1. How to (actually) think outside the box
Machine learning and decision making
‘You can’t code people, Millie. That’s basically impossible.’
I was eleven, and arguing with my older sister. ‘Then how do we all think?’
It was something I knew instinctively then, but would only come to understand properly years later: the way we think as humans is not so different from how a computer program operates. Every one of you reading this is currently processing thoughts. Just like a computer algorithm, we ingest and respond to data – instructions, information and external stimuli. We sort that data, using it to make conscious and unconscious decisions. And we categorize it for later use, like directories within a computer, stored in order of priority. The human mind is an extraordinary processing machine, one whose awesome power is the distinguishing feature of our species.
We are all carrying a supercomputer around in our heads. But despite that, we get tripped up over everyday decisions. (Who hasn’t agonized over what outfit to wear, how to phrase an email or what to have for lunch that day?) We say we don’t know what to think, or that we are overwhelmed by the information and choices surrounding us.
That shouldn’t really be the case when we have a machine as powerful as the brain at our disposal. If we want to improve how we make decisions, we need to make better use of the organ dedicated to doing just that.
Machines may be a poor substitute for the human brain – lacking its creativity, adaptability and emotional lens – but they can teach us a lot about how to think and make decisions more effectively. By studying the science of machine learning, we can understand the different ways to process information, and fine-tune our approach to decision making.
There are many different things computers can teach us about how to make decisions, which I will explore in this chapter. But there is also a singular, counter-intuitive lesson. To be better decision makers, we don’t need to be more organized, structured or focused in how we approach and interpret information. You might expect machine learning to push us in that direction, but in fact the opposite is true. As I will explain, algorithms excel by their ability to be unstructured, to thrive amid complexity and randomness and to respond effectively to changes in circumstance. By contrast, ironically, it is we humans who tend to seek conformity and straightforward patterns in our thinking, hiding away from the complex realities which machines simply approach as another part of the overall data set.
We need some of that clear-sightedness, and a greater willingness to think in more complex ways about things that can never be simple or straightforward. It’s time to admit that your computer thinks outside the box more readily than you do. But there’s good news too: it can also teach us how to do the same.
Machine learning: the basics
Machine learning is a concept you may have heard of in connection with another two words that get talked about a lot – artificial intelligence (AI). This often gets presented as the next big sci-fi nightmare. But it is merely a drop in the ocean of the most powerful computer known to humanity, the one that sits inside your head. The brain’s capacity for conscious thought, intuition and imagination sets it apart from any computer program that has yet been engineered. An algorithm is incredibly powerful in its ability to crunch huge volumes of data and identify the trends and patterns it is programmed to find. But it is also painfully limited.
Machine learning is a branch of AI. As a concept it is simple: you feed large amounts of data into an algorithm, which can learn or detect patterns and then apply these to any new information it encounters. In theory, the more data you input, the better able your algorithm is to understand and interpret equivalent situations it is presented with in the future.
Machine learning is what allows a computer to tell the difference between a cat and a dog, study the nature of diseases or estimate how much energy a household (and indeed the entire National Grid) is going to require in a given period. Not to mention its achievements in outsmarting professional chess and Go players at their own game.
These algorithms are all around us, processing unreal amounts of data to determine everything from what film Netflix will recommend to you next, to when your bank decides you have probably been defrauded, and which emails are destined for your junk folder.
Although they pale in insignificance to the human brain, these more basic computer programs also have something to teach us about how to use our mental computers more effectively. To understand how, let’s look at the two most common techniques in machine learning: supervised and unsupervised.
Supervised learning
Supervised machine learning is where you have a specific outcome in mind, and you program the algorithm to achieve it. A bit like some of your maths textbooks, in which you could look up the answer at the back of the book, and the tricky part was working out how to get there. It’s supervised because, as the programmer, you know what the answers should be. Your challenge is how to get an algorithm to always reach the right answer from a wide variety of potential inputs.
How, for instance, can you ensure an algorithm in a self-driving car will always recognize the difference between red and green on a traffic light, or what a pedestrian looks like? How do you guarantee that the algorithm you use to help diagnose cancer screens can correctly identify a tumour?
This is classification, one of the main uses of supervised learning, in which you are essentially trying to get the algorithm to correctly label something, and to prove (and over time improve) its reliability for doing this in all sorts of real-world situations. Supervised machine learning produces algorithms that can function with great efficiency, and have all sorts of applications, but at heart they are nothing more than very fast sorting and labelling machines that get better the more you use them.
Unsupervised learning
By contrast, unsupervised learning doesn’t start out with any notion of what the outcome should be. There is no right answer that the algorithm is instructed to pursue. Instead, it is programmed to approach the data and identify its inherent patterns. For instance, if you had particular data on a set of voters or customers, and wanted to understand their motivations, you might use unsupervised machine learning to detect and demonstrate trends that help to explain behaviour. Do people of a certain age shop at a certain time in a certain place? What unites people in this area who voted for that political party?
In my own work, which explores the cellular structure of the immune system, I use unsupervised machine learning to identify patterns in the cell populations. I’m looking for patterns but don’t know what or where they are, hence the unsupervised approach.
This is clustering, in which you group together data based on common features and themes, without seeking to classify them as A, B or C in a preconceived way. It’s useful when you know what broad areas you want to explore, but don’t know how to get there, or even where to look within the mass of available data. It’s also for situations when you want to let the data speak for itself, rather than imposing pre-set conclusions.
Making decisions: boxes and trees
When it comes to making decisions, we have a similar choice to the one just outlined. We can set an arbitrary number of possible outcomes and choose between them, approaching problems from the top down and starting with the desired answer, much like a supervised algorithm: for example, a business judging a job candidate on whether they have certain qualifications and a minimum level of experience. Or we can start from the bottom, working our way upwards through the evidence, navigating through the detail and letting the conclusions emerge organically: the unsupervised approach. Using our recruitment example, this would see an employer consider everyone on their merits, looking at all the available evidence – someone’s personality, transferable skills, enthusiasm for the job, interest and commitment – rather than making a decision based on some narrow, pre-arranged criteria. This bottom-up approach is the first port of call for people on the autistic spectrum, since we thrive on bringing together precisely curated details to form conclusions – in fact we need to do that, going through all the information and options, before we can even get close to a conclusion.
I like to think of these approaches as akin to either building a box (supervised decision making) or growing a tree (unsupervised decision making).
Thinking in boxes
Boxes are the reassuring option. They corral the available evidence and alternatives into a neat shape where you can see all sides, and the choices are obvious. You can build boxes, stack them and stand on them. They are congruent, consistent and logical. This is a neat and tidy way to think: you know what your choices are.
By contrast, trees grow organically and in some cases out of control. They have many branches and hanging from those are clusters of leaves that themselves contain all sorts of hidden complexity. A tree can take us off in all sorts of directions, many of which may prove to be decisional dead ends or complete labyrinths.
So which is better? The box or the tree? The truth is that you need both, but the reality is that most people are stuck in boxes, and never even get onto the first branch of a decision tree.
That certainly used to be the case with me. I was a box thinker, through and through. Faced with so many things I didn’t and couldn’t understand, I clung to every last scrap of information I could get my hands on. In between the smell of burnt toast on weekdays at 10.48 a.m. and the sound of schoolgirls gossiping in cliques, I would engage within my recreational equivalent – computer gaming and reading science books.
Night after night, throughout the years of boarding school, I would revel in my solitude by reading and copying selective bits of texts from science and maths books. My trusty instruction manuals. I took great pleasure and relief from doing this over and over, with different science books, not knowing why but only to reach the crescendo of pinning down some gravitational understanding of the reality before me. My controllable logic. The things I read helped give me rules that I set in stone, from the ‘right’ way of eating to the ‘right’ way to talk to people and the ‘right’ way to move between classrooms. I got stuck in a rut of knowing what I liked and liking what I knew – regurgitating a series of ‘should’s to myself because they felt safe and reliable.
And when I wasn’t sitting with my books, I was observing: memorizing number plates on car journeys, or sitting around dinner tables contemplating the shape of people’s fingernails. As an outsider at school, I would regularly use what I now understand to be classification to understand new people entering my world. Where were they going to fit into this world of unspoken social rules and behaviours that I struggled to understand? What group would they gravitate towards? Which box could I put them in? As a young child I even insisted on sleeping in a cardboard box, day and night, enjoying the feeling of being cocooned in its safe enclosure (with my mum passing biscuits to me through a ‘cat flap’ cut in the side).
As a box thinker I wanted to know everything about the world and people around me, comforting myself that the more data I accumulated, the better decisions I would be able to make. But because I had no effective mechanism for processing this information, it simply piled up in more and more boxes of useless stuff: like the junk that hoarders can’t bear to throw out. I would become almost immobilized by this process, at times struggling to get out of bed because I was so focused on what exact angle I should hold my body at. The more boxes of irrelevant information piled up in my mind, the more directionless and exhausted I became, as every box in my mind started to look the same.
My mind would also interpret information and instructions in a wholly literal way. One time I was helping my mum in the kitchen, and she asked me to go out and buy some ingredients. ‘Can you get five apples, and if they have eggs get a dozen.’ You can imagine her exasperation when I returned with twelve apples (the shop had indeed stocked eggs). As a box thinker, I was incapable of escaping the wholly literal bounds of an instruction like that, something I still struggle with today: such as my belief, until recently, that one could actually enrol at the University of Life.
Classification is a powerful tool, and useful for making immediate decisions about things, such as which outfit to wear or what film to watch, but it places severe limitations on our ability to process and interpret information, and make more complex decisions by using evidence from the past to inform our future.
By trying to classify our lives, thinking in boxes, we close off too many avenues and limit the range of possible outcomes. We know only one route to work, how to cook just a few meals, the same handful of places to go. Box thinking limits our horizons to the things we already know, and the ‘data’ in life we have already collected. It doesn’t leave much space for looking at things differently, unshackling ourselves from preconceptions, or trying something new and unfamiliar. It’s the mental equivalent of doing exactly the same thing at the gym every session: over time your body adapts and you see less impressive results from your workout. To hit goals, you have to keep challenging yourself and get out of the boxes that close in on you the longer you stay in them.
Box thinking also encourages us to think of every decision we make as definitively right or wrong, and to label them accordingly, as an algorithm would tell the difference between a hamster and a rat. It leaves no room for nuance, grey areas or things we haven’t yet considered or found out: things we might actually enjoy, or be good at. As box thinkers, we tend to classify ourselves in terms of what we like, what we want in life and the things we are good at. The more we embrace this classification, the less willing we are to explore beyond its boundaries and test ourselves.
It is also fundamentally unscientific, letting the conclusions direct the available data, when the opposite should be true. Unless you truly believe you know the answer to every question in life before you have reviewed the evidence, then box thinking is going to limit your ability to make good decisions. It can feel good to have clearly delineated choices, but that is probably a false comfort.
That is why we need to think outside the boxes we mostly use for decision making and learn a thing or two from the unsupervised algorithm (or, if you like, go back to our childhood and climb some trees).
You might be surprised that I am recommending a messy and unstructured method over a seemingly neat and logical one. Wouldn’t a scientific mind be naturally drawn towards the latter? Well, no. In fact, the opposite. Because while a tree might be sprawling, by that nature it is a far truer representation of our lives than the sharp corners of a box. Although box thinking was comforting to my ASD need to process and hoard information there and then, over time I have come to realize that clustering is by far the more useful way of understanding the world around me and navigating my way through it.
We are all wading through inconsistency, unpredictability and randomness – the things that make life real. In this context, the choices we have to make aren’t often binary, and the evidence we have to consider doesn’t stack up in neat piles. The clear-cut edges of the box are a reassuring illusion, because nothing is that straightforward. Boxes are static and inflexible, where our lives are dynamic and constantly changing. By contrast trees keep on evolving, just like we do. And their many branches, compared to the box’s few edges, allow us to envisage many more different outcomes – reflecting the multiplicity of choice we all have.
Crucially, the tree is ideally equipped to support our decision making because it is scalable. As a fractal, which looks the same from a distance as it does up close, it can serve its purpose however large and complex the question. Like clouds, pine cones, or that Romanesco broccoli we all look at in the supermarket but never buy, it preserves the same structure regardless of scale and perspective. Unlike the box, which is limited by its form to an entirely fleeting relevance, the tree can branch out from place to place, memory to memory and decision to decision. It functions across different contexts and points in time. You can be zooming in on a single issue or trying to plot the course of your entire life. The tree will still retain its essential shape, and remain your trusted ally in decision making.
Science teaches us to embrace complex realities, not to try and smooth over them in the hope that they go away. We can only understand – and then decide – if we explore, question and reconcile things that don’t fit neatly together. If we want to be more scientific about how we make decisions, that means embracing disorder before we can detect patterns and hope to draw conclusions. Which means we need to think more like trees. Let me show you what that looks like.
Thinking like a tree
Tree thinking has been my salvation. It is what allows me to function in everyday life, doing what might seem normal tasks to most of you – like commuting to work – but which could easily be insurmountable barriers for me. I can be sent into meltdown by anything from an unexpected crowd, noise or smell, to something that doesn’t turn out as I had planned.
But while my ASD means I crave certainty, it doesn’t mean that simplistic methods of making decisions are helpful for me. I want to know what is going to happen, but that doesn’t mean I am prepared to accept the most straightforward route from A to B (and from experience and perpetual anxiety, I know the route is never that easy). It’s the opposite, because I struggle to stop my mind racing through all sorts of possibilities based on everything I see and hear around me. In my world, appointments get missed, messages are left unanswered and my sense of time disappears because I’ve spotted something like a blackbird sitting on a roof, and wondered how it got there, and where it’s going next. Or I’ve become distracted because I noticed the pavement was smelling like raisins after a rain shower, only to then experience a close shave with a lamp post.
What you notice is only the half of it. My mind is a kaleidoscope of future possibilities about what I observe and experience. This is why I have a whole bunch of coffee-shop loyalty cards, all fully stamped, but never yet used. I can’t decide which is the greater risk: that there will be a time in the future when I need them more than I do now; or that the chain in question will cease to exist before I get the chance to use them. The net effect is that nothing at all happens. (But note: I don’t consider any of these far-out projections as wrong. They are things that haven’t yet happened, but still might.)
Add to that my ADHD, which means my perception of time is squished and stretched, and can sometimes disappear completely. Because information is flying through your mind at high speed, leaving your legs restless and shaking, it can feel like you are living a week’s worth of thoughts and emotions all within an hour: oscillating wildly from euphoria to despondency, thinking things are going to be brilliant one moment, and a catastrophe the next. Not ideal for making to-do lists.
For the same reason, I rely on a chaotic working environment to be productive. I will spread paper everywhere, make notes on anything that comes to hand, and simply let the material pile up around me, embedded within the white noises of the room. This ‘chaos’ is something I find stimulating, a weed whacker to cut through the non-stop noise within my mind, enabling me to focus. In contrast to what we are taught at school, I find silence doesn’t help me focus, but instead creates a pressure that simply stops me from doing anything.
My brain is craving certainty and feeding on chaos all at the same time. To keep myself functioning, I have had to develop a technique that satisfies both my need to think through everything, and my desire for an ordered life in which I know exactly where and when I am going to be. Which is where the trees come in.
A decision tree allows me to reach a certain end – which might be one of several potential outcomes, but at least I know what they are – through sometimes chaotic means. It provides structure to what I know my mind will do anyway, which is race through endless possibilities. But it does this in a way that leads me to something useful: a conclusion about what decisions I can make that give me something representing certainty. It also allows me to avoid putting all of my eggs in one basket, a process which at times gives me an outwardly cool edge of slight indifference.
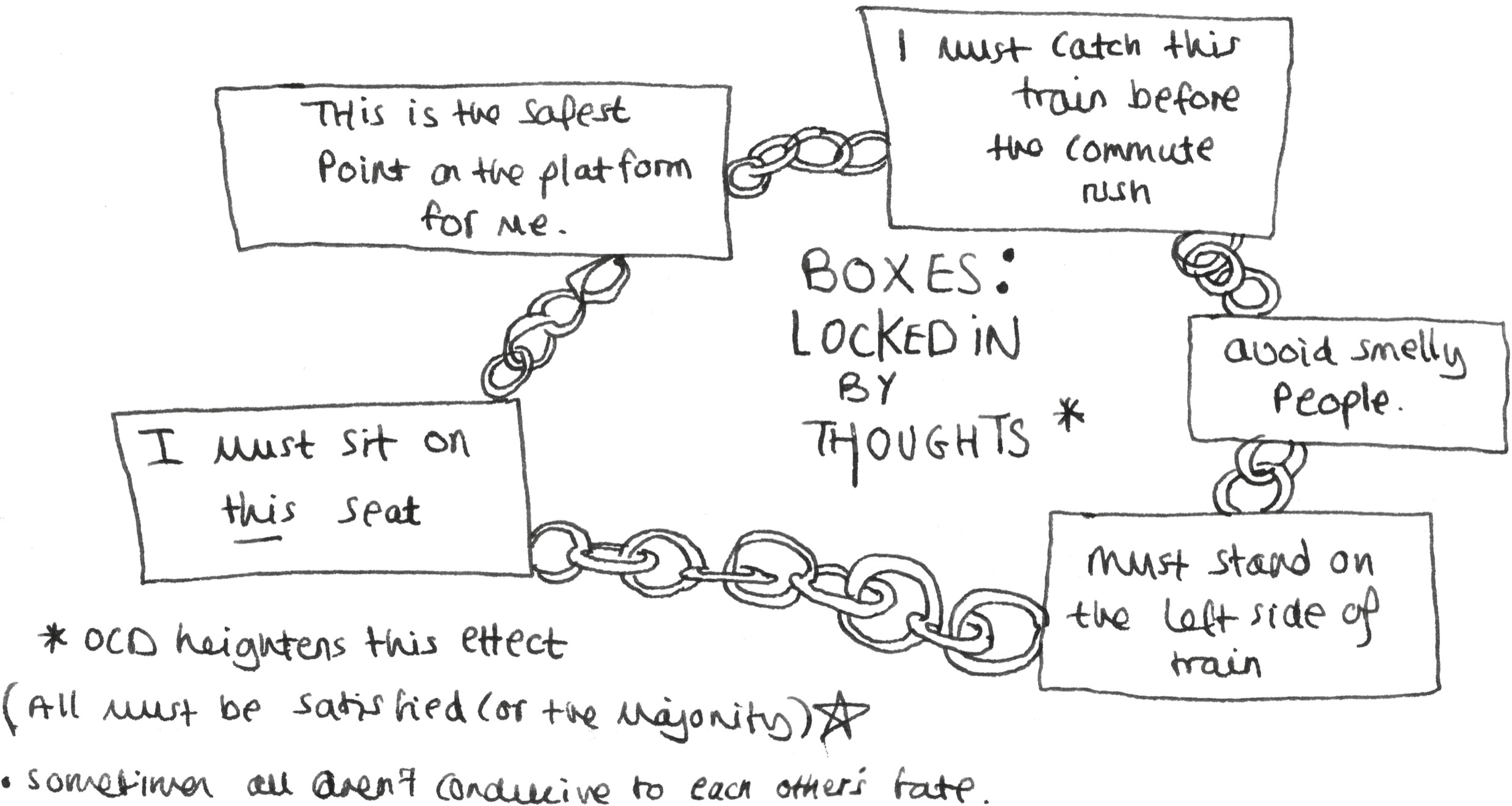
Think about your morning commute. Mine is across London by train. That, for me, is an anxiety attack waiting to happen. The crowded carriage, the noise, the smells, the pressured spaces. A decision tree helps to minimize the potential for all those things to trigger a meltdown. I know what train I am going to catch, and then I consider what I’ll do if it’s late or cancelled, or I get delayed. I know where I want to sit, and what I will do if those seats are occupied, or if it is too loud. I think through all the things I need to ensure a meltdown-free journey – the right time, before the commuter crush; the right seat, away from the smelliest parts of the train; the right place on the platform to stand – and then I shimmy up the branches that stem off each, for when any of those things might become impossible. I am a puppet on strings of probability, which guide me forward like a harness, allowing me to manoeuvre between branches. Rather than having a fixed routine, something brittle that will break under stress, I have multiple decision trees for my commute. I have lived in my mind all sorts of scenarios, most of which will never come to pass, in the hope that I won’t encounter one that hasn’t occurred to me, and which is likely to freak me out.
Before I get to any decisions, the ones that reassure me it’s safe to travel, I have to go through this messy mental planning. The apparent chaos of the decision tree is necessary to help get me towards the sense of certainty I need to function.

To you that probably sounds like a lot of hassle (you’d be right!) and, to be clear, I’m not suggesting that you start war-gaming your morning routine as I would. I need to do this, otherwise I would get too overwhelmed and just not leave the house. But I do think this method has a place when it comes to the more complex decisions – the ones that neurotypical instinct and methods tend to fall down on.
While the challenge for my ASD/ADHD brain is not getting paralysed by overthinking, the opposite of this is also a problem. If you don’t delve deeply enough into the data set that surrounds every major decision, allowing yourself to consider the different possibilities and outcomes, and the branches of the tree that different decisions will simultaneously close off and open up, then you are effectively making your choice while blindfolded. We can’t predict the future, of course, but for most situations we can cluster enough data points and plot enough possibilities to give ourselves a decent map. What I do to reassure myself and tamp down anxiety on an everyday basis could be useful for you in working through the difficult decisions in your life. With a decision tree, you can reach from the things that you know, to grasp onto the decisions you are seeking – not in a prescriptive way, based on fixed outcomes, but by letting the evidence guide your conclusion, and allowing yourself to consider multiple outcomes and their implications.
Trees are also necessary to make sense of the confusing, open-ended questions that people are so fond of asking. If someone asks me, ‘What do you feel like doing today?’ my instinctive response will be, ‘I don’t know, maybe.’ I need some specific options – branches of a tree – to offer a route from the chaos of total freedom towards the restriction of a decision, one which still leaves open alternative routes to divert down. A tree turns the multitude of underlying events and variables inherent in any decision into something like a route map. It might make every conversation into a jungle trek, but at least it allows me to find a way through.
By contrast, when we make decisions based on box thinking, we are usually doing so through a combination of emotion or gut instinct. Neither can be relied upon, and you can take it from me: there’s nothing like ADHD to help you understand what making immediate decisions after emotion has slapped you in the face is like. Good times.
Good decisions don’t generally emerge from an assumption of certainty, but out of the chaos otherwise known as evidence. You need to start from the bottom, building upwards towards the conclusion rather than starting with it. And to do that, you need a tree to climb up.
So how do I decide?
A tree is all very well in theory, you might be thinking, but with so many branches how do I actually make a decision? Isn’t there a risk of getting lost in all the wonderful complexity we have visualized around us?
Yes, there is (welcome to my world!) but don’t worry, machine learning has your back again. Algorithms also have a lot to teach us about how to sift through large amounts of data and draw conclusions – exactly what you need to do to make the tree method work for you in everyday circumstances.
Any machine-learning process essentially begins with what we call feature selection: filtering the useful data away from the noise. We need to narrow down our evidence base and focus on the information that can lead us somewhere. This is about setting the parameters of the experiments you will then undertake.
How is this done? There are different methods, but one of the most common in unsupervised machine learning is known as ‘k-means clustering’. This is where you create indicative clusters within a data set based on how closely related they are. Essentially, you group together things that look similar, or have certain features in common, to create a certain number of clusters, and then use those to test and evolve your assumptions. Because you don’t know what the outcome is meant to be, you are open-minded about the conclusions, and initially focus only on what can be inferred from the data: letting it tell its own story.
Is that really so different from the decisions we have to make all the time? Whether they are insignificant or life-changing choices, we always have data points that we can examine and try and cluster together. If it’s choosing an outfit, we know what makes us feel good, what is appropriate for the occasion, and what others might think. If it’s deciding whether to take a job in a different country, the data points might range from the salary on offer, to lifestyle, proximity to friends and family, and career ambitions.
If, when facing a big decision, you’ve ever said to yourself, ‘I don’t know where to start’, then feature selection is not a bad place – even if the choice is daunting, it enables you to consider many alternative possibilities, leaving you in a stronger and more empowered place.
First you separate the things that really matter from those that are just distractions – the main determinant being how it will make you feel, now or in the future. Then you group together those that share common features: what helps get me from A to B, or fulfils a particular need or ambition. And with those clusters, you can start to build the branches of your decision tree and see how your data points are related. This process helps to reveal the real choices you face, as opposed to those which are in the forefront of your mind to begin with (perhaps driven by FOMO – fear of missing out – or the likely judgement of strangers on social media). Those factors exist on their own tree separate from you, and simply cannot be compared like with like.
It’s never really a choice about the red top or the black, or about this job or that one. Those are just symbols and expressions of the things you actually want. Only by sorting the data and building your decision tree can you see how to navigate the choices in front of you, and reach decisions based on meaningful outcomes; for example, will it make me happy and fulfilled?
It’s always more complex than the binary ‘yes or no’ decisions that we like to pretend exist. We need to go deeper than the immediate choice point and mine the data of our emotions, ambitions, hopes and fears about the decision ahead, understanding how they are all linked, and what leads us to where. By doing this we can be more realistic about what a particular choice will and won’t achieve for us; deciding important things based on the fundamentals of what matters most in our lives, and less aligned with the boxes strewn around us. They simply represent our emotional baggage and immediate instincts, often populated in the piled boxes of social ‘should’s (‘I should explore the world while I’m young,’ ‘I should settle down and not take that risky job abroad,’ and so on) on how to be and behave. Variances in mental health are often perceived as a losing battle in this regard, since they naturally push and challenge such boxes.
We can also learn from the machine-learning process about how evidence should be used. Feature selection and k-means clustering get you to the starting line, but that’s all they do. Reaching conclusions requires a whole extra phasing of testing, iterating and refining. Evidence in science is something to be tested, not waved around like the tablets of stone. You make assumptions so you can question and improve them, not treat them as an immutable guide for life, however concrete they may seem.
We should treat the evidence in our own lives on the same basis. By all means pursue one branch of the tree that seems most favourable, but don’t saw off all the others before you do (the essence of declaring one option ‘right’ and the other ‘wrong’). Experiment with what you think you want, and be willing to backtrack and adjust your assumptions if it doesn’t work out as expected. The beauty of a tree-like structure is the ability to move easily between branches, whereas traversing between seemingly unrelated boxes leaves us anxious and without a clear path forward, resulting in an inevitable retreat. Just as any data set contains a mixture of inherent patterns, hidden truths and total red herrings, our lives comprise a whole selection of pathways forward, forks in the road and cul-de-sacs. Sorting the evidence can give you a good idea of which to pursue, but don’t bet against having to double-back and try again. Life isn’t linear but branched, and we need our thought patterns to match that reality.
That may sound haphazard, but it’s actually a far more scientific and sustainable method than making a decision and sticking to it regardless of the evidence. It allows us to set the course of our lives in the same way as machines are engineered: with more precision, and greater willingness to test, learn and adjust. It’s also something that we improve at over time: as we get older, we gather ever more data, allowing us to grow more mature, complex trees in our heads that better reflect the reality of a situation – like an architect’s drawing of a house compared to a child’s.
The good news is, you are probably doing a bit of this already. Social media has made scientists of us all when it comes to the art of posting the perfect photo. What angle, what combination of people and objects, what time of day and what hashtags? We observe, test, try again and over time perfect a method for documenting our perfect lives for the world to see. And if you can do it on Instagram, you can do it in the rest of your life too.
Learning to embrace error
By taking this approach to decision making, building chaos and complexity into our mental model through a tree-thinking or unsupervised approach, we start to develop a more realistic method for predicting events and making decisions based on the evidence available.
This method isn’t just useful because it’s scalable, flexible and more clearly represents the complex reality of our lives. It also equips us better to respond when things go wrong – or in situations where we think they might have done.
This is the point, to put it bluntly, at which the scientific approach copes a lot better than people. When you are a biochemist or a statistician, error doesn’t faze you, because you can’t afford to let it. It can be exasperating and time-consuming, but it’s also essential and fascinating. Science thrives on error, because it allows us to fine-tune, to evolve and to fix mistakes in our underlying assumptions. Only through the anomalies and the outliers can we reach a full understanding of the cell, data set or maths problem we are studying.
It’s why statistics uses standard error as a basic principle, building in an assumption that there will always be things that don’t accord with expectations and predictions. In machine learning, we have ‘noisy data’, information that sits in the data set but doesn’t actually tell us anything useful or help inform the creation of meaningful clusters. Only by acknowledging the natural noise in the system can we facilitate performance in big data groups. You can’t optimize unless you study and understand the noise, errors and deviations from the mean. After all, noise in one context is often a signal in the next – much as one person’s trash is another’s treasure, since signals are not objective, but based on what an individual is looking for. If scientists didn’t embrace the need for error, and find fascination in things that contradict and frustrate their assumptions, ground-breaking research would simply never happen.
People, on the other hand, can be less sanguine when things don’t go according to plan. You won’t find many commuters cheerfully quoting standard error when their train gets delayed or cancelled. This is because we have been taught to consider mistakes through an emotional, not a scientific, lens. We are generally quick to declare errors as symptomatic of category failure, and conclude that the system doesn’t work, or the decision that led to this point was entirely wrong. The truth is usually more mundane: the trains do run on time, most of the time; and your decision might have worked differently in the vast majority of foreseeable scenarios.
Experiencing a setback of some sort is not sufficient evidence to conclude that everything has failed, or that a system or decision should be abandoned wholesale. Humanity would have achieved only a fraction of what it has if that approach to error had been used by scientists and technologists throughout history. Even in everyday life, it is when things go wrong that people come alive – albeit that might be an angry reaction to a train being late, or when a stranger has stolen your trusted waiting spot.
The knee-jerk response to error is one of the main downfalls of box thinking. By acting much like supervised algorithms, we assign a binary quality to every data point and situation. Yes or no. Right or wrong. Rat or hamster. This limits our ability to see problems in their proper context, and makes every error seem like a critical one. The train is cancelled therefore my day is ruined. It creates the dangerous illusion that there is always a categorically right or wrong decision, and that the difficult thing is making a cliff-edge decision between them (pure box thinking). In my case, it also tends to lead to one setback – the missed train – derailing my entire day, sending me cascading into meltdown because my plan has gone awry.
Because reality is more nuanced than that, so must our techniques be for thinking about problems and reaching decisions. With a box, you have nowhere to go when something goes wrong. Your only choice is to label it as a failure, and start again. With a tree, you are surrounded by alternative branches: paths forward that you have gamed out in your head. It’s far easier and more efficient to switch course because you didn’t put all your chips on one outcome working out as you had hoped. You have already planned for just this eventuality, and left yourself with plenty of worthwhile backups.
Counter-intuitively, machine learning can help us to be less mechanical, and more human, in how we assess the decisions in front of us. It teaches us that ‘mistakes’ are normal and are inherent in real data. There are few, if any, truly binary choices, and not everything fits into a pattern or can be tied up into a neat and irrefutable conclusion. The exception makes the rule. I’ve benefited from the machine-learning perspective not because it filters out the randomness and uncertainty that are an inherent part of humanity, but because it embraces them more easily than most people do, and provides a method for assimilating them. It allows me to plan for situations I know I will find intimidating, and be better prepared for when things go wrong.
Tree-like thinking is important because it reflects the complexity that surrounds us, but also because it helps us to be resilient. Like a mighty oak that has stood for hundreds of years, a decision tree can stand up to all weathers, long after a box has been jumped on, broken and cast aside for ever.