The Problem of Control in Field Settings
Control Over Research Populations
Characteristics of a good setting
Implementing the Independent Variable
Problems in Field Experimentation
Control over extraneous variables
Vulnerability to outside interference
Natural Experiments and Quasi-Experiments
The nonequivalent control group design
The problem of preexisting differences
The problem of biased selection
How severe are these problems?
The interrupted time series design
Categories of Naturalistic Observation
Problems in Naturalistic Observation
Suggestions for Further Reading
Questions for Review and Discussion
As we noted in Chapter 2, the laboratory experiment has been the model for much research in the behavioral sciences. However, the laboratory experiment has a number of shortcomings, especially its artificiality. Compared to people’s normal life experiences—to which we frequently want the results of our research to apply—laboratory research takes place in an artificial setting, uses artificial operational definitions of variables, has participants perform artificial tasks, and uses as research participants people who may not constitute a reasonable sample of the population. In addition, as discussed in Chapter 7, laboratory research can be reactive because research participants know they are being studied. Not surprisingly, then, many researchers, especially those with applied interests, have expressed concerns over the potential lack of naturalism of laboratory research (see Greenberg & Folger, 1988). These critics of laboratory research hold that the validity of the conclusions one can draw from a study is closely related to its ecological validity, the degree to which the research situation mimics a natural situation (see Chapter 8).
This chapter examines some issues related to research in natural settings, also called field research. We first briefly discuss the problem of control in field research. We then look at four field research methods: field experiments, natural experiments, quasi-experiments, and naturalistic observation.
As we discussed in Chapter 2, the decision to use a laboratory or field setting for research involves making a tradeoff between control and naturalism. This section briefly reviews the ways in which the use of field settings limits the degree of control that the researcher has over the research. These factors also limit the degree to which causal conclusions can be drawn from field research. However, there have been advances in both the methodologies used in the design of field experiments and in the statistical techniques used to analyze data from this research. These advances have resulted in increased confidence that causal hypotheses can be tested in well-designed field experiments (Shadish & Cook, 2009; West, 2009).
An important goal of field research is to assess research participants’ natural reactions to situations; to do so, field researchers often seek to keep participants from becoming aware that they are being studied. That is, the researcher does not want participants to alter their behavior from what they would normally do in the situation (Reis & Gosling, 2010). One consequence of this increased naturalism is that researchers may have limited control over their independent variable. Although researchers can manipulate the independent variable in some forms of field research, the “manipulation” is often natural and therefore uncontrolled in terms of intensity, duration, and when and where it occurs. Researchers may also have only a limited choice of operational definitions for the dependent variable. The dependent variable in field research is usually behavioral and so measured by means of observation, resulting in the limitations discussed in Chapter 6. For example, you can learn what people do in a situation, but not their reasons for doing it. In addition, as discussed later in this chapter, some forms of field research, such as participant observation, can make the accurate recording of observations especially difficult. Field research also limits control over extraneous variables. The complexity of field research situations means that any number of uncontrolled factors could serve as alternative explanations for any effects that one wants to attribute to the independent variable. However, as Bourchard (1976) notes, replication across heterogeneous settings can provide evidence against setting factors as causes of the dependent variable: The more often an effect is replicated across different settings, the less likely it is that some aspect of the setting, rather than the independent variable, was the cause of the dependent variable.
In laboratory research, the researcher can choose the population from which participants are drawn. Consequently, laboratory researchers can test for interactions between the independent variable and characteristics of the participants, such as personality traits. However, as we noted in Chapter 8, laboratory researchers are often criticized for their reliance on settings that are low in mundane realism and for their reliance on undergraduates as research participants. Field researchers seek to address these criticisms by studying people in real world settings. However, as Reis and Gosling (2010) point out, research conducted in natural settings may also be based on unrepresentative samples. For example, individuals who choose to attend professional baseball games, shop on Rodeo Drive in Beverly Hills, or go to casinos are likely different from individuals who make different choices about where to spend their free time.
In field settings, it is often impossible to randomly assign participants to conditions of the independent variable. For example, field research testing the effectiveness of an educational intervention might use the students in one school as the experimental group and those in another school as the control group. Although the schools can be randomly assigned to the experimental or control condition, children are not randomly assigned to schools. As a result, participant characteristics may not be balanced across conditions, leaving them as possible alternative explanations for any effects found in the research. In some field experiments, random assignment to condition is possible, but there are still opportunities for bias that are not present in laboratory research. For example, researchers in a public setting may have a plan for assigning participants to condition but, in practice “are sometimes tempted to skip a potential participant who looks uncooperative or unfriendly, or to assign an unattractive person to a condition that would require less interaction” (Reis & Gosling, 2010, p. 89). Doing so compromises the principles of random assignment to condition and experimenters should carefully consider how to avoid such outcomes.
Field experiments attempt to achieve a balance between control and naturalism in research by studying people’s natural behavioral responses to manipulated independent variables in natural settings. The field experimenter tries to establish conditions that are as close as possible to those of a laboratory-based true experiment by manipulating the independent variable and exposing participants to conditions of the independent variable in a reasonably random fashion. The goal is to allow causal conclusions to be drawn from research conducted in natural settings. For example, Piliavin, Rodin, and Piliavin (1969) manipulated whether a person who collapsed on a New York subway train appeared to be drunk or ill; they then assessed the effect of this manipulation on bystanders’ responses. Seligman, Finegan, Hazlewood, and Wilkinson (1985) manipulated the reason given for a pizza deliveryman’s being early or late—whether it was a factor associated with the deliveryman or something beyond his control—and evaluated whether the reason affected the size of the tip he received.
Although field experiments and laboratory experiments may appear on the surface to be very different because of the difference in settings, Aronson, Wilson, and Brewer (1998) point out that there is no simple distinction between them. Rather, experiments fall along a laboratory-field continuum defined by three characteristics of the research. The first characteristic is the way in which the participants in the research perceive their experience. In contrast to laboratory experiments, participants in field experiments are unaware they are in an experiment and are in a setting that more closely mirrors their everyday life. Consequently, field experiments usually involve deception and/or a lack of informed consent, and the attendant ethical issues discussed in Chapter 3.
The second characteristic defining the laboratory-field distinction is the ease with which the experimenter can assign participants to conditions of the independent variable; the experimenter has much more control over assignment in the laboratory. Finally, in the laboratory the experimenter has a much higher degree of control over extraneous variables and how the dependent variable is measured. The field experimenter must be content with a research environment that contains a host of uncontrolled factors in addition to the independent variable and with observing behavior as the dependent variable. This section looks at three issues relevant to field experimentation: choosing the research setting, ways in which the independent variable can be implemented, and problems inherent in field experimentation.
In the laboratory, experimenters have the ability to manufacture the research settings that they need to test their hypotheses. In the field, however, researchers must carefully choose settings that permit a valid test of their hypotheses. In choosing a setting, the field experimenter must consider the extent to which the setting restricts the sample of people available as research participants and the amenability of the setting to the manipulation of the independent variable.
Settings and samples. Bochner (1979) notes that natural research settings vary along a dimension of “publicness,” in that some settings are more likely to have a wider variety of people in them than are other settings. At the high end of the dimension are settings in which the researcher could, in principle, find any member of the public. Such settings include public parks, streets, and highways. In the middle of the dimension are reasonably public settings in which the people are likely to be similar on one or more characteristics. Such settings include public meetings, racetracks, residential households, and college campuses. At the low end of the dimension are settings that are less public and more institutionalized, where people are linked by some common characteristic. Such settings include student dormitories, public lavatories, subway trains, restaurants, stores, and libraries.
The choice of one type of research setting over another should be governed by the hypothesis to be tested. “The correct sequence is for investigators to have an idea which they wish to explore, and then find a suitable place where that idea can be translated into a psychological experiment” (Bochner, 1979, p. 34). It is also useful to try to conduct the experiment in a variety of settings to determine the extent to which the setting affects the results. Like the multiple operationism discussed in Chapter 6, multiple research settings enhance the generalizability of the research.
Characteristics of a good setting. There are two important characteristics of a good setting for a field experiment (Aronson, Ellsworth, Carlsmith, & Gonzales, 1990; Bochner, 1979). The first is the ability to manipulate the independent variable in the setting. At a minimum, the researchers must have sufficient control over events in the setting to permit them to expose people in the setting to the independent variable in a reasonably random way. That is, random assignment of participants in field experiments consists of randomly deciding which condition of the independent variable will be conducted at any one time. For example, Piliavin et al. (1969) could use a table of random numbers to determine whether a particular subway trip would have a drunk or ill victim included in it. Although Seligman et al. (1985) could not randomly determine whether a customer’s pizza was early or late (that was determined by how busy the cook was), they randomly decided whether to blame the deliveryman or the situation when they called customers to inform them that their pizzas would be early or late. The capability to randomly assign participants to conditions is important because if you cannot use random assignment, then the study is not a true experiment, and you must be very cautious in drawing causal conclusions about the effects of the independent variable.
The second important characteristic of a field experimental setting is that the events used to manipulate the independent variable should be occurrences that could reasonably be expected to take place in that setting. For example, people who are drunk or ill do ride subways and sometimes they collapse (Piliavin et al., 1969); pizzas are sometimes delivered earlier than expected and sometimes later (Seligman et al., 1985). Even events that are a little unusual can sometimes be tailored to fit the situation. For example, pizzerias rarely call customers to inform them that their food will arrive early or late. Seligman et al. (1985) made the call plausible by telling customers that the pizzeria was making the call “in an effort to offer better service to our customers” (p. 316). To the extent that research participants perceive the situation to be atypical, their responses will be atypical, obviating one of the advantages of field research.
Once a suitable setting is identified, the researcher should evaluate whether permission is needed to use that setting and, if so, should obtain it. This requirement is perhaps obvious if the setting is privately owned, such as a restaurant or store, but it can also apply to public property. For example, police might look with suspicion on someone loitering in a public park closely observing a group of children. If the implementation of an independent variable consisted of a simulated emergency, someone could call the police. It is therefore a good procedure to coordinate field experiments with people who have custody of or are responsible for public safety in a proposed research setting. Not only will this procedure avoid false alarms that are likely to incur the displeasure of public officials and consequently of the institution sponsoring the research, but it also will help keep the people in the setting unaware that research is being conducted: As Bochner (1979) remarked, nothing draws attention to field researchers like the police sweeping in to arrest them.
The implementation of the independent variable is the manner in which it is “delivered,” so to speak, to the research participants. Bochner (1979) identified two implementation strategies: street theater and accosting. As with the choice of a setting, the choice of how to implement the independent variable should be governed by how well the strategy assists in achieving a valid test of the hypothesis.
The street theater strategy. “The principle of the street theater strategy … is to stage an incident or introduce an event that will be witnessed by virtually every person in the surrounding area” (Bochner, 1979, p. 38). Piliavin et al. (1969) employed this strategy,
using the express trains of the New York 8th Avenue Independent Subway as a laboratory on wheels. Four teams of students, each one made up of a victim, model [who would assist the victim], and two observers, staged standard collapses in which type of victim (drunk or ill), race of victim (black or white) and the presence or absence of a model were varied…. As the train passed the first station [after the one at which the researchers boarded] … the victim staggered forward and collapsed. Until receiving help, the victim remained supine on the floor looking at the ceiling.… On 38 trials the victim smelled of liquor and carried a liquor bottle wrapped tightly in a brown bag (drunk condition), while on the remaining 65 trials they appeared sober and carried a black cane (cane condition). In all other respects, victims dressed and behaved identically in the two conditions. (pp. 289, 291)
Using this procedure, Piliavin et al. found that subway riders were more likely to go to the assistance of someone who appeared ill than someone who appeared drunk.
The accosting strategy. “The principle of the accosting strategy is to select a specific subject who then becomes the target for the experimental intervention” (Bochner, 1979, p. 39). Seligman et al. (1985) employed this strategy in their study of the effect of the reason given to customers for an early or late pizza delivery on the tip received by the deliveryman. The theory that the researchers were testing predicted that customers who thought that the deliveryman was responsible for an early delivery would tip more than if they thought him to be responsible for a late delivery, but that if situational factors, such as heavy traffic, affected delivery time, there would be no difference in tips for early and late delivery. Research participants were customers of a pizzeria who called for a pizza; all were told that it would be delivered in 45 minutes. If the workload at the pizzeria resulted in the pizza being ready early, customers were called back and informed of the early delivery; half were told that their delivery would be early because the deliveryman was doing a good job, and half were told that it would be early because traffic was lighter than normal. Similarly, if the workload resulted in a delay, customers were called back and told that the pizza would be late; half were told that the late delivery was the deliveryman’s fault, half that it was due to heavy traffic. The deliveryman recorded the amount of the tip he received for each delivery. He received the largest average tip when he was credited for an early delivery and the smallest when he was blamed for late delivery. When early or late delivery was attributed to situational factors, the average tips did not differ.
Transferring the experiment from the laboratory to the field creates a number of potential problems that the researcher must take into consideration. This section briefly considers three: construct validity, control over extraneous variables, and vulnerability to outside interference.
Construct validity. Field experiments frequently avoid problems of construct validity by using manifest variables rather than hypothetical constructs as independent and dependent variables (see Chapter 6). Piliavin et al. (1969), for example, manipulated directly observable characteristics of the victim (race and ill or drunk) and measured speed of response. However, sometimes researchers want to manipulate hypothetical constructs; Seligman et al. (1985), for example, wanted to manipulate people’s beliefs about why the deliveryman was early or late. To ensure that the reasons they gave in the telephone calls to customers created the desired beliefs, the researchers conducted a pilot study in which people in their university library filled out a questionnaire about pizza delivery services. The questionnaire included items about reasons for deliveries being early and late, including the reasons used as the operational definition of the independent variable. Respondents indicated whether the reason reflected a characteristic of the driver or of the situation (the hypothetical construct they wanted to manipulate). The results of this manipulation check supported the validity of their operational definition.
Bochner (1979) points out that although the dependent variables in field experiments are almost always behavioral measures and therefore represent manifest variables, discriminant validity can be a problem. One such factor is the possibility that a research participant’s response might be influenced by other people and therefore not be an accurate representation of the person’s natural behavior. For example, the customer who gave the tip in Seligman et al.’s (1985) study might have been influenced by recommendations about the appropriate size of the tip made by other people who were present when it was delivered.
Control over extraneous variables. Conducting an experiment outside the laboratory means that the researcher is trading control over extraneous variables for naturalism in behavior and setting. Consequently, the researcher must be careful to ensure that the conditions of the independent variable are not confounded with some aspect of the environment. Piliavin et al. (1969), for example, used both northbound and southbound subway trains for their research, and so had to ensure that all the conditions of the independent variables were represented in both categories of trains. It is, of course, unlikely that direction of travel itself would affect people’s responses, but it is possible that the characteristics of people who are traveling north and south at the same time of day might differ. For example, those traveling south might be on their way to work and those traveling north, going home from a night shift. Consequently the northbound travelers could be more fatigued and less alert, characteristics that could affect speed of response.
This situation represents a general problem in field research: People select themselves into field settings so that characteristics of research participants might be confounded with setting. It is therefore a good idea to use multiple settings for field experiments. If you get the same results across settings, it is unlikely that some characteristic of one of the settings or of the people who inhabit it is an alternative explanation to the independent variable as a cause of the dependent variable.
Vulnerability to outside interference. Finally, field experiments can be disrupted by events beyond the researcher’s control. Weather problems in outdoor research is the most obvious example, but there can be human interference as well. Gonzalez, Ellsworth, and Pembroke (1993), for example, staged a theft in front of a class as part of an eyewitness identification experiment; at the time, the class did not know the theft was staged. One of the students began to chase the thief, an eventuality not anticipated by the experimenters. Political events can also be problematic. Piliavin et al.’s (1969) researchers were all students at Columbia University. While the research was going on, the students at Columbia organized a strike to protest some of the university’s policies; “the teams disbanded, and the study was of necessity over” before all the intended data had been collected (p. 291).
The natural experiment attempts to achieve naturalism in treatment and setting by taking advantage of events outside the experimenter’s control that, in effect, manipulate an independent variable. Natural experiments can come about in several ways. One form of natural experiment takes advantage of naturally occurring events. For example, Larson et al. (2011) compared school-aged children who had been born prior to 26 weeks gestation (ELBW) to children carried to full term. They found that ELBW children performed worse on a number of measures of subtle motor function such as dexterity and were less able to copy repetitive movements, such as foot tapping, compared to children who were carried to term. In situations such as this, a natural experiment allows researchers to study independent variables that could not be manipulated for ethical reasons. Researcher slipups can also sometimes create natural experiments. Sommer (1991), for example, showed that people often interpret questionnaire response options metaphorically rather than literally by comparing college students’ responses to two versions of a course evaluation questionnaire. In one version, a typographical error had resulted in response options that were unrelated to the question, such as having the options “Excellent, Very Good, Good, Poor, Terrible” for responses to the statement “I always come to class.” Sommer found that responses to both the correct and the incorrect versions of the questionnaire were virtually identical. A third form of natural experiment results from intentional human behavior. Simonsohn (2011), for example, studied whether the name letter effect, or people’s preference for letters that appear in their own name, affected people’s behavior, such as what city they chose to live in. The natural experiment is, of course, actually a correlational study because the researcher does not manipulate the independent variable, cannot randomly assign research participants to conditions, and has little control over extraneous variables. Nonetheless, the term natural experiment is commonly used for this type of research. However, sometimes events can produce random assignment to conditions of an independent variable. For example, Brickman, Coates, and Janoff-Bulman (1978) studied whether winning the lottery increased people’s general levels of happiness, compared to people who lived in the same location but did not win. General happiness was similar for the two groups, but lottery winners reported taking less pleasure from everyday activities, such as talking with a friend or hearing a funny joke, compared to other people who lived in their area.
In a quasi-experiment, the researcher attempts to achieve naturalism in settings by manipulating an independent variable in a natural setting using existing groups of people as the experimental and control groups. For example, Greenberg, (1990) studied the effects of an organizational intervention by conducting the intervention in one factory operated by a corporation and using two other, geographically separate, factories as control groups. He then compared the behavior of the workers in the factories. Individual participants in quasi-experiments cannot be randomly assigned to the experimental and control conditions, although the groups to which they belong can be. The researcher is also not likely to have much control over extraneous variables in the natural setting used for the research. However, Campbell and Stanley (1963) called this kind of research a quasi- (the Latin word for “as if “) experiment because the researchers do manipulate the independent variable “as if” they were conducting a true experiment.
The natural experiment and the quasi-experiment differ in that the researcher manipulates the independent variable and can do a limited form of random assignment in the quasi-experiment, but must take advantage of an uncontrollable event in the natural experiment. However, the two are similar and we discuss them together because they use the same two approaches to collecting and analyzing data: the group comparison approach and the time series approach.
In the group comparison approach, the researcher establishes an experimental group that experiences the treatment condition of the independent variable and a no-treatment control group. As in any other experiment, the hypothesis may require that multiple experimental groups and multiple control groups be used to rule out alternative explanations for the effect of the independent variable. The most common group comparison design for natural and quasi-experiments is the nonequivalent control group design (Shadish, Cook, & Campbell, 2002).
The nonequivalent control group design. In the nonequivalent control group design, the researcher studies two (or more) groups of people. The members of one group experience the treatment condition of the independent variable; the members of the other group, chosen to be as similar as possible to the experimental group, serve as the control group. This control group is not considered equivalent to the experimental group because participants are not randomly assigned to conditions. Only the use of random assignment can give researchers reasonable confidence that person-related extraneous variables, such as personal experiences, personality, and so forth, are not confounded with conditions of the independent variable—that is, that the groups are equivalent on these variables (see Chapter 7). Let’s look at a couple of examples of how researchers have used the nonequivalent control group design in natural and quasi-experimental research.
Researchers have used natural experiments to explore the name letter effect, the hypothesis that people have preference for letters that appear in their own names and that this preference influences their behavior, such as their choice of occupation. For example, Pelham, Carvallo, and Jones (2002) found a relationship between the initial letter of people’s first names and their occupations, so that Dennis and Denise were found to be disproportionately likely to be dentists and Laura and Lawrence were disproportionately likely to be lawyers. However, Simonsohn (2011) replicated this study, taking into account the overall popularity of the name in a given time period. Results showed that people named Dennis were more likely to be dentists than were people named Walter, but that people named Dennis were also more likely to be lawyers. That is, for the time period studied, Dennis was a more popular name than Walter and that popularity, rather than the name letter effect, accounted for Pelham et al.’s (2002) findings.
Greenberg (1990) used a quasi-experiment to test the effect of explaining the reasons for a temporary pay cut to the affected workers. He hypothesized that workers who received a full explanation would be less dissatisfied than those who received no explanation. The research took place at three plants operated by a company that unexpectedly lost a major contract; two of the plants lost work because of the contract cancelation, whereas the other plant was unaffected so their pay was not changed. Workers at one affected plant were given a full and accurate explanation of the situation. They were told about the canceled contract, that the pay cut was being implemented as an alternative to laying workers off, and that managerial pay was being cut by the same percentage as workers’ pay. Workers at the other affected plant were simply told that the pay cut was taking place. Workers at the unaffected plant served as a baseline control group. The workers at all three plants made the same product, were of the same average age and educational level, and had the same average tenure with the company. Greenberg used employee turnover and theft rates before, during, and after the pay cut period as indicators of dissatisfaction. Turnover and theft increased during the pay cut period at the plant where the cut was announced without an explanation, but they remained unchanged at the other two plants.
The nonequivalent control group design is a useful tool in situations in which it is impractical to randomly assign research participants to conditions. However, using the design poses two problems that limit the degree to which one can draw causal conclusions from the research: the possibility of preexisting differences between groups on the dependent variable and biased selection of people into the experimental and control groups. As we will discuss, however, these problems can be minimized by careful selection of the experimental and control groups.
The problem of preexisting differences. You will have noticed that Greenberg (1990) included a pretest in his research designs. In quasi-experiments, such pretesting is conducted whenever possible to ensure that the experimental and control groups are similar on the dependent variable before the independent variable is introduced. Pretests are rarely used in true experiments because random assignment of participants to conditions results in experimental and control groups that have a high probability of being equivalent on the dependent variable prior to implementation of the independent variable.
Consider a study in which an independent variable is supposed to increase the reading scores of sixth graders and the researchers do not conduct a pretest. At the end of the study, the experimental group has higher reading scores than the control group. This difference might be due to the effect of the independent variable, but it could also result if the experimental group started out with higher scores and the independent variable had no effect. If the researchers conduct a pretest, they can determine if the groups initially differ on the dependent variable. If the groups do not differ, the researchers can proceed with the study and assess the effect of the independent variable with a posttest. The desired outcome is little change in the scores of the control group, coupled with a significant change in the scores of the experimental group. Of course, history, maturation, and other time-related effects will frequently lead to some change in the control group’s scores. The simplest nonequivalent control group design with a pretest is therefore a 2 × 2 factorial design with one between-subjects factor (the conditions of the independent variable) and one within-subjects factor (time). As shown in Figure 10.1, the desired outcome is an interaction in which the groups are the same at the pretest but differ at the posttest.
If the experimental and control groups do differ on the pretest, the researchers have a problem: There is no way to directly determine the effect of the independent variable above and beyond any effects resulting from the preexisting difference between the groups. One approach to dealing with this problem is the statistical technique known as analysis of
Design of a Pretest-Posttest Nonequivalent Control Group Design Quasi-Experiment.
The pretest shows that the experimental (E) and control (C) group means on the dependent variables are statistically equal at the pretest but differ significantly at the posttest. .
covariance (ANCOVA; Tabachnick & Fidell, 2007). ANCOVA provides a test of the effect of the independent variable that is adjusted for group differences in pretest scores based on a regression analysis of the relation between the pretest and posttest scores. In essence, ANCOVA asks what would the posttest means look like if the experimental and control groups had not differed on the pretest? One problem with this approach, however, is that the researcher has to make an educated guess about what variable or variables might account for preexisting differences; it is unlikely that she or he can identify or measure all possible sources of those groups’ differences (Pitts, Prost, & Winters, 2005). Although ANCOVA can be a powerful statistical tool, it requires that the slopes of the relationship between pretest and posttest scores be equal in both groups, a requirement that the researcher must test before conducting the analysis. In addition, ANCOVA does not always provide a precise answer to the research question being asked (Porter & Raudenbush, 1987). In some situations researchers also can use advanced statistical techniques to estimate the unknown biases that result in differences between the treatment condition and the control condition; discussion of this procedure is beyond the scope of this chapter, but see Rubin (2006) or West and Thoemmes (2010).
“But,” you might say, “there is a simpler solution to the problem of group differences on the pretest. Remember the matching strategy for assigning participants to conditions? Why not use that?” Achieving equivalence by matching people in the experimental and control groups on their pretest scores is tempting, but it can result in invalid results. For example, it is unlikely that a match is available for all members of the two groups; in that case, participants for whom there was no match would need to be dropped, limiting the external validity of the obtained results (Pitts et al., 2005). Recall that the type of matching discussed in Chapter 9 was matched random assignment to groups: Members of matched pairs were randomly assigned to the experimental and control conditions. Random assignment of individual participants to conditions is not possible when a natural or quasi-experiment is being conducted.
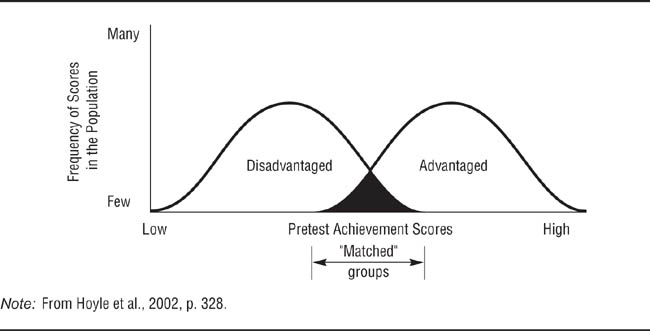
To understand the problem posed by trying to match participants when they cannot be randomly assigned to conditions, consider our proposed study aimed at increasing reading scores. Let’s assume that one group of sixth graders attends a selective private school and the second group attends a less selective public school. We have a standardized measure of initial reading scores that shows that the average achievement scores at the selective school are higher than those of the nonselective school. You therefore conduct your research using children from the two groups who have similar pretest scores; as shown in Figure 10.2, you would be taking the highest scorers from the selective school and the lowest scorers from the nonselective school. What happens to extreme test scores over time? They regress toward the group mean. Consequently, the scores of the children chosen for the research from the nonselective school will be lower at the posttest than at the pretest because their pretest scores were extremely high relative to their group’s average score, and the scores of the children chosen for the research from the selective school will be higher at the posttest than at the pretest because their pretest scores were extremely low relative to their group’s average score. Therefore, it will appear that the intervention improved the scores of the advantaged children and hurt the scores of the disadvantaged children. Trying to match members of nonequivalent groups that differ on the pretest will always lead to the possibility of a regression confound (Pitts et al., 2005).
Effect of “Matching” Members on Nonequivalent Groups That Differ on a Pretest.
Students from hypothetical advantaged and disadvantaged student populations are “matched” on pretest academic achievement scores. Because the “matched” students come from the higher end of the disadvantaged distribution and the lower end of the advantaged distribution, regression toward the mean will lead to the disadvantaged students appearing to do worse and the advantaged students appearing to do better on the posttest.
The problem of biased selection. As we discussed in Chapter 9, participants in true experiments are randomly assigned to conditions of the independent variable to avoid any bias that would result from confounding personal characteristics of the participants with conditions of the independent variable. However, participants in nonequivalent control group designs are not randomly assigned to conditions; it is therefore possible that the personal characteristics of the members of the experimental group differ from those of the control group. This problem is especially severe when participants select themselves into what will become the experimental and control groups. In Greenberg’s (1990) study, two kinds of biased selection could have been present. First, the participants applied to work at particular locations that appealed to them, one of which became the experimental site and the other of which became the control site. To the extent that different types of people preferred to work in the different locations, a confound was possible. Second, the factories decided whom to hire from among the applicants. To the extent that one personnel office hired people of a different type than another personnel office, a confound was possible.
As West (2009) points out, even when participants are randomly assigned to conditions, bias can operate so that after-the-fact selection differences exist between those conditions. One such fact is differential attrition between the groups. Consider, for example, an experiment on the long-term effects of a psychotropic drug on depression. Even if participants are initially randomly assigned to the drug or control condition, differential attrition rates may occur. For example, participants in the drug condition may drop out due to unpleasant side effects of the drug or participants in the control group may drop out and seek alternative treatment because they are not improving. Another way group differences can emerge is when treatment adherence differs across groups; that is, individuals in some experimental conditions may be more likely to follow the assigned treatment than individuals in other groups. For example, if some cancer patients are assigned to a new experimental regime that produces severe side effects, they might be more likely skip some treatment sessions than would individuals assigned to a treatment with less severe effects. If differential attrition or nonadherence is severe, the problem of biased selection could be operating in much the same way it does for groups that were not initially randomly assigned to condition; in this case, interpretation of results is subject to the same limitations as interpretation of the findings from a quasi-experiment (Shadish & Cook, 2009).
Patched-up quasi experiments. In many natural or quasi-experiments, conducting a pretest is impossible. For example, it is impossible to predict who will get cancer, so a pretest cannot be used to predict whether personality differences, such as resilience, affect responses to cancer treatments. However, it is sometimes still possible to add a control group to test for possible confounds (Campbell & Stanley, 1963; Cordray, 1986). Cordray (1986) calls these designs patched-up quasi-experiments because the control groups are selected in ways that patch over holes in the internal validity of the research. As discussed earlier, Simonsohn (2011), demonstrated that the overall popularity of the name Dennis accounted for the overrepresentation of dentists by that name. Simonsohn also recognized that names are often confounded with socioeconomic status. This might explain why certain names are associated with certain occupations; people from different backgrounds might be more likely to have a particular name and to pursue a particular occupation, for example. To examine this possibility, Simonsohn looked at whether people named George or Geoffrey were disproportionately likely to be geoscientists. They were. But they were also disproportionately likely to be other kinds of scientists. Simonsohn’s results do not explain why George is more likely to be a scientist than Dennis, but they do rule out the possibility that it is because his name sounds similar to his occupation.
Patched-up designs are also useful when researchers want to evaluate the effectiveness of an intervention after it has been designed and implemented. Posavac and Carey (2007) provide the example of an after-the-fact evaluation of a college’s junior year abroad program on the maturity level of seniors; the hypothesis was that foreign study would enhance international understanding. There were several problems to be faced evaluating their hypothesis. Because the request for the evaluation was made after the students had returned from their year abroad, no pretest could be conducted and the researchers could not use the next group leaving because of a short deadline for completing the measures. Consequently, the evaluators had to compare the returning seniors to seniors who had not studied abroad. However, self-selection then became a threat to internal validity: Students who choose to study abroad are different from those who choose not to. But self-selection could be controlled by comparing sophomores who applied for foreign study to the returned seniors. However, using sophomores as a control group raises maturation as a threat to internal validity; therefore, a maturation control group of sophomores who did not apply for foreign study was added to the design. The result was the 2 × 2 design shown in Table 10.1. As the bottom row of the table shows, seniors’ international understanding scores would be expected to increase by 5 points if they did not study abroad; however, the scores of those who took part in the program increased by 15 points relative to sophomores who intended to study abroad, indicating an effect for the program.
Of course, the possibility that preexisting group differences on other background variables, not assessed in the follow-up study, remains. One strategy for ruling out these effects is to add an additional control group that did not come from the same selection process as the original treatment or control group. Because selection procedures were different, any selection differences between this new control group and the original two groups would likely be due to a different set of preexisting conditions (Pitts et al., 2005). For example, recall our hypothetical example of a nonequivalent control group design comparing sixth graders reading ability after a reading program (experimental group) or without that program (control group). As we noted, if we selected students from a private and public school, we would be concerned that the difference in schools could create a selection confound and that any outcomes differences could be due to the type of school the students attended, rather than the reading program they took part in. If the private and public schools were both from an urban location, however, we might add a sixth-grade class from a rural school as an additional control group. These students would also be likely to differ from the experimental group, but those preexisting differences would be due to a different set of characteristics. If the results for the two control groups were similar and both of those groups showed less improvement than the experimental group, we can be more confident that our reading program was effective.
As we have explained, without random assignment to condition, researchers cannot ensure that selection biases do not threaten the validity of their results. Even so, some control groups provide a better match for the experimental group and researchers should strive to select the best control group possible. Shadish and Cook (2009) argue that researchers should take advantage of focal local controls, which can ensure that the control and treatment groups are as similar as possible. As they explain:
Example of a Patched-Up Quasi-Experimental Design
To assess the effect of a junior-year-abroad program, seniors who participated in the program were compared to seniors who had not; self-selection was controlled by comparing sophomores who intended to enter the program with those who did not.
|
Maturation Level | |
Student Group |
Sophomores |
Seniors |
Those who will study abroad or who have studied abroad |
50 |
65 (treatment group) |
Those who have not studied abroad or do not plan to do so |
40 |
45 |
Note: From Posavac and Carey, 2007, p. 212
The desirable control in a nonequivalent comparison group experiment is a focal local control group: in the same locale as the treatment group and focused on persons with the same kinds of characteristics as those in the treatment group, most particularly the characteristics that are most highly correlated with selection into conditions and with the outcome under investigation. Often control groups are one or the other, but not both. (Shadish & Cook, 2009, p. 619)
Hence, it might seem that a good comparison group for the sixth graders in our hypothetical reading intervention study would be a national random sample of sixth graders; this random sample, however, is “nonlocal” and likely differs in important ways from our experimental group. Similarly, the tactic of comparing readers from a selective school to those in a less selective school, which we discussed earlier, does not meet Shadish and Cook’s criteria. Selecting a focal local control “makes the job of estimating causal effects much easier from the start” (Shadish & Cook, 2009, p. 619).
In summary, the nature of research that uses the nonequivalent control group design therefore makes it difficult to rule out differences in the characteristics of the experimental and control participants as an alternative explanation to the effect of the independent variable for differences between the conditions. Consequently, this design cannot determine causality with certainty. However, as discussed, statistical procedures, such as ANCOVA, can be used to evaluate the effects of preexisting group differences and patched up designs can be used to rule out alternative hypotheses. Researchers can take two additional steps to increase their confidence that the independent variable was the cause of the difference. The first is replication: The more often an effect is replicated under different circumstances, the more likely it is that the independent variable was the causal agent. Second, in quasi-experimental research, it is sometimes possible to have multiple naturally occurring groups randomly assigned to experimental and control conditions. For example, in educational research, the schools in a school district might be randomly assigned as experimental and control sites for an educational intervention. This design is illustrated in Figure 10.3: Students (that is, research participants) are not randomly assigned to schools, but schools are randomly assigned to conditions of the independent variable. Even though students were not randomly assigned to schools, randomly assigning schools to conditions provides a limited degree of equivalence between the experimental and control groups. The data from such a study can then be analyzed using a nested analysis of variance design, which can separate the variance in the dependent variable due to the effect of the independent variable and from that due to the effect of attending a particular school (Shadish & Cook 2009).
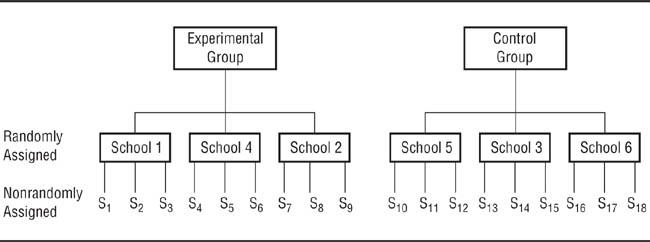
Nested Assignment in a Nonequivalent Control Group Quasi-Experiment.
Schools are randomly assigned to the experimental or control condition, but the students are not randomly assigned to the schools they attend.).
How severe are these problems? To examine the degree to which the results of true experiments and nonequivalent control group quasi-experiments might differ, Heinsman and Shadish (1996) compared the findings of 51 true experiments with those of 47 quasiexperiments that tested the same four hypotheses. They found that the results of the quasiexperiments were very similar to those of true experiments when the quasi-experiments were characterized by small differences between the experimental and controls on the pretests, low attrition rates, and low levels of participant self-selection into conditions—in other words, when the study has been well-designed and executed (see also Shadish & Cook, 2009). Such well-designed nonequivalent control group quasi-experiments are likely to provide results similar to those of true experiments and to lead to the same conclusion regarding the hypotheses being tested.
In the time series approach to quasi-experimentation, the researchers make a number of observations of the dependent variable, manipulate the independent variable, and make further observations of the dependent variable. The researchers then compare the level of the dependent variable before and after the manipulation of the independent variable. In a time series natural experiment, the researchers observe the dependent variable before and after the occurrence of an independent variable that they do not control. The time series approach is therefore essentially a single-case research technique and shares the advantages and limitations of that type of research (see Chapter 13). The number of observations needed depends on the variability of the dependent measure without treatment, but ranges from 10 to 100. The goal is to have sufficient numbers of observations to allow the researcher to rule out the possibility that observed changes following treatment are not, instead, the result of naturally occurring cycles or trends (Shadish & Cook 2009). The time series approach can take two forms: the interrupted time series design and the control series design.
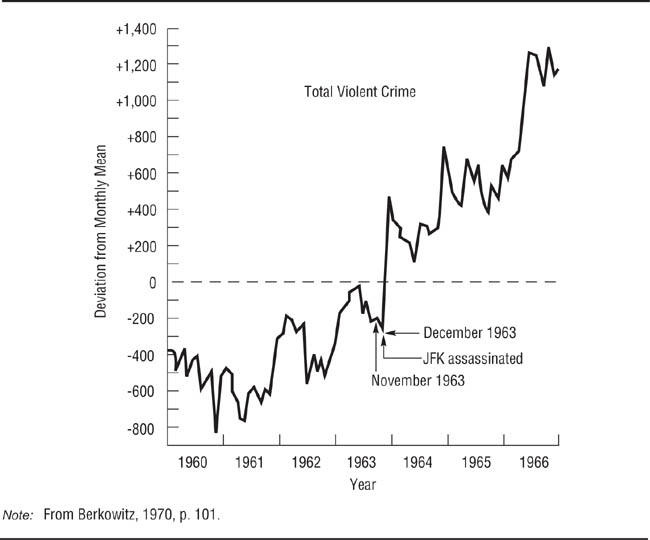
The interrupted time series design. The interrupted time series design consists of the basic single-case approach in which a baseline period is followed by a treatment that “interrupts” the baseline, followed by a period of post-treatment observations. Berkowitz (1970; Berkowitz & Macauley, 1971) used this approach in a natural experiment on aggression. As shown in Figure 10.4, Berkowitz used FBI crime statistics to plot the monthly frequency of violent crime from January 1960 to November 1963. President John F. Kennedy was assassinated in November of 1963; this event constituted the independent variable. Berkowitz then plotted the monthly violent crime statistics from December 1963 to December 1966. Given the sudden large increase in the crime rate, Berkowitz concluded that Kennedy’s assassination was a possible cause of the increase. However, as with other forms of non-experimental research, one must also consider the possibility of alternative explanations for the results of natural experiments such as this one. For example, social changes coinciding with the assassination, suggested by the upward trend in the baseline data for 1961 to 1963, might also have led to an increase in the violent crime rate.
Application of an Interrupted Time Series Design to a Natural Experiment.
Berkowitz (1970) examined the violent crime rate in the United States before and after John F. Kennedy’s assassination. The crime rate showed a marked increase after the assassination.
A variation on the interrupted time series design, known as the equivalent time samples design, expands the original design by withdrawing the treatment and again making observations about behavior without the treatment. At a later point, the treatment is reintroduced and behavior is assessed (Campbell & Stanley, 1963; Shadish & Cook, 2009). The expectation is that when the treatment is removed, responses will revert to the original baseline and, when the treatment is reintroduced, the results will be similar to those that emerged at the treatment’s first administration. If so, the researcher can be more confident that effects are not due to factors such as history, selection differences, or maturation. However, this design can only be used when treatment effects are temporary and are not subject to carry over effects (see Chapter 9).
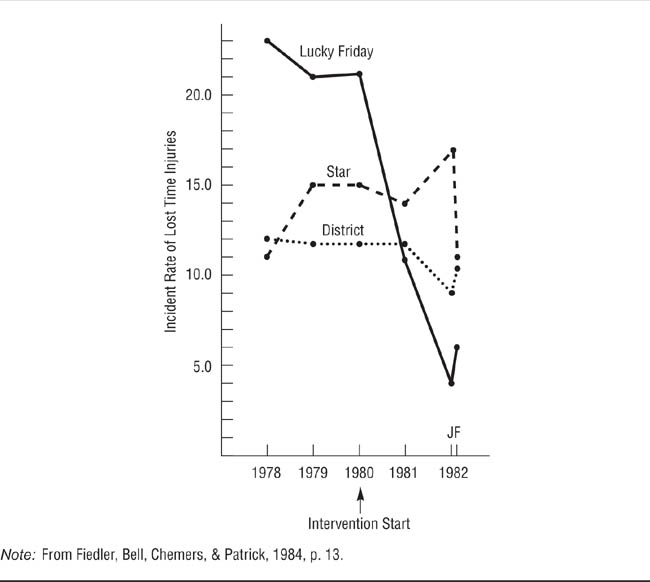
The control series design. The control series design consists of an interrupted time series design with the addition of one or more control cases. Fiedler, Bell, Chemers, and Patrick, (1984) used a control series quasi-experiment to evaluate the effectiveness of an intervention designed to improve mine safety. As shown in Figure 10.5, Fiedler et al. plotted the safety records for three mines for the years 1978 to 1980. In 1980, they conducted their safety intervention in the Lucky Friday mine. They then plotted the safety records of the mines for 1981 and 1982. The safety record of the Lucky Friday mine showed a sudden large improvement, the record of the District mine stayed essentially the same, and the record of the Star mine deteriorated. Fiedler et al. therefore concluded that the intervention was a success. Note that the Lucky Friday’s safety record at the beginning of the study was much worse than those of the other two mines (that’s why the mining company chose the Lucky Friday for the intervention). Regression toward the mean is therefore a possible alternative explanation for the improvement in safety. However, because the Lucky Friday’s injury rate fell to well below the mean, it is unlikely that regression was the cause of the change.
A Control Series Experiment.
Time lost to injuries was recorded in three mines from 1978 to 1982, with a safety intervention being implemented in the Lucky Friday mine in 1980. The sharp decrease in time lost to injuries in the Lucky Friday mine and the lack of change in the control mines indicate that the intervention was the cause of the improved safety.
A variation of the control series design is the multiple time series design, which involves including an additional treatment group that receives the treatment (or interruption) at a different time in the series than did the initial treatment group. For example, both experimental and archival research shows that driving while talking on a cell phone results in significant driver impairment (Harbluk, Noy, Trobovich, & Elizenman, 2007; Seo & Torabi, 2004). Because of this impairment, at the time of this writing, four states had enacted laws banning hand-held cell phone use while driving. Each locale enacted its law in a different month and year, allowing researchers to use the multiple-time series design to assess the effects of these laws. Collision claim data from three of those states before and after the ban are summarized in Figure 10.6. Regardless of the month the ban went into effect, collision claims did not decrease compared to control states assessed across the same time period (Highway Loss Data Institute, 2010).
We have described two major categories of time series designs, the interrupted time series design, in which baseline observations are interrupted by a treatment and then post-treatment observations are made, and the control series design, in which an untreated control group is observed across the same time period. As we’ve noted, these designs can be expanded by reversing treatment or by adding additional treatment groups. These designs can be extended in other ways as well; for example, researchers might introduce and remove treatments several times in a reversal design or might use switching replications where the control group becomes the treatment and the treatment group the control group. Researchers also sometimes add a nonequivalent dependent variable that is conceptually related to the variable of interest but is hypothesized to be unaffected by the treatment; if, as expected, this dependent measure is unaffected by the treatment, the researcher can be more confident in her or his results. These extended designs are described in detail in Shadish et al. (2002).

Adapted from Highway Loss Data Institute, 2010
Results of a Multiple Time Series Design Assessing Effect of No Texting While Driving Laws in Three States.
Researchers examined the frequency of collision claims in three states, Washington, Louisiana, and California, before and after laws against texting while driving went into effect. These data are based on a multiple time series design where the intervention (law went into effect) occurred on three different dates. Contrary to expectations, results showed no decrease in the number of collision claims compared to control states.
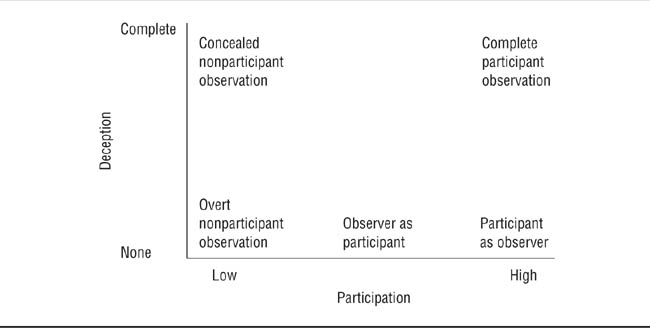
The goal of naturalistic observation is to study human behavior as it occurs in natural settings in response to natural events, uninfluenced by the researcher. As such, naturalistic observation tries to maximize the ecological validity of research but incurs the cost of minimizing control. Naturalistic observation is not a single method of research but, rather, a set of methods that vary along two dimensions (Bourchard, 1976). One dimension is that of participation, the degree to which the researcher-observer takes part in the events being observed. Participation can range from complete participation, in which the observer becomes an active member of the research setting, to complete nonparticipation, in which the observer remains apart from the situation and simply observes what occurs and records those observations. Level of researcher participation is also related to research strategy used. Generally speaking, the higher the level of researcher participation, the more likely a study is to use the case study strategy and involve qualitative data; the lower the level of researcher participation, the more likely a study is to involve group comparison strategies and quantitative data.
The second dimension is deception, the degree to which the observer conceals his or her identity as a researcher. In complete deception, the other occupants of the research setting are not aware of the observer’s role as researcher; the researcher is, in effect, an undercover agent collecting data on the other people in the setting without their knowledge or consent. In the absence of deception, the other members of the research setting are completely informed of the observer’s role as researcher. As noted in Chapter 3, the use of deceptive research methods places special obligations on researchers to protect the research participants. This section examines four categories of naturalistic observation derived from these dimensions and discusses some of the problems that can arise in research involving high levels of participation.
The dimensions of naturalistic observation research are illustrated in Figure 10.7, along with four prototypical categories of naturalistic observation research. Gold (1969) developed these categories as a means of distinguishing among various meanings of the way in which the term participant observation was being used in sociological research. In participant observation, the observer participates in the research setting. For example, Nathan (2005) enrolled as a Freshman college student and lived in the dormitory as a returning older student, but did not tell most of the people she interacted with that she was actually a cultural anthropologist. She did, however, inform those who she formally interviewed that she was a researcher, and those participants gave informed consent to being interviewed. Thorne (1988) was already a member of the draft resistance movement of the 1960s when she decided to study it as a sociologist, telling everyone with whom she had contact of her role as researcher. Black and Reiss (1967) had observers ride with police officers as they conducted their patrols in three large cities to study police-community interactions, informing the officers, but not the citizens with whom they dealt, of the observers’ roles as researchers.
Based on such differences in levels of participation and degree of deception, Gold (1969) distinguished three categories of participant observation (see Figure 10.7): complete participation, participant as observer, and observer as participant. A fourth category, nonparticipant observation, includes observational research in which the researcher overtly or covertly records behavior without taking part in the research setting. Let’s take a brief look at each of these categories.
Complete participation. In research in which the observer is a complete participant, the observer becomes a full member of the research setting (usually a group or community) without the other members of the setting being aware of the observer’s role as researcher.
Dimensions and Categories of Naturalistic Observation.
Types of naturalistic observation vary by the degree of deception and the degree of participation involved.
The researcher interacts as intimately as possible with the other members of the setting in as many ways as possible. As Nathan (2005) describes her research as a college student:
I moved into my dorm room on a Saturday in August, the first day that students were allowed to take possession of their rooms. The following week was designated “Welcome Week,” a time when students participate in optional social, sports and orientation activities prior to the start of classes…. The schedule was designed so that new students would choose from various activities, meet new people, and learn to negotiate the college campus. I joined as many activities as I could. (pp. 9–10)
As a participant-observer I concentrated, as many freshmen do in their first semester, on learning the ropes, meeting other students, getting acclimated to the dorm, trying out student clubs, and discovering what it took to do academic work. I spent every day and night of the week at the dorm, taking a full load of five undergraduate courses that ranged across the curriculum. Like other students, I went “home” only on the occasional weekend night or during holidays. (p. 16)
Levels of involvement such as these give the complete participant observer unique insight into the operations of a group and access to information about other members of the group that they would not reveal to nonmembers. However, it does raise the ethical issue of deception, and can lead to other problems, which will be discussed shortly.
Participant as observer. The participant as observer, like the complete participant, participates fully in the research setting but avoids the ethical problem of deception by fully informing the other people in the setting of her or his role as researcher. Thorne (1988) describes her approach to research:
I initially ventured into the draft resistance movement … because I was strongly opposed to the Vietnam war and wanted to be part of organized protest…. At the same period of time, I was looking around for a thesis topic, and after about a month of [participating in activities of the movement], I decided to become a sociological observer, as well as a participant committed to the goals of the movement….
As a point of principle, I wanted to avoid disguised research. From the start, I explained my research intentions to those I saw on a regular basis, as well as reassuring them that I shared their political commitments; their responses to my research activity ranged from hostility to mild tolerance. Overall, I was allowed to hang (often … under a specter of suspicion) because I did movement work and professed commitment to the goals of ending the war and the draft. (p. 134)
The participant as observer can avoid the problem of deception but, as Thorne’s experience illustrates, may induce reactivity among the other members of the research setting. Hostility and suspicion lead people to control the amount and type of information they give the researcher. Thorne also notes that even the best attempts to avoid deception are not always successful:
I discovered that people I had told tended to forget about my sociologist’s role…. Furthermore, in the course of [participating in movement activities], I encountered many people whom I had no chance to tell about my research intentions. In these situations I was, in effect, a disguised researcher. (p. 134)
Observer as participant. When researchers take the observer as participant role, they enter into the research setting but interact with the other members of the setting no more than is necessary to collect data. To use Jones’ (1985) phrase, the researcher is “only in, but not of, the setting” (p. 61). The observer’s role as researcher may or may not be known to the other members of the setting. For example, Black and Reiss (1967) had observers dressed in civilian clothes ride in patrol cars with uniformed police officers in Boston, Chicago, and Washington, D.C., to observe police-citizen interactions. The police officers knew that the observers were researchers, but the citizens who interacted with the officers were told nothing at all about the observers. If asked, the officers told the citizens that the observers were detectives. This research therefore had both deceptive and non-deceptive elements.
Nonparticipant observation. In nonparticipant observation, the observer avoids taking part in the research setting, merely watching what happens and recording the observations. The observations may be conducted overtly so that the people being observed are aware that they are under observation, or covertly so that the people are unaware of the observer. Schofield (1982), for example, conducted overt nonparticipant observation in a newly-opened integrated school to study the ways in which race affected the patterns of interactions among students and between students and teachers. The observers stood in hallways, playgrounds, and the backs of classrooms, and the students and teachers knew that they were there. Baxter (1970), in contrast, used covert observation to study the relationships of ethnicity, sex, and age to interpersonal distance. He sat near several exhibits at a zoo and recorded the sex, age (in terms of adult or child), and apparent ethnic group membership of pairs of people and estimated the distance between them. Note that, as in Baxter’s case, covert observers do not need to be physically concealed from the people they are observing; Baxter sat on a bench in plain view. Rather, the people under observation are not aware that an observer is watching and recording their behavior; most people pay little attention to someone who is apparently resting on a bench, as Baxter was.
Naturalistic observation methods allow the researcher to study natural behavior in its natural context, but they also involve some costs arising from the low degree of control that the researcher has over the research environment. Let’s briefly examine four categories of problems that can arise in naturalistic research: cognitive biases that can limit the validity of the data, limitations on recordkeeping, reactivity, and adverse effects on the researcher.
Cognitive biases. Human beings are the data collection mechanisms in naturalistic observation research; consequently, the normal human cognitive processes that lead to bias in everyday perceptual processes can bias the results of observations (Jones, 1985). One such bias is selective attention: People do not pay equal attention to everything that goes on around them; they selectively attend to stimuli that are salient to them, that is, those that attract their attention (Fiske & Taylor, 1991). For example, observers are more likely to attend to people who stand out from the background, such as those who are dressed differently from others in the setting, or those who constitute a minority in the setting, such as the only woman in a group of men. Point of view also affects attention: We are more likely to pay attention to people at whom we are looking face to face, rather than from behind or from one side. To the extent that people or events that are salient in a setting distract the observer’s attention from other, perhaps more important, people or events, the data from those observations will be biased.
As discussed in Chapter 2, the Redfield-Lewis debate over interpretations of the quality of life in a Mexican village showed that people’s expectations about what they will see affect their interpretations of those events. People tend to interpret events to conform with what they already believe about the situation (Fiske & Taylor, 1991). Recall Redfield’s comment that “the hidden question behind my book is, ‘What do these people enjoy?’ The hidden question behind Dr. Lewis’s book is, ‘What do these people suffer from?’” (quoted in Critchfield, 1978, p. 66). Even when people have no strong preset expectations, their first impressions of a person or situation establish expectations that color their interpretations of later events (Fiske & Taylor, 1991).
Finally, when people cannot take notes on events as they happen, as is normally the case in complete participation, they tend to remember what they think should have happened in a situation rather than what did happen (Fiske & Taylor, 1991). This kind of reconstructive memory occurs because people have mental scripts that tell them how events should unfold; for example, you can probably very easily describe the sequence of events in a job interview. These mental scripts provide people with a framework for understanding and remembering things, so that memory tends to follow the script even when the actual event departs from it. Shweder (1975), for example, found that observers at a boys’ camp tended to recall the boys’ behavior as more closely fitting their stereotypes of how boys should behave at camp than how the boys actually behaved.
These kinds of cognitive biases are normal aspects of human information processing and so are likely to affect any observational study. However, as we will discuss in Chapter 14, researchers can enhance the reliability and validity of behavioral observations by training observers, using behavioral ratings rather than observers’ interpretations of behavior as data, and, whenever possible, recording the behavior as it occurs.
Recordkeeping. Unfortunately, it is not always possible to record behavior as it occurs. Complete participant observers are normally unable to take notes as events occur because note taking would inhibit their full participation in events and reveal their roles as researchers. Note taking is not always possible even in overt observation. The participant as observer must take full part in the events being studied, and Black and Reiss (1967) found that their observers as participants could not take complete notes while watching police-citizen interactions and that it was difficult to write notes afterward in a moving patrol car, especially at night. Observers must therefore frequently write down their observations after the event, sometimes several hours later. Under these conditions, both the cognitive biases described earlier and normal memory lapses can lead to inaccurate recall. However, as Bogdan (1972) points out, experience has taught field researchers a number of techniques for recording observations with reasonable accuracy; some of these techniques are shown in Box 10.1.
• |
Record observations as soon after the event as possible. |
• |
Don’t talk to anyone about your observation session until after you have recorded the observations. |
• |
Talking about observations can have two adverse effects: What you talk about becomes more salient, and the other person’s comments might distort your memory. |
• |
Record your observations in complete privacy to eliminate distractions. Record observations in the order that the events happened; recording salient events first can distort memory for other events. |
• |
Draw a diagram of the physical layout of the observation setting, and as you record your notes attempt to trace your steps in the sequence that they occurred during the observation period. |
• |
Outline the topics covered in particularly long periods of observation before attempting to record those periods; then record one topic at a time. |
• |
Make observations in time periods of manageable size and record the observations for one period before starting another. You can increase the lengths of the periods as you gain experience. |
• |
When recording dialog, don’t worry about whether your quotations are flawless verbatim reproductions of what was said. |
• |
Pick up pieces of lost data after your initial recording session. If after a recording session you recall something that you omitted, go back and put it in. |
Source: Adapted from Bogdan, 1972, pp. 41-42.
Reactivity. As noted in Chapter 7, when people are aware that they are part of a research study, they may change their behavior to show themselves in a favorable light. Reactivity may be a special problem when the phenomenon under study includes behavior that is illegal or disapproved of by a powerful segment of society. Recall Thorne’s (1988) comment that her research activities were sometimes viewed with suspicion even though she was a committed member of the draft resistance movement. The possibility of reactivity leads some researchers to use covert methods in both participant and nonparticipant research.
Influencing events. In trying to reduce reactivity by concealing their status as researchers, covert participant observers can run the risk of contaminating the naturalism of what they observe by unintentionally influencing the people and events that they are observing. Alfred (1976) joined a Satanic church to study its members’ motivations for joining a Satanic group. As a complete participant, he did not reveal to any of the group members that he was a researcher and he tried not to influence their behavior. Alfred described his experience this way:
Throughout the research, I tried to minimize … my own effect on the group I was studying. I was generally nondirective in my comments and conversation, demurred in first requests for suggestions or ideas, answered subsequent requests with suggestions made previously in similar situations by others, and even selected at random pages from books out of which I was asked to read something of my choice. Even in the group’s ruling council I was able to avoid undue influence, since it was an advisory rather than a legislative body…. Such efforts and devices, however, did not completely solve the problem.; I often had to choose what ideas to second, since I was generally perceived as a high-status member and since my behavior was interpreted by others as flowing from genuine satanic conviction and devotion to the church rather than as random acts or simple yesmanship. (p. 184)
The more complete an observer’s participation in the research setting, the more likely such forms of reactivity are to occur and the more likely they are to be unavoidable. The only solutions to this problem are, as illustrated by Alfred’s comments, to attempt to minimize one’s influences on the research setting and to be aware of the possibility of such influences when interpreting data.
Effects on the observer. The role of participant observer can be very stressful, especially when the observer is concealing his or her identity as a researcher. In such cases, the researcher must work simultaneously at playing the role of a real member of the research setting—dressing, speaking, behaving, and interacting according to the norms of the setting, which may differ significantly from the observer’s own norms—and making careful, complete observations. In addition, covert observers often feel anxious or guilty over the deception they are carrying out and feel they are invading the privacy of the people they are observing. Not surprisingly, then, covert participant observers often feel overwhelmed by their roles (Lofland, Snow, Anderson, & Lofland, 2005).
Sometimes, covert participant observers act to relieve some of the stress by “confessing” their researcher roles to the people they are observing or to leaders among the people. Alfred (1976), for example, told the leader of the Satanic church he was studying about his role as researcher and asked the leader’s permission to publish the results of the research. He got a surprising response. Although Alfred had developed ethical qualms over his deceptive role, the church leader not only saw it as ethical, but commendable: As a proper Satanist, Alfred was supposed to deceive people and manipulate them for his own ends! Similarly, Nathan (2005) discusses her dual role as a faculty member, who as an officer of the university is duty bound to report any violation of university or public law, and that of a researcher who is ethically bound to protect the identity of her informants who might engage in these behaviors.
Even overt participant observation is not without its stresses. Thorne (1988) reports that throughout her research she experienced conflicts between her dual roles of researcher and activist; for example, she wanted to experience as many different resistance activities as possible in order to get a reasonably representative sample of experiences, but she felt that this lack of total commitment to any one activity limited her effectiveness in any of them. Thorne (1988) notes that although conflicts such as hers, Alfred’s, and Nathan’s are inevitable, their particular forms are not predictable in advance of the research. They are personal issues that each researcher must resolve in his or her own way. Nathan, for example, handled hers with a decision to formally “relinquish my role as an officer of the university” (p. 160).
Because participant observers live the roles they play, they can become socialized into those roles; that is, they can change to become the types of people whom they are studying. Reiss (1968) found this happening to the observers in his study of police-citizen interactions. Over the course of their experiences, the observers tended to become more propolice in their attitudes, albeit each in his own way. Sociologists among the observers, for example, initially tended to attribute police officers’ behavior to the officers’ personal characteristics, seeing them as bigoted and basically disinterested in the welfare of the citizenry. As they experienced police work, however, they tended to come to attribute police behavior to the stresses of the environment in which they worked, facing dangers unappreciated by “civilians.” The extreme of socialization is what Reiss calls “going native”: completely adopting the value system, attitudes, and behaviors of the people being studied. He cites the example of an observer he refers to as “Mr. M—” who worked in a high-crime African American neighborhood:
On the last evening he was in the [police] station, one of the officers said, “Mr. M—, what did you learn while you were here this summer?” And Mr. M—, to the shock of a fellow observer, replied, “I learned to hate [racial epithet].” I suspect he even shocked many of the officers with that. He had become a kind of mockery of what they were. (pp. 365–366)
As Reiss (1968) notes, “Participant observation can be socialization with a sociological vengeance” (p. 365).
Research in natural settings, or field research, is conducted to obtain data that are more representative of people’s true responses to natural situations than are data collected in the laboratory. However, field settings provide lower control over independent, dependent, and extraneous variables and over assignment of research participants to conditions of the independent variable. Natural setting research can take a number of forms, including field experiments, quasi-experiments, natural experiments, and observational research.
Field experiments attempt to achieve a balance between naturalism and control by manipulating an independent variable in a natural setting and observing natural behavior in response to the independent variable. In conducting a field experiment, the researcher must choose a setting that contains research participants who have the desired characteristics and that will allow implementation of the independent variable in a controlled and plausible manner. The researcher must also obtain permission to use the setting. The independent variable can be manipulated using either the street theater strategy, in which everyone in the setting is exposed to the independent variable, or the accosting strategy, in which one person is singled out as a participant. In designing a field experiment, the researcher must be concerned with potential problems of construct validity, control over extraneous variables, and vulnerability to outside interference.
Natural experiments attempt to achieve naturalism in treatments and setting by taking advantage of events outside the researcher’s control that, in effect, manipulate an independent variable. In a quasi-experiment, the researcher manipulates an independent variable using naturally occurring groups as the experimental and control groups. Both techniques use the same research designs. In the nonequivalent control group design, natural groups comprise the experimental and control groups in a group comparison approach. The researcher must ensure that the members of the experimental and control groups are equivalent on the dependent variable prior to the introduction of the independent variable and on extraneous variables. Whenever possible, this equivalence is determined by a pretest. Trying to match people from groups that are not equivalent on a pretest of the dependent variable is a mistaken strategy because it introduces the possibility of regression toward the mean on the posttest. However, researches can implement strategies, such as choosing a focal local control, to optimize the selection of the control group.
The time series approach, which uses either an interrupted time series design or a control series design, is akin to a single-case experiment: Scores for the dependent variable are plotted before and after the introduction of an independent variable, and the effect of the independent variable is gauged by the amount of change in post-intervention scores. Variations of these basic designs can be implemented to control for threats to internal validity.
Naturalistic observation seeks to attain naturalism in behavior, settings, and treatments by studying people’s natural behavior in natural settings with minimum interference by the researcher. Naturalistic observation research can vary along the dimensions of participation and deception, resulting in four categories of naturalistic observation. In complete participant observation, the researcher becomes a full member of the research setting without telling the other members of her or his role as researcher. The participant as observer becomes a full member of the setting but is open about the researcher role. The observer as participant enters into the research setting but interacts with members of the setting no more than is necessary to collect data, usually being open about the researcher role. In nonparticipant observation, the researcher takes no part in the research setting, passively observing, either overtly or covertly, what happens.
Naturalistic observation research can suffer from cognitive biases of the observer, such as selective attention, selective interpretation of events, and selective recall; poor record-keeping, especially in complete participant observation; reactivity; influencing events; and adverse effects on the researcher.
Lofland, J., Snow, D. A., Anderson, L., & Lofland, L. H. (2005). Analyzing social settings: A guide to qualitative observation and analysis (4th ed.). Belmont, CA: Wadsworth.
This comprehensive guide explains how to conduct observational research. The authors address issues related to gathering data, such as selecting the appropriate setting, factors affecting the researchers’ role as an observer, and strategies for recording and analyzing data.
Nathan, R. (2005). My freshman year: What a professor learned by becoming a student. Ithaca, NY: Cornell University Press.
Nathan’s research is not without its critics, especially about the ethics of her study and how easily the institution she studied was identified after her work was published. Even so, the book provides a highly readable example of naturalistic research on a topic familiar to both graduate and undergraduate students—the college campus.
Shadish, W. R., & Cook, T. D. (2009). The renaissance of field experimentation in evaluating interventions. Annual Review of Psychology, 60, 607–629.
This paper provides a comprehensive review of field experimentation, beginning with a history of this research and a discussion of how both statistical and methodological advances have changed researchers’ perceptions of the validity of this research. The authors discuss a number of designs, with a focus of how innovation has improved the quality of research based on each methodology.
West, S. G. (2009). Alternatives to randomized experiments. Current Directions in Psychological Science, 18(5), 299–304.
The author provides a brief and accessible review of nonrandomized designs, including internal validity issues and the question of whether causal inference is possible in those designs.
Analysis of covarience
Complete participant
Control series design
Field experiment
Field research
Interrupted time series design
Natural experiment
Naturalisitic observation
Nested analysis of variance design
Nonequivalent control group design
Nonparticipant observation
Observer as participant
Participant as observer
Participant observation
Patched-up quasi experiment
Quasi-experiment
Reconstructive memory
Selective attention
1. |
How do field research settings differ from laboratory settings? What advantages and disadvantages do these characteristics confer on field research? |
2. |
How does a field experiment differ from a laboratory experiment? |
3. |
What issues must one consider in choosing a research setting for a field experiment and implementing an independent variable in a field setting? |
4. |
Describe the problems and limitations of conducting field experiments. |
5. |
What are the similarities and differences between natural experiments and quasiexperiments? How does each differ from a true experiment? |
Describe the nonequivalent control group design. What problems is a researcher likely to face in conducting a study using this design? Why is matching a mistaken strategy when groups are initially different on the dependent variable? How can a degree of randomization of participant characteristics be achieved in this design? | |
7. |
What is the purpose of a patched up quasi-experimental design? How can it be used to address possible threats to validity in a nonequivalent control group design? |
8. |
What steps can a researcher take to ensure that the optimal control group is selected? |
9. |
Describe the interrupted time series and control series designs. How are they similar and how do they differ? |
10. |
What are the dimensions of naturalistic observation and the categories of observer roles derived from them? |
11. |
Describe the problems and limitations of conducting naturalistic observation research. |
12. |
Choose a hypothesis that interests you. How would you test the hypothesis using naturalistic observation, a field experiment, a natural experiment, and a quasi-experiment? What are the advantages and disadvantages of each of those approaches? |