
The SQL we have seen so far is powerful enough for many everyday tasks, but other questions require more powerful tools. This section introduces a handful and shows when and how they are useful.
Our next task is to calculate the total projected world population for the year 2300. We will do this by adding up the values in PopByRegion’s Population column using the SQL aggregate function SUM:
| | >>> cur.execute('SELECT SUM (Population) FROM PopByRegion') |
| | <sqlite3.Cursor object at 0x102e3e490> |
| | >>> cur.fetchone() |
| | (8965762,) |
SQL provides several other aggregate functions (see Table 33, Aggregate Functions). All of these are associative; that is, the result doesn’t depend on the order of operations. This ensures that the result doesn’t depend on the order in which records are pulled out of tables.
|
Aggregate Function |
Description |
|---|---|
|
AVG |
Average of the values |
|
MIN |
Minimum value |
|
MAX |
Maximum value |
|
COUNT |
Number of nonnull values |
|
SUM |
Sum of the values |
Addition and multiplication are associative, since 1 + (2 + 3) produces the same results as (1 + 2) + 3, and 4 * (5 * 6) produces the same result as (4 * 5) * 6. By contrast, subtraction isn’t associative: 1 - (2 - 3) is not the same thing as (1 - 2) - 3. Notice that there isn’t a subtraction aggregate function.
What if we only had the table PopByCountry and wanted to find the projected population for each region? We could get the table’s contents into a Python program using SELECT * and then loop over them to add them up by region, but again, it is simpler and more efficient to have the database do the work for us. In this case, we use SQL’s GROUP BY to collect results into subsets:
| | >>> cur.execute('''SELECT Region, SUM (Population) FROM PopByCountry |
| | GROUP BY Region''') |
| | <sqlite3.Cursor object at 0x102e3e490> |
| | >>> cur.fetchall() |
| | [('Eastern Asia', 1364389), ('North America', 661200)] |
Since we have asked the database to construct groups by Region and there are two distinct values in this column in the table, the database divides the records into two subsets. It then applies the SUM function to each group separately to give us the projected populations of Eastern Asia and North America. We can verify by computing the sums separately:
| | >>> cur.execute('''SELECT SUM (Population) FROM PopByCountry |
| | WHERE Region = "North America"''') |
| | <sqlite3.Cursor object at 0x102a3bb20> |
| | >>> cur.fetchall() |
| | [(661200,)] |
| | >>> cur.execute('''SELECT SUM (Population) FROM PopByCountry |
| | WHERE Region = "Eastern Asia"''') |
| | <sqlite3.Cursor object at 0x102a3bb20> |
| | >>> cur.fetchall() |
| | [(1364389,)] |
Let’s consider the problem of comparing a table’s values to themselves. Suppose that we want to find pairs of countries whose populations are close to each other—say, within 1,000 of each other. Our first attempt might look like this:
| | >>> cur.execute('''SELECT Country FROM PopByCountry |
| | WHERE (ABS(Population - Population) < 1000)''') |
| | <sqlite3.Cursor object at 0x102e3e490> |
| | >>> cur.fetchall() |
| | [('China',), ('DPR Korea',), ('Hong Kong (China)',), ('Mongolia',), |
| | ('Republic of Korea',), ('Taiwan',), ('Bahamas',), ('Canada',), |
| | ('Greenland',), ('Mexico',), ('United States',)] |
The output is definitely not what we want, for two reasons. First, the phrase SELECT Country is going to return only one country per record, but we want pairs of countries. Second, the expression ABS(Population - Population) is always going to return zero because we are subtracting each country’s population from itself. Since every difference will be less than 1,000, the names of all the countries in the table will be returned by the query.
What we actually want to do is compare the population in one row with the populations in each of the other rows. To do this, we need to join PopByCountry with itself using an INNER JOIN:
This will result in the rows for each pair of countries being combined into a single row with six columns: two regions, two countries, and two populations. To tell them apart, we have to give the two instances of the PopByCountry table temporary names (in this case, A and B):
| | >>> cur.execute(''' |
| | SELECT A.Country, B.Country |
| | FROM PopByCountry A INNER JOIN PopByCountry B |
| | WHERE (ABS(A.Population - B.Population) <= 1000) |
| | AND (A.Country != B.Country)''') |
| | <sqlite3.Cursor object at 0x102e3e490> |
| | >>> cur.fetchall() |
| | [('Republic of Korea', 'Canada'), ('Bahamas', 'Greenland'), ('Canada', |
| | 'Republic of Korea'), ('Greenland', 'Bahamas')] |
Notice that we used ABS to get the absolute value of the population difference. Let’s consider what would happen without ABS:
| | (A.Population - B.Population) <= 1000 |
Omitting ABS would result in pairs like (’Greenland’, ’China’) being included, because every negative difference is less than 1,000. If we want each pair of countries to appear only once (in any order), we could rewrite the second half of the condition as follows:
| | A.Country < B.Country |
By changing the condition above, each pair of countries appears only once.
Up to now, our queries have involved only one SELECT command. Since the result of every query looks exactly like a table with a fixed number of columns and some number of rows, we can run a second query on the result—that is, run a SELECT on the result of another SELECT, rather than directly on the database’s tables. Such queries are called nested queries and are analogous to having one function called on the value returned by another function call.
To see why we would want to do this, let’s write a query on the PopByCountry table to get the regions that do not have a country with a population of 8,764,000. Our first attempt looks like this (remember that the units are in thousands of people):
| | >>> cur.execute('''SELECT DISTINCT Region |
| | FROM PopByCountry |
| | WHERE (PopByCountry.Population != 8764)''') |
| | <sqlite3.Cursor object at 0x102e3e490> |
| | >>> cur.fetchall() |
| | [('Eastern Asia',), ('North America',)] |
This result is wrong—Hong Kong has a projected population of 8,764,000, so eastern Asia shouldn’t have been returned. Because other countries in eastern Asia have populations that are not 8,764,000, though, eastern Asia was included in the final results.
Let’s rethink our strategy. What we have to do is find out which regions include countries with a population of 8,764,000 and then exclude those regions from our final result—basically, find the regions that fail our condition and subtract them from the set of all countries as shown in the image.
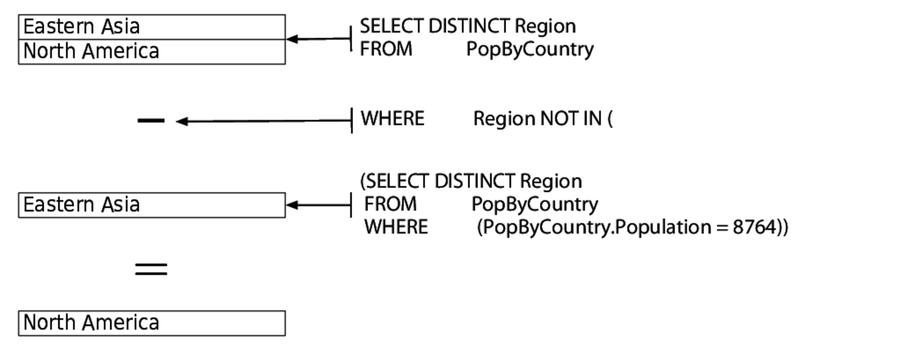
The first step is to get those regions that have countries with a population of 8,764,000, as shown in the following code:
| | >>> cur.execute(''' |
| | SELECT DISTINCT Region |
| | FROM PopByCountry |
| | WHERE (PopByCountry.Population = 8764) |
| | ''') |
| | <sqlite3.Cursor object at 0x102e3e490> |
| | >>> cur.fetchall() |
| | [('Eastern Asia',) |
Now we want to get the names of regions that were not in the results of our first query. To do this, we will use a WHERE condition and NOT IN:
| | >>> cur.execute(''' |
| | SELECT DISTINCT Region |
| | FROM PopByCountry |
| | WHERE Region NOT IN |
| | (SELECT DISTINCT Region |
| | FROM PopByCountry |
| | WHERE (PopByCountry.Population = 8764)) |
| | ''') |
| | <sqlite3.Cursor object at 0x102e3e490> |
| | >>> cur.fetchall() |
| | [('North America',)] |
This time we got what we were looking for. Nested queries are often used for situations like this one, where negation is involved.
A transaction is a sequence of database operations that are interdependent. No operation in a transaction can be committed unless every single one can be successfully committed in sequence. For example, if an employer is paying an employee, there are two interdependent operations: withdrawing funds from the employer’s account and depositing funds in the employee’s account. By grouping the operations into a single transaction, it is guaranteed that either both operations occur or neither operation occurs. When executing the operations in a transaction, if one operation fails, the transaction must be rolled back. That causes all the operations in the transaction to be undone. Using transactions ensures the database doesn’t end up in an unintended state (such as having funds withdrawn from the employer’s account but not deposited in the employee’s account).
Databases create transactions automatically. As soon as you try to start an operation (such as by calling the execute method), it becomes part of a transaction. When you commit the transaction successfully, the changes become permanent. At that point, a new transaction begins.
Imagine a library that may have multiple copies of the same book. It uses a computerized system to track its books by their ISBN numbers. Whenever a patron signs out a book, a query is executed on the Books table to find out how many copies of that book are currently signed out, and then the table is updated to indicate that one more copy has been signed out:
| | cur.execute('SELECT SignedOut FROM Books WHERE ISBN = ?', isbn) |
| | signedOut = cur.fetchone()[0] |
| | cur.execute('''UPDATE Books SET SignedOut = ? |
| | WHERE ISBN = ?''', signedOut + 1, isbn) |
| | cur.commit() |
When a patron returns a book, the reverse happens:
| | cur.execute('SELECT SignedOut FROM Books WHERE ISBN = ?', isbn) |
| | signedOut = cur.fetchone()[0] |
| | cur.execute('''UPDATE Books SET SignedOut = ? |
| | WHERE ISBN = ?''', signedOut - 1, isbn) |
| | cur.commit() |
What if the library had two computers that handled book signouts and returns? Both computers connect to the same database. What happens if one patron tried to return a copy of Gray’s Anatomy while another was signing out a different copy of the same book at the exact same time?
One possibility is that Computers A and B would each execute queries to determine how many copies of the book have been signed out, then Computer A would add one to the number of copies signed out and update the table without Computer B knowing. Computer B would decrease the number of copies (based on the query result) and update the table.
Here’s the code for that scenario:
| | Computer A: cur.execute('SELECT SignedOut FROM Books WHERE ISBN = ?', isbn) |
| | Computer A: signedOut = cur.fetchone()[0] |
| | Computer B: cur.execute('SELECT SignedOut FROM Books WHERE ISBN = ?', isbn) |
| | Computer B: signedOut = cur.fetchone()[0] |
| | Computer A: cur.execute('''UPDATE Books SET SignedOut = ? |
| | WHERE ISBN = ?''', signedOut + 1, isbn) |
| | Computer A: cur.commit() |
| | Computer B: cur.execute('''UPDATE Books SET SignedOut = ? |
| | WHERE ISBN = ?''', signedOut - 1, isbn) |
| | Computer B: cur.commit() |
Notice that Computer B counts the number of signed-out copies before Computer A updates the database. After Computer A commits its changes, the value that Computer B fetched is no longer accurate. If Computer B were allowed to commit its changes, the library database would account for more books than the library actually has!
Fortunately, databases can detect such a situation and would prevent Computer B from committing its transaction.