Allelic Variation and the Making of Race in Single Nucleotide Polymorphism–Based Research
On a hot Chicago day, I work with Pedro, a graduate student from Texas, as he retrieves samples from the 12-by-12-foot walk-in cooler. It is a welcome retreat from the Midwest heat. Pedro’s lab space is across the hall from the cooler. After shuttling a few times with Pedro as he replaces his samples and places the Styrofoam boxes onto the shelves, I notice that the shelves are loaded with such containers. Upon closer examination, I noted the inscriptions on the boxes presumably corresponding to their respective contents: “Jap 2/78,” “MexAm,” “Black,” “Utah,” “Af-Am.” Many of the boxes are more than ten years old. The array of nomenclature used to describe the populations mirrors the elasticity of ethnic identity in the United States over time and the general ambiguities of ethnic labeling. For example, labels for people of African ancestry change from “Black” to “African American” while other samples are labeled “MexAm,” “Hispanic,” or “Texas.”
The lab, I soon discover, is teeming with what I will call “racial discourse.” Racial discourse includes, among other things, labels on containers, abbreviations on reports, utterances from researchers, detailed and shorthand descriptions of human groups, and metalinguistic discussions about the origins of DNA samples. Racial discourse is productive and creative in Foucault’s sense. That is, it is not simply “groups of signs (signifying elements referring to contents or representations),” discourse consists of “practices that systematically form the objects of which they speak.”1 This book is a record of the processes of racial discursive formation that are produced, circulated, or consumed by the complex concatenation of people, places, and things that make up the diabetes enterprise.
On my first day at the lab, I phone Nora from the security desk, and she comes down to meet me. We wend our way through the maze of corridors and elevators to the endowed endocrinology research wing. Set off by richly grained wooden railings and distinctive wall and flooring color schemes, the wing houses the laboratories of Gary and three other scientists. Nora is a white woman in her mid-forties who started in Gary’s lab as a postdoc after receiving her Ph.D. in human genetics from Yale. She was Gary’s first postdoc. That was in 1982. She is now an associate professor in the departments of human genetics and medicine. Gary is a white middle-aged man who was trained in biochemistry at the University of California—San Francisco during the 1970s. He is now a professor in the departments of biochemistry and molecular biology, human genetics, and medicine.
The capital improvements of the wing are announced by gold-lettered signage that pays homage to the donor. I arrive at 11 A.M., and thirty minutes later Nora is in her first meeting of the day. A colleague from the genetics department arrived to discuss a project using “a big Mormon family”2 and a Hutterite3 data set. The scientist came to Nora to discuss typing methods, genetic markers to be used, and genotype and phenotype issues related to heritability of genes hypothesized to cause polycystic ovarian syndrome (PCOS, which is sometimes associated with diabetes) in these groups.
At 12:10 P.M., two other colleagues arrive to talk with Nora. One is an endocrinologist whose office is down the hall, a few doors away from the endowed wing, and the other is a postdoc from Nora’s dry lab. Carrying over her earlier conversation, Nora asks the endocrinologist if he would genotype a PCOS polymorphism in his samples. The researcher says it will take about a week, and talk moves to another project. Nora’s postdoc had been running statistical tests for the endocrinologist, who remarks that the findings suggest a racial admixture, which, as will be revealed, is a common theme among diabetes researchers. In this encounter, no specific ethnic label is used, and the talk quickly turns to results from another study.
Twenty minutes later Nora and I are dashing through the hospital for her next meeting. A senior colleague, a pediatric endocrinologist, sought Nora’s advice on his research. This colleague is new to research in general and newer still to genetics and statistics. He, too, is searching for PCOS genes, but the genotyping results of his ten subjects contained multiple errors. Of these ten, there are “five black samples” (which were referred to also as “African American”); the rest are “Caucasians.” After explaining the errors4 and encouraging the colleague to go back and have his genotyping redone, Nora concludes the meeting. On the walk back to the lab, Nora explains that while the pediatric endocrinologist, whom I would not see or hear about again, is likely an outstanding diagnostician and thus able to make phenotypic connections that most could not, he is not familiar with the basics of research design. He had, for example, found in his workup high levels of testosterone in his female subjects and thus spent some time trying to convince Nora (unsuccessfully) that the resultant increased musculature would confer evolutionary advantage that could be an important factor in the heritability of PCOS.
Back at her office I ask about PCOS, about the Hardy-Wienberg test, about the pediatric endocrinologist and his evolutionary theories, and about admixture. On the latter point, Nora offered the following explanation:
If we were to do a collaboration with Penn [University of Pennsylvania] using Philadelphia’s Italians and Chicago’s eastern Europeans and Poles, they could have differences based upon geographic clines [in the United States] east to west and north to south. Maybe it would be due to migration out of Africa or selective advantages. It doesn’t matter why they differ, but if you don’t control for population genetics you will miss it if one heterozygote is preferentially passed on. . . . Africans and African Americans or black samples from Europe are most likely north-to-south clinal variations. The increased similarity in allele frequency decreases the chances of clinal differences.5
Later in the day Nora has other meetings including her usual back-and-forth with Gary and responses to my queries. Most of Nora’s days consist of scheduled and impromptu meetings and phone calls, e-mails, and mail from across the corridor, the campus, the country, and continents. The volume of interactions between Nora and her collaborators make the pace of life in the lab, and thus following her physically and intellectually, very challenging. I was, at first, reluctant to intrude. Yet within days the novelty of my presence wore off, and Nora no longer introduced me as the anthropologist—à la J. K. Rowling “wearing a cloak of invisibility”—whom they should all ignore.
From this first day, the complexity of racial discourse in the diabetes enterprise was evident. The admixture narrative above reveals that the racial discourse of the lab draws upon population genetics, biological anthropology, evolution, statistics, human genetics, and physiology. Yet Nora’s use of Euro-American ethnic groups and three diverse groups with African ancestry suggests that additional knowledges inform the racial discourse of the diabetes enterprise as well. While Nora’s explanation of admixture that first day was simplistic and general—most likely for the benefit of her audience (me)—I would soon observe the complex scientific narratives about Africans, African Americans, European blacks, and a host of other groups. In fact, as I discuss in the sections and chapters that follow, Nora and her international colleagues in the diabetes enterprise routinely practice a racial discourse that troubles any notion that scientists are isolated from the social, cultural, and historical particularities of humans in the present moment. That is, racial discourse is shot through with contemporary social and historical realities.
By examining the racial discourse in the Chicago lab, my aim is to critically evaluate the race–no-race debates by elaborating the specific ways social constructions of race and ethnicity permeate the use of populations in the diabetes enterprise. This chapter sets the stage for those that follow by arguing that (1) race is not simplistically rebiologized; (2) words that describe groups are inherited from outside the labs; and (3) the rhetoric of danger that circulates in the ethical discussions about race in science and medicine is a discursive battlefield in which contested futures of racial stratification compete with one another using as evidence narratives of past abuses of medico-scientific power. To begin this discussion, I will attend to the ways scientists use and rationalize their use of ethnically labeled groups for diabetes genetics research. The racial discourse they use will be assessed for its reiteration of biological notions of racial difference in comparison with that of forensic sciences. Then I will return to the race-no-race debates to examine the ways the debates themselves stumble upon the presumption that science and society are somehow separate.
The racial discourse of the diabetes enterprise must be understood as a series of interlocking processes that involve production, circulation, and consumption of knowledges of and about disease, human biology, and ethnicity or race. Following scientists and blood samples through these discursive phases—the methodological and analytical strategy used for this research—is necessary to witness how racial discourse in the diabetes enterprise is constituted by social and material formations that are neither exclusively social nor bioscientific. By disaggregating these discursive phases we are able to see that the separation implied in the social/biological opposition is itself an artifice of a particular time and place, the explication of which is the aim of this book. We begin with the production of racial discourse as discerned in the Chicago laboratories of Gary and Nora.
In 2000, after several years of work, the main cluster of collaborator-informants with whom I work announced in the journal Nature Genetics the discovery of a polygene that confers susceptibility to type 2 diabetes. A polygene is an inherited set of genetic material from multiple chromosomes that together influence a phenotype. The report is significant for several reasons. First, it is the culmination of years of collaborative work across national, institutional, and disciplinary boundaries. Researchers from an array of disciplines and from state, corporate, and academic settings on three continents contributed to its production. Equally important is that the researchers reported having found a combination of genetic material that confers susceptibility to type 2 diabetes. As such, it was the first published report of a genetic association with disease susceptibility for a multigene disease with a rich environmental etiology. The report was so significant that it was accompanied by two commentaries, one on the methodological complexity of the report and the other a critique of the general merit of looking for genetic causes for diseases such as type 2 diabetes, which is well known to have environmental causes. The latter editorial reflects an open debate within diabetes sciences about the cost-benefit ratio of researching the genetics of complex diseases in light of the methodological complexity and immense uncertainty that the findings will result in any beneficial outcomes. The polygene finding is anthropologically interesting because the different bits of genetic material are thought to be variably found in different ethnoracial groups, which forms an important basis for the ways racial and ethnic admixture figures in diabetes science. Some diabetes scientists debate the appropriateness of using race and ethnicity at all by arguing that doing so detracts from closer scrutiny of gene locus-phenotype-trait interactions as opposed to noninteractive models. The stakes of these debates will become clearer as we examine the complex methodological approach used by researchers within the diabetes enterprise.
Genetic analysis is generally considered to be the process of drawing inferences from genetic data.6 The genetic analysis used by diabetes genetic epidemiology researchers is a statistical, computer-assisted, highly codified, and abstracted practice whereby the quantitative distribution of genetic variation is used to infer ways that known genetic material affects a phenotype.7 It is also used to hunt for genes or genetic material that affect a phenotypic group, such as diabetics, or for diabetes-specific genetic material in particular ethnic or racial populations.8 The selection of particular populations for genetic analysis is the subject of this discussion.
The process of diabetes genetic analysis, which I will unpack below, involves increasingly finer grained localization of genetic material. Imagine the levels of analysis as follows: humanity, subpopulation, diabetic versus nondiabetic, genetic material, specific bits of genetic material, combinations of specific bits of genetic material. It is complicated because researchers are looking for code within code. Whereas some diseases are caused by single genes that are always present in affected persons—that is, they follow standard Mendelian inheritance patterns—most common diseases do not follow this standard. The genetic contributions to common diseases remains elusive because they are thought to involve multiple genes or multiple variants of genes that, compared with those found in the general population, are believed to put an individual at increased risk. Complicating things further are the heterogeneous factors external to the physical body that significantly affect who gets sick and who does not. This makes complex disease gene research exponentially more complicated than research into monogenetic conditions. Because genetic analysis is principally concerned with interpreting genetic information, the practice of analysis occurs after samples have been collected and the genetic information has been extracted.
While the process is not entirely linear, it is useful to distinguish between sampling, genotyping, analysis, physiological research, drug target studies, and translational studies. Table 1 outlines the process in linear form from sampling to developing therapies. For each research practice, there are numerous steps, methods, techniques, histories, and controversies. Because diabetes genetic epidemiology is a collaborative venture requiring the participation of scientists involved in any number of areas of research, the controversies are largely glossed over until a problem arises.
The acquisition and use of population DNA is the first requirement for this kind of science. It is the raw material from which the genetic data are derived. When queried, scientists say that the rationale for the use of ethnically and racially classified populations in diabetes research has little to do with the population per se. When asked why the South Texas Mexicana/o group was used, for example, one scientist remarked,
TABLE 1 DEVELOPMENTAL MODEL OF MEDICAL GENETIC RESEARCH: SAMPLING TO THERAPY
Sampling |
Populations are identified, and DNA samples are secured. |
Genotyping and mapping |
DNA samples are scored according to the pattern of genetic markers that appear in their DNA. An array of DNA segments with known locations, genetic markers, are used to locate and identify segments of DNA of interest. |
Analysis (Association) |
Multiple gene segments in multiple individuals and groups are statistically analyzed to make inferences about the association of the gene or gene segment with disease susceptibility. |
Physiological research |
Once gene segments are identified, their function is determined in an effort to understand their role in disease pathology. |
Drug target studies |
Once researchers suspect a physiological function for the gene segments, research can focus on biochemically altering that function. |
Translational studies |
Once researchers target a physiological mechanism responsible for disease, research can focus on the efficacy of therapies that specifically address that physiological function, e.g., drugs, diet, exercise, exposure avoidance. |
“We’re not going to learn everything we need to know about the genetics of type 2 diabetes from our studies of Mexican Americans, but it’s a useful population in which to work.” Other scientists report the reasons are public health concerns. When asked why low-income Mexican Americans were sampled in a randomized way, another scientist explained, “That’s where the highest rates of diabetes are . . . and lower-income Mexican Americans have a higher rate than the suburbanites. It’s a huge public health problem.” Other reasons for the use of Mexican Americans are more pragmatically oriented to collecting samples. One geneticist remarked, “We were looking for a county in which the population was small enough that we could legitimately go in and characterize the whole county.”
When asked what the specific advantages are to sampling Mexican Americans or other groups, researchers gave more technical replies. Describing the ways scientists compare differences in the frequencies of versions of genes called “alleles,” one geneticist described it as follows:
The reason it [race/ethnicity] matters for genetic studies, why we have to really do the classification, is the following: The DNA markers that we use for these linkage studies can have markedly different allele frequency distributions in different racial and ethnic groups. If we had perfect data, where every member of the family was genotyped for our markers, it wouldn’t matter what the precise allele frequencies were because everybody would be tied [related], but for a late-onset disease like type 2. diabetes, when we collect data on a family we don’t usually have the parents, so we have to make assumptions about what the allele frequencies are in order to do our analyses. And the results of the analyses will depend on what we assume for those allele frequencies. And they can markedly affect the results, so if we think an allele is rare because, say, in the Caucasian population where we have a big survey of the allele frequency it is rare, and we say it’s rare, and we analyze data in an African American population and it’s common in that population, it may look like we have evidence for linkage there, because lots of the affected will have that allele, but it’s not shared identically by descent. It’s just because that’s a common allele in that population, and we didn’t know it was common because we used the wrong allele frequency estimated from a different racial or ethnic group [italics mine].
In other words, the use of racial or ethnic populations is explained as a means to control for the vast genetic variation that exists between and within human populations. Using populations, and, still better, members of the same families within these populations, reduces the number of variations that geneticists must contend with. Fewer allelic variations among the samples means that there is less genetic information to sift through. Further, the genetic markers used to highlight the genetics of those sampled have been developed with samples from specific populations. In short, researchers believe that racial- and ethnic-specific genetic information may ensure that important variations are not missed or, a related matter, that some populations are especially informative for some diseases.9
While the number of disease-related conditions for which the biomedical literature reports positive indications of genetic contributions increases weekly, diabetes has enjoyed a relatively long history of geneticized explanations. Neel’s thrifty genotype hypothesis, for example, postulated that such populations as North American Indians, Australian Aborigines, and Micronesian Nauru are at increased risk of diabetes because they carry genes that conferred selective advantage in times of famine.10 Now, according to the hypothesis, these peoples who have recently undergone a shift from hunter-gatherer mode of life to a modern sedentary lifestyle with concomitant energy dense food intake do not need the “thrifty genes” to rapidly convert sugars to fat. Thus, the “Coca colonization” hypothesis, as it is sometimes called, posits that recently “primitive” groups have undergone a “domestication of lifestyle” as they have moved to urban areas or lost their old way of life or both.11 According to this hypothesis, these populations have, over time, evolved genetic traits that could metabolically compensate for periods of food scarcity. Because such scarcity is no longer the norm, the theory contends, the phenotypic consequence of thrifty genes in combination with the abundance of food and sedentary lifestyle typical of contemporary urban living make for impaired metabolic regulation of glucose. In other words, diabetes, like sickle-cell anemia, is thought to result from a genetic anachronism.12
Neel’s hypothesis is predominantly environmental, that is, that the differential environments of certain groups confer significant risks. His published statements evince an uncanny reflexive modesty. For example, in revisiting his hypothesis 20 years later, Neel concludes that, “although incorrect in (physiological) detail, it may have been correct in (evolutionary) principle.”13 Neel concludes his revision with the following cautionary invitation: “All these speculations may be utterly demolished the moment the precise etiologies of NIDDM [non-insulin-dependent diabetes mellitus] become known. Until that time, however, devising fanciful hypotheses based on evolutionary principles offers an intellectual sweepstakes in which I invite you all to join.”14 The thrifty genotype hypothesis has captured the scientific imagination and underlying assumptions for why ethnically and racially identified populations have increased rates of diabetes.
The evidence for Neel’s hypothesis remains elusive, however, and likely does not exist. Among the reasons for the paltry evidence for the thrifty genotype hypothesis are false assumptions pertaining to cycles of famine and to population structures of racially labeled groups. Famine cycles did not just occur among ancestral populations of contemporary minorities: they occurred among many groups the world over. Further, the peoples referred to as indigenous hunter-gatherers (e.g., Amerindian, Nauhuatl, Aztec, Zapotec, Aborigine, etc.), are not biological but social groups. The term “Mexican” is all the more complicated to apply the thrifty genotype hypothesis to because it refers to a national group that is the result of a rich combination of many peoples. Most pertinent, the failure of genetic scientists to control for environmental factors when those factors provide stronger explanatory evidence for global prevalence patterns among ethnoracial peoples has greatly frustrated the search for genetic reasons that some believe explain higher rates of diabetes among minorities than nonminorities.15
Social epidemiological evidence points to radical lifestyle disruptions, dispossession, poverty, and other hardships particular to minority groups as strongly linked to their diabetes.16 Neel anticipated as much. In perhaps his last written statement on the thrifty genotype hypothesis, Neel writes that there is “no support to the notion that high frequency of Non Insulin Dependent Diabetes Mellitus (NIDDM) in reservation Amerindians might be due simply to an ethnic predisposition—rather, it must predominantly reflect lifestyle changes.”17 In spite of this, genetic epidemiologists argue that genetic differences, not lifestyle, explain rates of diabetes among different global populations. Drawing on research with Mexicanos/as, one diabetes consortium member writes, “There is strong evidence that Mexican Americans living in the barrio have considerably more Native Amerindian genetic admixture and as a result may have higher genetic susceptibility to diabetes.”18 And as Gary said of the protein implicated in the polygene discovery, “It smells and tastes like a thrifty gene in terms of its metabolic function.”
It would be easy to dismiss these scientists as simply behind the curve, ill informed, or somehow compromised. However, the belief that diabetes within minorities is a genetic condition and that a thrifty genotype is responsible is the dominant view among scientists and clinicians alike. This book is an attempt to explain the reasons scientists continue to pursue genetic explanations in spite of the obvious limitations of the model.
The process used to find the diabetes polygene began with the traditional epidemiological profile of diabetes. Standard clinical epidemiology was used to identify the Mexicana/o population for study. In the late 1970s, an evolutionary biologist who had been doing work in South America moved his research to Texas. He “was looking for a more local population and a disease,” recalled one geneticist. Death certificates from all 254 counties in Texas had been assessed. From this research and reports from physicians that “eighty percent of [their] patients were diabetic,” the epidemiological hot spots appeared to be clustered all along the Rio Grande. “The mortality [for this area] was about three times higher than the general population of Texas,” explained Carl, a middle-aged white human geneticist from the University of Texas and the director of the DNA collection field office along the border.
MAP 1. Image from El Camino Chamber of Commerce (2001).
Over the ensuing five years, population surveys and blood samples were taken from as many family members as possible. The samples were then, as now, genotyped—that is, scored according to the pattern of genetic markers that appear in their DNA. An array of DNA segments with known locations (“genetic markers”) were used to determine what genetic material the person with diabetes shares with his or her parents and siblings. This sharing pattern is then compared with known quantified patterns of inheritance to estimate which bits of genetic material are inherited together and thus are physically next to each other. This is an analytical method known as “linkage analysis.”
Linkage analysis determines this physical proximity by tracing the genetic material’s movement across generations. Linkage is important because the goal of genetic analysis is to find the position, identity, and, eventually, the function of the genetic material responsible for a particular disease.19 The discovery of the diabetes susceptibility polygene reported in the journal Nature Genetics was derived by a combination of positional cloning and statistical simulation.20 By tracking the inheritance patterns of known markers with those whose location is unknown, researchers could localize regions that may affect diabetes. Statistical tests determine whether two markers are likely to lie near each other on a chromosome and are therefore likely to be inherited together.
“Linkage disequilibrium” refers to patterns of inheritance of genetic material that do not occur randomly, as expected. Each person’s haplotype (shared pattern of genetic material expressed in single nucleotide polymorphisms [SNPs]) is ascertained through linkage analyses. A SNP (pronounced “snip”) is a place along a chromosome where there is allelic variation of just one nucleotide.21 Central to this concept is that there are several versions of the “same gene” that could have been inherited from a person’s parents. SNP analysis determines which version a person inherited and thus offers more specific genetic information about each individual. So, for example, a person could inherit one of two different versions of the same gene or the same version of the gene from each parent. Yet the objective of genetic analysis is to identity the precise bits of genetic material that confer susceptibility to disease. Therefore, the specific version of each gene of interest is important, since one or a combination of versions may be the culprit.
For researchers looking for clues to complex diseases, SNPs are a refinement of the gene concept. The statistical testing of inheritance patterns of SNPs between diabetics and nondiabetics, between diabetics and their affected and unaffected siblings, and between diabetics and their parents enables researchers to find the specific allelic variation that confers susceptibility to diabetes. Alleles are bits of genetic material with known effects upon a person’s body. So, for example, a gene for the color of hair is determined by the alleles one inherits from one’s parents. Diabetes genetic analysis attempts to identify the allele for diabetes by characterizing the single nucleotide variations that exist between diabetic and nondiabetic populations. For the case of type 2 diabetes polygenes, researchers first found the region(s) with the most linkage disequilibrium (nonrandom inheritance), then set about sifting through those region(s) to find the SNPs that were most closely associated with diabetes.22
At this point in the research process, the data set has been transformed from blood samples taken from individuals into graphic depictions of genetic sequences generated by computers attached to sequencing machines. Once the samples arrive at the lab, the DNA has to be purified and carefully placed in arrays of tiny wells on a plastic tray designed for use with the sequencing machine. The output from the sequencers is then entered into one of several statistical software programs created to localize genes and estimate inheritance patterns. Analysts continually tack back and forth between data sets or between multiple “runs” on the same data set to test the linkage between nucleotide markers. The analysts often run multiple data sets through multiple programs. Results come in the form of a ratio that expresses the likelihood that two markers are linked divided by the likelihood that they are not. These ratios rank the probability that nucleotides are inherited together. Anything higher than 1,000 to 1 is considered a positive indication of linkage. Those SNPs that are likely to be inherited with markers common to diabetics constitute the polygenes.
The SNPs implicated in the diabetes polygenes are from an intronic region (an allegedly noncoding region) of a gene that acts in combination with SNPs on other chromosomes. The inheritance of two different versions of the same gene is called “heterozygosity.” However, to complicate things further, what the diabetes researchers found was a model of susceptibility that consists of heterozygosity for two different patterns of genetic code. The heterozygous pattern is a result of different versions of the same allele being inherited from each parent. For the susceptibility hypotheses to hold true, each haplotype must contain the same single nucleotide polymorphism (SNP).
There is a twist to all the doubles, couples, two genes, and two versions of the same haplotype model promulgated by this admittedly complicated example. Two genes, one the heterozygous haplotype and the other located on another chromosome altogether, interact. The heterozygosity is important, say the scientists, because this model of inheritance is presumed to be the result of ethnic admixture—one part from the Mexican American’s Asian Native ancestry and the other from the Spanish Caucasian ancestry.23 The susceptibility is common in Mexican Americans, hypothesize researchers, and uncommon in Finns and Germans because the allelic frequencies of the “Caucasians” reflect homozygosity more often than the heterozygosity required for the diabetogenic affect. While the precise identities and functions of the polygenes are still unknown, the location now enables further experiments to specify their molecular and biochemical characteristics and function, which is necessary before effective new drugs can be developed to treat diabetes.
The positional cloning technique described above, in which ever finer and finer regions on chromosomes are sifted, deploys SNPs as candidate genetic material for disease susceptibility. That the groups who have donated their DNA have been classified with racial and ethnic taxa prior to their selection and sampling and thus prior to the use of SNPs makes possible what sociologist Duster has argued is “the re-emergence of race in molecular biological clothing.”24 Duster is a vocal critic of scientific practices that parse populations. He argues that the wedding of SNPs with rapid genotyping technology makes racial profiling once again imaginable, scientifically and popularly. Scientifically, the technology that enables SNPs as the units of measurement affirm another case of what Fujimura terms a “theory methods package.”25 For diabetes research, this means that theories about genetic susceptibility are made, remade, and tested through SNP technology.
What matters for the present analysis are the processes whereby racial phenotypes are presumed as real evidence for biological differences between the ethnic groups they putatively represent. The presumption of biological difference now fortified with SNP-based research will, in Duster’s view, have “real biological and social consequences.”26 Duster’s trenchant vigilance against the making and remaking of biological race and its social consequence is now, as before, right on the mark.27 Before we get too carried away with the latest tools for the genetic revolution, he cautions, the tools must be understood. Duster exposes the tautological basis of population differentiation based upon SNP analyses. “When researchers claim to be able to assign people to groups based on allele frequency at a certain number of loci, they have chosen loci that show differences between the groups they are trying to distinguish.”28 Yet, are these differences biological reiterations of racial groups?
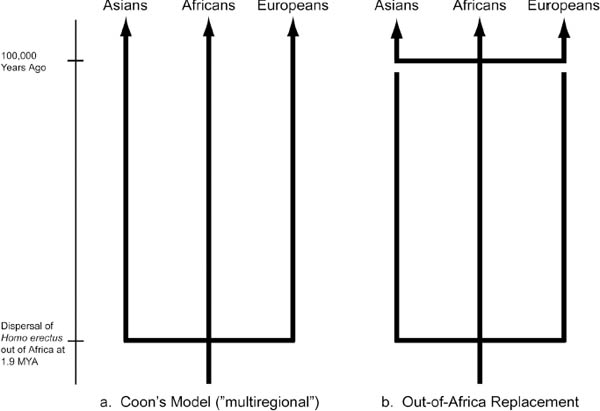
The concern that allele frequency estimates reiterate racial typologies rests on the premise that when scientists find different frequencies in human groups that those groups come to be defined by those allele frequencies. In its raw form, the belief that humans can be grouped through meaningful biological traits requires adherence to an evolutionary theory that posits that different populations evolved in isolation of one another and hence are in fact related but different subspecies. The position that races are human subspecies maintains that humans started with common erectus ancestors, migrated out of Africa as erectus and evolved into sapiens independently of one another. Evolutionary biologist and zoologist Alan Templeton refers to this as the distinct evolutionary lineages definition of “race.”29 He argues that race as a subspecies of Homo sapiens is not supported by the evidence.30
FIGURE 2. Candelabra model of evolution. Courtesy of Alan Templeton, Evolution, July 2007, 1507–1519.
Instead, Templeton offers a trellis model of continual cross-breeding between populations before, during, and after the outward migration from Africa. His critique of the out-of-Africa replacement hypothesis31 includes statistical analyses of allelic variation,32 genetic distance analyses, and various population and haplotype trees. For each kind of analysis, Templeton builds his case by weakening the data used for the candelabra evolutionary models. The candelabras are the three-pronged phylogenic model representing the three “races”—Asians, Africans, Europeans—whose origins are joined at the base by a crossbar on a single stand, the Homo erectus of Africa (fig. 2). The latest and most widely accepted version of the candelabra depicts a Homo sapiens takeover of the Homo erectus with the temporal crossbar repeated some hundred thousand years ago. But the three-pronged evolutionary pathways remain intact.
The differentiation depicted in the candelabra models are de facto biological races, argues Templeton. His trellis model (fig. 3) and the nested clade analysis (a statistical analysis of the variations on specific branches of a treelike diagram of genetic differences) of human genetic variation from which it is derived do not support the subspecies conclusion. Templeton’s trellis model shows the multiple prongs joined by continual crossbars connecting the vertical prongs. Hence, the trellis hypothesis does not support a race-as-a-subspecies proposition since through drift and flow33 we evolved together at about the same time.
FIGURE 3. Trellis model of evolution. Courtesy of Alan R. Templeton, “Haplotype Trees and Modern Human Origins,” Yearbook of Physical Anthropology 48 (2005): 33–59.
However, just because genetic scientists draw upon ethnoracial groups does not mean that they adhere to a subspecies theory. In fact, to argue that scientists are simplistically re-creating “race as subspecies” is unsupported by those studies, including the present one, where direct observation of scientific use of DNA acquired from racial and ethnic groups occurs.34 For example, anthropologist Duana Fullwiley found that there is a slippage between scientists’ understanding of evolutionary human difference resulting from migration, geographic isolation, food, disease, toxins, diseases, and social histories and those population monikers set forth by the U.S. Census, lay taxonomies, or self-identifiers.35 When queried directly, Fullwiley finds that scientists’ use of race is either a source of confusion or a reiteration of “five human types”36 corresponding to fractional percentages of genetic similarity. However, the closer one examines these genetic similarities, the more troubled with taxonomic uncertainty they become. Racial taxa become molecularized when intergroup genetic variation comes to stand in for intergroup difference along categorical lines set forth by U.S. government policies.37
Fullwiley (2008) details the way genetic scientists seeking to care for the health needs of their own ethnically defined communities craft biologistical constructions of race by selectively packaging DNA markers to craft composite populations.38 The populations scientists compose, Fullwiley writes, are comprised of Old World races and assembled to fit New World populations that map specifically onto U.S. categories of human difference (e.g., black, Puerto Rican, Hispanic, Native American, and so on). The theory method package is called ancestry informative markers (AIMs), and it is used in the emergent industry of recreational genomics and the older industry of forensic genomics.39 Fullwiley demonstrates how in the face of molecular-based evidence to the contrary, scientists’ commitments to the idea that there are three or five races of humans remain through a process of reframing—that is, by making the data fit a priori commitments. The conceptual distinction between human types and human subspecies is best understood as a linguistic sleight of hand wherein Fullwiley’s clearest interlocutor references typological difference, suggesting a mere linguistic convenience, when his definition of those typologies rest upon biologic human variation. Hence, while the overt reference to subspecies is avoided, the de facto definition of human types indeed reiterates these premises of difference.
Drawing upon Templeton and Fullwiley, the remainder of this chapter will refer to race as the representation of humans as if genetically distinct groups, subspecies, or types when such representation occurs (a) without reference to a definition of race or ethnicity, (b) without a qualification that such differences are estimates only, and (c) without the qualification that the genetic distinctions that can be estimated must be understood as variation along a continuous gradual geographically patterned clinal distribution of genetic variation.40 In other words, not merely subspecies counts as “race.” Rather, it is the unqualified use of biogenetic variation as if the populations represented anything more than the group from whom the DNA was taken. This will be the operational definition of race that will be used to tease out the dynamic meaning(s) of such words as “Mexican,” “black,” “Caucasian,” “Polish,” “Italian,” “Amish,” or “Hutterite” within the racial discourse of the diabetes enterprise.
The analyses of American Diabetes Association abstracts presented in the introduction demonstrates the profoundly social basis for the definition of the populations even before their DNA is used for the hunt for “meaningful” loci. However, what still requires an explanation is if a single nucleotide variant comes to be coded for “race” in the first place. Nor is it clear that biological race is what is meant when SNPs are used to identify populations. Careful scrutiny of the use of SNPs derived from racially and ethnically classified populations reveals a more complicated use of race.
At issue is whether the very use of race and ethnicity in medical science reiterates biological differences among Homo sapiens. Over the 20-month period I studied genetic epidemiologists at their benches, in their computer labs, at their DNA acquisition centers in Texas, and at numerous formal and informal meetings, I heard no one claim that his or her use of Mexicanas/os or African Americans or whites constituted evidence of differences between populations. However, the definition of race was never made explicit, and the clinal distributions of nucleotide variants were rarely noted. A notable exception was when Nora used clines in her description of why population admixture is important. Most of the time, however, qualifications of estimates and clines were absent, and definitions of “race or ethnicity” never occurred. Researchers were, after all, convinced of the relative homogeneity of Sun County Mexicanos through the admixture estimates reported in the literature. That these admixture profiles were estimates was the only consistent qualifier within the discussions of genetic variation. This occurred almost exclusively in the quantitative analyses and rarely if ever by Carl, his workers for the Sun County field office, or clinicians familiar with the diabetes enterprise. Similarly, the molecular biologists and clinical researchers spoke of population and group genetic differences without qualifiers of “estimates,” geographic clinal distributions, or definitions of race or ethnicity. For all but the most careful researchers, diabetes is spoken about as a genetic condition, and specific SNPs as proxies for evidence of differences between populations labeled with ethnoracial taxa. Much of this racialization can be explained through the Janus-faced definition of Genetic Epidemiology, the field to which Nora and colleagues belong.
Genetic Epidemiology: The use of populations to understand the genetics of disease.
Genetic Epidemiology: The use of genetics to understand disease in populations.
The difference between these two formulations, albeit simplified, is best understood by reexamining the reasons that researchers give for the use of population DNA. Duster argues that SNPs have their racializing potential because race is a biological classification that persists, in Marks’ words, as a “way of thinking.”41 Duster cites several examples of the socially objectionable ways this “way of thinking” could be bolstered by SNP-based research. His examples include forensic identification, blood quantum indices, and the making “of arbitrary [emphasis mine] groupings of populations (geographic, linguistic, self-identified by faith, identified by other by physiognomy, etc.)” with statistically significant allelic variations.42
On this last point I build upon Duster’s conclusions by pointing to the fact that population groupings are far from arbitrary. It is the conditions rendering these social groupings possible that make the biogenetic reiteration of race imaginable in the first place. That is, it is precisely because the populations used in diabetes research have an a priori ethnic identity that SNPs can be imbued with their racializing potential. Had the DNA used for diabetes research not been labeled with the population taxa, the SNPs would have no upstream ethnic or racial group to be attached to, nor would it matter for the “discovery” of the diabetes polygenes. Duster reveals that the use of SNPs for group identification is founded upon allelic variations already selected to show group identification—a logical tautology. SNPs A, B, and C are (found in) X group. SNPs A, B and C are found in person Y. Therefore, person Y is of X group.
Duster goes on to suggest that the next iteration of this logic is as follows: Most of the time, group X’s members share SNPs A–C, and group Y’s members share SNPs B–D. Therefore, group X is genetically different from group Y. Reminiscent of the infamous syphilis experiment of Tuskegee,43 of the U.S. government’s establishment of Indian blood quantum authentication measures and the genocide it represents,44 and of the invasiveness of forensic sampling on an already ethnically predetermined population of people, Duster alerts us to a science that can be used to discriminate between individuals based upon the purported biological differences between ethnic groups. The effort to find the genetic contribution to diabetes concerns us here for its potential to discriminate between Mexicanas/os and non-Mexicanas/os based upon the genetic differences purportedly discovered by the scientists within the diabetes research enterprise.
Part of the conundrum of race in the genomic era is that the same genetic methodologies used in medical research are used in forensic science. Two campus visitors with whom Nora made appointments are worth noting. The first worked in a lab in the U.S. South that specialized in admixture estimates using Alus, which are mobile chunks of common genetic elements with particular recombination patterns. The researcher worked in a lab that had funding from the CIA for forensics research. The second was a computational theorist from an internationally known computer firm who met with Nora to discuss his computational network theories. He noted that his theories were being developed for forensics as well as medical applications. Nora was interested in meeting with them because both Alus and computational network theories might aid in her admixture estimates and other methodological challenges. The year was 1999, and the scientific defense about the usefulness of race, racial admixture, and even American racial taxa had not yet surfaced.45 Researchers were still simply reporting specific markers or other statistically significant loci at conferences and in the literature.46
Recent ethnographic work with scientists using AIMs, which scientists claim can identify the ancestry of the DNA donor, reveals how these specific genetic markers are now used to configure racial groups. Detailing the use of ethnoracial populations that circulate through a San Francisco genetics lab, Fullwiley illustrates that AIMs configure biologistical ancestral groups that parallel old forms of racial thinking.47 Fullwiley shows how AIMs are a technoscientific model of human variation that meets specific historical, financial, and medical purposes—to wit, to find old racial groups often corresponding to the five races of man. Following a pattern of tautological reasoning and other data-framing techniques, AIMs researchers select those markers and loci that are most likely to fit North American ideas about racial groups. As Bolnick, Duster, and others have observed, scientists reify race as a biological phenomenon because the genetic technology they use finds those groups they set out to find.48 As Fullwiley notes of the alleles chosen for a given AIM, “The very continents and peoples chosen for this product were selected due to their perceived proximity to what we in North America imagine race to be.”49 For those researchers with whom Fullwiley worked, “making race” was not only acceptable, it was the point of their work.
Forensic anthropology contains its own racial logics. Surveying the field of forensic anthropology, Smay and Armelagos argue that race is used along a continuum from natural category to unsupportable by biologic observation.50 In the race-as-a-natural-category camp, researchers uncritically use race as “clear cut biological categories.”51 Researchers such as Rhine, for example, use the race concept as a valid way to biologically parse human populations.52 It does not seem to matter to those who fall into this category that their work is outside the debates about biological race.
The second school of thought Smay and Armelagos identify is the race-as-Newtonian-physics position. Scientists who fit into this category, they argue, understand that while it may not be precise, delineating humans by racial typology is close enough for applied work.53 As the category’s name suggests, Smay and Armelagos compare this race usage to Newtonian physics, which, though inaccurate in light of the theories of relativity, still can be used to explain a particular class of events that affect human day-to-day affairs.
The third school of thought, observe Smay and Armelagos, is the race-as-a-necessary-evil position. Forensic anthropologists who adhere to this position are stuck in a professional hard place.54 While bearing questionable scientific merit, racial typing of forensic evidence is required by the medical-legal exigencies of their profession. For these anthropologists, it is important to accurately label, not question the validity of the label. In other words, the forensic anthropologists’ role is to make an educated determination as to “how the person would have been identified in life”55 to help identify human remains, find missing persons, and be used for other forensic purposes.
Finally, Smay and Armelagos discuss the group of researchers who argue for the nonexistence and nonutility of race.56 These researchers argue that forensic anthropologists—from whatever camp—or any other scientists, for that matter, who use folk taxonomies are irresponsible. Their position is that scientists who use racially identified populations for research support the false lay assumption that race is biological and thus perpetuate racism.57 “Nothing is to be gained by using a model that we not only know is unsupported by data, but also to be potentially socially destructive,” the authors write.58 Smay and Armelagos conclude that the public is not ready to do away with race, and hence those scholars who argue against it fight against the social tide even though their position is supported by the evidence.59
So where do Nora and her collaborators fit within these racialization rubrics? One day over lunch, I mentioned to Nora that I would be gone for a few days attending the American Anthropological Association meetings. I remarked that I would be giving a paper titled “Social Prescriptions: Race, drugs, and the making of diabetes-gene-carrier-populations.” Nora protested, “We didn’t make these [populations]; we inherit the population descriptions from [those who collect the samples].” For her, disease-gene-carrier populations were not made at all. They were, in fact, already in existence prior to her involvement. This inherited factor does not mean that Nora and colleagues think that race is real. For Nora, the Mexican American taxonomy in her publication is, like the necessary evil group evaluated by Smay and Armelagos, good enough for her purposes. The labels are not accurate, but they work for their research.
My interlocutors argue that the SNPs that comprise the at-risk haplotype for diabetes do not code for race as a biological or social category. Rather, they are simply allelic variations found in Mexican Americans, Finns, Germans, and Zapotec Indians but in different frequencies. In fact, Nora and Gary publicly object to the presumption that their work pertains to specific ethnic or racial populations. “We’re trying to understand the molecular basis for the disease,” explains Gary.60 The goals of Nora’s work are to understand the biological contributions to disease susceptibility that can be applied to all humans. This proposition is one that forensic sciences cannot as easily claim. “We are [universal] human geneticists,” Nora’s mentor, Gary, said, angrily decrying Nature Genetics’ insistence on a Mexican American label for the title of one of their publications.
Gary’s point is that the consequences of diabetes genetics research—a better understanding of the molecular basis for the biological contribution to a complex disease—affects us all. In other words, what affects Mexican Americans affects us all. However, the robust usage of population genetics requires continual vigilance against inaccurate assumptions about the meaning of admixture. For example, Nora wondered out loud while reading a paper if the notion that Asians are more homogeneous is biased. “Most of the admixture studies are between black and white (populations)” she remarked. And when I asked about the accuracy of the admixture estimates of the Mexican data set, she replied: “We’ve got one haplotype for Caucasians and one for Native Americans. We assume a homogeneous Mexican American population randomly mating. But that’s not the case, really. Some of our families could be first-generation admixtures and some old longtime admixed. Without knowing this, my evidence for linkage is compromised.” Polygenes and SNPs, they argue, are universally distributed genetic material that occur at different frequencies. Getting those frequencies right is the aim of Nora’s work. Thus, while SNPs are being used for analyses of genomewide significance, they are not used to identify genes specific to any one group. Nora and Gary would like to know the genetics of populations because they want to understand the biology of the disease, not the biology of the group.
In other words, Gary and Nora work as genetic epidemiologists who borrow existing taxonomies as a means to a scientific end. Recall the labels on the Styrofoam boxes Pedro handled in the walk in cooler; boxes that were labeled by dozens of lab or field office workers over decades of research. These labels were obviously inherited from the census and other sociopolitics of identity at work during the era in which they were collected. It is difficult thus to claim that Nora and Gary are reiterating biological race even though they use racially and ethnically labeled DNA. The population identifiers simply denote the ethnoracial identity of the donors as understood and practiced by scientists at the time and place of DNA donation. I am not saying that the racial discourse of Gary and Nora are exceptions to the productive capacities of discursive formation. Rather, I am saying that the reiterations, if they exist, do not originate in the laboratory. To resolve this puzzle first requires that we look again at the no-race critique.
An examination of the arguments in the no-race debate reveals the complexity of racial discourse in and out of the diabetes enterprise. To make his argument, Duster cites the principle that “physical variation in the human species have no meaning except the social ones that humans put on them,” which is taken from the American Anthropological Association’s Statement on race.61 Duster argues that the association’s statement gives the impression that the biological meanings that scientists attribute to race are biological facts, while the social meanings that lay persons give to race are either (1) errors or mere artificial constructions, or (2) ideas incapable of feedback loops into the biochemical, neurophysiological, and cellular aspects of our bodies.62
Although correct in his critique, it is ironic that in interpreting the AAA statement as a misunderstanding of the social construction of race, Duster—not the statement—constructs the separation between biological facts and social ones. It must be remembered that scientists place social meanings onto the physical variations they construct.
A conversation with Sally, a quantitative geneticist who works in Nora’s dry lab, illustrates a related example of how the social is always already part and parcel of genetic analysis. While explaining the ways she incorporates multiple variables into her algorithms, she noted:
The nature of our health care system makes age of onset not a good indicator because people don’t go to the doctor when symptoms appear . . . and the poorer a person is, the longer they have lived with the disease. In France and the UK, where there exists state-sponsored health care, age of onset is a good variable to work with.
Here we see how the health care system of the United States affects the algorithms used by computational scientists. This is far from a knowledge-making practice isolated from the social world by method or statistics. This is the norm. As I will show in subsequent chapters, the social, historical, political, and economic conditions that make populations intelligible are always already part and parcel of DNA research. After all, without bodies (however labeled, classified, and segregated) there could be no genetic knowledge.
Of course SNPs will be used to discriminate between individuals and populations. That is their function. But the population groupings are already established. There is nothing arbitrary about the geographic, linguistic, and other means by which we identify and are identified by others. SNP-based research that is used to ethnically classify people reiterates an old taxonomic system that has been shown to be profoundly social. However, they—or DNA more generally—can also be used to exonerate death row inmates or to better understand the biology of disease. To denounce SNP-based research as having “some not-so-hidden potential to be used for a variety of forensic purposes in the development and ‘authentication’ of typologies of human ethnicity and race”63 is to overly emphasize the technology at the expense of the context and conditions for its production and use. Thus, an understanding of the co-configuration of populations and discriminating medical-genetic technologies is obscured rather than clarified.
I share the call for empirically grounded characterizations of the ways race becomes biological, but not that for summary dismissals.64 My concern with a no-race critique is not with the conclusions. Rather, my concern is with any argument that dismisses out of hand any instance where race seemingly appears in science. Even in Duster’s account, the slippage between the biological and the social that his argument constructs seems objectionable. Calling attention to the potential of new genetic technologies to be used to bolster knowledge that has been shown to support prejudice, discrimination, and genocide is an important contribution. However, equal vigilance must be paid to the complicated ways social analysts of technoscience reiterate the false binaries of society/science and of scientist and laity. As Marks notes, “Merely calling racial issues ‘racial’ may serve to load the discussion with reified patterns of biological variation and to focus on biology rather than on the social inequalities at the heart of the problem.”65 In this regard, my task here is to unpack race in practice (as subspecies, subtype, and social category) to tease out the cultural processes and sociological consequences of deploying race and ethnic categories in the genomic milieu.66
While we must be vigilant about the varied uses of SNPs in science, we must also strive to document the conditions that make SNP research possible and productive. This means detailing the political, economic, social, and scientific exigencies of SNP-based research practices. In this chapter, I have focused on the latter. To be sure, SNPs or, more precisely, the population-specific haplotype groups that are constructed out of them, are textual representations of a priori classifications of groups. These representations are neither arbitrary nor inconsequential.
Drawing upon Bakhtin, linguist Fairclough notes that a text at times can be both repetitive or creative.67 That is, the use of a text (or label, in this instance) can reproduce social conditions by drawing upon historically particular discursive practices. “Texts negotiate the sociocultural contradictions and more loosely ‘differences’ which are thrown up in social situations, indeed they constitute a form in which social struggles are acted out.”68 Yet, as the use of ethnic and group labels within the diabetes enterprise illustrates, the productive power of texts is only discernable within specific procedures of meaning making. Neither the scientific nor the sociological should ever be made to appear as standing alone.
To press the point further: the social conditions that underlay the use of DNA and the written, printed, computational or visual texts or utterances of ethnoracial taxa that name this genetic material remain to be explained if consequences are to be discerned, prevented, or enabled. Neither the labels alone nor the means of their acquisition are sufficient. My interests are the conditions that make such problems themselves imaginable. This is not for the sake of our imagination alone, but rather so that we can appreciate our contemporary predicament in transformatively productive ways. And to do that well, we should trouble the borders and bodies crafted of the natures/cultures of race, science, and disease.69 To merely pronounce, even after carefully presented ethnographic evidence, that race is biological here or social there profoundly misses the most interesting and important part of this story. To wit, the impulse to make race one or the other, social or biological, drives the material and semiotic interplay within chronic disease genetics. Just as the normal and pathological were made manifest by the physiologists’ and physicians’ work to separate the two,70 the undisciplined (social, biological, humanist, juridical) pursuit of the causes and consequences of disease and race by a heterogeneously preoccupied and interested host of corporate, state, and academic scientific actors is itself bringing the “apparatus of naturalcultural production,” into being.71 This is the cultural phenomena that captures our attention. It is the impossible and unbearable predicament of attending to an instance of biosocial negotiation haunted by eugenics and the future perils of disease epidemics among socially, economically, and otherwise marginalized peoples. It is this predicament of culture that has vexed anthropology since Franz Boas’s attempts to demonstrate the inadequacies of craniometry or Montague’s critique of physical anthropology.72 That is, how to account for human variation without reiterating the “apparatus of naturalcultural production,” which presumes that human variation can ever be explained as either social or biological.
We see that the labels that Nora and Gary use are inherited from outside the lab. Further, Gary and Nora are not interested in SNPs in order to produce genetic differences between populations. Do Gary and Nora rebiologize the populations by using them in their research? What I have found in diabetes research is not the constructing of biological race as a human evolutionary subspecies or even human types.73 Duster’s point, however, is that race is real if people believe it is. For Duster, SNP research supports this belief because SNPs make biological differences between racially labeled people imaginable.
Fullwiley’s direct queries to pharmacogenomic scientists about their concepts of race and Kahn’s interrogation of the consequences and economic motives behind an “ethnic drug” BiDil are instructive here.74 Allelic variation and the computer simulations it inspires provide analytical tools with which diabetes researchers hunt for genetic contributions to diabetes. What concerns us here in assessing the diabetes enterprise are those categories that make and are made from scientific knowledge and the local sites of origin of those categories. I ask the reader to withhold full determination of the productive capacity to make biological race through SNP technology deployed within diabetes genetic epidemiology until beliefs about racial difference are shown to accompany material consequences of those beliefs—in other words, until racial discourse within the diabetes enterprise has been fully characterized.
Diabetes scientists I worked with do not make evolutionary arguments about race per se. They instead make strategic use of racially labeled data sets because those are what are available. Therefore, it would be inaccurate to argue that the content of diabetes discourse relies upon subspecies arguments even though their labels suggest it. To conclude at this stage—as some critics would—that Gary and Nora are racists simply because they use population-based genetics for diabetes research ends the discussion precisely where it should begin. This is not to say that a present practice should not be assessed for its consequences. In this chapter I have intentionally maintained a presentist pretense to disentangle the specific procedures that make racial discursive formation productive of social relations of inequality based upon presumptions of essential difference.75 That is, I have not analytically linked Gary’s and Nora’s use of ethnoracially labeled DNA to historical abuses of science. To fully appreciate the downstream consequences of the present-day practices of genetic epidemiology, it is far better to begin with an ethnographic characterization of the co-configuration of biology and society.
Returning to the rhetorical question posed earlier in this chapter: If there is no genetic basis for racial classification, why does it persist? The conundrum for human genetics in all its expressions (genomics, medicine, forensics, anthropology) lies in the social underpinnings of race. That is, it is important to recognize that race, while not a biologically based phenomenon, is a social one that appears in biomedical milieu just as it appears in the popular imagination. Because the distinction between the biomedical and popular imaginations is artificial, the no-race school of thought warrants our attention. For it cannot be argued that race has no consequence in the legal, corporate, educational, and workaday world of American towns and cities, as even a superficial interrogation of the U.S. judicial system demonstrates.
This book begins with the race/no-race conundrum precisely because it is the aim of this project to offer ethnographic evidence to the no-race school of thought. I do not pretend neutrality. Drawing upon Omi and Winant, I suggest that race be thought of as “a concept which signifies and symbolizes social conflicts and interests by referring to different types of human bodies.”76 The differences in human bodies are not, as Duster and Omi and Winant imply, arbitrary.77 They are derived from a complicated interplay of the processes of scientific knowledge production and contemporary political exigencies, processes this book seeks to productively explode.
In this chapter, I have argued that (1) words that describe groups are inherited from outside the labs, and (2) population taxonomies used in Nora’s and Gary’s lab are entirely social. I have also shown that in misrecognizing that science and society are inseparable, critics of race in medicine make present-day predictions of future social consequences based upon past abuses of race in science and medicine. Thus, the critiques of race in science on the grounds that it rebiologizes race imputes a power to “science” it does not have. The racialization and the pernicious effects of claiming that groups are biologically different are a function of racial discursive formation. These discursive formations are crafted of procedures “whose role is to avert its powers and its dangers, to cope with chance events, to evade its ponderous, awesome, materiality.”78 It is a materiality that will be more evident as we analytically detail other phases of knowledge production within the diabetes enterprise.
In the next chapter, I will detail the process of data gathering along the border between the United States and Mexico. This will initiate a narrative device that will follow DNA samples from their point of origin to the production and consumption of diabetes knowledges. Beginning on the border, where the diabetes enterprise first acquires data derived from Mexicanas/os, will enable an understanding of the workings of racial formation wherein the “different types of human bodies forged out of specific social conflicts and interests” will be made explicit. Thus echoing Omi’s and Winant’s concept of racial formation, Visweswaran asserts, “Races certainly exist, but they have no biological meaning outside the social significance we attach to biological explanation itself.”79 Such explanation is far from arbitrary. Failure to recognize that race is different from social and political difference is to forget that “the category of nature (or biology) is itself founded on the cultural distinction between nature and culture.”80 Thus Visweswaran writes:
The middle passage, slavery, and the experience of racial terror produce a race of African Americans out of subjects drawn from different cultures.81 Genocide, forced removal to reservations, and the experience of racial terror make Native Americans subjects drawn from different linguistic and tribal affiliations: a race. War relocation camps, legal exclusion, and the experience of discrimination make Asian American subjects drawn from different cultural and linguistic backgrounds: a race. The process of forming the southwestern states of the United States through conquest and subjugation and the continued subordination of Puerto Rico constitute Chicanos and Puerto Ricans as races.82
The question is not whether race is biological and whether its use in genetic sciences necessarily leads to harm. Rather the question is; Can genetics researchers looking into an important medical condition afford to misrecognize the fundamentally social meaning of race in understanding patterns of disease and health? That is, can researchers interested in the etiology of disease ignore the impact of discriminatory experiences and social inequality on marriage, diet, educational and occupational attainment, access to health care, healthy living and working environments? More important, if they can, why?