Open- and Closed-Ended Questions
Use the language of research participants
Ask only one question at a time
Avoid leading and loaded questions
Address sensitive topics sensitively
Advantages of Multi-Item Scales
Respondent interpretations of numeric scales
Suggestions for Further Reading
Questions for Review and Discussion
In the most general sense, survey research is the process of collecting data by asking people questions and recording their answers. Surveys can be conducted for a variety of purposes, two of which predominate. One purpose is the estimation of population parameters, or the characteristics of a population. For example, the goal of a survey might be to determine the percentage of people who hold supporting and opposing positions on social issues, such as nuclear power; the percentage who perform certain behaviors, such as smoking cigarettes; or the demographic characteristics of the population, such as sex, age, income, and ethnicity. The U. S. census, public opinion polls, and the periodic General Social Survey (GSS) conducted by the University of Chicago’s National Opinion Research Center are all surveys directed at estimating population parameters. The second purpose for which a survey might be conducted is hypothesis testing. Researchers might be interested in the correlations between the answers to questions or between characteristics of respondents and their answers. Surveys can be conducted specifically for the purpose of hypothesis testing, or researchers might use data from survey archives, such as those described in the next chapter, to test their hypotheses. Experiments can also be conducted by survey methods when the researcher manipulates independent variable by varying the information that participants receive: People in the different conditions of the independent variable receive versions of the survey that contain the information that defines the condition to which they are assigned.
Surveys can also be classified into two broad categories based on the way respondents are recruited. Respondents in sample surveys are selected in ways that are designed to produce a respondent sample whose characteristics closely mirror those of the population from which the sample was drawn. National public opinion polls and the GSS are examples of sample surveys: They use techniques described in the next chapter to obtain respondent samples from each region of the United States who reflect the gender, ethnic group, and age distributions of the population. Respondents in convenience surveys consist of members of whatever group or groups of people that the researcher found it convenient to sample from. Most self-report research in the behavioral sciences uses convenience surveys, primarily of college students. The data from sample surveys can be used either to estimate population parameters or to explore relationships between variables. Because the samples used in convenience surveys are not representative of a population, they cannot be used to estimate population parameters but are commonly used in hypothesis-testing research.
This chapter provides an overview of several key issues in survey research. We first describe the process of writing questions and creating question response formats, and the advantage of using multi-item scales, especially when measuring hypothetical constructs. We next discuss the problem of response biases and conclude with an overview of the principles of questionnaire design and administration. One chapter cannot cover all the information you would need to know before conducting survey research, so before getting started on your own survey research you should consult a specialized book on the topic.
Survey researchers collect data by asking questions. The questions, or items, are compiled into questionnaires that can be administered to respondents in a variety of ways, as discussed later in this chapter. These items are composed of two parts. The stem is the question or statement to which the research participant responds, and the response options are the choices offered to the respondent as permissible responses. Consider the following item:
The university should not raise tuition under any circumstances.
Agree |
Disagree |
In this example, “The university should not raise tuition under any circumstances” is the stem and “Agree” and “Disagree” are the response options. This section discusses stem (or question) writing, and the next section discusses formats for response options. The phrasing of the question is extremely important because differences in phrasing can bias responses. In fact, the issue of question phrasing is so important that entire books have been written on the topic (for example, Bradburn, Sudman, & Wansink, 2004). In this section we have space to touch on only a few of the major issues; see the suggested reading list at the end of the chapter for sources that can guide you on your own research.
Questions can be grouped into two broad categories. Open-ended questions, such as essay questions on an exam, allow respondents to say anything they want to say and to say it in their own words. Closed-ended questions, such as multiple-choice exam questions, require respondents to select one response from a list of choices provided by the researcher. Researchers generally prefer closed-ended questions because they can choose response options that represent categories that interest them and because the options can be designed to be easily quantified. However, open-ended questions are more useful than closed-ended questions in three circumstances. The first is when asking about the frequency of sensitive or socially disapproved behaviors. Bradburn and colleagues (2004), for example, found that people reported higher frequencies of a variety of drinking and sexual behaviors in response to open-ended questions than in response to closed-ended questions. A second circumstance is when you are unsure of the most appropriate response options to include in closed-ended questions on a topic or to use with a particular participant population. Schuman and Presser (1996) therefore recommend using open-ended questions in preliminary research and using the responses to those questions to design response options for closed-ended questions. This strategy can reveal response options the researchers did not think of. Conversely, the response options included in closed-ended questions might remind respondents of responses they might not think of spontaneously. We discuss this issue later in the chapter as well as the possibility that open-ended questions can assess some types of judgments more accurately than can closed-ended questions.
A major lesson survey researchers have learned is that the way in which a question is phrased can strongly affect people’s answers. Consider the two questions shown in Table 15.1. Half the respondents to surveys conducted in the late 1970s were asked the first question; the other half were asked the second question. Notice that adding the phrase “to stop a communist takeover” increased the approval rate for intervention from 17% to 36%. Let’s examine a few basic rules of question writing.
Use the language of the research participants. The questions used in survey research are usually written by people who have at least a college education and frequently by people who have a graduate education. As a result, the question writers’ vocabularies may differ significantly from those of their respondents in at least two ways. First, researchers use many technical terms in their professional work that are unknown or that have different meanings to people outside the profession. Using such terms in questions will usually result in confusion on the part of respondents. Second, researchers’ normal English vocabulary is likely to be larger than that of their participants, and using what might be called an intellectual vocabulary is another source of misunderstanding. As Converse and Presser (1986, p. 10) note, the “polysyllabic and Latinate constructions that come easily to the tongue of the college educated” almost always have simpler synonyms. For example, “main” can be used for “principal” and “clear” for “intelligible.” It is also wise to avoid grammatically correct but convoluted constructions such as “Physical fitness is an idea the time of which has come” (Fink & Kosecoff, 1985, p. 38). “An idea whose time has come” might irritate grammarians, but will be clearer to most people. When people fail to understand a question, they will interpret it as best they can and answer in terms of their interpretation (Ross & Allgeier, 1996). Consequently, respondents might not answer the question that the researcher intended to ask.
TABLE 15.1
Effect of Question Wording on Responses to Survey Questions
Question |
Percent in Favor of Sending Troops |
If a situation like Vietnam were to develop in another part of the world, do you think the United States should or should not send troops? |
17.4 |
If a situation like Vietnam were to develop in another part of the world, do you think the United States should or should not send troops to stop a communist takeover? |
35.9 |
Note: From Schuman and Presser (1996)
Because respondents may misunderstand or misinterpret questions, it is important to pretest questionnaires to assess people’s understanding of the questions. Samples of respondents from the population in which the questionnaire will be administered should be used for pretests. Sudman, Bradburm, and Schwarz (1996) describe a number of methods for assessing the comprehensibility of questionnaire items; Box 15.1 lists a few of them.
• |
Have respondents read each question, give their responses, and then explain how they decided on their responses. For example, “Tell me exactly how you arrived at your answer …how did you work it out … how exactly did you get to it?” (Sud-man, Bradburn, & Schwarz, 1996, p. 19). This technique is sometimes called the think aloud method. |
• |
Directly ask respondents what the item meant to them. For example, Ross and Allgeier (1996) asked their respondents, “What I would like you to do is tell me what you though the item was actually asking you. I’m only interested in your interpretation. What did you think this item was asking when you responded to it?” (p. 1593). |
• |
Ask respondents to define specific terms used in the items. Be sure to let them know that you are trying to identify unfamiliar words and terms, so “I don’t know” is an appropriate response. |
• |
When you administer the questionnaire to the research sample, for each item record the number of respondents who ask for clarification, give incomplete responses, or give responses that suggest they misinterpreted the item. |
Avoid unnecessary negatives. Using negative constructions in questions can lead to confusion. Consider this hypothetical example: “Do you agree or disagree that people who cannot read well should not be allowed to teach in public schools?” Whether respondents agree or disagree, it’s impossible to tell what they’re agreeing or disagreeing with. Although this is an extreme example, researchers are sometimes tempted to use negative constructions as a way of balancing questions to control for some people’s tendencies to agree with whatever position they are presented with. Very often, however, a little searching will turn up alternatives. If our example were changed to “Do you agree or disagree that only people who read well should be allowed to teach in public schools?” the meaning of the responses would be clearer.
Ask only one question at a time. A double-barreled question asks for two or more pieces of information at once. Consider the following question used in a national opinion poll in 1973: “Do you think that President Nixon should be impeached and compelled to leave office, or not?” (Wheeler, 1976, p. 182). Impeachment is the investigation and indictment of an official by the House of Representatives for an alleged offense; removal from office is a possible punishment if the official is found guilty after trial by the Senate. It would certainly be possible to agree that an official’s actions should be investigated but to disagree that removal from office is the appropriate penalty if the official is found guilty. This question also illustrates the vocabulary problem: A concurrent poll found that fewer than 50% of its respondents knew the meaning of impeachment (Wheeler, 1976).
Questions can become double-barreled through implication as well as the use of the word and. Consider the following example given by Lewin (1979, p. 137):
Your class functions as a stable, cohesive group, with a balance of leadership, which facilitates learning.
Always |
Often |
Sometimes |
Rarely |
Never |
This question asks for four pieces of information: perceived group stability, perceived group cohesiveness, type of leadership used in the group, and the effects of these factors, if any, on learning. Always ensure that each question used on a scale asks for only one piece of information; otherwise, you never know which question respondents are answering.
Avoid leading and loaded questions. A leading question implies that a certain response is desired. For example, “Do you agree that implies that agreement is the desired response. Similarly, the question “How attractive is this person?” suggests that they are, in fact, attractive; phrasing the question as “How attractive or unattractive is this person?” is less leading. Notice that the questions used as examples so far in this section have been balanced; that is, they suggest that either agreement or disagreement is an acceptable response (for example, “Do you think that … or not?” “Do you agree or disagree that …?”).
A loaded question uses emotional content to evoke a desired response, such as by appealing to social values, such as freedom, and terms with strong positive or negative connotations. Sudman and Bradburn (1982, p. 7) give this example:
Are you in favor of allowing construction union czars the power to shut down an entire construction site because of a dispute with a single contractor, thus forcing even more workers to knuckle under to union agencies?
Although this example is extreme, question loading can also be subtle. Rasinski (1989), for example, found that 64% of respondents to a series of surveys agreed that too little money was being spent on assistance to the poor, whereas only 23% agreed that too little was being spent on welfare. Clearly, welfare has a more negative connotation than assistance to the poor, even though both terms denote providing money to people in need. Table 15.2 lists some other pairs of phrases that Rasinski found to elicit different agreement rates.
Be specific. People’s belief systems are very complex. One result of this complexity is that people’s beliefs about general categories of objects can be very different from their beliefs about specific members of those categories. For example, you might like dogs in general but detest your neighbor’s mutt that barks all night. The effect of question specificity on response can be seen in the examples shown in Table 15.3, taken from a poll conducted in 1945. You must therefore ensure that your questions use the degree of specificity necessary for the purposes of your research.
Examples of Question Phrasings Receiving Different Agreement Rates in Surveys
Too little money is being spent on … |
Percent Agreeing |
Solving problems of big cities |
48.6 |
Assistance to big cities |
19.9 |
Protecting Social Security |
68.2 |
Social Security |
53.2 |
Improving conditions of African Americans |
35.6 |
Assistance to African Americans |
27.6 |
Halting rising crime rates |
67.8 |
Law enforcement |
56.0 |
Dealing with drug addiction |
63.9 |
Drug rehabilitation |
54.6 |
Note: From Rasinski (1989)
Do not make assumptions. It is easy to write questions that include unwarranted assumptions about the respondents’ characteristics or knowledge base. For example, the question “Do you agree or disagree with U.S. trade policy toward Canada?” assumes the respondent knows what that policy is. Similarly, asking, “What is your occupation?” assumes that the respondent is employed. People are quite willing to express opinions on topics with which they are unfamiliar; for example, Sudman and Bradburn (1982) reported that 15% of the respondents to one survey expressed opinions about a fictitious civil rights leader. Therefore, it is generally a good idea to verify that a respondent is familiar with a topic when asking questions about it. However, such verification questions should be tactful and not imply that the respondent should be familiar with the topic. Such an implication could lead the respondent to make up an opinion in order not to appear uninformed.
TABLE 15.3
Effect of Different Degrees of Question Specificity on Survey Responses From a Poll Conducted in 1945
Question |
Percent Answering Yes or Favor |
Do you think the government should give money to workers who are unemployed for a limited length of time until they can find another job? |
63 |
It has been proposed that unemployed workers with dependents be given $25 per week by the government for as many as 26 weeks during one year while they are out of work and looking for a job. Do you favor or oppose this plan? |
46 |
Would you be willing to pay higher taxes to give unemployed people up to $25 dollars a week for 26 weeks if they fail to find satisfactory jobs? |
34 |
Note: $25 in 1945 is the equivalent of $295 in 2010. From Bradburn, Sudman, and Wansink (2004), p. 7.
Address sensitive topics sensitively. Sensitive topics are those likely to make people look good or bad, leading respondents to underreport undesirable behaviors and to over-report desirable behaviors. Sudman and Bradburn (1982) suggest some ways to avoid biased responses, a few of which are shown in Box 15.2.
To avoid underreporting of socially undesirable behaviors:
• |
Imply that the behavior is common, that “everybody does it.” For example, “Even the calmest parents get angry with their children some of the time. Did your children do anything in the past week to make you angry?” |
• |
Assume the behavior and ask about frequency or other details. For example, “How many cans or bottles of beer did you drink during the past week?” |
• |
Ask respondents to define specific terms used in the items. Be sure to let them know that you are trying to identify unfamiliar words and terms, so “I don’t know” is an appropriate response. |
• |
Use authority to justify the behavior. For example, “Many doctors now think that drinking wine reduces heart attacks. How many glasses of wine did you drink during the past week?” |
To avoid over-reporting of socially desirable behaviors:
• |
Be casual, such as by using the phrase “Did you happen to …?” For example, “Did you happen to watch any public television programs during the past week?” Phrasing the question this way implies that failure to do so is of little importance. |
• |
Justify not doing something; imply that if the respondent did not do something, there was a good reason for the omission. For example, “Many drives report that wearing seat belts is uncomfortable and makes it difficult to reach switches on the dashboard. Thinking about the last time you got into a car—did you use a seat belt?” |
Note: From Sudman and Bradburn (1982).
As you can see, good questions can be difficult to write. This difficulty is one reason why it is usually better to try to find well-validated scales and questions than to create your own. If you must write your own questions, take care to avoid biases such as those described here.
Survey researchers ask questions to obtain answers. As noted earlier, these answers can be either open- or closed-ended. Most survey questions are designed to elicit closed-ended responses. In this section we discuss two issues related to closed-ended responses: levels of measurement and the relative merits of various closed-ended response formats.
Researchers use questionnaires to measure the characteristic of respondents: their attitudes, opinions, evaluations of people and things, their personality traits, and so forth. Measurement consists of applying sets of rules to assign numbers to these characteristics. Several different rules could be applied in any situation. To measure student achievement, for example, the researcher might use any of three rules: (a) Classify students as having either passed or failed, (b) rank order students from best to worst, or (c) assign each student a score (such as 0 through 100) indicating degree of achievement. Each rule provides more information about any particular student than did the preceding rule, moving from which broad category the student is in, to whom the student did better and worse than, to how much better or worse the student did. Because of these increasing amounts of information content, these rules are called levels of measurement (also sometimes referred to as scales of measurement).
Measurement levels. A variable can be measured at any of four levels of information content. From lowest to highest, these levels are called nominal, ordinal, interval, and ratio.Nominal level measurement sorts people or things into categories based on common characteristics. These characteristics represent different aspects of a variable, such as gender or psychiatric diagnosis. As a result, nominal level data are usually reported in terms of frequency counts—the number of cases in each category—or percentage of cases in each category. To facilitate computerized data analysis, the categories are often given numbers (or scores); for example, “female = 1 and male = 2.” These numbers are completely arbitrary. In this example, someone receiving a score of 2 does not have more gender than someone receiving a score of 1; he is only different on this characteristic.
Ordinal level measurement places people or things in a series based on increases or decreases in the magnitude of some variable. In the earlier example, students were arranged in order of proficiency from best to worst, as in class standings. As a result, ordinal level data are usually reported in terms of rankings: who (or what) is first, second, and so forth. Notice that while ordinal level measurement provides comparative information about people, such as “Mary did better than Phil,” it does not quantify the comparison. That is, it does not let you know how much better Mary did. Because of this lack of quantification, one cannot mathematically transform ordinal level data, that is, perform addition, subtraction, multiplication, or division. As a result, most inferential statistics, such as the t test, which are based on these transformations, are usually considered to be inappropriate for use with ordinal level data.
Interval level measurement assigns numbers (scores) to people and things such that the difference between two adjacent scores (such as 1 and 2) is assumed to represent the same difference in the amount of a variable as does the between any other two adjacent scores (such as 3 and 4). In other words, the people using an interval level measure perceive the intervals between scores to be equal. Thus, if Chris scores 5 on a variable measured at the interval level, Mary scores 3, and Phil scores 1, we can say that Mary scored higher than Phil to the same degrees that Chris scored higher than Mary. For this reason, interval level measures are used to most hypothetical constructs, such as personality traits, attitudes, beliefs, psychiatric symptoms, and so forth.
In addition, interval level scores can be added to and subtracted from each other, multiplied and divided by constants, and have constants added to or subtracted from them; they cannot, however, be multiplied or divided by each other. For example, we could not say that Mary’s score was three times higher than Phil’s or that someone with a score of 20 on the Beck (1972) Depression Inventory is twice as depressed as someone with a score of 10. These transformations are impossible because interval level scores lack a true zero point; that is, the variable being measured is never totally absent in an absolute sense. For example, in women’s clothing, there is a size zero. Clearly, everyone has a clothing size; “size 0” is merely an arbitrary designation indicating “extremely small;” it does not indicate the total absence of size. Similarly, someone who wears a size 14 is not twice as big as someone who wears a size 7; such multiplicative comparisons are meaningless on interval-level scales.
Ratio level measurement, like interval level measurement, assigns equal interval scores to people or things. In addition, ratio measures have true zero points, and so can be multiplied and divided by each other. Therefore, it is appropriate to say that a ratio level score of 10 represents twice as much of a variable as does a score of 5. Some ratio level measures used in psychological research include the speed and frequency of behavior, the number of items recalled from a memorized list, and hormone levels. However, most measures of psychological states and traits and of constructs such as attitudes and people’s interpretations of events are interval level at best.
There are at least three reasons why understanding the measurement level of your items is important: it influences the amount of information obtained, it affects which statistical tests are appropriate, and it relates to the ecological validity of your findings. It is important to bear these considerations in mind when choosing a level of measurement.
Information content. Higher level measures contain more information than do lower level measures; they also contain all the information lower levels provide. For example, you could measure people’s heights in feet and inches and make ratio level comparisons, such as Mary is 1.2 times taller than Peter (ratio level); you can also measure height but not make ratio comparisons (interval level). Another option is to use the original measurement to rank people by height (ordinal level) or classify them as short or tall (nominal level). You cannot go the other direction; for example, if you ask people to classify themselves as short or tall, you cannot use this information to estimate actual their heights. As a general rule, you should collect data using the highest level of measurement possible.
TABLE 15.4
Hypothetical Opinion Data
Analyzing these data at the nominal level and at the interval level lead to different conclusions. |
||
|
Group A |
Group B |
Nominal Level Data |
|
|
Favor |
50% |
50% |
Oppose |
50% |
50% |
Interval Level Data |
|
|
Strongly favor |
2 |
16 |
Moderately favor |
2 |
2 |
Slightly favor |
16 |
2 |
Slightly oppose |
2 |
16 |
Moderately oppose |
2 |
2 |
Strongly oppose |
16 |
2 |
This difference in information content has two implications. First, the conclusions you can validly draw on the basis of measures constructed at one level of measurement, such as ratio, would be invalid if drawn on the basis of a lower level of measurement, such as interval. For example, you can say things such as “Group A improved twice as much as Group B” only if a ratio level measure is used. Second, higher level measures tend to be more sensitive to the effects of independent variables than are lower level measures. Consider the following hypothetical example, which uses the data shown in Table 15.4. Researchers conduct a study comparing the opinions of two groups of people (perhaps liberals and conservatives) on a political issue. Members of the groups are asked whether they favor or oppose a particular position on the issue, with the results shown in the top part of Table 15.4. Given this outcome, the researchers would conclude that there is no difference in opinion between the groups: 50% of the people in each group favor the position and 50% oppose it. If, however, the researchers asked people to put their opinions into one of the six categories shown in the bottom part of Table 15.4, with the frequency of response as shown for each category, they can analyze their results as interval level data. They would then conclude that the members of Group B have more favorable opinions than the members of Group A, p = .002. A difference was detected in the second case but not the first because the interval level measure contained more information than the nominal level measure, in this case information about the respondents’ relative degree of favorability toward the issue.
Statistical tests. Assumptions underlie statistical tests. The t-test, for example, assumes that the scores in the two groups being compared are normally distributed. However, nominal level measures are not normally distributed, and ordinal level data frequently are not, and so violate this assumption (as well as others). Therefore, some authorities hold that one can only use statistics that are designed for a particular level of measurement when using data at that level. Other authorities, however, hold that there is no absolute relationship between level of measurement and statistics. See Michell (1986) for a review of this debate.
On a more practical level, statisticians have investigated the extent to which the assumptions underlying a particular statistic can be violated without leading to erroneous conclusions (referred to as the robustness of a statistic). The results of this research indicate that under certain conditions, ordinal and dichotomous (two-value nominal) data can be safely analyzed using parametric statistics such as the t-test and analysis of variance (Davison & Sharma, 1988; Lunney, 1970; Myers, DiCecco, White, & Borden, 1982; Zumbo & Zimmerman, 1993). Before applying parametric statistics to nonparametric data, however, you should carefully check to ensure that your data meet the necessary conditions.
Ecological validity. As we saw in Chapter 8, the issue of ecological validity deals with the extent to which a research setting resembles the natural setting to which the results of the research are to be applied. Ecological validity is related to levels of measurement because the natural level of measurement of a variable may not contain enough information to answer the research question or may not be appropriate to the statistics the researcher wants to use to analyze the data. The researcher then faces a choice between an ecologically valid, but (say) insensitive, measure and an ecologically less valid, but sufficiently sensitive, measure. Consider, for example, research on juror decision making. The natural level of measurement in this instance is nominal: A juror classifies a defendant as guilty or not guilty. A researcher conducting a laboratory experiment on juror decision processes, however, might want a more sensitive measure of perceived guilt and so might ask subjects to rate their belief about how likely or unlikely it is that the defendant is guilty on a 7-point scale (interval level measurement). The researcher has traded off ecological validity (the measurement level that is natural to the situation) to gain sensitivity of measurement. As discussed in Chapter 2, such tradeoffs are a normal part of the research process and so are neither good nor bad per se. However, researchers should make their tradeoffs only after carefully weighing the relative gains and losses resulting from each possible course of action. Sometimes the result of this consideration is the discovery of a middle ground, such as using both nominal and interval level measures of juror decisions.
There are four categories of closed-ended response formats, commonly referred to as rating scales: the comparative, itemized, graphic, and numerical formats. Let’s look at the characteristics of these formats.
Instructions: Listed below are pairs of brand names of automobiles. For each pair, indicate the brand you think is of higher quality by putting an “X” on the line next to its name. Please make one choice in each pair and only one choice per pair; if you think the choices in a pair are about equal, mark the one you think is of higher quality even if the difference is small.

Comparative rating scales. In comparative scaling, respondents are presented with a set of stimuli, such as five brands of automobiles, and are asked to compare them on some characteristic, such as quality. Comparative scaling can be carried out in two ways. With the method of paired comparisons, raters are presented with all possible pairings of the stimuli being rated and are instructed to select the stimulus in each pair that is higher on the characteristic. Box 15.3 shows a hypothetical paired comparisons scale for five brands of automobiles. The score for each stimulus is the number of times it is selected. A major limitation of the method of paired comparisons is that it becomes unwieldy with a large number of stimuli to rate. Notice that with five stimuli, the scale in Box 15.3 had to have 10 pairs; the number of required pairs is n(n - 1)/2, where n is the number of stimuli. Consequently, 20 stimuli would require 190 pairs. With a large number of similar judgments to make, people can become bored and careless in their choices. Although there is no absolute rule about the maximum number of stimuli to use in the method, Crano and Brewer (2002) suggest no more than 10 (resulting in 45 pairs).
One solution to the problem of numerous pairs of stimuli lies in the method of rank order. With this method, respondents are given a list of stimuli and asked to rank them from highest to lowest on some characteristic. However, selecting the proper ranking for each stimulus can be a daunting task for respondents who are faced with a large number of stimuli. One way to simplify the task is to have respondents alternately choose the best and worst stimulus relative to the characteristic being rated. For example, if respondents had to rank 20 colors from the most to least pleasing, you would have them first choose their most and least preferred of the 20 colors, assigning those colors ranks 1 and 20, respectively. You would then have them consider the remaining 18 colors and choose their most and least preferred of those, giving those colors ranks 2 and 19, respectively. The process continues until all colors have been chosen.
Three conditions must be met for comparative scaling to provide reliable and valid results (Crano & Brewer, 2002). First, the respondents must be familiar with all the stimuli they compare. If a respondent is not familiar with a stimulus, the ranking of that stimulus will be random and therefore not reflect where it stands on the characteristic. For example, people who have never driven Fords cannot judge their quality relative to other brands of automobiles. Second, the characteristic on which the stimuli are being rated must be unidimensional; that is, it must have one and only one component. Note that the example in Box 15.3 violates this rule: automobile quality is made up of many components, such as physical appearance, mechanical reliability, seating comfort, the manufacturer’s reputation, and so forth. If a rating characteristic has several components, you have no way of knowing which component any respondent is using as a basis for making ratings. To the extent that different respondents base their ratings on different components, the ratings will be unreliable. This situation is similar to the specificity problem in question phrasing. Finally, the respondents must completely understand the meaning of the characteristic being rated. For example, when rating automobiles on mechanical reliability, each respondent must define reliability in the same way. It is therefore best if the researcher defines the characteristic being rated for the respondents.
Notice that comparative scaling results in data at the ordinal level of measurement. Consequently, the ratings represent relative rather than absolute judgments. That is, a stimulus that raters perceive to be mediocre might be ranked highest because it is better than any of the others despite its low absolute quality: It might be seen as “the best of a bad lot.”
Itemized rating scales.Itemized rating scales are multiple-choice questions: The item stem is in the form of a question, and the respondent chooses an answer from the options the researcher provides. A primary use of itemized scales is for classification—you can ask research participants to classify themselves as to sex, marital status, or any other variable of interest. Itemized scales can also be used to assess hypothetical constructs. Harvey and Brown (1992) present a theory of social influence that postulates five influence styles that every person uses to some degree. The degree to which any person uses each style is assessed with a scale composed of a set of social influence situations; each situation is followed by a set of possible responses to the situation. Each response represents one of the social influence styles. For example,
If I have made a suggestion or proposal and a person reacts negatively to it, I am likely to
a. |
Accept the person’s position and try to reexamine my proposal, realizing that our differences are largely due to our individual ways of looking at things, rather than take the reaction as a personal affront. |
b. |
Suggest the best course of action and make clear the results of not following that course of action. |
c. |
Feel upset about the disagreement but will go along with the other person’s ideas and allow him or her to express ideas fully. |
d. |
Point out the requirements of the situation but avoid becoming involved in fruitless argument. |
e. |
Search for a compromise position that satisfies point of view. |
(Harvey & Brown, 1992, p. 147)
Respondents choose the response most similar to the one they would make in the situation. Respondents’ scores for each style can be calculated as the total number of times that a response indicative of a style was chosen.
Itemized rating scales generally provide data at the nominal level of measurement. The data can become ordinal if choices representing a single characteristic are cumulated across items, as in the Harvey and Brown (1992) example. People can then be ranked on how often they chose the dimension as characteristic of themselves. Itemized rating scales can also provide ordinal level data if the response options are ordered along some dimension; for example,
Put an X on the line next to the phrase that best describes your political orientation:
_____ |
Very conservative |
_____ |
Moderately conservative |
_____ |
Slightly conservative |
_____ |
Slightly liberal |
_____ |
Moderately liberal |
_____ |
Very liberal |
Itemized rating scales must be developed carefully to ensure that all the relevant response options are presented to research participants. Failure to include all options will reduce the validity of the measure in either of two ways. First, respondents may skip the item because it doesn’t include a response option that accurately reflects their viewpoint. For example, when asked to choose from a list of five options the most important thing for children to learn to prepare for life—to obey, to be well liked, to think for themselves, to work hard, and to help others who need help—62% of the respondents to a survey chose “to think for themselves.” However, when another sample of respondents was asked the same question in an open-ended format, “to think for themselves” was mentioned by only 5% of the respondents. It ranked seventh in frequency of being mentioned; none of the first six characteristics mentioned were on the itemized list (Schuman & Presser, 1996). Alternatively, they may choose one of the options in the list even though that option differs from their actual viewpoint because they think they have to choose something, even it is not a completely accurate representation of their viewpoint. An incomplete list of options can also lead to biased research results that confirm old stereotypes rather than provide new knowledge. As Bart (1971) pointed out, allowing women to describe their sexual roles only as “passive,” “responsive,” “aggressive,” “deviant,” or “other” does not allow for responses such as “playful,” “active,” and so forth.
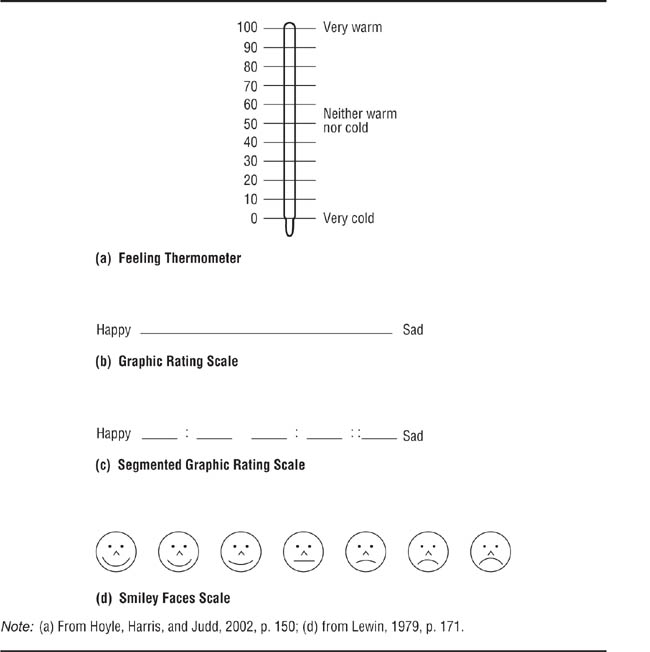
FIGURE 15.1
Examples of Graphic Rating Scales.
Graphic rating scales. With graphic rating scales, (also called visual analog scales), people indicate their responses pictorially rather than by choosing a statement as with itemized rating scales or, as we will see, by choosing a number with numerical rating scales. Figure 15.1 shows some examples of graphic rating scales. With the feeling thermometer—Figure 15.1(a)—respondents rate their evaluations of a stimulus, such as a political candidate, from warm (favorable) to cold (unfavorable); respondents indicate their feelings by drawing a line across the thermometer at the appropriate point. The simple graphic rating scale—Figure 15.1(b)—is used in the same way as the feeling thermometer: The respondent marks the line at the appropriate point. The scale is scored by measuring the distance of the respondent’s mark from one end of the line. The segmented graphic rating scale—Figure 15.1(c)—divides the line into segments; the respondent marks the appropriate segment. This format simplifies scoring because a numerical value can be assigned to each segment. The Smiley Faces Scale, Figure 15.1(d), (Butzin & Anderson, 1973) can be used with children who are too young to understand verbal category labels or how to assign numerical values to concepts. As with the segmented graphic rating scale, the researcher can give each face a numerical value for data analysis.
Indicate your current mood by circling the appropriate number on the following scale:
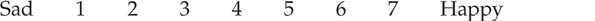
How would you rate your performance on the last test?
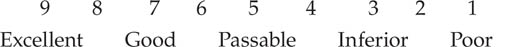
The university should not raise tuition under any circumstances.

Numerical rating scales. With numerical rating scales, respondents assign numerical values to their responses. The meanings of the values are defined by verbal labels called anchors. Box 15.4 shows some hypothetical numerical rating scales. There are three elements to the design of a numerical rating scale: the number of scale points, the placement of the anchors, and the verbal labels used as anchors.
In principle, a numerical rating scale can have from 2 to an infinite number of points. In practice, the upper limit seems to be 101 points (a scale from 0 to 100). Two factors determine the number of points to use on a scale. The first is the required sensitivity of measurement. A sensitive measure can detect small differences in the level of a variable; an insensitive measure can detect only large differences. In general, scales with more rating points are more sensitive than scales with only a few points. More points allow the raters finer gradations of judgment. For example, a 2-point attitude scale that allows only “Agree” and “Disagree” as responses is not very sensitive to differences in attitudes between people—those who agree only slightly are lumped in with those who agree strongly and those who disagree only slightly with those who disagree strongly. If you are studying the relationship between attitudes and behavior, and if people with strongly held attitudes behave differently from people with weakly held attitudes, you will have no way of detecting that difference because people with strongly and weakly held attitudes are assumed to be identical by your scale. In addition, respondents might be reluctant to use a scale they think does not let them respond accurately because there are too few options. People sometimes expand scales that they perceive as being too compressed by marking their responses in the space between two researcher-supplied options.
The second factor related to the number of scale points is the usability of the scale. A very large number of scale points can be counterproductive. Respondents can become overwhelmed with too many scale points and mentally compress the scale to be able to use it effectively. One of us (Whitley) once found, for example, that when he had people respond to a scale ranging from 0 to 100, many compressed it to a 13-point scale using only the 0, 10, 20, 25, 30, 40, 50, 60, 70, 75, 80, 90, and 100 values. Researchers have found that people generally prefer scales that have from 5 to 9 points (Cox, 1980). With fewer than 5 points, people feel they cannot give accurate ratings; with more than 9 points, they feel they are being asked to make impossibly fine distinctions. In addition, although the reliability of a scale increases as points are added from 2 to 7, there is little increase after 7 points (Cicchetti, Showalter, & Tyrer, 1985). A scale of 5 to 9 points is therefore probably optimal.
As Box 15.4 shows, the anchors for a numerical rating scale can be placed only at the end points or at the end and intermediate points. The use of intermediate anchors has two advantages. First, they more clearly define the meaning of the scale for respondents. When anchors are used only at the end points, respondents might be unsure of the meaning of the difference between two points on the scale. From the respondent’s point of view, it can be a question of “What am I saying if I choose a 3 instead of a 4?” Perhaps because of this greater clarity of meaning, numerical rating scales that have anchors at each scale point show higher reliability and validity than scales with other anchoring patterns (Krosnick, 1999b).
The second advantage of intermediate anchors is that, in combination with the proper selection of labels for the anchors, they can increase the level of measurement of the scale. When numerical scales have only end point anchors or have intermediate anchors arbitrarily chosen by the researcher, ordinal level measurement results. There is no basis for assuming that simply because the mathematical differences between the scale points are equal that respondents perceive them as psychologically equal. However, the verbal labels used as anchors can be chosen so that the difference in meaning between any two adjacent anchors is about equal to the difference in meaning between any other two adjacent anchors (Bass, Cascio, & O’Connor, 1974; Spector, 1976, 1992). Table 15.5 shows some approximately equal interval anchors for 5-point scales of agreement—disagreement, evaluation, frequency, and amount. These 5-point scales can be expanded to 9-point scales by providing an unlabeled response option between each pair of labeled options, as shown in the second scale in Box 15.4. Bass et al. (1974) and Spector (1976) list additional anchor labels and their relative scale values.
Which response format is best? The answer to that question depends primarily on the purpose of the rating scale. If the purpose is to determine the relative position of the members of a set of stimuli along a dimension, then a comparative format is best. The method of paired comparisons is better with a small number of stimuli, and ranking is better with a large number of stimuli. If the purpose is to locate an individual or a single stimulus along a dimension, a numerical rating scale with equal interval anchors is probably best because it can provide interval level data. Itemized scales place people and stimuli into specific categories. Despite these differences, the results of stimulus ratings using different formats are highly correlated (Newstead & Arnold, 1989), suggesting that format might not have a large effect on the conclusions drawn about relationships between variables.
Anchors for 5-Point Equal-Appearing Interval Scales of Agreement-Disagreement, Evaluation, Frequency, and Amount
Scale Point |
Agreement-Disagreementa |
Evaluationa |
Frequencya |
Amountb |
1 |
Very much |
Excellent |
Always |
All |
2 |
On the whole |
Good |
Frequently |
An extreme amount |
3 |
Moderately |
Passable |
Sometimes |
Quite a bit |
4 |
Mildly |
Inferior |
Seldom |
Some |
5 |
Slightly |
Terrible |
Never |
None |
aFrom Spector (1992), p. 192
bFrom Bass, Cascio, and O’Connor (1974), p. 319
A multi-item scale is composed of two or more items in rating scale format, each of which is designed to assess the same variable. A respondent’s scores on the items are combined—usually by summing or averaging—to form an overall scale score. A multi-item scale can be composed of two or more multi-item subscales, each of which measures a component of a multidimensional variable. A self-esteem scale, for example, could have subscales for global self-esteem, social self-esteem, academic self-esteem, and so forth. Each subscale would provide a subscale score for the component that it measures. In this section we discuss the advantages of using multi-item scales and describe the four types of these scales.
Multi-item scales have several advantages over single items as measures of hypothetical constructs. First, as just noted, multi-item scales can be designed to assess multiple aspects of a construct. Depending on the research objective and the theory underlying the construct, the subscale scores can be either analyzed separately or combined into an overall scale score for analysis. A second advantage of multi-item scales is that the scale score has greater reliability and validity than does any one of the items of which it is composed. This increased reliability and validity derive from the use of multiple items. Each item assesses both true score on the construct being assessed and error. When multiple items are used, aspects of the true score that are missed by one item can be assessed by another. This situation is analogous to the use of multiple measurement modalities discussed in Chapter 6. Generally speaking, as the number of items on a scale increases, so does the scale’s reliability and validity, if all the items have a reasonable degree of reliability and validity. Adding an invalid or unreliable item decreases the scale’s reliability and validity.
Finally, multi-item scales provide greater sensitivity of measurement than do singleitem scales. Just as increasing the number of points on an item can increase its sensitivity, so can increasing the number of items on a scale. In a sense, multi-item scales provide more categories for classifying people on the variable being measured. A single 9-point item can put people into 9 categories, one for each scale point; a scale composed of five 9-point items has 41 possible categories—possible scores range from 5 to 45—so that finer distinctions can be made among people. This principle of increased sensitivity applies to behavioral measures as well as self-reports. Let’s say that you are conducting a study to determine if a Roman typeface is easier to read than a Gothic typeface. If you asked participants in the research to read just one word printed in each typeface, their responses would probably be so fast that you could not detect a difference if one existed. However, if you had each participant read 25 words printed in each typeface, you might find a difference in the total reading time, which would represent the relative difficulty of reading words printed in the two typefaces.
Multi-item scales can take many forms. In this section we describe four major types: Likert scales, Thurstone scales, Guttman scales, and the semantic differential.
Likert scales.Likert scales are named for their developer, Rensis Likert (pronounced “Lick-urt”). Also known as summated rating scales, they are, perhaps, the most commonly used form of multi-item scale. A Likert scale presents respondents with a set of statements about a person, thing, or concept and has them rate their agreement or disagreement with the statements on a numerical scale that is the same for all the statements. To help control for response biases, half the statements are worded positively and half are worded negatively. Respondents’ scores on a Likert scale are the sums of their item responses. Table 15.6 shows some items from Kite and Deaux’s (1986) Homosexuality Attitude Scale. The numbers in parentheses by the anchors indicate the numerical values assigned to the response options; the plus and minus signs in parentheses after the items indicate the direction of scoring. Items with minus signs are reverse scored; that is, their numerical values are changed so that a high number indicates a higher score on the characteristic being assessed. In the example in Table 15.6, 1 would become 4, 2 would become 3, 3 would remain 3 because it is in the center of the scale, 4 would become 2, and 5 would become 1. Reverse scoring can be accomplished by using the formula R = (H + L) -I, where R is the reversed score, H is the highest numerical value on the scale, L is the lowest value, and I is the item score.
TABLE 15.6
Example of a Likert-Type Scale
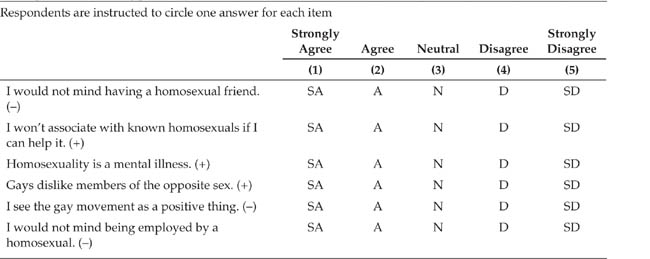
Note: Respondents do not see the information in parentheses. From Kite and Deaux (1986).
As Dawis (1987) notes, the term Likert scale is frequently misused to refer to any numerical rating scale with intermediate anchors. However, Likert scaling is defined by the process by which items are selected for the scale, not by the response format. Only a scale with items that have been selected using the following four steps is a true Likert scale:
1. |
Write a large number of items representing the variable to be measured. The items represent the extremes of the variable, such as high or low self-esteem; moderate levels of the variable will be assessed as low levels of agreement with these extremes. The items have a numerical rating scale response format with intermediate anchors. |
2. |
Administer the items to a large number of respondents. Dawis (1987) suggests at least 100, but some statistical procedures that can be used for item selection, such as factor analysis, require more respondents (recall Chapter 12). Record respondents’ item scores and total scale scores. |
3. |
Conduct an item analysis. This analysis selects the items that best discriminate between high and low scorers on the scale; items that discriminate poorly are thrown out. This procedure ensures the internal consistency of the scale. The criterion for item selection is the item-total correlation: the correlation of the item score with a modified total score; the total score is modified by subtracting the score of the item being analyzed. No item with an item-total correlation below. 30 should be used in the final version of the scale (Robinson, Shaver, & Wrightsman, 1991a). |
4. |
The items with the highest item-total correlations comprise the final scale. There should be a sufficient number of items to provide an internal consistency coefficient of at least. 70 (Robinson et al., 1991a). |
An important assumption underlying Likert scale construction is that the scale is unidimensional; if the scale assesses a multidimensional construct, the assumption is that each subscale is unidimensional. That is, every item on the scale or subscale measures just one construct or just one aspect of a multidimensional construct. When the items on a scale measure more than one aspect of a construct, the meaning of the overall scale score can be ambiguous. Assume, for example, that a self-esteem scale measures both social and academic self-esteem. There are two ways for a respondent to get a middle-range score on the scale: by scoring in the middle on both aspects of self-esteem or by scoring high on one and low on the other. These two types of scores define self-esteem differently; they are not equally valid unless the theory of self-esteem on which the scale is based holds that the distinction between these aspects of self-esteem is unimportant. The number of dimensions represented in a scale can be investigated using factor analysis. Factor analysis of a Likert scale should result in one factor if the items were intended to measure only one construct, or one factor for each aspect of the construct if the items were intended to form subscales measuring different aspects of the construct. DeVellis (2003) presents a detailed description of the development of a Likert scale.
The popularity of the Likert approach to scaling is due to its possessing several desirable features, one or more of which are absent in the other approaches to scaling. First, Likert scales are easy to construct relative to other types of scales. Even though the Likert process has several steps, other processes can be much more laborious. Second, Likert scales tend to have high reliability, not surprising given that internal consistency is the principal selection criterion for the items. Third, Likert scaling is highly flexible. It can be used to scale people on their attitudes, personality characteristics, perceptions of people and things, or almost any other construct of interest. The other scaling techniques are more restricted in the types of variables with which they can be used, as you’ll see in the next two sections. Finally, Likert scaling can assess multidimensional constructs through the use of subscales; the other methods can assess only unidimensional constructs.
Thurstone scales. Louis Thurstone was the first person to apply the principles of scaling to attitudes. Thurstone scaling, like Likert scaling, starts with the generation of a large number of items representing attitudes toward an object. However, these items represent the entire range of attitudes from highly positive through neutral to highly negative, in contrast to Likert items, which represent only the extremes. Working independently of one another, 20 to 30 judges sort the items into 11 categories representing their perceptions of the degree of favorability items express. The judges are also instructed to sort the items so that the difference in favorability between any two adjacent categories is equal to that of any other two adjacent categories; that is, they use an interval-level sorting procedure. The items used in the final scale must meet two criteria: (a) They must represent the entire range of attitudes, and (b) they must have very low variance in their judged favorability. Respondents are presented with a list of the items in random order and asked to check off those they agree with; they do not see the favorability ratings. Respondents’ scores are the means of the favorability ratings of the items they chose. Sample items from one of Thurstone’s (1929) original attitude scales are shown in Table 15.7 along with their scale values (favorability ratings).
TABLE 15.7
Example of a Thurstone Scale
Scale Value |
Item |
1.2 |
I believe the church is a powerful agency for promoting both individual and social righteousness. |
2.2 |
I like to go to church because I get something worthwhile to think about and it keeps my mind filled with right thoughts. |
3.3 |
I enjoy my church because there is a spirit of friendliness there. |
4.5 |
I believe in what the church teaches but with mental reservations. |
6.7 |
I believe in sincerity and goodness without any church ceremonies. |
7.5 |
I think too much money is being spent on the church for the benefit that is being derived. |
9.2 |
I think the church tries to impose a lot of worn-out dogmas and medieval superstitions. |
10.4 |
The church represents shallowness, hypocrisy, and prejudice. |
11.0 |
I think the church is a parasite on society |
Note: |
On the actual questionnaire, the items would appear in random order and the scale would not be shown. From Thurstone (1929). |
Bogardus (1925) Social Distance Scale
Directions: For each race or nationality listed, circle the numbers representing each classifi cation to which you would be willing to admit the average member of that race or nationality (not the best members you have known nor the worst). Answer in terms of your first feelings or reaction.
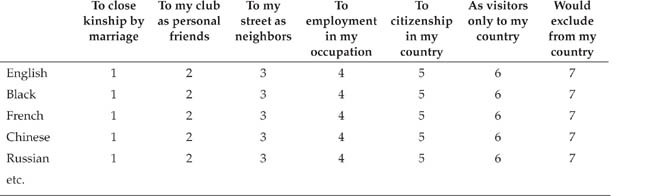
Note: Adapted from Bogardus (1925), p. 301.
Thurstone scales are rarely seen today, primarily because of their disadvantages relative to Likert scales. Thurstone scales are more laborious to construct than Likert scales and they tend to produce less reliable scores than Likert scales of the same length (Tittle & Hill, 1967). In addition, Thurstone scaling assumes that the attitude being assessed is unidimensional; the technique provides no way of to set up subscales for different aspects of an attitudes. A third limitation inherent in Thurstone scaling is that the judges’ attitudes influence their assignment of scale values to items (Hovland & Sherif, 1952): People rate statements that are close to their own opinions more favorably than divergent opinions, despite instructions to “be objective.” It is therefore essential that judges represent a cross-section of opinions on the attitude being scaled. Finally, the scale values that judges assign to items can change over time; Dawes (1972), for example, found some significant changes in the rated severity of crimes from 1927 to 1966. Such changes limit the “reusability” of Thurstone scales.
Guttman scales. With a Guttman scale (named for Louis Guttman, who developed the theory underlying the technique), respondents are presented with a set of ordered attitude items designed so that a respondent will agree with all items up to a point and disagree with all items after that point. The last item with which a respondent agrees represents the attitude score. The classic example of a Guttman scale is the Bogardus (1925) Social Distance Scale, a measure of prejudice, part of which is shown in Table 15.8. On the Social Distance Scale, acceptance of a group at any one distance (such as “To my street as neighbors”) implies acceptance of the group at greater distances; the greater the minimum acceptable social distance, the greater the prejudice. Behaviors can also be Guttman scaled if they represent a stepwise sequence, with one behavior always coming before the next; DeLamater and MacCorquodale (1979), for example, developed a Guttman scale of sexual experience. Guttman scaling is rarely used because few variables can be represented as a stepwise progression through a series of behaviors or beliefs.
The semantic differential. The semantic differential (Osgood, Suci, & Tannenbaum, 1957) is a scale rather than a scaling technique, but is widely used because of its flexibility and so deserves discussion. In their research on the psychological meanings of words (as opposed to their dictionary definitions), Osgood et al. found that any concept could be described in terms of three dimensions: evaluation, representing the perceived goodness or badness of the concept; activity, represented whether the concept is perceived as active or passive; and potency, representing the perceived strength or weakness of the concept. A concept’s standing on each dimension is assessed by having respondents rate the concept on sets of bipolar adjective pairs such as good-bad, active-passive, and strong-weak. Because it represents one aspect of attitudes, evaluation tends to be the most commonly used rating dimension, and the scale takes the form of a set of segmented graphic rating scales; for example:
My voting in the forthcoming election is

(Ajzen & Fishbein, 1980, p. 55)
Each item is scored on a 7-point scale, usually ranging from +3 to -3, and respondents’ scale scores are the sums of their item scores. Notice that the items are balanced so that the positive adjective of each pair is on the right half the time; these items must therefore be reverse scored.
The semantic differential represents a ready-made scale that researchers can use to measure attitudes toward almost anything and so can bypass the item selection state of scale development. Its validity has been supported by more than 50 years of research. However, great care must be taken to ensure that the adjective pairs one chooses for scale items are relevant to the concept being assessed. For example, although foolish-wise is relevant to the evaluation of a person, behavior, or concept, it would be much less relevant to the evaluation of a thing, such as an automobile. Osgood et al. (1957) list a large variety of adjective pairs from which one can choose. Finally, Ajzen and Fishbein (1980) warn that many scales used in research are incorrectly called semantic differential scales. Although these scales use the semantic differential format, they consist of arbitrarily chosen adjective pairs rather than pairs that have been demonstrated to represent the rating dimension. Such scales are of unknown validity.
A response bias exists when a person responds to an item for reasons other than the response’s being a reflection of the construct or behavior being assessed by the content of the item. Response biases obscure a person’s true score on a measure and therefore represent a form of measurement error; better measures are less affected by response biases. Response biases can be categorized in two ways. Question-related biases are caused by the ways in which questions or response options are worded; person-related biases result from respondent characteristics.
The earlier section of this chapter that discussed question wording described some of the ways in which question stems can bias responses. This section describes four types of response bias that can result from item response options: scale ambiguity effects, category anchoring, estimation biases, and respondent interpretations of numerical scales.
Scale ambiguity. Problems with scale ambiguity can occur when using numerical or graphic rating scales to assess frequency or amount. Anchor labels such as “frequently” or “an extreme amount of” can have different meanings to different people. Consider the following hypothetical question:
How much beer did you drink last weekend?
5 |
4 |
3 |
2 |
1 |
A great amount |
Quite a bit |
A moderate amount |
A little |
None |
People evaluate frequency and amount relative to a personal standard (Newstead & Collis, 1987): To some people, one can of beer in a weekend might be a moderate amount and six cans of beer in a weekend a great amount; to another person, six cans might be moderate and one can a little. One possible solution to this problem is to use an ordered itemized scale, such as
How much beer did you drink last weekend?
_____ |
None |
_____ |
1 or 2 cans |
_____ |
3 to 6 cans |
_____ |
7 to 12 cans |
_____ |
12 to 24 cans |
_____ |
More than 24 cans |
Although using this response format can resolve some of the problems associated with the measurement of frequency and amount, it can lead to another form of response bias, category anchoring.
Category anchoring.Category anchoring occurs when respondents use the amounts provided in the response options as cues for what constitutes an appropriate response, based on the range of values on the scale. Schwarz (1999) distinguishes between two types of itemized scales. Low-range scales start at zero or a very low value and increase until reaching a “greater than” value, such as in a question that asks how many hours of television a person watches per day and provides response options that start at “Up to ½ hour” and increase in half-hour increments to more than 2½ hours.” High-range scales start at a higher value and increase until reaching a “greater than” value, such as in a television-watching question that provides response options that start at “Up to 2½ hours” and increases in half-hour increments to “More than 4½ hours.” Scales such as these are problematic because people tend to give lower responses with low-range scales and high responses with high-range scales. For example, Schwarz, Hippler, Deutsch, and Strack (1985) found that 30½ of respondents using the high-range scale just described reported watching more than 2½ hours of television per day, whereas none of the respondents using the low-range scale did. In comparison, 19% of people responding to an open-ended version of the question reported watching more than 2½ hours of television each day.
Another problem that can arise is that people see an option phrased in terms of “more than” a certain amount as representing an excessive amount and that endorsing it will make them look bad (Sudman & Bradburn, 1982). Finally, respondents may use the scale range to interpret the question stem, assuming that questions using low-range scales refer to events that happen rarely and that questions using low-range scales refer to events that happen frequently (Schwarz, 1999). For example, Schwarz, Strack, Müller, and Chassein (1988) found that people who were asked to report the frequency of irritating events assumed the question referred to major irritants when responding on low-range scales, whereas people responding on high-range scales assumed the question referred to minor irritants. Schwarz (1999) recommends using open-ended questions to assess frequency and amount as a solution for both of these problems.
Estimation biases. Open-ended questions asking for frequency and amount have their own problem. Unless the behavior being assessed is well represented in people’s memory, they will estimate how often something occurs rather than counting specific instances of the behavior. A problem can occur because memory decays over time, making long-term estimates less accurate than short-term estimates. It is therefore advisable to keep estimation periods as short as possible (Sudman et al., 1996). In addition, members of different groups may use different estimation techniques, leading to the appearance of group differences where none may exist. For example, men report a larger number of lifetime opposite-sex sexual partners than do women even though the numbers should be about the same (Brown & Sinclair, 1999). Brown and Sinclair found the difference resulted from men and women using different techniques to recall the number of sexual partners: Women generally thought back and counted the number of partners they had had whereas men tended to just make rough estimates. When this difference in recall method was controlled, Brown and Sinclair found that there was no sex difference in the reported number of partners.
Respondent interpretation of numeric scales. As Box 15.4 shows, scale values can be either all positive numbers or a combination of positive and negative numbers. Just as respondents can use the range of itemized response categories to interpret the question, they can use the range of values on a numerical rating scale in the same way. For example, when people rated how successful they were in life, 34% responding on a -5 to +5 scale chose a value in the lower part of the scale range (-5 to 0), whereas only 13% of those responding on a 0 to 10 scale chose a value in the lower part of the scale range (0 to +5; Schwarz, 1999). Schwarz explains that
this difference reflects differential interpretations of the term “not at all successful.” When this label was combined with the numeric value “0,” respondents interpreted it to reflect the absence of outstanding achievements. However, when the same label was combined with the numeric value “-5,” and the scale offered “0” as the midpoint, they interpreted it to reflect the presence of explicit failures… In general, a format that ranges from negative to positive numbers conveys that the researcher has a bipolar dimension in mind, where the two poles refer to the presence of opposite attributes. In contrast, a format that uses only positive numbers conveys that the researcher has a unipolar dimension in mind, referring to different degrees of the same attribute. (p. 96)
Therefore, be certain of which meaning you want to convey when choosing a value range for a numerical rating scale.
Person-related response biases reflect individuals’ tendency to respond in a biased manner. There are five classes of person-related response biases: social desirability, acquiescence, extremity, halo, and leniency (Paulhus, 1991).
Social desirability.Social desirability response bias, the most thoroughly studied form of response bias, is a tendency to respond in a way that makes the respondent look good (socially desirable) to others (Tourangeau & Yan, 2007). Paulhus (1991) has identified two forms of social desirability response bias. Self-deceptive positivity is “an honest but overly positive self-presentation” (p. 21). That is, some people respond in ways that put them in a more positive light than is warranted by their true scores on the construct, but they do so unknowingly, believing the overly positive responses to be true. However, impression management is “self-presentation tailored to an audience”; that is, some people “purposely tailor their answers to create the most positive social image” (p. 21). Self-deceptive positivity is an aspect of personality and so is consistent across time and situations, whereas the type and amount of impression management that people engage in vary with the demands of the situation and the content of the measure. For example, people are more likely to try to “look good” during an interview for a job they really want than during an interview for a less desirable job. This distinction between the two forms of social desirability response bias has an important implication for measurement.
Paulhus (1991) notes that self-deceptive positivity is a component of some personality traits such as self-esteem and achievement motivation. Consequently, measures of such constructs should not be totally free of self-deceptive positivity; such a measure would not be fully representative of the construct. However, most measures should be free of impression management bias; the exceptions, of course, are measures of impression management or of constructs, such as self-monitoring (Snyder, 1986), that have an impression management component.
Because social desirability response bias is caused by motivation to make a good impression on others, the bias is reduced when such motivation is low. For example, people are more likely to exhibit social desirability response bias when making a good impression is important. Thus, Wilkerson, Nagao, and Martin (2003) found that people made more socially desirable responses when completing an employment screening survey than when completing a consumer survey. In addition, collecting data in ways that make respondents anonymous, such as by using anonymous questionnaires (Tourangeau & Yan, 2007) and not having an experimenter present when respondents are completing a questionnaire (Evans, Garcia, Garcia, & Baron, 2003), is effective in controlling social desirability response bias.
An Example of Acquiescence Response Bias
Question Form |
Percent Agreeing |
Individuals are more to blame than social conditions from crime and lawlessness in this country. |
59.5 |
Social conditions are more to blame than individuals from crime and lawlessness in this country. |
56.8 |
Note: From Schuman and Presser (1996).
Acquiescence. Acquiescence response bias is a general tendency to agree or disagree with statements, such as items on a self-report measure. People who show a tendency to agree are called “yea-sayers” and those who show a tendency to disagree are called “nay-sayers.” Although acquiescence response bias includes the tendency to disagrees, it is named after acquiescence, or agreement, because that aspect has received the most attention. For example, respondents to a survey answered one of two versions of a question about their perceptions of the cause of crime: whether it is caused by individual characteristics (such as personality) or by social conditions. As Table 15.9 shows, respondents tended to agree with the statements regardless of which causes was mentioned.
Acquiescence is a problem because it can make the meaning of scores on a measure ambiguous. For example, assume that a measure assesses anxiety by asking people whether they have experienced certain symptoms; respondents answer yes or no to each question. If someone gets a high score (that is, gives a large proportion of yes responses), does the score indicate a high level of anxiety or a yea-saying bias?
Acquiescence response bias is more likely to manifest itself when people lack the skill or motivation to think about answers, when a great deal of thought is required to answer a question, and when respondents are unsure about how to respond and so consistently agree or disagree as a way of resolving the uncertainty (Krosnick, 1999a). Writing questions that are clear and easy to answer will therefore help to reduce acquiescence response bias. Because acquiescence response bias has its strongest impact on dichotomous (yes/no or agree/disagree) questions, the use of other types of response formats will also help to alleviate its effects (Krosnick, 1999a).
The most common way of controlling for acquiescence response bias is through the use of a balanced measure. In a balanced measure, on half the items agreement leads to a higher score (called “positive items”) and on half the items disagreement leads to a higher score (“negative items”). For example, an interpersonal dominance scale could include items such as “I frequently try to get my way with other people” and “I frequently give in to other people.” Because agreement with one type of item leads to a higher score and agreement with the other type of item leads to a lower score, the effect of acquiescence on positive items will be balanced by its effect on the negative items. However, writing balanced questions can be difficult because questions intended to have opposite meanings may not be interpreted that way by respondents. Consider, for example, the questions shown in Table 15.10. Both questions assess respondents’ attitudes toward public speeches in favor of communism. They are also balanced in that the first question asks whether such speeches should be forbidden and the second asks whether they should be allowed. However, more people endorsed not forbidding the speeches than endorsed allowing the speeches.
An Illustration of the Difficulty of Writing Balanced Questions
Question Form |
Percent in Favor of Speeches |
Do you think the United States should forbid public speeches in favor of communism? |
60.1 |
Do you think the United States should allow public speeches in favor of communism? |
43.8 |
Note: From Schuman and Presser (1996).
Extremity.Extremity response bias is the tendency to give extreme responses on a measure; for example, to use only the end points (1s and 7s) on a 7-point scale. Extremity response bias is primarily a function of the respondent rather than of an interaction of respondent and scale characteristics, as are social desirability and acquiescence, so it is difficult to establish controls for it. However, an understanding of extremity response bias is important for interpreting the results of research because, as we will discuss shortly, there is evidence that the members of some groups of people are more likely to use the end points of rating scales than are members of other groups.
Halo and leniency. A halo bias occurs when a respondent sees a stimulus as being positive or negative on some important characteristic and that evaluation influences ratings of other characteristics (Cooper, 1981). For example, a physically attractive person might be judged as more intelligent than is actually the case. The halo bias will have the greatest effect when the characteristic being rated is not easily observable, not clearly defined for the respondent, involves relations with other people, or is of some moral importance (Rosenthal & Rosnow, 2008). Leniency bias, related to halo bias, occurs when respondents overestimate the positive characteristics and underestimate the negative characteristics of people (or other stimuli) whom they like.
A cultural response set is “a cultural tendency to respond in a certain way on tests or response scales” (Matsumoto, 2000, p. 33). Cultural response sets are an important consideration in cross-cultural research and research that compares members of social groups because “data obtained from any culture [or group] may be just as reflective of response sets as of the underlying tendency the research is trying to measure” (Matsumoto, 2000, p. 33). That is, cultural response sets are a form of measurement confound or systematic error (recall Chapter 6): observed scores consist of both the true score plus the effect of the response set. For example, if members of Group A exhibit a stronger extremity response bias than members of Group B, even if the true group means are identical, the observed mean for Group A may differ from that for Group B because of the effect of the extremity bias.
There has not been a lot of research on cultural response sets, but researchers have identified a few. One such response set involves social desirability response bias. For example, Lalwani, Shavitt, and Johnson (2006) found that European American college students scored higher on the self-deceptive positivity component of social desirability response bias than did Korean American and Singaporean college students, whereas members of the latter two groups scored higher on impression management. In addition, Matsumoto (2006) found that differences between Japanese and American college students’ self-reports of culturally valued characteristics were greatly reduced when socially desirable responding was controlled statistically.
Cultural and social group differences have also been found on extremity response bias. For example, Black and Hispanic Americans tend to make give extreme responses than White Americans (Bachman & O’Malley, 1984; Clarke, 2000), and older and less well-educated respondents tend to give more extreme responses than younger and better-educated respondents (Greenleaf, 1992). In addition, Van Herk, Poortinga, and Verhallen (2004) found that people in southern European countries exhibited more extremity and acquiescence response bias than people from northern European countries. More generally, extremity response bias seems to appear more often and acquiescence response bias less often in cultures that place a high value on traits such as masculinity, power, and status (Johnson, Kulesa, Cho, & Shavitt, 2005). However, previously identified gender differences in extreme responding (Hamilton, 1968) appear to have disappeared (Bachman & O’Malley, 1984; Greenleaf, 1992).
Cultural response bias can also result from the reference group effect. This phenomenon occurs when people rate where they stand on a characteristic relative to the average of their group or culture (Heine, Lehman, Peng, & Greenholtz, 2002). Consider, to use Heine and colleagues’ example, height in two cultures. Assume that the average height of men is 5 feet 8 inches (173 cm) in Culture A and 6 feet (183 cm) in Culture B. A man who is 5 feet 10 inches (178 cm) in height would rate himself as tall if a member of Culture A but as short if a member of Culture B. The reference group effect can also hide group differences: If people see themselves as being at the reference group mean on a characteristic, they will score themselves as “average” on a rating scale. However, even if Group A has a higher average on the characteristic than Group B, members of both groups will give themselves the same score—average—thereby obscuring any group differences. As Heine and colleagues (2002) note, “It is hard to make sense of the finding that 35-year olds rate themselves to be as healthy as do 80-year olds (Nilsson et al., 1997) without invoking the reference group effect” (p. 914).
Cultural response sets may also exist for other response biases. Therefore, differences between groups on rating scale measures may be a result of response sets (that is, differences in the use of the scale) rather than differences on the constructs, especially when there is no a priori reason to expect differences. Conversely, no-difference findings may be the result of response sets, especially when there is an a priori reason to expect differences.
Because of these biases and other factors, when interpreting the ratings made by respondents it is important to avoid what Dawes and Smith (1985) call the literal interpretationfallacy. This fallacy consists of taking the meanings of scale anchors at face value. Scale anchors, even interval-scaled anchors, are simply markers that help respondents find an appropriate point at which to mark the scale; they have no inherent meaning. For example, consider a situation in which respondents are asked to rate an automobile using one of five terms—excellent, very good, good, poor, very poor—but the true opinion of some respondents is that “fair” best describes a particular model. Because “fair” is not an option, respondents with leniency biases might choose good as their response because they are unwilling to go any lower. Other respondents might choose good because that option is the closest to their true opinion. In neither case is the chosen response a literal representation of the respondents’ beliefs.
Once the questions for a survey have been written, they are compiled into questionnaires, lists of questions that the respondents to the survey will be asked to answer. Questionnaire construction is a very complex process of which only a brief overview can be given here. Before designing your own questionnaire, you should carefully read some books on survey research, such as those by Dillman, Smyth, and Christian (2009) and Bradburn et al. (2004), which extensively discuss questionnaire design. This section looks at some issues concerning question order, the layout of questionnaires, questionnaire instructions, and the use of existing measures in questionnaires.
The order in which questions appear in a questionnaire is very important for two reasons. First, a poorly organized questionnaire will confuse respondents and lower their motivation, resulting in low completion rates. Second, the order in which questions are presented can affect people’s responses to them.
Question sequencing. The clarity of a questionnaire can be enhanced by careful sequencing of questions. It should start out with questions that are easy to answer, but that are also interesting to the respondents, clearly important, and clearly related to the stated purpose of the research. Consequently, although demographic questions such as those concerning sex, age, education, and so forth are easy to answer, they may not be perceived to be interesting, important, or relevant, and so should be placed at the end. The main questions should be grouped by topic. Providing respondents with homogeneous groups of questions keeps them focused on the topic at hand and enhances recall. There must also be clear transitions between topics so that respondents can refocus their attention properly, and the transition should emphasize the relevance of the new topic to reinforce respondents’ motivation.
Within a topic, questions should move from the general to the specific. For example, a set of questions dealing with job satisfaction should start out by asking respondents about their overall level of satisfaction and then ask about specific areas of satisfaction, such as satisfaction with pay, supervisors, working conditions, and so forth. Respondents tend to perceive general questions as being more relevant to the purpose of the research (which is usually expressed in general terms); general questions are also easier to answer and provide a context for the more specific questions.
Question order becomes an especially difficult issue when order is contingent on the answer to a question. For example, a lead-in question might be “Did you drink any alcoholic beverages during the past week?” Respondents who answer yes then go on to one set of follow-up questions, whereas those who answer no go on to a different set of follow-up questions. In such cases, instructions must make very clear what the respondent is to do next. For example, if the lead-in question was Number 21, the instructions might be “If you answered YES to Question 21, go on with Question 22. If you answered NO to Question 21, skip ahead to Question 31 on page 8.” Using differently colored pages can also aid respondents and interviewers in finding the correct question to answer next; for example, the instructions just given could end, “on page 8 (the green page).” Structure contingent questions so that respondents always move forward in the questionnaire; moving back and forth can be confusing.
Context effects. A context effect occurs when responding to one question affects the response to a later question. For example, Schuman and Presser (1996) found that 61% of respondents answered yes to this question when it was used as a lead-in question for the topic of abortion: “Do you think it should be possible for a pregnant woman to obtain a legal abortion if she is married and does not want any more children?” However, when that question followed a more specific one about abortion in the case of a child who was likely to be born with a birth defect (to which 84% of the respondents said yes), only 48% said yes to the more general question.
Sudman et al. (1996) note that context effects are often unavoidable because using context to interpret meanings is an integral part of everyday conversational processes, and a questionnaire is a type of conversation between the researcher and the respondent. A number of factors influence the strength of context effects, including the content and number of preceding questions, the specificity of the question being asked, and the content of instructions and other information (such as that on a consent form) given to respondents. If there is reason to suspect that context might affect some questions, it is a good practice to pretest several versions of the questionnaire using different question orders. The order producing the least variation in response can then be used in the final version of the questionnaire. See Sudman et al. (1996) for a complete discussion of context effects.
The physical layout of a questionnaire and its questions can enhance the ease with which respondents can use it. Here are a few guidelines drawn from several sources (Bradburn et al., 2004; Dillman, Smyth, & Christian, 2009; Fowler, 1988). These issues apply to both online surveys and to paper and pencil surveys; however, we note below some special considerations for internet surveys.
The instructions that come with a questionnaire, whether it is self-administered or interviewer administered, affect the validity of the data. Instructions that are confusing or hard to follow will result in errors and lead people to abandon the task. Babbie (1990) divides the instructions used in questionnaires into three categories. General instructions tell respondents how to answer the questions. They explain the response formats and scales used in self-administered questionnaires, and tell people how to answer open-ended questions. For example, should a response be brief or lengthy? Introductions to topics explain the topic areas to respondents and tie the topics into the overall purpose of the research. These introductions can function as transitions between topics, focusing respondents’ attention on the new topic. Specific instructions introduce questions that use a different response format than the one explained in the general instructions. For example, a question might ask respondents to make rankings rather than ratings or to use a matrix rather than a vertical response layout. Instructions should use repetition and examples to enhance respondents’ understanding of the task. At a minimum, give an example of how to use each response format. As in other research, pilot studies are crucial in survey research for identifying and fixing problems with procedures and materials.
When writing instructions, it is important to avoid phrasing them in ways that might bias participants’ responses. For example, Gomez and Trierweiler (2001) had African American college students complete a questionnaire about their classroom experiences. The questionnaire included items about a variety of types of experiences, including being avoided by others, being disrespected by others, and being treated as if they needed help with the academic work. Half the students received a questionnaire entitled “Everyday Experiences” followed by “Here are some questions about school and the classroom environment” (p. 632). The other students received a questionnaire entitled “Racial Discrimination” followed by “In this study, we are interested in the everyday experience of RACISM AND RACE DISCRIMINATION for college students on this campus” (p. 632; emphasis in original). Participants who received the discrimination instructions reported higher levels of perceived disrespect than those who received the everyday experiences instructions (there were no differences for the other categories). Gomez and Trierweiler suggested that the difference may have occurred because the discrimination instructions led participants to think of and report instances of past discrimination that they might not otherwise have thought of. Thus, even what might appear to be minor differences in the wording of instructions can bias participants’ responses to the items on a questionnaire.
Frequently, questionnaires are composed entirely or in part of existing measures, such as personality inventories, attitude scales, or questions from other surveys. Using existing measures rather than creating your own is usually a good idea for several reasons: The degrees of reliability and validity of existing measures are already known, using measures that other researchers have used makes it easier for you to compare your results with those of previous research, and the process of developing a reliable and valid new measure is long and arduous. However, when combining existing measures into a single questionnaire, two issues become important: the response format to use and the possibility of context effects.
Response formats. Different measures are likely to use different response formats. For example, some will use 5-point scales and others will use 11-point scales; some will have anchors only at the end points, others will have anchors at each scale point (recall Box 15.4). These differences create a dilemma: On the one hand, each measure was validated using its own response format, making the response format an integral part of the measure; on the other hand, using multiple response formats in one questionnaire is likely to confuse respondents and cause them to make erroneous responses. This problem is especially severe when, for example, one attitude measure uses higher numbers to indicate agreement with item stems and another measure uses higher numbers to indicate disagreement. In such circumstances it is best to use a single response format for all items regardless of their source. This procedure will minimize confusion for respondents, thereby reducing errors in the data, and will have little impact on the validity of scores on the measures. As noted earlier, scores using different response formats for a measure are highly correlated (Newstead & Arnold, 1989).
Context effects. As we have seen, instructions can influence participants’ responses to the items on a questionnaire and one item can influence the responses to other items. Not surprisingly, then, completing one measure can influence scores on another measure. These mutual influences can lead to spurious correlations between the measures. For example, Council and his colleagues (reported in Council, 1993) have found that a correlation between reported childhood trauma, such as sexual abuse, and adult symptoms of psychopathology emerges when the trauma survey is completed before the symptom survey but not when the symptom survey is completed first. Council (1993) concluded that “presenting the trauma survey first would prime memories of victimization and lead to increased symptom reporting” (p. 32). Council also cites research that shows that context effects can reduce correlations between measures.
These kinds of context effects occur when research participants fill out two (or more) questionnaires they believe are related to one another, such as when the questionnaires are presented as part of the same study. Therefore, one way to prevent context effects is to keep research participants unaware that the questionnaires are related until they have completed both. This separation of the questionnaires can be accomplished by having two data collection sessions, one for each questionnaire, that the respondents think are part of different studies. Another approach is to have participants complete both questionnaires in the same session, but to psychologically separate the questionnaires by presenting them as belonging to different studies but being administered at one time for the sake of convenience. The independence of the questionnaires can be reinforced by having respondents complete separate consent forms for each. Because both of these procedures involve deception, participants must be thoroughly debriefed after all the data have been collected.
A third possible control measure is to counterbalance the order of presentation of questionnaires administered in the same session: Half the participants complete one measure first, and the other half complete the other measure first. The researcher can then compare the correlation between the measures completed in one order with the correlation found when the measures are completed in the other order. If the correlations are equivalent, context effects are unlikely to be a problem; significantly different correlations would indicate a context effect. However, as with the counterbalancing of more than two conditions in a within-subjects experiment (recall Chapter 9), counterbalancing more than two measures in a questionnaire is exceedingly difficult. Therefore, a final control measure is to randomly intermix the items from each measure when compiling the questionnaire. However, this procedure complicates the scoring of the measures because items from a given measure will not be adjacent to one another. There is no one best method for dealing with inter-measure context effects, but you should always take steps to control them.
Once a questionnaire has been constructed, it must be administered to respondents. This section describes the ways in which survey data can be collected and compares their relative advantages and disadvantages.
Several methods can be used to collect survey data: group administration, mail surveys, Internet surveys, personal interviews, and telephone interviews. This section outlines the principal advantages and disadvantages of each method and the following section compares the methods.
Group administration. In the group administration method, as the name implies, respondents are brought together in one or more groups to complete a survey. This method is best suited for research situations in which the respondents are a “captive audience,” such as in research using college student participants or in surveys of organizations whose members are co-located, such as the employees of a company.
Compared to the other methods, the use of group-administered survey is inexpensive, the main cost being the reproduction of the questionnaires. This cost can be lowered by using computer software to present the questions and record responses. Because people participate in groups, data collection is fast relative to methods that require individual data collection, such as personal interviews. Group-administered surveys also usually have a high response rate, with almost 100% of all respondents completing the questionnaires. Responses to group-administered questionnaires can be completely anonymous, which can be of great importance in some situations.
With written questionnaires, there is no room for interviewer bias, the people administering the questionnaire need only minimal training, and it is easy to supervise them during data collection. The questionnaire itself can be fairly long, but one should be careful not to induce boredom or fatigue in respondents by asking them to answer a very large number of questions. In addition, you can control the setting in which the questionnaire is administered, minimizing the possibility of distractions. You can also control the order in which respondents answer questions by dividing the questionnaire into sections and having respondents submit one section before receiving the next. Unlike telephone surveys, you can use visual aids, but only those that can be easily explained and responded to in writing. Computer-administered questionnaires can also include audio and video components.
A major drawback of group-administered surveys is that it can be difficult to motivate respondents to answer the questions fully and correctly. For example, there is no way of preventing people from skipping questions. Motivation may be especially problematic with coerced respondent samples such as college students recruited from subject pools. The problem is compounded in the group setting because complete anonymity facilitates random responding and may contribute to a lackadaisical attitude toward the task. Even with well-motivated respondents, it is impossible to probe inadequate responses, and the group situation might inhibit people from asking for clarification of questions lest they appear foolish in front of the group. Because it is usually impossible to bring randomly selected respondents together for the group administration of a questionnaire, this method almost always uses a convenience sample with its attendant problem of low representativeness. However, you can use random sampling when surveying members of organizations. Finally, and very importantly for some forms of research, the validity of the data is totally dependent on the respondents’ reading and writing ability.
Mail Surveys. In this age of electronic communication it is tempting to dismiss sending questionnaires via postal mail as an anachronism. However, Dillman, Smyth, and Christian (2009) give several reasons why mail questionnaires are still relevant, including the fact that not everyone has access to the Internet, not everyone who does have access likes electronic surveys, and that it is easy to include incentives with mail surveys, such as a small gift, to motivate people to respond. It is therefore likely that despite having some drawbacks as well as advantages, mail surveys will continue to be used.
Mail surveys are most useful when the researcher has a list of valid addresses for the people to be surveyed. They are therefore frequently used for surveys of members of organizations whose members are geographically dispersed, such as professional associations. Mail questionnaires can also be used for surveys of the general public, using telephone directories or city directories as sources of names and addresses. However, the U. S. Postal Service will not deliver mail to apartment residents unless the apartment number is shown as part of the address. Because telephone directories generally do not provide apartment numbers, using them as sources of addresses might result in a high rate of undelivered surveys.
As with group-administered surveys, there can be no interviewer bias effects on the responses to mail surveys and the respondents can have complete anonymity. Mail surveys can also include visual aids, but again only those that can be explained and responded to in writing. There is, of course, no need to train or supervise interviewers. However, mail surveys can be relatively expensive given the costs of printing, postage (for both sending the questionnaire and a pre-paid return envelope), and overhead such as entering the responses from returned questionnaires into a database.
There is, of course, no way for the researcher to ask for clarification of responses unless respondents give up their anonymity and provide a telephone number. Similarly, there is no way for respondents to ask for clarification unless the researcher provides a telephone number. The researcher cannot control the order in which respondents answer the questions or the setting in which they answer them. For example, there is no way to know whether the response to an opinion question represents only the respondent’s view on the issue or if the respondent consulted with someone else, such as his or her spouse, before answering. Mail survey research also requires a fairly long time to complete because the questionnaire may sit on a respondent’s table for days or weeks before being filled out. Finally, like group-administered questionnaires, mailed questionnaires are totally dependent on the respondents’ reading and writing abilities.
A potential shortcoming of mail surveys is their relatively low response rate: An average of 47% of the people who receive mailed questionnaires return them, compared to an average of 82% of people approached who consent to personal interviews, and 72% of those who consent to telephone interviews (Yu & Cooper, 1983). Low response rates can threaten the validity of the research because the people who do return questionnaires might not be representative of the initial sample. The low return rate probably derives from recipients’ having little motivation to complete the questionnaires, although Dillman, Smyth, and Christian (2009) suggest that proper design of both the questionnaire and cover letter can enhance motivation; Box 15.5 shows some of their suggestions. However, some of the more effective techniques—such as notifying respondents in advance that they will be asked to take part in a survey, including money or coupons as incentives, and sending follow-up requests to people who do not respond initially—can increase the cost of the survey. Personally addressing the envelope and cover letter is also helpful, indicating a special interest in the addressee’s response. However, be very careful if you use a computerized database and mailing list program to address envelopes and personalize the cover letter. Many databases include both organizations and people, and although a survey recipient might find a letter that starts “Dear Dr. Department of Psychology” to be amusing, such a letter is not likely to motivate the person to complete the questionnaire. If you are planning to conduct a mail survey, consult Dillman, Smyth, and Christan (2009), who provide a wealth of information on the mechanics of the process.
Increase the perceived benefits of responding by:
• |
Letting potential respondents know that a survey is coming and why it is being conducted and sending reminders to return the survey; |
• |
Providing respondents with information about the survey, explaining why the survey is being conducted and why their responses are important; |
• |
Asking for respondents’ help in achieving the goals of the research or their advice on issues covered in the survey; |
• |
Showing consideration for respondents, such as by providing toll-free telephone numbers or email addresses so that respondents can ask questions (and be sure to reply promptly and courteously); |
• |
Thanking respondents for their assistance; |
• |
When surveying members of a group, remind them of the ways in which responses to the survey will further group goals and values; |
• |
Giving tangible rewards; |
• |
Making the questionnaire interesting such as by using a visually attractive layout and design. |
Reduce the perceived costs of responding by:
• |
Making it convenient to respond; |
• |
Avoiding “talking down” to respondents such as by appearing to give orders (e. g., “it is necessary that you respond”) rather than making requests (e. g., “we would greatly appreciate the help your responses will provide”); |
• |
Making the questionnaire short and easy to complete; |
• |
Minimizing requests for personal or sensitive information. |
Based on Dillman, Smyth, & Christian, 2009, pp. 23–27
Internet surveys. As the World Wide Web has expanded and as computer technology and access to it has improved, an increasing number of researchers have turned to the Internet as means of collecting data. We will address general issues of Internet research in the next chapter; here we will focus on it as a tool for conducting survey research. Internet surveys are much like mail surveys except for the means of delivering the questionnaire to respondents; consequently, many of the principles for improving mail surveys, such as those in Box 15.4, apply to Internet surveys as well.
There are three main approaches to conducting Internet surveys. The first is to email potential respondents to request their cooperation and directing them to a Web site that hosts the survey. Email lists for this approach can be provided by an organization that has agreed to sponsor the research, which gives the researcher credibility with potential respondents. It is possible to include a questionnaire as an attachment to the original email, but a long questionnaire might take up an excessive amount of the recipient’s in-box capacity. A second approach recruits participants from college and university subject pools and directs them to the research Web site. Participants also can be recruited from chat rooms or group pages in social networking sites, such as Facebook and then directed to the Web site. If you are collecting data on the Web, you should inform your participants if the Web site you are using collects respondents’ IP addresses, particularly if your participants expect that their responses are anonymous. IP addresses can be traced to specific computers and, as such, if that information is recorded, responses are no strictly anonymous. Finally, there are Web sites that are directories of Web-based research that include links to the Web site where data collection takes place. Some examples include Psychological Research on the Net (http://psych.hanover.edu/research/exponnet.html), Online Research UK (http://online-psychresearch.co.uk), and Inquisitive Mind (http://beta.in-mind.org/online-research).
Internet surveys have a number of advantages relative to other survey methods. One is the potential to reach a broad segment of the population, including international respondents, quickly and easily. Internet surveys can also help researchers recruit members of otherwise hard-to-reach groups, such as transgendered individuals, if the research is sponsored by an organization that represents the group. Respondents to Internet surveys also exhibit less social desirability response bias, perhaps because they feel confident about their anonymity (Evans et al., 2003). Finally, respondents can complete Internet surveys more quickly than self-administered or telephone surveys without loss of accuracy (Thomas, 2010). For example Thomas found that respondents could answer 7 or 8 questions per minute in Internet surveys compared with 6 or 7 in self-administered surveys and 4 to 5 in telephone surveys.
Internet surveys also have limitations. One is cost (Thomas, 2010). Professionally designed surveys can be expensive and unless one uses a ready-made web survey program to collect data, there will be programming costs. Although there are several sites that host surveys, such as Survey Monkey, they have fees for all but the simplest surveys. Another limitation is an inconsistent response rate. For example, Williams, Cheung, and Choi (2000) found in one study that 86% of the visitors to their research site completed their survey, but achieved a response rate of 46% in another study hosted at the same site. Dillman, Phelps, et al. (2009) telephoned a random sample of households to request their participation in an online survey. Of those who had Internet access, only 13% completed the survey. Another potential problem is that Internet access is not equally distributed across demographic groups, at least in the United States. Overall, 79% of Americans have Internet access, but the proportions are much smaller for African Americans, people older than 65, people with low incomes, and people who live in rural areas (Pew Internet, 2010). Although the anonymity provided by the Internet can reduce social desirability response bias, it also allows users to pose as members of groups to which they do not belong. For example, Mathy, Schillace, Coleman, and Berquist (2002) found that men sometimes posed as lesbians in online chat rooms for gay and bisexual women. Finally, except in longitudinal studies, researchers want each participant to complete their questionnaire only once; however, it is possible for people to access an Internet survey more than once (Skitka & Sargis, 2005). Despite these shortcomings, research on the quality of the data obtained in Internet research has proven to be high in terms of replicating the results of laboratory research and in terms of the reliability and validity of the measures used (Gosling, Vazire, Srivastava, & John, 2004; Skitka & Sargis, 2005).
Personal interviews. Although the personal interview, with hordes of interviewers pounding the pavement and knocking on doors, is the archetype of survey research, it has been largely supplanted by telephone interviews. Nonetheless, it has many advantages and is still used for many research purposes.
The main advantage of personal interviews is the high level of respondent motivation that a skilled interviewer can generate, resulting in high response rates and a high-quality sample of respondents. A personal interview can be long, and there is ample opportunity for the interviewer to probe inadequate responses and for the respondent to ask for clarifications. The interviewer can also use visual aids that require more explanation than those that can be used in written questionnaires. The interviewer has complete control of the order in which questions are asked and often of the interview context. Finally, the success of the personal interview does not depend on the respondents’ abilities to read and write.
Because respondents are contacted individually and in person, with the interviewers having to travel from respondent to respondent, personal interviews are very costly and data collection can take a long time. There is also a high degree of risk that interviewer bias will contaminate responses, resulting in the need for well-trained interviewers, which also adds to the cost of the method. Moreover, it is rarely possible to supervise interviewers while they collect data. Another drawback is the lack of respondent anonymity, which might result in reluctance to discuss certain issues. Finally, although the development of laptop computers has made it possible to use them to record data from personal interviews, use them sparingly: Some respondents might find the presence of a computer distracting, and it might detract from the person-to-person atmosphere that is a major plus of the personal interview (Saris, 1991). One exception to this guideline is the use of computerassisted self-interviews (CASI), in which the interviewer gives the respondent a laptop computer containing audio files of the survey questions and an electronic response sheet. The respondent listens to the questions over headphones and responds to them by pressing the appropriate key on the computer (Gribble, Millers, Rogers, & Turner, 1999). With this method, the interviewer is present to give instructions and answer questions but does not know at any point which question a respondent is answering or what that answer is. Several studies have found that this method lowers social desirable responding and increases the accuracy of responses while maintaining the advantages of personal interviewing (Gribble et al., 1999).
Telephone interviews. Telephone interviews have almost all the advantages of personal interviews, but they can be conducted at a lower cost and completed more quickly. Because interviewer and respondent do not interact face-to-face, there is also less opportunity for interviewer bias to affect responses. In addition, telephone interviewing can be assisted by computers in three ways. First, random digit dialing (RDD) can be used to draw a random sample of telephone owners and makes possible inclusion of people with unlisted numbers. Second, survey questions can be presented to telephone interviewers via computer terminals and the interviewers can enter responses directly into the database.
Telephone interviews also share some of the disadvantages of personal interviews. Telephone interviewers require a fair degree of training, especially in gaining potential respondents’ cooperation after they answer the telephone. However, it is easy to supervise interviewers to ensure that they are conducting their interviews properly. As with personal interviews, respondent anonymity is all but impossible. However, telephone versions of the CASI method described above have been developed in which the interviewer introduces the survey to respondent, who then listens to questions presented by a computer and responds using the telephone key pad (Gribble et al., 1999). Unlike personal interviews, however, telephone interviews cannot make use of visual aids. In addition, the growing number of cell-phone-only households may cause sampling problems if cellphone numbers are not included in the RDD database. For example, although only about 14% of households overall are cell-phone-only, 38% of people aged 18 to 29 have only a cell phone versus 3% of people aged 65 and older (Pew Research Center, 2010). If you are considering conducting a telephone interview, consult Dillman, Smyth, and Christian (2009), who include a very detailed discussion of the mechanics of the process.
Comparison of Survey Data Collection Methods
Adapted from Hoyle, Harris, and Judd, 2002, p. 111
Table 15.11 compares the methods for collecting survey data on the dimensions that we discussed. For most general survey purposes, the telephone interview is probably the best all-around performer. As Quinn, Gutek, and Walsh (1980) note, its “generally favorable comparison with face-to-face interviews in terms of response rates, overall quality of data, and quality of data on sensitive issues should make telephone interviewing the most efficient, inexpensive, and methodologically sophisticated form of collecting survey data” (p. 152). Mail surveys can be used when mailing lists are available for homogeneous but geographically dispersed groups, such as professional organizations, or if cost is an especially important factor. Internet surveys allow access to a wide variety of populations, but there are still a number of groups with limited access to the Net. Personal interviews are better when one is dealing with populations that are hard to reach by other means, such as members of deviant groups, or if the study population is geographically concentrated, reducing the cost of personal interviewing. Group-administered surveys are, as noted, generally used with “captive audiences.” As with all other aspects of research, the choice of a survey methodology requires the researcher to examine the goals of the research and to decide which method has the combination of advantages and disadvantages that will most facilitate the research while hindering it the least.
Survey research is the process of collecting data by asking questions and recording people’s answers. Important issues in survey research are question wording, question response formats, the use of multi-item scales, response biases, questionnaire design, and questionnaire administration.
Survey questions must be written carefully because the phrasing of the questions and the response options used in closed-ended questions can bias respondents’ answers. In writing questions, you must be careful to use language familiar to your respondents, avoid negatively worded questions, ask only one question at a time, avoid loaded words and phrases, be specific, avoid making assumptions, and address sensitive topics sensitively. When writing response scales, it is important to decide on the appropriate level of measurement—nominal, ordinal, interval, or ratio—based on considerations of the information content provided by the level, its ecological validity, and the statistical tests to be used with the data.
There are four formats for closed-ended scale response options: comparative, itemized, graphic, and numerical. These formats typically provide data at the ordinal level of measurement, but judicious choice of anchors for numerical scales can result in interval-level measurement. Choice of a response format for a scale must be dictated by the purpose of the research. However, some evidence suggests that open-ended questions are better for assessing frequency and amount. When interpreting responses, one should not take the meanings of anchors literally because several biases can affect how respondents use the anchors to select a response.
Hypothetical constructs are usually assessed using multi-item rating scales, which are generally exhibit higher reliability and validity than single-tem scales. The most commonly used technique for constructing multi-item scales is the Likert approach, which maximizes the internal consistency of the scale. The Thurstone approach uses interval-scaled items, and the Guttman approach uses items that represent a sequential ordering of beliefs or behaviors. Of these approaches, only the Likert technique allows the development of a scale that can assess multidimensional or multifaceted constructs through the use of subscales. The semantic differential is a well-developed multi-item graphic rating scale widely used to assess the evaluative component of attitudes.
Response biases can threaten the validity of survey and other types of self-report data. Question-related response biases include scale ambiguity, in which respondents judge amount and frequency relative to their own behavior; category anchoring, in which respondents use the categories of itemized response scales as cues to how to respond; estimation biases, which occur when people cannot, or are not motivated to, count specific instances of a behavior; and respondent interpretations of numerical scales, which may lead them to make assumptions about the types of behavior the question asks about. Person-related response biases include social desirability, in which respondents give answers they think will make them look good; acquiescence, the tendency to consistently agree or disagree with statements; extremity, the tendency to consistently use the end points of a scale; and halo and leniency, the tendencies to answer all questions the same way and to give positive ratings. The tendency for some response biases may vary across cultures, and so must be taken into consideration when conducting or reading cross-cultural research.
When designing questionnaires, group questions according to topic and move from general to more specific issues. Be vigilant for context effects, in which answering one question can bias the response to later questions. When the order of questions is contingent on the answer to a prior question, special care must be taken to ensure that instructions clearly indicate how the respondent is to proceed. The questionnaire itself must be formatted so that it is easy to use. Instructions must be clearly written and include transitions between topics that will motivate respondents to answer the questions. It is a good idea to use existing questionnaires in your research, but when combining existing questionnaires use a consistent response format and use controls to reduce context effects.
Survey data can be collected in several ways; although each method has its advantages and disadvantages, each also has situations to which it is best suited. Group-administered surveys are generally used when it is easy to bring respondents together in groups. Although fast and inexpensive, group administration does not contribute to respondent motivation and can generally be used only with convenience samples. Mail surveys can be used when mailing lists are available for geographically dispersed groups. However, mail surveys can take a long time to complete and can have low response rates. Internet surveys allow access to a wide variety of populations and minimize social desirability response bias than other, but response rates can be a problem and there are still a number of demographic groups with limited access to the Internet. For most general survey purposes, the telephone interview is probably the best all-around performer in terms of balancing geographic coverage and expense. Personal interviews are better when one is dealing with populations that are hard to reach by other means or if the study population is geographically concentrated.
Bradburn, N., Sudman, S., & Wansink, B. (2004). Asking questions (rev. ed.). San Francisco: Jossey-Bass.
This book is a comprehensive guide to writing survey questions. It provides guidance on questions about behavior, attitude and behavioral intentions, knowledge, performance evaluation, lifestyle, and demographics.
Trochim, W. M. K. (2006). Scaling. Retrieved August 20, 2010, from htttp://www.socialresearch-methods.net/kb/scaling.php
Trochim provides detailed analyses and descriptions of how to construct Thurston, Likert, and Guttman scales.
Fife-Schaw, C. (2000), Levels of measurement. In G. M. Breakwell, S. Hammond, C. Fife-Schaw, & J. A. Smith (Eds.), Research methods in psychology (3rd ed., pp. 50-63). Thousand Oaks, CA: Sage.
Fife-Schaw presents a succinct summary of the nature of the four levels of measurement and their implications for research design.
Dillman, D. A., Smyth, J. D., & Christian, L. M. (2009). Internet, mail, and mixed-mode surveys: The tailored design method (3rd ed.). Hoboken, NJ: Wiley.
This is one of the standard works on designing and administering surveys. It covers question writing, questionnaire design, sampling, and data collection in both general and business settings.
Presser, S., Rothgeb, J. M., Couper, M. P., Lessler, J. T., Martin, E., Matin, J., & Singer E. (2004). Methods for testing and evaluating survey questionnaires. Hoboken, NJ: Wiley.
Part 6 of this book, “Special Populations,” provides excellent advice on developing questionnaires for use with children and adolescent, in cross-national surveys, and for surveys that have to be translated.
Acquiescence response bias
Anchor
Category anchoring
Comparative rating scale
Context effect
Convenience survey
Cultural response set
Double-barreled question
Extremity response bias
Graphic rating scale
Guttman scale
Interval level measurement
Itemized rating scale
Leading question
Leniency bias
Level of measurement
Likert scale
Literal interpretation fallacy
Loaded question
Multi-item scale
Nominal level measurement
Numerical rating scale
Ordinal level measurement
Population parameters
Ratio level measurement
Reference group effect
Response bias
Reverse scoring (of a scale item)
Robustness (of a statistic)
Sample survey
Semantic differential
Sensitivity of measurement
Social desirability response bias
Subscale
Thurstone scale
1. |
How do sample surveys and convenience surveys differ? |
2. |
How do closed-ended and open-ended questions differ? What are their relative advantages and disadvantages? Under what circumstances is it better to use open-ended questions, and under what conditions are closed-ended questions preferable? |
3. |
Wheeler (1976) has said that by carefully manipulating the wording of a survey question, one can get any response pattern that one desires. Choose an issues and a position, pro or con, on the issue. Write two opinion survey questions on the issue, one that you think will result mostly in agreement with your chosen position and one that you think will result mostly in disagreement. What question-wording principles did you exploit in constructing your questions? |
4. |
Take the same issue that you dealt with in Question 3 and try to write two unbiased questions on it. Exchange your questions with a classmate and analyze each other’s questions based on the principles of question wording |
5. |
Name and define the four levels of measurement. What characteristics of levels of measurement must the researcher bear in mind when choosing a level? |
What are the relative advantages and disadvantages of the two methods of comparative scaling? What conditions must be met if comparative scaling is to provide reliable and valid results? | |
7. |
How can preliminary research using open-ended questions be used to improve the content validity of itemized rating scales? |
8. |
How are graphic rating scales and numerical rating scales similar? How do they differ? Describe the ways in which itemized rating scales can be constructed to provide data similar to that from numerical scales. |
9. |
How can the measurement sensitivity of rating scales be increased? |
10. |
What level of measurement results from each scale response format? Under what conditions can interval and ratio level measurement be achieved? |
11. |
What advantages do multi-item scales have over single-item scales? |
12. |
Describe the development processes for Likert, Thurstone, and Guttman scales. How are these types of scales similar and how do they differ? Likert is currently the predominant approach used in developing multi-item scales. Describe the characteristics of Liking scaling that have led to its popularity. |
13. |
Describe the structure and use of the semantic differential. |
14. |
How do scale ambiguity, category anchoring, and estimation biases affect responses to survey questions? What steps can the researcher take to reduce these biases? |
15. |
Find a survey that has been used at your college or university. Are any of the questions likely to induce response biases? If so, how can those questions be rewritten to reduce response bias? |
16. |
What are the most common forms of respondent-related response biases? What can be done to reduce the influence of these biases on responses to survey questions? |
17. |
What are cultural response sets? What implications do they have for conducting and interpreting the results of cross-cultural research? |
18. |
What is the literal interpretation fallacy? |
19. |
Describe the principles for ordering questions in questionnaires. What are context effects? How can they be controlled? |
20. |
How should questionnaires be laid out? |
21. |
What types of instructions are used in questionnaires? |
22. |
Obtain a copy of a questionnaire that has been used in research at your college or university, and evaluate the effectiveness of its question ordering, instructions, and layout. What suggestions would you make for improving the questionnaire? |
23. |
What are the advantages of using existing measures in research? What considerations are important when combining existing measures in a questionnaire? |
24. |
Describe the methods of survey data collection. Compare and contrast the advantages and disadvantages of each method. What type of situation is each best suited for? |