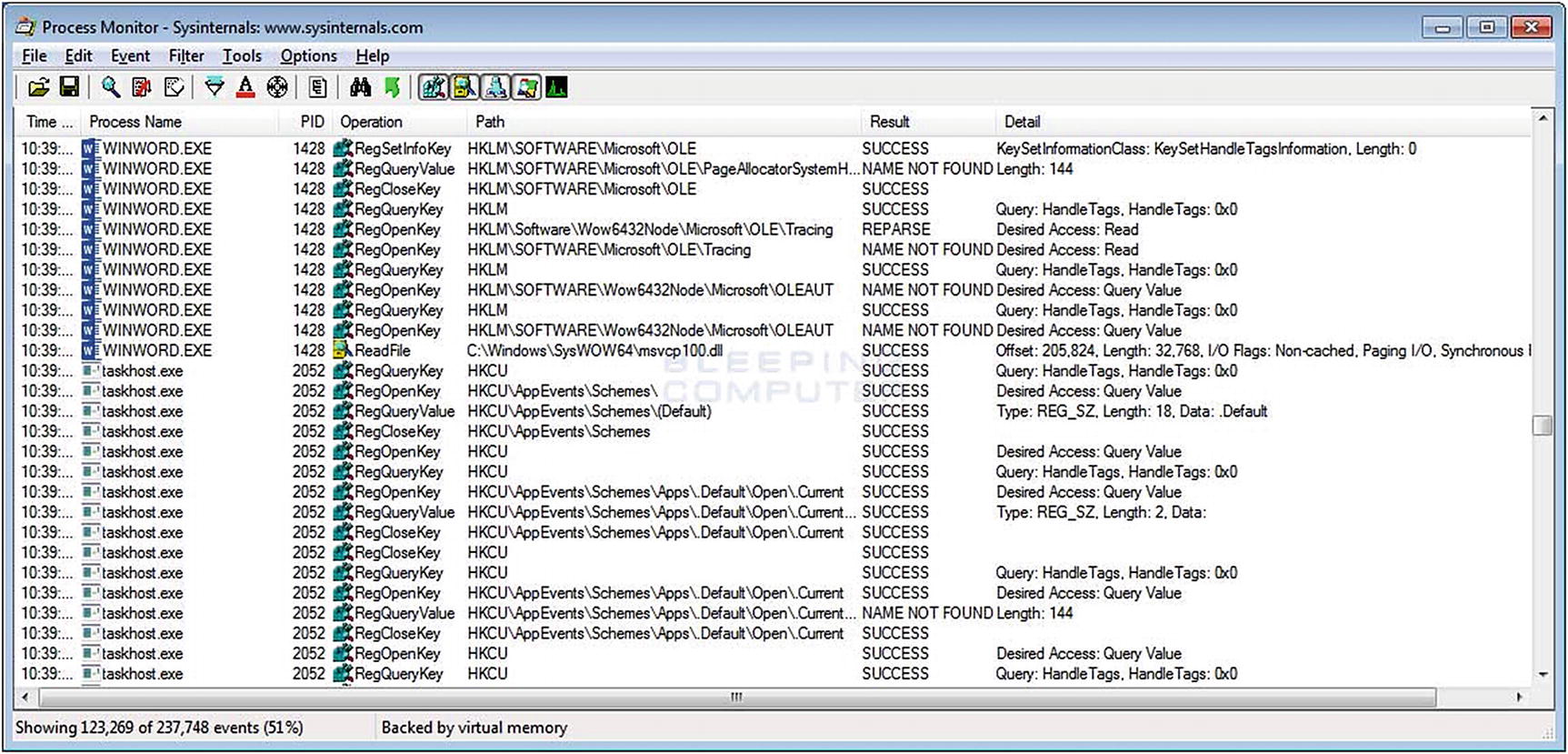
Image displaying the screen contents when running Process Monitor. Executables initiated with Process Monitor live in a sandbox are beneficial to understanding what the executable does in the environment.
If the malware is an executable, analysts observe the details for later use, searching for other instances of the malware in the environment. The processes in this example highlight numerous activities affecting the registry and one initiating a file read. The details lead analysts to further sources of investigation.
Commercial sandboxes are offered by several entities. Solutions often execute the malware in the sandbox and report the IOCs to the team. Teams do this manually or, when suspicious files traverse the network, they can be automatically detonated in the sandbox, with results sent to analysts.
Once the malware is examined and all indicators of compromise are documented, the incident response team can get down to finding all affected end points. If available, end point detection and response (EDR) SIEM and packet capture sources are used to inventory all affected devices.
Denial of Service
Identify the logical flow of the attack and the assets targeted.
Assess firewalls, routers, servers, and other affected device logs.
Pinpoint how the traffic for the DDoS attack differs from non-threatening ones and review network traffic looking for DDoS traffic.
Block traffic with perimeter devices.
Block outbound traffic responding to the DDoS.
Blackhole malicious IPs attributed to the attacker.
Temporarily disable applications and services affected by the attack.
Add servers and load balancers, as needed.
The response team can also contact the Internet service provider to confirm if it sees the attack. If so, it may aid in thwarting the adversary.
Lost Assets
If theft occurred, was a law enforcement report filed?
What types of data were stored on the asset?
What was the asset used for?
Can the asset be tracked, wiped remotely, or can it call home?
These questions determine what risk exists due to the lost asset and the steps necessary to contain. If the asset was stolen, the matter should be reported to the police. More important is what data was stored on the asset. Concern arises when electronic protected health information (ePHI), personally identifiable information (PII), or confidential data the entity does not want made public were stored on the asset. If the asset was encrypted and powered down when possession was lost, the risks of data exposure are reasonably low. Some entities can track certain assets and/or wipe the contents remotely. These protections also reduce the risks of data exposure. If the company is uncertain whether sensitive data was stored on the asset, or if it was used in sensitive functions, monitoring the situation internally and externally is the extent of what the incident response team can do.
Data Theft
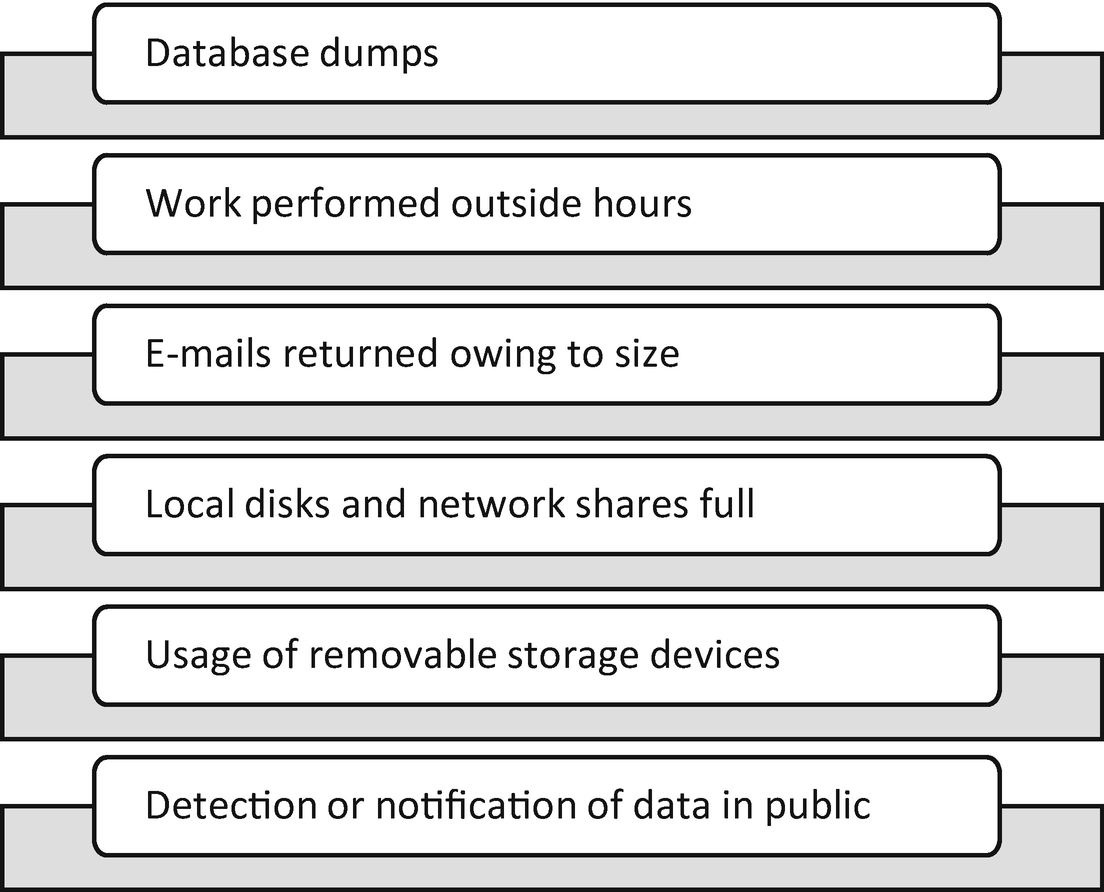
Sample indicators of data theft
The context of these warning signs is key to understanding the impact of the situation. Attacks on databases housing sensitive information, PII, ePHI, intellectual property, and trade secrets are serious. The same goes for alerts resulting from full disk space. If this situation occurs on infrastructure hosting sensitive data types, impact could be more significant. Further investigation is required because data can be moved from sensitive locations to less sensitive locations before exfiltration outside the entity boundaries.
User-based alerts, e-mails returned for size, working outside normal hours, and use of removable storage, which should be restricted to a select few, necessitate investigation of the user’s access rights. Immediately understanding the class of assets at risk is important. Users with access to the data types previously mentioned pose the biggest threat to the entity.
Unauthorized Access and Misuse of Assets
Access outside normal business hours
Numerous login failures
Users locked out of accounts (without having failed login attempts)
Unexplained use of dormant accounts
Unauthorized creation of accounts
Increased logins of a system
Unexplained system restart or failure
When one or more of the indicators occurs, the incident response team considers what systems or assets are affected and the relevant criticality. If the team suspects other end points and systems may be affected, investigating the environment is required. The team must know what servers, desktops, laptops, and mobile devices are affected. Are these directory accounts or accounts local to the device? These details address the impact of the scenario.
Retaining Forensic Investigators
Throughout the response, the team must gather digital evidence, to understand what happened. Some of this evidence is used to identify other compromised systems, and some is used to understand how the attack occurred. Images of systems in question are obtained by the incident response team. There are numerous commercial and open source tools to conduct these tasks, but, as discussed earlier in this chapter, the skills are not often found internally.
Retaining an incident response firm prior to an incident is ideal when you know the capabilities to respond do not exist on the team. These experts have experience containing incidents and collecting forensic evidence in response to cyberattacks. Depending on the agreement, the expected level of service might place the team on-site within 24 hours, or it could be that experts promise best efforts to place a team on-site as soon as possible. During large outbreaks, such as WannaCry, best efforts may mean days or weeks before response help arrives. Attention to these details is necessary, to make sure the required response times are built into the agreement.
Once a firm is engaged, on-site workshops and walkthroughs teach the entity’s local IR team what to expect when calling the firm for assistance, expectations for deploying forensic tools in the environment, and opportunities for improvement that the forensic firm identified during these discussions. IR teams must be prepared to rapidly deploy forensic tools used by these firms and plan to gather the necessary approvals to do so.
Executive Expectations
One obstacle the incident response team will face during the containment phase results from executives and members of the business wanting rapid answers and conclusions. This is understandable. Business repercussions may be looming, and leaders want to get in front of any negative situations. The incident response team must stay focused on the task at hand, sharing relevant information when possible, updating leaders on the steps taken and planned, but resisting incomplete or speculative information just to appease the audience. Doing the latter can cause more harm later.
Summary
Containment requires an organization to collect indicators of compromise. Indicators are attributions and artifacts left behind during events. Threat actors have specific attributes, based on tools, techniques, and procedures used. Specific types of malware or ransomware make changes to systems the incident response team uses to search the remaining information systems and assets. When matches to the indicators hit, the incident response team can quarantine these systems, taking them offline for further analysis.
The process of gathering an initial set of indicators and searching for signs of each in the remaining systems are documented in playbooks used by the response team. Playbooks are specific to event types: malware/ransomware, denial of service, lost assets, data theft and unauthorized use or misuse of company assets. This is not a complete list, but very common scenarios seen by incident response teams.
During the containment phase, forensic evidence used to determine the root cause and how the event unfolded is also gathered. Images of the systems are captured for complete analysis of all system characteristics as part of containment.
During this time, incident response teams deal with contact from members of the business and company leadership seeking answers. This is to be expected. The organization could be impacted, depending on the severity of the events in question, and these groups have a need to know. The key is to give facts and not speculate. Speculation causes more harm than good.