11
Miscellaneous
11.1 Recipe 20: To Find Customers Who Will Potentially Churn
Industry: The recipe is relevant to publishers, finance, insurance, software, online services such as premium accounts of social networks and all industries with long-term contracts with clients.
Areas of interest: The recipe is relevant to marketing, sales and management.
Challenge: Some businesses are based on long-term contracts with less interaction between the parties, for example, contracts for most kinds of insurance and telecommunication, licensed software and daily delivered newspapers. In all of these businesses, it is pertinent to keep the customer or client in the system for as long as possible. Every customer that quits a contract too soon is lost money and is difficult to replace by a new one. It is an advantage for the companies to know in advance which customers are likely to quit and to work out ways to avoid it or to lower the probability. When customers quit or change supplier, it is referred to as customer churning (see Figure 11.1 ).
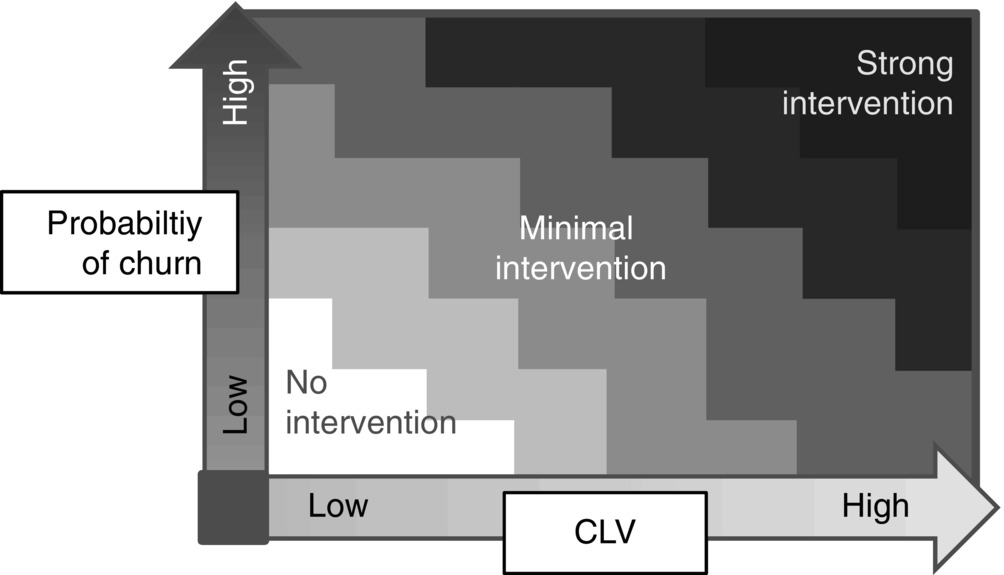
Figure 11.1 Intervention possibilities depending on churn and CLV.
Necessary data: As in other recipes, order and contract data for the single customer are very important, but because of the type of business, this information may not reflect the customer behaviour as well as it does in the retail sector, and hence, it will not be sufficient to solve the problem of predicting which customers will churn. It is vital to get access to any kind of data from customer service or related online services and also if available to have data on the individual usage of the product. For example, how often does a customer use the software or the specific service, and is their usage increasing or decreasing? Customer payment habits prove to be very valuable and also the history of any advertising actions (online or offline) directed to the customers and their reactions to them.
Population: The recipe is relevant to all customers with at least one active contract at a specific day in the past. Make sure that there is enough time to measure churn between now and the day you have chosen. Churn rates reported elsewhere may help you to decide how long the time period needs to be to model the churn. If there are any seasonal aspects that are relevant to your business, these will also influence your choice. Everyone relevant for the analysis has to have at least one active long-term contract in place on the specific day and you need to clearly define the period during which you can usefully measure the churn.
Target variable: The target variable is whether the customer churns or not. However, you have to make sure that you have included the right behaviour as churn. We have to separate whether the churn is because the customer wants to stop the contract or the overall business relationship or whether the churn is because the company itself wants to stop supplying the original product and swop the customer to a newly launched product or contract. Churn may also come about because there was a successful up-selling action and the old contract was stopped and a new one was opened. You might wonder why all of these alternatives can be mixed up with customer churn. The reason is that the business process and the corresponding data footprints are similar in each situation; there will be a data case with an opening and an end date. Ideally, you will find additional indicators or variables in the dataset that will help to qualify the real targets. As a rule of thumb, you should project forward from the customer’s viewpoint; does he or she stop the specific service completely, or do they continue with a similar or upgraded product? Another indicator might be that the closing date of the finished product or service is actually the same date as the start of a new contract. The target needed to develop a churn model is whether or not the customer quits without immediately starting a new contract.
Input data – must-haves: The following data are must-haves:
- Order and contract data (existing and former contracts or bought products)
- Data on received invoices
- Customer services/online services (like ‘my account’)
- Data on advertising activities (online and offline including newsletters)
Input data – nice to have: The following data are nice to have:
- Payment data
- Usage history of services, software or knowledge
Possible data mining methods: Comparable to the other prediction problems, you can use:
- Logistic regression, decision trees or neural nets
How to do it:
Data preparation: Even if a data warehouse is accessible for the data miner, before you start your main analysis, try to find out whether the contract or service has a specific client article number or not. In many systems, you may be faced with the fact that one contract appears in several data cases because the contract contains several product elements each with its own article number and data footprint. Without this generated pre-knowledge, one customer contract can look like three contracts in the data.
Most of the time, the number of cases with Target = 1 (churn) is small. To construct a suitable dataset that can be used for model building requires a stratification strategy.
Business issues: Firstly, as discussed earlier, take care with the internal definition of churn. It will be different from company to company. Secondly, the target definition you decide upon should be discussed with colleagues responsible for working out the strategy to avoid churn. You should note that in some cases it is easier to predict churn than to find a suitable strategy to avoid it. The prediction is only useful for the business if there are strategies in place to avoid churn having been alerted to its likelihood. Work on developing these strategies can utilise the pre-knowledge gained by the close scrutiny of the data taking place during the modelling process. For example, if advertising pressure is identified as a churn indicator, then a strategy can be worked out that will ensure that less advertising is sent to those groups particularly sensitive to it.
Transformation: The purpose of transformation is to make the final models more robust. Sometimes, strange things can happen causing oddities in the dataset, and the model needs to be robust to all these artefacts. For example, a mistake could occur at any stage in the data input or transfer, or a change in customer behaviour may be noted but not recorded properly or a comment may be added without further adjustment, or some people may end up with a quitting reason even though they did not quit. The model needs to reflect the underlying truth in the data rather than any erroneous quirks introduced during the data input and manipulation processes. For this, we need to replace missing values, exclude outliers (or ameliorate them) and smooth the data. We also need to Normalise to use methods requiring Normality and standardise to reduce the effects of differing means and variances. Apart from these more statistical aspects, transformations are also necessary to create combined variables that summarise the information in the data. From one contract, you may create several variables in the following ways:
- Calculate a variable for each service or product that says how long the customer accessed the product, in days, before the service stopped, or if it has not stopped, calculate the time until the end of the input period.
- Calculate a variable for each service or product that says how many days have elapsed since the product or service was last ordered.
- Calculate a variable for each service or product that says how many days have elapsed since it was stopped. When you calculate this variable, be careful about those people who did not quit and those people who never ordered the product. You have to think how these values will appear in the analytics.
These are just examples, and there are plenty of other combinations that could usefully be expressed as variables. Some are more complicated, for example, the time elapsed before quitting a first contract if a second one is accepted.
Transformation is very important to improve results; otherwise, models can be over-affected by vagaries in the data. Transformation is equally important where necessary for the newly calculated variables arising from the particular business requirements.
Analytics:
Partitioning the data: It has to be decided whether to split the data into training and test samples. Generally, this is the preferred option if there is enough data. If the number of cases available to ‘learn’ the model is quite small, then cross-validation might be better than data partitioning.
Pre-analytics: Pre-analytics will help give you more ideas for artificial or combined variables and to get a first clue which variables might have a relationship with the target. During this stage, it is also possible to gather important knowledge that might help the business.
Model building: We recommend using a decision tree. It has the advantage that some of the rules found might guide to potential solutions for how to avoid churn. If decision tree analysis is not available in your toolbox, you can use logistic regression or neural networks as well.
Evaluation and validation: Apart from the statistical numbers to ensure the model quality, you have to be careful that the model is reasonable in a business sense and that it can be transferred to future applications. The threshold predicted probability of churn is likely to be an issue of discussion. In general, a threshold of 0.8 (if the prediction is given on a scale 0 to 1) is a good starting point to search for the optimal threshold. Another possibility is to look for the predicted probability at the point where the cumulative lift is 2. Recall that a lift curve shows the proportion of Target = 1 (churn) customers for each predicted probability of churn divided by the actual proportion of churners in the dataset. The predicted probability of churn (on the horizontal axis) at the point on the lift chart vertical axis where customers are twice as likely to churn could be a good value to use as the threshold.
Implementation: In some companies, it is very useful to implement the model so that the results can be used at the service desk. If this is intended, then you need to make sure that the rules/models and the newly created variables can be calculated, for example, in an ERP system. Another way of implementing the models is just by calculating/applying the model regularly in the analytical environment and selecting the relevant customers for further treatment.
Hints and tips: It might be useful to discuss different treatments for different predictions.
How to sell to management: In most companies, keeping hold of long-term contracts is seen as a top priority, and so, selling the modelling and the results to management is not a problem. However, putting strategies in place to avoid churn might become a problem.
11.2 Recipe 21: Indirect Churn Based on a Discontinued Contract
The business problem behind this recipe is similar to that in Recipe 20, but the business process is different. In some countries and companies, contracts with no pre-defined end date are unusual. To clarify the issue, consider the following overview of possible variations:
- Contract with open or undefined end.
- Contract with a defined minimum end, for example, it can only be stopped by the customer after 24 months, but if the customer does not quit by a specific date, the contract will continue for another period, for example, for another year.
- Contract will end at a specific date if the customer does not extend it.
Churn with contracts of types 1 and 2 can be predicted.
Churn with contracts of type 3 can be seen as a buying problem because churn happens if the customer does not buy the service/product again (after using it before). In this case, the churn problem turns into a problem that can be solved as described in the recipes for buying affinity in Chapter 8.
Target variable: The target is quite easy, being Target = 1 for all those with an old contract who ordered again in a defined time slot and Target = 0 for those with an old contract who did not order again.
Data preparation: It is worthwhile being creative in the choice of variables including the following data if they are available:
Input data – must-haves:
- Order and contract data (existing and former contracts or bought products)
- Data on received invoices
- Customer service/online services (like ‘my account’)
- Data on advertising activities (online and offline including newsletters)
Input data – nice to have:
- Payment data
- Usage history of services, software or knowledge
If we look back to the business problem, it might be an opportunity to do a second prediction for every customer with low affinity to reorder the same product or service as they might have a higher predicted affinity for another product.
11.3 Recipe 22: Social Media Target Group Descriptions
Industry: The recipe is relevant to everybody with a strong digital marketing focus who needs to learn more about their digital target group.
Areas of interest: The recipe is relevant to marketing, sales and online promotions.
Challenge: The challenge is to learn more about the consumers who are related to the company-owned pages or accounts in social media. Based on these descriptions, the marketing strategies might be optimised.
Typical application: A typical application is defining target groups based on their social media data and behaviour. There are 3 ways to gather this information:
- Use analytics services as provided by the social network itself or by third-party companies.
- Advantage: There is fast access because the results are delivered on a summarised level and there is no need for permission to access the data.
- Disadvantage: Data is not accessible on an individual level, neither can you obtain different groupings on a similar level of aggregation to the one provided by the service.
- Use static grouping based on the data you have permission to use.
- Advantage: You can define the target group as similar to the definitions used by the marketing department based on the data you have access to.
- Disadvantage: New and so far unknown combinations might be overlooked. You have to have the permission to use the personal data and the behaviour data.
- Use analytical based grouping. This way uses clustering or Self-Organised Maps (SOM) to find homogeneous groups in the data you have permission to use.
- Advantage: You may find unexpected groupings that give you new insight.
- Disadvantage: You have to have the permission to use the personal data and the behaviour data. The new groupings may totally mismatch with all existing target group definitions.
In this social media recipe, we will concentrate on the first and second ways to gather information because the third way is a variation of Recipe 13 (clustering) and the only new aspect is how the data is used which will be described here. So, we just focus on social media-generated data and the use of given static groupings (see Figure 11.2 ).

Figure 11.2 Typical application.
Necessary data: This includes data collected when social media is used. Note that data protection rules differ from country to country. Also note that different kinds of social networks collect different data and give different data access to users compared to access given to the owners of company accounts or pages. We recommend that you consider this seriously and if in doubt ask the actual users for their permission. For example, if a user chooses to download a game or app or to use another service, then they should be asked to give their permission for their data to be used both for analytics and for further communication.
Population: The population is everybody registered or linked to a company-owned social media page or brand account in a social network.
Target variable: No target variable needed.
Input data – must-haves: This includes personal data and behaviour data (amount of post, followers, people to follow, activity on social media, etc.). The data are available through the Application Programming Interfaces (APIs) with the relevant permission.
Input data – nice to haves: A Single Sign-On (SSO) allows the user to log into a number of different systems simultaneously. If an SSO is available, then additional data for other networks might be accessible.
Possible data mining methods: The methods used are descriptive and exploratory statistical analysis.
How to do it:
Data preparation: The specific task in this recipe is the data preparation. The data out of social networks is sometimes unstructured or may follow a specific structure such as that in a JSON (JavaScript Object Notation) file. An example of a Json file is the following:
As you may have noticed, the distinctive feature of the structure is that only the available information is stored. In this structure, the variable name is given first and the value comes second, for example:
You need programming skills or the help of software to transfer this data structure into a format that is suitable for further analytics, for example, see Figure 11.3 .

Figure 11.3 Typical dataset.
The format of the original file extracted out of the social network API may be different from one network to another. So, if you do not have strong programming skills, you will need to ask the IT department for help.
Business issues: The aim is to learn more about your social media target groups, and you can use the given information to describe them better.
Transformation: After the unstructured data is put into shape for analytics, you still need to consider making transformations for good results. For example, if the data has been typed in by hand, it is likely that there will be ‘typos’ and these must be corrected. The variable ‘age’ has to be calculated and may be classified into categories. If gender is given as a code and data is assembled from several social networks, make sure that the code is the same in every network!
Analytics: Analysis of the static groups proceeds in the same way as in the experience-based approach of segmentation described in Recipe 13. To carry out this approach, first, set up the rules for the experience-based segments, for example, one segment may be women aged 18–34 years old; then, group people in the different segments with all their associated variables.
An example of potential segments is shown in Figure 11.4 .
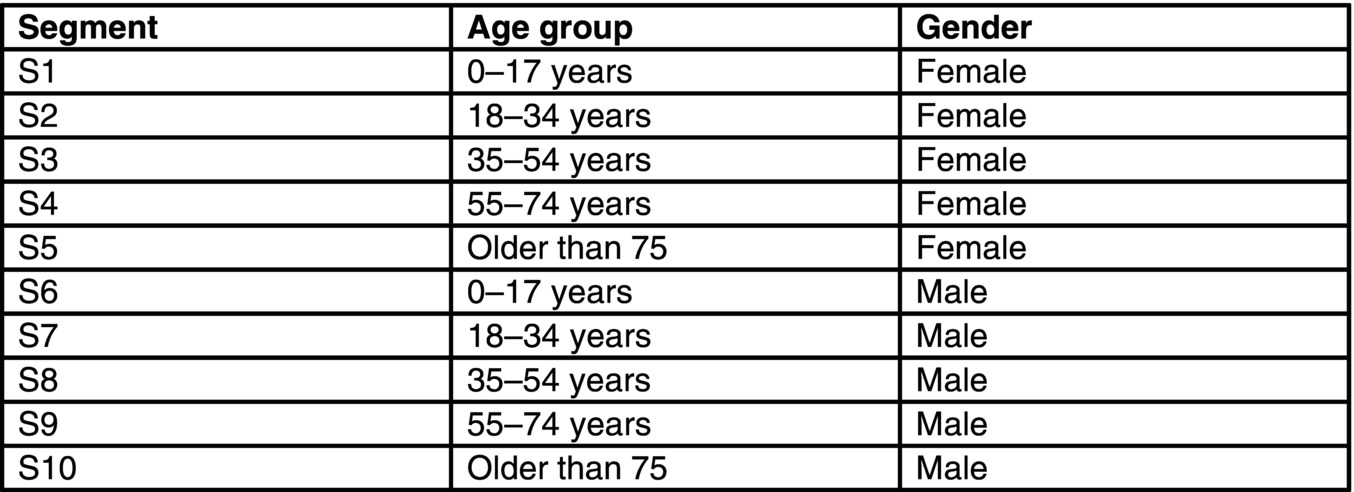
Figure 11.4 Typical segmentation.
In this approach, we calculate frequencies, ranks and means to help to describe the segments and their behaviour in detail.
Evaluation and validation: This recipe involves an unsupervised approach, and so, it is recommended to cross-check whether the results found fit in with the known picture of the target groups as learnt, for example, from market research. If they do not fit, then try to find out why.
Implementation and more: The implementation is as described in Recipe 13.
11.4 Recipe 23: Web Monitoring
Industry: The recipe is relevant to all industries, mainly those with strong customer relationships, high recommendations or owning great brands. Actually, it is most relevant to industries in business-to-consumer business.
Areas of interest: The recipe is relevant to marketing, sales and online promotions.
Challenge: The challenge is to find and learn about all bits of information, data and whispers regarding your products, service, brand, etc. Only the knowledge of those ongoing communications in the web will enable the company to interact in time (see Figure 11.5 ).
Figure 11.5 Typical application of web monitoring.
Necessary data: Web monitoring and especially text mining use words and phrases instead of numbers.
First of all, the whole web can be seen as a potential source of data. There are some public and freely available tools that claim to be able to find everything: A typical tool, for example, is ‘Google Alerts’. This tool lists every piece of news or notes every time a specified keyword or key phrase shows up. Depending on the keyword, you will end up with quite a big unstructured list of sometimes hundreds of links that may or may not contain some relevant information for you.
Generally, it is much more effective to put time into distinguishing between potentially relevant sources and potentially irrelevant sources than just checking out everything on the list so that you can go to the potentially relevant sources to find what you are looking for (see Figure 11.6 ).

Figure 11.6 A potential result.
We propose to use the following questions to find where to search first:
- Do you see your business as business to business or business to consumer?
- Who drives the decisions from the client side? A single person or a group?
- How important is image in your business?
- Are there forums, blogs or portals that you know have big impact on your business?
- What about societies, associations, printed magazines and their websites?
- What kind of social network is relevant to your industry?
- Have you ever asked a client how they search for news from your industry?
- Does your industry have an industry or subject typical language and what kind of words would a naive person use to search for the same subject? Would both groups use the same words to find the same information?
Possible data mining methods: The most common technique to do web monitoring is text mining (see Figure 11.7 ). Given the volume of text generated by business, academic and social activities – in, for example, competitor reports, research publications or customer opinions on social networking sites – text mining is highly important. Text mining offers a solution to these problems, drawing on techniques from information retrieval, natural language processing, information extraction and data mining/knowledge discovery as the following figure illustrates.
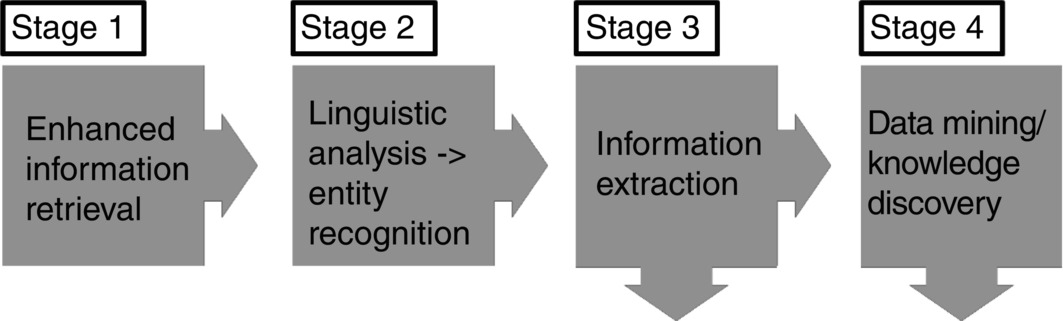
Figure 11.7 Text mining.
In essence, during enhanced information retrieval (stage 1), sophisticated keyword searches retrieve potentially relevant electronic documents. The words of the document (and associated meta-data) are then processed (stage 2), using, for example, lexical analysis (aided by domain-specific dictionaries), into a form that allows a computer to extract structured data (information) from the original unstructured text. Useful information can then be extracted from the documents (stage 3). The identified information can then be mined to find new knowledge and meaningful patterns across the retrieved documents (stage 4) which would be difficult, if not impossible, to identify without the aid of computers. Exactly how and what can be achieved depend on the licensing, format and location of the text to be mined.
Text mining is the discovery of previously unknown information or concepts from text files by automatically extracting information from several written resources using computer software. In text mining, the files mined are text files which can be of one of two forms:
- Structured text
- Unstructured text
Structured text consists of text that is organised usually within spreadsheets, whereas unstructured text is usually in the form of summaries and user reviews. Unstructured data exists in two main forms: bitmap objects and textual objects. Bitmap objects are non-language based (e.g. image, audio or video files), whereas textual objects are ‘based on written or printed language’ and predominantly include text documents.
How to do it:
Data preparation: You need to find the right places to search for information. Use our checklist in the preceding text to help set up the keyword and key phrase that reflects your business.
The usual data mining processes for predictive modelling are not suitable for text mining, so descriptive analytics and data partitioning are not necessary.
Model building: Association rules, sequence analysis and decision trees are the most commonly used families of algorithms. Apart from methods that have their roots in data mining, there are also other algorithms that have been developed, including the following:
- Token scanner: Text structure (paragraphs, titles, characters, paragraphs, etc.) and special strings (punctuation, dates, acronyms, HTML tags, etc.) are identified.
- Lexical analysis: Morphological analysis of word forms (definition of the word class with part-of-speech tagger) and the inflected form (plural/singular, etc.).
- Named entity recognition: Finding special words such as person, company, product, place names and complex dates, times and measurements.
- Parsing: Highly modularised and thus allows easy but domain-independent analysis with phrases and very domain-specific rules for the recognition of complex units.
- Core reference identity: The central task is to determine whether different linguistic objects refer to the same template instance reference. This includes determining whether different words describe the same thing or person, for example, ‘President Bush’, ‘George W. Bush’ and ‘Bush’, and the resolution of pronominal reference (references between pronouns, proper names, phrases) and references between designators (‘the software giant’) and other entities (‘Microsoft’).
- Domain-relevant pattern recognition: Finding characteristics of the heads of the extracted phrases filled with the individual characteristics of a domain-specific template instance.
- Template unification: As the information sought may be spread over several sentences and paragraphs, it is necessary to combine information from different template instances. In general, this complex task is established by unifying two templates that have at least a similar attribute which could be that they include similar words or are part of a relationship.
The latter two components require domain-specific knowledge and are very time consuming in their preparation. They require expertise and customisation and are generally automated using methods of machine learning.
Evaluation and validation: Apart from looking at the statistical numbers to ensure the model quality, you have to be careful that the model is reasonable in a business sense.
Implementation: Web monitoring results are mainly used to improve communication and public relations strategies, and they particularly influence strategies regarding the social web. Web monitoring results are not deployed in the same way as the results of prediction modelling, but they provide general background knowledge.
11.5 Recipe 24: To Predict Who is Likelyto Click on a Special Banner
This problem can be solved as a predictive model and is a variation of Recipe 1. Clicking on a specific banner is similar to reacting to a specific marketing campaign. But there are some issues that need special consideration. These issues are discussed later.
Lack of information: For most banners, there is no information available as to whether they are viewed by any user or not. For a typical direct marketing campaign, this information is usually available and can be used to limit the population to whom the marketing is directed. This is not normally possible for banners published on websites.
Disproportionate reaction rates: If we consider that a typical banner will reach a couple of million people during the time it is published but only a few hundred will click on it, we are faced with a significant mismatch between those who reacted (Target = 1) and those who did not react (Target = 0). If we compare an offline campaign such as an ordinary mailshot with using a banner, we will see a marked difference as illustrated in the following:
Mailshot (offline): Mailshot is sent to 500 000 prospects and 3 000 react giving 0.6% reaction.
Banner (online): Banner is visible to 5 000 000 people and 800 click on it giving 0.02% reaction.
Analysing the reaction to a banner requires sophisticated sampling. We recommend creating an artificial sample by taking several samples out of the 800. This could be done by taking a random sample of 500 out of the 800 and repeating this 10 times to get a dataset of 5000 for Target = 1. For the Target = 0, we recommend to take a sample of 15 000 out of the 5 000 000 people who may have seen the banner. The dataset for analysis is therefore stratified 1:3.
Shape and content of data: The shape and content of the input data is quite different. You should check how the past clicking and web usage data of users and visitors to the website is stored. It is possible that the data is online and available as a log file in which case the main focus is on creating a suitable dataset. You should end up with a dataset that is quite similar to the example dataset in the ENBIS Challenge as shown in Figure 11.8 .

Figure 11.8 ENBIS Challenge DATA.
To generate data in this sort of format, just think in general terms because it is unlikely that your variables can be transferred to future usage. This is especially true when dealing with the web as it changes so quickly. For example, consider the following situation:
You count clicks on a sub-page that contains information on a single event such as ‘election to the Bundestag 2013’. Provided you map the information to more general variables related to politics, elections, national politics, etc., then it is easy to reuse the resulting model in future, but if you sum up the clicks in a variable called ‘elections to the Bundestag 2013’, you cannot reuse the model for prediction because this event will never come back. Such a model can only be used for explanation.
Last thing to consider: The model you worked out should be fast and easy to implement in the business environment. Sometimes, the model must be translated into ‘if then else’ rules so that a system like the ‘Adserver’ can use it to send the banner out to the right people.