

Purposes of Literature Reviews
Integrative Literature Reviews
Defining the Research Question
Approaches to Answering the Question
Include Only Published Studies
Integrating the Results of Primary Research
Types of studies that can be reviewed
Objectivity versus subjectivity
“Best evidence” literature reviewing
Operationally Defining Study Outcome
The Correlational Nature of Moderator Variable Analyses
Defining the Research Question
Deciding Which Studies to Include
Integrating the Results of the Studies
Interpreting the Results of the Meta-Analysis
Suggestions for Further Reading
Questions for Review and Discussion
The term literature review can sometimes be a bit confusing because behavioral scientists use the term in more than one way. One type of literature review is the background reading, such as we discussed in Chapter 5, that researchers do on existing theories and research in preparation for conducting a new study. Literature review also refers to the part of the introduction section of a research report the provides the authors’ summary of the relevant theories and research that form the bases of their hypotheses (see Chapter 20). Another type of literature review is a form of research that summarizes what is known about a topic. This type of review can focus on the historical development of theory or research on a topic, on comparisons and evaluations of competing theories on a topic, or on summaries and critical evaluations of the research on a topic.
It is this last purpose of literature reviewing—summarizing the research evidence on a hypothesis or set of related hypotheses—that is the main focus of this chapter. Such summaries have several goals. One is to determine how well the hypothesis is supported. Every study has its flaws; no one study can be perfect and so by itself cannot provide a complete answer to a research question—the outcome of a single study could be the result of its flaws rather than of the effect of the independent variable, for example. However, if several studies of a hypothesis, each with its own flaws but each also having strengths that compensate for the weaknesses of the others, all come to the same conclusion, then it is unlikely that the overall result is an artifact resulting from design flaws. When this type of literature review shows that there is consensus across of a number of studies, that summary provides the best picture of the effect of an independent variable. Nonetheless, some studies in a set will support the hypothesis and others will not; therefore, a related goal of integrative literature reviewing is determining the causes of inconsistencies in research results. Sometimes the cause is methodological, such as the use of different operational definitions in different studies, and sometimes the cause is a variable that moderates the effect of the independent variable, such as when men respond differently from women. In such a case, the use of all-male samples in some studies and all-female samples in other studies will lead to apparently conflicting results. Once the summary is completed, the literature reviewer can draw implications for theory, research, and application. For example, the discovery of moderating variables might require modification to theories, the literature review might show that a commonly used operational definition has validity problems, or the review might indicate that an intervention works better for some types of people or in some situations than it does for other people or in other situations.
We begin this chapter with a discussion of the various purposes that a literature review can serve. We then describe the issues involved in conducting the most common type of literature review, the integrative review. We conclude with a “walk-through” of an example of what has become the most common form of integrative literature review, meta-analysis.
A literature review can either have a conceptual or an integrative purpose (e.g., Baumeister & Leary, 1997; Cooper, 2010). Conceptual literature reviews address broader theoretical and methodological issues such as theory development and evaluation, problem identification, and the analysis of historical trends in theory and research. Integrative literature reviews focus on the same issues that primary research addresses: The effect of an independent variable on a dependent variable, the factors moderate that effect, and whether the effect is found under specific sets of conditions.
Conceptual literature reviews. Conceptual reviews deal with questions that are broad in scope, focusing on theory and the research process rather than on hypothesis testing. As a result, there are a large number of conceptual issues that can be addressed and it may be better to think of them in terms of goals rather than as questions (Baumeister & Leary, 1997; Bem, 1995). One such goal, summarizing knowledge, is akin to that of integrative literature reviews. Knowledge summaries provide an overview and integration of what is known about a particular topic, but focus on general principles rather than on specific hypotheses. The chapters published in the Annual Review of Psychology are examples of this type of literature review.
Conceptual literature reviews can take any of three approaches to theory. Reviews focusing on theory development collate information from existing theories and empirical research to develop a new theory. For example, Bigler and Liben (2006) made use of research and theory from social and developmental psychology to create a new theory of how prejudice develops in children. Reviews that focus on theory evaluation examine the literature on the validity of a theory or of two or more competing theories to evaluate the validity of the theory. For example, Premack (2010) compared three theories of why human beings are fundamentally different from animals and concluded that one was more valid (animal abilities are limited to attaining single goals, but human abilities are domain general and serve many goals) than the others. Theory integration reviews point out similarities and areas of overlap between theories and explain how those theories work together to provide a better understanding of the topic they address. For example, Ranganath, Spell-man, and Joy-Gaba (2010) provided an integration of social and cognitive psychological perspectives on the factors that influence how people evaluate the believability of persuasive arguments.
Problem identification as a goal of literature reviews points out problems or weaknesses in existing research or theory on a particular topic. For example, Uziel (2010) pointed out shortcomings in existing measures of social desirability response bias and suggested ways of re-conceptualizing the concept on the basis of his analysis. Point of view reviews present evidence on a controversial issue in an attempt to persuade readers to accept the viewpoint advocated by the authors, or at least to give it serious consideration. For example, Bem and Honorton (1994) presented evidence in support of the existence of extrasensory perception (ESP) to convince readers that ESP is a phenomenon worthy of serious research. Finally, historical analyses provide accounts of trends in theory in research over time. For example, Duckitt (1994) presented the history of the study of prejudice in terms of seven time periods, outlining for each time period the main theory of prejudice, the theory’s social context, the predominant research questions addressed, and the prevailing conception of prejudice used by theorists and researchers.
Integrative literature reviews. Integrative literature reviews are a form of research whose goal is to bring together research on a hypothesis and draw overall conclusions concerning its validity based on the results of studies that have tested the hypothesis. As Jackson (1980) noted, “Reviewers and primary researchers share a common goal … to make accurate generalizations about phenomena from limited information” (pp. 441–442). In primary research, that information is the data collected from research participants; in literature reviewing, the information is the results of a set of studies testing a hypothesis.
The first question addressed by an integrative literature review is, what is the average effect of an independent variable on a dependent variable? That is, ignoring such factors as differences among studies in research strategies, participant populations, operational definitions, and settings, what effect does an independent variable have on a dependent variable, and how large is that effect? Although this is a rather simplistic way of looking at the effect of a variable, this so-called main effects approach to literature reviewing (Light & Pillemer, 1984) can serve two purposes. One is to guide social policy makers, who are often more interested in the overall effect of a variable than in the factors that moderate its effects (Light & Pillemer, 1984). For example, consider a hypothetical policy question such as “Should public funds be used to pay for psychotherapy services?” Because the question is one of whether the services should be funded at all, policy makers will want to know if psychotherapy in general is effective and therefore deserving of funding. Questions concerning moderator variables, such as whether some types of therapy are more effective for some types of people or problems, are too narrow to form the basis for a broad social policy. Paraphrasing Masters (1984), Guzzo, Jackson, and Katzell (1987) frame the issue in this way:
Policy makers voice a need for “one-armed” social scientists who give straight, unqualified answers when asked for advice. Instead, they too often encounter a response such as, “Well, on the one hand thus and so is the case, but on the other hand this and that may hold.” Unlike scientists, who often prefer to dwell on the contingencies that make global generalizations impossible, policy makers must seek to find the most justifiable generalizations. (p. 412)
Policy makers may consider interactions especially irrelevant when the moderator is an estimator variable, over which they have no control (recall Chapter 5). However, the consideration of relevant policy variables as potential moderators is essential to any applied meta-analysis (Light & Pillemer, 1984).
A second purpose of main effects literature reviewing is to identify general principles that can guide research. Consider, for example, a general finding that there are sex differences in nonverbal communication skills. Such a finding could provide the basis for additional research investigating the origins of these differences. For research on nonverbal communication that does not focus on sex differences, the finding implies that sex of research participant should be controlled in future research in order to minimize extraneous variance.
The other integrative question addressed by literature reviews—What factors moderate the effect of an independent variable?—is the question of the generalizability of an effect: Does the independent variable have the same effect under all conditions? Ideas for the potential moderator variables to consider in a literature review can come from a number of sources (Mullen, Salas, & Miller, 1991). One source of ideas is the theories that deal with the independent variable; these theories might postulate the existence of moderator variables and so predict that research should find certain interactions. For example, Hackman and Oldham’s (1980) Job Characteristics Model of work motivation holds that interventions based on the model will be more effective for certain types of people—those high in what Hackman and Oldham call growth need strength—than for others. Reviews of the literature on the effectiveness of the model should therefore compare the outcomes of studies conducted with people high in growth need strength with studies conducted with people low in growth need strength. This procedure both tests the theory and examines its impact under the conditions that are specified as crucial to its effectiveness.
Potential moderator variables can also be identified from the reviewer’s knowledge of research on the topic and from prior literature reviews. For example, the reviewer might know that the results of research on a topic vary as a function of research setting. Similarly, potential mediator variables may emerge from the studies being reviewed: As the reviewer reads through them, she may see patterns of relationships between factors such as study characteristics and the magnitude of the impact of the independent variable. Finally, one can apply “one’s intuition, insight, and ingenuity” (Jackson, 1980, p. 443) to the problem. Reviewers might have hypotheses of their own to test in the review.
A shortcoming of many literature reviews is a tendency to look primarily for simple moderator effects, those involving only one moderator variable (Shadish & Sweeney, 1991). As Shadish and Sweeney point out, however, multiple moderator variables can sometimes influence the effect of an independent variable. They use the example of reviews of psychotherapy outcome research, which have generally found that behavioral and non-behavioral therapies have equal effects in terms of recovery rates. That is, these reviewers concluded that type of treatment does not interact with condition of the independent variable (treatment versus control) to affect outcome: An equal proportion of people improve with each type of therapy when compared to control groups. However, Shadish and Sweeney’s review found that type of therapy does interact with therapy setting to affect outcome: Behavioral therapies have twice the effect of non-behavioral therapies when the research is conducted in university settings, but there is no difference in effect size when the research is conducted in non-university settings. To be able to identify possible moderator variables, literature reviewers need to be thoroughly familiar with both the theoretical and empirical issues related to the topic of the review. Reviewers new to a topic should seek the advice of people who are experts on it.
The third integrative question asks, is the effect found under specific condition? This is the question of the ecological validity of an effect (recall Chapter 8); that is, how well can a broad principle be applied to a specific type of situation? The answer to this question can be used to assist in deciding if an intervention should be implemented under a given set of circumstances: Has previous research shown it to be effective or ineffective under those, or similar, circumstances?
Because integrative literature reviews are more common than conceptual reviews, we focus the rest of the chapter on them. We first address the process of defining the research question. We go on to discuss issues concerned with locating studies that deal with the research question, deciding which ones to include in the review, and integrating the results of those studies. We then outline issues that arise when interpreting the results of integrative literature reviews.
Integrative literature reviews, like all research, start with a question. There are two issues to consider in formulating a literature review question (Light & Pillemer, 1984): the scope of the question and the approach to take in answering the question.
The issue of scope deals with how narrowly or broadly the question is defined. For example, is the review to be limited to just one operational definition of the independent variable, or will multiple operational definitions be considered? Will the review be limited to one dependent variable, or will the independent variable’s effects on several dependent variables be assessed? Will the review include just one or more than one operational definition of each dependent variable? Will it include only one research strategy or will all strategies be included? The answers to questions such as these will depend on the purpose of the literature review. For example, only experiments can test causality, so a review that asks a causal question might be limited to or give more emphasis to experiments. A review that is too narrow in scope—for example, a review limited to one operational definition of each of the independent and dependent variables—may lead to conclusions with little generalizability. Yet a review that is too broadly defined might become impossible to complete, with the reviewer overwhelmed by a huge number of studies. As with many other aspects of literature reviewing, and research in general, defining the scope of the review is a judgment call that must be guided by the reviewer’s knowledge of the topic under review.
Light and Pillemer (1984) suggested that there are two broad approaches to conducting integrative literature reviews, although any review can involve a combination of the two. With the hypothesis-testing approach, the reviewer starts with a specific hypothesis about the relationship between an independent variable and a dependent variable, and tests the hypothesis against the results of research. For example, Loher, Noe, Moeller, and Fitzgerald (1985) tested the hypotheses that application of Hackman and Oldham’s (1980) Job Characteristics Model would lead to increases in job satisfaction and that it would be more effective for people high in growth need strength. They found that the model had a moderate positive impact overall and that its impact was, as the theory predicted, greater for people high in growth need strength.
The second approach is exploratory, in which the reviewer focuses on an outcome and searches the relevant literature to determine which independent variables consistently produce the outcome. For example, Whitley and Schofield (1986) asked, “What variables predict the use of contraception by adolescents?” Their review found 25 reasonably consistent predictors for young women and 12 for young men. One drawback to the exploratory approach is that the predictors found can be intercorrelated so that controlling for one might remove the effects of others (recall the discussion of multiple regression analysis in Chapter 11). Therefore, any relationships found using an exploratory literature review should be confirmed by collecting new data. When Whitley (1990a) did this, he found that only three of the variables independently predicted contraceptive use by young women and only one predicted contraceptive use by young men.
The choice between the hypothesis-testing and exploratory approaches to literature reviewing depends on the purpose of the review and the nature of the research being reviewed. For example, the hypothesis-testing approach can be used only when the reviewer has a specific hypothesis in mind, derived from theory, from prior empirical work, or from her own insight or experience. The exploratory approach can be used to identify important independent variables in order to develop new theories from existing research or, as Whitley and Schofield (1986) did, to catalog independent variables in an area of research that has been generally unguided by theory and to determine which appear to have effects and which do not.
Once a research question has been defined, one must locate primary research that deals with the hypothesis or topic of interest. Chapter 5 discussed this process, going over the various indexes available for locating research reports; you might want to review that discussion before going on.
Although the methods discussed in Chapter 5 provide useful starting points for locating studies for an integrative literature review, they do not provide a complete listing of relevant research. There is also what is known as the “fugitive” (Rosenthal, 1994) or “grey” (Rothstein & Hopewell, 2009) literature—research reports in the form of technical reports, unpublished manuscripts, papers presented at conventions, and dissertations and theses—that are not published in scientific journals and so are often not covered by the more commonly used indexes. Rothstein and Hopewell discuss several strategies for locating these kinds of studies.
In addition, indexes do not always provide a complete listing of all the published studies on a topic. Durlak and Lipsey (1991), for example, noted that computer searches of indexes overlooked 67% of the studies relevant to a literature review that they conducted. People doing literature reviews therefore often find it useful to conduct what Green and Hall (1984) call a source-by-source search: Identify all the journals that are likely to carry research reports on your topic, and examine every issue of every journal for relevant articles. Such a procedure is laborious and time consuming, but Green and Hall believe it is the best way of being certain to have located all relevant published studies.
Baumeister (2003) cautions that when compiling studies to use in a literature review, it is important to cast as wide a net as possible. He notes that because literature reviewers are often strongly committed to the validity of the hypotheses they test in their reviews, they tend to focus on the literature that supports those hypotheses. Baumeister therefore recommends that literature reviewers actively search for studies that fail to support the hypothesis under review to ensure that the review produces accurate conclusions.
Once you have collected the studies relevant to your hypothesis, you must decide which ones to include in your literature review. Although your initial impulse might be to include all the studies, there are other options (Light & Pillemer, 1984): including only published studies, including only highly valid studies, stratified sampling of studies, and using experts’ judgments to choose studies. Let’s look at the advantages and disadvantages of these options.
Including all the relevant studies in the literature review has the distinct advantage of completeness: All the available data will be used in drawing conclusions. There are, however, several potential disadvantages to this approach (Light & Pillemer, 1984). First, it might be difficult or impossible to locate all relevant studies. As noted, few unpublished studies are indexed, making it very difficult to locate them, and the benefit derived once they are found might not be worth the effort. Second, including all studies in the review will give equal weight to both highly valid and poor research. Conclusions drawn from the latter studies should be qualified by consideration of the alternative explanations for their results posed by the threats to their internal validity. However, if all studies are lumped together, valid results are confounded with potentially invalid results. Finally, if there is a very large number of studies on a topic, it might be impossible to include all of them, especially if the time available for conducting the review is limited.
Most literature reviews include only published studies or make only limited attempts to locate unpublished studies, such as through the use of the ERIC database discussed in Chapter 5. Published studies are easy to locate because they are indexed. In addition, the peer review process provides some screening for methodological validity, although the process—in which other scientists evaluate the quality of a research report as a condition of publication—is not perfect. Considering only published studies also limits the number of studies you must deal with.
The disadvantage of including only published studies in the review is that it brings into play the publication biases discussed in Chapter 17. As we noted then, there is a bias against publishing null results (Borenstein, Hedges, Higgins, & Rothstein, 2009; Greenwald, 1975). Because studies that do not find a statistically significant difference between the conditions of the independent variable—that is, those with small effect sizes—are unlikely to be published, those that are published may overestimate the true effect of the independent variable, resulting in a literature review that gives a distorted picture of the relationship between the independent and dependent variables (Schmidt, 1992). White (1982), for example, conducted a literature review of studies of the relationship between socioeconomic status (SES) and IQ scores, and discovered that unpublished studies found an average correlation of r = .29, studies published in journals found an average correlation of r = .34, and studies published in books found an average correlation of r = .51.
Another form of publication bias is in favor of studies whose results are consistent with accepted theory (Greenwald, Pratkanis, Leippe, & Baumgardner, 1986). Studies that challenge the explanations of phenomena provided by popular theories tend to be evaluated more strictly than studies that support the theory and so are less likely to get published. Garcia (1981), for example, recounted the difficulties he encountered in getting the results of research on the biological constraints on classical conditioning published. Many of his problems stemmed from his challenges to principles that had long been accepted without question. Consequently, a literature review aimed at evaluating a theory is less likely to turn up data that challenge the theory if it includes only published studies.
As we noted earlier, including all studies in a literature review, or even only all published studies, may result in using studies that have threats to their validity. Consequently, literature reviewers frequently attempt to assess the validity of the studies conducted on a topic. Reviewers are generally most concerned with internal validity, theoretical validity, and ecological validity (Valentine, 2009); they assess generalizability with analyses of the effects of moderator variables.
Internal validity. Because the results of studies that suffer from internal validity problems might not accurately reflect the true relationship between the independent and dependent variables, including them in a literature review could threaten the validity of the conclusions drawn from the review. For example, White (1982) noted the studies he thought were of low internal validity found an average correlation of .49 between SES and IQ scores, whereas the highly valid studies found an average correlation of .30. Consequently, literature reviews usually evaluate the internal validity of the research they review and give more weight to those considered more valid. Some reviewers completely exclude from consideration studies they consider invalid.
Theoretical validity. You can also evaluate studies on their theoretical validity (Cook & Leviton, 1980). That is, some theories specify conditions that must be met for the predictions made by the theories to be fulfilled. As already noted, Hackman and Oldham (1980) said that their theory of work performance applied only to a certain type of person but not to other types of people. A true test of the validity of a theory can take place only if the conditions that it sets for itself are met. Cook and Leviton (1980) cite the example of research on the “sleeper effect” in persuasion, the finding that attitude change is sometimes delayed until well after the persuasive message is received:
If all past studies of the sleeper effect were included in a review without regard to how well the necessary conditions for a strong test of the effect were met, one would probably conclude from the many failures to obtain the effect that “it is time to lay the sleeper effect to rest.”… And the number of failures to obtain the effect would be psychologically impressive. Yet the very few studies that demonstrably met the theory-derived conditions for a strong test of the effect all obtained it and one can surmise that these studies should be assigned greatest inferential weight because of their higher theoretical relevance. (pp. 460–461)
Ecological validity. Finally, when the literature review is aimed at determining the applicability of a principle to a specific situation, the reviewer will want to assess the ecological validity of the studies relative to that situation. The studies that were not conducted under conditions reasonably similar to those in the situation to which the principle is going to be applied could be eliminated from or given less weight in the review.
Evaluating validity. Excluding studies from consideration in a review on the basis of their validity raises the question of what constitutes a study that is sufficiently valid to be included in the literature review. As we noted in Chapter 2, no study can be perfect (McGrath, 1981); as a result, even experts can disagree about the degree of validity of a study. Therefore, selecting studies for inclusion in a literature review on the basis of their validity might be overly restrictive: A methodological flaw in a study does not necessarily mean its results are biased, only that the conclusions you can draw from it are less certain than the conclusions that can be drawn from a better study (Jackson, 1980). In addition, as Rosenthal (1990) points out, “Too often, deciding what is a ‘bad’ study is a procedure richly susceptible to bias or to claims of bias. … ‘Bad’ studies are too often those whose results we don’t like or … the studies [conducted by] our ‘enemies’” (p. 126).
What, then, should you do when you face a set of studies that vary on their validity? Mullen et al. (1991) suggest a three-step approach. First, exclude those studies that are so flawed in terms of internal or construct validity that no valid conclusions can be drawn from them. For example, a study might use a measure that later research has shown to be invalid; because the wrong construct was measured, the study does not really test the hypothesis under review. Second, establish an explicit set of criteria for judging the degree of validity of the studies under review (e.g., Valentine & Cooper, 2008). For example, a study that randomly assigned participants to conditions of the independent variable would be considered of higher internal validity than a study that allowed participants to select themselves into conditions. Criteria could also be established for ecological or theoretical validity. Third, classify the studies as to their degree of validity, being sure to check the reliability of the classification system, and analyze the results of the studies within validity categories. Using this approach, you can determine if degree of validity affected the results of the studies, as did White (1982). If there are large discrepancies in results on the basis of degree of validity, you might want to give more weight to the high-validity studies when drawing conclusions.
If the number of studies on a topic is so large that including all of them in a review would be unduly burdensome or would make it impossible to complete the review in the time available, you can classify (or stratify) the studies on the basis of important characteristics, such as the operational definitions or participant samples used, and randomly sample studies from each category for inclusion in the review (Light & Pillemer, 1984). This approach will result in a review based on a sample of studies whose characteristics are reasonably representative of the characteristics of all the studies. As a result, the conclusions drawn from such a review should be similar to those drawn from a review of all the studies. The drawback of this approach is that it might not be possible to classify all the studies on all the relevant characteristics; the information needed might not be available for some studies. If all the studies cannot be classified, a sample based only on the classifiable studies might be biased.
Another solution that Light and Pillemer (1984) suggest to the overabundance of studies problem is to have acknowledged experts on the topic under review choose the best and most relevant studies for review. This approach capitalizes on the experts’ knowledge and experience and ensures that the review will focus on studies that are valued by experts in the field. However, studies chosen by experts might reflect biases that the experts hold, such as favoring studies that use large numbers of participants or that are well known over other studies that are equally or more relevant or valid.
Once the studies are selected for inclusion in the literature, the reviewer must synthesize or combine their results. As a first step in the process, the reviewer must decide between the two basic approaches to integrating the results of primary research, narrative literature reviewing or meta-analysis. Next, the reviewer must determine the overall effect of the independent variable as shown by the results of the studies: On the average, does the independent variable have an effect or not? Using the chosen technique, the reviewer must determine the factors that moderate, or lead to differences in, the results of the studies. For example, does the independent variable have an effect in one situation, such as a laboratory environment, but not in another, such as field settings? To accomplish these tasks, the reviewer must make several sets of decisions: how to operationally define the outcomes of studies, how to classify studies on possible moderating variables, how to assess flaws in research designs, and how broadly to define the independent and dependent variables.
There are two techniques for integrating the results of studies. The traditional approach has been the narrative literature review. Narrative literature reviews take a qualitative approach, with the reviewer considering the outcomes of the studies and the relationships of the moderator variables to the outcomes, and providing a narrative description of the overall effect of the independent variable and of the variables that appear to moderate that effect. Commonly, these conclusions are supported by “vote counts” of studies supporting and not supporting the hypothesis, both overall and within conditions of moderator variables. The last 35 years have seen the emergence of an integrative literature review technique called meta-analysis. Meta-analysis takes a quantitative approach by computing mean effect sizes for an independent variable (Chapter 16), both overall and within conditions of moderator variables. One can also compute the statistical significance of a mean effect size and of the difference between the mean effect sizes in different conditions of a moderator variable. Meta-analysis therefore takes a more statistical or quantitative approach to literature reviewing, whereas the narrative literature review takes a more qualitative approach.
The development of meta-analysis has led to a fair degree of controversy and disagreement between advocates of the narrative literature review, who see meta-analysis as being an overly mechanistic and uncreative approach to literature reviewing, and the advocates of meta-analysis, who see the narrative literature review as too subjective and imprecise (Borenstein et al., 2009; Greenberg & Folger, 1988). However, a comparison of the techniques shows that they tend to be complementary—the strengths of one compensating for the shortcomings of the other—rather than competing. Let’s consider some of the points of comparison between narrative literature reviews and meta-analyses.
Research goals. Both meta-analysis and narrative literature reviews can be used for summarizing and integrating the results of primary research on a particular hypothesis. However, meta-analysis has several advantages over narrative literature reviews for this purpose (outlined below) and so it is the preferred method when it can be used (Baumeister, 2003). In contrast, narrative literature reviews are better for addressing conceptual questions such as theory development, problem identification, and historical analysis, although most integrative literature reviews also raise or address conceptual questions. For example, a review centered around a meta-analysis might identify one or more problems in the research literature as did Kite and Whitley’s (1996) meta-analysis of the research on gender differences in attitudes toward homosexuality. They found that the magnitude of the difference varied as a function of whether the dependent variable assessed attitude toward homosexual people (lesbians and gay men), homosexual behavior, or the civil rights of lesbians and gay men. This finding indicated the importance of differentiating between these three constructs in research on the topic. Similarly, a meta-analysis can examine research from an historical perspective, examining how relationships between variables change over time. For example, Hall, Matz, and Woody (2010) found that the size of the correlation between religious fundamentalism and racial/ethnic prejudice declined substantially between 1964 and 2008.
Types of studies that can be reviewed. The narrative literature reviewer can consider the results of both qualitative and quantitative studies in drawing its conclusions. Meta-analysis, as a quantitative technique, can only consider the results of studies that provide numerical results. Consequently, meta-analysis must ignore entire bodies of research in fields that make extensive use of case studies and single-case experiments. The exclusion of such studies from a literature review can severely limit the conclusions drawn, especially if qualitative and quantitative studies come to different conclusions about the effect of an independent variable. Such conflicts are not unlikely given the differences in philosophy, data collection, and data analysis evidenced in the two approaches to research (Guzzo et al., 1987). Note, however, that some researchers are looking for ways to include the results of single-case research in meta-analyses (e.g., Swanson & Sachse-Lee, 2000).
Meta-analysis faces a similar problem of data exclusion when quantitative studies do not provide the information necessary to compute an effect size. This situation is especially likely to occur when the effect of the independent variable is not statistically significant; researchers often simply note that the difference between conditions was not significant and move on to report the (presumably more important) statistically significant effects. The number of studies that must be excluded from a meta-analysis can sometimes be substantial; to give but two examples, Burger (1981) could compute effect sizes for only 7 of 22 studies (32%) and Guzzo, Jette, and Katzell (1985) for only 98 of 207 studies (47%). The exclusion of such no-difference studies can have substantial effects on the conclusions drawn from a meta-analysis. For example, Marks and Miller (1987) described a meta-analysis that concluded that there was no support for one theoretical explanation for the false consensus effect (the tendency for people to see others as agreeing with them), but they noted that several studies supporting that explanation were excluded from the meta-analysis because effect sizes could not be computed for them. It is therefore important to use extreme caution when interpreting conclusions from meta-analyses that had to exclude a substantial number of studies due to lack of data. The problem of unreported effect sizes has been reduced substantially in recent years as professional journals have instituted a policy or requiring authors or articles that report on primary research to include effect size indicators as part of their results (e.g., American Psychological Association, 2010b).
Meta-analysts’ dependence on effect sizes can also limit their ability to evaluate interactions because it can be difficult to find the data required to test theory-based interactions (Mullen et al., 1991). If the interaction was tested as part of the original research, then the research report must provide the data necessary to compute the a priori contrast for the interaction predicted by theory. Such data are less likely to be available than are main effects data, especially since only a subset of studies testing the theory is likely to include any one moderator variable. If the interaction was not tested as part of the original research, you would have to find studies that were characterized by different conditions of the moderator variable and compare the mean effect sizes in the two groups of studies, just as you would test for the effects of a methodological moderator. However, it is often impossible to determine if a study was conducted in a way that represents one or another condition of the moderator variable. Lacking that data needed to evaluate interactions, all you can do is look at main effects; this problem would also apply to narrative literature reviews.
Meta-analysis has also given little attention to the role of mediating variables—those that come between an independent and dependent variable in a causal chain—from either a theoretical or methodological perspective (Shadish, 1996). As with moderating variables, the problem is often that there is not a sufficient number of studies that include all the important potential mediators to allow a good test of their effects. However, techniques do exist for testing mediational hypotheses using meta-analysis and should be applied to appropriate research questions (Shadish, 1996).
Objectivity versus subjectivity. Advocates of meta-analysis generally view it as a more objective means of drawing conclusions about the effects of an independent variable than the narrative literature review (e.g., Green & Hall, 1984). This view is based on meta-analysis’s using statistical tests to determine the overall effect of an independent variable and the effects of any potential moderator variables. In contrast, the conclusions of narrative reviews are not based on a predefined criterion of whether or not effect occurs, such as the probability values used in statistical analyses but, rather, on the subjective judgment of the literature reviewer. This judgment can be affected by the theoretical and other biases of the reviewer; decisions based on statistics are free of such biases.
However, although it is true that the mathematical aspects of meta-analysis are relatively free of bias, the meta-analyst, like the narrative literature reviewer, must make a number of subjective decisions before getting to the data analysis stage of the review. Wanous, Sullivan, and Malinak (1989) listed 11 decisions that must be made in a meta-analysis, eight of which are subjective judgments that also must be made by narrative literature reviewers. Some of these decisions include defining the scope of the review, establishing criteria for including studies in the review, defining the scope of search for studies, deciding which moderator variables to consider, and evaluating the quality of the studies. Different decisions made at such choice points can easily lead to contradictions between the conclusions drawn from a meta-analysis compared with a narrative literature review of a hypothesis, to contradictions between the conclusions drawn by two meta-analyses, and, of course, to contradictions between the conclusions of two narrative literature reviews (Cook & Leviton, 1980; Wanous et al., 1989). Also bear in mind that, as noted in Chapter 17, the interpretation of the results of research—what it means in theoretical and practical terms—is always a subjective judgment open to the influence of the personal and theoretical biases of whoever is making the interpretation. It would appear, then, that meta-analysis has only a narrow advantage in objectivity over the narrative literature review, limited to conclusions about the statistical significance of the effects of the independent and moderator variables.
Precision of results. The advocates of meta-analysis also believe that it provides more precise information about the magnitude of the effect of an independent variable—expressed as a mean effect size—than does the narrative literature review, which generally provides only a broad yes-or-no conclusion. In addition, the use of effect sizes in meta-analysis reduces the likelihood of making a Type II error: deciding that the independent variable had no effect when there was insufficient statistical power to detect an effect. The vote-counting approach taken by most narrative literature reviews, in contrast, must depend entirely on the statistical power of the studies being reviewed to avoid Type II errors.
However, a number of factors limit the precision with which meta-analysis can estimate the size of the effect of an independent variable. First, as already noted, publication biases might inflate the Type I error rate present in the studies reviewed. Although this is also a problem for a vote-counting approach, it may be a greater problem for meta-analysis because it will lead to an inflated estimate of the mean effect size. To the extent that the effect size is used as an indicator of the importance of the effect, its importance will be overestimated, perhaps leading to faulty policy decisions (Bangert-Downs, 1986). Second, the mean effect size can be very sensitive to outliers—values that are unusually large or unusually small—especially when only a few studies are included in a meta-analysis. Light and Pillemer (1984) give the example of a meta-analysis (Burger, 1981) that found a mean d (the difference between experimental and control conditions expressed in standard deviation units) of .63 based on the results of seven studies. However, one study had an unusually large d of 4.01; with this value dropped, the mean d became .33, which might be a better estimate of the true effect size. Finally, as we have noted, it might not be possible to compute effect sizes for all studies. Consequently, these studies cannot be included in the meta-analysis, and their exclusion reduces the precision with which the mean effect size found in the meta-analysis estimates the true effect of the independent variable.
The degree of precision gained by meta-analysis over the narrative literature review comes at the cost of requiring effect sizes from multiple studies. Borenstein et al. (2009) recommend a minimum of 10 to 15 studies. As with any variable, the precision with which a mean effect size estimates the population effect size depends on the number of observations. Although meta-analysis cumulates results over a large number of research participants and thereby gains statistical power, the studies are also likely to vary widely in their operational definitions, participant populations, settings, and other methodological characteristics, which will lead to variance in effect sizes, thereby reducing the precision of the estimate of the true effect size (Cook & Leviton, 1980). To determine how much of this variance is attributable to these methodological factors, they must be treated as moderator variables in the analysis. When conducting moderator variable analyses, one should have 10 to 15 studies per condition of the moderator variable. If this many studies are not available, one should be cautious about drawing firm conclusions from the analysis. A narrative literature review can be conducted on fewer studies because it does not aspire to the higher degree of precision desired by meta-analysts, although this lesser precision should also be reflected in more tentative conclusions.
Meta-analysis attains precision by focusing on numbers—effect sizes—which has led some writers (e.g., Cook & Leviton, 1980; Wanous et al., 1989) to caution against mindless number-crunching: paying so much attention to effect sizes, their mean, and their statistical significance that one loses sight of the meaning of the numbers. It is easy, for example, to become so entranced by the seemingly precise “bottom line” provided by a mean effect size that one overlooks the limitations that moderator variables might put on the accuracy of that statistic or the degree to which the mean might be influenced by publication and other biases (Cook & Leviton, 1980). Therefore, always pay careful attention not only to the numbers produced by meta-analyses but also to the substantive meaning of those numbers, the limitations of the studies that produced them, and limitations of meta-analysis as a method. For this reason, Wanous et al. (1989) recommend that one do a narrative literature review before conducting a meta-analysis. The narrative review provides an overview of the important issues on the topic and sensitizes the reviewer to the limitations of the studies under review and to factors that require attention as potential moderator variables.
“Best evidence” literature reviewing. Both narrative literature reviews and meta-analyses have strengths and weaknesses; the most important of these are summarized in Table 19.1. A major restriction on meta-analysis is that, unlike narrative literature reviews, it cannot address broad theoretical issues. When it comes to empirical questions, both meta-analysis and the narrative literature review can synthesize the results of quantitative studies although they differ in their approaches. The meta-analyst computes mean effect sizes whereas the narrative reviewer categorizes study outcomes as supporting or not supporting the hypothesis. However, meta-analysis cannot synthesize the results of qualitative research because there is no way to compute an effect size, whereas the narrative review can use those results because its conclusions are not based on effect sizes. The conclusions drawn from a meta-analysis are more precise in the sense that meta-analysis can describe the magnitude as well as the existence of the effect of an independent variable. These advantages also contain an element of weakness because meta-analyses can include only studies that provide the necessary statistical information, whereas the narrative review can consider the results of studies that do not provide statistical information. In addition, meta-analyses, like all other statistical techniques, can suffer from insufficient statistical power if the number of studies is too small. Again, because of its non-statistical nature, the narrative review can draw at least tentative conclusions from a smaller number of studies. In practical terms, more studies might be available for a narrative review because it can include qualitative studies and quantitative studies that don’t provide the statistical information required for meta-analysis.
In summary, then, meta-analysis gains statistical precision at the cost of inclusiveness and the narrative review gains inclusiveness at the cost of statistical precision. The ideal literature review would therefore use the strengths of each technique to balance the weaknesses of the other by using both qualitative and quantitative elements in a review of the best evidence bearing on a hypothesis, providing what Slavin (1986) calls “best evidence” research synthesis. As Light and Pillemer (1984) observed in the context of program evaluation,
Comparison of Narrative Literature Reviews and Meta-Analysis
|
Narrative |
Meta-Analysis |
Can address broad theoretical questions |
Yes |
No |
Can include quantitative studies |
Yes |
Yes |
Can include qualitative studies |
Yes |
No |
Can identify broad patterns of results |
Yes |
No |
Precision of conclusions |
Low |
Higha |
Vulnerability to Type I errors through publication bias |
High |
High |
Vulnerability to Type II errors in studies reviewed |
High |
Low |
Requires statistical information about study outcomes |
No |
Yes |
Number of studies required |
Few |
Many |
Effi ciency for large number of studies |
Low |
High |
aWithin the limits described in the text.
Both numerical and qualitative information play key roles in a good [integrative literature review]. Quantitative procedures appeal to scientists and policy makers who experience feelings of futility when trying to develop a clear statement of “what is known.” But using them does not reduce the value of careful program descriptions, case studies, narrative reports, or expert judgment, even though this information may be difficult to quantify. We cannot afford to ignore any information that may provide solid answers. For most purposes, a review using both numerical and narrative information will outperform its one-sided counterparts. For example, formal statistical analysis is often needed to identify small effects across studies that are not apparent through casual inspection.… But qualitative analyses of program characteristics are necessary to explain the effect and to decide whether it matters for policy. (pp. 9–10)
Best evidence synthesis would first use the narrative approach to provide an overview of the theoretical, applied, and empirical issues that have guided research in the field. This overview would identify potential theoretical and methodological moderator variables that you would have to take into consideration in drawing conclusions about the effect of the independent variable, and it would identify appropriate criteria for deciding which studies to include in the review. For example, you would exclude studies that used operational definitions that were subsequently shown to be invalid. Once you have located studies, you can put them into three categories: those for which an effect size can be computed for a meta-analysis, those that used quantitative procedures but for which an effect size cannot be computed, and those using qualitative procedures. You can then use design flaw analysis to identify patterns of flaws (if any) across studies. You can use this information to categorize studies to see if outcomes vary as a function of design flaws and to determine the limits of the conclusions that can be drawn from the studies. The reviewer would then synthesize the results for each category of studies, using quantitative or qualitative methods as appropriate. You can subject quantitative studies that report no effect for the independent variable, and for which no effect size can be computed, to an analysis of their statistical power, to see if that might be a problem. Next, compare the results of the syntheses across categories of studies to see if they are consistent. If they are not, you need to see if there was any apparent reason for the inconsistencies. Finally, you interpret the results of the literature review in terms of the theoretical, applied, and empirical implications of its results.
An integrative literature review combines the outcomes of studies to draw conclusions about the effect of an independent variable. The first step in this process is operationally defining study outcome in a way that allows the reviewer to directly compare the results of different studies even though those studies might have used different operational definitions of the independent and dependent variables. For example, studies of the relationship between television violence and aggression in children have used a wide variety of operational definitions of both constructs (Hearold, 1986). How can you compare the results of studies and draw overall conclusions in such circumstances? You must develop an operational definition of study outcome that can be applied to the studies under review. Three operational definitions are commonly used (Jackson, 1980): effect size, multiple outcome categories, and a dichotomous categorization based on whether the results of the study supported or did not support the hypothesis.
Effect size. Effect size is the ideal operational definition of study outcome because it provides a precise index of the impact of the independent variable on the dependent variable. Two effect size measures are commonly used in literature reviews. When the independent variable is categorical, such as the experimental versus control conditions in an experiment, the standardized difference in the means of the two conditions, indicated by the symbol d, is used as the operational definition of outcome. The d statistic is computed as the mean of the experimental condition minus the mean of the control condition divided by the pooled, or combined, standard deviation of the conditions. Therefore, d indicates the number of standard deviations that separate the means of the two conditions. Typically, d is given a plus sign if the results are in the direction predicted by the hypothesis being tested in the review, and a minus sign if the results are opposite to the prediction. Take a hypothetical example: The hypothesis is that boys are more aggressive than girls, and a study finds a mean aggression score of 16.5 for boys and 10.9 for girls with a pooled standard deviation of 12.8. The effect size d would be computed as d = (16.5 - 10.9)/12.8 = +.44. When the independent variable is continuous, such as scores on a personality questionnaire, then the Pearson product moment correlation, r, is used as the effect size indicator. Given an effect size for each study, you can answer the question of the overall effect of the independent variable by computing the mean effect size across studies.
Both d and r require that the dependent variable in the study be continuous; however, there are also effect size indicators for categorical dependent variables that can be mathematically transformed to d and r; d and r can also be converted to one another (e.g., Boren-stein, 2009). For example, the d of +.44 computed earlier is equivalent to r = +.21.
Multiple outcome categories. One problem with the use of effect size as an operational definition of study outcome is that studies do not always report an effect size or the statistical information required to compute one. This kind of non-reporting is especially likely when the independent variable did not have a statistically significant effect. When exact effect sizes are not available, Jackson (1980) suggests the use of multiple outcome categories as a secondary tactic. A study would be put into one of five categories depending on the statistical significance of its outcome: (1) the results were statistically significant and supported the hypothesis, (2) the results were not statistically significant but did support the hypothesis, (3) the independent variable had no effect, (4) the results were not statistically significant and contradicted the hypothesis, or (5) the results were statistically significant and contradicted the hypothesis. Once all studies have been categorized, you can examine the distribution of outcomes to draw conclusions about the effect of the independent variable.
Two outcome categories. Unfortunately, not all studies provide sufficient information to allow the reviewer to use five outcome categories. Sometimes the best the reviewer can do is categorize studies as either supporting or not supporting the hypothesis based on the statistical significance of the results and draw conclusions about the effect of the independent variable by counting the “votes” for and against the hypothesis (Bushman & Wang, 2009). This vote-counting approach to literature reviewing has a serious drawback: It is highly susceptible to Type II errors—incorrectly accepting the null hypothesis (Borenstein et al., 2009). Statistical significance is strongly affected by sample size. Consequently, two studies could find identical effect sizes for an independent variable, but the study using a large sample could have a statistically significant result while the study with a small sample could have a statistically nonsignificant result. For example, an r of .25 would be statistically significant with a sample size of 100 but not with a sample size of 50. Although the outcomes are identical in terms of effect size, the first study would be classified as supporting the hypothesis and the second as not supporting it. Rossi (1990) described an example of this problem. He reported the results of two literature reviews of the same set of studies, one using the vote-counting method to operationally define study outcome and one using effect sizes. The vote-counting review concluded that the research was inconsistent, sometimes finding an effect for the independent variable and sometimes not finding an effect; however, the effect size analysis concluded that the independent variable did have an effect, albeit a small one equivalent to a correlation of about r = .18. Furthermore, Rossi noted that
the average power of [the studies reviewed] was .375, suggesting that 37.5 percent of [the] studies should have found statistically significant results, in good agreement with the observed rate of significance of 41.7 percent.… This [power] analysis suggested that the sample sizes of [the] studies were inadequate to ensure detection of the effect in most studies but were sufficient to guarantee some statistically significant results. (p. 652)
The five-category approach described earlier is also susceptible to Type II errors, but it is less susceptible than the vote-counting method because it uses more categories.
In summary, the use of effect sizes is the best approach to empirical literature reviewing (Bushman & Wang, 2009). It precisely estimates the magnitude of the effect of the independent variable and avoids the problem of Type II errors. However, not all quantitative studies provide the statistical information required to compute effect sizes, and qualitative research is not intended to provide precise estimates of effect size. In these cases, the researcher can only take a categorical approach to operationally defining study outcome.
In addition to identifying the overall effect of an independent variable, integrative literature reviews have the goal of identifying the factors that moderate that effect. To achieve this goal, you must first identify possible moderator variables, such as participant population and research setting, and then classify each study on each variable. For example, one study might use a college student sample in a laboratory setting and another might use a non-college-student sample in a field setting. Because a study might not clearly fall into only one category, classifying studies can sometimes involve relatively subjective judgments (Wanous et al., 1989). Consequently, you must be careful to check the reliability of the classifications, just as you would check the reliability of behavioral observations or the reliability of the classifications made in a content analysis (e.g., Orwin & Vevea, 2009). Once the studies have been classified, you can compare the typical outcome in one category with the typical outcome in another. For example, an independent variable might have an effect in laboratory settings but not in natural settings. However, you must also be alert for confounds among moderator variables, such as the confound between participant population and research setting in the example just given. These comparisons of outcomes between categories of studies can identify limits on the generalizability of an effect.
In addition to establishing the degree of validity of each study in a literature review as discussed earlier, it is important to look for patterns of design flaws within the set of studies being reviewed. A set of studies might all point to the same conclusion, but if the studies have one or more validity threats in common, the consistency in their results could come from the shared flaw rather than from the effect of the independent variable (Salipante, Notz, & Bigelow, 1982). Salipante et al. recommend conducting a design flaw analysis by creating a matrix, such as shown in Table 19.2, in which the rows represent the studies being reviewed and the columns represent potential validity threats. The columns in Table 19.2, for example, represent some of the internal validity threats identified by Campbell and Stanley (1963) that we discussed in Chapter 7; the matrix could, of course, be expanded to include other threats to internal validity, threats to ecological, construct, and theoretical validity, and possible confounds. In Table 19.2 an “x” indicates that the threat did not arise because the research design precluded it; for example, pretest sensitization is not a threat if the study did not use a pretest. A “√” indicates that the study included a specific control for or an assessment of the effects of the threat. A large number of blanks in a column therefore indicates that the entire set of studies suffered from a common flaw; consequently, conclusions drawn about the effects of the independent variable must be tempered by consideration of the flaw as a possible alternative explanation for the effects found. For example, Table 19.2 shows that the research reviewed (a set of quasi-experiments) generally did not control for the effects of maturation and mortality. As we noted earlier, literature reviews are important because they let us draw conclusions from a set of studies each of which has strengths that compensate for the weaknesses of the others. The design flaw matrix lets you be sure that all weaknesses are compensated, that none affect all or most of the studies.
Sample Matrix for Assessing Validity Threats
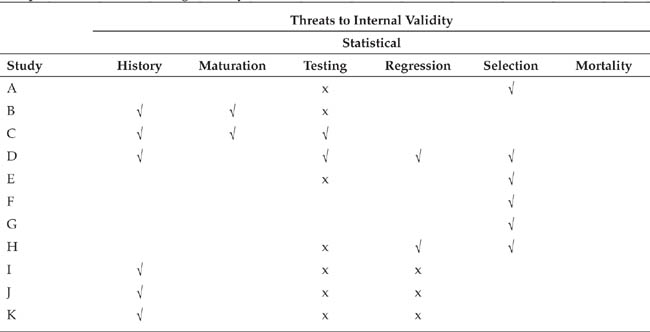
x = design precludes threat
V = study controlled for or assessed effect of threat
Note: Adapted from Salipante et al., 1982, p. 344.
An important decision that literature reviewers must make is determining the appropriate conceptual level of analysis at which to define the independent and dependent variables. Let’s say you want to conduct a literature review on the effectiveness of psychotherapy. As shown in Figure 19.1, the hypothetical construct of psychotherapy could be operationally defined at different levels of abstraction. For example, you could simply define psychotherapy as a general concept and not investigate whether different types of therapy, such as behavioral and psychodynamic therapy, have different effects. Or you could decide to compare the relative effectiveness of behavioral and psychodynamic therapy, but not investigate the relative effectiveness of specific therapeutic techniques within these general categories. Or, of course, you could conduct a very fine-grained analysis in which you compared the effectiveness of specific techniques within each of the categories. Similarly, dependent variables can be defined at various levels of abstraction.
The inappropriate combining of effect sizes or other definitions of outcome across different independent variables, dependent variables, and operational definitions of the variables is sometimes referred to as the problem of “mixing apples and oranges” (Cook & Leviton, 1980). This criticism was directed initially at a review of psychotherapy outcome studies (Smith & Glass, 1977) that combined effect sizes across different types of therapy (for example, mixing the apples of behavior therapy with the oranges of psychodynamic therapy) after initial analyses indicated no difference in outcome by type of therapy. Glass (1978) defended this approach by noting that both behavior therapy and psychodynamic therapy are subcategories of the general concept of psychotherapy and that this higher order concept was the independent variable of interest in the review; that is, he argued that it is permissible to mix apples and oranges if you’re interested in studying fruit. Such higher order combination of effect sizes is generally considered appropriate as long as two cautions are borne in mind: that such “mixed” independent variables can at times be somewhat artificial or remote from real applications (Bangert-Downs, 1986) and that effect sizes should be examined within types of independent variable to determine if effect sizes differ as a function of the type of independent variable or if moderators have different effects on different independent variables (Shadish & Sweeney, 1991). Recall Shadish and Sweeney’s finding that research setting interacted with type of psychotherapy to affect recovery rates.
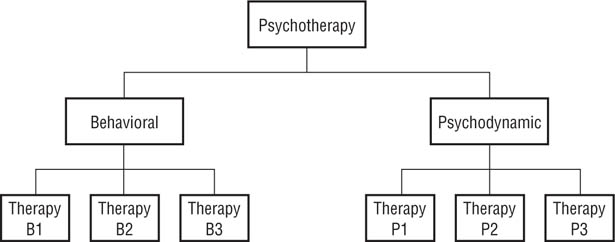
FIGURE 19.1
Defining a Concept at Different Levels of Abstraction.
In this example, the concept of psychotherapy can be defined very generally, encompassing all types of therapy; at an intermediate level, as broad categories of therapies such as behavioral and psycho-dynamic; or very narrowly as specific therapies within categories.
It is more difficult to justify mixing across dependent variables, as Smith and Glass (1977) also did, on the principle that in psychotherapy outcome was outcome regardless of whether the outcome was defined in terms of clinicians’ judgments, clients’ self-reports, or independent assessments of behavior. This tactic is risky because any one independent variable can have greatly divergent effects on different types of dependent variables. As Bangert-Downs (1986) notes,
Treatments may influence many phenomena but averaging measures of all these phenomena only confuses our picture of the treatment. A drug may cure cancer but make colds worse. Averaging these effects would obscure important information about the drug and produce a single effect size that is difficult to interpret. (p. 397)
Averaging outcomes across different operational definitions of a single independent or dependent variable is less controversial: If the operational definitions are valid indicators of the construct, the studies being reviewed should get the same pattern of results regardless of the operational definition used. It is extremely useful, however, to check this assumption of equivalence of operational definitions by treating operational definition as a moderator variable in the literature review. If no difference in outcome is found as a function of operational definition, the outcomes of the different operational definitions can be combined for further analysis; if differences are found, you must assess the implications of those differences for the validity of the research being reviewed. If, for example, there is evidence that one operational definition is more valid than another, then research using the more valid definition should be given more weight when drawing conclusions.
Because the integrative literature review is a form of research, the final stage of the process is the same as that of all research—drawing conclusions from the data and laying out the implications of those conclusions for theory, research, and application. In Chapter 17, we discussed that process, so the next section simply considers a few limitations on interpreting the results of literature reviews.
First, integrative literature reviewing is a process that involves a fairly large number of judgment calls, decisions that one person may make in one way and another person may make in another (Wanous et al., 1989). For example, if two people were to review the research on the same hypothesis, they might make different decisions about which studies to include in their reviews. One person might choose to include only published studies, whereas the other might also include any unpublished research that could be found. One consequence of this judgmental factor in literature reviewing is that the different decisions made by different reviewers may lead to different results in the literature reviews and different conclusions being drawn about the hypothesis being tested. Wanous et al. (1989), for example, describe four pairs of literature reviews that came to opposite conclusions and show how different decisions at various judgment points could have led to those conflicting conclusions.
Because differences in judgment calls can produce such large differences in conclusions, it is extremely important for literature reviewers to clearly specify the decisions they make at each point in the review process (APA Publications and Communications Board, 2008; Clarke, 2009). Literature reviewers should report the operational definitions of variables included in the review. For example, in reviewing the effects of psychotherapy, one should specify exactly what kinds of treatments were considered to be therapies for the purpose of the review and the kinds of therapies put into each subcategory used, such as behavioral or psychodynamic therapies. Similarly, one should specify the operational definitions of the dependent variables, such as anxiety or depression. Another factor that reviewers should report is the criteria they used for including studies in the review or excluding them from consideration. These criteria could include study characteristics such as validity level and participant population. Reviewers should also tell readers the methods they used to locate studies, such as computer searches of indexes (in which case the key words used should be reported), bibliographic searching, and source-by-source searching (specifying the sources searched). Finally, the reviewer should report the methods used to analyze the data, including the specific statistical techniques used for a meta-analysis. This information should be detailed enough that another person could exactly replicate the literature review. Such information allows readers to judge the adequacy of the review procedures and the validity of the conclusions that the reviewer draws.
A second point to bear in mind when interpreting the results of a literature review is that any relationships found between moderator variables and study outcomes are correlational, not causal (Borenstein et al., 2009). That is, a literature review can at best demonstrate only that there is a relationship between a moderator variable and study outcomes, not that the moderator variable caused the difference in outcomes. For example, if a literature review found that a hypothesis tended to be supported in laboratory settings but not in natural settings, the only way to determine if type of setting caused the difference in outcomes would be to conduct an experiment with type of setting as an independent variable. In addition, conditions of a moderator variable might be confounded with other characteristics of the studies. For example, the research participants in the laboratory settings might have been college students and those in natural settings, older adults. The only way to determine which variable actually moderated the effect sizes would be through an appropriately designed experiment.
Finally, it is important to temper the conclusions drawn from literature reviews with consideration of the possible effects of publication biases. As noted earlier, publication bias in favor of statistically significant outcomes may lead the literature reviewer to overestimate the impact of an independent variable. Conversely, insufficient statistical power in the studies reviewed might lead to an underestimation of the independent variable impact. Finally, you must be aware of any design flaws that are common to the studies reviewed and to interpret the results of the literature review with these flaws in mind. A set of studies might point to a common conclusion, but a common flaw would cast doubt on that conclusion.
1. |
What was the purpose of the literature review? |
a. |
Theory development, evaluation, or integration |
b. |
Problem identification |
c. |
Advocating a point of view |
d. |
Conducting a historical analysis |
e. |
Summarizing the evidence on a hypothesis |
2. |
Was the purpose of the review clearly stated? |
3. |
When the goal was to summarize the evidence on a hypothesis, was the hypothesis clearly stated so that the results of studies could be unambiguously classified as supporting or not supporting it? |
4. |
Were all relevant theories thoroughly analyzed? |
a. |
In conceptually-oriented reviews, were all relevant theories included and accurately described? |
b. |
In empirically-oriented reviews, were all relevant theories analyzed to identify variables that might moderate study outcomes and to identify the conditions required for an accurate test of the hypothesis? |
5. |
Was all relevant research thoroughly analyzed to identify methodological variables (such as operational definitions, research settings, research strategies, participant populations, etc.) that might moderate study outcome? |
Data Collection
1. |
Was the scope of the search for studies clearly stated? That is, were there clear rules regarding the characteristics of studies that are considered for inclusion in the review? |
2. |
Were all relevant sources of studies checked? |
a. |
Indexes |
b. |
Previous literature reviews on the hypothesis |
c. |
Reference lists and bibliographies from studies already located |
d. |
A manual search of relevant journals |
3. |
Were the proper search terms used with indexes? Were all variants of the terms (such as both singular and plural) and synonyms checked? |
Data Evaluation
1. |
Were the criteria used to include and exclude studies clearly stated? Were those criteria appropriate? What bias might these criteria have brought to the conclusions drawn from the review? |
How many studies were excluded from the review relative to the total number located? Was the remaining sample large enough to allow valid conclusions to be drawn? |
Data Analysis
1. |
What literature review technique was used, narrative, meta-analysis, or best evidence? Was the technique used appropriate to the purpose of the review and the nature of the research being reviewed, such as the number of quantitative and qualitative studies that have be conducted? |
2. |
What was the mean (meta-analysis) or modal (narrative review) outcome of the studies? |
3. |
How much variance was there in the study outcomes? Were there any outliers that increased the variance or skewed the mean? |
4. |
Were moderator variables used to try to explain the variance in study outcomes? |
5. |
Were clear rules established for classifying studies relative to the moderator variables? Were these rules applied reliably? |
6. |
Were there enough studies within each category of the moderator variables to permit reliable conclusions to be drawn? |
7. |
Were the studies analyzed to determine if there were any common design flaws that might call into question the validity of their overall results? |
8. |
Was a list of studies used in the review included in the report? Did the list include how each study was classified on each moderator variable? In a meta-analysis, was the effect size for each study included? |
Interpretation
1. |
Were the interpretations appropriate given the scope of the review, the types of studies included in the review (such as restriction to one participant population), and the limitations of the review technique? For example, did the conclusions from a narrative review reflect an awareness of the possibility of Type II errors? Did a meta-analysis acknowledge the possibility of inflated mean effect sizes due to publication biases? |
2. |
Were clear implications drawn for theory, research, and application? |
3. |
Were all possible interpretations of the findings considered? For example, did a review of correlational research consider both directions of causality and the possibility of third-variable influences? Were all theoretical perspectives considered? |
4. |
Was the impact of any common design flaws given full consideration? |
5. |
Were all possible confounds among moderator variables, such as laboratory experiments using only college students as participants and field studies using only non-college participants, considered in interpreting the impact of moderator variables? |
The preceding description of the process of conducting a literature review implies a set of criteria that you can use to evaluate the quality of a literature review. Box 19.1 summarizes these criteria in the form of a set of questions you can ask as you read a literature review.
Meta-analysis statistically combines the results of a set of studies of the same hypothesis to come to an overall conclusion about the effects of the independent variable and to identify variables that might moderate its effects. Meta-analysis has been increasingly used as a literature-reviewing tool over the past 35 years (Cordray & Morphy, 2009). Although this rise in the use of meta-analysis makes it look like a new technique, the basic principles have been around since the early 1900s (Shadish & Haddock, 2009); however, only relatively recently have statisticians given much attention to its formal development. Because of the importance of meta-analysis as a means of reviewing research literature, it is important to understand the technique’s strengths and weaknesses so that you can correctly interpret the results of published meta-analyses. Therefore, this section examines a sample meta-analysis. In addition, Durlak and Lipsey (1991) provide a “practitioner’s guide” to meta-analysis that discusses the important issues in the field in more detail than space allows here. The statistical procedures for conducting a meta-analysis are fairly complex, so we will not discuss them. See the suggested readings listed at the end of the chapter for more detailed discussions of conducting meta-analyses.
Let’s examine the process of conducting a meta-analysis by looking at one conducted by Johnson and Eagly (1989). Their meta-analysis is not especially better or worse than others we could have chosen, but it does illustrate the process of meta-analysis well. It also illustrates the use of moderator variables to analyze effect sizes and the use of theory-related moderator variables to understand the results of a body of research. This exploration of Johnson and Eagly’s work is organized in terms of the five stages of literature reviewing.
Johnson and Eagly (1989) drew their research question from the field of attitude change and persuasion. The question was one that has been the subject of over 60 years of theory and research: When people are exposed to a persuasive message designed to change their attitudes on an issue, does the degree to which they are personally involved in the issue affect the degree to which their attitudes change? In other words, is it easier or harder to persuade people who have a strong personal involvement in an issue to change their minds?
Johnson and Eagly (1989) began their review of the research on this question by noting that there are three theoretical approaches to answering this question, each of which has used a different operational definition of “issue involvement” in its research. One theoretical perspective focuses on what Johnson and Eagly called “value-relevant involvement,” which defines involvement as the degree to which the message recipient personally identifies with the issue under discussion; the issue is closely related to the recipient’s personal values and self-definition. In “outcome-relevant involvement,” the issue has an important, direct impact on the recipient’s life but is not necessarily linked to his or her personal value system. For example, if the message recipients are college students, involvement might be manipulated by a message dealing with raising tuition at their college (high involvement) versus raising tuition at a distant college (low involvement). With “impression-relevant involvement,” the message recipient wants to make a favorable impression on the person sending the persuasive message; that is, the recipient wants to “look good” to the persuader.
Johnson and Eagly (1989) also noted that the quality of the message—whether it used strong, relevant, and logical arguments to support its position versus weak, irrelevant, and illogical arguments—could moderate the relationship between issue involvement and persuasion, and that the three theories made different predictions about the form the interaction would take. Value-relevance theory holds that there should be no interaction between message strength and involvement: More highly involved people should be less easy to persuade regardless of the form the message takes. Impression-relevance theory also makes a simple prediction: Neither involvement nor argument strength should affect persuasion. Because the message recipients simply want to look good to the persuader, they will tell the persuader what they think he or she wants to hear, but their true attitudes are not affected. Outcome-relevance theory makes a complex prediction: When arguments are strong, highly involved people will be more persuaded than less involved people because they will give more thought to the arguments; when arguments are weak, highly involved people will be less persuaded than less involved people because they will be offended by the poor arguments the persuader made. (This is an oversimplification of outcome-relevance theory, but a full explanation would take up too much space; see Johnson & Eagly, 1989, pp. 292–293, for more detail.)
Based on their analysis of these theories, Johnson and Eagly (1989) decided to conduct a meta-analysis of the research on the relationship between issue involvement and persuasion to see which theory was best supported. Because of the theoretical importance of the operational definition of issue involvement and argument strength, they used these variables as moderators in their analysis. Note that Johnson and Eagly used a narrative literature review to identify the important theoretical issues relevant to their topic. As we will see, the results of the narrative review defined the structure of the meta-analysis.
Johnson and Eagly (1989) began their search for studies relevant to their research question by defining the type of study they wanted: “To examine the effects of the three types of involvement, we endeavored to locate all studies that had manipulated or assessed message recipients’ involvement and related this independent variable to the persuasion induced by a communication” (p. 294). They used four strategies to locate studies. First, they conducted computer searches of six indexes using the search term involvement. They also checked the reference lists and bibliographies of relevant literature review articles, books, and book chapters. In addition, they looked through the tables of contents of journals that published the largest number of involvement studies. Finally, they checked the reference lists and bibliographies of the studies they had located by other means. Although it would be interesting and useful to know the total number of studies they located, Johnson and Eagly did not report that information.
Johnson and Eagly (1989) established four criteria for including studies in their review: “(a) subjects were adults or adolescents not sampled from abnormal populations; (b) subjects received a persuasive message; (c) subjects indicated their [degree of ] acceptance of the position advocated in the message; and (d) involvement … was used in the analysis of persuasive effects” (p. 295). They also established 13 criteria for excluding studies from the review, starting with “studies with obviously confounded manipulation” (p. 294)and studies with any of 10 other methodological inadequacies. Johnson and Eagly clearly defined both “obviously confounded” and the other methodological faults. They also excluded on theoretical grounds studies that used extremely simplistic persuasive messages: “the theories underlying … involvement research … have been tailored to account for the persuasion that occurs when people are exposed to relatively complex messages” (p. 294). Finally, they excluded studies for which they could not compute an effect size. After these exclusion criteria were applied, Johnson and Eagly had a sample of 38 studies with which to conduct their meta-analysis.
Because meta-analysis is a set of techniques rather than a single method of combining results across studies (see Borenstein et al., 2009, for a comparison of methods), Johnson and Eagly (1989) had to select a technique. They chose to define effect size in terms of d (they could, of course, have chosen r) and computed the mean effect size for the entire set of studies and within the conditions of the moderating variables. In addition, they weighted the d from each study by the study’s sample size, thereby giving more importance to larger samples in computing the mean value for d. This is a standard procedure in meta-analysis because a study using a large sample provides a more accurate estimation of the true effect size than does one using a small sample.
Johnson and Eagly (1989) found a mean d for all 38 studies of –.21, indicating that higher involvement in the issue led to less persuasion. These results are consistent with value-relevance theory. When the studies were categorized on the basis of operational definition of involvement, Johnson and Eagly found that the mean d was –.48 for value-relevance studies, –.02 for outcome-relevance studies, and –.17 for impression-relevance studies. These results indicate that higher involvement led to less persuasion for value-and impressionrelevant involvement (but less so for impression relevance) and that involvement had no relationship to persuasion when involvement was defined in terms of outcome. These results are consistent with the prediction made by value-relevance theory, but not with predictions made by outcome-and impression-relevance theories. Note an important point illustrated by this set of results: A main effect for a moderator variable in meta-analysis is equivalent to an interaction between the moderator variable and the independent variable being examined in the meta-analysis. That is, the relationship between the independent variable (issue involvement, in the example given) and the dependent variable (persuasion) changes depending on the condition of the moderator variable (involvement type). The meta-analysis with involvement type as a moderator variable was therefore equivalent to a 2 (high versus low involvement) × 3 (involvement type) factorial design in an experiment.
Because both impression-relevance and outcome-relevance theories make specific predictions about argument strength, the best test of the theories comes only when both moderators are included in the analysis. These results are shown in Table 19.3. For value-relevant involvement, higher involvement resulted in less persuasion regardless of argument strength, although this effect was stronger for weak arguments. For outcome-relevant involvement, higher involvement resulted in more persuasion in response to strong arguments and less persuasion in response to weak arguments. For impression-relevant involvement, involvement was not related to persuasion regardless of argument strength. These results are all consistent with the predictions made by the respective theories.
Mean d Values for Effect of Involvement on Persuasion Moderated by Type of Issue Involvement and Argument Strength
|
Type the Issue involvement |
||
|
Value Relevent |
Outcome Relevent |
Impression Relevent |
Strong arguments |
–.28* |
.31* |
–.17 |
Weak arguments |
–.58* |
–.26* |
–.17 |
* p < .05.
Data from Johnson and Eagly, 1989.
Johnson and Eagly (1989) made a number of theoretical and methodological interpretations of these results and of other results not discussed here. One major conclusion to be drawn from the portion of their meta-analysis examined here is that there are three different types of issue involvement, each of which has different effects on persuasion when considered in conjunction with argument strength. For our purposes, however, let’s consider two lessons that their findings have for the interpretation of meta-analyses and literature reviews in general. First, these results illustrate the importance of conducting a thorough theoretical analysis of the hypothesis to be reviewed in order to identify moderator variables. Notice that the conclusions you would draw from the meta-analysis change as you move from an analysis without any moderators, to one that includes one moderator, to the final analysis with both moderators. A less thorough theoretical analysis might have overlooked a moderator variable and so led to incorrect conclusions.
The second lesson illustrated by Johnson and Eagly’s (1989) findings is the importance of including methodological moderator variables in the analysis, in this case the different operational definitions of the independent variable (which also have theoretical importance in this instance). If Eagly and Johnson had not included operational definitions as a moderator variable (a situation not included in Johnson and Eagly’s analysis, but one that can be examined with the information they provide), none of the theories would have been supported very well and there would appear to be a mass of contradictions among the results of the studies. Including the operational definition of involvement as a moderator variable resolves many of those contradictions. Note that this is an example of the apples-and-oranges problem discussed earlier: Value relevance, impression relevance, and outcome relevance are all forms of issue involvement and therefore could be considered, in Glass’s (1978) terms, “fruit.” However, in this case the type of fruit makes a big difference in terms of the conclusions one draws from the analysis.
Literature reviews can be conducted to fulfill a number of purposes: summarizing new theories, findings, research methods, and data analysis techniques for a topic; identifying linkages between theories and developing new theories from existing knowledge; evaluating the validity of theories; tracing the histories of ideas; and summarizing the research evidence on a hypothesis or set of hypotheses. The last purpose has several goals: determining how well the hypothesis (or hypotheses) is supported, determining the factors that lead to differences in outcomes across studies, and identifying the implications of the review for theory, research, and application. The results of the review can be used to decide how theories should be modified, to identify new topics for research, and to inform policy decisions.
Viewed as a form of research, the literature review has five steps. The first step is defining the research question. Literature reviews can address three questions: What is the average effect of an independent variable? Under what conditions does the independent variable have its effects (external validity)? Does an independent variable have an effect under a specified set of conditions (ecological validity)? The scope of the question must also be carefully defined. A question that is too narrow might not produce a generalizable answer, but one that is too broad might be impossible to complete—there will be too much information to deal with. Finally, literature reviews can either test specific hypotheses or be exploratory, attempting to identify the independent variables that affect a given dependent variable.
The second step in a literature review is locating relevant research. Chapter 5 described this process; also note that to find all the research that has been conducted on a topic, literature reviewers must go beyond the use of the standard indexes to other techniques such as source-by-source searching.
The third step is deciding which studies to use in the literature review. Five options exist. The first is to include all studies in the literature review; however, it might be impossible to locate all relevant studies, and this procedure could give equal weight to both good and poor research in reaching conclusions. The second option is to include only published studies. This approach makes it easy to locate studies, but the studies used in the review will reflect any publication biases that might exist. A third option is to include only valid studies, but this approach raises the question of how to grade studies on validity. Often, reviewers categorize studies in terms of level of validity and check to see if study outcomes vary as a function of validity. The fourth option, which can be used when there is an overwhelming number of studies to review, is to stratify the studies on important characteristics and randomly sample studies within strata. Finally, you can ask experts to choose the best or most important studies for inclusion in the review, but the studies reviewed will then reflect any biases the experts hold.
The fourth step in literature reviewing is integrating the results of the studies, which involves several tasks. The first task is choosing a technique for summarizing the results of the studies and relating variation in outcomes to moderator variables. Narrative literature reviews take a qualitative approach, with the reviewer verbally summarizing the results of the studies and the effects of the moderator variables. Meta-analyses are quantitative reviews based on average effect sizes across all studies and differences in average effect sizes between conditions of moderator variables. Meta-analysis and narrative literature reviews complement one another in that the strengths of one often compensate for the shortcomings of the other. The most useful approach to literature reviewing is to use the techniques in tandem.
The next task is choosing an operational definition of study outcome. Effect size is probably the best definition because it is precise and not affected by the statistical power of the studies reviewed; however, not all studies report effect sizes or the information needed to compute them. When effect sizes are not available, studies can be classified according to the degree to which they support the hypothesis; however, these classification systems are vulnerable to Type II errors when studies have low statistical power. The third task is classifying studies on potential moderator variables to determine if they are related to study outcomes. The fourth task is analyzing the validity of the studies to determine if there is a common flaw that could challenge the accuracy of the conclusions drawn from the review. The last task is determining the proper level of abstraction at which to define the independent and dependent variables. Choosing too high a level can result in combining the results of studies whose independent or dependent variables are too conceptually different to provide meaningful overall results.
The final step in literature reviewing is interpreting the results of the review. Four points should be borne in mind. First, literature reviewing involves a large number of judgments, each of which can influence the conclusions drawn from the review. Second, any relationships found between moderator variables and study outcomes are correlational, not causal. Third, the results of literature reviews can be influenced by publication biases and the statistical power of the studies. Finally, design flaws that are common to a large number of the studies can limit the validity of the conclusions drawn from the review.
In conclusion, Box 19.1 lists some questions you can use to evaluate the quality of literature reviews, both meta-analyses and narrative reviews.
Baumeister, R. F., & Leary, M. R. (1997). Writing narrative literature reviews. Review of General Psychology, 1(3), 311–320.
Bem, D. J. (1995). Writing a review article for Psychological Bulletin. Psychological Bulletin, 118(2), 172–177.
These authors provide two of the few guides to writing narrative literature reviews. They lay out the goals and distinctive characteristics of this form of research, discuss the writing process, and point out common mistakes made by writers of narrative literature reviews.
Borenstein, M., Hedges, L. V., Higgins, J. P. T., & Rothstein, H. R. (2009). Introduction to meta-analysis. Chichester, UK: Wiley.
A comprehensive guide to conducting meta-analysis that covers conceptual as well as statistical issues.
Cooper, H. (2010). Research synthesis and meta-analysis (4th ed.) Thousand Oaks, CA: Sage.
A basic how-to guide for conducting meta-analysis, going into more detail than Roberts and colleagues (below).
Cooper, H., Hedges, L. V., & Valentine, J. C. (Eds.). (2009). The handbook of research synthesis (2nd ed.). New York: Russell Sage Foundation.
The chapters in this book provide detailed information on the conceptual and statistical issues one faces when conducting a meta-analysis.
Durlak, J. A. (1995). Understanding meta-analysis. In L. G. Grimm & P. R. Yarnold (Eds.), Reading and understanding multivariate statistics (pp. 319–352). Washington, DC: American Psychological Association.
Durlak presents a broad overview of the issues involved in meta-analysis and a more detailed guide to reading and interpreting meta-analysis than we had space for here.
Hunt, M. (1997). How science takes stock: The story of meta-analysis. New York: Russell Sage Foundation.
Hunt, a science journalist, gives a history and overview of meta-analysis and describes a ways in which it has been used in medical educational, and social science research.
Hunter, J. E., & Schmidt, F. L. (2004). Methods of meta-analysis: Correcting error and bias in research findings (2nd ed.). Thousand Oaks, CA: Sage.
A very detailed guide to conducting meta-analysis, including a discussion of correcting for statistical problems such as unreliability of measures and restriction in range.
Roberts, B. W., Kuncel, N. R., Viechtbauer, & Bogg, T. (2007). Meta-analysis in personality psychology: A primer. In R. W. Robins, R. C. Fraley, & R. F. Krueger (Eds.), Handbook of research methods in personality psychology (pp. 652–672). New York: Guilford Press.
Roberts and his colleagues present a brief overview of how to conduct a meta-analysis, including both conceptual and statistical issues.
If you are planning to conduct a meta-analysis, we suggest that you read Roberts and colleagues first, then Cooper, and then Borenstein et al. and Hunter and Schmidt (especially if you are using the correlation coefficient as your effect size indicator). Use the chapters in Cooper et al. for detailed information on specific issues.
Design flaw analysis
d statistic
Integrative literature review
Meta-analysis
Narrative literature review
Primary research
1. |
Describe the purposes of literature reviews. Explain the three ways the term literature review is used in behavioral science. In what ways can the results of a literature review be used? |
2. |
Describe the types of questions literature reviews can address. How does the question addressed in a literature review affect its scope and the approach taken to answering the question? |
3. |
Guzzo et al. (1987) have stated that policy makers prefer simple, main effects conclusions from literature reviews. What do you see as the advantages and disadvantages of this approach to research synthesis? Is it proper for scientists to provide apparently simple answers, or should they insist on more complex analyses? Explain your answers. |
Describe the strategies for deciding what studies to include in a literature review. What are the advantages and disadvantages of these strategies? | |
5. |
What is theoretical validity? How can the degree of theoretical validity of the studies included in a literature review affect the conclusions drawn? |
6. |
Describe the ways of operationally defining study outcome. What are the advantages and disadvantages of each? What role does statistical power play in this process? |
7. |
Describe the process of design flaw analysis. Why is this process important to the validity of a literature review? |
8. |
What problems are involved in determining the most appropriate level of analysis at which to define the independent and dependent variables in a literature review? |
9. |
Compare and contrast the narrative and meta-analytic approaches to literature reviewing. How are these approaches affected by such issues as the types of studies each can handle and the objectivity and precision of the results each approach produces? |
10. |
What factors affect the interpretation of the results of a literature review? Explain their effects. |
11. |
What is best evidence literature reviewing? How can the strengths of meta-analysis and the narrative literature review compensate for the other technique’s limitations? |
12. |
In Psychological Bulletin, Perspectives on Psychological Science, or another journal that publishes literature reviews, look up a literature review on a topic that interests you. Critique it using the guidelines in Box 19.1. What are its strengths and weaknesses? |