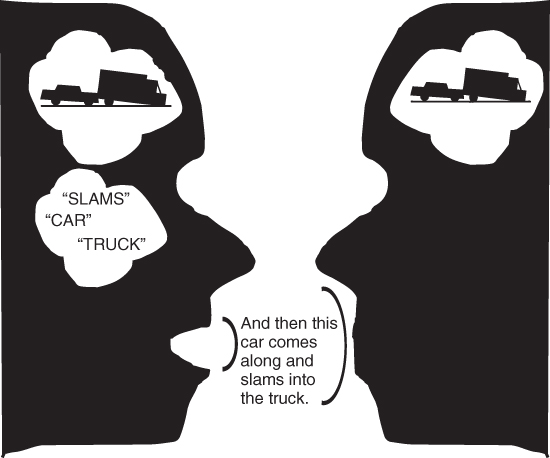
Figure 9.1 Outline of the communicative act: Speaker has in mind a scene of a car hitting a truck, and communicates it to a listener.
Language may be the behavior that is most uniquely human. Most everything else that we do has reasonably close correspondence with behaviors in other species. Animals engage in complex social behavior; they are able to learn based on observation and imitation of others; they are able to remember various types of information, such as the location of key food areas or the identification of familiar individuals; they can solve problems; and more. Many animals also communicate with members of their species in various ways—through production of sounds, visual displays, and pheromones—but no species other than humans is able to use the complex, highly structured, open system that is language (Hauser, Chomsky, & Fitch, 2002;Pinker, 1994). There have been several attempts to teach highly intelligent animals, such as chimpanzees and gorillas, to use specially designed visually based languages (since their vocal apparatus is not geared toward spoken speech), but the consensus is that what they are able to acquire is not nearly up to the skill level of an average 3-year-old child (Pinker, 1994). Humans therefore may be unique in the animal kingdom as a species with language. That possibility alone would make language worthy of study.
However, language is also central to our social and intellectual lives. We use language not only to communicate with other people, but to help us solve problems, remember information (e.g., through verbal rehearsal), and engage in creative activities (e.g., writing a short story). Language also serves as a mode of thought; our thinking can involve something like talking to oneself. It is also closely related to our system of concepts (see Chapter 8), because some concepts may depend on the possession of language. For example, could there be concepts such as bachelor or obligation without the human ability to convey complex ideas with language? In sum, language plays a central role in many of our cognitive activities.
This chapter and the next review what we know about humans' remarkable language abilities, and how the capacity to speak and understand language is related to other cognitive processes. Chapter 9 begins with an overview of the functions of language and the different levels of analysis in linguistic study. We then address language's role as a social communication system. Having set the broad stage, we turn to the different levels of analysis in linguistic study, beginning with the lowest-level component of language: the sound system. This includes prosody, the study of the role of intonation, pitch, and stress or emphasis patterns in language; and phonology, the analysis of the basic units of sound in language. Our analysis then moves to the structure of words, the building blocks of language, where sound and meaning come together. The study of the basic units of meaning that make up those words is called morphology. We will consider how words are stored in our mental lexicon—our mental dictionary—based on studies of how people use and process words, including occasions when they have difficulty retrieving words, as in tip-of-the-tongue (TOT) states. The discussion will also examine how children learn the meanings of words, an area in which many important theoretical questions have been raised.
Lastly, recent advances in brain-imaging techniques and in the study of neuropsychological syndromes have provided evidence concerning how language is processed in the brain. In several places we discuss the role of brain processes in understanding word meaning, and in assembling the phonological representation necessary to produce words. The chapter concludes with a discussion of the role of brain processes in understanding meanings of words. Combining words into sentences adds still more complexity to the phenomenon of language, and will be examined in Chapter 10.
In order to get a feeling for the multifaceted complexity of language, we now turn to an overview of language as a communicative device. This will provide us with an introduction to the various levels of processing involved in using language, and how they function together. Figure 9.1 presents an outline of the processes that might occur during a typical act of communication, where one person has some information that he or she wishes to transmit to another (e.g., a speaker attempting to convey a perceptually based memory of some experience to a listener).
Figure 9.1 Outline of the communicative act: Speaker has in mind a scene of a car hitting a truck, and communicates it to a listener.
Language is studied in one of two ways—through the production of words and sentences (whether verbally or in writing), or through comprehension. In order to set the process of communication in motion, the speaker must be able to put into words the information to be transmitted (see Figure 9.1). This skill depends on at least three kinds of knowledge. First, the speaker must have a vocabulary that allows him or her to put the idea into the right words. Our knowledge about words and their meanings is called the lexicon or mental lexicon (lexis means word in Greek). A fluent speaker also must know how to use the syntactic structure of a language to put words together into sentences, and to add the small grammatical or function words (such as a and the), so that a specific meaning can be transmitted accurately. Simply knowing the words a, dog, man, and bites does not allow you to communicate the difference between A dog bites a man and A man bites a dog (Pinker, 1994). Those words have to be put together in the correct way to communicate the difference between those two situations. When the message has been formulated, the final stage in language production is its transmission to the listener, usually by means of sounds.
In language comprehension, the process works in reverse. The listener must first process words from the sound stream, and determine the organization of a sentence. From the analyzed sentence, the listener then constructs a meaning, which, if the speaker was effective, will correspond to the idea that the speaker set out to communicate (see Figure 9.1).
Although language production and comprehension have often been used as separate measures of linguistic competence, there is considerable evidence for interaction between the two subsystems (Pickering & Garrod, 2004, 2007). For example, during comprehension, there is evidence that people engage the production system, by predicting which words will be said next (DeLong, Urbach, & Kutas, 2005; Lau, Stroud, Plesch, & Phillips, 2006), and, in so doing, engage their tongue and brain areas responsible for speech production (Fadiga, Craighero, Buccino, & Rizzolatti, 2002; Watkins & Paus, 2004; Watkins, Strafella, & Paus, 2003). Conversely, people use the words and syntactic structures they have just comprehended to influence their actual language production (Bock, 1986; Branigan, Pickering, MacLean, & Stewart, 2006). Thus, the distinction between production and comprehension is functionally useful to conduct research, but not necessarily reflective of what is happening cognitively.
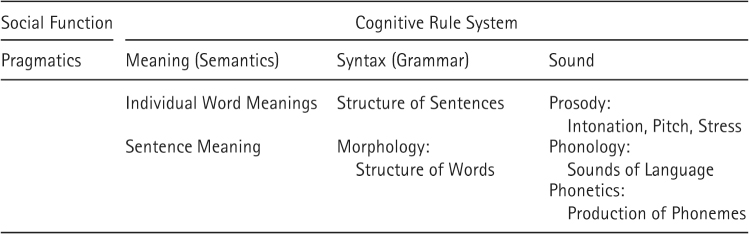
Table 9.1 depicts the various levels of linguistic analysis. As we have already discussed, language serves a social, communicative function. Pragmatics is the study of the rules of social discourse: how the broader context—including the intent of the speaker and the linguistic knowledge of the speaker and listener—affects the interpretation of a linguistic message. Language also has many complex cognitive aspects to it, encompassing semantic, grammatical, and sound-related functions. Semantics, the study of meaning, examines the relationships between language, ideas, and events in the environment. In this chapter we will be concerned with the meanings of individual words; Chapter 10 examines how people process the meanings of sentences. Syntax, the study of the grammatical organization of sentences, is the study of how speakers of a language combine individual words into legal sentences that follow the rules or constraints of a language. Related to comprehension, the study of syntax involves analyzing how listeners use information from an utterance to determine its grammatical structure, as an early step in specifying the meaning that a speaker was trying to communicate. Syntax also involves morphology, the study of the structure of words (e.g., adding tenses).
Table 9.1 Levels of Analysis in Language
Finally, we come to the sound system of a language, the actual string of sounds the speaker uses to convey the message. One component of the sound system is prosody, the study of the role of intonation, pitch, and stress in communication. Prosody plays an important role in communication. For example, we can change the meaning of an utterance—from a statement to a question, for example—by changing the intonation pattern (such as speaking the last word at a higher pitch). The sound system also involves the study of the individual sounds that make up a language, which linguists call phonemes, as well as how those sounds are combined to form words. The study of phonemes themselves is called phonology; while the study of the physical means through which the phonemes are articulated with the mouth and vocal cords is known as phonetics.
Having now examined the levels of linguistic analysis, and their relationship to each other, we examine the theoretical debates—both historical and current—that guide much of the research and interpretation of language studies.
Language, and how it develops, has fascinated people for centuries. For example, Psamtik, an Egyptian king, mandated that two children be isolated and raised by deaf-mute caretakers to see what language they spoke spontaneously, as that would be the root language. (He was chagrined when their first word appeared to be bekos—Phyrigian for bread, rather than an Egyptian word). As we noted in Chapter 1, a prominent impetus for the cognitive revolution was Chomsky's (1959) critique of Skinner's behavioristically based views on language, with Chomsky arguing that language in humans was a built-in behavior, part of our genetic structure, while Skinner proposed that language development came about through conditioning. However, nowadays most researchers are not directly concerned with the question of whether language learning is purely a function of nurture versus nature (Bates, 1997). Most researchers now acknowledge that humans have an innate ability to learn language. A more useful research question is how that skill is developed as a result of their exposure to language (Bates, 1997; Croft & Cruse, 2004).
Currently, the two dominant theories of language are a rule-based/computational one, based on Chomsky's theory and largely popularized by Pinker (1994, 1999), and an emergent perspective, advocated by a wide array of researchers. The rule-based/computational theory argues that environmental input triggers innate mechanisms for acquiring the rules of grammar for the language one grows up with. Furthermore, the rules for language learning and mechanisms by which we acquire speech are modular and language-specific. These computational rules then permit the generativity of language, and allow us to construct an infinite number of novel sentences. Under the emergent position, the mechanism for language learning is based on general, nonmodular, cognitive-based learning mechanisms, such as association, or induction of statistical principles, which also underlie many other cognitive skills. Thus, people detect patterns in language that influence speech production, rather than learning or activating rule-based computational subsystems.The two theoretical perspectives also differ in the importance that they place upon social modeling and social cues in language development. The rule-based perspective emphasizes that hearing other people speak merely activates existing syntactic structures that are innate; thus, they point to the poverty of the input—children's language abilities are often more complex than the speech they hear, because innate language knowledge fills in what is missing to allow them to achieve grammatical competence. Alternatively, within the emergent camp, advocates of the social-pragmatic view (Akhtar & Tomasello, 1996; Hollich, Hirsh-Pasek, Tucker, & Golinkoff, 2000;Nelson, 1988;Tomasello, 2006; Tomasello & Akhtar, 1995; Tomasello, Strosberg, & Akhtar, 1996) emphasize that children build up a vocabulary and grammatical knowledge based on the social and contextual cues surrounding linguistic input and use; there is not any innate linguistic framework to guide their language acquisition. Thus, critical areas in which the two theoretical perspectives differ include: (a) whether language is rule- or pattern-based; (b) whether language is a modular skill or is tied to the general cognitive system; (c) the extent to which language is influenced by an innate language module or constructed out of use; and (d) the relative importance of social cues and pragmatic knowledge in language acquisition. These issues will frame our discussion in this chapter and the next.
Having introduced the levels of linguistic analysis and their relationship to each other, as well as the main theoretical perspectives in the study of language, we can now examine in detail the psychological processes involved in speech production and comprehension. Whenever relevant, we will assess whether the available data better support a computational or emergent perspective.
Language use involves more than words or sentences in isolation. As participants work their way through a conversation, for example, they acquire common ground—information that has been activated as the conversation proceeds and which serves as background to what they say (Stalnaker, 2002). This information comes in part from general knowledge and beliefs—presuppositions—from their shared cultural background, as well as information accumulated through their ongoing personal interaction. Common ground guides both what they say and how they interpret one another's speech.
Return to the situation in Figure 9.1. If both the speaker and hearer knew that the car in question had hit that same truck before, one might say, “That car hit that truck again.” If neither knew about the history of the car and truck, one would be more likely to say that a car hit a truck. In the short-term, people assume that once a new topic has been introduced in conversation, the other person will remember that information. In the example in Figure 9.1, the speaker says that a car hit the truck, because he or she has already introduced the truck into the conversation. More generally, if one conversant—a participant in a conversation—says something like “The guy then said…,” she is assuming that the listener will have information in memory about the identity of “the guy” from earlier in the conversation, whereas someone who newly joins the conversation will not have that common ground and therefore will not be able to understand “the guy.” Thus, we say things differently, depending on our common knowledge.
Grice (1975) proposed that participants in a conversation work under a set of pragmatic rules, or conversational maxims, which serve to keep communication on course and save effort on the part of speaker and listener (see Table 9.2). They ensure that the speaker does not say what he or she believes to be false, or go into detail that is either unnecessary to the thrust of the conversation or is already known by the listener. The listener is provided with sufficient information so that he or she does not have to keep struggling to determine the message that the speaker is transmitting. We all know people whose conversation violates one or more of these maxims, such as the person who gives a lengthy and detailed response to your casual query, “How are you doing?”
Table 9.2 Grice's Conversational Maxims
| Maxim | Purpose |
| Relevance | Speakers' contributions should relate clearly to the purpose of the exchange. |
| Quality | Speakers should be truthful. They should not say what they think is false, or make statements for which they have no evidence. |
| Quantity | Do not say more than is necessary, but say everything that is necessary. |
| Manner | Speakers' contributions should be perspicuous: clear, orderly, and brief, avoiding obscurity and ambiguity. |
We now turn to an analysis of more detailed aspects of the linguistic message, beginning with the sounds that a speaker produces, focusing first on prosody and then on phonology and phonetics.
When we listen to language, we typically are cognizant mainly of what the other person is saying, but how they are saying is just as important. For instance, imagine playing quarterback for your intramural football team and throwing an interception that loses the game. A friend of yours says, “Well, that was a brilliant pass.” Did she mean it? The words, by themselves, sound positive, but given that your pass was anything but brilliant, chances are your friend used sarcasm, which was reflected in her tone of voice. She probably accented “that” and “brilliant” differently than if she had meant the words sincerely. Likewise, if your professor announces that, “Term papers are due tomorrow,” with the last word strongly emphasized, you might conclude that he will not accept late papers. Thus, the meanings of words or sentences can be affected by the intonation they receive (Norrick, 2009). Prosody includes the rhythm, intonation, and emotional tone of speech, as well as when stress is applied to certain words. There is one area of language in which prosody is particularly important: infant- and child-directed speech, where we exaggerate prosody to facilitate infants' attention to language. Neuropsychological evidence suggests that prosody is mainly controlled by areas in the right hemisphere, as a complement to speech areas in the left that process traditional elements of speech production and comprehension.
Most adults speak differently to infants than they do to older children or other adults—with higher pitch, wider variation in intonation, and more-precise enunciation of individual phonemes. This particular type of speech—called motherese or parentese, or more technically, infant-directed speech—is nearly universal in human communities (Fernald, 1992). Infants prefer to listen to motherese compared with ordinary speech, (Fernald, 1985), which may largely be due to the elevated pitch (Fernald & Kuhl, 1987). Infant-directed speech may facilitate perception of the phonemes of a language (Kuhl et al., 1997). Sensitivity to prosody precedes word comprehension in infants. Fernald (1993) presented 9- and 18-month-olds with an attractive toy. The infants heard messages such as “No, don't touch,” or “Yes, good boy/girl,” using either a consistent or inconsistent intonation. For example, in the inconsistent-negative condition, “No, don't touch” would be said in a lilting, happy tone. The 9-month-olds responded only to the intonation, touching the toy when the voice was happy, no matter what was said. The older infants, on the other hand, modulated their behavior based on the sentence content, and often showed consternation when the voice told them “Don't touch” with positive intonation. Thus, infants' primary response to speech may be based on the intonation; only later is the meaning of an utterance of equal importance.
The question then arises as to whether intonation and prosody are controlled by the same speech centers in the brain as word and sentence production and comprehension.
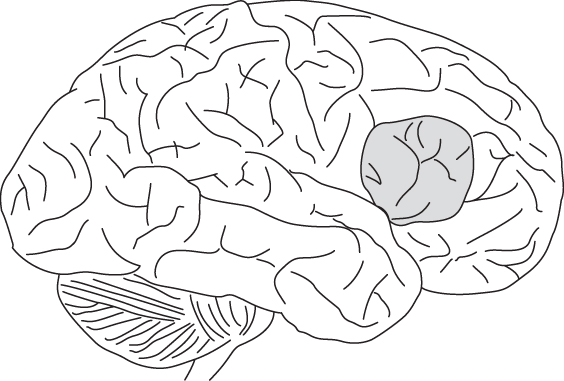
Prosodic components of language, most particularly intonation and the cadence or rhythm of speech, are represented in specific areas in the right hemisphere of the brain. Ross, Edmondson, Siebert, and Homan (1988) administered a Wada test (named after neurologist J. A. Wada) to five patients. This test involves injecting sodium amobarbital into one of the two carotid arteries, which temporarily incapacitates the ipso-lateral (same-side) hemisphere of the brain. In the Ross et al. study, the participants were asked to repeat a sentence using either a neutral, happy, sad, angry, surprised, or bored intonation. Participants were unable to speak the sentence at all after a left-hemisphere Wada test. In contrast, after a right-hemisphere Wada test, they could reproduce the words in correct order, but they lost the ability to adjust the emotional tone in their speech. Ross et al. (1988) concluded that, in most right-handed people, prosodic and affective elements of language are added to speech by the right hemisphere. Shapiro and Danly (1985) found that neuropsychology patients with damage to a right hemisphere area analogous to Broca's area (see Figure 9.2), tended to read paragraphs in a flattened emotional tone.
Figure 9.2 Grey area depicts right inferior frontal gyrus, used in processing/recognizing emotional tone and prosodic information, which corresponds to the right-hemisphere analogue to Broca's area.
People also seem to vary their intonation patterns based on their regional accent; some dialects tend to have more of a musical rhythm, with a lilt at the ends of sentences (e.g., Irish and Scottish accents). Thus we could assume that accent might also be controlled by the right hemisphere. One unusual condition caused by brain injury is foreign-accent syndrome, in which people who have suffered some type of brain trauma or stroke appear to speak with a different accent. For instance, after a stroke, a native speaker of British English might sound like a Noo Yawkah. There have been several famous cases, such as that of a Norwegian woman who was struck by shrapnel in World War II and began speaking with a German accent (Monrad-Krohn, 1947), or the British woman whose severe migraine left her with a Chinese accent (The Sunday Times, April 20, 2010).
Both prosody and pronunciation of phonemes are often affected in foreign-accent syndrome (Haley, Roth, Helm-Estabrooks, & Thiessen, 2010). Albert, Haley, and Helm-Estabrooks (in preparation, cited in Haley et al., 2010) surveyed 30 cases of foreign-accent syndrome for which neurological information was available, and determined that the most common lesion was in the left frontal lobe, in the white matter. Akhlaghi, Jahangiri, Azarpazhooh, Elyasi, and Ghale (2011) confirmed the left hemisphere (LH) correlation. What were the differences between foreign-accent syndrome and the patients just described who lost all prosody due to right hemisphere (RH) damage? While some have considered it an impairment of prosody (Blumstein & Kurowski, 2006), others have said that foreign-accent syndrome is due either to a side effect of aphasia (Ardila, Rosselli, & Ardila, 1987) or to apraxia—motor impairments in articulating phonemes (Coelho & Robb, 2001;Moen, 2000). For example, if a person has trouble pronouncing the r sound at the end of words after a stroke, it may sound as if the person had acquired a Boston accent. Most cases of foreign accent syndrome do, indeed, arise after periods of nonfluent (Broca's) aphasia, muteness, or apraxia. This would mean that foreign accent syndrome is a problem with speech production at the phonological/phonetic/motor level, rather than an intonation problem. Thus, it would be expected to result from LH damage.
Another element of the linguistic sound system is the specific phonemes that are used in speech. Pronounce the following string of letters: bnench. English speakers agree that bnench is not an English word and also that it does not sound like it could be a legitimate English word. In order to understand why English speakers reject bnench as a possible English word, we must consider the phonemes that are used to construct words in English.
The human vocal apparatus is capable from birth of producing a very large number of sounds, ranging from coos to giggles to screeches, and our auditory system is capable of responding to all these sounds and many others. Each language uses a subset of those sounds, called phonemes, to construct words. English uses about 44 phonemes (http://www.dyslexia-speld.com/LinkClick.aspx?fileticket=Kh7hycbitgA%3D&tabid=92&mid=500&language=en); other languages use from around a dozen to well over 100 in Taa (or “!Xo'o”), a language spoken in Botswana and Namibia (DoBeS project on Taa language, http://www.mpi.nl/DOBES/projects/taa/). One can get a general idea of the phonemes of English by considering the letters of the alphabet. Most consonant letters correspond to single phonemes (e.g., f, z, d). Each of the vowel letters represents several different phonemes, depending on how each is pronounced in a specific context. For example, a can be pronounced “ay,” as in cake, or “ah” as in hard; e can be pronounced “ee” or “eh”; and so forth. Some phonemes are made up of combinations of letters; sh and ch are single phonemes in English. (We will designate phonemes by using / /; sounds will be designated by writing the italicized letter, e.g., p.)
Phoneticists, researchers who study the physical properties of phonemes, have developed a method of analysis of phonemes using a small set of articulatory features based on the ways in which each sound is articulated, or spoken. As an example of how articulatory features are determined, pronounce the sound p aloud several times in succession, paying particular attention to the position of your lips. At the same time, hold your hand an inch in front of your mouth as you produce the p.
When you say p, p, p, holding your hand in front of your mouth, you will notice that there is no sensation, then a slight explosion of air against your hand. This indicates that the airstream is first blocked, and then comes out in a burst. The general fact that the airstream is interrupted defines the phoneme /p/ as a consonant. The difference between consonants and vowels is that consonants are produced by blocking the airstream either partially or completely; vowels are produced with a continuous stream of air. When producing p, the airstream is completely blocked, or stopped, which defines /p/ as a stop consonant. In contrast, fricatives (such as /f/, /s/, or /th/) involve sustained turbulence, rather than complete interruption, in the sound stream. The type of interruption in the airstream is called the manner of production of the phoneme (see Table 9.3, section A).
Table 9.3 Summary of Phonological Feature Analysis, Showing Features Comprising Several Related Phonemes
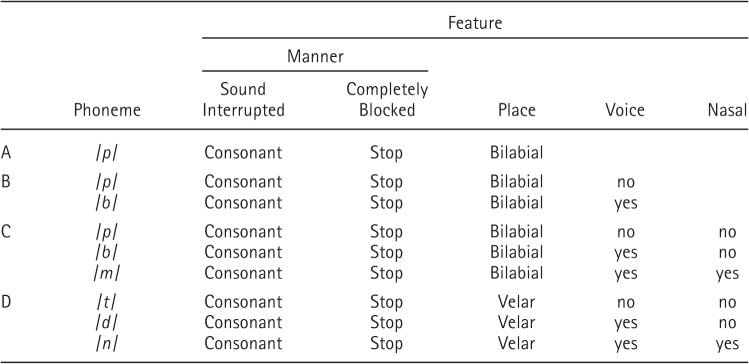
In saying p, the airstream is stopped by bringing the two lips together and then bursting them apart with the air forced up from the lungs. Thus, /p/ is a bilabial stop consonant (bi-labia means two lips in Latin). The specific parts of the mouth used in producing the phoneme, in this case the two lips, are called the place of articulation. Other sounds are produced by pressing the tongue against the teeth, such as /th/; such sounds are known as dental sounds. Labiodental sounds involve contact between the lips and the teeth, e.g., /f/ or /v/. /H/ is a glottal sound, because it is produced by the glottis in the throat.
Say p and b several times with one hand in front of your mouth, as before, but this time put your other hand on your Adam's apple (the voice box). Both sounds involve bringing the two lips together, and expelling air out of one's mouth, so /b/ is also a bilabial stop consonant. The difference between the production of the two sounds is in the vocal cords: One feels vibrations in the throat for /b/, but not for /p/. So /b/ is a voiced bilabial stop consonant, while /p/ is voiceless, as shown in Table 9.3, section B.
Now say p, b, and m several times in succession. All three sounds involve bringing the two lips together and then opening them, so all are bilabial stop consonants. Also, both b and m involve activity in the vocal cords, so they are both bilabial voiced consonants. In addition, however, if you lay a finger like a moustache under your nose as you say p, b, and m several times in succession, you will feel a slight puff of air from your nose as you say m. Thus, /m/ is a nasal voiced bilabial stop consonant, because the air comes out through the nose, rather than the mouth (Table 9.3, section C).
In conclusion, Table 9.3 presents feature analysis for a family of phonemes, in which the members are related through the possession of overlapping sets of features. Table 9.3, section D also presents another family of phonemes, /t/, /d/, and /n/, which are also stop consonants, but this time the place of articulation involves the tip of the tongue touching the velar ridge, behind the teeth. Except for that component, the analysis parallels exactly that for /p/, /b/, and /m/, respectively, as far as voicing and nasality are concerned.
Now we can return to the question with which we began this section: Why is bnench not an acceptable phonological string in English? In English, no word begins with two stop consonants such as b and n. Although some words are spelled with two stop consonants at the beginning, such as knew, pneumonia, and mnemonics, the two stop consonants are not both pronounced. One could view this as a phonological rule for forming words in English, because of the high degree of regularity that one finds. All people who know English seem to know that rule implicitly, since no speaker of English produces words that violate it, even though few of us could articulate the rule. English speakers have induced certain phonemic patterns as a result of their exposure to the language, and use them as the basis for word production and for judgments about acceptable sound sequences. Thus, regularities seen in language processing could be explained by the rule-based/computational view as being the result of the person's explicit internalization of rules, or by the emergent perspective as being the result of the person's sensitivity to patterns or high-probability tendencies in the language. This is an example of how the same set of results can be interpreted as evidence for language learning being rule-governed versus pattern-based.
Every day, we are exposed to a multitude of speakers, some with high-pitched voices (such as children), others with deep voices, and those who speak with different dialects or accents. Speech comprehension would be very difficult, indeed, if we processed words or sounds differently based on individual voices. For instance, we perceive the /p/ in pickle and pumpkin as the same sound, even when spoken by our professor from New York City, and our friend from the South. We carry out categorical perception of phonemes, in which we ignore small acoustic differences between phonemes and treat them as members of the same phonemic category. Research on categorical perception has had theoretical implications as to whether language processing is based on a modular system or not.
When a speaker produces a sound stream in the process of speaking, that sound stream is a form of physical energy, which can be represented in a sound spectrogram: a visual representation of the distribution of energy of an utterance. Figure 9.3 presents an idealized spectrogram of the energy distribution underlying production of the syllable ba. As can be seen, there are two bands of concentrated energy, which are called formants. The upper band, formant2, corresponds to the burst of energy from the explosion of the stop consonant, which we have already discussed. A rising transition of the first formant (formant1), is correlated with the voicing component of the class of voiced stop consonants (Harris, Hoffman, Liberman, DeLattre, & Cooper, 1958), and formant1 also helps determine the specific vowel that we hear. The shape of the formant is based upon the time separating air release and vibration of the vocal cords, which is known as voice onset time (or VOT).
Figure 9.3 Acoustic analysis of speech sounds: Idealized spectrogram of the energy distribution underlying production of the syllable ba. Note the two formants (bands of energy) and the fact that both formants begin at the same time.
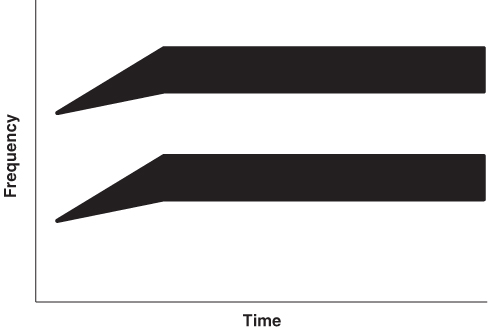
Figure 9.4 presents the spectrograph for pa. As we know from earlier discussion, the main difference between pa and ba is the absence or presence of the voicing component in the first phoneme (/p/ versus /b/). A comparison of Figures 9.3 and 9.4 shows that the first formant is delayed a significant amount of time in pa (e.g., 30–60 milliseconds), which is what gives the consonant its voiceless quality. So an increase in VOT at a given frequency, while formant2 is consistently articulated, results in a change in perception from a voiced bilabial stop consonant to a voiceless one (Lisker, 1975; Abramson & Lisker, 1967; Stevens & Klatt, 1974).
Figure 9.4 Idealized spectrograph for pa. Note again the two formants, but this time the lower (voicing) format begins after the other. The time before the voicing begins (voice onset time, VOT) results in hearing a voiceless sound (pa) rather than a voiced sound (ba).
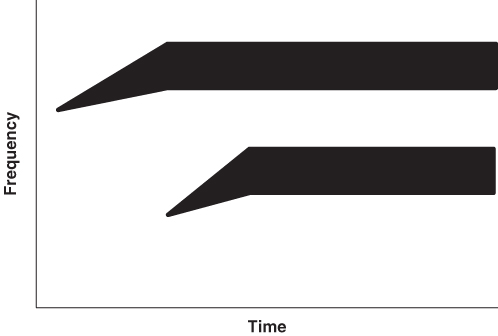
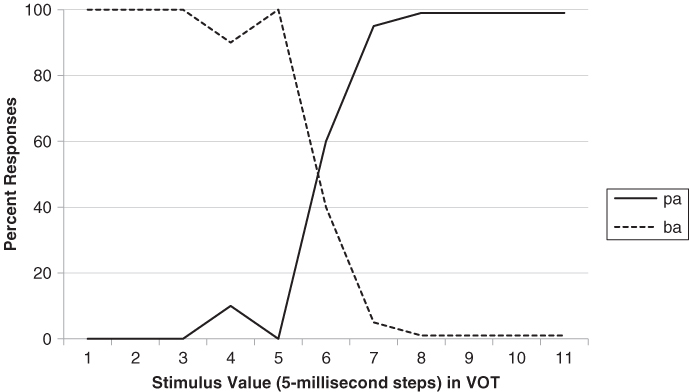
It is possible to manipulate VOT changes artificially using a speech synthesizer—a machine that generates sounds—and one can then ask listeners to report what they hear. In Figure 9.5 is a set of artificial spectrographs in which VOT is increased in increments of 20 milliseconds, going from 0 milliseconds (ba) to 60 milliseconds (pa). One might expect that people's perceptions would gradually shift from one sound to the other, as shown in Figure 9.6. At the middle values of VOT, then, people might perceive mixed versions of the two sounds, or some sound intermediate between ba and pa.
Figure 9.5 Set of spectrographs: VOT increases from the first (ba) to the last (pa).
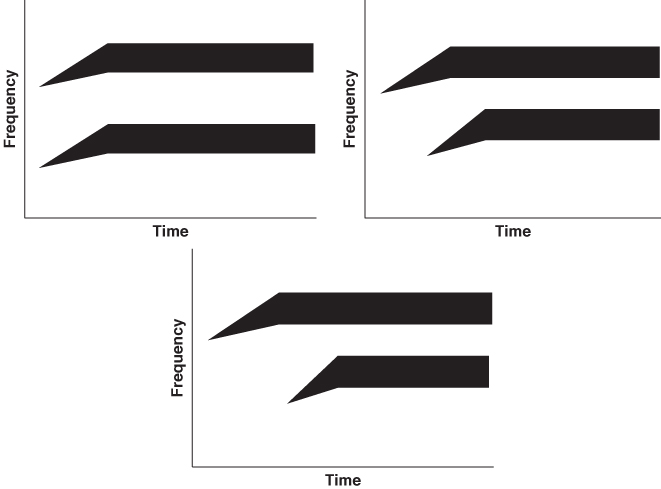
Figure 9.6 Predictions concerning people's perceptions of pa versus ba in response to an expanded set of stimuli such as those in Figure 9.5, if there is no categorical perception. As VOT increases, there should be a gradual shift from ba to pa as responses.
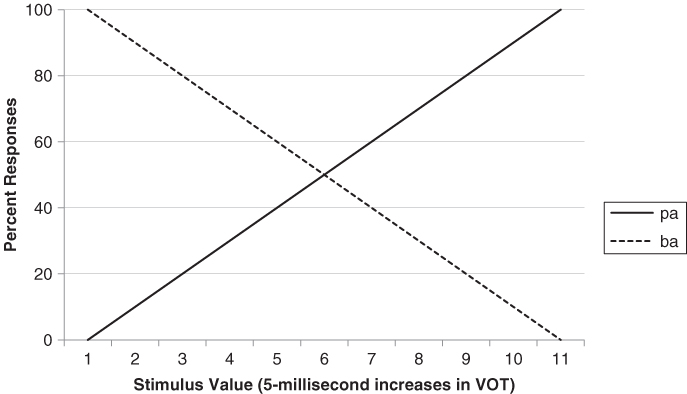
However, that is not what occurs. As VOT increases over the first few steps, people continue to report hearing ba. Then, midway through the VOT series, there is an all-or-none shift in perception, with the voiced sound changing into the voiceless one (see Figure 9.7). Despite minor VOT differences, adults behave as if there are two separate phoneme categories: Short VOTs are perceived as the voiced /b/ sound and longer VOTs as the voiceless /p/. A 20-millisecond change in VOT within the category boundary (e.g., from +0 to +20) is not perceived as articulation of a different phoneme, but a 20-millisecond change across the boundary (+20 to +40) is significant and results in a differences in speech perception. This categorical perception seems to be different from what occurs in other domains, such as when we listen to music getting louder gradually (rather than in discrete steps). Such results have often been used to support the notion of a language-dedicated module (Liberman, Cooper, Shankweiler, & Studdert-Kennedy, 1967).
Figure 9.7 Actual perceptual judgments in response to stimuli such as those in Figure 9.5. Perception shifts suddenly from ba to pa.
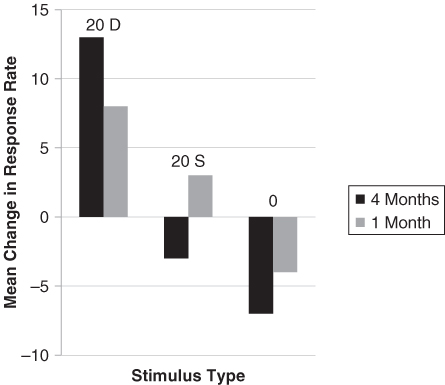
Humans' ability to perceive phonemic categories is evident very early in life. In a classic study by Eimas, Siqueland, Jusczyk, and Vigorito (1971), 1- and 4-month-old infants were exposed to repeated speech sounds, in a habituation design (as described in Chapter 6). The infants were given a nipple to suck that triggered a repeated speech sound, such as ba. After the infants habituated to, or lost interest in, the sound (e.g., /b/) and stopped sucking, the sound was then changed, with the VOT of the new sound being the critical difference. Half the time, the change in VOT resulted in what adults perceived as a movement across the voiced/voiceless boundary (e.g., ba to pa; shift of VOT from 20 to 40 milliseconds; 20D in Figure 9.8). Both 1- and 4-month-olds showed dishabituation—an increase in sucking—when the new phoneme was triggered. On the other hand, if the VOT stayed within a category boundary (e.g., +0 milliseconds to +20—ba, or +40 to +60 milliseconds—pa; 20S in Figure 9.8), the infants continued to show habituation and sucked less because they perceived the same category sound (see Figure 9.8). Thus, very young infants, who had had very limited speech input, nonetheless responded to the same phonological categories as the adults did. Initially, these results seemed to be strong evidence that the categories for speech perception were built into the human perceptual apparatus, consistent with Chomsky's proposal for an innate module for human language.
Figure 9.8 Infants' changing response rate to different stimuli.
Adapted from Eimas et al., 1971, Figure 3.
However, more recent evidence has cast doubt on the modular nature of this language skill (Goldstone & Handrickson, 2009, 2010). For example, categorical perception has also been found in chimps (Kojima, Tatsumi, Kiritani & Hirose, 1989), and chinchillas (Kuhl & Miller, 1975), neither of which has a complex natural language in the manner of humans. Categorization abilities have also been found for general non–speech-based sounds (Cutting, 1982; Cutting & Rosner, 1974; Rosen & Howell, 1981), indicating that the tendency may be a general function of the sound system itself (Kuhl, 1978, 2009), rather than language-specific. Categorical perception can also be found in nonspeech domains, such as when we perceive bands of separate colors—red, orange, yellow, and so forth—when we look at a rainbow (even though the rainbow is made up of light rays which form a continuous band of physical energy as they are diffracted through drops of moisture). At the very least, categorical perception is not limited to perception of phonemes. In conclusion, studies of categorical perception of phonemes, which showed that infants have the same phoneme boundaries as adults (e.g., Eimas et al., 1971), seemed initially to have provided support for the existence of an innate language-specific processing module in humans. However, subsequent research indicates that this is neither a human-specific nor speech-specific tendency, and thus may not be solely a linguistic skill.
People clearly use purely acoustic features of phonemes to recognize and categorize sounds. However, people also use visual clues, making much speech perception multimodal (where input comes from multiple modalities—e.g., auditory and visual). One phenomenon that illustrates this multimodality is the McGurk-MacDonald effect (McGurk & MacDonald, 1976). When a videotape of a man saying ga is presented in coordination with an audio of another man saying ba, people often perceive the sound as an intermediate da. (You can easily find a video of this effect on YouTube.) First listen and watch to see what syllable is perceived. Then close your eyes and only listen. Finally, turn off the computer sound and only watch the visual cues as to what is being said. The effect should be clear: What you see affects what you hear.
This conclusion is supported by studies showing that people perceive speech more easily in ordinary communication situations when they can see the speaker, especially when there is competing noise (MacLeod & Summerfield, 1987). Remez, Fellowes, Pisoni, Goh, and Rubin (1998) asked people to transcribe sentences while only listening to an audiotape of the sentences, or while simultaneously seeing a video of the speaker. The number of syllables transcribed accurately was significantly higher in the audiovisual condition than audio only, again showing that visual language cues contribute to our perception and phonemic analysis of spoken speech. Although both audio and visual information are used in speech perception, the audio may be more important when detecting phonemes (Schmid, Thielmann, & Zigler, 2009), and people can often detect the disconnect between the audio and visual input in the McGurk effect (Soto-Faraco & Alsius, 2009).
The perception of speech involves processes similar to those found at the core of pattern-recognition as discussed in Chapter 5, including both feature analysis and top-down processes (as illustrated by categorical perception of phonemes). While we can accomplish speech perception based purely on the physical properties of the sounds a person produces (e.g., when we listen to someone talk in the dark), speech comprehension can also be multimodal and knowledge-based. The McGurk effect illustrates that we not only attend to auditory aspects of a speaker's output, but also to the shape of their lips, and other cues such as body language.
We have seen that, many months before they produce their first words, infants are sensitive to the prosody and phonemic structure of the language they hear around them. In production, too, there are precursors to actual language. Infants first begin cooing, using mainly vowel sounds and gurgling noises, and then progress to babbling, which includes consonant-vowel combinations, such as dada, gege, and so on. Initially, infants' babbling can include phonemes used in a wide range of languages. With increasing age and exposure to one language, however, the sounds they produce come to resemble more and more the phonemes of the language being spoken around them (Pinker, 1994).
Most people assume that there are pauses between words that allow children to isolate words and acquire them from adult speech. However, we usually do not produce words as separate units, which means that the stream of sound is continuous, like this:
How, then, does a child hear separate words in the stream of continuous sound? While the exaggerated enunciation of words and phonemes in motherese/parentese helps (Thiessen, Hill, & Saffran, 2005; Thiessen & Saffran, 2003, 2007), much of our designation of word boundaries is based on top-down processing. Saffran, Aslin, and Newport (1996) studied 8-month-old infants' sensitivity to phonological structure by presenting strings of computer-generated three-syllable nonsense words with consonant-vowel-consonant-vowel-consonant-vowel (CVCVCV) structure, such as bidaku, babupu, and golabu. Strings of the new “words” were presented repeatedly, with no breaks between them, as in this example:
This situation is similar to what happens in life when children are exposed to language in their typical interactions with other people. Each infant simply heard the strings for two minutes. As can be seen in the just presented example, within each “word,” the syllables followed each other in regular order. There is thus a very high probability that, when bi is heard, da will follow, and that ku follows da. However, the multisyllabic “words” themselves did not follow each other with regularity.
After the 2-minute exposure to the experimental strings, Saffran et al. (1996) presented the infants with test strings, some of which contained words that had been heard before, and others that contained familiar syllables put together randomly. The infants showed habituation (see Chapter 6), in that they spent less time listening to the “words” from the speech stream and attended more to the novel nonwords. Amazingly, the infants had learned the structure of the strings from asimple,2-minute exposure. In a second experiment, Saffran et al. confirmed that infants were able to determine word boundaries from statistical regularities in the 2-minute speech stream. Infants paid more attention to syllable combinations composed of the last syllable from one word plus the first syllable of another (e.g., “kuba,” because this constituted a novel stimulus) than to syllables from within a single word. Simple exposure to a brief speech sample was enough to acquire top-down knowledge about the syllabic structure of new “words.”
This research addressed two important questions concerning language comprehension. First, even when speech is continuous, one way to tell when words begin and end is by imposing an organization on the speech spectrum, based on top-down knowledge as to which phonemes and syllables have been heard together before. Secondly, the research of Saffran et al. (1996) indicates that humans are sensitive to statistical probabilities of speech syllables very early in life, and can use that sensitivity to begin to analyze language into word units (see also Lany & Saffran, 2010). This research has been interpreted as supporting an emergent perspective, because general learning principles such as detecting statistical patterns were found to facilitate word learning.
At about the end of the first year, a child's babbling changes into recognizable words that clearly seem to refer to objects, properties, or actions in the world, such as when a child says ba upon seeing a bottle. This does not mean, however, that the first words produced by children are accurate renditions of the words they have heard. Examples of children's early mispronunciations and reductions of words are shown in Table 9.4A. At the level of sounds, consonant clusters in words tend to be reduced—e.g., black is pronounced as “b-ack” or turtle as “tu-tle.” Some phonemes are almost universally difficult for children to pronounce, and are often replaced by other phonemes that tend to be produced earlier in development. For example, the glide sounds /l/ and /r/ are often replaced with /w/ (as in “wabbit” for rabbit). Other sounds, such as /th/ or /v/ may not be mastered until a child is between 4 and 7 years old (International Children's Education, http://www.iched.org/cms/scripts/page.php?site_id=ichedanditem_id=child_speech1). At the level of the syllable, young children are likely to omit first syllables that are unstressed (Demuth & Fee, 1995;Kehoe, 2001) so that giraffe becomes 'raffe); other examples can be seen in Table 9.4.
Table 9.4 Children's Early Word Production: Cognitive Bases for Children's Early Words
| A. Examples of children's early words | |
| Elephant | EL-fun |
| Hippopotamus | POT-mus |
| Giraffe | RAF |
| B. Relation between parental speech and children's first words | |
| Parental Speech | Child (Pattern Recognition > Memory > Output) |
| Elephant | EL – fun |
| Hippopotamus | POT – mus |
The systematic mispronunciation of children's first words raises the question of how and why those errors arise. Errors in production of some phonemes cannot explain all patterns. Our discussion of memory, pattern recognition, and attention in Chapters 1–6 can help us understand why young children might only extract certain sorts of information from the speech stream. That is, what a child will say in a situation must depend on what he or she has stored and can retrieve about what adults said in similar situations (see Table 9.4B). Several factors, such as whether a syllable appears at the beginning, middle, or end of a word, and whether or not it is stressed, may contribute to a particular part of a word being relatively easy to hear and remember. First, in multisyllabic words, some syllables are stressed or emphasized. One example of this is the initial syllable in elephant (compare it with the initial un-stressed syllable in giraffe). Stressed syllables in English also tend to have longer pronunciation times than unstressed syllables, thus permitting longer processing. In addition, perception of some syllables may be facilitated by their appearing at the beginning or end of words or sentences (similar to a primacy and recency effect in memory).
Echols and Newport (1992) compared words produced by children with those words in standard adult pronunciation. Their summarized results are shown in Table 9.5. They found a serial-position effect in articulation of the children's words: The last syllable is most likely to be produced across all words. In words with three syllables, the first syllable is also very likely to be reproduced by the child and the middle syllable most likely to be left out. Children were also most likely to produce syllables that are stressed in adult speech, that are spoken relatively loudly. For example, one child produced “el-fun” for elephant, thereby omitting the unstressed middle syllable. However, the serial-position effect is seen for both stressed and unstressed syllables. Echols and Newport concluded that two hypotheses were supported by their results: (1) Children may be biased to attend to certain syllables in the speech stream (Blasdell & Jensen, 1970; Gleitman, Gleitman, Landau, & Wanner, 1988), or (2) they may process all syllables in adult speech—stressed and unstressed, regardless of position—but are most likely to produce stressed syllables, especially in final position (Allen & Hawkins, 1980; Gerken, Landau, & Remez, 1990).
Table 9.5 Data on Production of Syllables in Children's Words, from Echols and Newport (1992): Probability That Syllable Is Produced by Child in Spontaneous Speech
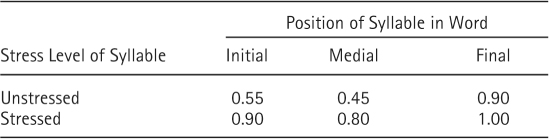
The pattern of findings in Table 9.5 points to a close tie between language and the other cognitive processes. Children's production of words can be understood, perhaps not surprisingly, on the basis of their ability to extract information out of the speech stream. Furthermore, that ability seems to be based on general principles of processing that have already been extensively discussed in relation to memory, pattern recognition, and attention.
Over the first year of life, infants become better at processing linguistic input, including individual words. Fernald, Marchman, and their colleagues (e.g., Fernald, Perfors, & Marchman, 2006; Hurtado, Marchman, & Fernald, 2008; Marchman & Fernald, 2008) have analyzed the developing infant's capacity to extract information from the sound stream using a selective looking technique. An infant is seated in front of two computer-monitor screens. A picture is presented in each monitor—say, a baby and a shoe—and at the same time a voice says “Where's the baby? Do you see it?” A video camera records the infant's eye gaze, allowing the researcher to determine whether or not the infant looks at the picture of the object named in the sentence. Frame-by-frame analysis of the video recordings showed that over the second year of life (from 15 to 25 months of age) infants responded more and more quickly to the label in the spoken sentence, and that the infants were also able to respond correctly to partial words (“Where's the sh…?”), indicating that their developing word-knowledge played a role in processing the linguistic input (Fernald et al., 2006).
In addition, the infants who were more efficient in processing the linguistic message were those whose mothers who talked to them more and who also used more-complex utterances. Thus, infants' abilities are at least in part based on the quality of the speech they hear (Hurtado, Marchman, & Fernald, 2008). Also, language-processing skills in infancy predicted cognitive skills later in life (Marchman & Fernald, 2008). The children who processed words more efficiently at 24 months of age performed better on tests of overall IQ, language production, and working memory at 8 years.
After a child extracts repeating strings of sounds from speech, he or she has to link each of those strings to an event or object in the world. We now turn how the child learns the meanings of words.
Children's first words are usually nouns (bottle, mommy, daddy), social phrases (bye-bye), adjectives (wet), and verbs (drink, kiss). Parental input has an effect on the predominant type of words produced: Western parents (as in the United States) tend to emphasize nouns, which is reflected in a noun-bias in their children; Chinese parents are more likely to emphasize verbs, and verbs make up a larger proportion of their children's early vocabulary (Levey & Cruz, 2003). Word learning initially progresses very slowly, but, at around 18 months, children go through a vocabulary spurt (though the exact age at which this happens varies greatly from child to child). At this point, the child may learn an average of nine new words per day (Carey, 1978;Dromi, 1987). Pinker (1994) has referred to the children as becoming “vacuum cleaners” for words. Underlying this rapid vocabulary growth is what is called fast mapping, in which words and their meanings may be acquired after a single exposure, or only a few. That is, the child quickly maps meanings to words. Fast mapping had been thought to occur around 2 years of age, but children as young as 18 months have demonstrated it in the laboratory (Houston-Price, Plunkett, & Harris, 2005).
How does a child know to what a new word refers? This connection is not as obvious as it may seem. Imagine that a child and an adult see a white rabbit hopping across a lawn. The adult says “Rabbit!” Presumably, the child has now learned the label for that animal, and will use the word rabbit the next time she sees a similar furry creature. However, Quine (1960) pointed out that learning what a word's reference is—what the word refers to—is not nearly that simple. How does the child know exactly what “Rabbit!” picks out? The adult might have been referring to the whole scene, including the rabbit hopping its way across the grass on the way to a line of bushes. Alternatively, perhaps the adult was referring to the rabbit's white color; or to the act of hopping; or to the rabbit's ears; or its legs; or its puffy tail. Might “Rabbit” be that animal's proper name? Without some help or guiding principles, the child is reduced to guessing—probably incorrectly—what the label means.
Psychologists have proposed several explanations for the efficiency with which infants and children learn words and their meanings. The constraints view holds that the child comes into the world with processing constraints that direct the child to focus on relevant aspects of the environment in a word-learning situation (Clark, 1990; Golinkoff, Mervis, & Hirsh-Pasek, 1994;Markman, 1989). In contrast, the social theory of word learning argues that social factors, most importantly the knowledge and intentions of the adult speaker, assist the child in determining the meanings of words (Akhtar & Tomasello, 1996; Hollich, Hirsh-Pasek, Tucker, & Golinkoff, 2000;Nelson, 1988; Tomasello et al., 1996; Tomasello & Farrar, 1986).
The constraints view of world learning (e.g., Baldwin, 1989;Clark, 1990; Gleitman, Gleitman, Landau, & Wanner, 1988; Golinkoff et al., 1994;Markman, 1989; Markman & Hutchinson, 1984; Nagy & Gentner, 1990; Waxman & Gelman, 1986) asserts that children are biased toward analyzing the world in ways that increase the likelihood of attaching the right meaning to a word. For instance, the child in the “rabbit” example would only consider the possibility that the parent is referring to the whole object—the rabbit—rather than one or more of its parts or its action. This is called the whole-object constraint on word learning. On this view, the mind is so designed that only a few possible meanings are considered to constrain the references for nouns and verbs (Pinker, 1994). This whole-object tendency may be due to the perceptual salience of whole objects (Spelke, 1990). When word learning begins, this whole-object tendency combines with a tendency for speakers to refer to whole objects, and results in the child largely producing words that refer to whole objects. A second constraint is children's realization that most words apply to a class of objects (Markman & Hutchinson, 1984). Thus when they learn a new word, e.g., “rabbit,” it applies not only to that particular individual animal, but to a larger category of similar animals.
Another constraint that the child uses to maximize word learning is called mutual exclusivity. Young children seem to believe that names are mutually exclusive: If an object already has a name, then they resist a second name for that object (Markman, 1990). Markman and Wachtel (1988) presented 3-year-olds with two objects—one familiar with a known name (e.g., a cup), the other unfamiliar with no known label (e.g., a kitchen gadget for removing pits from cherries). In one condition, the child heard a new word (e.g., “dax”), and was asked to hand the experimenter “the dax.” The children assumed that the novel label applied to the object that did not yet have a name (Experiment 1). In another condition, when a second name was produced for a familiar object, children applied the term to a distinctive part of the object which did not already have a label, or to the substance of which it was made—e.g., “pewter,” rather than adopt a second label for the whole object (Experiments 2–6).
In summary, the constraints view holds that there must be some constraints on the hypotheses that children entertain during the word-learning situation (Hollich, Hirsh-Pasek, Tucker, & Golinkoff, 2000). Words cannot be learned by mere association, because the label is associated with multiple aspects of the scene—parts of an object, the background, any action that is taking place—and it is impossible to distinguish which aspect of an object or scene was intended by a spoken word. Some researchers believe that these word-learning constraints are universal in all people and specific to a language module (Nagy & Gentner, 1990), and have an innate basis (Carey, 1993; Soja, Carey, & Spelke, 1991; Woodward & Markman, 1991). Alternatively, it might be the case that the whole-object and mutual-exclusivity constraints are simply lexical principles, which the child has induced from experience and are useful during language learning (Golinkoff et al., 1994;MacWhinney, 1989). From this latter perspective, the processing constraints are not necessarily based on innate or language-specific guidelines, but on general inductive learning principles; over time a child implicitly realizes which strategies optimize word-learning.
Recall from our earlier discussion that a major perspective within emergent theories is the social-pragmatic theory of word learning (Akhtar & Tomasello, 1996; Hollich et al., 2000; Houston-Price, Plunkett, & Duffy, 2006;Nelson, 1988; Tomasello et al., 1996), which emphasizes that, from an early age, infants and children are sensitive to social cues which can help them learn the meanings of words. Furthermore, people supplying the teaching typically attend to what a child is interested in:
Children do not try and guess what it is that the adult intends to refer to; rather…it is the adult who guesses what the child is focused on and then supplies the appropriate word. (Nelson, 1988, pp. 240–241)
One important social-cognitive mechanism affecting word learning is that of joint attention (Tomasello & Farrar, 1986). Word learning is optimized when an adult labels an object at which the child is already looking (Tomasello & Farrar, 1986). Joint attention is assumed to involve a child's understanding of the intentional state of another person, (i.e., what the other person knows); the child adopts a new label for an object because he or she believes that the object is the target of the attentional focus for another person (Tomasello, 2000). Children as young as 19 months of age look at their parent's eyes to determine the direction of gaze when the parent is labeling an object. Also, infants who are more socially attentive to the adult's direction of gaze during linguistic interaction are more likely to accurately apply the labels they hear around them, and learn words more quickly (Baldwin, 1991, 1993;Tomasello, 1995). In conclusion, young children are aware of social cues in the linguistic environment that indicate the intentional states of other speakers. They then use those cues as a way to map words to objects.
Although social cues are clearly important in learning the meanings of words, given language's important communicative function, they cannot be the whole story. Even if an adult sees a child watching a rabbit hopping across a field, the adult cannot determine exactly what it is about the situation to which the child is attending. Conversely, watching an adult's eye gaze as she labels “dog,” for example, will not tell the child if the speaker is referring to the animal versus its leash or its tail, or to the fact that the dog is panting. These examples lead to the conclusion that there must be an additional, nonsocial factor that focuses the child's attention to the aspects of a word's meaning that are not transmitted solely through social cues. This need for an additional factor to explain acquisition of word meanings seems to indicate that some constraints are needed for rapid word learning.
Hollich, Hirsh-Pasek, Tucker, and Golinkoff (2000) have developed a theory of word learning that attempts to reconcile the constraints and social-pragmatic views, bringing them together in a coalition model of word learning. The coalition view proposes that learning word meanings depends on a coalition of cues; that is: (1) cues from the object in the environment (e.g., perceptual salience, novelty); (2) constraints that the child uses to confine the possible intended meanings of words; (3) cues from the person talking to the child (e.g., social cues, joint attention); and (4) the verbal message itself are all used by the young child in the learning of meaning of words. Furthermore, the weighting of linguistic versus object-related versus social cues can shift over time. For example, before 18 months of age, new talkers may rely heavily on the perceptual salience of objects to merely associate a word label with its referent; after 18 months, social cues such as the intent of the speaker become more relevant (Hollich, Hirsh-Pasek, Tucker, & Golinkoff, 2000).
Children are able to acquire meanings of words, often quickly, due to a variety of cues and factors. First, there are constraints in processing information and the kinds of hypotheses children entertain concerning word meanings. Second, the linguistic community is sensitive to the child's capacities, and adults structure the communication situation to maximize the chances that the child will attend to the relevant object as well as to the phonology of a to-be-learned word. Finally, the child utilizes cues about the social/cognitive aspects of language, and adopts strategies that help to optimize word learning.
We have now examined the acquisition of the first words, which form the bricks out of which language is built. As noted earlier, the hypothesized location in memory where words and their meanings are stored is called the mental lexicon. Children's word learning is referred to as lexical acquisition; when we retrieve or activate words, we engage in lexical access. Psychologists have developed several methods to study how the mental lexicon is organized and how we access words and their meanings, including studies of both tip-of-the-tongue states and the processing of ambiguous words in sentences.
We all experience tip-of-the-tongue (TOT) states, those exasperating situations in which one is trying to recall a word or name, without success, but with the distinct feeling that success is just over the horizon. College students report an average of 1–2 TOT states per week; older adults report 2–4 (Schacter, 2001). The types of words we have trouble retrieving, and the cues that facilitate retrieval, can provide clues as to the organization and functioning of the mental lexicon.
In a classic study, Brown and McNeill (1966) produced TOT states in the lab, by presenting a list of definitions of relatively unfamiliar words, and asking the research participants to produce the word that fit each definition. One such question was: What is the name of the instrument used by sailors to determine their position based on the positions of the stars? [Answer: sextant.] When participants reported that they were in a TOT state, they were asked to provide any available information on the number of syllables that the word contained; the first letter; any similar-sounding words; or any words of similar meaning that they could retrieve. Of 360 TOT states reported, people were able to retrieve the first letter of the word 57% of the time, and the correct number of syllables 37% of the time. Furthermore, when participants wrote down words related to their intended target, the words were most often related phonologically; for instance, when the target was caduceus, similar-sounding words retrieved included Casadesus, Aeschelus, cephalus, and leucosis. Brown and McNeill concluded that people often have partial information about target words when in TOT states, and that the retrieval difficulty appears to be at the phonological level.
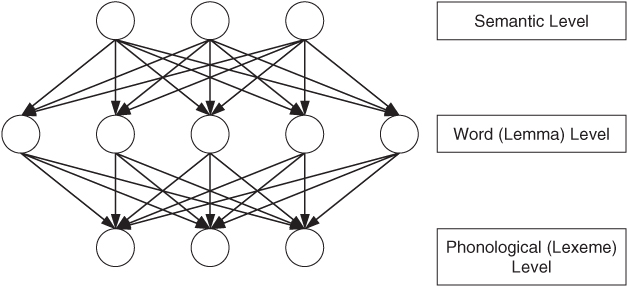
Brown and McNeill (1966) had proposed that TOT phenomena are due to only partial activation of the phonological specification of a word, particularly for the beginning sounds or letters. A more contemporary theory that includes this notion of partial activation is the transmission deficit model by Burke, MacKay, Worthley, and Wade (1991; also MacKay & Burke, 1990). The transmission deficit model is built on the node structure theory, a connectionist model developed by MacKay (1982, 1987), depicted in Figure 9.9. At the top are semantic or meaning nodes; during experiments in which a definition is provided, these nodes are already activated. They then send activation down to the word nodes (also known as lemmas), which contain grammatical information, including word class and gender of nouns in some languages (such as Spanish, French, and Italian), and so forth. Activation then spreads to the phonological level, where the phonemic representation of a word (or lexeme) is activated.
Figure 9.9 Node structure theory: A PDP model that has been proposed as an explanation for tip-of-the-tongue phenomena.
The transmission deficit model explains TOTs as being caused by weak connections between the word and phonological levels, typically because only low-frequency words that we rarely use produce tip-of-the-tongue states. Weakened connections may also explain why bilingual people exhibit more TOT states than monolinguals (Colomé, 2001;Ecke, 2004): Dividing speech between two spoken languages may result in lower frequencies for all lexical entries, and thus weakened connections between a word and its phonological representation (Pyers, Gollan, & Emmorey, 2009).
If the transmission deficit model/partial activation theory is correct, then: (a) word-related information about a TOT word should be available, such as the grammatical class of the word, and its masculine or feminine designation of nouns in romance languages; and (b) any extra activation that can accrue at phonological nodes should facilitate retrieval. Phonological hints and similar sounding words should thus lead to resolution of a TOT more than semantic hints or semantically-related words. Research has found that people who speak languages in which nouns are designated as masculine or feminine, such as French or Italian, can retrieve the gender of a word a majority of the time (Ferrand, 2001; Miozzo & Caramazza, 1997).
Meyer and Bock (1992, Experiment 2) induced TOT states in college students (e.g., what word means saying little, reserved, uncommunicative; Answer: taciturn), and then provided either a phonological hint (e.g., tolerant), a semantically-related hint (e.g., withdrawn), or an unrelated hint (e.g., baby). Resolution of TOT states was more than twice as likely following a phonological hint than after a semantic hint. Activating the initial phoneme of the target with a phonologically similar cue (which also shared the number of syllables and stress with the target) led to activation of the rest of the target. White and Abrams (2002) also found that same-first-syllable cues (e.g., aberrant for the target word abdicate) were more likely to result in TOT resolution than second- (e.g., handicap) or third-syllable primes (e.g., educate) in groups of people aged 18–26 and 60–72. However a group of older participants (aged 73–83) did not significantly benefit from any phonologically similar cues, relative to unrelated prompts. These age-related findings are consistent with the idea that connections among nodes in semantic memory, and transmission from node to node, weaken with age, due perhaps both to the aging process itself and decreased use of low frequency words (Burke, MacKay, Worthley, & Wade, 1991; MacKay & Burke, 1990).
A study by Kikyo, Ohki, and Sekihara (2001) used fMRI to measure brain activity while Japanese people attempted to retrieve proper names of people in the news (e.g., politicians, scientists, heads of companies). An identifying question appeared on a screen (e.g., “Who established SONY?”), and participants pressed button 1 if they knew the target, button 2 if they did not know. TOT states were considered those in which the person took over 6 seconds to correctly retrieve the answer. The researchers found increased activation in the left dorsolateral prefrontal cortex and anterior cingulate gyrus during successful retrieval of TOT targets, while neither site was active when people were unable to retrieve the target. This indicates that these areas in the left hemisphere may be active in word retrieval.
A neuropsychological disorder in which people experience chronic TOT states is anomia (meaning without [a-] name [nomia]). Anomic people have difficulty producing the names of even common objects. Retrieval is especially impaired for low frequency words (Goodglass, 1980; Martín, Serrano, & Iglesias, 1999; Raymer, Maher, Foundas, Rothi, & Heilman, 2000). This symptom can exist on its own, or as a symptom of aphasia, Alzheimer's disease (Joubert et al., 2008), or temporal-lobe epilepsy (Trebuchon-Da et al., 2009). Although we all experience word-finding difficulties occasionally, such as when we are under stress or fatigued, people with anomia often have more profound problems that render them unable to retrieve the labels of familiar, though often infrequently encountered, objects. During word production, they may often substitute a similar-meaning word for the target (e.g., calling a beaver a “chipmunk”), which is a semantic error; or a higher-level category name (e.g., saying “a musical instrument” for flute; Martín, Serrano, & Iglesias, 1999). As we saw in Chapter 8, researchers have also found that some categories, such as living creatures, are subject to greater naming difficulties than others (e.g., Goodglass, Wingfield, Hyde, & Theurkauf, 1986; Kolinsky et al., 2002).
There are two major ways in which naming and word-retrieval difficulties may exhibit themselves, which may correspond to activity in different brain areas. Upon being presented with a definition, picture, or object to identify, people with brain damage may have degraded semantic knowledge, and thus may be unable to even place the object in its correct category (e.g., they are unable to say that a spatula is a “utensil”) or describe its function (to flip pancakes or hamburgers). This is known as semantic anomia, and is typically associated with damage to left or bilateral anterior temporal lobe regions due to progressive dementia (Binder & Price, 2001; Bright, Moss, & Tyler, 2004; D'Esposito et al., 1997; Moore & Price, 1999; Vandenberghe, Price, Wise, Josephs, & Frackowiak, 1996). Pure anomia, in contrast, is a condition more like being in a perpetual TOT state, and involves problems with retrieval of phonological information. These patients know the meaning and function of an object (e.g., saying “You sleep on it” for a hammock; Antonucci, Beeson, & Rapcsak, 2004), but without a hint, are unable to retrieve its name (Antonucci, Beeson, Labiner, & Rapcsak, 2008;Benson, 1979, 1988; Foundas, Daniels, & Vasterling, 1998; Raymer et al., 1997). Pure anomia is associated with left inferior posterior temporal lobe damage (Binder et al., 1997; Damasio, Grabowski, Tranel, Hichwa, & Damasio, 1996). Thus, when discussing the processes that occur when someone is asked to name a picture, researchers have agreed upon a series of stages: visual processing of the picture, activation of the semantic representation (including activation of the abstract version of the word, known as the lemma), and retrieval of the label and its phonological representation (Watamori, Fukusako, Monoi, & Sasanuma, 1991). Semantic anomia is a breakdown at the second stage, while pure anomia occurs at the last stage, during phonological representation of a word (Badecker, Miozzo, & Zanuttini, 1995).
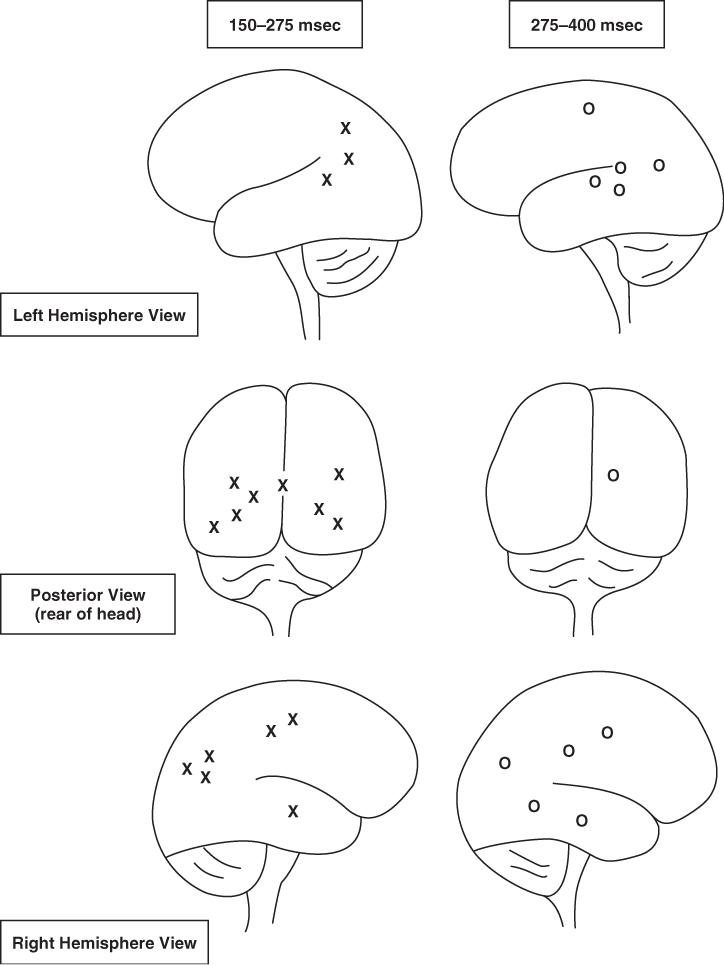
Levelt, Praamstra, Meyer, Helenius, and Salmelin (1998) studied the time course and brain activation of cognitive steps in picture naming in normal patients using a neuromagnetometer (similar to an EEG, but measuring magnetic fields to determine cortical activation). The average time to name a picture was 538 milliseconds (although pictures with low frequency names, such as rake or sled, took longer to name than high frequency ones, such as dog or pants). The researchers proposed lemma activation took place 150–230 milliseconds after picture presentation, and was accomplished by bilateral activity in the occipital and parietal cortex, with some temporal lobe activation (see Figure 9.10). Phonological encoding of the actual verbal label corresponded to activation of left temporal regions in and around Wernicke's area about 200–350 milliseconds after presentation of the target.
Figure 9.10 Activation of brain areas during lemma selection (X's) and phonological encoding (O's), as depicted in left hemisphere (top), posterior (middle), and right hemisphere (bottom) views, at two time intervals after presentation of word stimuli.
Adapted from Levelt et al., 1998.
Laganaro, Morand, and Schnider (2009) discovered different time courses in lexical retrieval for anomia due to semantic impairments (semantic anomia) versus those due to phonological impairments (pure anomia). They studied EEG data from 16 aphasia patients who were engaged in a picture-naming task. Half of the patients typically produced semantically based errors during naming, the other half produced predominantly phonological errors. Those with lexical-semantic impairments tended to show abnormal EEG patterns relatively soon after presentation of a picture, within 90–200 milliseconds. The lexical-phonologically impaired patients (pure anomics) were more likely to show abnormalities after 300 milliseconds, perhaps as they were retrieving the phonological specification of the word. In conclusion, studies of lexical activation, including research on TOT states and anomia, have provided evidence concerning factors involved in activating words in memory and the brain areas that contribute to lexical retrieval. Further information on word activation comes from studies that have investigated the processing of ambiguous words in sentence contexts, to which we now turn.
A standard children's joke asks, “Why was six scared of seven?” Answer: “Because seven eight (ate) nine!” When spoken, the joke hinges on lexical ambiguity, because the word pronounced as ate is ambiguous, or is polysemous (poly = many; semous = meaning). It can mean both the number eight and the past tense of eat. Appreciating the joke requires that a person access both meanings, and realize that the standard interpretation within the seven, eight, nine sequence is not correct. Someone figuring out the joke might say: “‘Because seven, eight, nine’? Huh? Oh! ‘Seven ate nine.’ Now I get it.” But what about when your friend says she needs to deposit a check at the bank? You may only be aware of interpreting bank as a place for money, but bank is also an ambiguous word: savings bank and river bank. There is evidence that we may sometimes activate both meanings when we comprehend a message containing an ambiguous word, even though we are aware of only the meaning that fits the context. Processing of ambiguity has thus provided information on how people access word meanings.
In a pioneering study, Swinney (1979; also Swinney & Hakes, 1976) examined lexical access using a cross-modal priming task. Experimental participants listened to a passage that contained an ambiguous word while simultaneously engaging in a visual lexical-decision task, where they had to decide whether a string of visually presented letters formed a word. For instance, people would hear:
Rumor had it that, for years, the government building had been plagued with problems. The man was not surprised when he found several roaches, spiders, and other ______ in the corner of his room.
Figure 9.11 Outline of Swinney paradigm to study activation of meanings of ambiguous words during sentence processing.

In the empty slot, half of the participants heard the ambiguous word bugs (which could mean insects or spy-related listening devices), the other participants heard the unambiguous word insects. As soon as either of those critical words ended, a visual target word appeared on the computer screen in front of them. The target word was (a) related to the dominant meaning of the ambiguous word as implied by the sentence (e.g., ANT); (b) related to the alternate meaning of bugs (e.g., SPY); or two control conditions in which the target word was either (c) unrelated to the sentence (e.g., SEW), or (d) not a word (XNR). The task for the participants was to report as quickly as possible whether the target was a word. The entire experimental task is outlined in Figure 9.11.
When the unambiguous word (insect) was in the sentence, people were fastest to respond to the word related to its meaning (ANT), as would be expected (Swinney, 1979). When the ambiguous word (bug) was in the sentence, however, people were faster to respond to both meanings (ANT and SPY). Based on these and other similar results, a number of researchers have proposed an exhaustive-access view of lexical processing (Onifer & Swinney, 1981; Seidenberg, Tanenhaus, Leiman, & Bienkowski, 1982;Swinney, 1979; Tanenhaus, Leiman, & Seidenberg, 1979). According to this view, when a person encounters an ambiguous word, all its meanings are activated, regardless of context (Tabossi, 1988). After all meanings have been activated, a second post-access process sways the final interpretation toward the intended meaning, based on the context of the sentence. Evidence suggests that both meanings are not necessarily accessed simultaneously; the dominant meaning of a word, in virtue of its greater frequency (it is the dominant meaning because it is the one more frequently used), has a lower threshold, is activated almost immediately (Paul, Kellas, Martin, & Clark, 1992), with the subordinate meaning activated within 100 milliseconds (Simpson & Burgess, 1985, 1988).
However, there is evidence that, under some specific circumstances, only one meaning of an ambiguous word is accessed, and selective access theories propose that only the meaning relevant to the sentence context is activated (Glucksberg, Kreuz, & Rho, 1986; Schvaneveldt, Meyer, & Becker, 1976;Simpson, 1981). For example, if one presents an ambiguous word in a linguistic context that highly constrains the dominant meaning, there is no activation of the subordinate meaning (Tabossi, 1988, Experiment 2; Tabossi & Zardon, 1993). A second factor that influences the activation patterns of the meanings of ambiguous words may be whether the two meanings of the term are balanced (relatively equal in frequency of usage) or biased (where one meaning occurs much more frequently). During reading, people look longer at balanced words (as if trying to resolve which of the two meanings is meant); but they look no longer at biased ambiguous words than they do at control (single-meaning) words (Rayner & Frazier, 1989). Presenting disambiguating information that precedes the ambiguous word (e.g., kitchen table versus statistical table) can also alter reading patterns. Disambiguating information that supports the subordinate or less-frequent interpretation of a biased ambiguous word increases reading times for that word (Rayner, Cook, Juhasz, & Frazier, 2006). This suggests that, in cases where only the dominant meaning of a word would normally be activated, extra processing time is needed to resolve competition between the dominant and subordinate interpretations when the latter is activated because of the disambiguating information. It should be noted, however, that the research discussed in this section has examined processing of ambiguous nouns. Processing of other types of ambiguous words, such as verbs (e.g., lie; Pickering & Frisson, 2001), may involve different activation patterns, based on sentence context.
In summary, there is substantial evidence that multiple meanings are activated when we hear or read ambiguous words. When no context is provided, the dominant meanings of ambiguous words are activated first (Simpson & Burgess, 1985; Simpson & Krueger, 1991), because they may have lower thresholds due to their higher frequency, followed by access of the subordinate meanings of the word. When a context is provided by a sentence or other constraining factor, both meanings are sometimes activated, but the irrelevant meaning may be suppressed in favor of the context-relevant interpretation (Tabossi & Zardon, 1993).
Wernicke's aphasia is usually due to damage to the superior temporal gyrus of the left hemisphere. Historically, Wernicke's aphasia was referred to as receptive aphasia, because patients' main deficit is in recognizing incoming speech; or as fluent aphasia, because Wernicke's patients can speak fluently (i.e., in well-formed sentences), although their sentences are often meaningless. Here are two examples of utterances produced by patients with Wernicke's aphasia.
I called my mother on the television and did not understand the door. It was too breakfast, but they came from far to near. My mother is not too old for me to be young. (http://atlantaaphasia.org/WhatIsAphasia02.html)
You know that smoodle pinkered and that I want to get him round and take care of him like you want before. (http://www.nidcd.nih.gov/staticresources/health/voice/FactSheetAphasia.pdf)
As can be seen, the spoken utterances of Wernicke's aphasics are peppered with neologisms (nonsensical words) and paraphasias (errors of various sorts, either semantic paraphasias, e.g., word substitutions, or phonemic paraphasias, e.g., mispronunciations). The first patient exhibits mainly semantic paraphasias, and the second exhibits more neologisms.
Researchers have proposed that neologisms and paraphasias may be due to overactivation of lexical entries (Milberg, Blumstein, & Dworetsky, 1988); or to a competition among lexical items, in which items that should be rejected fail to become deactivated (Janse, 2006). By way of illustration, Yee, Blumstein, and Sedivy (2008) measured eye movements during a picture-finding task. An auditory target word (e.g., “tuba”) was presented, along with a three-by-three matrix containing four pictures—one in each corner (see Figure 9.12). Participants were to touch the computer screen on the area where the target picture (tuba) appeared. In Experiment 2, the pictures were (a) the target (e.g., tuba); (b) a picture whose name began with the same first syllable (e.g., tulip), and (c) two control items (e.g., owl and olives). The participants without aphasia glanced at the nontarget pictures, but then suppressed looking toward the same-first syllable item once they realized that it was not the target. Wernicke's aphasics, on the other hand, fixated longer on the nontarget pictures with similar phonological beginning (e.g., tulip). This indicated that phonological competitors to the auditory target remained activated longer than normal. In Experiment 3, Yee et al. determined that phonological competitors were not only activated, but also spread their activation to semantically associated items; Wernicke's patients who heard hammock looked longer at a picture of a nail than at the controls. That result was interpreted as evidence that hammock had activated the phonologically related lexical entry for hammer, which in turn spread activation to nail. Thus, words in the lexical system in Wernicke's aphasics may both become overactivated and spread activation to multiple other words (Yee et al., 2008), resulting in a problem opposite to that suffered during tip-of-the-tongue states.
Figure 9.12 Stimulus matrix similar to those used by Yee et al. (2008) to examine activation of information in aphasic participants versus non-aphasic participants.

Harpaz, Levkovitz, and Lavidor (2009) used transcranial magnetic stimulation (TMS) to determine the role of Wernicke's area and its right-hemisphere analogue (the area in the right hemisphere comparable in location to Wernicke's area in the left hemisphere) in activation of the dominant versus subordinate meanings of ambiguous words. In Chapter 1, we reported two uses of TMS—one to functionally paralyze or deactivate parts of the brain. This is typically done by applying low-level frequencies to a region to inhibit performance of that region. The second method was used by Harpaz et al., and involved using a short burst of high-frequency waves to increase activity in that area (see also Mottaghy et al., 1999; Sparing et al., 2001). When high-frequency TMS was applied to Wernicke's area in the LH, people were better at making semantic-decision judgments based on the dominant meanings of words; when applied to the corresponding area in the right hemisphere, people were faster at responding to the subordinate meanings of the ambiguous words. This result supports the idea of lateralization of activation of word meanings, with the left hemisphere being best at processing dominant meanings. This result is consistent with early research that reported that right hemisphere damage was most likely to lead to an inability to understand jokes (Gardner, Ling, Flamm, & Silverman, 1975), since jokes often hinge on focusing on the contextually subordinate meaning of an ambiguous word (as in the “seven eight/ate nine” example at the beginning of this section).
We all suffer from tip-of-the-tongue states occasionally, especially for low frequency words. However, even in TOT states, people often have partial information about a target word available, such as the first or last phoneme or syllable (Brown & McNeill, 1966). With both normal people and pure anomics, the block seems to be at retrieving the phonological representation of the word, which is why phonologically related hints often facilitate retrieval. Research on processing lexical ambiguity indicates that multiple meanings of words are often activated, and then the system utilizes the interpretation that best fits the sentence context. When a context is provided by a sentence or other constraining factor, the irrelevant meaning may be suppressed in favor of the context-relevant interpretation. In this way, a person's mental lexicon can accommodate the multiple meanings of many words, without the meanings of words being in competition with each other indefinitely. In addition, studies of brain functioning in lexical access indicate that there may be lateralization of meanings of ambiguous words. Such studies shed light on lexical storage of words, and psychological processes such as word retrieval.
Many words have a complex internal structure that allows people to use language creatively and to convey subtleties about words and meanings. Consider, for example, the word untied, as in I untied my shoes. Untied has three parts: tie, which is a word that has meaning and can stand on its own; and un- and -ed, both of which are not separate words, but which convey meaning nonetheless. Un- tells you that the action being carried out is the opposite of tie, and -ed tells you the action took place in the past. These small particles of meaning, the smallest units of meaning in a language, are called morphemes. Books is constructed out of two morphemes—book plus the plural morpheme -s, which signals that more than one book is being discussed. Morphemes, such as tie and book—single words that can stand alone—are called free morphemes. Morphemes that cannot stand alone, like un-, -s, and -ed, are called bound morphemes. The study of the morphemic structure of words is called morphology. Specifying the mechanisms through which we combine morphemes into words will help us understand important aspects of language functioning and language development.
There is a high degree of regularity in how bound morphemes are combined with free morphemes to create new words. As one example, verbs are made into adjectives in English by adding suffixes, or endings, such as -able, as in imaginable. The suffix -ism (as in Darwinism, or Marxism) makes one kind of noun out of another (“I am not a believer in Marxism”). The suffix -ian, as in Marxian or Mozartian, makes an adjective out of a noun (“That philosophy sounds Marxian”). Similarly, the suffix -er makes any verb a noun, as in writer and reader. There is ample evidence from adult, child, and aphasic data that we access morphemes separately when we speak (e.g., read + er), and that we decompose multimorphemic words into their components in word recognition, spelling, and other tasks. For example, Laine and Koivisto (1998) determined that multimorphemic words take longer to recognize than single-morpheme words in a lexical decision task.
The most widely used suffixes in English signal pluralization of nouns and the past tense of verbs. These endings, or any alteration to a word to indicate tense, number, person, or case, are called inflections. (Note that inflection as it is used here is morphological, and not the same as the prosodic aspects of language that we discussed earlier in the chapter.) Most nouns can be made plural by adding the plural morphemes, -s or -es. A similar phenomenon occurs with verbs. One can take almost any verb and speak about the action having occurred in the past by adding the appropriate inflection—in English it is written as -ed. Both these cases seem to indicate application of rules in English.
A groundbreaking study of the potential importance of morphological rules in the child's learning to speak was carried out by Berko (1958). Berko set out to demonstrate that, early in their development as speakers, children were learning rules of language, as demonstrated by how they used morphemes for particular grammatical classes of words. She exposed children to novel nouns and verbs, and studied how the children constructed new plurals and past tenses. For example, a child was presented with a card with a novel animal pictured on it, which was labeled a wug by the researcher. The child then saw a new card, with two of the new creatures on it, and the experimenter said: “Here is another one. Now there are two of them. There are two _____.” Most children responded with “wugs.” They had no difficulty creating the correct plural form for a new noun at the first opportunity. In another condition, a new verb was introduced. A child saw a picture of a girl doing something unfamiliar such as building a structure with sticks, while the experimenter said: “Here is a girl who knows how to rick. She is ricking. She did the same thing yesterday. What did she do yesterday? Yesterday she ______.” This time the children responded with ricked, the correct past-tense form.
Berko's (1958) study provided clear evidence that young children can generalize to new examples the morphological forms that they have heard. Her results have also been cited as evidence that children are able to learn morphological rules, such as “-ed is applied to the end of verbs to indicate past tense,” that are then appropriately applied to new words (seePinker, 1994, Chapter 2). As we shall soon see, these results are still important in theoretical analyses of language processing, especially as to whether children learn morphological rules (Berko, 1958;Pinker, 1994) or merely patterns (McClelland & Rumelhart, 1986; Plunkett & Marchman, 1993, 1996).
In many languages, such as English, there are a large number of irregular verbs for which the rules for past-tense formation do not apply, such as do/did; come/came; think/thought; draw/drew; be/was; see/saw; and go/went. In addition, some verbs do not change at all from past to present, such as cut, set, hit, and put. Children sometimes produce overregularizations, by adding -ed to the end of irregular verbs to indicate past tense (e.g., goed). There are also nouns in English which violate the rule of adding /s/ to form the plural, such ox/oxen and foot/feet. However, the irregular verbs have been of much more interest to researchers, so we will concentrate on them here. Children's production of regular and irregular verbs has been a testing ground for whether rule learning (Chomsky, 1959;Marcus, 1996;Pinker, 1994) or induction of high-probability patterns underlies language acquisition.
A recent analysis has examined the frequency of 40 million words in contemporary American English, taken from many different sources: transcripts from spoken language, books—fiction and nonfiction—newspapers, magazines, and so forth (http://www.wordfrequency.info/; retrieved October 8, 2012). If we consider the 5,000 most frequent words from that corpus, the 10 most frequent verbs on the list are: be, have, do, say, go, can, get, make, know, think. All of those high-frequency verbs are irregular, and many of their alterations to past tense are unique in the language. That is, once you have learned that the past tense of say is pronounced said, there is no transfer in form to the past tense of similar root morphemes, such as pay, stay, or play. Thus, irregular verbs do not typically permit rule learning; often, one simply has to remember the specific exemplars of the various irregular tenses.
Here is another group of verbs, taken randomly from near the bottom of the top-5,000 list, from positions 4,136–4,189: tackle, heat, tuck, post, specialize, sail, condemn, unite, equip, exchange. All those less-frequent verbs are regular, which means that the pattern found in one verb can help in forming the past tense of other verbs; once you have learned that the past tense of post is posted, it can help you to form the past tense of roast, toast, host, and boast, among others.
Examination of the development of the past tense in the speech of children shows an intriguing pattern in their use of regular versus irregular forms (Marcus, 2000;Pinker, 1991, 1994; Plunkett & Marchman, 1993). The earliest verbs used by children, usually in the second year, are typically the highly frequent irregular verbs, and they are used correctly: The child says came, went, and did. Since these verbs are so frequently heard by the child in the speech environment, it is not surprising that they are learned first and used correctly. Shortly thereafter, however, most children begin adding the regular ending to irregular verbs, producing forms that are never heard in ordinary adult speech: comed, goed, and doed. This phenomenon is called overregularization: The child takes the regular form and uses it in places where it is incorrect. Overregularized forms are found less than 3% of the time when children use past tense (Marcus et al., 1992), but their occurrence does seem to indicate rule learning, since children are unlikely to have heard adults use those overregularized past-tense forms. Later, children produce the correct form of irregular verbs (Cazden, 1968; Ervin & Miller, 1963; Miller & Ervin, 1964; Pinker & Prince, 1988).
Thus, there appears to be a U-shaped form to development of past-tense usage (Marcus et al., 1992). First the child learns each verb separately, by rote, producing correct endings for irregular and regular verbs. Second, the child learns the rule for forming the past tense (add -ed), and he or she extends that rule to every verb that is produced, which results in overregularization errors for irregular verbs (Marcus, 1996, 2000). Third, with increasing exposure to irregular verbs, each of them begins to function again as an independent unit and the correct irregular form is retrieved and produced. It is as if a competition arises between the rule and the specific irregular form. Once the irregular form gets strong enough and fast enough, it becomes too fast for the rule to block it, and is correctly produced.
As just discussed, the development of overregularizations has been explained by appealing to the child's learning an implicit rule for how to produce the past tense. This perspective is consistent with Chomsky's (1959) proposal that innate, language-specific grammatical rules are triggered in the child, based on the language that the child hears (Pinker, 1991). An alternative explanation that has been considered by researchers does not rely on the notion of linguistic rules, however. This alternative perspective assumes that only one learning mechanism is involved in learning to produce the correct past tenses of all verbs, regular and irregular: Children rely on whatever associations between linguistic elements are strongest at a given time. When the -ed to indicate past tense becomes prevalent, they will append -ed to both regular and irregular verbs. Then, as they continue to hear the irregular past tense versions of words such as sing/sang, write/wrote, eat/ate, those associations will each strengthen, and children will return to the correct forms of those verbs. In this view, there are no “rules,” per se, merely strengths of associations among linguistic elements. This perspective has been represented in parallel-distributed processing models of verb learning (e.g., McClelland & Rumelhart, 1986; Plunkett & Marchman, 1993, 1996). As we know from Chapter 1, such models are trained to generalize patterns from repeated stimuli, and to use those patterns to assign strengths of connections between stimulus elements, either between a verb and the -ed suffix, or, eventually, between an irregular verb and its proper past-tense form.
Plunkett and Marchman (1993, 1996) carried out a series of investigations in which they exposed a PDP model to a vocabulary of verbs, structured similarly to the vocabulary to which a young child might be exposed, to investigate the similarity between the model's output and the productions of children. As the network was being exposed to an increasing number of words, both regular and irregular verbs, the model was subjected to periodic tests, in which both familiar and unfamiliar verbs were presented to see which past tense form the model produced. At first, the network (just like children) produced the irregular verbs correctly, since each one of them had been presented a relatively large number of times, and each verb was relatively unique. With more training, however, and increasing exposure to a wide range of regular verbs, the network began to produce overregularizations of irregular verbs, similar to what occurs with children. Finally, further exposure to the irregular verbs strengthened connections between the present and past tense of those words, and irregular past tenses again were produced correctly.
The important point emphasized by those adopting a PDP perspective (e.g., Plunkett & Marchman, 1996) is that the model simply responds to the patterns in the input, rather than either implicit or explicit rules (but seeMarcus, 1995, 1996, for a critique). This assumes that there is only one learning mechanism—associationism—operating throughout the process of learning past tense. That is, there is no rote learning, followed by rule development, followed by blocking the application of the past-tense -ed rule. Rather, changing associative weights between morphological elements—present-tense and past-tense forms—can explain the early correct use of irregular forms, the later overregulation responses, and the final return to correct use of irregular forms. The evidence from such PDP models has been used to argue against Chomskian claims of an innate language-specific module, because general associative learning principles seemingly explain the U-shaped nature of past-tense verb use in children.
However, Pinker (1991) has maintained that a combination of both the rule-based and associative mechanisms best explains the developmental data: rule-based computation of past tense for regular verbs, and associated memory links between the present and past tense of irregular verbs. On the one hand, Pinker noted that trained neural networks often supply unusual past tense forms which humans themselves do not produce, such as when a neural network produced “wok” as the past tense of “wink” (Pinker, 1994). On the other hand, humans who are confronted with a nonsense verb, or a noun that is to be changed to a verb, usually use the regular -ed inflection (as when we tell a classmate, “I friended you on Facebook”). Similarly, connectionist models that rely on associative memory are just as likely to spit out “freezled” as the past tense of the nonsense verb frilj (Pinker, 1994). Thus, it may be that new verbs and low-frequency verbs are converted to past tense based on rules, whereas only high-frequency verbs are maintained with irregular verb status (Bybee, 1985), because their high frequency permits greater connections that help retrieve the irregular past-tense lexical forms from associative memory (Pinker, 1991).
Children's production of overregularizations and their eventual switch to correct forms of irregular nouns and verbs raises the issue of what counts as a “word” in the lexicon. One possibility is that, even as adults, we store in our mental dictionary roots and morphemes independently, and then combine tenses (-s, -ed, -ing), plurals (e.g., -s, -es), and so forth as needed during speech (MacKay, 1979; Murrell & Morton, 1974; Smith & Sterling, 1982;Taft, 1981). The alternative is that we have multiple forms of any given word stored (bed, beds, bedding, etc.) and simply retrieve these lexical units directly, much like older children are able to retrieve irregular nouns and verbs (Aitchison, 1987;Monsell, 1985;Sandra, 1990).
Two main techniques have been used to test which theory—roots+morphemes versus multiple lexical forms—is correct. Consider people's possible performance on a lexical-decision task in which multimorphemic words, such as impartial or hunter, are presented. Based on the roots+morphemes view, people should be slower to respond to multimorphemic words, because two or more morphemes must be activated. However, lexical access times should not differ if words are stored as wholes, in all their various forms. MacKay (1979) found that reaction times to words increased as the number of constituent morphemes increased. Suffixed words, such as hunter, also take longer than pseudo-suffixed words, such as daughter (which cannot be broken down into a root morpheme, daught- and -er).
There is evidence that many multimorphemic compound words, such as teacup, may also be composed of separate lexical entries (Fiorentino & Poeppel, 2007). As one example, compounds composed of two high-frequency constituents (e.g., birthday) are recognized faster than those in which only the first or second constituent is of high frequency (e.g., birthday versus handcuff or scrapbook—in which “hand” and “book” are high frequency, but “cuff” and “scrap” are not). This suggests that both component words contribute to recognition (Andrews, 1986; Andrews & Davis, 1999). However, very common compound words, such as butterfly or gingerbread, may have developed into complete morphological units on their own in the lexicon, so that they are no longer processed as butter+fly as we speak or listen (Monsell, 1985; Osgood & Hoosain, 1974;Sandra, 1990). For example, in lexical decision tasks, bread semantically primes butter (Meyer & Schvanevedlt, 1971); however, bread does not prime butterfly, indicating that butterfly (and other compound words) may be stored as separate representations (Monsell, 1985; Osgood & Hoosain, 1974;Sandra, 1990). Ullman, et al. (1997; also Vannest, Polk, & Lewis, 2005) have provided neuropsychological evidence that supports the idea that two different types of processes are involved in word production. Lexically based retrieval of irregular noun/verb forms relies on medial/temporal lobe activity, while decompositional, rule-based processing of regular forms activates frontal lobes and underlying basal ganglia.
Evidence from neuropsychology patients also supports a decompositional view of morphology. On a number of tasks—spontaneous speech, picture naming, spelling to dictation, verbal repetition—aphasic patients show an ability to independently access, combine, or substitute morphemes (Badecker & Caramazza, 1987;Miceli, 1994). For example, Romani, Olson, Ward, and Ercolani's (2002) patient, D.W., produced “coatyard” instead of “courtyard,” and often added endings to words, even when it did not result in a real word (e.g., “older” became “olders”). Patient F.S., studied by Miceli (1994), produced morphological errors in a repetition task of Italian words, often substituting the wrong gender- and number-based case markers. Badecker (2001) studied an aphasic patient whose picture naming resulted in more errors for compound word targets (e.g., “downpour” became “down storm,” and “butterfly” became “butter flower”). The morpheme maintained in compound word errors was usually the one with higher frequency.
Because Finnish is a morphologically rich language that uses multiple cases for pronouns, verb tenses, adjectives, and most forms of speech, interesting data have arisen from Finnish aphasics. One such patient, studied by Laine, Niemi, Koivuselkä-Sallinen, & Hyönä (1995), often made stem+affix errors (see alsoKukkonen, 2006). These cases demonstrate that these patients access morphemes independently, even in compound words such as butterfly, and can combine morphemes to produce novel (albeit illegal) words, and are not merely accessing multisyllabic words directly from the lexicon.
The two areas in which morphology has been most studied are overregularization of children's verb tenses and the related issue of how words are stored and retrieved from the lexicon. The evidence from both child speech and PDP models suggests that children use rule learning to generate verb tenses, but also rely on associative memory for irregular verbs. Thus, language development appears to rely on both rules and patterns, in partial support of both the rule-based/computational and emergent viewpoints. We will come across similar issues—each view may explain part of the results, rather than one view being correct and the other incorrect—when we consider the development of sentence production in the next chapter. Research from multimorphemic words—free morphemes plus tenses and plurals—and compound words supports a decompositional approach to the lexicon, with root and bound morphemes stored separately and combined as needed during speech. The exceptions are (a) irregular verb forms, and (b) high-frequency compound words, which may, over time, have earned their own lexical representations.
Modern brain-imaging techniques have made it possible to observe which brain areas are active during processing of words. Petersen, Fox, Posner, Mintun, and Raichle (1988) used PET to isolate areas active in the processing of word meaning. The multilevel task that they used is shown in Figure 9.13, and is based on the subtraction method outlined in Chapter 1. The first task was simply visual presentation of a fixation point. The second task level required passive registration of words presented every 1.5 seconds either visually or auditorily (with no action required of the participant beyond looking or listening). The third task introduced word production, as the participants had to repeat or read aloud the words they had heard or seen, respectively. Finally, the fourth task added semantic processing to the components required, as the participants generated a use for the noun they heard or read (e.g., fork might lead the person to say “eat”). Thus, subtracting task1 from task2 isolates areas involved in passive word processing; subtracting task2 from task3 isolates areas serving word-production processes; and subtracting task3 from task4 isolates areas serving semantic processing.
Figure 9.13 Design of study by Peterson et al. (1988) investigating brain areas involved in processing word meaning.

The diagrams of activity for the various types of processing are shown in Figure 9.14. Passive processing of words (task2 minus task1) produced activity in modality-specific primary sensory areas. Viewing of words resulted in activation in the left and right occipital cortex. Passively listening to words, on the other hand, produced activity bilaterally in the temporal lobes—in brain areas dedicated to auditory processing, such as Wernicke's area in the LH and its analogous area in the RH. When participants had to produce speech in response to the words (to read the visually presented word or to repeat the auditorily presented one), both tasks activated similar motor areas of the brain bilaterally, especially areas in the right- and left-motor cortex involved in mouth and tongue movement.
Figure 9.14 Results of study by Peterson et al. (1988). Activation in left hemisphere (left side images) and right hemisphere (right side images), on lateral view of (external) cortex (top images) and inside longitudinal fissure between the hemispheres (bottom images). The key depicts areas most active during visual or auditory presentation of words, in which participants merely recognized the words (Sensory), said the words aloud (Output), or produced a related word (Association).
Finally, when the participants had to access the meaning of the words by generating a use for them, the areas now involved were similar for both the visual and auditory word tasks. They included left-hemisphere inferior frontal regions known to be involved in semantic association, and the anterior cingulate gyrus, part of the attentional system (see Figure 9.15). In conclusion, this study demonstrates the complexity of the processing that underlies accessing word meaning, with initial modality-specific sensory areas first registering stimuli, and later thought-related areas participating during both visual and auditory presentation of words. Posner and Raichle (1994/1997) commented that the Peterson et al. (1988) study also helped isolate the brain processes underlying conscious thought, because it separated the effects of input processing (passive perception of words) and output (speaking in response to words). One could conclude that when task3 is subtracted from task4, what remains are the processes involved in verbal conscious thought.
Figure 9.15 Anterior cingulate gyrus (inside longitudinal fissure; left hemisphere depicted).
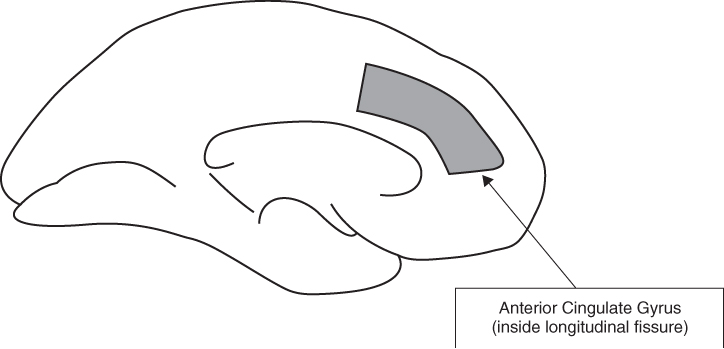
In another study on the physiological processing of words, Fridriksson, Baker, and Moser (2009) asked aphasia patients and normal control subjects to name aloud 80 colored pictures while undergoing an fMRI scan. Trials on which the pictures were correctly named were compared to those in which the participants made either phonemic or semantic errors. Correct naming in all participants was associated with widespread right hemisphere activation, especially the area in the right hemisphere corresponding to Wernicke's and Broca's areas (which are typically found in the left), plus the right motor cortex. Production of phonemic paraphasias (mispronunciations of a target word) engaged regions in the left inferior parietal lobe—known to be involved in phonological processing—and in the left occipital and posterior inferior temporal lobes. Semantic paraphasias (i.e., word substitutions), on the other hand, were associated with activation of the occipital cortex and posterior inferior temporal gyrus of the right hemisphere. Hickok and Poeppel (2007) have suggested that the left inferior temporal lobe regulates more-specific semantic designations, and the right hemisphere more-general semantic information. Thus, since semantic paraphasias are “in the ballpark” of the target terms (e.g., “horse” for “donkey”), greater RH engagement may only result in close, but not specific, lexical terms.
This chapter first introduced you to the different levels of linguistic analysis, and the major theoretical perspectives on language and language development. We then considered the phonological and morphological aspects of words, and how word meanings are acquired. At the level of phonology, important questions centered on how people analyze and process the sounds of language and whether or not that ability is supportive of a language module. Lexical, or word, acquisition was also examined from the perspective of whether innate versus social factors provide the impetus for language learning; much research suggests that both factors interact to permit a child's understanding and production of word meanings. Related to word learning is morphology, where the discussion centered on whether people learn word structure through learning of rules, or induction of morphological patterns. Neuropsychological syndromes have supplemented standard psychological experiments on cognitive processing of speech sounds and words, and have linked the various component skills involved in word use to particular areas of the brain.
Here are some questions to help you organize your review of this chapter.